Un modèle de personnalisation des aspects éducatif et
ludique pour les jeux sérieux
Mémoire
Pierre Valentin
Maîtrise en informatique - avec mémoire
Maître ès sciences (M. Sc.)
Un modèle de personnalisation des aspects éducatif et
ludique pour les jeux sérieux
Mémoire
Pierre Valentin
Sous la direction de :
Résumé
L’utilisation des jeux en éducation, appelés jeux sérieux, se développe de plus en plus, mais pour être performants, ces jeux doivent être personnalisés en fonction de la progression des apprentissages tout en conservant leur aspect ludique. Un état de l’art sur le domaine de l’analyse de l’apprentissage a été effectué pour comprendre comment personnaliser de tels jeux. Cependant, les travaux actuels prennent peu en compte les deux aspects pédagogiques et ludiques. L’objectif de cette recherche a été de proposer un modèle de personnalisation du contenu pédagogique et ludique pour les joueurs-apprenants dans les jeux sérieux. Le modèle proposé organise le savoir du domaine à apprendre et indique les télémétries à enregistrer sur l’apprenant pour personnaliser son parcours en fonction de ses performances. Le modèle a été validé par la création d’un prototype qui a permis de vérifier sa fonctionnalité. Ainsi, avec ce modèle, le jeu peut proposer le contenu le plus pertinent pour l’apprenant, lui montrer sa progression et interagir avec lui selon la mécanique de jeux qui lui correspond le mieux. Bien que la personnalisation ludique soit limitée, le modèle est assez flexible pour s’adapter à toute forme de matériel pédagogique et tout domaine d’étude. Des tests impliquant des apprenants permettraient une validation plus avancée.
Abstract
The use of games in education, called serious games is growing, but to be effective, these games must be personalized according to the progress of learning while keeping their playful aspect. A state-of-the-art on the field of learning analytics was conducted to understand how to customize such games. However, the current works do not cover educational and entertainment aspects. The objective of this research project was to propose a model for the personalization of educational and playful content for players-learners in serious games. The proposed model organizes the knowledge of the field to be learned and indicates the telemetry to be recorded on the learner in order to personalize his or her path according to his or her performance. The model was validated by creating a prototype that verified its functionality. Thus, with this model, the game can offer the most relevant content for the learner, show him his or her progress and interact according to the game mechanics that best match him or her. Although playful customization is limited, the model is flexible enough to adapt to any form of educational content and any field of study. Tests involving learners would allow a more advanced validation.
Table des matières
Résumé ... ii
Abstract ... iii
Table des matières ... iv
Liste des figures ... vi
Liste des tableaux ... vii
Remerciements ... ix
Introduction ... 1
Chapitre 1 : L’état de l’art ... 3
1.1 Analyse de l’apprentissage ... 3
1.2 Ludification ... 5
1.3 Techniques basées sur le processus de rétention de l’information ... 6
1.3.1 La répétition espacée ... 6
1.3.2 La courbe d’apprentissage ... 8
1.4 Les tuteurs intelligents ... 9
1.4.1 Modèle du domaine ... 9
1.4.2 Modèle de l’apprenant ... 15
1.4.3 Modèle du tuteur ... 18
1.5 Personnaliser les jeux en fonction des traits psychologiques ... 21
1.5.1 Les profils psychologiques du joueur ... 21
1.5.2 Application des typologies psychologiques avec des jeux ... 23
1.6 La problématique ... 24
Chapitre 2 : Modèle de personnalisation du contenu éducatif et ludique d’un jeu sérieux ... 26
2.1 Objectif de recherche ... 26
2.2 Architecture proposée ... 26
2.3 Les Structures de données ... 29
2.3.1 Les données du domaine ... 29
2.3.2 Les données de l’apprenant ... 32
2.3.3 Les Règles pédagogiques ... 32
2.4 Les agents ... 32
2.4.1 L’agent de télémétrie ... 33
2.4.2 L’agent de personnalisation ... 36
2.4.3 L’agent de visualisation ... 41
Chapitre 3 : Expérimentation, mise en place du modèle ... 45
3.2 Architecture du prototype. ... 46
3.3 Les Structures de données ... 47
3.4 Interaction des agents avec l’apprenant ... 48
Chapitre 4 : Résultats et discussion ... 55
4.1 Résultats ... 55
4.2 Discussion ... 56
Conclusion ... 57
Bibliographie ... 58
Annexe 1 : Questionnaire Hexad ... 64
Liste des figures
Figure 1 : Système de Leitner, traduit de (« Flashcard » 2018) ... 7
Figure 2 : Exemple de Réseaux Bayésien (« Bayesian Network » 2018) ... 16
Figure 3 : Architecture de l'ITS CanadarmTutor tirée de (Dubois et al. 2005) 20 Figure 4 : Représentation du modèle hexad tirée de (Tondello et al. 2016) ... 22
Figure 5 : Architecture d'un jeu sérieux ... 27
Figure 6 : Architecture du modèle ... 28
Figure 7 : Graphe des thèmes du cours ... 30
Figure 8 : Exemple de graphe pour un thème donné ... 31
Figure 9 : Attribution d’une « note » au chapitre en cours d’apprentissage .... 34
Figure 10 : Exemple des télémétries à la suite de l’action de l’agent de télémétrie ... 36
Figure 11 : Exemple de situation de calcul de cote ... 37
Figure 12 : Exemple de chapitre avec des cotes ... 39
Figure 13 : Les chapitres du domaine une fois ordonné par l’agent de personnalisation ... 40
Figure 14 : Exemple de visualisation des données de l’apprenant ... 41
Figure 15 : Capture d’écran d’un jeu de PédagoSoft ... 45
Figure 16 : Schématisation du prototype réalisé ... 46
Figure 17 : Représentation graphique d’une partie de la structure de donnée dans l’outil graphique de Neo4J ... 47
Figure 18 : Enregistrement de l’apprenante Jeanne ... 48
Figure 19 : Questionnaire psychologique ... 49
Figure 20 : Capture de la visualisation ... 49
Figure 21 : Exemple d’exercice d’apprentissage ... 50
Figure 22 : Écran de fin d’exercice ... 50
Figure 23 : Visualisation à la suite de l’exercice ... 51
Figure 24 : Exemple d’interaction avec l’apprenant ... 52
Figure 25 : Visualisation d’un graphe d’apprenant ... 53 Figure 26 : Réponse de l’agent de visualisation à la question de l’apprenant. 53
Liste des tableaux
Tableau 1 : Échelle des cotes ... 35
Tableau 2 : Équivalence entre cote et Score ... 38
Tableau 3 : Relation entre un score de chapitre et une cote ... 39
Remerciements
Je voudrais exprimer ma plus sincère gratitude à Laurence Capus pour la qualité de son encadrement tant sur le plan scientifique qu'humain.
Je remercie Francois Guite et la société PédagoSoft pour leurs aides et participations.
Je remercie l’université de Laval pour l’accueil chaleureux, ainsi que l’ISEP de m’avoir fait confiance pour ce premier double diplôme.
Merci à Christopher De Boisvilliers et l'ensemble des étudiants du laboratoire ERICAE.
Je tiens également à remercier mes amis, qui m'ont toujours supportés, ainsi que les encouragements constants de ma famille qui m’a toujours soutenu pour avancer.
Introduction
Améliorer l’expérience d’apprentissage des apprenants peut se concrétiser de manière différente. Les enseignants peuvent changer leur manière de travailler (« Ludification » 2018), changer de support (Nkambou et al. 2010) ou diminuer la taille des classes pour améliorer les performances des apprenants et augmenter leur engagement. Les efforts récents aussi bien sur les méthodes que le contenu donnent des résultats positifs (« Montessori Education » 2019; « Singapore Math » 2018). Une autre piste consiste à utiliser les outils informatiques pour se rapprocher du tutorat individuel. Des chercheurs et entreprises ont développé des plateformes éducatives qui s’adaptent aux apprenants. Une des approches consiste à utiliser les mécaniques popularisées dans les jeux vidéo au service de l’éducation, on parle de jeux sérieux. Utiliser ces mécaniques transforme l’expérience d’apprentissage. Notre motivation est de continuer à travailler sur ces outils pour encore améliorer l’expérience du joueur-apprenant. Nous avons eu la chance de collaborer avec PédagoSoft, une entreprise qui travaille sur une plateforme de jeux sérieux destinée à l’enseignement du français. Ainsi notre cadre de travail s’inscrit dans l’apprentissage des langues à l’aide des jeux sérieux.
