HAL Id: tel-03210653
https://tel.archives-ouvertes.fr/tel-03210653
Submitted on 28 Apr 2021
HAL is a multi-disciplinary open access
archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
Jerôme Dias
To cite this version:
Jerôme Dias. Profondeur par la couleur : analyse spatio-spectrale d’un système chromatique. Autre. Université de Grenoble, 2013. Français. �NNT : 2013GRENT120�. �tel-03210653�
DOCTEUR DE L’UNIVERSITÉ DE GRENOBLE
Spécialité : Signal, Image, Parole, Télécoms
Arrêté ministériel : 7 août 2006
Présentée par
Jérôme DIAS
Thèse dirigée par David Alleysson CNRS/LPNC et codirigée par Stéphane Gétin CEA–Leti MINATEC préparée au sein du CEA–Leti MINATEC
et de EEATS
Profondeur par la couleur
Analyse spatio-spectrale d’un système chromatique
Thèse soutenue publiquement le 6 décembre 2013,devant le jury composé de :
M. Pierre-Olivier Amblard
Directeur de recherche CNRS au GIPSA-lab, Président
Mme Sabine Süsstrunk
Professeur à l’École Polytechnique Fédérale de Lausanne, Rapporteur
M. Guy Le Besnerais
Maître de recherche à l’ONERA, Rapporteur
M. Philippe Carre
Professeur à l’Université de Poitiers, Examinateur
M. Thierry Lépine
Enseignant-chercheur à l’IOGS, Examinateur
M. David Alleysson
Chargé de recherche CNRS au LPNC, Co-Directeur de thèse
M. Stéphane Gétin
Ingénieur Chercheur au CEA-Leti MINATEC, Co-Encadrant de thèse
M. Yvon Cazaux
Je remercie tout d’abord David Alleysson et Stéphane Gétin, respectivement codirecteur et encadrant de thèse. Leurs compétences m’ont permis d’aborder de nombreux domaines de recherche passionnants. Je les remercie également pour leur enthousiasme, leur dis-ponibilité ainsi que pour tous leurs conseils et toutes les discussions passionnantes qu’ils m’ont accordées pendant ces quelques années.
Je tiens aussi à exprimer toute ma gratitude à Christian Marendaz pour avoir accepté d’être mon directeur de thèse.
Je souhaite vivement remercier Sabine Süsstrunk, Guy Le Besnerais et Pierre-Olivier Amblard de l’honneur qu’ils m’ont fait en acceptant d’être respectivement rapporteurs de ce mémoire et président du jury. Je remercie également Philippe Carre, Thierry Lépine et Yvon Cazaux d’avoir accepté de participer en tant qu’examinateurs et invité du jury. Plus généralement, j’adresse de profonds remerciements à l’ensemble des membres du jury pour l’intérêt qu’ils ont porté à ces travaux et pour toutes leurs remarques constructives.
Cette thèse est le résultat d’une collaboration entre les laboratoires CEA-Leti et CNRS/LPNC de Grenoble. Elle a bénéficié d’un financement CEA qui a été obtenu grâce à l’aval de Xavier Hugon et Bruno Mourey. C’est pourquoi je tiens à les remercier.
Je remercie également Patrick Chaton et Alexei Tchelnokov, respectivement ex-responsables du service SIONA et du laboratoire LCSP associé, ainsi qu’Émilie Viasnoff, actuelle res-ponsable du laboratoire LCV, pour leur accueil et la mise à disposition des outils de travail nécessaires.
Une part de mes remerciements va aussi vers les nombreuses personnes avec qui j’ai pu échanger pendant ces années.
Je pense en particulier à mes différents collègues de bureau, Paul Dufouleur, Giovanni Beninca de Farias, Stéphanie Bigault et Pierre Barritault. Merci à eux pour leur enthou-siasme, leur humour, mais aussi pour tous leurs conseils et les nombreuses discussions passionnantes que nous avons échangées.
Ainsi qu’à tous les membres de l’ancien service SIONA du laboratoire CEA-Leti et du laboratoire CNRS/LPNC, avec qui j’ai pu discuter et trouver bon nombre de solutions.
anciens stagiaires Fabien Audran et Papp Gergely.
Enfin, je remercie mes parents, ma sœur, ma compagne et tous mes proches pour leur soutien sans faille qui m’a permis de mener à bien cette thèse.
La profondeur est une information importante, en complément d’une image couleur, pour interpréter le contenu d’une scène. Nous proposons un système d’imagerie chro-matique pour acquérir en simultané ces deux informations. Celui-ci se compose d’une optique présentant du chromatisme longitudinal qui a pour propriété d’effectuer un fil-trage spatio-spectral, variable en fonction de la profondeur des objets qui composent la scène. Ce filtrage génère un flou image dépendant de la longueur d’onde et de la profon-deur. Pour mesurer ce flou, on a généralement recours à un capteur d’image revêtu d’une mosaïque de filtres dite de Bayer, conçu pour l’acquisition d’image couleur. Il est montré qu’une analyse par couleur (RGB) de la dispersion spatiale d’une telle image permet, sans ambiguïté, d’estimer la profondeur et de reconstituer l’image couleur nette correspondante [48]. Cependant, cette méthode est efficace pour reconstituer l’image couleur nette mais ne permet d’obtenir qu’une faible précision de profondeur. Pour améliorer cette préci-sion, nous proposons un système d’imagerie chromatique différent, composé d’un capteur revêtu d’une mosaïque de filtres adaptée à l’acquisition d’une image spectrale.
Nous avons établi un modèle spectral permettant de simuler l’image mosaïque ac-quise à partir d’un tel système. Puis nous avons mis en place une procédure d’analyse spatio-spectrale, afin d’estimer conjointement la profondeur et l’image couleur nette des objets de la scène correspondante. À partir de celle-ci, nous avons établi deux algorithmes d’estimation basés sur un problème inverse. Le premier inclut les paramètres physiques du système alors que le second est appliqué de manière aveugle à partir d’une base de données d’images. Un démonstrateur système a été réalisé pour évaluer les performances expérimentales de ces méthodes, pour différents types de scènes.
Les algorithmes développés montrent qu’il est possible d’améliorer la précision de l’estimation de profondeur d’un système chromatique en effectuant une analyse multis-pectrale. Cette approche ne nuit pas à la qualité de l’image couleur reconstruite. De plus, le premier algorithme mis en place nous a permis d’établir un critère pouvant être utilisé pour optimiser les paramètres systèmes, en fonction de l’application souhaitée.
Mots-Clés : Computational imaging, Photographie numérique, Système d’imagerie
chromatique, Problème inverse, Démosaïçage, Analyse spatio-spectrale, Déconvolution d’image, Couches minces optiques, filtrage spectral
Like color, depth is a very useful information to interpret the content of a scene. Depth can be estimated from an acquisition obtained with a chromatic imaging system. It consists of an optical system with an axial chromatic aberration. This aberration creates an image blur that depends on the wavelength and the depth. To measure this, an image sensor with a Bayer color filter array, particularly suitable for color image acquisition, is generally used. It has been shown that a color (RGB) analysis of the spatial dispersion of such image enabled unambiguous estimation of the depth map and a corresponding sharp color image of the given scene. However, this method is more suitable for EDOFs applications as it reconstructs a sharp color image and provides a low depth accuracy.
To improve this technique, we propose a different chromatic imaging system, consisting of an image sensor coated with a color customized filter array, suitable to acquire spectral image. In this perspective, we have established a spectral model to simulate the mosaic image. Then we have developed a procedure for spatio-spectral analysis applied to this image, to jointly estimate the depth and the sharp color image of the corresponding scene. From this, two estimation algorithms based on inverse problem solving have been proposed and implemented. The first includes the physical system parameters while the second is a blind approach applied from an images database.
An experimental system has been designed, qualified and built to evaluate the real performance of these two methods, for different scenes. The developed algorithms show that it is possible to improve the depth estimation accuracy with a chromatic imaging system, by performing a multispectral analysis. This approach does not affect the recons-tructed sharp color image quality. In addition, the first algorithm allowed us to establish an optimization criterion to find the optimal system parameters for a desired application.
