T
T
H
H
È
È
S
S
E
E
En vue de l'obtention du
D
D
O
O
C
C
T
T
O
O
R
R
A
A
T
T
D
D
E
E
L
L
’
’
U
U
N
N
I
I
V
V
E
E
R
R
S
S
I
I
T
T
É
É
D
D
E
E
T
T
O
O
U
U
L
L
O
O
U
U
S
S
E
E
Délivré par l'Université Toulouse III - Paul Sabatier Discipline ou spécialité : Océanographie physique
JURY
Serge Chauzy, président, professeur émérite de l'Université Paul Sabatier (Toulouse) Eric Blayo, rapporteur, professeur à l'université Joseph Fourier (Grenoble) Andrew M. Moore, rapporteur, professeur à l'université de Californie (USA)
Magdalena Balmaseda, chercheur sénior à l'ECMWF (Reading, U.-K.) Gérald Desrozier, chercheur à Météo-France (Toulouse)
Arthur Vidard, chercheur à l'INRIA (Grenoble) Anthony Weaver, chercheur au CERFACS (Toulouse)
Olivier Thual, professeur à l'INP Toulouse
Ecole doctorale : Sciences de l'Univers, de l'Environnement et de l'Espace Unité de recherche : CERFACS
Directeur(s) de Thèse : Anthony Weaver et Olivier Thual Rapporteurs : Eric Blayo et Andrew M. Moore Présentée et soutenue par DAGET Nicolas
Le 9 juin 2008
Titre : Estimation d'ensemble des paramètres des covariances d'erreur d'ébauche dans un système d'assimilation variationnelle de données océaniques
UNIVERSIT´E DE TOULOUSE III – PAUL SABATIER ´
Ecole doctorale« Sciences de l’Univers, de l’Environnement et de l’Espace » U.F.R. Physique Chimie Automatique
TH`
ESE
pour obtenir le grade de
DOCTEUR DE L’UNIVERSIT ´
E DE TOULOUSE
d´elivr´e par l’Universit´e Toulouse III – Paul Sabatier Sp´ecialit´e : Oc´eanographie Physique
pr´esent´ee et soutenue par
Nicolas DAGET
le 9 juin 2008
Estimation d’ensemble des param`
etres
des covariances d’erreur d’´
ebauche
dans un syst`
eme d’assimilation
variationnelle de donn´
ees oc´
eaniques
Th`ese dirig´ee par
Olivier THUAL
Th`ese encadr´ee parAnthony WEAVER
Pr´esident : Serge Chauzy Universit´e Paul Sabatier, Toulouse, France.
Rapporteurs : Eric Blayo Universit´e Joseph Fourier, Grenoble, France. Andrew M. Moore University of California, Santa Cruz, U.S.A.
Examinateurs : Magdalena Balmaseda ECMWF, Reading, United Kingdom. G´erald Desrosziers M´et´eo France, Toulouse, France. Arthur Vidard INRIA, Grenoble, France.
Travaux effectu´es au CERFACS
Centre Europ´een de Recherche et de Formation Avanc´ee en Calcul Scientifique 42, avenue G. Coriolis, 31057 Toulouse Cedex 01, France
Remerciements
Voici le moment le plus redouté. Celui qui risque de vexer les personnes « oubliées » ou, pire encore, citées après quelques autres qu’elles jugent de piètre valeur. Pour éviter cet écueil, je tiens d’abord à remercier tous ceux et celles qui attendent (légitimement) des remerciements. J’y met toute mon affection et bien plus encore. Qu’ils sachent qu’ils ont tous une place particulière dans mon c œur, que je les estime tous chacun plus les uns que les autres.
Je ne peux toutefois pas m’en tirer avec ces quelques ronds de jambes. Il faut bien que je cite quelques unes des ces personnes. Je remercie ainsi Jean-Claude André, directeur du CERFACS, de m’avoir accueilli pour cette thèse. Je tiens aussi à remercier Anthony Weaver qui m’a encadré, aidé, soutenu durant ces trois années. Cette thèse n’a été possible que par son entremise et ses conseils avisés qui m’ont guidés dans le monde de la recherche. Je remercie bien sûr le courage des mes deux rapporteurs, Andrew Moore et Eric Blayo, qui ont lu le manuscrit dans son intégralité. Je tiens aussi à remercier tous ceux qui ont participé plus ou moins directement à mon travail de thèse : Sophie Ricci avec qui j’ai beaucoup échangé, qui m’a aidé à éclaircir les points les plus obscures, qui a relu patiemment mon manuscrit et qui a partagé mon bureau ; Elisabeth Remy, Sébastien Massard, Olivier Pannekoucke, Philippe Rogel et Jean Tshimanga qui ont tous apportés quelques briques à mon travail ; Magdalena Balmaseda, Arthur Vidard et Kristian Mogensen qui, de plus loin, ont été de très bons conseils et m’on fait découvrir la belle ville de Reading. Je tiens aussi à remercier tous ceux et celles qui ont su me donner un petit coups de main pour résoudre les embûches informatiques : Eric Maisonnave qui a toujours su prendre de son temps pour me montrer comment il faisait si bien ce qu’il faisait et qui a, en plus, supporter trois années de bureau commun ; Isabelle Dast, Gérard Dejean et Fabrice Fleury de l’équipe informatique qui ont toujours su résoudre mes problèmes en un temps record malgré leur charge de travail ; Dominique Lucas qui, malgré la distance, a toujours été très réactif pour m’aider à domestiquer le calculateur du CEPMMT. Bien sûr, je n’oublie pas celles qui ont toujours été présentes et efficaces lorsqu’il s’agisait de me faire découvrir le grand monde : Nathalie Brousset et Isabelle Moity.
Mais une thèse ne se résume pas au travail proprement dit. L’environnement et l’ambiance joue un rôle fondamentale. Je dois donc remercier tout le personnel du CERFACS qui est par-ticulièrement accueillant et sympatique, et tout parpar-ticulièrement l’équipe Global Change and
Climate Modelling qui m’a accueilli en son sein. Je remercie les « jeunes » qui ont su créer une
ambiance détendue : Emilia Sanchez Gomez, Marie Minvielle, Cyril Caminade, Julien Boe, Ju-lien Najac. . . Je pense aussi à mes collègues de bureau Sophie Ricci et Eric Maisonnave qui ont su supporter mes transports et mes costumes de cycliste. Je remercie bien sûr Isabelle Moity avec qui je me suis occupé de la K’fet du CERFACS. Je pense aussi à toujours les joueurs de foot qui, sous ma direction, n’ont gagné aucun tournoi mais ont joué toute l’année et même les jours de grand froid. Je n’oublie pas non plus ceux qui ont usé leurs chaussures avec moi autour du lac de la Ramée. J’en oublie, j’en oublie. Je les remercie tous.
Et je continue car une thèse, c’est un laboratoire, mais c’est aussi trois années de vie. Trois années particulières qui n’ont pas toujours étaient simples pour les personnes les plus proches de moi. Je tiens à remercier, mais le mot est bien faible pour exprimer mes sentiments . . .Enfin, je remercie Malika Clouin pour ce qu’elle est et pour avoir supporté ces trois années faites de longues heures de train. Je remercie toute ma famille, car c’est la première fois que je peux le faire et c’est un réel plaisir. Donc, je remercie mes parents Colette et Bernard, mes sœurs Isabelle, Joëlle et Carelle, leurs maris Jean-Christophe, Emmanuel et Patrice et leurs enfants, si
nombreux, dont j’ai été bien distant durant ces trois années. Je ne résiste pas à les citer tous : Eloa, Clément, Maëline, Hina, Lauréna, Léane et Tinariko. Mais ma famille, c’est aussi Pierre, Ellé, Ghania, Michel, Patricia, Karim, Maéva, Auréa et Siham. Je pense aussi à mes amis qui sont toujours là et qui donnent ce goût si agréable à la vie : Silvia, Simon, J-B, Damien et Ali à Toulouse ; Zoé, François, Envel, Misako, Aurélie, Claude, Elie, Christel, Sabine, Paco, Farid et bien d’autres ailleurs.
Je fini ma logorrhée verbale par ce cri : Je vous remercie tous ! Merci. . .
L’amour d’un père est plus haut que la montagne. L’amour d’une mère est plus profond que l’océan.
