HAL Id: tel-01322692
https://halshs.archives-ouvertes.fr/tel-01322692
Submitted on 27 May 2016
HAL is a multi-disciplinary open access
archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
interprétation:Contribution à l’élaboration d’un modèle
informatique de la Sémantique Interprétative
Ludovic Tanguy
To cite this version:
Ludovic Tanguy. Traitement Automatique de la Langue Naturelle et interprétation:Contribution à l’élaboration d’un modèle informatique de la Sémantique Interprétative. Informatique et langage [cs.CL]. Université de Rennes 1, 1997. Français. �tel-01322692�
Mémoire présenté pour l’obtention d’un
Doctorat nouveau régime
Spécialité : informatique
Traitement Automatique de la Langue Naturelle et
interprétation : Contribution à l’élaboration d’un
modèle informatique de la Sémantique Interprétative
Ludovic Tanguy
Dirigé par Jean-Pierre Barthélémy
Encadré par Ioannis Kanellos
Soutenu le 7 Mai 1997 à
l’Ecole Nationale Supérieure des Télécommunication de Bretagne
Devant le jury composé de :
Président : Daniel Herman Professeur Univesité de Rennes 1 / IRISA
Rapporteur : Patrice Enjalbert Professeur Université de Caen
Rapporteur : François Rastier Directeur de Recherche CNRS / INaLF
Directeur : Jean-Pierre Barthélemy Professeur ENST de Bretagne
Encadrant : Ioannis Kanellos Maître de Conférences ENST de Bretagne
— Je remercie
Monsieur Daniel Herman pour avoir bien voulu accepter de présider le jury de cette thèse.
Monsieur Patrice Enjalbert et Monsieur François Rastier, les deux rap-porteurs de cette thèse, pour l’intérêt qu’ils ont tous deux manifesté à l’égard de mes travaux, ainsi que pour la pertinence de leurs remarques et de leurs conseils.
Monsieur Jean-Pierre Barthélemy pour avoir dirigé ces travaux. Qu’il reçoive ici ma reconnaissance pour la bienveillance et la bonne humeur dont il a agrémenté ces quelques années de recherche.
Monsieur Jacques Siroux pour m’avoir fait l’honneur de participer au jury,
— Je remercie particulièrement Monsieur Ioannis Kanellos, qui a encadré, guidé et éclairé mon parcours parfois sinueux. J’espère que cette thèse re-flétera fidèlement l’humilité et le respect de la difficulté inhérente des pro-blèmes liés à la formalisation de la langue qu’il a su, au cours de longues discussions, et de courtes altercations, m’inculquer.
— Je remercie également Madame Michèle Noailly, et toute l’équipe du sémi-naire Sémantique en contexte de l’Université de Bretagne Occidentale, pour m’avoir fait découvrir les nombreuses facettes de la linguistique, et m’avoir fait comprendre la relativité d’une formalisation face à une discipline qui laisse aussi place à la sensibilité.
— Je remercie chaleureusement Madame Monique Le Coz, et les membres du département Informatique de la Faculté des Lettres de l’Université de Bre-tagne Occidentale, pour la confiance et la sympathie qu’ils m’ont accordées, et les facilités d’organisation qu’ils m’ont permises pour terminer la rédac-tion de ce travail.
— Je remercie la joyeuse équipe du Département IASC de Télécom Bretagne, qu’ils soient enseignants, ex-membres, thésards, ex-thésards ou stagiaires. Je doute qu’un travail de thèse puisse se dérouler dans une ambiance plus franche et sympathique que celle qui y règne au quotidien.
— Je remercie mon ami Pierre pour son soutien sans faille, ses créations théâ-trales et les dimanches-après-midi-thé.
— Je remercie bien sûr tous mes collègues, amis, et ma famille pour avoir supporté les sautes d’humeur liées à ce travail.
— Je remercie enfin tous ceux qui prennent le temps de lire les remerciements que l’on trouve au début d’une thèse.
Résumé
Nous proposons dans cette thèse une modélisation informatique de la sémantique interprétative de F. Rastier. Après une première critique des traitements classiques du langage naturel sous ses aspects sémantiques, nous concluons à une non-réductibilité du sens d’un texte à une structure calculée à partir de descriptions locales, et à la nécessité de déterminations globales. Nous étudions ensuite la théorie linguistique de la sémantique interprétative, afin d’en retirer les concepts centraux captables par une approche informa-tique. Nous proposons un modèle formel de description de ceux-ci, ainsi que des mécanismes de manipulation des structures sémantiques descrip-tives. Enfin, nous proposons un logiciel appliquant cette formalisation, sous la forme d’une assistance à l’analyse des textes. Nous rejoignons une appoche de coopération homme-machine, en distinguant les activités interprétatives propres à l’utilisateur de leur manipulation formelle par la machine. Nous concluons par une mise en relief des avantages suggestifs et descriptifs d’une approche informatique de certains aspects de l’interprétation.
Abstract
This thesis proposes a computer model for F. Rastier’s interpretative semantics. After a criticism of classical natural language processing for se-mantics, we conclude that there is a need for a description that focuses on the impact of global determination on local descriptions. Through an analysis of the linguistic theory, we identify the main descriptive concepts and then pro-pose a formal description. This formalism consists of a number of semantic structures and operators to manipulate them in order to describe an inter-pretation process. We then propose a software system which applies these concepts, and provides a computer aid for the semantic analysis of texts. Ac-cording to a human-computer cooperation paradigm, we distinguish between human interpretative processes and their formal description for management by the machine. We conclude by an emphasis on the advantages of computer assistance for both suggestion and representation purposes.