Keywords : Computational imaging, Digital Photography, Chromatic Imaging
Sys-tem, Inverse problem, Demosaissing, Spatio-spectral analysis, Image deconvolution, Thin-film optics, Spectral filtering
Résumé III
Table des matières VII
Introduction 1
Notations et Abréviations 5
1 Système d’imagerie 2D+Z passif 9
1.1 Système d’imagerie mono-capteur . . . 9
1.1.1 Principe d’une estimation 2D+Z mono-capteur. . . 12
1.2 État de l’art : estimation 2D+Z mono-capteur passive . . . 13
1.3 Approche utilisée . . . 22
1.3.1 Architecture système . . . 24
1.3.2 Méthode d’estimation 2D+Z . . . 25
2 Modèles et Algorithmes 27 2.1 Modèle d’un système d’imagerie . . . 28
2.1.1 Capteur d’image . . . 28
2.1.2 Mosaïque de filtres et démosaïçage . . . 31
2.1.3 Système optique . . . 40
2.2 Imagerie et estimation multispectrale . . . 58
2.2.1 Introduction générale . . . 58
2.2.2 Estimation d’images multispectrale . . . 60
2.3 Déconvolution d’image . . . 64
2.3.1 Méthode de base . . . 64
2.3.2 Déconvolution par minimisation d’un critère de coût . . . 66
2.3.3 Méthode de déconvolution utilisée . . . 71
2.3.4 Validité des hypothèses formulées a priori . . . 77
3 Modèle système complet 83 3.1 Simulation de scène . . . 84
3.3 Système Optique Chromatique Longitudinal : SOCL . . . 86
3.3.1 Matériau dispersif . . . 86
3.3.2 Aberration chromatique . . . 87
3.3.3 Composante chromatique longitudinale . . . 88
3.3.4 Propriétés d’un SOCL . . . 89
3.3.5 Comparaison d’un SOCL et d’un système optique achromatique, pour une estimation Z . . . 92
3.3.6 Modèle SOCL prenant en compte la diffraction . . . 93
3.4 Modèle système général . . . 97
3.4.1 Forme analytique . . . 97
3.4.2 Forme matricielle linéaire . . . 97
4 Algorithmes d’estimation 2D+Z 103 4.1 Principe algorithmique . . . 103
4.1.1 Processus de filtrage système . . . 104
4.1.2 Processus d’inversion linéaire . . . 105
4.1.3 Procédure d’estimation 2D+Z . . . 106
4.2 Algorithme d’estimation par MAP . . . 108
4.2.1 Processus d’inversion général . . . 108
4.2.2 Processus d’inversion simplifié . . . 114
4.2.3 Reconstitution de la carte de profondeur . . . 134
4.2.4 Reconstitution de l’image couleur EDOF . . . 136
4.2.5 Résultats avec la méthode par MAP . . . 137
4.3 Optimisation de paramètres . . . 148
4.3.1 Détermination d’un critère d’optimisation . . . 148
4.3.2 Détermination des paramètres optimaux . . . 150
4.4 Algorithme d’estimation par Apprentissage . . . 158
4.4.1 Processus d’inversion par apprentissage . . . 158
4.4.2 Reconstruction de la carte de profondeur . . . 161
4.4.3 Reconstitution de l’image couleur EDOF . . . 164
4.5 Conclusions . . . 165
5 Mise en œuvre expérimentale 167 5.1 Conception du système . . . 167
5.1.1 Capteur d’image . . . 169
5.1.2 Mosaïque de filtres . . . 170
5.1.3 Système optique . . . 177
5.2.1 Modèle système utilisé . . . 192
5.2.2 Détermination des paramètres optique et géométrique . . . 193
5.2.3 Comparaison des réponses impulsionnelles expérimentales et théo-riques . . . 200
5.3 Résultats d’estimations 2D+Z . . . 202
5.3.1 Prévisions par le critère d’optimisation . . . 202
5.3.2 Estimation de profondeur dans le cas d’un objet plan centré . . . . 204
5.3.3 Estimation 2D+Z dans le cas d’une scène plus complexe . . . 206
5.3.4 Limites d’estimation . . . 209
5.4 Conclusion . . . 210
Conclusions et perspectives 211 A Annexes 215 A.1 Mosaïçage capteur par dépôt de filtres couches minces . . . 215
A.2 Développement du calcul par MAP simplifié . . . 218
A.3 Développement matriciel du critère d’optimisation . . . 220
A.4 Erreur d’estimation de profondeur liée au champ . . . 222
A.5 Système d’imagerie : conditions d’acquisition . . . 228
A.5.1 Modèle de détecteur . . . 228
A.5.2 Calcul SNR . . . 229
A.5.3 Bilan photométrique . . . 230
A.5.4 Exemple de calcul . . . 232
Les travaux présentés dans ce manuscrit ont été effectués au sein du Département d’Optique et de Photonique du CEA-Leti, en collaboration avec le Laboratoire de Psy-chologie et de NeuroCognition de Grenoble (CNRS/UPMF/LPNC UMR 5105).
Motivations : couleur et profondeur
Actuellement, les systèmes permettant de reconstituer l’image couleur et la profondeur d’une scène donnée font l’objet d’une grande effervescence (Interactions homme-machine, véhicule autonome, mesure dimensionnelle, réalité augmentée, domotique, etc.).
L’information de profondeur permet facilement d’isoler et de mesurer les dimensions des objets d’une scène, alors que l’information de couleur est intéressante pour identifier la nature de chacun de ces objets.
Fig 1: Image couleur nette notée 2D et carte de profondeur notée (Z), d’une scène.
Il n’existe pas de solution système unique pour reconstituer ces deux informations. En effet, il y a une trop grande variabilité de scènes possibles dépendant des propriétés des objets et éclairages, qui les composent. C’est ce qui explique l’émergence d’une multitude de systèmes, que l’on classe souvent selon deux catégories, dites active ou passive.
Pour reconstituer ces deux informations, un système actif est généralement composé d’un projecteur de lumière structuré et de deux systèmes d’acquisition. Le premier sys-tème permet d’acquérir l’image des objets de la scène considérée, modulés par la lumière
projetée. Une analyse de la variation de cette modulation permet de déterminer précisé-ment la profondeur de ces objets. Le second système permet d’acquérir l’image couleur nette de cette scène, sans interférer avec les projections lumineuses effectuées. C’est pour-quoi les projections sont souvent réalisées dans une gamme de longueurs d’ondes proche infrarouge, qui n’est pas visible dans les acquisitions effectuées avec ce second système. Les solutions actives sont les plus précises et fiables en termes d’estimation de profon-deur. Elles représentent cependant une consommation énergétique et un coût important. Par ailleurs, cette précision peut être altérée si les projections structurées et l’éclairage ambiant interfèrent, en plein jour par exemple.
Fig 2: Exemple de système actif. (Kinect)
Un système passif utilise un ou plusieurs systèmes d’imagerie couleur, permettant d’ef-fectuer une ou plusieurs acquisitions de la scène considérée. Généralement, la profondeur est estimée, dans un premier temps, à partir d’une analyse par triangulation de cette ou de ces images. Puis l’image couleur nette est reconstituée par un algorithme de traitement d’image adapté. Un tel système consomme potentiellement moins d’énergie, a un faible coût et est généralement moins encombrant qu’un système actif. Par contre, sa précision est tributaire de bonnes conditions d’exposition et de la texture des objets.
Fig 3: Exemple de système passif. (Fujifilm)
Dans ce contexte, le DOPT (CEA-Leti), en collaboration avec le LPNC (CNRS/UPMF UMR 5105), dont l’une des directions de recherche est l’étude de la vision des couleurs et du démosaïçage effectué par l’Homme, se sont intéressés aux propriétés d’un système d’imagerie dit chromatique afin de reconstituer l’information de profondeur et l’image couleur nette d’une scène. L’un des défis majeurs à relever étant d’estimer efficacement ces deux informations à partir d’une unique acquisition.