Quatorzain pour tous Ô mes contemporains du sexe fort, Je vous méprise et contemne point peu, Même il en est que je déteste à mort Et que je hais d’une haine de dieu. Vous êtes laids moi compris au-delà De toute expression, et bêtes, moi Compris, comme il n’est pas permis : c’est la Pire peine à mon cœur, et son émoi De ne pouvoir être (ni vous non plus) Intelligent et beau pour rire ainsi Qu’il sied, du choix qui me rend cramoisi Et pour pleurer que parmi tant d’élus À faire, ces messieurs aient entre tous Pris Brunetière, Ô les topinambous1 Paul VERLAINE (1844-1896) in Dédicaces
Table des matières
Résumé xiii
Abstract xv
Préambule xvii
Introduction 1
Partie I L’assimilation de données
1 Introduction 7
1.1 Références . . . 7
1.2 Un exemple simple : les prémices de la météorologie . . . 7
1.3 Un exemple plus théorique . . . 8
2 Présentation du problème 11 2.1 Concepts de base . . . 11
2.1.1 L’analyse . . . 11
2.1.2 L’assimilation de données . . . 11
2.1.3 Analyse de Cressman and Co . . . 12
2.1.4 Approche statistique . . . 13
2.2 Description des vecteurs et espaces . . . 14
2.2.1 Vecteur d’état . . . 14
2.2.2 Variable de contrôle . . . 14
2.2.3 Observations . . . 15
2.2.4 Écart entre les observations et leurs équivalents modèle . . . 15
Table des matières
2.3.1 Représentation de l’incertitude par des fonctions de densité de
proba-bilité . . . 16 2.3.2 Variables d’erreur . . . 16 2.3.3 Covariances d’erreur . . . 17 3 Interpolation statistique 19 3.1 Notations et hypothèses . . . 19 3.2 Le problème de l’estimation . . . 20 3.3 Estimation non-optimisée . . . 20 3.3.1 Définition du gain . . . 20
3.3.2 Erreur d’analyse commise . . . 21
3.4 Best Linear Unbiased Estimation . . . 21
3.5 Propriétés du BLUE . . . 22
3.5.1 Formule de Sherman-Morrison-Woodbury . . . 22
3.5.2 Erreur d’analyse optimale . . . 22
3.5.3 Écart aux observations sans biais . . . 23
3.5.4 Corrélation de l’analyse et de son erreur . . . 24
3.6 Approche variationnelle . . . 24
3.6.1 Équivalence avec le BLUE . . . 24
3.6.2 Hessien . . . 25
3.6.3 Extension des méthodes variationnelles . . . 25
3.7 L’exemple du naufragé . . . 25
3.7.1 Définition des variables . . . 26
3.7.2 Analyse optimale . . . 26
3.7.3 Erreur commise . . . 27
4 Méthodes d’assimilation 29 4.1 Interpolation Optimale - OI . . . 29
4.2 Les filtres de Kalman de rang plein . . . 31
4.2.1 Filtre de Kalman - KF . . . 31
4.2.2 Filtre de Kalman Étendu - EKF . . . 32
4.2.3 Coût de calcul . . . 32
4.2.4 L’exemple du naufragé . . . 33
4.3 Les filtres de Kalman réduits . . . 35
4.3.1 Filtre RRSQRT . . . 35
4.3.2 Filtre SEEK . . . 36
4.3.4 Coût de Calcul et filtres dégradés . . . 37
4.4 Filtre de Kalman d’ensemble - EnKF . . . 39
4.5 Méthodes variationnelles . . . 39
4.5.1 3D-Var . . . 40
4.5.2 4D-Var . . . 44
4.6 Choix d’une méthode d’assimilation . . . 51
5 Modèle de covariance d’erreur 55 5.1 Description des erreurs . . . 55
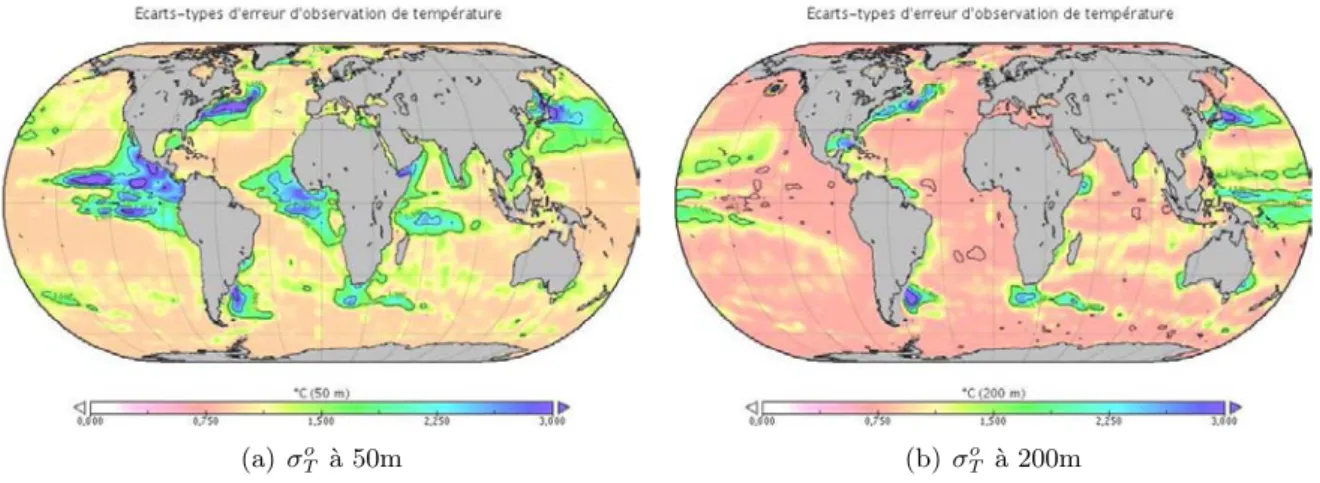
5.1.1 Variances d’erreur d’observation . . . 55
5.1.2 Covariances d’erreur d’observation . . . 55
5.1.3 Variances d’erreur d’ébauche . . . 56
5.1.4 Covariances d’erreur d’ébauche . . . 57
5.2 Estimation des erreurs . . . 59
5.2.1 Méthode basée sur l’innovation . . . 60
5.2.2 Méthode NMC . . . 61
5.2.3 Méthode d’ensemble . . . 63
5.3 Modélisation des erreurs . . . 64
Partie II Description du système OPAVAR 1 Introduction 67 2 Le modèle océanique 69 2.1 Le modèle OPA . . . 69
2.1.1 Hypothèses et équations . . . 70
2.1.2 Les conditions limites . . . 72
2.1.3 Discrétisation . . . 73
2.1.4 Intégration . . . 75
2.2 La configuration ORCA à deux degrés . . . 75
2.2.1 La grille . . . 75
2.2.2 Les forçages . . . 76
Table des matières
3 Les observations 79
3.1 Les observations in situ . . . . 79
3.2 Les observations satellitaires . . . 80
3.3 Les observations assimilées . . . 82
4 La méthode variationnelle OPAVAR 85 4.1 Formulation . . . 85
4.1.1 Le vecteur de contrôle . . . 85
4.1.2 L’opérateur d’observation H . . . . 86
4.1.3 La matrice de covariance d’erreur d’observation R . . . . 86
4.1.4 La matrice de covariance d’erreur d’ébauche B(w) . . . 86
4.1.5 Préconditionnement . . . 87
4.1.6 Mise à jour de l’analyse de manière incrémentale . . . 88
4.2 La matrice de covariance d’erreur d’observation R = D(y) . . . 88
4.2.1 Profils analytiques : D(1)(y) . . . 88
4.2.2 Prise en compte des régions côtières . . . 91
4.2.3 La méthode de Fu et al. : D(2)(y) . . . 91
4.3 L’opérateur de variance d’erreur d’ébauche D(bx) . . . 93
4.3.1 Température . . . 93
4.3.2 Salinité « non-équilibrée » . . . 94
4.3.3 Hauteur de mer « non-équilibrée » . . . 94
4.3.4 Vitesses horizontales « non-équilibrées » . . . 95
4.3.5 Discussion . . . 95
4.4 L’opérateur d’équilibre K(x) . . . 95
4.4.1 L’opérateur linéaire d’équilibre de salinité . . . 97
4.4.2 L’opérateur linéaire de densité . . . 97
4.4.3 L’opérateur linéaire d’équilibre de hauteur de mer . . . 97
4.4.4 L’opérateur linéaire de pression . . . 98
4.4.5 L’opérateur linéaire d’équilibre des vitesses horizontales . . . 98
4.4.6 Exemple . . . 99
4.5 L’opérateur de corrélation F(bx)FT (bx) . . . 101
4.5.1 Introduction . . . 101
4.6 Algorithme . . . 103
1 Introduction 107
2 Théorie 111
2.1 Introduction . . . 111
2.2 Démonstration . . . 111
2.2.1 Évolution, au premier ordre, de l’erreur d’ébauche et d’analyse . . . . 111
2.2.2 Représentation ensembliste de l’erreur d’ébauche et d’analyse . . . 113
2.3 Implications . . . 114
3 Mise en œuvre 117 3.1 Description générale . . . 117
3.2 Perturbation des forçages . . . 118
3.2.1 Perturbation des tensions de vent . . . 118
3.2.2 Perturbation des flux d’eau douce . . . 119
3.2.3 Perturbation de la température de surface océanique . . . 120
3.3 Perturbation des observations . . . 123
3.4 Taille de l’ensemble . . . 124
3.5 Utilisation . . . 125
4 Caractérisation 129 4.1 Variances des perturbations . . . 129
4.2 Impacts des différentes perturbations . . . 131
4.3 Dispersion de l’ensemble . . . 134
Partie IV Estimation d’ensemble des variances d’erreur d’ébauche 1 Introduction 139 2 Modification des variances d’erreur d’observation 143 2.1 Description du problème . . . 143
2.2 Diagnostic des erreurs dans l’espace des observations . . . 146
2.2.1 Théorie . . . 146
2.2.2 Mise en œuvre . . . 148
2.3 Méthode de Fu et al. . . . 148
Table des matières
3 Étude de la sensibilité du système aux variances d’erreur d’ébauche 161
3.1 Étude d’une expérience d’ensemble . . . 161
3.1.1 Présentation des expériences comparées . . . 161
3.1.2 Diagnostics dans l’espace des observations . . . 162
3.1.3 Diagnostics dans l’espace du modèle . . . 174
3.1.4 Résumé des impacts des estimations d’ensemble des variances d’erreur d’ébauche . . . 177
3.2 Paramétrage de l’expérience d’ensemble . . . 178
3.2.1 Sensibilité à la taille de l’ensemble . . . 179
3.2.2 Sensibilité au filtrage des estimations d’ensemble des variances d’er-reur d’ébauche . . . 182
3.2.3 Sensibilité aux perturbations des observations . . . 185
3.2.4 Sensibilité à l’accroissement des variances d’erreur d’ébauche . . . 187
4 Conclusion 193 Partie V Estimation d’ensemble des covariances d’erreur d’ébauche uni- et multivariées 1 Introduction 199 2 Covariances univariées 201 2.1 Introduction . . . 201 2.2 Portées paramétrées . . . 202 2.3 Fonctions de corrélation . . . 203 2.4 Portées . . . 206 2.4.1 Définition . . . 206 2.4.2 Portées de température . . . 209 2.4.3 Portées de salinité . . . 213