Pour commencer notre travail, nous avons fait un méta analyse de « l’analyse de l’apprentissage ». Ce domaine cherche à comprendre et modéliser les mécaniques d’apprentissage dans tous les contextes où l’éducation a lieu. Les contextes sont variés, allant de la plateforme de mathématique en ligne à la simulation de chirurgie. Cependant, l’état de l’art que nous avons effectué montre que les travaux couvrent peu le spectre des jeux sérieux. Les chercheurs tentent d’optimiser soit la personnalisation pédagogique, soit la personnalisation des mécaniques de jeux. Peu de travaux tentent de faire le lien entre ces deux types de personnalisation (Loh et al. 2015). Dans un jeu sérieux, c’est l’ensemble composé des mécaniques de jeux et de contenus pédagogiques qui donne une expérience d’apprentissage unique. Il nous semble alors intéressant de travailler sur ce point. Notre question de recherche se résume ainsi : est-il possible de personnaliser le jeu et le contenu pédagogique ? Pour répondre à cette problématique, nous nous sommes fixé l’objectif suivant : proposer un modèle pour jeux sérieux de personnalisation du contenu pédagogique et des mécaniques de jeux.
Pour réaliser notre travail, nous avons d’abord fait une revue de littérature pour comprendre les techniques existantes et réutiliser les plus intéressantes pour l’apprentissage des langues dans un jeu sérieux. Ensuite nous avons proposé un modèle qui combinait les techniques vues dans l’état de l’art pour tenir compte du contexte joueur-apprenant. Pour valider notre modèle au vue de notre objectif de recherche, nous avons créé un prototype avec le contenu prêté par PédagoSoft.
Nos résultats sont positifs, le prototype a pu être implémenté et il réalise son objectif de départ. En effet, il enregistre les télémétries (temps de réaction, ratio succès/échec) de l’apprenant et adapte le jeu à sa
progression et à ses préférences de joueur. Notre modèle propose une manière de structurer le domaine pédagogique, puis des heuristiques de personnalisation vont automatiquement personnaliser l’apprentissage en fonction des télémétries mesurées. Notre modèle peut être réutilisé sur les jeux sérieux de tout domaine car nous ne l’avons pas optimisé pour l’apprentissage des langues uniquement. Malgré notre travail sur la personnalisation des mécaniques de jeux, nous pensons que les futurs travaux devraient s’intéresser encore plus à la personnalisation des mécaniques de jeux. Notre modèle permet de savoir comment interagir avec l’apprenant, mais ne donne pas d’indice si un type de jeu plutôt qu’un autre est adapté (par exemple: un casse brique ou un jeu de courses).
Dans le chapitre 1, nous présentons l’état de l’art et définissons la problématique sur laquelle nous avons travaillé. Le chapitre 2 détaille le modèle qui répond à nos objectifs de recherche. Puis le chapitre 3 décrit la mise en pratique du modèle avec un prototype. Nous présentons et discutons nos résultats dans le chapitre 4. Une conclusion termine ce mémoire.
Chapitre 1 : L’état de l’art
Notre motivation dans ce mémoire est d’améliorer l’expérience du joueur apprenant. Pour que notre travail s’imbrique dans les travaux existants, nous avons réalisé un état de l’art qui permettra aux lecteurs de comprendre les concepts et solutions déjà apportés par les chercheurs du domaine. Avec ces éléments, nous avons pu mettre en lumière quels sont, parmi les travaux cités, les plus intéressants aux yeux de notre motivation et contexte.
Cet état de l’art porte sur les techniques d’analyse de l’apprentissage. Chatti et al. (2012) proposent une revue de littérature qui introduit bien le sujet de ces techniques et en présentent les branches les plus importantes. Les chercheurs définissent le concept et les contextes dans lesquels cela s’applique. Après avoir défini l’analyse de l’apprentissage, nous introduisons la notion de « ludification », afin de souligner les enjeux de ce contexte particulier d’éducation.
Ensuite, nous présentons trois ensembles de techniques utilisées pour l’analyse de l’apprentissage et qui nous semblent les plus pertinentes pour répondre aux défis de notre travail de recherche. Le premier ensemble rassemble des techniques qui sont utilisées dans un environnement ludique d’apprentissage des langues et qui s’appuient sur la manière dont l’apprenant retient les notions éducatives au cours du temps. Ces techniques se limitent à personnaliser le contenu pédagogique et les environnements d’apprentissage intègrent la ludification mais ne sont pas vraiment des jeux à part entière.
Le deuxième ensemble porte sur les tuteurs intelligents, soit des systèmes complets de tutorat personnalisé qui représentent une partie conséquente de l’analyse de l’apprentissage (Chatti et al. 2012). Ils ont été autant utilisés pour l’apprentissage des langues que pour d’autres contextes et apportent des éclaircissements sur la manière d’analyser l’apprentissage.
Enfin, dans le troisième ensemble, nous verrons comment les travaux sur la psychologie peuvent permettre de personnaliser l’expérience de jeu selon le profil de l’apprenant. Ses travaux sont importants car ils proposent des solutions pour la personnalisation des aspects ludiques.
Pour compléter ce chapitre, nous présentons la problématique que nous nous sommes proposé de résoudre dans ce travail de recherche.
1.1 Analyse de l’apprentissage
L’analyse de l’apprentissage (learning analytics) englobe tous les modèles qui visent à utiliser les données (mesurées ou déduites) des apprenants pour améliorer ou personaliser tous les systèmes compris dans un contexte d’apprentissage. Par exemple, nous utilisons le terme d’apprenant et non d’étudiant pour aussi inclure
les systèmes éducatifs en dehors des milieux scolaires classiques (Universitaire, Elémentaire etc.). L’analyse de l’apprentissage est définie de manière générale comme : la mesure, collection, l’analyse et la présentation des données des apprenants et leur contexte dans l’objectif d’optimiser l’apprentissage et l’environnement d’apprentissage (« Stanford Learning Analytics Summer Institute | Learning and Knowledge Analytics » 2011). Chatti et al. (2012) listent les techniques utilisées pour l’analyse de l’apprentissage :
• Analyse Académique (Academic Analytics) :
Ce terme a été utilisé pour la première fois dans Goldstein et Katz (2005). Cette catégorie d’analyse de l’apprentissage regroupe les applications d’intelligence d’affaires aux données des universités pour prévenir les échecs des étudiants (dans les MOOCS par exemple).
• Forage de données pour l’éducation (Educational data mining) :
Romero et al. (2010) regroupent toutes les techniques de forage de données pour aider tous les acteurs du système éducatif.
• L’apprentissage adaptatif (Personalized adaptative learning) :
L’adaptativité est la capacité à personnaliser le contenu pédagogique selon des règles prédéfinies. On retrouve cette fonctionnalité principalement dans les systèmes de tuteurs intelligents.
Après avoir présenté ces grands concepts, Chatti et al. (2012) proposent une méthode de réflexion pour mener à bien un projet d’analyse d’apprentissage. Ils identifient quatre questions qui peuvent se poser pour chaque projet :
• Quelles données mesurons-nous ?
Les données peuvent être les télémétries du logiciel ou tirées de plusieurs médias comme dans les systèmes hypermédia (« Hypermédia » 2019). Les télémétries correspondent à la liste des actions horodatées menées par l’utilisateur, à la manière du journal d’un système Linux.
• Qui est l’acteur visé pour l’analyse des données ?
Un système vise souvent à améliorer l’expérience de l’apprenant mais certaines approches visent aussi d’autres acteurs. Par exemple des enseignants ou des institutions peuvent utiliser le système pour obtenir des informations sur leur groupe d’apprenants. Ils peuvent adapter leur matériel pédagogique et prévenir les apprenants qui sont en échec (Campbell et al. 2007).
• Quel est l’objectif de la mesure des données ?
Les objectifs sont très divers dans la littérature. Cela va de la visualisation de données jusqu’au système de recommandation pour personnaliser l’expérience d’apprentissage pour l’apprenant. • Comment le système mesure et traite les données ?
Souvent les chercheurs se reposent sur les méthodes de forage de données massives (Han et al. 2011) comme utilisée en intelligence d’affaires (Business Intelligence ou BI). Les techniques BI sont notamment utilisées pour segmenter où trouver des classes de client ou de fournisseur. Utiliser ces mêmes techniques sont utiles dans le contexte éducatif ou on souhaite avoir des informations sur des groupes d’apprenant.
Tous les points précédents sont très généraux mais s’appliquent à tous les projets liés à l’éducation dans tous ces contextes. Voyons maintenant les contextes de ludification.