1
Environnement
Cette thèse a été réalisée au sein du Laboratoire d’Intelligence Artificielle et Sciences Cognitives de l’École Nationale Supérieure des Télécommunica-tions de Bretagne, sous la direction de Jean-Pierre Barthélemy et l’encadre-ment de Ioannis Kanellos. Elle a bénéficié d’un financel’encadre-ment sous la forme d’une allocation de recherche du Ministère de la Recherche.
2
Cadre scientifique
Le travail présenté dans ce mémoire pourrait s’inscrire confortablement dans ce domaine interdisciplinaire qu’est le traitement de la langue naturelle, également appelé informatique linguistique (mais dont l’idéal de référence serait celui d’une linguistique informatique). Il rejoindrait ainsi nombre de travaux plus ou moins spécialisés tentant de modéliser le sens d’un énoncé en langue naturelle. Cependant, nous désirons revendiquer une approche dif-férente de cette problématique. Le problème du sens, sans doute le plus vertigineux de ceux rencontrés par l’homme, a souvent, à notre avis, été sous-estimé par les informaticiens et autres artificiers de l’intelligence, selon le terme consacré.
C’est dans ce cadre général de réflexion, concrétisé déjà par un petit en-semble de travaux, que nous nous situons. À partir d’une réflexion menée sur les concepts fondateurs de la représentation de connaissances en IA, et sur les notion d’identité dans un cadre formel général, nous proposons d’aborder ici, sous cet angle, le problème de la formalisation du sens dans le traitement de la langue naturelle. Le problème central restera celui de l’objectivité illu-soire du sens, telle qu’elle est affirmée ou sous-entendue par les approches formelles de l’informatique appliquée au langage. La subjectivité, elle, dé-clarée détestable car ennemie d’une simplification opératoire, n’a jamais, ou
presque, été abordée directement, respectée voire revendiquée.
Ces considérations générales, heureusement, entrent en résonance avec d’autres visions plus centrées sur le langage. La revendication de la centralité de l’individu dans les rapports à la langue transparaît dans certaines théories linguistiques, dont nous avons sélectionné la sémantique interprétative de F. Rastier.
Cette théorie nous a séduit par plusieurs aspects. Au-delà de forts louables déclarations d’intention, elle constitue en effet une avancée majeure dans la rationalisation des phénomènes de sens, sans pour autant considérer l’immanence de celui-ci. La notion d’interprétation, pilier central de cette approche, définit en effet le sens comme influencé par un ensemble de consi-dérations « extérieures » dont on ne peut guère décrire que l’incidence dans l’ordre linguistique. En ce sens, elle se rapproche des travaux de traitement automatique de la langue naturelle, où certains problèmes centraux du lan-gage sont résolus ad hoc par l’invocation subite d’un nébuleux « contexte ». Il s’agira ici de l’intention première, en reconnaissant que le sens se construit, et que l’environnement (au sens large) de l’acte d’interprétation prime.
Ces grands principes sont cependant coûteux pour une opérationnalité immédiate. Malgré un appel à des notions structuralistes rigoureuses, ne pourra être décrite qu’une possible interprétation d’un texte, et non une compréhension que certains voient idéalement comme absolue.
3
Principes de notre approche
Nous prenons en quelque sorte le relais de l’avancée théorique linguis-tique. Notre premier travail sera de préciser le rôle de la machine dans la prise en considération de ces principes généraux. Nous nous rapprocherons ainsi du paradigme récent de la coopération homme-machine anthropocen-trée, que l’on peut voir comme une alternative opératoire au vu des échecs des automatisations complètes issues du cognitivisme dogmatique. Il s’agira, parallèlement de cerner la zone d’immodélisabilité des activités humaines, et de la respecter. L’ordinateur, en abandonnant son autonomie illusoire, de-vient alors un assistant, doté de qualités qu’il faudra aussi reconnaître : sa capacité de calcul, qui ne doit pas prépondérer, sa faculté de représentation et sa possibilité de gérer certains ordres logiques, et de veiller sur certains aspects de sa cohérence.
Dans un second temps, nous devrons analyser plus en détail les aspects conceptuels de la théorie linguistique, en traçant, ici aussi, des limites entre le formalisable et l’inaccessible pour la machine. Nous nous permettrons dans
certains cas de prendre parti, et de modifier en toute conscience certains as-pects, mais respectant la cohérence de l’ensemble de la vision interprétative. Il sera alors temps de réfléchir aux modalités de cette fameuse coopération homme / machine dans cette situation précise d’un utilisateur interprétant un texte. Le rôle principal de la machine sera alors celui d’une motivation à la rationalisation. Sans réfuter une traduction par trop formelle des concepts linguistiques dégagés, nous les revendiquerons comme garants d’une cohé-rence globale de l’interprétation. Cherchant à obtenir une identité formelle des unités sémantiques, le logiciel que nous proposerons permettra ainsi un « dialogue » avec l’interprète, il l’aidera dans la construction d’une nouvelle forme de discursivité mise au profit de l’analyse. L’interprète se verra sollicité tout au long de son acte d’attribution de sens.
Nous proposons ainsi un prototype d’interface homme / machine destiné à une assistance au cours d’une analyse de texte. Nous l’avons baptisé PAS-TEL (approximativement pour Programme d’Aide à l’Analyse de TExtes, même Littéraires).