2.4.4 Portées de hauteur de mer . . . 216
2.4.5 Portées des vitesses horizontales . . . 217
2.4.6 Anisotropie . . . 220
3 Covariances multivariées 225
3.1 Introduction . . . 225
3.2 Corrélation T-S . . . 226
3.3 Variances expliquées . . . 229
3.3.1 Introduction . . . 229
3.3.2 Variances expliquées de la salinité . . . 230
3.3.3 Variances expliquées de la hauteur de mer . . . 231
3.3.4 Variances expliquées des vitesses horizontales . . . 234
3.4 Conclusion . . . 234
4 Distribution de l’innovation 239 Conclusions et perspectives 245 Partie VI Annexes A Estimation des covariances d’erreur d’observation à l’aide de la méthode de Fu et al. 253 B Description théorique du filtre récursif 257 B.1 Les équations de Langevin . . . 257
B.1.1 Présentation . . . 257
B.1.2 Discrétisation . . . 258
B.2 modèle auto-régressif du second ordre . . . 258
B.3 Les conditions limites . . . 261
B.3.1 Conditions limites pour i = 0 . . . 262
B.3.2 Conditions limites pour i = n + 1 . . . 262
B.3.3 Résumé des trois premières conditions limites . . . 263
C A three-dimensional ensemble variational data assimilation system for the global ocean : Sensitivity to the observation- and background-error variance formulation 265 C.1 Abstract . . . 265
Table des matières
C.3 The assimilation system . . . 267
C.3.1 Ocean model and forcing fields . . . 267
C.3.2 Observations . . . 269
C.3.3 Data assimilation method . . . 269
C.4 Specification of the observation- and background-error variances . . . 273
C.4.1 Observation-error variance matrix : D(y) . . . 273
C.4.2 Background-error variance matrix : D(wb) . . . 274
C.5 Results . . . 277
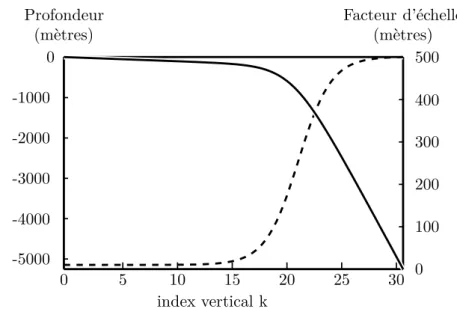
C.5.1 Geographical distribution of σb . . . 278
C.5.2 Vertical profiles of σb and σo . . . 278
C.5.3 Assimilation statistics . . . 280
C.5.4 Specified versus diagnosed σb and σo . . . 285
C.5.5 Temporal variability of the ensemble and assimilation statistics . . . . 288
C.5.6 Comparison with independent data . . . 289
C.6 Summary and conclusions . . . 293
C.7 Acknowledgements . . . 294
C.8 Observation-error covariance estimation using the Fu et al. method . . . 295
C.9 Background-error covariance estimation using an ensemble method . . . 296
C.9.1 First-order evolution of the true background- and analysis-state errors 297 C.9.2 Ensemble representation of background- and analysis-state errors . . 298
Table des figures 301
Liste des tableaux 305
Glossaire 307
Index 311
Résumé
L’objectif de ce travail de thèse est d’estimer la matrice de covariance d’erreur d’ébauche d’un système d’assimilation de données variationnelle océanique à partir d’une méthode d’ensemble. L’assimilation de données est une procédure qui permet de combiner l’information provenant d’un modèle numérique et d’observations (in situ ou satellitaires) pour estimer l’état de l’océan. L’estimation ainsi faite est meilleure que dans le cas où une seule source d’information (le modèle ou les observations) est utilisée. L’approche variationnelle s’appuie sur la formulation aux moindres carrés du problème inverse de l’assimilation de données. La méthode identifie un état de l’océan qui minimise la fonction coût mesurant l’écart entre l’état recherché et une description du système a priori donnée par le modèle (condition initiale appelée ébauche) d’une part et l’écart entre l’état recherché et les observations d’autre part. Au sein de la fonction coût, ces écarts sont respectivement pondérés par l’inverse de leur matrice de covariance d’erreur. Faute d’une bonne connaissance de ces covariances d’erreur, elles sont approximées par des modèles de covariance respectivement liés aux observations, à l’ébauche et éventuellement aux équations du modèle numérique. Le modèle de covariance d’erreur d’ébauche distribue spatialement l’information provenant des observations et la projette sur les autres variables du vecteur d’état.
Dans cette thèse, une méthode d’ensemble est utilisée pour estimer les paramètres du modèle de covariance d’erreur d’ébauche dans un système d’assimilation de données variationnel (3D-Var) appliqué à une configuration globale du modèle de circulation océanique OPA. L’ensemble est obtenu en perturbant les champs de forçage de surface (tension de vents, flux d’eau douce et flux de chaleur) et les observations (profils de température et de salinité in situ) utilisées durant le processus d’assimilation. Ce travail de thèse s’intéresse particulièrement aux possibilités offertes par l’ensemble d’estimer au cours du temps les variances d’erreur d’ébauche de température et de salinité dépendants de l’écoulement.
Deux formulations des variances d’erreur d’ébauche dépendant de l’écoulement ont été étu-diées. La première est une estimation provenant de l’ensemble tandis que la seconde est paramé-trée en fonction du gradient vertical de température et de salinité d’ébauche. L’étude de sensi-bilité de l’analyse à ces deux formulations des variances d’erreur d’ébauche a été effectuée grâce à l’inter-comparaison d’expériences 3D-Var sur la période 1993-2000. Pour ces expériences, les variances d’erreur d’observation varient géographiquement et sont estimées à l’aide d’une com-paraison entre les observations et le modèle effectuée avant l’assimilation. Une autre expérience 3D-Var utilisant les variances d’erreur d’ébauche paramétrées et une formulation plus simple des variances d’erreur d’observation, ainsi qu’une expérience de contrôle (sans assimilation), ont aussi été effectuées et comparées.
Toutes les expériences 3D-Var réduisent significativement la moyenne et l’écart-type de l’in-novation de température et de salinité comparativement à l’expérience de contrôle. L’impact de la formulation des variances d’erreur d’ébauche sur les statistiques d’innovation est, en moyenne globale, similaire au-dessous de 150 mètres de profondeur. Au-dessus, où les tests de consis-tance statistique suggèrent que les estimations d’ensemble des variances d’erreur d’ébauche sont sous-estimées, la formulation des variances d’erreur d’ébauche paramétrées présente des résul-tats légèrement meilleurs. Toutefois, la croissance d’erreur de température et de salinité entre les cycles d’assimilation est nettement réduite à l’aide des estimations d’ensemble des variances d’erreur d’ébauche ce qui laisse supposer que l’état analysé est mieux équilibré. Les anomalies de hauteur de mer dans la région du Gulf Stream et les vitesses zonales dans le Pacifique
tro-pical sont des champs qui ne sont pas directement contraints par les observations et qui sont nettement améliorés en utilisant les estimations d’ensembles des variances d’erreur d’ébauche plutôt que les variances d’erreur d’ébauche paramétrées. Les comparaisons avec l’expérience de contrôle sont moins concluantes et indiquent que lorsque certains aspects des ces variables sont améliorés (anomalie de hauteur de mer et courants dans le centre et l’Est du Pacifique), d’autres sont dégradés (anomalies de hauteur de mer dans le Gulf Stream et courants dans l’Ouest du Pa-cifique). Les possibilités d’améliorations de la méthode d’ensemble et d’une meilleure utilisation de l’information ensembliste sont discutées.