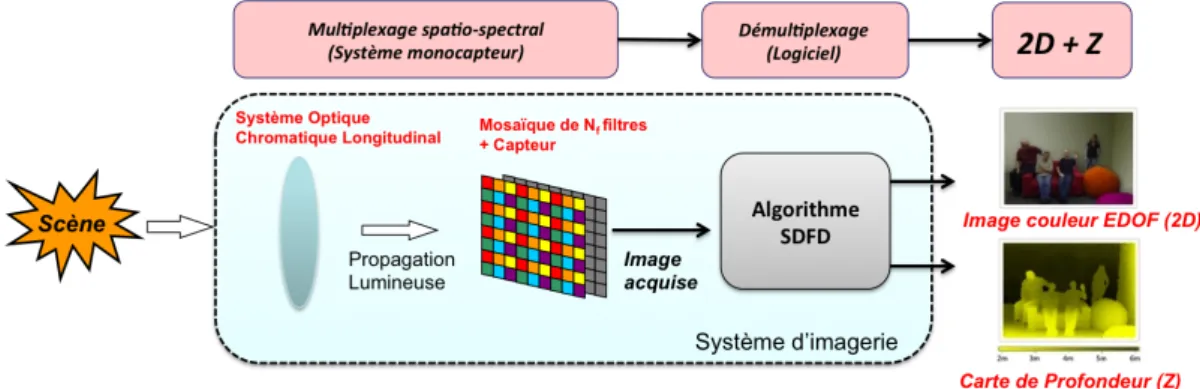
Nous avons considéré un système d’imagerie passif comme un module permettant d’ac-quérir une image, par multiplexage de l’information d’une scène. C’est un démultiplexage de cette image qui permet donc de retrouver, a posteriori, la profondeur et l’image couleur nette correspondantes. Dans notre cas, ce démultiplexage est effectué par un algorithme de traitement d’image spécifique, déterminé à partir d’un problème inverse. Son rôle consiste à compenser les filtrages successifs de l’information de scène, effectués par le système d’acquisition utilisé.
Fig 4: Procédure de Multiplexage et de Démultiplexage du système considéré, pour reconstituer la profon-deur et l’image couleur nette d’une scène (2D+Z).
L’état de l’art regorge de méthodes passives permettant d’estimer ces deux informa-tions. Cependant, peu d’entre elles considèrent l’utilisation d’une seule image acquise à partir d’un unique système passif. Dans notre cas, nous nous sommes intéressés à la mé-thode présentée par Guichard et al. [48], lesquels proposent de restituer la profondeur et l’image couleur nette d’une scène en utilisant les propriétés d’un système optique dit chromatique. La particularité d’un tel système optique est d’effectuer un filtrage spatio-spectral de l’information de scène, en fonction de la profondeur des objets qui composent celle-ci. Ce filtrage permet de générer un flou image proportionnel tant à la longueur d’onde captée qu’à cette profondeur. Pour mesurer ce flou, Guichard et al. [48] proposent d’utiliser un capteur d’image revêtu d’une mosaïque de filtres dite de Bayer (Standard dans l’industrie), particulièrement adaptée pour l’acquisition d’image couleur (RGB). Ainsi, il est montré qu’une analyse par couleur (RGB) du flou de cette image permet d’estimer la profondeur sans ambiguïté et l’image couleur nette de la scène considérée. Cependant, si cette méthode permet d’obtenir une image couleur nette de bonne qualité, elle ne fournit qu’une faible précision de profondeur.
Dans notre méthode, nous avons pensé améliorer cette précision en effectuant une analyse spectrale de l’image acquise plutôt qu’une analyse selon trois couleurs RGB. Pour appliquer celle-ci, nous avons considéré un système chromatique différent, composé cette fois d’un capteur revêtu d’une mosaïque de filtres adaptée à l’acquisition d’une image spectrale. Pour mettre en œuvre cette méthode, nous avons développé un logiciel
à partir d’un modèle système complet. Celui-ci nous a permis de simuler des images qui seraient acquises avec un tel système. En parallèle, nous avons mis en place des algorithmes d’estimation basés sur une analyse spectrale. Nous avons pu les tester à partir d’images simulées. Ces algorithmes ont ensuite été appliqués sur des images acquises expérimentalement, à partir d’un système chromatique réel que nous avons constitué et calibré.
Organisation du document
Ce document se décompose en 5 chapitres organisés selon le schéma suivant.
Fig 5: Schéma d’organisation du document.
Dans le chapitre 1, après avoir présenté une analyse de l’état de l’art sur les systèmes passifs et le cadre applicatif, nous décrivons nos choix systèmes ainsi qu’une procédure d’estimation algorithmique.
Dans le chapitre 2, nous présentons les briques nécessaires à l’établissement du modèle physique de notre système et de nos algorithmes d’estimation. Ce modèle est décrit dans le chapitre 3.
Le chapitre 4 présente les algorithmes d’estimation développés. Leurs performances théoriques sont évaluées sur des images simulées et à partir d’un critère de prédiction.
Dans le chapitre 5, nous présentons la conception, la réalisation et la qualification d’un démonstrateur expérimental. Cet outil nous permet de comparer le comportement de nos algorithmes sur des scènes réelles et d’illustrer leurs performances.
Notations
x, y, z : coordonnées spatiales continues
n, m : coordonnées spatiales discrètes correspondant à x,y λ : coordonnée spectrale continue
l : coordonnée spectrale discrète
T F(xi,yi) : transformée de Fourier selon les dimensions continues (xi, yi)
T F(x−1i,yi) : transformée de Fourier inverse selon les dimensions continues (xi, yi)
T F[n,m] : transformée de Fourier selon les dimensions discrètes (n, m)
s et ˆs : une image et sa transformée de Fourier fxo : coordonnée dans l’espace de Fourier de xo j : unité imaginaire
Re : partie réelle im : partie imaginaire
�(xi,yi) : corrélation continue selon les dimensions (xi, yi) �[n,m] : corrélation discrète selon (n, m)
�(xi,yi) : convolution continue selon (xi, yi)
�[n,m] : convolution discrète selon (n, m)
∇x,yi(x, y) : gradient de l’image i selon les dimensions x et y
δ : Dirac
∆(T,T )(xi, yi) : peigne de Dirac 2D de période T exprimé dans l’espace image
EX : espérance mathématique selon la variable aléatoire X
Cest : estimation de la matrice C
CT : transposée de la matrice C C−1 : inverse de la matrice C
CH : transposée et complexe conjugué de la matrice C (Hermitien)
T r(C) : trace de la matrice C
IdN M : matrice identité de taille NM × NM
⊗ : produit de Kronecker
H�A� : valeur algébrique de la distance H�A�
Abréviations
DOF : Depth Of Field. Profondeur de champ du système d’imagerie utilisé. Celle-ci
représente une gamme de profondeur objet. Dans la scène considérée, chaque objet posi-tionné dans cette gamme est représenté net sur l’image acquise par le système utilisé.
EDOF : Extended Depth Of Field. Profondeur de champ étendue. Ce terme est employé
lorsque la gamme de profondeur de champ du système d’imagerie utilisé a été élargie artificiellement à partir d’un algorithme spécifique. On parle alors d’une image EDOF.
2D+Z : Nous utilisons ce terme pour abréger l’image couleur EDOF associée à la carte
de profondeur d’une scène donnée, comme cela est illustré dans les figures suivantes.
(a) Image 2D (b) Image Z
Fig 6: Notion "2D+Z"
Bien qu’une image couleur soit formellement composée de trois dimensions, nous avons, dans cette notation, considéré celle-ci comme une image dite 2D, à laquelle est associée une dimension supplémentaire correspondant à la carte de profondeur notée Z. La carte de profondeur est une image en niveau de gris, de la même taille que l’image couleur 2D
Système Actif/Passif : Parmi les différents systèmes de mesure de distance existants
on distingue les systèmes actifs et les systèmes passifs. On dit d’un système qu’il est "actif" s’il nécessite l’utilisation d’une projection lumineuse artificielle sur la scène consi-dérée pour mesurer la carte de profondeur correspondante. Dans le cas de ces systèmes, les modifications de la lumière projetée sont captées et analysées pour déduire la carte de profondeur de la scène considérée. Par comparaison, un système est dit "passif" s’il ne nécessite aucune source de projection lumineuse artificielle pour estimer la carte de profondeur de la scène considérée.
Système d’imagerie 2D+Z passif : Se dit d’un système d’imagerie qui effectue de
manière passive l’acquisition d’une image particulière de la scène considérée, puis qui applique sur cette image un traitement algorithmique adapté, afin de restituer des esti-mations de l’image couleur EDOF (2D) ainsi que de la carte de profondeur (Z) de cette même scène.
Système d’imagerie "Pinhole" : Le terme consacré en français est système d’imagerie
"Sténopé". Se dit d’un système d’imagerie pour lequel le système optique a été remplacé
par une mince ouverture. Dans ce document nous considérons qu’un tel système permet d’acquérir l’image EDOF d’une scène (limite de diffraction non considérée).
SNR : Signal to Noise Ratio (Rapport Signal sur Bruit). Mesure qui permet de comparer
le niveau d’une image à celui du bruit de fond présent dans celle-ci. Ce paramètre est calculé en effectuant le rapport entre la densité spectrale de puissance de l’image considérée et la densité spectrale de puissance du bruit considéré.