Par moments fastidieuse, par d’autres sources de suggestions, cette nou-velle relation entre l’homme et la machine possède deux aspects techniques intéressants.
Le premier est l’absence d’utilisation de données linguistiques générales : la seule connaissance de la langue mise en place dans l’utilisation du logiciel proviendra de l’utilisateur. Celui-ci pourra donc en toute liberté utiliser les descripteurs sémantiques (également exprimés en langage « naturel ») pour traduire son interprétation, et ne sera pas contraint par des formes figées de la langue, ni limité dans son application à un domaine sémantique particulier. D’un autre côté, il pourra effectivement « dire n’importe quoi », mais le second point l’en dissuadera.
Effectivement, en contrepartie de cette souplesse d’expression, le logiciel mettra en place une structure de données, s’appuyant aveuglément sur les données descriptives que l’utilisateur lui communique, pour organiser formel-lement le résultat de l’interprétation. Un ensemble de contraintes formelles à ce sujet seront autant de requêtes d’éclaircissement qu’il transmettra à l’uti-lisateur. Ce qui mettra à rude épreuve une vision fantaisiste d’un texte, qu’il faudra justifier plus loin que la simple énonciation de thèmes généraux. En quelque sorte, la vision première de l’utilisateur / interprète sera explorée plus profondément peut-être qu’il ne l’aurait fait seul, et peut mener à des découvertes d’un nouvel aspect sémantique du texte analysé.
4
Plan du mémoire
Notre présentation se déroulera en cinq chapitres, dont le contenu général sera le suivant :
1. Premier chapitre, à forte teneur introductive, dans lequel nous pla-çons notre approche au sein du traitement de la langue naturelle, en y dégageant quelques principes directeurs. À travers une critique des systèmes existants, pour lesquels la syntaxe joue un rôle cen-tral, nous précisons les besoins d’un affranchissement des considéra-tions que celle-ci véhicule (principe de compositionnalité, limite de la phrase, etc.). Dans un deuxième temps, toujours en prenant appui sur des travaux en TALN, nous précisons les limites de la considé-ration du sens comme information, et de la sémantique référentielle, pour justifier le recours au paradigme différentiel, en développant la notion de situation du sens, et la pertinence de la notion d’interpré-tation. Enfin, nous discutons des approches récentes dans le domaine de la coopération homme/machine, précisant l’orientation de notre approche vers l’assistance et non l’automatisation, en redonnant à la machine un rôle de suggestion et non de décision.
2. Second chapitre, consacré à l’étude de la sémantique interprétative comme fondement théorique du modèle présenté par la suite. Après une description des grands principes de la théorie, nous passons en revue les aspects plus formels de celle-ci (notions de sème, sémème, taxème, isotopie, etc.), en précisant leur utilisation, leur remaniement ou leur rejet, en fonction de l’application informatique.
3. Chapitre plus formel, où nous décrivons la structure de données décri-vant le résultat d’une interprétation d’un texte, en reprenant les prin-cipes et considérations dégagés au chapitre précédent. Cette structure est ici décrite de façon statique, comme finalité de l’acte d’interpréta-tion, et comporte un ensemble de contraintes quant à l’organisation structurelle des différentes entités sémantiques
4. Dans le même esprit que le chapitre précédent, nous y décrivons la structure sous son aspect dynamique, en établissant notamment un « protocole » d’interprétation, ou mise en place de la structure. Nous prenons soin d’y détacher les étapes automatiques des nécessaires (et nombreux) recours à la compétence humaine. Nous y insistons éga-lement sur l’aspect positif des contraintes précédemment évoquées comme source de suggestion et de créativité. Y sont également pro-posées quelques transformations générales de la structure, afin de
per-mettre la cohésion de celle-ci avec des contraintes externes, ou comme source possible de l’approfondissement d’une interprétation.
5. Dernier chapitre, décrivant les aspects informatiques de la thèse, no-tamment la transcription de la structure formelle, l’organisation gé-nérale du logiciel proposé, et de l’interface graphique qui le rend uti-lisable et convivial. Le principe général de cet outil informatique est d’accompagner l’utilisateur dans la description de son interprétation d’un texte par repérage de sèmes. Il n’est pas fait appel à des bases de données stables, l’utilisateur ayant toute liberté (et donc néces-sité) d’attribuer les sèmes qui lui semblent pertinents aux éléments du texte qu’il désire prendre en compte. Les contraintes précédem-ment citées ont donc deux rôles : garantir autant que faire se peut la cohérence de l’interprétation, en garantissant l’identité sémantique de chaque signifié, mais également, inciter l’utilisateur a expliciter au maximum son interprétation, par un jeu de questions-réponses, une réponse étant ici le repérage d’un sème et son attribution a un signifié. Le travail présenté ici a donné lieu à quelques publications : [26], [27], [59].
Problématique au sein du
Traitement Automatique de la
Langue Naturelle
1
Introduction
Dans ce premier chapitre, nous tenterons de définir nos objectifs, ainsi que les principes qui les sous-tendent.