La méthode d’ensemble a aussi été utilisée pour estimer d’autres aspects du modèle de covariance d’erreur d’ébauche. Ce travail a exploité les résultats de la ré-analyse océanique d’un ensemble de neuf membres sur une période de 45 ans produite pour le projet européen ENSEMBLES. La distribution géographique des portées de corrélation tri-dimensionnelle a été estimée à partir de l’ensemble et comparée aux portées prescrites dans le modèle de corrélation quasi-Gaussien du système d’assimilation de données 3D-Var. L’ensemble a aussi été utilisé pour vérifier la validité des relations d’équilibres utilisées dans la formulation multivariée du modèle de covariance d’erreur d’ébauche. Ces diagnostics nous éclairent sur les forces et faiblesses du modèle de covariance d’erreur d’ébauche utilisé et proposent des perspectives de recherche intéressantes. Mots-clés: Assimilation de données, 3D-Var, 4D-Var, ensemble, covariance, modélisation.
Abstract
The goal of this thesis is to estimate the background-error covariance matrix of a vari-ational ocean data assimilation system using an ensemble method. Data assimilation is the procedure by which information from observations (in situ or satellite) and models are com-bined in order to give a more accurate estimate of the ocean state than if either source of information were used alone. The variational approach is based on a least squares formulation of the assimilation problem. The algorithm identifies the state of the ocean that minimises a cost function measuring the statistically weighted square difference between the observational information and their model equivalent. Within the cost function, each piece of information on the system (observations, model equations and an a priori description of the ocean state given by the model, namely, the background state) is weighted by the inverse of their respective error covariance matrix. Since these error covariances are poorly known, they must be approximated using error covariance models. The background error covariance model plays a fundamental role in spatially distributing the observational information and projecting it onto the other fields of the state vector.
In this thesis, an ensemble method is designed and used to estimate parameters of the background-error covariance model in a three-dimensional variational data assimilation (3D-Var) system of a global version of the OPA ocean general circulation model. The ensemble is created by perturbing the surface forcing fields (wind-stress, fresh-water and heat flux) and the observations (temperature and salinity profiles) used in the assimilation process. This thesis work focuses on the use of the ensemble for providing flow-dependent estimates of the background-error standard deviations (σb) for temperature and salinity.
Cycled 3D-Var experiments were performed over the period 1993-2000 to test the sensitivity of the analyses to the ensemble σb formulation and to a simpler flow-dependent formulation of
σb based on an empirical parameterization in terms of the vertical gradients of the background temperature and salinity fields. In both experiments, the observation-error standard deviations (σo) are geographically dependent and estimated from a model-data comparison prior to assim-ilation. An additional 3D-Var experiment that employs the parameterized σb but a simpler σo formulation, and a control experiment involving no data assimilation were also conducted and used for comparison.
All 3D-Var experiments produce a significant reduction in the mean and standard devia-tion of the temperature and salinity innovadevia-tions compared to those of the control experiment. Comparing innovation statistics from the two σb formulations shows that, on the global average, both formulations give similar results below 150 m but the parameterized σb give slightly better results above 150 m where statistical consistency checks suggest that the ensemble σb are under-estimated. The temperature and salinity error growth between cycles, however, is shown to be much reduced with the ensemble σb, suggesting that the analyses produced with the ensemble
σb are in better balance than those produced with the parameterized σb. Sea surface height (SSH) anomalies in the northwest Atlantic and zonal velocities in the equatorial Pacific, which are fields not directly constrained by the observations, are clearly better with the ensemble σb than with the parameterized σb when compared to independent data. Comparisons with the control are less conclusive, and indicate that, while some aspects of those variables are improved (SSH anamalies and currents in the central and eastern Pacific), other aspects are degraded
(SSH anomalies in the northwest Atlantic, currents in the western Pacific). Areas for improving the ensemble method and for making better use of the ensemble information are discussed.
The ensemble method has also been used to estimate other aspects of the background-error covariance model. This work exploited results from the 45-year nine-member ensemble of ocean reanalyses produced for the European ENSEMBLES project. A geographical distribution of three-dimensional correlation length scales were estimated from the ensemble and compared to the empirically-derived length scales prescribed in the (quasi-Gaussian) correlation model of the 3D-Var system. The ensemble was also used to test the validity of some of the balance relationships used in the multivariate formulation of the background-error covariance model. These diagnostic studies highlight both strengths and weaknesses in the current background-error model and open up interesting avenues for future research.
Préambule
Plus le message est probable moins il fournit d’information : les clichés et les lieux communs éclairent moins que les grands poèmes.
Préambule Historique
La recherche scientifique repose sur deux sources d’information et d’étude différentes, les observations d’une part, et les modèles d’autre part. Au cours de l’histoire des Sciences, les ob-servations furent d’abord qualitatives avant de devenir quantitatives. Parallèlement, les modèles descriptifs s’améliorèrent grâce aux techniques mathématiques, et particulièrement à l’analyse numérique.
La charnière du XVIIIe et XIXe siècle vit ainsi apparaître l’assimilation de données. Cette technique vise à estimer l’état d’un système dynamique en utilisant toutes les sources d’informa-tion. Elle appartient au domaine de l’estimation statistique et de la théorie du contrôle apparues plus tard (Gelb, 1974 ; Lions, 1968). Johann Tobias Mayer (1723-1762), astronome allemand, calcula les mouvements de la lune avec une admirable précision, et mérita, par ses Tables de la
Lune, le grand prix décerné par le Bureau des longitudes de Londres (1755). En effet, il évalua les
erreurs dues aux imperfections des réglages des instruments de mesure et eut le premier l’idée de répéter la mesure des angles pour atténuer les erreurs de mesure. À cette époque, de nombreux mathématiciens et astronomes développèrent des méthodes proches de la Méthode des moindres
carrés. Adrien Marie Legendre (1752-1834), professeur de mathématiques à l’école militaire de
Paris, exposa, dans un traité sur les orbites des comètes en 1805, cette méthode d’ajustement dite
des moindres carrés. Elle fut cependant attribuée à Karl Friedrich Gauss (1777-1855) qui publia
en 1809 son travail sur les mouvements des corps célestes contenant la méthode des moindres
carrés et permettant de calculer l’orbite de Cérès. Il affirma, pour sa défense, qu’il utilisait cette
méthode depuis 1795. Cependant, l’astronome, physicien et mathématicien Pierre Simon La-place revendiqua aussi la paternité de cette méthode dans ses travaux sur la stabilité mécanique du système solaire dans lesquels il développa en 1783 une méthode proche de celle des moindres carrés visant à résoudre un système d’équations sous-déterminé.
Les astronomes furent donc les premiers à travailler sur la théorie de l’estimation avant que les mathématiciens ne reprennent la thématique. C’est au XXe siècle que Sir Ronald Aylmer Fisher (1890-1962) apporta une contribution majeure au domaine de l’estimation. Il publia en 1912 (Fisher, 1912) un article sur les fonctions de densité de probabilité en utilisant, sans le citer, l’estimateur du maximum de vraisemblance. Il publia ensuite en 1925 l’ensemble de ses travaux sur l’estimation (Fisher, 1925) qui devint un best-seller de la statistique (14 éditions et traduit en 6 langues). Il faut ensuite attendre les années 40 pour que Norbert Wiener (1894-1964), phi-losophe et mathématicien, en se fondant sur la théorie des processus aléatoires, présente une approche du filtrage optimal adaptée aux problèmes spectraux (Wiener, 1949). Cette technique nommée filtre de Wiener traite les problèmes continus dans le temps à l’aide de fonctions de corrélation et se limite aux processus stationnaires. À la même époque, Andreï Nikolaïevich Kol-mogorov (1903-1987) traite le problème discret dans le temps : ce que les historiens des sciences appellent une double découverte. Durant les années suivantes, le travail de Wiener fut étendu aux cas non-stationnaires. Dans les années 60, Rudolf Emil Kalman (1930- ) unifia d’abord le problème continu et discret dans le temps avant de développer le filtrage optimal récursif (Kal-man, 1960 ; Kalman et Bucy, 1961), plus connu sous le nom de filtre de Kalman. À la différence du filtre de Kalman, le filtre de Wiener n’a pas cette bonne propriété de récursivité. Le filtre de
Kalman est maintenant utilisé dans beaucoup de domaines tels que la détermination d’orbites
satellitales, les systèmes de guidage, le traitement d’images, les sciences de la terre ou l’écono-métrie. Vers la même époque, Yoshi Kazu Sasaki, qui travaillait sur la prévision des trajectoires des ouragans, proposa une approche variationnelle de l’estimation (Sasaki, 1958 ; Sasaki, 1970) qui, sous certaines hypothèses, conduit à des résultats semblables à ceux du filtrage optimal. La formulation tri-dimensionnelle est connue sous le nom de 3D-Var tandis que celle quadri-dimensionnelle est ordinairement nommée 4D-Var.