1.2 Ludification
Le lien entre joueur et apprenant n’est en effet pas présent dans la revue de Chatti et al (2012). En effet dans les jeux sérieux, deux mécaniques ne font qu’une : la mécanique pédagogique et la mécanique ludique. Dans le livre de Loh et al. (2015), les chercheurs s’intéressent tout particulièrement aux jeux sérieux. Ils définissent le jeu sérieux comme : « Un jeu dont l’objectif premier lors de sa conception est moins le divertissement mais plutôt l’optimisation de l’apprentissage du contenu visé ». L’auteur donne cette définition pour le séparer de la ludification.
La ludification selon Zichermann et Cunningham (2011) est l’application de mécaniques de jeux dans un système qui n’est pas un jeu. Par exemple, une application de sport peut utiliser des médailles et un système de scores pour motiver ses utilisateurs comme dans un jeu. Cependant dans ce cas, la ludification n’est qu’un outil pour augmenter la rétention des utilisateurs et non celle de proposer une alternative par le jeu. La distinction doit être faite car la réflexion est différente et ne se pose pas dans le même contexte. Pour illustrer ce point, Loh et al. (2015) donnent des exemples de problématique particulière aux jeux. Par exemple, les jeux se déroulent en temps réel, un bon jeu sérieux devrait donc réagir en même temps que le joueur joue et pas seulement en fin de partie de manière asynchrone. De même, un jeu génère des télémétries différentes d’un logiciel classique. Le jeu peut mesurer toutes les interactions du joueur avec le jeu mais il reste encore à trouver des modèles qui utilisent pleinement toutes les traces du joueur. Malgré les points soulevés par Loh et al. (2015), la plupart des techniques d’analyse de l’apprentissage peuvent s’appliquer sur un jeu sérieux. Cependant ces techniques se concentrent souvent sur la partie « éducative » du logiciel, en laissant de côté l’aspect ludique.
1.3 Techniques basées sur le processus de rétention de
l’information
Pour personnaliser l’expérience d’apprentissage, il faut que les contenus suivent au plus près la progression de l’élève. Si l’apprenant comprend et retient une règle grammaticale rapidement, nous pouvons raccourcir son agenda de révision. Ce type de comportement n’est possible que dans un type d’enseignement un à un. L’enseignant dans une classe ne peut adapter le rythme d’apprentissage de toute la classe au détriment des élèves aux besoins particuliers. En plus de la question pédagogique, il y a une question d’engagement de l’élève. Si le rythme d’enseignement ne lui correspond pas, l’élève risque de s’ennuyer en classe et son engagement envers le contenu va diminuer. Pour remédier ce problème des techniques pédagogiques ont été créées et automatisées par ordinateur.
Dans cette section, nous allons présenter les approches simples de personnalisation du rythme d’apprentissage. Notamment la répétition espacée et la courbe d’apprentissage. Enfin nous allons montrer comment elles ont été perfectionnées avec les ordinateurs et le traitement de données massives.
1.3.1 La répétition espacée
La répétition espacée est un concept éducatif qui tente d’optimiser le temps passé à apprendre (« Répétition espacée » 2018). Le premier constat a été réalisé par Ebbinghaus (1885). Le chercheur a comparé deux méthodes de travail. Son objectif était d’apprendre une liste de syllabes construites au hasard. Dans un premier temps, il apprend la suite de 12 mots en une journée complète de travail. Ensuite dans une deuxième tentative, il remarque qu’il peut obtenir le même résultat avec deux fois moins d’efforts. Pour cela, il a réparti son effort sur trois jours. Spitzer (1939) montre que la méthode est effective avec une population de 3600 étudiants. C’est dans les années 1970 que la méthode est utilisée de manière commerciale et validée dans le cas de l’apprentissage des langues (Atkinson 1972). Cette méthode est le système Leitner (« Répétition espacée » 2018). Il est l’amélioration du système de « flash-cards » tel qu’illustré figure 1. Les « flash-cards » est une méthode où l’apprenant tente de mémoriser des concepts écrits sur des cartes. La carte comporte la question sur une face et la réponse sur l’autre. L’apprenant tente de répondre seul à ces questions. S’il réussit la question au temps t, il met la carte dans une section qu’il révisera à un temps t+ 1. À chaque succès, l’intervalle de temps augmente. Si l’apprenant échoue à se souvenir de la réponse, la carte passe dans la section précédente pour être revue plus tôt. Avec cette méthode de travail, l’étudiant personnalise seul son apprentissage.
Figure 1 : Système de Leitner, traduit de (« Flashcard » 2018)
Cependant cette approche fonctionne par paliers. Nous pouvons peut-être être plus précis dans la répartition dans le temps des cartes ou notions. Settles et Meeder (2016) ont amélioré cette méthode avec le jeu de données des apprenants du système Duolingo. Duolingo est un programme qui vise à enseigner les langues étrangères avec une approche ludique (« Learn a Language for Free with Duolinguo » 2018). Puisque le système est utilisé par des centaines de milliers d’utilisateurs, les chercheurs ont pu réaliser un modèle d’apprentissage automatique pour personnaliser le système de répétition espacée en fonction du vocabulaire enseigné et des performances des utilisateurs. Les chercheurs ont pour objectif de modéliser la « demi-vie » des mots enseignés dans l’application. La demi-vie correspond au moment t où l’apprenant a une chance sur deux d’oublier le mot. Il faut remémorer les mots avant cet instant t pour poursuivre l’apprentissage et éviter l’oubli. Les chercheurs ont modélisé la probabilité de se souvenir du mot avec la formule suivante :
(1)
• p est la probabilité que l’apprenant se souvienne du mot.
• Δ représente le temps qui s’est écoulé depuis la dernière interaction avec le mot. • h représente la demi-vie du mot en cours d’apprentissage.
Ainsi avec cette formule, p = 0.5 si Δ = h, c’est-à-dire que la dernière interaction est assez éloignée pour que l’apprenant n’est qu’une chance sur deux de se souvenir du mot. Pour déterminer la demi-vie de chaque mot, les chercheurs ont réalisé une descente de gradient. Les chercheurs ont sélectionné deux « éléments » : les interactions et le type du mot. Par exemple, pour chaque mot, ils prennent en compte le nombre d’interactions, les succès ou échecs. Enfin, le type de mot correspond au lexème, c’est-à-dire au rôle du mot dans la phrase. Avec cet élément, les chercheurs pensent capturer la difficulté d’apprendre le mot. En réalisant la descente de gradient, les chercheurs obtiennent les poids associés à chaque élément dans le calcul de la demi-vie. Les
résultats donnés dans l’article montrent de meilleures prédictions par rapport au système de « flash-cards » existant. Une fois déployé, le système de demi-vie a augmenté la proportion des apprenants hebdomadaires sur Duolingo (Settles et Meeder 2016). Cependant l’utilisation du lexème dans les éléments a entrainé des surapprentissages, les utilisateurs l’ont remonté aux concepteurs de l’application. Utiliser des caractéristiques plus fines comme des vecteurs de mots (« Word Embedding » 2018) pourrait être une solution. Les vecteurs de mots permettent de capturer plus d’information sur la nature du mot en plus de son lexème (Lai et al. 2016). Le modèle de demi-vie est une première approche à la problématique de courbe d’apprentissage.