Nous nous intéresserons particulièrement au traitement de la sémantique du langage naturel. Les principes que nous revendiquons sont les suivants :
- Tout d’abord, nous reconnaîtrons la primauté de la sémantique dans le langage, dont le traitement doit ainsi se dégager des spécificités des méthodes appliquées à la syntaxe. À ce sujet, nous envisagerons les distinctions entre syntaxe formelle et syntaxe linguistique. Nous récuserons ainsi les tentatives de manipulation / définition du sens à travers une analyse, si fine soit-elle, des phénomènes de surface du langage, qui correspond à une vision empruntée aux systèmes formels de l’articulation sémantique/syntaxe. Le principe de compositionnalité qui y est supposé devra également être explicité et rejeté dans le cadre de la sémantique. De plus, nous accorderons un statut premier au texte, et non à la phrase, dont le régime, du point de vue logique, est celui de la limite supérieure de l’application des méthodes syntaxiques (ce qui n’a plus lieu d’être si l’on aborde la sémantique, où au contraire c’est le texte (et le contexte) qui prime(nt)).
- Ensuite, nous nous placerons dans une position interprétative. Tout d’abord, nous accuserons les assimilations entre compétences interprétative et générative, en explicitant leur origine dans une vision restrictive du
gage comme vecteur d’information. Voulant aborder le sens d’un énoncé lin-guistique comme éminemment situé, et donc dépendant des conditions de communication et des intentions de son destinataire, nous récuserons la sy-métrie précédente et nous nous dirigerons ainsi vers une vision différentielle de la sémantique. Cette prise de position dans le structuralisme nous per-mettra de nous interroger sur l’identité des unités sémantiques, qui devra être construite et structurée et non simplement vue comme le résultat d’un décodage.
- Enfin, nous expliciterons plus en détail le rôle que nous assignons à l’outil informatique dans le cadre du traitement de la langue naturelle. Au vu des précédentes constatations, nous préciserons notre passage d’une auto-matisation impensable, puisque seul l’humain peut supporter les notions de l’interprétation, à une assistance et une source de suggestions. Après avoir explicité les conditions de cette coopération entre l’homme et la machine, nous discuterons également des types d’applications envisageables (et envi-sagées), tant du point de vue de la méthode que du domaine linguistique.
2
Place de la syntaxe dans le TALN
1À partir de la prédominance constatée de la syntaxe dans les applica-tions du TALN, alors que tout le monde reconnaît le sens comme objectif, il faut bien se poser la question de sa nature et de son rôle dans l’approche du sens. De plus, la syntaxe telle qu’elle est définie pour les systèmes de traitement de la langue (systèmes informatisés donc formels) est-elle bien celle dont on parle dans des considérations plus centralement linguistiques ? Nous tenterons donc de dégager les tenants et les aboutissants de la profusion d’applications centralement syntaxiques dans le TALN, et comparer ceux-ci avec nos objectifs et prises de position.
2.1 Prédominance de la syntaxe dans le TALN
Revenons quelques temps sur les tentatives initiales en traduction au-tomatique, telles qu’elles fleurirent après la dernière guerre, motivées par la volonté américaine de traduire automatiquement les messages russes. Les productions en ce sens, avant d’être déclarées inutilisables par la comité AL-PAC3 en 1965, s’appuyaient essentiellement sur l’utilisation de
correspon-1. TALN est un AQL2 pour Traitement Automatique du Langage Naturel. 2. Acronyme de Quatre Lettres.
3. Automatic Language Processing Advisory Committee, dont l’initiative a vu le jour en 1952.
dances mot-à-mot. Les traditions sous-jacentes à l’époque provenaient plus de la cryptographie (dont le succès dans son traitement informatique était validé) que de la linguistique véritable.
À partir de là, deux programmes majeurs furent envisagés au vu des échecs : affiner l’analyse syntaxique ou apporter des connaissances générales au système. On peut citer par exemple Weaver, reconnaissant que le «déco-dage du russe vers l’anglais» [66] est plus complexe qu’une simple correspon-dance, et Bar-Hillel [3], qui reconnaît le besoin de connaissances sur le monde, et non plus sur la langue (lexique et grammaire) pour parvenir à une traduc-tion acceptable. S’affirment donc deux programmes : le premier vise l’affi-nement syntaxique (comme affil’affi-nement/complexification de la structure) ; le second concerne le mode de coordination du thème de la connaissance avec l’objet linguistique.
Pour l’instant, nous étudierons la première possibilité : développement des méthodes d’analyse morphologique (dictionnaire de formes simples et règles de composition des mots, cela dès les premières tentatives de tra-duction, pour diminuer la place en mémoire des dictionnaires), et surtout syntaxique, afin de déterminer la structure de la phrase, et atteindre ainsi une meilleure compréhension, donc traduction. Dans le cas de la traduction, cela suppose toujours une correspondance, non plus au niveau du mot, mais au moins au niveau du syntagme et de la proposition.
Ceci se traduit également par le développement de formalismes syn-taxiques originaux, à partir des simples grammaires syntagmatiques, en cher-chant à atteindre un taux de couverture maximal des phrases correctes ana-lysées. À ce propos nous ne pouvons bien entendu pas nous affranchir de citer les travaux de Chomsky [11, 12], et leur abondante tradition critique qui a nourri presque toute la recherche en TALN, qui s’inscrivent pleine-ment dans cette vision du sens (structure profonde) accessible par la forme (structure de surface). Nous ne nous lancerons pas dans une critique maintes fois proposée, mais reconnaîtrons simplement que la théorie de la grammaire transformationnelle constitue l’approfondissement le plus notable de cette vision générale.