L’assimilation de données en météorologie. . .
Des sciences de la terre, la météorologie s’empara la première de l’assimilation de don-nées. Gandin développa une analyse objective des champs de précipitations totales dès 1963 (Gandin, 1963). Au cours des dernières décennies, les progrès en météorologie ont été rendus possibles par la conjonction systématique des observations et des apports de la théorie. La mo-tivation et l’enjeu essentiel de ces différentes sources d’informations étaient et sont encore le besoin de prévisions météorologiques numériquement calculables. Très rapidement s’est impo-sée l’idée que les modèles dynamiques utilisés devaient rendre compte de la propagation des informations dans le temps et l’espace. Cette notion de propagation tente de compenser la dis-parité et l’imprécision des observations en permettant de construire une image consistante et quadri-dimensionnelle de l’atmosphère. Convaincus de l’importance cruciale de l’assimilation de données, de nombreux centres de recherche ou de prévision opérationnels tels que Météo-France ou le CEPMMT2(Rabier et al., 2000) participent à des projets internationaux ayant pour objec-tif l’amélioration des prévisions opérationnelles, mais aussi l’étude de l’impact anthropique sur l’évolution du climat et l’amélioration de la connaissance de nombreux phénomènes climatiques régissant ce système. Ceci devient possible par une amélioration, qualitative et quantitative, des sources d’informations, grâce notamment aux nouvelles générations de satellites d’observation (ERS-2, Envisat, . . .), et par une incessante augmentation des capacités de calcul.
. . .puis en océanographie
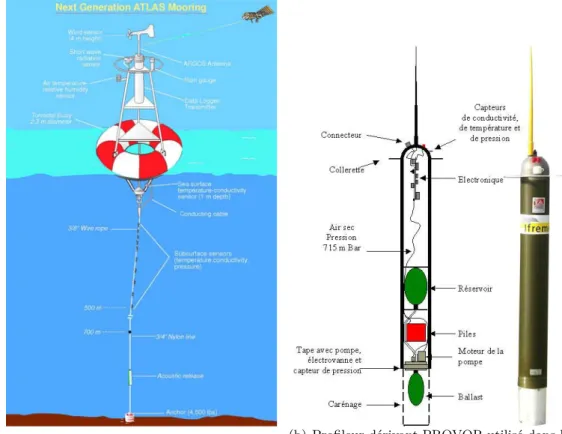
L’essor de l’océanographie physique est plus récent. Cependant l’intérêt de plus en plus mar-qué pour l’étude de la dynamique de l’océan, ainsi que l’amélioration des modèles numériques (Gent et McWilliams, 1990 ; Holloway, 1992 ; Large et al., 1994 ; Griffies et al., 2000) ont motivé l’émergence de l’assimilation de données dans le domaine de la prévision océanique (Koblinsky et Smith, 2001 ; Di Lorenzo et al., 2007). Le déploiement de réseaux d’observation des océans avec des bouées ou des flotteurs (données in situ) et l’utilisation des données satellitaires (al-timétriques, radiométriques,. . .) ont soutenu l’émergence et le développement de l’assimilation de données appliquée à l’océanographie. Ses objectifs sont de satisfaire, d’une part, aux besoins de l’étude de la dynamique océanique en effectuant la meilleure estimation possible de l’état de l’océan au cours du temps. Cette estimation permet d’obtenir un état initial le plus réaliste pos-sible pour la prévision océanique et pour la prévision saisonnière qui utilise des systèmes couplés océan-atmosphère. D’autre part, l’assimilation de données permet d’estimer, voire d’améliorer, les paramètres du modèle numérique d’océan (Smedstad et O’Brien, 1991), les forçages (Stam-mer et al., 2002 ; Stam(Stam-mer et al., 2004 ; Vossepoel et Behringer, 2000) ou les conditions aux frontières (Bennett et McIntosh, 1982 ; Deltel, 2002). La capacité du système à s’ajuster vers les observations permet d’identifier certains biais ou dérives du modèle numérique d’océan (Bennett
et al., 1998, 2000). De la même manière, des écarts trop importants identifiés par l’assimilation
entre les observations et le modèle peuvent mettre en évidence une incohérence dans les obser-vations (Holland, 1989). Enfin, l’assimilation peut aussi être utilisée pour évaluer un système d’observations (Miller, 1990 ; Carton et al., 1996).
Les principaux objectifs
L’assimilation de données passées disponibles sur de longues périodes se nomme ré-analyse. Le projet européen ENACT3avait ainsi pour objectif de réaliser, entre autre, des ré-analyses sur
2Centre Européen pour les Prévisions Météorologiques à Moyen-Terme. 3ENhanced ocean data Assimilation and Climate predicTion.
Préambule
la période 1962-2001. La compréhension de la circulation océanique, de la variabilité du système et des mécanismes qui engendrent les phénomènes physiques majeurs de l’océan (Stammer, 2002) peut être améliorée avec les produits issus de ces ré-analyses.
Comme en météorologie, la connaissance d’un état initial le plus juste possible permet de pro-duire des prévisions les plus fiables. L’assimilation de données a ainsi pour objectif de construire cette condition initiale afin d’améliorer les prévisions océaniques. C’est pourquoi elle est au cœur de projets d’océanographie opérationnelle comme MERCATOR. Les prévisions obtenues permettent de connaître au mieux la dynamique globale des courants et masses d’eau, ainsi que l’équilibre biologique régnant dans l’océan qui en découle. Tous ces produits sont directement utiles dans les domaines de la pêche, du transport maritime, de la protection des espèces ma-rines, de la défense et, plus anecdotiquement, dans celui des courses au large. La qualité des systèmes permet aujourd’hui une analyse de la circulation océanique réelle ainsi que la repré-sentation de la physique méso-échelle globale (Fu et Smith, 1996). Un système d’océanographie opérationnel performant doit ainsi être composé d’un modèle océanique réaliste, d’une méthode d’assimilation efficace et d’observations nombreuses et de qualité.
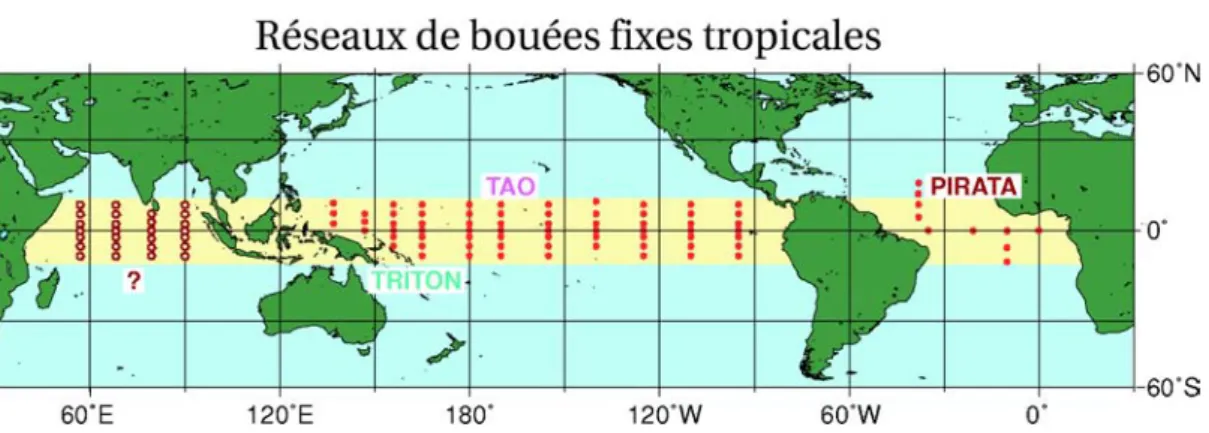
Pour la prévision saisonnière, la connaissance la plus réaliste de l’état de l’océan est pri-mordiale. En effet, la qualité du couplage océan-atmosphère est conditionnée fortement par la composante océanique qui représente la mémoire du système : la capacité de stockage de l’océan est 1200 fois supérieure à celle de l’atmosphère. L’assimilation de données permet de déterminer des conditions initiales suffisamment réalistes à l’interface océan-atmosphère. En supposant que le couplage soit réalisé parfaitement entre un modèle d’océan et un modèle d’atmosphère tout deux parfaits, l’information contenue dans l’état initial de l’océan est préservée et propagée par le modèle d’océan, puis transmise correctement au modèle d’atmosphère. Une des hypothèses fortes des modèles parfaits est d’être non biaisé. Cependant, et malgré ces hypothèses fortes, la capacité des méthodes d’assimilation à améliorer la qualité des conditions initiales océaniques et des prévisions saisonnières n’est plus à démontrer. La mise en évidence d’un impact positif sur l’ensemble du globe est cependant plus compliquée. Ces difficultés sont dues notamment aux techniques de couplage, par exemple l’échange des flux entre les modèles d’océan et d’at-mosphère, et à la qualité des modèles toujours perfectibles. Cependant, pour certaines régions du globe où la dynamique est spécifique, ou dans un contexte d’étude particulier, l’assimilation de données a pu clairement montrer son intérêt. L’exemple de la région Pacifique tropical avec l’assimilation des données TAO4 améliore clairement la prévision des événements ENSO5 (Ji et
al., 1997 ; Segschneider et al., 2000 ; Alves et al., 2004). Ces prévisions saisonnières sont
pro-duites de manière opérationnelle par le NCEP6 (Behringer et al., 1998 ; Ji et al., 1998) et par le CEPMMT (Segschneider et al., 2000 ; Alves et al., 2004 et Balmaseda et al., 2008).