PSNR : Peak Signal to Noise Ratio. Critère d’erreur en dB que nous utilisons pour
comparer deux images. Dans le cas que nous présentons, ce critère permet principalement d’effectuer une comparaison entre une image originale et une image qui représente son estimation. Un PSNR = 40dB indique généralement une très bonne estimation de l’image originale considérée.
RMSE : Root Mean Square Error. Critère obtenu par calcul de la racine carrée de
l’erreur quadratique moyenne des estimations de profondeur effectuées. Nous utilisons ce critère comme un indicateur de la précision de profondeur de notre système.
DSP : Densité Spectrale de Puissance.
SOCL : Système Optique Chromatique Longitudinal
CFA : Color Filter Array. Matrice composée de différents filtres spectraux. Chaque filtre
peut parfois être associé à une couleur.
DFD : Depth From Defocus. Estimation de la carte de profondeur de la scène
consi-dérée par analyse, dans l’image acquise à partir du système d’imagerie utilisé, des zones défocalisées (zones floues dans l’image).
DFF : Depth From Focus. Estimation de la carte de profondeur de la scène
considé-rée par analyse, dans l’image acquise à partir du système d’imagerie utilisé, des zones focalisées (zones nettes dans l’image).
IHM : Interaction Homme-Machine
CDFD : Chromatic Depth From Defocus. Terme employé lorsque la profondeur de la
scène considérée est estimée à partir d’une analyse du flou présent dans l’image acquise, selon plusieurs couleurs.
SDFD : Spectral Depth From Defocus. Terme employé lorsque la profondeur de la scène
considérée est estimée à partir d’une analyse du flou présent dans l’image acquise, selon plusieurs longueurs d’ondes.
Compte tenu des compétences et directions de recherche de nos laboratoires, nous avons souhaité mettre en place une méthode d’estimation 2D+Z innovante. Celle-ci doit pouvoir s’exécuter à partir d’une seule image acquise avec un système d’imagerie mono-capteur passif. Dans ce chapitre, nous présentons tout d’abord le principe de base utilisé pour effectuer une estimation 2D+Z à partir d’un tel système. Puis nous mettons en perspectives différentes méthodes d’estimation existantes. Ensuite, nous présentons l’ar-chitecture du système que nous avons utilisé ainsi que la méthode d’estimation 2D+Z déterminée.
1.1 Système d’imagerie mono-capteur
Dans cette partie, nous présentons l’influence d’un système d’imagerie mono-capteur, afin de mettre en évidence son utilisation possible pour effectuer l’estimation 2D+Z d’une scène.
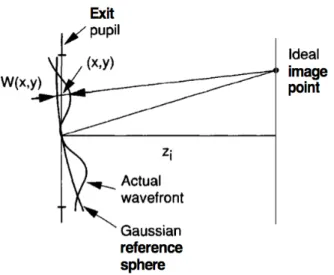
Pour illustrer la réponse d’un tel système, nous considérons le schéma optique suivant :
Fig 1.1: Schéma optique d’un système mono-capteur.
convergent vers un point image A�, à une distance dite de focalisation image notée D f.
Puis ils continuent de se propager jusqu’à un plan image disposé de la même manière que le capteur d’image du système considéré. Les rayons provenant du point objet A vont donc se projeter sur le capteur d’image utilisé pour former une tache circulaire de diamètre Φt.
Dans le cas où le système optique utilisé est considéré comme une lentille mince de focale
f�, Φ
t s’exprime comme suit :
Φt= ΦdDc � � � � � 1 D − 1 Df − 1 f� � � � � � (1.1)
avec Dc la distance capteur (distance du plan image) et Φt le diamètre de l’ouverture
circulaire du système optique.
À partir de cette équation, on peut tracer la courbe d’évolution de Φt en fonction de
la distance ou de la profondeur D du point objet considéré.
Fig 1.2: Évolution caractéristique de Φten fonction de D et mise en évidence de la profondeur de champ
(DOF).
Un système d’imagerie utilise un capteur d’image composé de pixels carrés d’une largeur Tp. On définit la zone dite de profondeur de champ notée DOF (Depth Of Field)
comme la plage de profondeur objet pour laquelle Φt ≤ Tp. Ainsi, l’ensemble des objets
situés dans cette plage de profondeur seront nets sur l’image acquise, alors que les autres seront plus ou moins flous. L’évolution de ce flou image étant proportionnel à Φt(D) figure
1.2.
Dans notre cas, l’image couleur nette associée au terme 2D, dans l’estimation 2D+Z à effectuer, correspond à l’image couleur qui serait acquise si la profondeur de champ du système d’imagerie utilisé était très étendue. Pour la suite, nous appellerons celle-ci image couleur avec profondeur de champ étendue ou image couleur EDOF (Extended Depth Of Field).
Fig 1.3: Illustration de la profondeur de champ (DOF) d’une image acquise.
Le modèle de formation d’image généralement admis pour simuler l’image acquise à partir d’un tel système se base sur l’équation suivante :
s= P SF � ig+ η (1.2)
L’image acquise, notée s, est donnée par une convolution entre l’image EDOF ig de
la scène considérée et la réponse impulsionnelle PSF (Point Spread Function) du système optique utilisé. Un paramètre additionnel η étant intégré pour simuler le bruit de mesure qu’introduit un capteur d’image. La figure suivante détaille un exemple du contenu, sous forme d’images, de chacune des composantes de cette équation.
Fig 1.4: Processus de formation d’image.
L’image acquise est le résultat de la dispersion spatiale de l’image EDOF d’une scène, par la PSF du système optique considéré, parasité par un bruit capteur. L’étendue de la PSF est proportionnelle à Φt, exprimé équation 1.1, qui s’exprime lui-même en fonction
des paramètres système p et de la profondeur objet D.
À partir d’une acquisition, il faut maintenant utiliser une procédure algorithmique qui permet d’estimer au mieux la profondeur et l’image couleur EDOF de la scène considérée.
1.1.1 Principe d’une estimation 2D+Z mono-capteur.
Comme le montrent Schechner et Kiryati [95], l’estimation de la profondeur à partir d’une ou de plusieurs acquisitions effectuées par un système d’imagerie mono-capteur passif ne peut se faire que par triangulation spatiale. En effet, avec un tel système, c’est une mesure de l’angle α des rayons collectés, provenant de l’objet considéré, qui permet de déterminer la profondeur D de cet objet.
Fig 1.5: Illustration d’une mesure de distance par triangulation.
où α peut être obtenue par une estimation de l’étendue de la PSF système, moyennant la connaissance des paramètres système p. Estimer la profondeur des objets d’une scène revient donc à estimer le niveau de dispersion ou de flou dans l’image acquise.
D’après le modèle équation 1.2, l’image EDOF ig ne peut être reconstituée à partir
de l’image acquise s, que si la dispersion image par la PSF et le bruit capteur peuvent être compensés. La profondeur objet doit donc être estimée avant de reconstituer l’image EDOF souhaitée, car l’étendue de la PSF dépend des paramètres systèmes et de D.
La compensation du flou ainsi que celle du bruit présent dans l’image acquise s’effec-tuent grâce à un algorithme dit d’inversion linéaire, qui s’applique généralement à partir d’un modèle de formation d’image dans lequel une hypothèse statistique de bruit capteur, des paramètres systèmes et une hypothèse de profondeur sont pris en compte.
Pour effectuer une estimation 2D+Z à partir d’une ou de plusieurs images acquises avec un système mono-capteur passif, de nombreuses méthodes existent dans l’état de l’art.
1.2 État de l’art : estimation 2D+Z mono-capteur
passive
Historiquement, l’estimation de profondeur a été introduite par Pentland [84] en 1987. Il a proposé une méthode d’analyse du flou d’images acquises à partir d’un système mono-capteur passif. Ses travaux ont donné naissance à un domaine de recherche axé sur l’estimation 2D+Z d’une scène, à partir d’analyses d’une ou de plusieurs images acquises avec un tel système.
Les images obtenues dans le cas d’un système optique simple ne sont pas forcément op-timales pour estimer cette information 2D+Z. C’est pourquoi l’état de l’art se compose de différentes voies de recherches que l’on peut classer selon le type de système mono-capteur utilisé. De plus, nous avons séparé celles-ci en fonction du nombre d’images acquises pour effectuer ces estimations.
Utilisation d’un système optique simple
Les méthodes utilisant un système optique simple (achromatique) cherchent à effectuer une analyse du flou image pour estimer la profondeur de l’objet considéré. L’image couleur EDOF souhaitée étant reconstituée en même temps ou après cette estimation.