Ces formalismes ne furent pas utilisés exclusivement à des fins de tra-ducteurs automatiques. Une grande majorité d’outils de TALN utilisent un analyseur morpho-syntaxique ou parser. Que ces outils servent à l’interro-gation de bases de données en langage naturel, à la production de résumé ou l’indexation de documents, en bref des outils qui visent à une certaine forme de compréhension de la langue, ils passent presque toujours par une phase purement syntaxique. C. Fuchs [19] reconnaît à la syntaxe un statut de nécessité pour la généralité de l’outil, dans le sens de la variété des
énon-cés que celui-ci traite. À travers des domaines variés, de la météorologie à la classification des bateaux [24], en passant par la simulation de dialogues psy-chanalytiques [68] (de nombreux ouvrages discutent de ces différents outils, notamment [4], [15], [55]), la constante serait donc la structure syntaxique, sorte de substrat originel de la langue. D’ailleurs cette primauté doit être remise en question, dans la mesure où elle contredit des données établies en psychologie expérimentale. On peut en effet établir facilement l’accès de l’en-fant à la langue par la sémantique, et l’apparition tardive d’une compétence syntaxique (voir à ce propos les travaux de J. Piaget [45]). Parle-t-on alors de la même syntaxe dans les deux cas ?
2.2 Syntaxe linguistique et syntaxe formelle
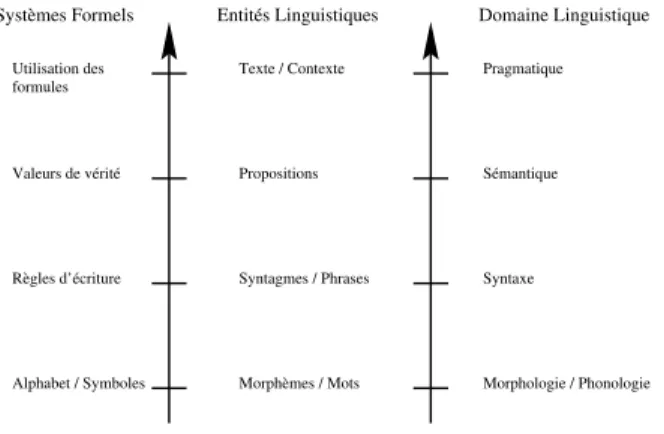
Nous nous interrogerons ici sur la séparation syntaxe / sémantique telle qu’elle est définie dans les systèmes formels. Cette distinction, entièrement justifiable dans un rôle formalisateur très général en logique, semble impli-quer une projection directe dans la langue, renforcée par d’autres analogies (morphologique et pragmatique), comme indiqué par la figure 1.1, alors que la syntaxe de la langue n’est pas indépendante. En témoignent déjà les tra-vaux de Benvéniste [6, 7] et sa reconnaissance du fait que le sens de la phrase influe sur le sens des mots. Pour résumer son raisonnement, disons que ce sont les rapports forme / sens qui traduisent ces notions de composition. La forme d’une entité est sa composition en entités inférieures et son sens est fonction de sa place dans une entité supérieure. Ainsi, la forme de la phrase ne peut être la suite des mots qui la composent, car le sens de ces mots dépend de celui de la phrase, et elle n’a pas de sens puisqu’elle ne rentre pas dans la composition logique (propositionnelle) d’une autre entité, étant elle-même une proposition.
Ceci récuserait donc le principe de compositionnalité du sens, qui posait déjà des problèmes à Frege (cf. son article Sens et dénotation dans [18]), et a motivé l’arrivée des logiques intensionnelles. De ces problèmes que pose la compositionnalité, nous retiendrons également la centrale question de l’iden-tité des unités sémantiques, dont nous parlerons plus loin, en discutant de l’approche différentielle. La possibilité ou impossibilité de substituer des uni-tés linguistiques d’un contexte à l’autre présuppose en effet une identité de ces unités au travers de leurs diverses utilisations : il s’agit d’une identité de forme, mais que dire alors de la polysémie ? La notion d’identité séman-tique devra donc être considérée avec attention, et devra sans doute être construite et non présupposée. Nous verrons plus loin la nécessité de la consi-dérer comme construite par le sujet qui traite l’énoncé, en y intégrant des
Alphabet / Symboles Règles d’écriture
Systèmes Formels Entités Linguistiques Domaine Linguistique
Utilisation des formules Valeurs de vérité Texte / Contexte Propositions Syntagmes / Phrases Morphèmes / Mots Pragmatique Sémantique Syntaxe Morphologie / Phonologie
Figure 1.1 – Systèmes formels et niveaux linguistiques traditionnels
données externes, relatives à la situation de ce traitement.
Même dans l’hypothèse d’une influence mutuelle des différents sens des mots dans la phrase, on serait conduit à une complexité exponentielle (au sens technique du terme, il s’agit d’un problème NP-complet), qui de toute façon supposerait une connaissance absolue des significations et emplois pos-sibles pour chaque élément.
Si la syntaxe possède cette vertu compositionnelle, si toute phrase isolée peut être analysée de façon grammaticale, alors le sens ne peut s’y réduire, il fait entrer en jeu des considérations qui dépassent au moins la limite de la phrase : d’où la nécessité d’un recours au contexte, et ce contexte est plus qu’une phrase, voire quelques phrases.
À ce propos, la notion de contexte a récemment connu une poussée pro-ductive. Mais les récentes interrogations formalistes sur le contexte (voir par exemple [10] et [71]) ne traduisent pas autre chose. La constante mise en situation ou contexte de l’unité linguistique (constante quelle que soit la na-ture de cette unité) ne peut qu’infléchir les développements dans la recherche d’une description formelle de ce contexte. Cependant, le contexte est plus que cela, il est plus qu’une fonction de choix des sens possibles, plus que la trace d’une heuristique sémantique (comme il est souvent invoqué dans certaines approches du TALN, comme [8]). C’est un moment essentiel dans la consti-tution de l’objet linguistique : il ne vient ni après ni avant mais en même temps que lui.