Les contraintes
Le développement des méthodes d’observation et de la modélisation de l’océan ont fait évo-luer, au cours des dernières décennies, les techniques d’assimilation de données du système océanique. D’autre part, le développement de méthodes d’assimilation de plus en plus perfor-mantes dans le domaine de l’atmosphère a profité au domaine océanique. Cependant, quelle que soit la méthode d’assimilation de données choisie, les problèmes sont globalement les mêmes, essentiellement celui de la taille du système, qui comprend généralement plus de 107 degrés de liberté, et qui pose certains soucis de temps de calcul et d’espace mémoire. Aucun progrès
4Tropical Atmosphère Océan. 5El Niño Southern Oscillation.
notable n’aurait pu voir le jour sans la mise à disposition de moyens de calculs importants. Au-jourd’hui, grâce à des super-calculateurs, les centres de prévisions atmosphériques opérationnels utilisent des méthodes d’assimilation performantes. Néanmoins, la puissance de calcul reste le facteur limitant pour le développement de méthodes d’assimilation dans le domaine des sciences de la terre. Les objectifs actuels de la communauté scientifique sont donc les suivants : réduire la taille des systèmes étudiés sans perdre d’information, améliorer la connaissance des paramètres physiques, la statistique des erreurs de mesure, prendre en compte l’erreur modèle sans trop pénaliser la résolution numérique. . .
Introduction
Par des citations on affiche son érudition, on sacrifie son originalité.
Arthur Schopenhauer
Le contexte océanographique
Avec la théorie de l’estimation statistique, l’océanographie dispose d’un outil très puissant pour assimiler de façon optimale (en un sens à préciser) les informations provenant des observa-tions et celles provenant du modèle numérique décrivant la dynamique du système. Cependant l’utilisation de ces outils dans un contexte opérationnel ou de recherche se heurte à un écueil conséquent : la taille importante du système approchant les 107degrés de liberté et sa complexité nécessaire pour représenter les phénomènes physiques des géofluides. Certaines des méthodes les plus avancées ne sont ainsi pas les plus adaptées pour le domaine de l’océanographie. C’est le cas du filtre de Kalman ou du 4D-Var7 qui sont extrêmement coûteux. Des simplifications astucieuses peuvent être appliquées au prix d’hypothèses plus ou moins contraignantes. Des méthodes plus simples, moins coûteuses, toujours très performantes et dérivées des précédentes sont ainsi développées et utilisées (Courtier et al., 1990 ; Evensen, 1994). La spécification des hypothèses et la mesure de leurs impacts et conséquences font partie des axes majeurs du travail de l’assimilateur.
Les hypothèses concernent essentiellement les sources d’informations disponibles sur le sys-tème étudié. En océanographie, comme en météorologie, ces informations proviennent des ob-servations qui sont à la fois imparfaites, peu nombreuses et réparties de manière inhomogène, et du modèle numérique pour lequel les équations de la physique sont simplifiées, paramétrées et discrétisées. Ce modèle numérique est un système d’équations qui propage l’état de l’océan temporellement : c’est le modèle océanique. Il est, par essence même, imparfait et comporte des lacunes plus ou moins importantes dans la représentation des processus océaniques (tur-bulence, non-linéarité, phénomènes de sous-maille. . .). Cependant, il permet de décrire à tout instant l’état de l’océan, y compris à l’instant précédent le début de l’assimilation. Cet état de l’océan particulier est appelé ébauche. Les observations ne permettent, quant à elles, qu’une représentation grossière de l’état de l’océan. Elles sont empreintes d’erreurs instrumentales et de représentativité. Elles ne mesurent pas forcément des variables du modèle. Et elles ont une répartition très inhomogène dans l’espace et dans le temps. Toutes les informations, qu’elles proviennent du modèle ou des observations, doivent être traitées par la méthode d’assimilation en tenant compte de leurs erreurs. A défaut de connaître les erreurs liées aux différentes sources d’informations, il est possible d’en approcher ses statistiques.
Les modèles de covariance d’erreur
Introduction
Ses statistiques sont représentées par des modèles de covariance d’erreur. Plusieurs modèles de covariance d’erreur sont utilisés : le modèle de covariance d’erreur des observations ; le modèle de covariance d’erreur du modèle lié aux erreurs d’approximations et de troncatures dans les équations de la physique océanique ; et le modèle de covariance d’erreur d’ébauche qui représente l’état initial de l’océan, en général obtenu par le modèle numérique. Ces modèles de covariance d’erreur sont essentiels et influent profondément sur la qualité de l’assimilation de données comme le mettent en évidence de nombreuses études (Derber et Bouttier, 1999 ; Gauthier et
al., 1999). La qualité des analyses obtenues par une assimilation de données est directement
liée aux modèles de covariance d’erreur qui projettent les corrections obtenues aux points des observations vers les points de la grille du modèle numérique et des variables observées vers les autres variables du modèle numérique. Les covariances d’erreur d’ébauche se décomposent ainsi en covariances d’erreur univariées propageant spatialement l’information et en covariances d’erreur multivariées propageant l’information entre les différentes variables du modèle numé-rique. L’impact des covariances d’erreur multivariées est particulièrement important quand une seule variable du modèle numérique est assimilée ou que les observations d’une des variables du modèle numérique sont très majoritaires. Ce qui est généralement le cas avec les observations de température in situ dans notre système actuellement.
Les objectifs
Ce travail de thèse propose une amélioration du système d’assimilation variationnelle de données appliqué au modèle d’océan OPA8(Madec et al., 1998), devenu depuis NEMO9, dans sa configuration globale. Ce système est appelé OPAVAR10Le travail se concentre plus précisément sur le modèle de covariance d’erreur d’ébauche décrit comme une séquence d’opérateurs (Derber et Bouttier, 1999) traitant distinctement les covariances d’erreur univariées et multivariées.
Un opérateur intégral (Gaspari et Cohn, 1999) permet de formuler les corrélations spatiales qui sont au sein du modèle de covariance d’erreur univariée. La résolution d’une équation de diffusion généralisée (filtre Laplacien) (Weaver et Courtier, 2001) permet d’évaluer efficacement cet opérateur intégral.
Les covariances d’erreur multivariées sont modélisées par le biais d’un ensemble de contraintes dépendant éventuellement de l’état du système, entre les différentes variables du vecteur d’état (température, salinité, vitesses zonale et méridienne, et hauteur de mer). Ces contraintes sont rassemblées sous le terme d’un opérateur d’équilibre. Cet opérateur peut être appliqué comme une contrainte faible ou forte (Le Dimet et Talagrand, 1986 ; Derber et Bouttier, 1999 ; Lorenc, 2003). Quand les covariances d’erreur entre les variables sont complètement décrites par des relations physiques analytiques ou empiriques prescrites dans l’opérateur d’équilibre, la contrainte est dite
forte. Dans le cas contraire, la contrainte est dite faible.
Les variances d’erreur sont, quant à elles, spécifiées en tous points selon plusieurs méthodes allant d’une prescription globale à une spécification par des fonctions analytiques dépendant de l’état du système.
Cependant, l’estimation des covariances d’erreur d’ébauche est un problème particulièrement difficile car l’état vrai du système n’est pas connu. En l’absence d’échantillons de l’état vrai, les erreurs d’ébauche (entre l’ébauche et l’état vrai) ne sont pas accessibles. Il existe cependant d’autres sources d’informations pertinentes et utiles, mais insuffisantes pour déterminer entière-ment ces erreurs. Différentes méthodes permettent d’obtenir des informations sur ces covariances
8Océan PArallélisé : modèle océanique aux équations primitives. 9Nucleus for European Modelling of the Ocean.
10Un nouveau système, NEMOVAR, est en cours de développement au CERFACS en collaboration avec le
d’erreur. Elles peuvent se scinder en deux grandes familles.