1.3.2 La courbe d’apprentissage
La répétition espacée peut être un des éléments de la courbe d’apprentissage. Ebbinghaus (1913), en même temps qu’il étudie la répétion espacée, formalise la courbe d’apprentissage. Dans cette section, nous allons présenter un exemple d’utilisation des courbes d’apprentissage sur le même jeu de données de Duolingo. La courbe d’apprentissage est la fonction qui représente l’évolution de la probabilité que l’apprenant fasse une erreur en fonction du temps (« Learning Curve » 2018). Dans Streeter (2015), l’auteur modélise les courbes d’apprentissage des apprenants et les catégorise par profil (clustering). Avant de modéliser les courbes d’apprentissage, Streeter (2015) montre que les systèmes de tuteurs intelligents doivent faire des assomptions sur la manière dont les apprenants apprennent avec le système. Par conséquent, le système doit a priori estimer que tous les apprenants évoluent de la même manière. Le modèle proposé par Streeter (2015) vise à améliorer le système de trace d’apprentissage (knowledge tracing) utilisé dans les tuteurs intelligents. Dans le système de trace d’apprentissage, on applique le théorème de Bayes pour déterminer si l’apprenant a maîtrisé un concept éducatif. Streeter (2015) montre que dans les tuteurs intelligents « classiques », tel que décrit dans (Pavlik et Anderson 2008) et (Xu et Mostow 2012), les probabilités de rétention, d’oubli, ou de glissement (une erreur même si l’étudiant maitrise le concept) sont identiques pour chaque exercice du domaine d’apprentissage. Comme pour le travail sur la répétition espacée, Streeter a utilisé les données enregistrées sur les utilisateurs de Duolingo pour déterminer les courbes d’apprentissage de chaque mot pour chaque étudiant. Pour déterminer les courbes d’apprentissage, Streeter regroupe les échecs de l’apprenant dans un vecteur binaire (échecs ou succès), ensuite applique le théorème de Bayes pour déterminer la distribution probabiliste (échec, succès, glissement) exacte des apprenants pour chaque exercice du logiciel. Avec l’ensemble des courbes d’apprentissage, trois actions peuvent être réalisées :
1. personnaliser les courbes d’apprentissage a priori pour chaque exercice ; 2. étudier les groupes d’apprenants qui ont la même courbe d’apprentissage ;
En conclusion de son modèle, Streeter (2015) met en avant des groupes d’apprenants qui échouent les tests oraux de l’application. Après investigation, on a constaté que l’application ne prenait pas en compte les moments où les apprenants ne peuvent pas parler et utiliser leur micro.
Pour conclure, l’analyse de l’apprentissage permet d’adapter le rythme d’apprentissage pour chaque apprenant. De plus, après avoir personnalisé le contenu, de nouveaux comportements peuvent être détectés comme le montre le travail de Streeter (2015).
1.4 Les tuteurs intelligents
Les tuteurs intelligents ou ITS (Intelligent Tutoring System) en anglais font partie de l’écosystème de la recherche en « éducation assistée par ordinateur » (EAD). La définition d’ITS selon Psotka et al. (1988) est un système qui vise à donner un retour et des indications personnalisées à l’apprenant en fonction de ses performances. Le système se comporte comme un tuteur, sans intervention humaine. C’est pourquoi ces logiciels sont nommés tuteur intelligent.
Nous présentons les systèmes ITS même s’ils ne font pas partie des jeux sérieux puisque certains de leurs aspects peuvent nous intéresser lors de la création d’un jeu sérieux. En effet les ITS sont conçus pour s’adapter à leur utilisateur. Ainsi ils personnalisent leur fonction tuteur face à chaque apprenant, cette fonctionnalité est une forme de personnalisation.
Chaque tuteur intelligent est composé de trois systèmes : un modèle apprenant, un modèle tuteur et enfin un modèle du domaine. Ces trois modèles communiquent entre eux mais sont indépendants. Leur étude permet donc d’extraire les techniques et architectures qui peuvent être ensuite réutilisées.
Ainsi dans un premier temps, nous verrons comment sont construits les modèles du domaine et de l’apprenant. Leurs constructions s’appuient sur des techniques d’ingénierie des connaissances classiques. Enfin nous verrons en quoi consiste le modèle tuteur et donnerons un exemple d’architecture simple.
1.4.1 Modèle du domaine
Dans cette section, nous allons étudier la modélisation du domaine, la première brique du tuteur intelligent. Dans un ITS, la modélisation du domaine représente le savoir que possède un expert ou un enseignant sur un sujet. La modélisation du domaine consiste en une structure de données associée à un agent. L’agent ou algorithme en parcourant cette structure de données peut prendre des décisions de manière autonome sur le sujet dont il est expert. Par exemple, l’agent peut inférer de nouvelles règles et adapter la réaction du tuteur à toutes les solutions proposées par les apprenants. Les chercheurs en intelligence artificielle et en sciences de l’éducation ont plusieurs approches pour essayer de construire le modèle du domaine. Nous allons dans un premier temps
revenir sur les objectifs auxquels répond le modèle du domaine puis enfin quels sont les différents modèles utilisés, enfin nous discuterons les techniques appliquées.
1.4.1.1 Types de modèles
La tâche d’un professeur ou d’un tuteur peut se résumer par : aider l’apprenant au meilleur moment en apportant les meilleurs conseils. Pour apporter le meilleur conseil, le tuteur doit reconnaitre un mauvais raisonnement ou une erreur commise par l’étudiant. La problématique du tuteur consiste à : détecter les mauvaises et les bonnes réponses de l’élève et réagir en conséquence. On distingue alors deux objectifs : connaitre le domaine à enseigner et connaitre les bonnes actions pédagogiques à prendre. Pour répondre à cet objectif les chercheurs ont utilisé le travail de l’ingénierie des connaissances comme le montrent les premiers tuteurs intelligents avec EMYCIN (Clancey 1985). Les chercheurs ont développé un ITS en ajoutant des fonctions pédagogiques au système expert MYCIN. Le système expert à base de règles est ainsi devenu un tuteur intelligent à base de règles. Puisque le module expert est la base de l’analyse pédagogique (Corbett et Bhatnagar 1997), il est important de bien le choisir. Dans l’ingénierie des connaissances, les méthodologies et représentations utilisées varient, il en est de même dans les ITS avec leurs avantages et inconvénients.
Le cœur de la modélisation du domaine repose sur sa structure de données et son moteur d’inférence. Le moteur d’inférence est la logique utilisée pour prendre des décisions (inférer) à l’aide du savoir inscrit dans le module expert. Par exemple, un tuteur en mathématique va résoudre une équation polynomiale en utilisant les règles mathématiques inscrites dans sa représentation du domaine. En fonction du type de représentation, on distingue trois types de modèles dans les ITS (Nkambou 2010):
- les modèles « boîte noire » :
Les modèles en boîte noire ne sont pas explicites. Ils ne présentent que le résultat final. Le modèle n’est pas capable de donner une trace intelligible de sa déduction (Nwana 1990).
- les modèles « boîte transparente » (glass box) :
Les modèles en boîte transparente se rapprochent plus de l’expertise humaine. En effet, dans ces systèmes chaque étape du raisonnement de la machine est vérifiable. Par exemple le système GUIDON (Clancey 1982) est un tuteur intelligent pour les diagnostics médicaux. Ce système fut construit autour du système populaire MYCIN. Le système expert MYCIN est construit à l’aide d’un ensemble de règles probabilistes « SI ALORS ». Ces règles représentent le même raisonnement qu’un docteur pourrait utiliser pour diagnostiquer un patient. Ainsi le système GUIDON compare la suite des actions de l’apprenant avec celles présentes dans MYCIN. Si les deux diffèrent, le système va critiquer ou conseiller l’étudiant pour lui indiquer les « bonnes
règles ». L’étudiant peut demander à voir l’enchainement des règles pour obtenir le raisonnement de la machine. Les règles étant explicites, le modèle est dit transparent.
- les modèles « cognitifs » :
Enfin, il existe des modèles dits cognitifs qui tentent d’égaler à la fois le formalisme et la logique d’inférence sur celui des humains. Selon Corbett et Bhatnagar (1997), si le savoir est au maximum représenté comme un humain, le tuteur intelligent pourra réagir comme un étudiant qui résoudra les exercices. Nkambou (2010) donne l’exemple le plus populaire : ACT-R, Adaptative Control of Thought (Hope [2012] 2018). L’outil ACT-R permet aux enseignants et ingénieurs de créer des modules experts à base de règles. Cependant, les règles capturent aussi la problématique pédagogique. Les règles sont écrites pour couvrir toute la pensée de l’apprenant, c’est-à-dire ses réussites mais aussi ses échecs possibles. Ainsi vient l’adjectif cognitif qui vise à reproduire ou comprendre la pensée humaine. Cette approche tente d’aller plus loin que de seulement modéliser le domaine. Les trois types de modèles experts définis précédemment englobent la totalité des implémentations dans les ITS. Nous allons maintenant revenir en détail sur deux des implémentations les plus courantes dans les tuteurs intelligents : les modèles à base de règles et ceux à raisonnement avec contraintes. Pour chacun de ces exemples, nous allons donner un aperçu de leur implémentation au sein de l’ITS, le moteur d’inférence et des exemples d’implémentation.
1.4.1.2 Techniques d’implémentation les plus courantes
Dans Aleven (2010), l’auteur décrit en détail l’usage de la méthode à base de règles dans le cas des tuteurs cognitifs. Comme nous l’avons décrit précédemment, le terme cognitif correspond à la volonté de reproduire la méthode de travail et de réflexion de l’humain. L’auteur y inclut deux approches, celle à base de règles et celle à base de contraintes.