2.3 La syntaxe pour la sémantique
L’articulation entre syntaxe et sémantique, projetée dans le monde du TALN, se traduit de différentes façons. Il y a tout d’abord le schéma sou-vent invoqué d’un traitement séquentiel de l’information langagière, à l’aide de différents modules spécialisés, dans l’ordre : module morphologique (re-connaissance des mots), module syntaxique (identification des syntagmes et des structures de phrases), module sémantique (modélisation du contenu des mots et de la phrase), et module pragmatique (utilisation des données sé-mantiques, en fonction du type d’application : traduction, réponse à une question, inférences, etc.) Un système répondant à ce schéma central est par exemple le célèbre SHRDLU de Winograd [69] qui manipule un robot à par-tir d’ordres énoncés en anglais, ou le LUNAR de Woods [70] qui traduit les questions en requêtes pour une base de données.
Même si la syntaxe s’analyse correctement, ne laissant subsister que quelques ambiguïtés, le travail du traitement sémantique sensé la suivre n’est jamais résolu correctement (en tout cas, sûrement pas dans le cas d’une géné-ralité d’énoncé que l’analyse syntaxique est sensée mettre à sa portée). Ceci orienta donc la recherche vers le développement de formalismes «mixtes», comme la LFG (Lexical Functional Grammar) [1], où les notions séman-tiques, traduites par des formules logiques, sont intégrées directement dans le traitement syntaxique. On voit également des tentatives d’ajouter des considérations sémantiques à des formalismes d’analyse syntaxique, comme le propose A. Abeillé pour les TAGs4 dans [52].
Mais il faut aussi noter le développement de formalismes purement sé-mantiques, pour attaquer à nouveau le problème. Ces formalismes rejoignent ainsi des considérations plus générales sur la représentation de connaissances, mais on y retrouve toujours une prédominance des principes fondamentaux de la syntaxe, à savoir la notion de calcul et de compositionnalité. Cette fois, des notions sémantiques sont calculées, mais toujours à partir de don-nées locales attribuées aux mots, même si elles sont bien plus riches que de simples catégories grammaticales. Notons également, mais nous y revien-drons par la suite, les présuppositions que traduit la pluralité d’utilisation de ces formalismes. Leur classicisme en IA, et dans le domaine de la repré-sentation de connaissances induit une prise de position sur le langage, dont il faut prendre conscience. Il s’agit bien de formalismes de représentation de connaissances, pas de représentation de sens. Leur utilisation est compréhen-sible lors de l’application à un système classique de l’IA, comme la résolution de problèmes ou la réponse à des questions sur une base de données (ou base
de connaissances), mais dans un cas général de représentation du sens, la prudence est de mise, d’autant plus que la notion même de connaissance reste opaque. Dans un cadre applicatif, comme celui de l’IA, la notion de connaissance est liée à celle de représentation, et une telle assimilation des deux réalités pose donc le problème de la représentativité du sens, dont nous discuterons par la suite.
Il faut également noter la (ré-)apparition de méthodes d’analyses de cor-pus s’inspirant du paradigme distributionnaliste [23], mettant en œuvre une approche sans aprioris de la sémantique basée sur des considérations de sur-face, mais purement empiriques et statistiques. Il faut y voir ici un autre moyen de signifier, voire d’affirmer l’accessibilité du sens par l’analyse de la surface. La seule notion extérieure à la restriction empirique des données traitées vient ici de la reconnaissance de l’unité du corpus (comptes-rendus d’actes médicaux comme dans [22]) : le principe de compositionnalité, s’il n’est pas directement exploité, n’en reste pas moins présent. Il est cependant important de noter la diminution de la complexité des relations syntaxiques (au sens large) utilisées : ne subsistent plus que des considérations d’identité de forme, de différence, et de proximité. Nul besoin en effet pour classifier des formes linguistiques, de les articuler autour de notions grammaticales complexes (et d’ailleurs inapplicables dans le cas de corpus importants) : la complexité ici provient justement du nombre. Nous nous permettrons d’y voir ici un argument pour la reconnaissance de la sémantique, par une di-minution de la complexité de la modélisation syntaxique. De plus, et nous y reviendrons à la fin de ce chapitre, ces méthodes ne produisent que des pro-positions quant à la nature du sémantique, en ce sens qu’elle laissent, pour l’affirmation de phénomènes liés aux corpus analysés, la conclusion finale à l’homme qui va interpréter ces données statistiques.
2.4 Premier principe
Le problème du sens demande à être abordé directement et prioritaire-ment. La rupture épistémologique doit être ici de la même taille que celle proposée par le «tout syntaxique» de Chomsky. Ce qui veut dire qu’il s’agit de négliger la syntaxe dans un premier temps, et de reconnaître la primauté de la sémantique. Cela permet au moins de s’affranchir des principes inhé-rents à la syntaxe, dont nous avons discuté l’inappropriation précédemment. Renier le principe de compositionnalité revient également à rejoindre Benvéniste (Les niveaux de l’analyse linguistique, [6], p. 119s) pour consi-dérer la phrase comme limite, mais non plus de la linguistique, mais de la syntaxe. Dès lors l’objet de la sémantique devient au moins un objet
supé-rieur à la phrase, sans refuser les paliers infésupé-rieurs. Il doit être un tout, pour supporter des considérations globales, qui influenceront ses éléments, et non l’inverse. Cet objet primordial est le texte, seule entité également susceptible de situation (cf infra).