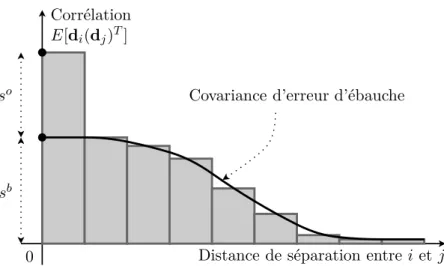
La première utilise les statistiques de l’innovation (l’écart entre les observations et l’état du modèle) afin d’estimer, dans l’espace des observations, les covariances d’erreur d’ébauche et des observations. Inspirée des travaux de Hollingsworth et Lönnberg (1986), l’idée générale est d’effectuer les hypothèses adéquates permettant des séparer les erreurs d’observations des erreurs d’ébauche. La première hypothèse, assez classique, est de supposer les erreurs d’observations indépendantes des erreurs d’ébauche. La seconde hypothèse est un peu plus forte et consiste à supposer que les erreurs d’observations ne sont pas corrélées spatialement. Cette méthode est la seule permettant un diagnostic direct des covariances d’erreur d’ébauche. Malheureusement, les statistiques sont obtenues dans l’espace des observations et seulement pour les régions observées. Elle nécessite donc un réseau d’observations uniforme qui est loin d’exister en océanographie. De plus, les statistiques sont biaisées dans les régions denses en observations du fait de la seconde hypothèse.
La seconde famille englobe toutes les méthodes qui consistent à utiliser des quantités dont les statistiques d’erreur sont, sous certaines hypothèses, équivalentes à celles de l’erreur d’ébauche et qui sont calculées dans l’espace du modèle. Dans cette famille, on distingue particulièrement la méthode NMC (Parrish et Derber, 1992) et la méthode d’ensemble (Evensen, 1994 ; Fisher, 2003).
La méthode NMC fait l’hypothèse que les corrélations spatiales de l’erreur d’ébauche sont équivalentes à celles des différences entre des prévisions de durées différentes valides au même moment. En pratique, une prévision est effectuée du temps t− 2 au temps t + 1 et une autre du temps t au temps t+1. L’état initial de chaque prévision est obtenu par le système d’assimilation de données. La différence entre les deux prévisions au temps t est que la première prévision est déjà issue d’une prévision entre t− 2 et t tandis que la seconde est issue d’un état analysé entre t− 2 et t. La différence entre ces deux prévisions au temps t + 1 est censée représenter
l’erreur d’ébauche. Cette hypothèse est assez juste si le réseau d’observations est très dense et si les covariances d’erreur d’observations et d’ébauche sont pratiquement équivalentes. C’est-à-dire que les observations sont supposées avoir les mêmes structures spatiales d’erreur qualitativement et quantitativement que l’ébauche. Cependant, en océanographie, peu de régions sont denses en observations et les erreurs d’observations sont, en général, moins corrélées spatialement que les erreurs d’ébauche. En conséquence, les covariances d’erreur d’ébauche estimées par la méthode NMC sont généralement surestimées.
La méthode d’ensemble fait, quant à elle, l’hypothèse que les différences entre les membres de l’ensemble ont les mêmes covariances d’erreur que l’ébauche. En effet, les différences entre les membres au cours de la prévision et de l’analyse évoluent exactement comme l’erreur du système. Ainsi, si les perturbations appliquées aux différents membres de l’ensemble représentent bien les covariances d’erreur des champs perturbés, alors les covariances des différences entre les membres de l’ensemble seront directement liées aux covariances d’erreur d’ébauche (à un facteur près). La difficulté de la méthode d’ensemble est donc de réussir à perturber les différents membres selon les covariances d’erreur adaptées. Par exemple, il est nécessaire de perturber les observations selon les covariances d’erreur d’observations qui ne sont pas non plus connues. Il est donc impossible de respecter parfaitement les hypothèses quant à la fabrication des perturbations. Malgré tout, cette méthode permet d’approcher de manière très intéressante les covariances d’erreur d’ébauche. Cette approche a de très nombreuses similarités avec le filtre de Kalman d’ensemble (Evensen, 2007).
L’objectif de ce travail de thèse est de mettre en œuvre une méthode d’ensemble autour du système OPAVAR afin d’obtenir des statistiques permettant de faire évoluer la matrice de covariance d’erreur d’ébauche. L’installation d’une méthode d’ensemble dans un contexte
Introduction
quasi opérationnel est particulièrement contraignante du fait des coûts de calculs importants et de quantités de données mises en œuvre. Un travail important a été effectué permettant une utilisation simple et robuste du système désormais disponible avec les outils opérationnels du CEPMMT. Le système estime à chaque cycle d’assimilation les variances d’erreur d’ébauche à l’aide de l’ensemble et permet ainsi de les faire évoluer. Les covariances d’erreur univariées et multivariées sont aussi obtenues de manière diagnostique. Leur étude permettra d’exhiber les qualités et défauts des opérateurs d’équilibre et de corrélation spatiale. À terme, les estimations d’ensemble des covariances univariées pourront être utilisées pour faire évoluer l’opérateur de corrélation spatiale au cours du temps.
Plan de la thèse
La première partie de ce manuscrit de thèse présente l’assimilation de données dans un cadre général en mettant en évidence son intérêt et les principales méthodes existantes. La seconde partie s’attache à présenter le système utilisé — OPAVAR — composé d’un modèle d’océan — OPA —, d’une méthode d’assimilation variationnelle incrémentale et d’un jeu de données
in-situ. La troisième partie présente l’ensemble développé pour OPAVAR en précisant la
théo-rie soutenant cette méthode, en décrivant de manière détaillée les perturbations utilisées pour construire l’ensemble et en caractérisant cet ensemble dans l’optique de valider l’approche. La quatrième partie étudie les impacts de l’estimation d’ensemble des variances d’erreur d’ébauche. Pour ce faire, une nouvelle formulation des variances d’erreur d’ébauche (Fu et al., 1993) prenant en compte les variations géographiques est testée avant d’être utilisée conjointement avec les es-timations d’ensemble des variances d’erreur d’ébauche. Ces eses-timations sont ensuite étudiées et diverses études de sensibilité aux paramètres de la méthode d’ensemble sont présentées. Fina-lement, la cinquième partie présente et compare les covariances d’erreur d’ébauche univariées et multivariées estimées à l’aide de l’ensemble à celles utilisées actuellement dans OPAVAR et propose des corrections aux opérateurs d’équilibre et de corrélation spatiale.
Première partie
1
Introduction
La connaissance progresse en intégrant en elle l’incertitude, non en l’exorcisant.
Edgar Morin in La Méthode (1977), La Vie de la vie
1.1
Références
Une littérature foisonnante présente l’assimilation de données, en particulier dans les do-maines atmosphériques et océaniques. Ce travail de thèse et en particulier la première partie de ce manuscrit ont été grandement inspirés par de nombreux ouvrages, articles et cours. Citons de manière non exhaustive les livres de Daley (1991), Anderson (1991), Bennett (1993) et Evensen (2007), les supports de cours de Bouttier et Courtier (1999), Hólm (2003), Bocquet (2004) et Sportisse et Quélo (2004), les articles de Le Dimet et Talagrand (1986), Cohn (1997), Courtier (1997), Courtier et al. (1998), Rabier et al. (1998), Behringer et al. (1998) et finalement les manuscrits de thèse de Vidard (2001), Hoteit (2001), Massart (2004) et Ricci (2004).
Par ailleurs, ce travail de thèse s’appuie sur les travaux de Weaver et Courtier (2001), Weaver
et al. (2003), Vialard et al. (2003), Ricci et al. (2005), Weaver et al. (2005) et Davey et al. (2006).
1.2
Un exemple simple : les prémices de la météorologie
La première question que l’on peut se poser est : « À quoi sert l’assimilation de données ? ». Une question bien peu scientifique car ne répondant pas à la question « Comment ? ». Et pour-tant, c’est souvent la première question posée lorsque l’assimilation de données fait irruption dans une discussion. Certes, c’est un sujet peu abordé d’ordinaire, mais que certains chercheurs ou doctorants travaillant dans le domaine rencontrent fréquemment.
Alors, à quoi peut bien servir l’assimilation de données ?
Un exemple à la fois simple et historique est celui de la météorologie. Prenons un exemple concret tel que la prévision de la température à Toulouse. La première méthode consiste à faire régulièrement des mesures et à utiliser cette série de mesures pour prévoir la température. Plu-sieurs possibilités existent comme celle de dire que la température du lendemain sera identique à celle du jour précédent. Ou alors celle supposant que la température du lendemain sera fonction de la tendance des derniers jours. En d’autres termes, la démarche consiste à extrapoler les
Chapitre 1. Introduction
mesures en se fondant sur la régularité de la courbe statistique ou bien sur une base statistique événementielle. Cette méthode était celle utilisée avant l’arrivée des ordinateurs.
La seconde méthode consiste à étudier le système globalement pour comprendre quelles sont les lois qui gouvernent la dynamique météorologique. Armé de ces lois, il est ensuite possible de développer un modèle informatique de prévision météorologique. En lui prescrivant un état initial construit grâce aux mesures effectuées, ce modèle peut alors prévoir la température sur Toulouse. Cependant, la complexité du modèle, la taille du système et les observations permet-tant d’initialiser le modèle sont telles que les prévisions ne sont pas toujours très précises.
La solution parait donc évidente : il faut utiliser le meilleur des deux méthodes. C’est-à-dire combiner au mieux la connaissance théorique du système avec les observations effectuées sur ce système. Dans le cas des prévisions météorologiques, cela consiste à initialiser la dynamique du modèle à l’aide de toutes les observations passées. C’est-à-dire que la dynamique du modèle est contrainte par les observations jusqu’à atteindre l’instant présent où une prévision, à proprement parlé, est lancée.