Méthodes multi-images
Dans les méthodes d’analyse de flou à partir de plusieurs images, nous avons distingué deux techniques dites Depth From Defocus (DFD) et Shape From Defocus (SFD). Celles-ci se différencient par l’utilisation d’hypothèses de scènes différentes.
Depth from defocus
Dans ses travaux, Pentland [84] propose d’estimer la profondeur en analysant le flou relatif entre deux images acquises avec des diamètres d’ouverture système Φd différents.
Fig 1.6: Évolution du flou image (proportionnel à Φt équation 1.1), pour deux diamètres d’ouverture
Φd1<Φd2.
Cette figure illustre la méthode proposée par Pentland, qui consiste a étudier le flou relatif entre ces deux images, qui évolue proportionnellement à P hit1−Φt2, selon la
profon-deur D considérée. Ainsi, en considérant la PSF du système utilisé comme une gaussienne 2D, il met en évidence une relation entre D, les paramètres du système considéré et le rapport de la transformée de Fourier des deux images acquises pour Φd1 et Φd2. Ce qui
permet d’estimer D à partir de la valeur de ce rapport. Avec cette méthode, la profondeur de champ commune aux deux ouvertures utilisées induit une plage de profondeurs non estimables. De plus, il peut y avoir ambiguïté entre les profondeurs D correspondant à un même niveau de flou relatif. Subbarao [99] a ensuite généralisé cette approche pour permettre d’estimer D à partir d’une variation de n’importe quel paramètre système. D’autres méthodes, présentées par Gökstorp [42], puis par Rajagopalan et Chaudhuri [91], proposent une approche fréquentielle locale, par application de filtres de Gabor ou d’une distribution de Wigner, similaire à celle menée par Pentland [84].
Ces méthodes se basent sur l’étude d’un rapport de fréquences spatiales images qui est très sensible au contenu fréquentiel de celles-ci (cf. [103]).
Pour réduire cette sensibilité, Watanabe et Nayar [103] ont utilisé un critère calculé à partir du rapport entre la différence et la somme de deux images, acquises pour différentes ouvertures Φd. Il est montré que celui-ci respecte, de manière plus robuste, une même loi
d’évolution dépendante de D. Cette loi est ensuite modélisée à partir de fonctions de base et d’un modèle système se servant d’un calcul de PSF plus fidèle, afin d’estimer plus rapidement et efficacement D à partir de la valeur de ce critère.
Nous pouvons aussi évoquer les travaux de Bove [12], qui propose d’estimer D par un calcul d’entropie effectué entre des images acquises à partir d’ouvertures différentes. Pour effectuer ce calcul, une hypothèse initiale considère la réponse d’un système optique comme un filtrage linéaire faisant varier la prévisibilité statistique des images acquises, proportionnellement à D. Cette propriété est exploitée par un calcul d’entropie pour
es-timer D.
Plus récemment, Rajan et Chaudhuri [92] ont proposé une méthode permettant d’es-timer la profondeur et l’image EDOF d’une scène, à partir d’un calcul de maximum a posteriori. Pour effectuer celui-ci, ces deux informations ont été modélisées par des champs de Markov aléatoires distincts.
Shape from Defocus
Pour plus d’efficacité, d’autres méthodes considèrent la carte de profondeur et l’image EDOF d’une scène comme une surface texturée. Cette hypothèse permet d’introduire des a priori communs à ces deux informations.
Dans ces conditions, Favaro et Soatto [31] ont proposé d’effectuer un apprentissage à partir d’images floues et nettes de référence afin de constituer, par décomposition en valeurs singulières (SVD), une base d’opérateurs linéaires permettant d’estimer la pro-fondeur en temps réel. Notons aussi les travaux de Favaro et Soatto [28] et de Favaro et
al. [32], qui proposent de considérer le flou image comme un processus de diffusion de la
chaleur. La profondeur à estimer et les images acquises pour deux ouvertures Φd1 <Φd2
étant respectivement considérées comme le coefficient de diffusion et le résultat d’une propagation de chaleur d’un temps t1 à t2.
Méthodes mono-image
L’estimation de la profondeur et de l’image EDOF d’une scène à partir d’une unique image est un problème initialement très mal posé. Contrairement aux méthodes multi-images, celle-ci ne peut pas procéder par une analyse relative d’images acquises avec des paramètres différents. Ainsi, avec une seule image, une variation liée à la texture d’un objet peut être interprétée comme un certain niveau de flou image, correspondant à une profondeur. C’est pourquoi ces méthodes sont souvent imprécises et peu fiables.
Nous pouvons tout de même citer les travaux de Bando et Nishita [10] qui proposent de pallier le manque d’image de référence en constituant une base de plusieurs images successivement obtenues par différentes déconvolutions de l’unique image acquise. C’est ensuite une analyse de ces différentes images qui permet d’estimer la profondeur.
Une autre manière de remédier à ce manque d’image de référence consiste à employer des hypothèses sur les données à estimer. C’est le cas des travaux de Namboodiri et
Chaud-huri [66] qui considèrent la dispersion de l’unique image utilisée comme le résultat d’un
processus de diffusion de la chaleur. Ainsi, estimer la profondeur et l’image EDOF revient à remonter le temps pendant lequel l’image EDOF s’est diffusée pour arriver au résultat de l’image acquise.
Utilisation d’un système optique chromatique longitudinal
L’utilisation d’un système optique dit chromatique longitudinal est une solution inté-ressante pour effectuer l’estimation 2D+Z d’une scène. En effet, avec un tel système, les rayons provenant d’un point objet vont converger vers un point image dont la position dépend de la profondeur D, mais aussi, dans ce cas, de la longueur d’onde λ des rayons considérés. Cette propriété vient de la dépendance en λ de la focale équivalente d’un tel système optique.
Fig 1.7: Schéma optique d’un système chromatique mono-capteur.
En utilisant un tel système optique avec un capteur d’image couleur RGB, Guichard
et al. [48] ont montré que chacune des images R, G et B acquises est nette pour des objets
positionnés à différentes distances.
Fig 1.8: Images RGB acquises à partir d’un système chromatique longitudinal. Cette figure est empruntée à [48].
Comme l’ont tout d’abord décrit Garcia et al. [40], sans présenter de résultats, il est possible de retrouver l’information de profondeur de la scène considérée par une analyse relative du flou des trois images couleur R, G et B acquises.
Plus tard, Guichard et al. [48] ont montré la faisabilité d’une telle méthode en dévelop-pant un système chromatique complet et un algorithme qui estime une carte de profondeur par identification du gradient maximum entre ces trois images. L’image couleur EDOF est ensuite reconstituée par copie des hautes fréquences spatiales de l’image R, G ou B la plus nette (fort gradient) vers les autres canaux couleurs. Cette méthode permet d’obtenir les résultats suivants :
Fig 1.9: Résultats d’estimation 2D+Z obtenus avec la méthode de Guichard et al. [48]. Cette figure est empruntée à [48].
Celle-ci est plutôt adaptée à la reconstruction de l’image couleur EDOF, mais pas de la carte de profondeur. Les zones noires de celle-ci étant des zones non reconstruites.
Les résultats les plus denses et précis en termes d’estimation de profondeur ont été obtenus par P. Trouve [102]. Dans son étude, un algorithme d’analyse du niveau de flou des images R, G et B acquises est présenté. Les estimations de profondeur obtenues ont une précision proche de 5cm dans le meilleur des cas et un biais très faible, pour des objets positionnés entre 1m et 5m. Ce qui est une bonne précision compte tenu de l’acquisition d’une seule image et de l’utilisation d’un système passif.
L’image couleur EDOF est ensuite reconstituée par une méthode de transport de hautes fréquences spatiales images, comme celle proposée par Guichard et al. [48].
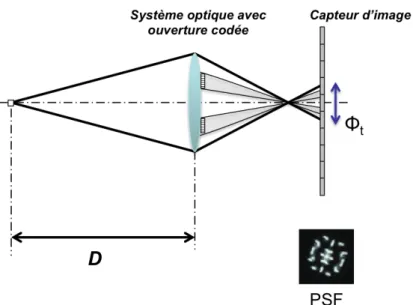
Utilisation d’un système optique avec ouverture codée
Une autre méthode pour effectuer une estimation 2D+Z consiste à intégrer dans l’ou-verture d’un système optique simple un masque qui va coder la réponse impulsionnelle de celui-ci. La figure suivante montre les conséquences d’un masque binaire (laissant ou non passer la lumière) sur la réponse impulsionnelle (PSF).