Deux questions se posent alors : tout d’abord, existe-t-il une possibilité de représenter formellement suivant ce principe des données sémantiques ? Et si oui, quels seront les rapports d’un tel traitement avec la réalité informatique ?
3
De la nature du formalisme sémantique
Nous discuterons ici plus centralement de la sémantique. À partir d’une constatation de la possibilité de confusion entre les deux pôles de manipula-tion du sens dans le TALN (généramanipula-tion et compréhension), nous discuterons des restrictions qu’entraîne une vision référentielle et/ou informationnelle de la langue. À la suite de quoi nous plaiderons en faveur d’un paradigme différentiel.
3.1 Langage et information
On peut dans un premier temps repérer deux faces générales intéressant le sens : la génération et la compréhension. Leur comparaison offre dès lors la possibilité d’en envisager la symétrie. Si cette symétrie est reconnue, quelles hypothèses implique-t-elle sur la nature de la langue, et quelles influences sur son traitement ? Si ces deux aspects transparaissent dans les plus ambitieuses des applications envisageables, traduction et dialogue homme/machine, cette situation doit-elle impliquer une symétrie ?
Si nous reprenons un schéma simple d’une situation de communication, tel qu’il est utilisé pour représenter un transfert d’information, on retrouve trois entités principales : le destinateur, producteur du message, le destina-taire, et le message proprement dit. Les rapports entretenus par les deux participants avec le message sont alors de même nature : un passage du cog-nitif (ou conceptuel, bref du non-linguistique) au linguistique, et vice-versa. Pour reprendre un pied volontaire dans la théorie de l’information, ce sont des opérations d’encodage et de décodage, l’outil linguistique, manifesté par le message, est donc un simple vecteur de transmission de cette information. Lorsque Jakobson [25] envisage les fonctions du langage, il reprend comme base ce schéma simple et général, pour le compléter comme nous verrons par la suite.
Si ces supposées fonctions d’encodage / décodage ne sont pas réversibles, elles n’en gardent pas moins une nature similaire, reposant sur l’opposition
entre linguistique et non-linguistique. Le sens premier d’un énoncé est en effet vu comme une représentation mentale initiale, devant être reconstituée par le destinataire lors de l’acte de communication, et introduit par ce biais une qualification de la communication, comme transfert accompli ou échoué de ce contenu informationnel, en supposant une comparaison des deux structures de représentation. La reconstitution en question est, en effet, une reconstruc-tion ; on recherche ainsi toujours la même chose : l’identité entre le modèle et sa reconstitution. Tout le comprendre devient une sorte de quête d’identité, et toute la génération un problème dont la solution repose sur la possibilité de sa réversibilité.
Mais surtout, cette vision simpliste, mais sans doute insidieuse subor-donne la linguistique à une description de ces structures (que nous pouvons appeler cognitives) encodées. Outre le fait que de telles structures ne sont pour l’instant pas traitées ni modélisées de façon satisfaisante, cela n’amé-liore pas la situation de la linguistique, dont Saussure [56] énonçait comme premier objectif de se définir elle-même. P. Siblot [57] rappelle ceci à juste titre, en considérant les rapports de la linguistique avec ces disciplines re-connues comme connexes, et parfois hiérarchisées que sont la psychologie, la philosophie, et parfois même la physique.
Certes, une vision ainsi simplifiée à l’extrême ne trouve plus beaucoup d’adeptes, surtout après une telle caricature, mais nous verrons que certaines assertions plus complexes peuvent trouver un écho dans cette constatation, et nous enfermer dans une vision restrictive de la notion de sens d’un énoncé linguistique.
C’est d’ailleurs en suivant cette vision que les formalismes classiques de représentation de connaissances en IA ont trouvé leur place dans le TALN. Moults réseaux sémantiques [9] [13], Frames [41] et graphes conceptuels [58] servirent de support aux fameux modules sémantiques des systèmes de TALN à l’architecture classique. L’activation de ces structures, initialement envisa-gées pour modéliser la mémoire, et justifiés (ou anéantis) par des expérimen-tations en psychologie, résulte alors d’un appauvrissement considérable du contenu linguistique, afin de n’en retenir que quelques concepts pré-définis et articulés par des relations pour le moins ambiguës (la plus célèbre étant le is-a des réseaux sémantiques). Ce point de rencontre, s’il rejoint la prise de position de Bar-Hillel, à laquelle s’opposait en quelque sorte le programme chomskien, n’a pas non plus arrangé les affaires d’identité de la science du langage par rapport à la psychologie5.
5. Et l’inverse non plus, les modèles hiérarchiques de représentation de connaissances, et autres modèles de la typicalité [32] s’étant vu accusés de n’utiliser comme validation
3.2 Sens situé et interprétation
Reprenons alors les fonctions de Jakobson dans leur totalité. Les trois pre-mières concernaient les deux protagonistes de l’acte communicatoire, et le «monde», par la fonction référentielle. Il y ajouta ainsi des fonctions mettant en jeu des relations sociales entre les communicants, et des considérations sur le message lui-même ou le «code» employé. Autant de considérations qui laissent transparaître que l’acte de communication est en partie défini par un entourage régi par des systématicités variées, et que le seul message isolé de celui-ci, considéré comme il peut l’être dans les technologies de télécom-munications, ne suffit plus.