Approche à base de règles
L’approche à base de règles est très populaire car beaucoup d’outils libres et gratuits de création comme CTAT (Cognitive Tutor Authoring Tools. 2018) sont disponibles sur internet. Par exemple, 500000 étudiants américains l’utilisent tous les jours pour apprendre les mathématiques (« Carnegie Learning Math Curriculum & Software » 2018).
En utilisant un exemple simple, on peut comprendre comment les systèmes à base de règles peuvent inférer au bon moment la bonne donnée. L’exemple populaire pour décrire les systèmes à base de règles est un tuteur en mathématique (Aleven 2010). Notre tuteur n’a qu’une seule tâche à enseigner : additionner deux fractions.
Dans un premier temps, nous devons découper le problème en tâches plus simples. Pour additionner deux fractions, il y a trois sous-objectifs :
- convertir les fractions pour qu’elles aient le même dénominateur ; - additionner les fractions ;
- si nécessaire, réduire la fraction au plus petit dénominateur.
Pour réussir une addition de fractions, l’étudiant doit suivre ces trois sous-objectifs dans l’ordre. Cependant au sein de ces sous-objectifs, l’apprenant peut avancer tel qu’il le souhaite. Pour cela, les règles doivent être rédigées et assemblées de manière flexible. Dans un premier temps, voyons comment s’exécute une règle. Pour cela le système enregistre l’état du tuteur dans « la mémoire de travail » (Aleven 2010). Ensuite c’est dans la mémoire que les règles vont s’appliquer.
Voici en exemple la première règle en pseudo code de notre tuteur en mathématique extrait de (Aleven 2010) :
DETERMINER le PDC (Plus petit dénominateur commun)
SI
Il n’y a pas de sous-objectif
ET D1 est le dénominateur de la première fraction ET D2 est le dénominateur de la deuxième fraction
ALORS
Initialiser la variable PDC comme le plus petit dénominateur commun de D1 et D2
Ajouter le sous-objectif : Convertir les fractions pour PDC soit le dénominateur
Ajouter le sous-objectif : Additionner les deux fraction convertis
La première règle du tuteur de mathématique s’exécute dès le départ. En effet, il n’y a pas encore de sous-objectif. Cette règle réalise trois actions. En premier lieu, elle lit la mémoire de travail pour trouver les deux dénominateurs. La mémoire de travail contient tous les éléments courants du problème avec lesquels
l’apprenant peut interagir. Après avoir associé l’état de la mémoire avec cette règle, elle s’exécute. Ensuite, la règle réalise les deux dernières tâches. Elle modifie la mémoire de travail en initialisant la variable PDC et ajoute deux sous-objectifs. La mémoire de travail est la partie cognitive du système, elle représente ce que l’étudiant devrait schématiser dans son esprit. L’étudiant identifie les dénominateurs et va tenter de les convertir. Ainsi la règle capture le comportement idéal de l’apprenant. Cependant la règle ne capture pas les mauvaises stratégies. Pour compléter le domaine, les concepteurs ajoutent des « règles erronées » qui permettent au tuteur de détecter les erreurs. Nous avons vu comment une règle s’exécute mais le tuteur doit enchaîner les règles pour pouvoir mener à bien son objectif. Pour pouvoir comprendre le raisonnement de l’étudiant, le tuteur va tenter de « chainer » un maximum de règles qui vérifient l’historique de la mémoire de travail. Le chainage des règles se comporte comme un graphe. Le tuteur va explorer en profondeur le graphe pour trouver le raisonnement le plus long qui vérifie l’état de la mémoire de travail. Si la dernière feuille du graphe est une règle erronée alors le tuteur pourra intervenir et présenter des conseils ou un rappel de la règle à l’étudiant.
Enfin, c’est en ajoutant les règles correctes et erronées d’autres exercices qu’un auteur crée un tuteur intelligent. Malgré la présence d’outils reconnus (Cognitive Tutor Authoring Tools. 2018; « Jess, the Rule Engine for the Java Platform » s. d.) pour aider à la construction d’ITS à base de règles, Aleven (2010) indique qu’il faut 200 heures de travail à des experts du domaine pour produire une heure de contenu pour l’ITS. Une solution a été trouvée pour répondre à ce problème de temps de rédaction avec les systèmes à base de contraintes. Nous allons présenter cette nouvelle méthode dans la section suivante.
Approche à base de contraintes
L’autre approche cognitive populaire est le module expert à base de contraintes. Lors de sa première introduction par Ohlsson (1992), l’approche par règles est la plus populaire (Mitrovic 2010). Cette nouvelle approche avait pour but de contourner certaines limites du modèle de règles. Notamment contourner la complexité de l’écriture des règles (Ohlsson 1992). En effet, comme nous l’avons vu dans le système à base de règles, des règles correctes et incorrectes doivent être rédigées. Cette rédaction demande beaucoup de travail et de considération pour les ingénieurs et experts du domaine. A première vue, l’approche par contraintes peut sembler similaire. Cependant au lieu de représenter tous les aspects du domaine cognitif (les règles correctes et incorrectes), les contraintes ne vont représenter que les aspects corrects du domaine. En d’autres mots, dans une bonne solution au problème, toutes les contraintes doivent être vérifiées. En effet, si le domaine correct est représenté au complet, tout ce qui ne lui appartient pas ou ne le vérifie pas est faux. Une contrainte est constituée de deux conditions, la condition de pertinence et la condition à satisfaire (Cp et Cs respectivement). Cp s’assure que la contrainte s’active au bon moment, toutes les contraintes ne sont pas vérifiables en début de problème. Si la condition Cp est vérifiée alors la contrainte Cs doit être vérifiée. Si Cs est vérifiée l’apprenant avance correctement. Si elle ne l’est pas alors le tuteur détecte une erreur et intervient pour la souligner à l’élève et
l’aider dans sa résolution. De manière formelle voici un exemple de contraintes dans le cas de l’addition de deux fractions :
SI
Le problème actuel est a/x + b/y, et que la solution propose est (a+b)/n ALORS
Il faut que n = x = y
Pour déterminer l’action que le tuteur doit réaliser pour chaque contrainte non respectée, les concepteurs des contraintes rangent chaque contrainte dans des classes d’équivalence (Mitrovic 2010). Pour chaque classe d’équivalence, une action est définie avec l’aide d’experts du domaine. Ohlsson et Bee (1991) montrent que les systèmes à base de contraintes ne sont pas sensibles à la variance de stratégie (ou « radical strategy variability » en anglais). Cette expression englobe le problème soulevé par les modules experts à base de règles où les concepteurs doivent prendre en compte toutes les stratégies possibles. Les modules à base de contraintes n’y sont pas sensibles puisqu’on ne cherche pas à décrire toutes les stratégies.
Pour conclure, la modélisation du domaine dans l’ITS est le support des deux actions : - détecter les erreurs de l’apprenant ;
- proposer de l’aide à l’apprenant ;
Pour cela, toutes les approches choisissent de représenter le domaine enseigné avec des outils de l’ingénierie des connaissances. En plus de représenter le domaine, les concepteurs ajoutent la partie cognitive pour modéliser le comportement de l’étudiant et réagir en fonction. Dans cette section, nous avons présenté deux des approches les plus populaires, d’autres techniques existent moins courantes comme les ontologies et les graphes sémantiques. Nous redirigeons les lecteurs vers (Nkambou (2010) pour en apprendre plus.
Dans la section suivante, nous allons présenter la deuxième brique du tuteur intelligent, « le modèle apprenant ». Nous présenterons comment les chercheurs déterminent si les apprenants retiennent les aspects vus avec le tuteur.
1.4.2 Modèle de l’apprenant
Lorsqu’un enseignant est avec son élève, il connait sa méthode de travail, ses acquis et ce qui lui reste encore à apprendre. Woolf (2010a) indique que les enseignants avec le plus d’expériences sont capables d’adapter leur méthode d’apprentissage à la personnalité de l’étudiant. La problématique du modèle de l’apprenant dans les ITS est de reproduire la même adaptabilité. Son objectif premier est de mesurer la progression de l’élève. Dans la suite de cette section, nous allons présenter les approches utilisées au sein de la communauté pour répondre à ce problème et ensuite détailler une approche en particulier, le réseau bayésien car il est populaire dans la littérature comme mentionné par Peña-Ayala (2014).