Fig 1.10: Schéma optique d’un système mono-capteur avec un masque qui code l’amplitude des rayons (0 ou 1).
L’intérêt de ce codage est de faciliter l’analyse du flou dans l’image acquise, afin d’estimer plus efficacement la profondeur.
Méthodes multi-images
Avec un codage binaire, on peut ne laisser passer que les rayons provenant d’un objet selon une même direction. Ce qui peut permettre de générer des images selon des angles de vues différents. En faisant l’acquisition de plusieurs images selon différents angles de vue (différents codages binaires), Liang et al. [59] proposent d’effectuer un calcul de disparité entre celles-ci, pour estimer la profondeur. L’image couleur EDOF étant ensuite reconsti-tuée par un traitement adapté de ces images. D’un point de vue géométrique, Schechner et Kiryati [95] ont montré qu’une telle mesure de disparité est équivalente à une mesure de la dispersion ou du flou de l’image qui serait acquise avec le même système d’imagerie, sans codage de l’ouverture.
D’autres travaux présentés par Zhou et al. [108] proposent une méthode d’estimation 2D+Z, basée sur l’analyse relative du flou présent dans deux images acquises pour des ouvertures binaires différentes. Cette méthode exploite les artéfacts qui se créent lors de la déconvolution de ces deux images, en utilisant un critère d’erreur spécifique. De plus, le
développement analytique de ce critère a permis de mettre en place une procédure pour optimiser les deux codages d’ouverture à utiliser.
Méthodes mono-image
L’un des avantages d’un codage d’ouverture est de rendre plus abordable l’estimation 2D+Z à partir d’une unique acquisition. Dans ce cas, une multitude de méthodes ont été proposées.
Présentons tout d’abord celle de Levin et al. [55], qui calcule un critère d’erreur sta-tistique à partir d’un modèle système prenant en compte un codage binaire et d’une hy-pothèse statistique sur l’image EDOF à estimer. De ce critère sont dérivés une méthode pour effectuer une estimation 2D+Z et une méthode permettant d’optimiser le codage d’ouverture à utiliser. Dans ces travaux, un tel codage est vu comme une manière de moduler spécifiquement la réponse fréquentielle d’un système d’imagerie, afin de faciliter l’estimation de la profondeur.
Toujours dans le but de moduler spécifiquement la réponse fréquentielle système
Simo-nov et Rombach [98] ont mis en place un élément optique qui effectue un codage de phase
appelé "Chiral Phase coding". Celui-ci permet à la réponse fréquentielle correspondante d’être composée d’oscillations dont l’orientation dépend de la profondeur objet. Ce type de codage pourrait rendre plus facile l’estimation de la profondeur, mais il n’est applicable que pour des systèmes d’imagerie microscopiques.
Une autre méthode présentée par Bando et al. [9] se base sur l’utilisation d’un codage d’ouverture effectué avec trois des filtres colorés R, G et B. Dans ce cas, chaque image R, G ou B acquise à partir d’un capteur d’image couleur est obtenue selon le codage couleur correspondant. Ce qui peut permettre d’obtenir des images couleur issues d’angles de vue différents et d’estimer la profondeur par une mesure de disparité.
Utilisation d’un système plénoptique
Le principe des systèmes plénoptiques découle des travaux effectués par G.
Lipp-man [60] en 1908. Ceux-ci présentent les effets de la disposition d’un réseau de lentilles
convergentes sur une plaque photosensible, le tout positionné devant un système optique principal.
C’est cette disposition judicieuse de lentilles qui a donné naissance aux systèmes dits plénoptiques. Ceux-ci sont composés d’un système optique et d’un capteur d’image revêtu d’une matrice de micro-lentilles. Le bloc de pixels situés sous une micro-lentille étant appelé macro-pixel.
Fig 1.11: Illustration d’un macro-pixel. Cette figure est empruntée à [34]
Ainsi, avec un système plénoptique, les pixels appartenant à un même macro-pixel intègrent chacun un angle spécifique d’arrivée des rayons provenant d’un même point objet. Cela signifie que l’image reconstituée à partir de l’information acquise par les pixels situés à une même position, dans chaque macro-pixel, correspond à un angle de prise de vue spécifique de la scène. Comme illustré dans la figure suivante :
Fig 1.12: Schéma de principe d’un système plénoptique. Cette figure est empruntée à [71]
Ce type de système peut donc permettre, en une seule acquisition, de générer plusieurs images, selon différents angles de vue.
Ainsi, comme l’ont présenté Adelson et Wang [2], une mesure de disparité entre ces différentes images peut permettre d’estimer la profondeur. Cependant, les images recons-tituées avec un tel système sont de faible résolution, car limitées par le nombre de macro-pixels utilisés. En outre, avec un tel système, des problèmes de recouvrement peuvent se produire dans le cas où les rayons lumineux d’un même point objet se propagent dans le macro-pixel voisin.
C’est pourquoi Bishop et Favaro [100], puis Perwass et Wietzke [86] ont développé un algorithme de sur-échantillonnage utilisant un modèle précis de ce type de système. De cette manière, des images de plus grande résolution sont reconstituées selon plusieurs angles de vue, permettant ainsi d’estimer plus précisément la profondeur de la scène considérée, par une mesure de disparité.
1.3 Approche utilisée
L’État de l’art regorge de méthodes permettant d’estimer la profondeur et l’image couleur avec une profondeur de champ étendue d’une scène, notée image couleur EDOF (Extended Depth Of Field) dans ce document. Une méthode potentiellement intéressante pour estimer ces deux informations, à partir d’une unique acquisition, consiste à exploiter les propriétés d’un système optique chromatique longitudinal (noté SOCL). La princi-pale caractéristique d’un tel système optique est d’avoir une focale f�(λ) dépendant de
la longueur d’onde des rayons qui le traversent. Cette propriété a pour conséquence de générer un flou image dépendant de la profondeur D de l’objet considéré, comme pour un système d’imagerie achromatique classique, mais aussi dans ce cas de la longueur d’onde λ.
Comme nous l’avons dit dans la première partie de ce chapitre, le paramètre Φt,
exprimé équation 1.1, est proportionnel au niveau de flou de l’image qui serait acquise pour des paramètres système donnés. Dans le cas d’un SOCL, nous montrons dans le chapitre 3 que ce paramètre dépend des caractéristiques du système utilisé, de D mais aussi de λ.
Fig 1.13: Influence d’un SOCL sur le niveau de flou image (proportionnel à Φt), en fonction de λ et pour
trois profondeurs objet différentes D1< D2< D3.
Si les paramètres du système d’imagerie chromatique utilisé sont connus, estimer la profondeur D revient à déterminer la courbe d’évolution spectrale du flou image, pro-portionnel à Φt(λ). D’où l’importance d’utiliser, en plus d’un SOCL, un capteur d’image
capable de discriminer différentes bandes de longueur d’onde.
Citons l’exemple des capteurs d’image couleur RGB qui permettent de reconstituer, à partir d’une seule acquisition, trois images vues à travers trois filtres colorés R, G et B. Ces capteurs sont en réalité composés d’un seul capteur d’image monochrome revêtu d’une mosaïque de filtres colorés RGB, dite de Bayer, qui permet d’acquérir une image dite mosaïque. Les trois images R, G et B sont obtenues, après acquisition, par applica-tion d’un algorithme de démosaïçage sur cette image. Le principe d’un tel algorithme est
détaillé dans la partie 2.1.2 du chapitre 2.
Les méthodes existantes [40], [48] et [102], proposent d’estimer D par une analyse du flou des images R, G et B acquises par un système composé d’un capteur d’image RGB et d’un SOCL. Cette approche est appelée "Chromatic Depth From Defocus" (CDFD), puis-qu’elle se base sur une analyse de flou image, par couleur, pour estimer D. Ces méthodes sont appliquées à partir d’une hypothèse considérant la réponse impulsionnelle du SOCL utilisé non pas dépendante de λ mais d’un indice couleur c ∈ {R, G, B} : PSF (D, c). Cette approche est physiquement incorrecte d’un point de vue spectral. Néanmoins, elle permet de simplifier le modèle système utilisé et d’obtenir de bonnes estimations, comme le montre P. Trouve dans ses travaux [102].
Dans le but d’améliorer encore les estimations effectuées à partir d’un SOCL, nous nous sommes intéressés aux résultats que permettrait d’obtenir une méthode basée sur une analyse par longueur d’onde, et non plus par couleur, du flou de l’image acquise. λ étant la dimension selon laquelle le niveau de flou image évolue physiquement, dans le cas d’un SOCL. Ainsi, en comparaison aux approches CDFD existantes, notre approche serait plutôt appelée "Spectral Depth From Defocus" (SDFD).