1.3
Un exemple plus théorique
Une autre façon de penser l’assimilation de données est de la comparer aux méthodes tradi-tionnelles de la recherche scientifique.
En général, face à un système inconnu, la première démarche est d’essayer de comprendre comment il fonctionne. Ceci se traduit par le développement d’un modèle qui va tenter de simu-ler toutes les composantes internes du système. Ce modèle, aussi perfectionné soit-il, nécessite des paramètres d’entrée. Une fois le modèle abouti, il est ensuite comparé à des résultats expé-rimentaux. En supposant que le modèle est adapté, les comparaisons entre les sorties du modèle et les mesures expérimentales permettent d’améliorer les entrées du modèle. Il s’agit donc d’un problème inverse.
Une autre approche, inspirée de l’automatisme, est de considérer le système inconnu comme une boîte noire. En faisant évoluer les paramètres d’entrées du système et en étudiant les varia-tions des mesures expérimentales obtenues en sortie, il est possible de construire des lois appelées généralement des fonctions de transfert. Ces lois ne décrivent pas le fonctionnement interne du système mais lient seulement les entrées aux sorties. De ce fait, si le système est complexe et non-linéaire, il est alors difficile d’obtenir les sorties prévues. Comme dans l’optique de l’auto-matisme, l’objectif est de contrôler les entrées afin d’obtenir les sorties espérées, il suffit de faire une boucle de rétroaction qui compare les sorties obtenues aux sorties désirées en temps réel et de corriger en conséquence les entrées du système. Il s’agit donc encore une fois d’un problème inverse.
L’approche de l’assimilation de données est encore différente. Elle nécessite qu’un modèle paramétrique ait été développé au préalable. Elle ne peut donc intervenir qu’après une étude sur le système inconnu. Ensuite, elle envisage la comparaison des sorties du modèle et des mesures expérimentales sous l’angle probabiliste afin d’estimer les paramètres d’entrée du modèle. Il s’agit donc aussi d’un problème inverse pour lequel les erreurs (c’est-à-dire les incertitudes) sur les sorties du modèle, sur les mesures expérimentales et sur le modèle lui-même doivent être estimées. Cette méthode consiste à obtenir le meilleur du modèle et des mesures expérimentales. Cependant, le meilleur n’est pas toujours d’obtenir des sorties du modèles très proches des mesures expérimentales si cela se fait au détriment de la dynamique du système et des sorties du modèle qui n’ont pas d’équivalent en mesures expérimentales. En effet, aux erreurs de mesures s’ajoutent généralement des erreurs de représentativité dues au caractère discontinu des modèles
1.3. Un exemple plus théorique
numériques et des erreurs liées à la transformation des sorties du modèle afin d’obtenir un équivalent des observations (de la simple interpolation jusqu’à la transformation des variables des sorties du modèle pour obtenir des grandeurs comparables aux mesures expérimentales). La comparaison avec des mesures expérimentales est donc très différente de la comparaison avec un état « vrai ». L’assimilation de données est donc particulièrement adaptée aux systèmes de grande taille pour lesquels les modèles doivent être simplifiés (simplification des lois physiques et discrétisation ne permettant pas de résoudre des processus fins) ou pour les systèmes pour lesquels les observations sont parcellaires et inhomogènes. Elle reste cependant aussi adaptée à des problèmes plus « simples ».
L’assimilation de données est donc définie comme l’ensemble des techniques statistiques qui permettent d’améliorer la connaissance de l’état d’un système à partir de sa connaissance théorique et des observations expérimentales.
L’interpolation statistique est alors une technique permettant de trouver une solution à ce problème. Ces techniques sont souvent mathématiquement assez simples (équivalent à la méthode des moindres carrés), mais techniquement complexes du fait de la taille des systèmes.
2
Présentation du problème
Il est très triste qu’il y aie si peu d’informations inutiles de nos jours.
Oscar Wilde
2.1
Concepts de base
2.1.1 L’analyse
L’analyse est une description fiable de l’état vrai du système à un instant donné : l’état analysé. Elle est déjà utile par elle même en tant que représentation globale et consistante du système étudié. Elle peut aussi servir comme état initial pour une prévision du système à l’aide du modèle ou comme pseudo-observation. Elle peut aussi servir de référence afin de vérifier la qualité des observations.
Pour obtenir l’état analysé, les seules informations objectives sont les mesures des observa-tions effectuées sur l’état vrai. Le système peut parfois être surdéterminé. Dans ce cas, l’analyse se résume à un problème d’interpolation. Il est, en général, sous-déterminé car les observations sont clairsemées et pas toujours liées directement aux variables du modèle. Ce qui n’empêche pas d’avoir des régions où les observations sont très denses et où le système est ainsi sur-déterminé. Afin de bien poser le problème, il est nécessaire de disposer d’une ébauche de l’état du modèle (c’est-à-dire une estimation a priori de l’état du modèle). Des contraintes physiques peuvent aussi permettre de mieux déterminer le système. Cette ébauche peut aussi bien être une clima-tologie, un état quelconque ou état obtenu à partir de précédentes analyses. Dans ce cas, si le système est efficace, l’information est censée s’accumuler dans l’état du système modélisé et se propager entre les variables du modèle.
2.1.2 L’assimilation de données
L’assimilation de données est une technique d’analyse pour laquelle les informations appor-tées par les observations sont accumulées dans l’état du modèle grâce à des contraintes cohé-rentes avec les lois d’évolution temporelle et grâce à certaines propriétés physiques permettant, par exemple, de propager l’information entre les variables.
Les approches de l’assimilation de données peuvent être décrites, basiquement, de deux ma-nières différentes : l’assimilation séquentielle et non-séquentielle. L’approche séquentielle suppose
Chapitre 2. Présentation du problème
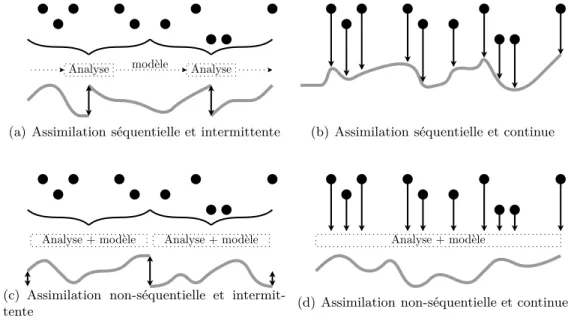
que toutes les observations proviennent du passé de l’analyse (les instants d’observations sont antérieurs à celui de l’analyse). C’est une approche tout à fait appropriée pour les systèmes d’as-similation de données en temps réel. Elles s’appuient sur l’étude statistique des états du système afin de déterminer celui qui, statistiquement, est le plus adapté aux observations. En d’autres termes, ces méthodes permettent d’effectuer une analyse à chaque temps où une observation est disponible afin d’estimer l’état vrai du système à cet instant. L’approche non-séquentielle suppose que des observations provenant du futur par rapport à l’analyse sont aussi utilisables. Ce type de méthode est particulièrement adapté aux ré-analyses. Il est aussi possible de décrire les méthodes d’assimilation de données en distinguant si elles sont intermittentes dans le temps ou continues. Les méthodes dites intermittentes découpent le temps en petites périodes sur les-quelles une analyse est effectuée. Ces méthodes sont très pratiques techniquement parlant. Les méthodes dites continues utilisent de très longues périodes sur lesquelles elles effectuent l’analyse. L’intérêt est d’obtenir un état analysé respectant mieux la dynamique physique et l’évolution temporelle du modèle. Ces différentes méthodes sont résumées succinctement dans la Fig. I.2.1.
Analyse modèle Analyse
(a) Assimilation séquentielle et intermittente (b) Assimilation séquentielle et continue
Analyse + modèle Analyse + modèle
(c) Assimilation non-séquentielle et intermit-tente
Analyse + modèle
(d) Assimilation non-séquentielle et continue
Fig. I.2.1 : Représentation des quatre méthodes caractéristiques pour l’assimilation de données en fonc-tion du temps. Les points noirs représentent les observafonc-tions utilisées par la méthode d’assimilafonc-tion pour obtenir une série d’états analysés, continus ou non, représentée par le trait gris.
2.1.3 Analyse de Cressman and Co
Il est possible de définir une méthode d’analyse telle que l’état analysé soit égal aux ob-servations dans leur voisinage et égal à un état arbitraire partout ailleurs. Par exemple une climatologie ou une précédente prévision. Cette méthode s’apparente au schéma d’analyse de Cressman qui est souvent utilisé pour des systèmes d’assimilation simples.
L’état du modèle est supposé être univarié et représenté par les valeurs aux points de grille. En définissant xb comme une estimation a priori de l’état du modèle provenant d’une climatologie, d’une persistance ou d’une prévision antérieure et yoi comme une série de N observations d’un même paramètre, une simple analyse de Cressman permet d’obtenir un état analysé du modèle