1.4.2.1 Différentes implémentations
Les solutions proposées par la communauté ressemblent beaucoup à celles utilisées pour le modèle du domaine présentées dans la section précédente. Woolf (2010a) réalise un aperçu de toutes les solutions employées pour créer le modèle apprenant. Comme dans le modèle du domaine, les approches à base de contraintes et de règles sont largement utilisées. En effet, les systèmes sont souvent construits avec peu de données. Les concepteurs ont recours aux techniques d’ingénierie des connaissances qui permettent de construire des modèles sans inférence sur un jeux de données (ex : approche par règle). Nous ne décrirons pas ici le fonctionnement de ces deux approches puisqu’il est identique à celui utilisé dans le modèle du domaine. Au lieu de représenter le domaine à apprendre, le modèle de l’apprenant va représenter le cheminement, les erreurs et parfois même les émotions ressenties lors de l’utilisation de l’ITS (Mitrovic et Ohlsson 1999; Mitrovic 1998). Les résultats comparent les performances de leurs tuteurs face à un enseignant humain. Les étudiants uniquement en interaction avec SQL-Tutor montrent autant de réussite que ceux en interaction avec le professeur « humain ». Enfin, l’autre approche par règles se base sur le travail de Anderson et Reiser (1985) et Anderson et al. (1984). L’utilisation des règles dans le modèle apprenant est nommé « model tracing » (Woolf 2010a). Par exemple dans l’ITS Andes (Schulze et al. 2000), le modèle de l’apprenant va reproduire les étapes suivies par le futur apprenant. Chaque étape que suit l’apprenant va créer un arbre de règles respectées ou non. Le graphe représente ainsi la trace de l’apprenant. En étudiant la trace, le système peut prendre des décisions de tutorat, c’est-à-dire afficher des indices ou un rappel de la règle pour l’étudiant.
Nous allons maintenant aborder l’une des techniques les plus populaires et que nous n’avons pas abordés dans la section précédente l’approche à base de réseaux bayésiens.
1.4.2.2 Les réseaux bayésiens
Une des approches populaires pour construire un modèle apprenant est l’utilisation de réseaux bayésiens. L’utilisation de ces réseaux apporte deux avantages. Elle permet de construire un modèle apprenant avec ou
sans données et elle simplifie la construction du modèle. Dans un premier temps, nous abordons comment un réseau bayésien fonctionne et permet d’obtenir des informations utiles sur l’apprenant.
Un réseau bayésien se base sur la formule de Bayes qui régit les probabilités conditionnelles :
(2)
La formule de Bayes indique quelle est la probabilité que l’évènement A se produise sachant que B s’est produit. Ce raisonnement est identique pour un enseignant. Par exemple, un enseignant sachant que son étudiant a réussi l’exercice B souhaite savoir s’il va réussir l’exercice A. De manière implicite, l’enseignant va prendre en compte tout ce qu’il sait sur l’apprenant et l’inclure dans son « estimation » (P(A|B)). L’enseignant sait si l’étudiant a réussi les exercices précédents et représente aussi les états « non-observables » de l’étudiant. Par exemple, si l’étudiant d’anglais a une facilité pour parler d’un sujet politique, un professeur en prend compte après quelques discussions avec lui. Le professeur n’a pas forcement conservé une trace écrite. De même, l’étudiant ne sait peut-être pas qu’il est plus à l’aise sur ce sujet, c’est pour cela que l’on parle d’états non observables (Conati 2010). La formule de Bayes ne prend en compte qu’un seul précèdent alors que les réseaux bayésiens permettent de prendre autant d’évènements et de conditions que l’on souhaite dans un graphe probabiliste. Ainsi, on peut inclure tous les évènements observables et non observables importants pour comprendre l’étudiant. Ce graphe peut être une représentation de ce que l’enseignant peut modéliser à propos d’un de ses étudiants. Pour mieux visualiser le concept nous choisissons un exemple simple : un réseau bayésien pour déterminer si une pelouse sera mouillée (voir figure 2).
Dans cet exemple, on remarque des nœuds et des segments. Chaque nœud représente un évènement et les segments représentent une « condition ». Sur la figure 1, on voit que wet grass est un évènement qui a deux « parents », sprinkler et rain. Chacun de ces évènements dépend de la présence de cloudy. Chaque évènement peut avoir autant d’états possibles suivant une répartition probabiliste. Dans cet exemple, chaque évènement est vrai ou faux mais chaque nœud peut avoir n « résultats » (wet, a little wet ou non wet). La répartition probabiliste des évènements est enregistrée dans les tableaux attachés aux nœuds. Les tableaux de probabilité ont autant d’entrées que le nombre d’évènements possibles que les parents du nœud possèdent. Par exemple, wet grass peut-être vrai ou faux selon quatre états possibles (deux parents aux états booléens). Si nous devions utiliser simplement le théorème de Bayes, les calculs seraient très longs et l’architecture compliquée. C’est pourquoi les réseaux bayésiens sont utilisés dans les environnements complexes comme les ITS.
En effet, dans cet exemple, nous pouvons demander au réseau bayésien de nous donner la répartition de probabilité de l’évènement wet grass sachant n’importe quel évènement parent (« Bayesian Network » 2018; Conati 2010). Par exemple, si nous construisons le réseau bayésien de la figure 2, nous pouvons demander au système : quelles sont toutes les probabilités de tous les évènements wet grass sachant que cloudy est faux ? Le système va rapidement nous donner la probabilité de tous les évènements possibles de wet grass. Avec ces probabilités, nous pouvons prendre une décision. Si nous nous projetons dans un cadre éducatif, nous pouvons demander au système quelle est la probabilité que « l’étudiant maîtrise le sujet A sachant qu’il a réussi deux exercices et en a échoué un ». Nous pouvons mettre une fonction « Heaviside » (« Fonction de Heaviside » 2019) qui prendra en entrée les probabilités données par le réseau bayésien pour retourner un booléen sur la maîtrise du sujet.
La clé de voute d’un réseau bayésien est sa structure ainsi que ses probabilités. Il faut que ces dernières se rapprochent au plus de la réalité des évènements. Cependant, cela peut devenir rapidement compliqué avec la taille du graphe et des domaines flous.
Deux problèmes sont soulevés :
1. Comment construire le graphe du modèle ? Avec quels évènements (nœud) ? 2. Comment remplir les tableaux de probabilité de chaque variable ?
Pour chacune de ces questions, les chercheurs en ITS ont développé plusieurs techniques. Pour établir le graphe et les tableaux de probabilité, la première approche intuitive est de faire appel à un expert, celui-ci va expliciter son savoir et aider les ingénieurs à construire le graphe (Murray et al. 2004; Mayo et Mitrovic 2001; Arroyo et Woolf 2005). Ces approches peuvent être chronophages et nous pouvons nous interroger sur la
capacité de l’expert de mettre à plat son savoir. L’autre approche comme dans d’autres contextes de l’IA est l’utilisation de données. Les données peuvent être par exemple les « logs » d’un système déjà existant. Mayo et Mitrovic (2001) ont utilisé les télémétries d’un ITS de langue seconde pour apprendre les tableaux de probabilité dans un graphe déjà construit. La librairie en Python PGMPY permet de reproduire ces résultats simplement (Python Library for Probabilistic Graphical Models. PGMPY [2013] 2018). Conati et al. (2005) utilisent eux aussi les télémétries pour générer les tableaux de probabilité. Ils ont utilisé les données mesurées pendant le tutorat comme le centre d’attention sur l’écran et les retours écrits des étudiants. Ils ont confronté ces données avec les télémétries classiques du tuteur. En comparant ces données, ils ont pu faire une corrélation et déduire les probabilités de leur réseau bayésien. Ce processus est plus long que le précèdent mais se base sur des données expérimentales au lieu d’uniquement celles de l’expert. Pour générer la structure du graphe, Zhou et Conati (2003) ont réussi, par exemple, à construire un réseau bayésien avec des données qui représente la personnalité et les types d’interaction. Pour plus de détails, nous recommandons au lecteur de lire l’article.
Bull et Kay (2010) donnent un aperçu de l’utilisation du graphe en dehors du tutorat : les modèles apprenants ouverts. L’approche fut formalisée dans la méthodologie de Bull et Kay (2007) qui proposent de rendre explicite le modèle apprenant à tous ou certains acteurs du tuteur intelligent. Par exemple, un étudiant ou un enseignant ayant accès à une représentation précise des connaissances acquises de l’étudiant pourra à son tour concentrer ses efforts. Bull et Kay (2010) donnent beaucoup d’exemples d’application du modèle apprenant ouvert avec toutes les techniques de modèle : à base de contraintes (Mitrovic et Martin 2007), à base de règles (Corbett et Bhatnagar 1997) et à base de réseaux bayésiens (Zapata-Rivera et Greer 2004). Ce qui ressort de tous ces travaux est l’utilisation de visualisation de données pour mieux communiquer les connaissances du système avec tous les acteurs qui l’utilisent : les enseignants, les étudiants ou même les parents.