Fig 1.14: Comparaison des espaces d’analyse utilisés par les approches CDFD existantes (gauche) et l’approche SDFD proposée (droite).
L’idée d’utiliser une telle approche spectrale nous est aussi venue d’une des compé-tences technologiques du laboratoire CEA-Leti, qui permet d’envisager la fabrication de mosaïques de filtres colorés personnalisées, par une technique de dépôt de couches minces optiques succinctement présentée dans l’annexe A.1. Cette mosaïque étant à disposer sur un capteur d’image monochrome, pour permettre à celui-ci d’acquérir des images mosaïque plus adaptées à la reconstitution d’images appartenant à un espace couleur différent de l’espace RGB classique.
C’est pourquoi nous avons considéré une architecture système plus générale, qui permet de prendre en compte n’importe quel type de mosaïque.
1.3.1 Architecture système
Dans l’hypothèse d’une amélioration des estimations 2D+Z obtenues par une analyse spectrale, nous nous sommes affranchis du paradigme RGB d’une mosaïque de Bayer clas-siquement utilisée. C’est pourquoi nous avons considéré un système d’imagerie composé d’un SOCL, d’une mosaïque de Nf filtres colorés à définir et d’un module de traitement
logiciel dont le rôle est d’effectuer une estimation 2D+Z, par une analyse spectrale de l’image acquise.
Fig 1.15: Représentation des éléments du système d’imagerie retenu pour utiliser une approche spectrale.
Pour mettre en place notre approche, nous avons considéré la partie physique de ce système comme un module composé de différents éléments qui effectuent ensemble un multiplexage, dit spatio-spectral, de l’information de scène (rayons lumineux provenant de la scène).
Le but est donc de définir un algorithme permettant d’inverser ce multiplexage afin de remonter à la profondeur et à l’image couleur EDOF de la scène considérée. Pour ce faire, nous avons tout d’abord mis en place un modèle système linéaire, détaillé dans le chapitre 3, prenant en compte ces deux informations à estimer. Puis, en prenant en compte ce modèle, nous avons déterminé une méthode d’estimation 2D+Z chargée d’effectuer un démultiplexage de l’image acquise.
1.3.2 Méthode d’estimation 2D+Z
La méthode d’estimation utilisée se décompose en deux étapes successives. La première analyse l’image acquise, selon une approche SDFD, pour estimer la profondeur. La seconde utilise cette estimation ainsi que l’image acquise, pour reconstituer l’image couleur EDOF correspondante.
Estimation de profondeur par une approche SDFD
La profondeur est estimée par une approche "Spectral Depth From Defocus" (SDFD), qui se base sur une analyse spectrale de l’image acquise. Pour ce faire, nous proposons d’utiliser une méthode d’analyse des artéfacts qui se créent lors de l’inversion linéaire de cette image. Le processus chargé d’effectuer cette inversion est déterminé dans le chapitre 4, à partir du modèle système mis en place. Son but est de compenser le multiplexage système illustré figure 1.15, afin de remonter à une estimation de l’image multispectrale EDOF réelle de la scène considérée.
Comme nous le verrons dans le chapitre 4, cette estimation présente des artéfacts par rapport à l’image réelle. Ce sont ces artéfacts que l’on exploite pour estimer la profondeur réelle de la scène considérée. En effet, il s’avère que ceux-ci ont un minimum lorsque la profondeur test utilisée pour appliquer le processus d’inversion est égale à la profondeur réelle Dt= D.
Estimer la profondeur avec une telle méthode revient donc à identifier ce point d’arté-facts minimums. Pour ce faire, nous avons transposé, dans un espace image multispectral, le critère d’erreur développé par Zhou et al. [108]. Ainsi, l’estimation de la profondeur réelle est donnée par la profondeur test Dt qui minimise le critère d’erreur C (n, m, Dt)
de la figure suivante.
Fig 1.16: Procédure de calcul du critère d’erreur à minimiser pour estimer la profondeur, par une analyse SDFD.
En minimisant ce critère selon chaque coordonnée discrète (n, m) des pixels considérés et chacune des profondeurs testées, on obtient l’estimation Dest(n, m) de la carte de
profondeur réelle D (n, m) de la scène considérée. Le terme carte de profondeur permet de prendre en compte une possible variation de la profondeur de la scène considérée, d’un pixel à l’autre du capteur utilisé.
Dest(n, m) = min Dt
C(n, m, Dt) (1.3)
Après cette estimation, l’image couleur EDOF peut être reconstituée selon la méthode suivante.
Reconstruction de l’image couleur EDOF
Pour reconstituer l’image couleur EDOF, on ré-applique simplement le processus d’in-version linéaire mis en place dans le chapitre 4, en prenant en compte la profondeur estimée Dest(n, m) comme donnée d’entrée. Ce qui permet de reconstituer une estimation
de l’image multispectrale EDOF de la scène considérée. Celle-ci étant ensuite convertie dans l’espace couleur souhaité, en l’occurrence un espace RGB, pour reconstituer l’image couleur EDOF, notée iRGBest(n, m).
Fig 1.17: Processus de reconstruction de l’image couleur EDOF iRGBest.
Nous avons déterminé deux algorithmes selon cette méthode d’estimation. Ceux-ci sont présentés dans le chapitre 4 et validés expérimentalement dans le chapitre 5.
Dans le chapitre suivant sont présentés tous les modèles et algorithmes de base qui nous ont permis de déterminer notre modèle système et nos algorithmes d’estimation 2D+Z.
Pour mettre en place un système d’imagerie 2D+Z passif, nous avons établi un modèle théorique complet de celui-ci, auquel nous avons associé un algorithme adapté, basé sur la notion de système inverse. L’intérêt étant de maîtriser théoriquement toute la chaîne d’acquisition de ce système et, ainsi, d’inverser l’influence de certains éléments qui le com-posent, par un traitement algorithmique adapté et appliqué sur l’image acquise à partir de celui-ci. Le but est de recomposer, avec cet algorithme d’inversion, l’information 2D+Z originale de la scène considérée.
Pour établir ce modèle et cet algorithme d’inversion, nous nous sommes inspirés de différents modèles et d’algorithmes basés sur la notion de système inverse. Nous avons aussi utilisé les méthodes d’estimation 2D+Z présentées dans l’état de l’art du chapitre suivant. Ces différents modèles et algorithmes sont énoncés dans cette partie, selon une description par étapes de la chaîne d’acquisition d’un système d’imagerie classique.
2.1 Modèle d’un système d’imagerie
Dans cette partie, nous décrivons l’ensemble des modèles nous ayant permis d’établir le modèle intégral d’un système d’imagerie classique. Celles-ci sont organisées depuis le capteur d’image jusqu’à la scène objet.
2.1.1 Capteur d’image
La description suivante, laquelle permet de mettre en évidence la relation entre les plans image et objet, est établie à partir d’une projection de l’information provenant de l’espace objet vers un espace image. Nous l’utilisons tout au long de ce document.
Projection de l’information de scène
Nous introduisons le processus de projection de l’information d’une scène objet, d’un système d’imagerie dit "Pinhole", constitué uniquement d’une petite ouverture circulaire. Dans ce cas, les rayons lumineux provenant d’une scène considérée sont projetés sur un plan image donné, en passant par le centre optique. Comme illustré selon les deux dimen-sions x, z, dans la figure suivante.
Fig 2.1: Projection d’un rayon provenant d’une scène sur un plan image.
où l (x, z, θ, λ) est la radiance du rayon lumineux émis dans la direction θ par un élément de surface centré sur le point objet en (x, z). λ étant la longueur d’onde du rayon considéré.
Une image continue de la scène est alors formée par projection de chaque rayon pro-venant de l’objet, sur un plan image donné, à travers la mince ouverture. Une position dans le plan image ne correspond donc qu’à un seul angle d’arrivée des rayons provenant de la scène. L’image obtenue est une projection de la fonction de radiance l (x, z, θ, λ), en fonction de θ, Z et de la distance Di du plan image considéré. Ainsi, l’angle θ d’arrivée des
rayons implique une multiplication de la dimension x par le rapport Di
z sur le plan image.
C’est cette opération qui induit l’effet de perspective sur l’image formée à la distance Di.
inversement proportionnelle à la distance de celui-ci.
Maintenant un espace 3D selon (x, y, z), on utilisera dans la suite de ce document la notion d’image spectrale continue notée i (xi, yi, λ). Celle-ci est le résultat de l’éclairement
du plan image considéré, à partir de la radiance l�x.Di
z , y. Di
z , λ
�
provenant d’une scène objet. l � x.Di z , y. Di z , λ � =⇒ i (xi, yi, λ) (2.1)
où xi et yi sont des coordonnées spatiales continues qui parcourent ce plan image.
Nous considérons qu’un capteur d’image est une fenêtre d’observation d’un espace image continu, selon les pixels qui le composent. Chaque pixel effectuant l’intégration spatiale et spectrale d’une partie de l’image spectrale continue i (xi, yi, λ).
Discrétisation spatiale du plan image
Un capteur d’image est composé de pixels carrés, de largeur Tp, régulièrement répartis
sans discontinuité sur une surface de taille N.Tp×M.Tp, avec NM le nombre de pixels. De
plus, nous émettons l’hypothèse que chaque pixel effectue une intégration indépendante de l’angle d’incidence des rayons collectés.
Fig 2.2: Discrétisation du plan image par un capteur matriciel.
De cette intégration résulte une image spectrale continue, vue par le capteur et notée
ig(xi, yi, λ). Celle-ci peut s’exprimer théoriquement en mettant en équation les opérations
spatiales effectuées sur i (xi, yi, λ). Ces opérations sont issues des travaux de Gaskill [41]
ig(xi, yi, λ) = ∆(Tp,Tp)(xi, yi). � Rect � xi Tp , yi Tp � �(xi,yi) � Rect � xi N.Tp , yi M.Tp � .i(xi, yi, λ) �� (2.2)
où i(xi, yi, λ) représente l’image spectrale continue obtenue sur le plan image considéré.
Cette image est acquise à travers une fenêtre d’observation de la taille du capteur uti-lisé, modélisée par une fonction rectangle Rect� xi
N.Tp,
yi
M.Tp �
. Ensuite, l’intégration spa-tiale effectuée par chaque pixel est modélisée par la convolution d’une fonction rectangle
Rect�xi
Tp,
yi
Tp �
de la taille de celui-ci, suivie d’une multiplication par un peigne de Dirac réparti au centre de chaque pixel capteur ∆(Tp,Tp)(xi, yi) =
�
m�nδ(xi− n.Tp, yi− m.Tp).
Nous en déduisons l’expression de l’image spectrale ig(n, m, λ) spatialement discrétisée
par le capteur, selon chaque pixel centré sur les coordonnées (n.Tp, m.Tp). Avec (n, m) les
coordonnées discrètes associées à un pixel.
ig(n, m, λ) = δ(xi−n.Tp, yi−m.Tp). � Rect � xi Tp , yi Tp � �(xi,yi) � Rect � xi N.Tp , yi M.Tp � .i(xi, yi, λ) �� (2.3)
Cette image est le résultat de la discrétisation spatiale du plan image continu délimité par le capteur considéré.
Il faut aussi prendre en compte l’intégration spectrale et le bruit de mesure introduit par chaque pixel.
Intégration spectrale et bruit de mesure
L’intégration spectrale se fait en prenant en compte la sensibilité spectrale capteur
qe(λ), que l’on considère identique pour chaque pixel. Celle-ci représente le taux de
conversion en électrons des photons incidents sur le pixel considéré. Le niveau de gris numérique obtenu pour ce pixel étant linéairement dépendant de la quantité d’électrons collectés par celui-ci.
Toute cette chaîne de conversion des photons incidents en niveaux de gris numérique introduit un bruit de mesure non négligeable. Celui-ci est modélisé par un bruit additif
η(n, m), de loi de probabilité normale N (0, σb). L’image acquise par le capteur s’écrit :
s(n, m) = �
La partie suivante est dédiée à la modélisation d’un capteur d’image revêtu d’une mosaïque de filtres.
2.1.2 Mosaïque de filtres et démosaïçage
Nous introduisons les notions ayant amené à l’utilisation de mosaïques de filtres pour l’acquisition de l’image couleur d’une scène. Puis, nous présentons l’influence et la modé-lisation d’une telle mosaïque disposée sur un capteur d’image monochrome. Enfin, nous abordons la notion de démosaïçage.
Acquisition d’image couleur
La perception humaine des couleurs est obtenue à partir de cellules rétiniennes, appe-lées cônes, qui ont différentes sensibilités spectrales. Chez l’Homme, il y a trois types de cônes, qui ont permis d’introduire la notion de vision humaine des couleurs (trichromie). Chaque type de cône se différencie des autres par une absorption spectrale différente des rayons lumineux reçus et est classé selon la longueur d’onde correspondant à son maximum d’absorption. Il y a des cônes L, M et S, respectivement associés à des longueurs d’ondes dites Long, Medium et Short. Dans de faibles conditions d’éclairage, ce sont d’autres ré-cepteurs, appelés bâtonnets, qui prennent le relais pour permettre la perception d’une image en niveau de gris de la scène considérée. La figure suivante illustre les absorptions spectrales des cônes et bâtonnets dans la gamme des longueurs d’ondes dites visibles � [400nm; 700nm].
Fig 2.3: Absorption spectrale des cônes (courbes L, M et S) et des bâtonnets (courbe R) chez l’Homme. Image Wikipédia et courbes issues des mesures de Bowmaker et Dartnall [13].
Pour construire l’image couleur d’une scène, l’œil humain collecte les rayons lumineux provenant de celle-ci, à partir d’une répartition en mosaïque de ces différents types de cônes sur la rétine. Ceux-ci génèrent ensuite des signaux nerveux transmis par les nerfs optiques vers le cerveau qui effectue un traitement complexe de ces signaux afin de
consti-tuer une image couleur perçue de la scène considérée.
Pour enregistrer une image couleur, la majorité des systèmes d’imagerie existants effectuent un traitement algorithmique sur l’image acquise à partir de trois types de photorécepteurs répartis en mosaïque et sensibles à trois couleurs primaires : rouge, vert et bleu (RGB). Cette mosaïque de photorécepteurs RGB est généralement obtenue en disposant une mosaïque de filtres colorés R, G et B sur un capteur d’image monochrome. La figure suivante illustre une mosaïque de filtres, dite de Bayer, disposée sur un capteur et classiquement utilisée pour acquérir l’image couleur d’une scène.
Fig 2.4: Mosaïque de filtres dite de Bayer disposée sur un capteur d’image monochrome. Cette figure est empruntée à [22]
Ce dispositif permet d’acquérir une image, dite mosaïque, de la scène considérée, sur laquelle est appliqué un algorithme dit de démosaïçage, inspiré des traitements effectués par le cerveau, dont le rôle est de reconstituer trois images correspondant aux trois filtres colorés R, G et B utilisés dans cette mosaïque. Ce sont ces trois images qui peuvent ensuite être projetées, à partir d’un écran d’affichage RGB, afin de visualiser l’image en couleur acquise, de la scène considérée.
Pour garantir une acquisition fidèle de ces images RGB, la disposition et les réponses spectrales des filtres utilisés dans la mosaïque peuvent être optimisées à la manière de
Par-mar et Reeves [81] ou de Sadeghipoor et al. [94], en minimisant la différence entre l’image
couleur qui serait perçue à partir des images RGB acquises par le système d’imagerie considéré et celle qui serait directement perçue par un observateur humain de référence.
Il existe plusieurs techniques pour déposer une mosaïque de filtres colorés sur un cap-teur d’image monochrome. Nous détaillons dans l’annexe A.1 une technique, dite de dépôt de filtres couches minces optiques, qui est une des compétences technologiques du labora-toire CEA-Leti. Cette dernière peut permettre de constituer une mosaïque de filtres non conventionnelle, comme nous le souhaitons.
Nous décrivons maintenant l’influence d’une mosaïque de filtres sur l’image acquise par un capteur monochrome.
![Fig 1.9: Résultats d’estimation 2D+Z obtenus avec la méthode de Guichard et al. [48]. Cette figure est empruntée à [48].](https://thumb-eu.123doks.com/thumbv2/123doknet/14558452.726283/28.892.273.616.280.542/fig-résultats-estimation-obtenus-méthode-guichard-figure-empruntée.webp)
![Fig 1.12: Schéma de principe d’un système plénoptique. Cette figure est empruntée à [71]](https://thumb-eu.123doks.com/thumbv2/123doknet/14558452.726283/31.892.272.632.777.1052/fig-schéma-principe-système-plénoptique-figure-empruntée.webp)