Comme pour le modèle du domaine où on cherche à construire une représentation du savoir à apprendre, le modèle de l’apprenant cherche à construire une représentation de l’étudiant tel que le fait un vrai enseignant. Pour cela on peut utiliser les mêmes techniques que pour le modèle du domaine. Pour compléter le modèle du domaine, le modèle de l’apprenant crée une représentation cognitive de l’étudiant (Woolf 2010a). Maintenant c’est la tâche du modèle du tuteur de faire communiquer les deux modèles et d’interagir avec l’étudiant.
1.4.3 Modèle du tuteur
Dans cette section, nous allons détailler la partie tuteur des systèmes intelligents. Dans un premier temps, nous allons donner sa définition et les problématiques que cela soulève. Enfin, nous allons présenter un exemple d’application de modèle tuteur.
« un à un » entre un professeur et son élève. En effet, comme le précisent les auteurs (Bourdeau et Grandbastien 2010) « Un professeur demande à ses élèves de s’adapter à la classe. Alors qu’un tuteur s’adapte à l’étudiant». Graesser et al. (2001) indiquent que l’interaction doit se faire dans les deux sens, le tuteur réagit par rapport à l’apprenant et vice versa. Dans la section précédente sur le modèle apprenant, nous avons montré que le savoir sur l’apprenant peut tout contenir à propos de lui, jusqu’à ses émotions. Ainsi par exemple, la présence des émotions dans le modèle de l’apprenant peut être utilisée dans les fonctions de tutorat du modèle tuteur en plus des performances de l’étudiant. En effet, plus le système a d’informations sur son utilisateur, plus il peut interagir. Nous comprenons que l’objectif du tuteur est de bien réagir face aux informations dont il dispose avec les modèles présents dans le tuteur intelligent.
Comme pour les autres modèles du système, il revient de bien choisir la représentation du savoir du tuteur. Nous nous apercevons que la manière de concevoir est souvent identique aux deux autres modèles du système. Comme nous l’avons présenté précédemment, la représentation des données avec des règles ou des réseaux bayésiens adaptent le savoir d’un expert ou le savoir contenu dans des données. Il n’existe pas de système qui mesure les performances des enseignants sur des logiciels. Par conséquent, les données utilisables pour alimenter de tel système n’existent pas encore. Bourdeau et Grandbastien (2010) font référence à l’exploration de données en éducation (Romero et Ventura 2010; Woolf 2010b) qui pourrait mettre en place des techniques déductives entre des données et un modèle tuteur. Cependant nous n’avons pas noté de modèle viable à l’heure actuelle. Dans la prochaine section, nous allons présenter un exemple de modèle tuteur, CanadarmTutor, puis aborder les éléments généralisables pour les modèles tuteurs.
1.4.3.1 Illustration avec CanadarmTutor
Pour illustrer la partie tuteur d’un tuteur intelligent, nous avons choisi le tuteur intelligent utilisé par les astronautes pour apprendre à piloter le bras robotique CanadaArm2 de l’ISS. Dubois et al. (2005) donnent un aperçu de son architecture, reprise dans la figure 3.
Figure 3 : Architecture de l'ITS CanadarmTutor tirée de (Dubois et al. 2005)
Ce tuteur intelligent tente de reproduire fidèlement le processus cognitif de l’apprenant avec un maximum de précision. Dans la figure 3, on retrouve tous les éléments de l’ITS que nous avons présenté jusqu’à présent, un modèle du domaine (Domain expert), le savoir de l’étudiant, la mémoire de travail et aussi l’état émotionnel de l’apprenant. Dubois et al. (2010) expliquent en détail tous les éléments de son architecture. Cependant les deux éléments à retenir sont : le réseau de comportements et l’ensemble des « morceaux de codes » (codelets). À eux deux, ces éléments regroupent l’ensemble des compétences de tutorat : l’obtention des données sur l’étudiant et la prise de décision. La prise de données est réalisée par les codelets. Dubois et al. (2005) indiquent que chaque codelet ne représente que quelques lignes de code. Ainsi les chercheurs peuvent déployer plusieurs codelets pour étudier l’apprenant sous un maximum d’angles différents. Par exemple la figure 3 montre que les chercheurs s’intéressent à l’attention de l’apprenant. Tous ces éléments alimentent la mémoire de travail qui va ensuite interagir avec le « réseau de comportement ». Ce réseau est un arbre de décisions qui, en fonction de l’état du système (mémoire de travail), va proposer des interactions. Comme le montre la figure 3, le réseau peut proposer une discussion, des indices ou un support moral avec l’étudiant. CanadarmTutor réalise ses actions de tutorat de cette façon. Le système va tenter au maximum d’interagir avec l’apprenant. C’est pourquoi le réseau de comportement a beaucoup de sorties pour interagir de manière variée.
En résumé, le système mesure des données supplémentaires à celles déjà présentes dans le modèle de l’apprenant puis prend des décisions en accord à une logique de tutorat. Cette approche en deux temps est souvent présente dans le modèle tuteur des ITS. CanadarmTutor en est un exemple, cependant son architecture
est unique, tous les autres ITS utilisent des architectures différentes en fonction de leur domaine d’enseignement (Dubois et al. 2010).
Cependant, ce qui ressort le plus souvent ce sont des architectures de tutorat qui sont liées ou incluses avec le modèle du domaine ou de l’apprenant. En somme, toutes les architectures logicielles qui permettent de prendre des décisions à propos du tutorat correspondant à un modèle tuteur.
1.5 Personnaliser les jeux en fonction des traits psychologiques
Dans les sections précédentes, nous avons présenté les techniques possibles pour personnaliser la partie éducative d’un système. Il nous reste à aborder comment les chercheurs personnalisent l’aspect ludique des jeux. Comme pour les tuteurs intelligents, les chercheurs font appel aux experts, ici en psychologie, pour mieux comprendre les comportements des joueurs et s’adapter en conséquence. Dans cette section, nous allons présenter les aspects psychologiques, les profils de joueurs qui sont déduits, comment les implémenter et enfin quels sont les impacts dans les jeux sérieux.1.5.1 Les profils psychologiques du joueur
Dans cette section, nous allons présenter le modèle « hexad model » (Marczewski 2015). Ce modèle a été validé par Tondello et al. (2018) comme un modèle pertinent pour la ludification. Dans son modèle psychologique appliqué à la ludification, Marczewski (2015) liste les travaux précédents en soulignant les améliorations successives du modèle.
L’une des premières typologies de joueur a été rédigée par Bartle (1996). Ce travail porte sur les MUD (Multi-User Dungeons). Nacke et al. (2014) résument bien le travail de Bartle. Ce dernier a étudié les joueurs de manière empirique à l’aide des messages publics échangés entre joueurs et en observant leur comportement. Le chercheur a identifié quatre types de joueurs :
• Les tueurs (killers) : Ce sont les joueurs compétitifs intéressés par les combats avec les autres joueurs. • Les réalisateurs (achievers) : Ce sont les joueurs cherchant à obtenir un maximum de points et un
maximum d’objets dans le jeu.
• Les socialisateurs (socializers) : Comme son nom l’indique, ces joueurs sont intéressés par les autres joueurs et les interactions sociales. Ils cherchent souvent à créer des guildes ou groupes de joueurs. • Les explorateurs (explorers) : Ils s’intéressent aux mécaniques de jeux et à la découverte de l’entièreté
Ce travail est considéré comme une première étape pour la suite d’études qui vont suivre et qui ont menées au modèle « hexad model ». Par exemple, dans le travail de recherche de Nacke et al. (2014), les chercheurs ont créé le modèle « BrainHex ». Avec les résultats obtenus des études précédentes, ces chercheurs ont proposé un nouveau modèle et un questionnaire de personnalité qu’ils ont ensuite validé avec une étude en ligne. Pour construire le modèle, les chercheurs ont utilisé les travaux de typologie psychologique comme le Myers-Briggs Type Indicator, MBTI (« Myers–Briggs Type Indicator » 2018). Puisque le MTBI existe depuis suffisamment de temps, son utilisation est simple et les données plus accessibles. En effet, utiliser le « Big Five » (Busch et al. 2015) (Une autre typologie psychologique, utilisant 5 traits) semble plus pertinent selon la communauté en psychologie, mais Nacke et al. (2014) soulignent que le MBTI l’emporte sur le nombre d’utilisations en cas pratiques. Nacke et al. prennent aussi en compte les études de (Bateman et Boon 2005; Bateman et al. 2011) qui permettent de souligner les différences entre les sexes et les nuances d’implication des joueurs de forte implication à occasionnelle. Pour plus de détails nous conseillons la lecture de leur étude démographique. En combinant les recherches démographiques et les études sur d’autres types de jeux (Lazzaro 2008; Yee 2006), Nacke et al. ont créé une typologie de joueurs avec sept traits. Les sept traits en anglais sont : « Seeker, Survivor, Daredevil, Mastermind, Conqueror, Socialiser, Achiever ». En définissant ces traits, Nacke et al. donnent aussi un questionnaire à utiliser dans un contexte de jeux. Même si BrainHex est supérieur aux autres typologies selon le chercheur, d’autres travaux Tondello et al. (2018) et Marczewski (2015) évoquent de nouvelles pistes d’amélioration. En se rapprochant de l’état de l’art de la théorie des traits (des « Big Fives »), le modèle « Hexad » (Marczewski 2015) est une amélioration du modèle BrainHex.
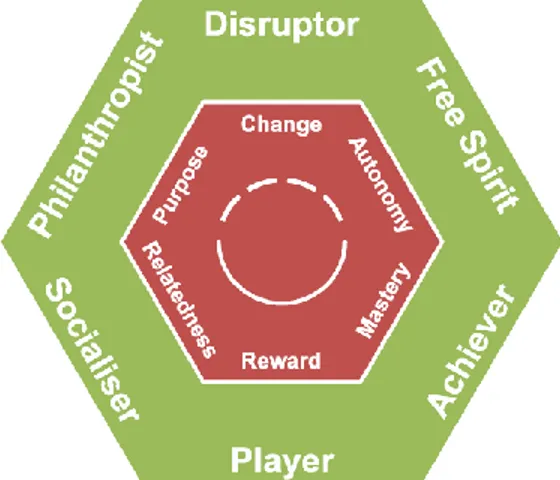
Figure 4 : Représentation du modèle hexad tirée de (Tondello et al. 2016)
Ce modèle définit six traits, chacun associé à des éléments de ludification particuliers. La figure 4 montre l’association entre les traits et les différentes motivations possibles lors de la ludification. Au contraire de Brainhex qui se concentre surtout sur les jeux, le modèle Hexad essaie d’englober tous les contextes de
ludification possibles. Par exemple, les chercheurs définissent le questionnaire avec quatre items par trait. À chaque item, les chercheurs associent une question avec du vocabulaire « simple » (destiné aux personnes ne connaissant pas le vocabulaire des jeux vidéo). Voici un exemple pour le trait de « Player » traduit de l’anglais :
• Joueur (Player)
o J’aime la compétition quand il y a un prix à gagner. o Les récompenses sont efficaces pour me motiver. o Un retour sur investissement est important pour moi. o Si la récompense est suffisante, je vais faire des efforts.
Pour chacun des six traits, on demande au joueur de mettre une note sur sept pour chaque item (1-négatif à 7-positif). Pour obtenir le profil du joueur, il faut faire la somme de tous les scores. Une fois le profil défini, nous pouvons déterminer les éléments de ludification qui sont les plus adaptés pour le joueur.
1.5.2 Application des typologies psychologiques avec des jeux
Après avoir déterminé le profil du joueur, il reste à personnaliser en conséquence l’expérience de jeu. Tondello et al. (2016) présentent des pistes pour chaque trait. Par exemple pour le trait de « joueur », ils proposent d’ajouter un classement des joueurs, un système de badges ou pour le trait de philanthropie d’ajouter un système de collection d’objet qui peut être offert entre joueur. Avec le modèle composé du questionnaire et des exemples de ludification, les concepteurs de jeux peuvent personnaliser l’expérience de tous les joueurs. Il existe des systèmes personnalisés en utilisant le modèle Brainhex (Birk et al. 2015; Lavoué et al. 2018) et le modèle Hexad (Knutas et al. 2017). L’application des modèles est assez simple. Dans (Lavoué et al. 2018), les chercheurs ont identifié des mécaniques implémentables dans leur jeu. Ils en ont sélectionné quelques-unes seulement selon le jeu de leur étude. Ensuite, ils ont déterminé en fonction de traits du joueur la mécanique qui serait la plus adaptée. Une fois les mécaniques implémentées dans le jeu, les chercheurs ont pu confronter leur travail à de vrais apprenants. Avec un test A/B, ils ont remarqué une hausse significative du temps passé dans le jeu pour les joueurs les plus actifs dans le jeu (dernier quartile de la population). Cependant, pour les autres joueurs qui ont passé moins de temps à jouer (moins de deux heures sur trois semaines), aucune différence n’a été remarquée. Malgré ces résultats mitigés, l’approche reste nouvelle et améliore l’expérience d’une partie des apprenants. Une étude propose de se passer du questionnaire psychologique (Guardiola et Natkin 2015). Les auteurs proposent d’utiliser les éléments interactifs d’un jeu à monde ouvert comme indicateur psychologique. Les résultats sont aussi mitigés avec seulement une partie des éléments de l’univers qui ont une corrélation vérifiée avec un trait psychologique.
Nous retenons que les traits psychologiques sont une information qui permet de personnaliser l’expérience du « joueur apprenant », au contraire du tuteur intelligent qui ne se concentre que sur l’aspect apprentissage.
Cette section nous donne un aperçu d’une des techniques utilisées dans les jeux vidéo et les jeux sérieux pour personnaliser le divertissement et ainsi améliorer son expérience de jeu. L’aperçu montre que les résultats sont mitigés dans les jeux sérieux seulement une partie des joueurs voient son engagement augmenter.
1.6 La problématique
En voyant la performance des nouvelles méthodes d’enseignement qui mêlent jeu et apprentissage (« Montessori Education » 2019; « Singapore Math » 2018), nous souhaitons avec ce mémoire continuer d’avancer dans cette voie.
Notre état de l’art permet de confirmer une chose, les chercheurs divisent leurs travaux entre personnalisation des aspects éducatifs et personnalisation des aspects ludiques. Dans peu de travaux, nous avons vu une volonté de faire le lien entre ces deux types de personnalisation. Ainsi nous pensons que joindre ces deux types de personnalisation est une piste de travail intéressante. Ainsi nous proposons de répondre à la problématique suivante : Comment personnaliser les aspects ludique et éducatif dans un jeu sérieux ?
L’état de l’art nous présente beaucoup de techniques pour aider et analyser l’apprentissage. Revenons sur leurs principaux attraits et désavantages.
• L’analyse de l’apprentissage propose des heuristiques qui ont porté leurs fruits sur différents produits commerciaux. Dans ces produits, les apprenants passent le temps adapté à leurs besoins sur le parcours éducatif. Ces travaux sont intéressants pour notre contexte d’apprentissage des langues mais ne sont pas transposables pour tous les domaines éducatifs.
• Les ITS sont pour la plupart construits sur un domaine en particulier par exemple les maths ou l’informatique. Malgré leur champ d’application limité, les résultats sont concluants et déjà industrialisés. Les ITS sont composés de trois modules qui demandent beaucoup de temps de développement. Mais puisque les résultats des ITS sont très encourageants, nous pensons qu’extraire les éléments appropriés au contexte de travail seront des briques puissantes et flexibles.
• Les travaux en psychologie et en ludification proposent des études statistiques sur les affinités entre mécaniques de jeux et profil psychologique. Ces travaux sont les solutions les plus proches et accessibles pour proposer des mécaniques de jeux personnalisées. Cependant les premières mises en place de ces heuristiques montrent des résultats mitigés sur les groupes de joueurs. Seulement les joueurs les plus engagés sont réceptifs. Les joueurs déjà en retrait ne sont pas plus attirés par l’expérience de jeux.
Avec l’état de l’art réalisé, nous pouvons répondre à la problématique. Dans les prochains chapitres, nous proposons un modèle qui s’inspire des structures des ITS pour organiser les données du domaine. Pour les
heuristiques de personnalisation, nous avons combiné ce que proposent certains ITS et la répétition espacée. Nous nous sommes inspiré des travaux de psychologie et de ludification pour la personnalisation des mécaniques de jeux.