Dès lors, si l’on considère comme importante cette notion de situation, la dualité linguistique / conceptuelle se complexifie d’autant plus, et la belle symétrie initiale se ternit. Ainsi, la notion de compréhension doit s’abstenir d’un simple décodage qui peut ou ne peut pas être «efficace», au vu de ces données complexes. La notion d’efficacité est assurément préjudiciable à l’intérieur de la compréhension. Outre le fait qu’elle traduit une volonté de quantifier le comprendre, elle témoigne d’un attachement au test de Turing [62] qui tente de définir les approches sous le régime du succès. Or, déjà, la notion même de succès est une inférence interprétative, et peut supporter différentes définitions. Elle ramène par ailleurs le vieux mirage béhavioriste à un moment fondamental de la constitution de l’objet linguistique.
La sélection des données «externes» et «internes» au message, et leur intégration dans la signification sous-entend un rôle actif de la part du ré-cepteur. Comme le développe F. Rastier [53], une grande part de créativité lui revient, puisque l’acte de comprendre peut également faire intervenir des données qui lui sont propres ; on parle alors d’interprétation. Son résultat n’est pas moins quantifiable (réussite / échec) que la compréhension, mais sa description peut plus aisément intégrer une notion de cohérence, plus per-tinente sans doute que celle de réussite. La notion de performance ne nous informe pas plus sur une prétendue compétence que sur ses propres critères définitoires. Mais surtout, la notion d’interprétation permet d’expliquer la multiplicité des «codes» applicables au langage : à chacun correspond une nature d’éléments extérieurs à la réalité du texte, ou à sa propre structu-ration. De la notion de norme linguistique aux présupposés et objectifs de l’interprétation, en passant par les aspects historiques des interprétations «traditionnelles» du texte, un grand nombre de facteurs interviennent, ou du moins sont susceptibles d’être pris en compte. D’une théorie de l’inter-prétation on ne peut bien sûr pas exiger une explicitation exhaustive de
ces aspects, mais du moins on peut en espérer une porte ouverte vers leur respect, qu’une vision référentielle exclusive rejetterait par principe.
3.3 L’autre sémantique
La constatation précédente implique donc un choix épistémologique sur le type de sémantique à prendre en compte. La notion classique de contenu d’un énoncé linguistique répond au paradigme de la sémantique référentielle (ou dénotationnelle), résultant bien souvent de l’isolement du signe. Une alternative est donc la sémantique différentielle, principe structuraliste inté-grant le signe dans un système, et lui conférant une valeur en fonction de ses relations avec d’autres signes. La notion de contenu référentiel est donc subordonnée à ces relations, et peut même, pour des raisons d’assainissement théorique, être éludée. La vision différentielle est l’assise d’un méta-langage de description de l’objet linguistique (le texte) : elle n’annonce pas un re-tour à un structuralisme désuet, mais la mise en relief du caractère central des relations d’identité et de différence dans la description de l’ordre séman-tique. Ce thème critique de la textualité ne peut en effet trouver d’appui à l’intérieur d’une vision structuraliste standard.
Ainsi, sur la base de ces relations formalisables entre signes (en étudiant les rapports entre les signifiants et entre les signifiés), la notion d’interpré-tation peut être développée, comme méthode de construction de l’identité sémantique. Le rôle d’une entité sémantique est en effet à définir pour chaque texte et chaque situation. La théorie de l’interprétation que nous exploiterons par la suite et répondant, comme on s’en doute, à ces critères structuralistes, ne nous informera pas sur la formation du sens à proprement parler, mais se voudra une rationalisation d’un effet différenciateur d’une entité séman-tique. Elle nous permettra d’expliciter ce qui fait un sens pour un texte et un interprète dans un contexte....
Certes, la part de description formelle ne sera pas éludée de notre ap-proche, pour la simple raison du besoin d’une opérationnalité minimale. Simplement, en nous ramenant à des outils descriptifs simplifiés, l’impact du choix de la méthode formelle est réduit : si c’est bien une syntaxe dont il s’agira, elle ne nous conduira pas à l’apparition de structures présuppo-sées classiques. Sur le substrat de ces fonctionnalités simples, le concept de créativité pourra se développer avec moins de contraintes.
3.4 Deuxième principe
Grâce à ce paradigme différentiel, capable de décrire par des relations simples (et donc formalisables et implémentables) une identité sémantique, il est possible de redonner à l’interprète sa spécificité situationnelle. La volonté de ne pas se limiter à un contenu informationnel du sens suppose en effet une souplesse dans les outils de description, d’où une nécessité de se ramener à des concepts fondamentaux dans l’organisation des unités locales.
De plus, à l’aide d’une description non préalablement figée des unités linguistiques, il est envisageable de permettre l’activation de descripteurs locaux (attribués à des entités réduites, comme les mots et expressions) en fonction de données globales. La base d’apriori, présente habituellement dans la description classique des unités locales, serait alors située au niveau du texte et de son environnement, tel que ceux-ci sont appréhendés par l’inter-prète. La notion de calcul, fondatrice de l’outil informatique devra donc être repensée dans l’impact de ces données textuelles sur les entités locales.
4
Le texte, l’homme et la machine
Comment concilier les principes précédemment définis avec la notion d’automatisation, ou du moins d’informatisation ? Cela semble impossible : on exige ici une trop grande place accordée a l’homme pour envisager un rap-port «classique». Il faut donc redéfinir ces relations, et surtout trouver une nouvelle place pour la notion de calcul de la machine. Cette dernière notion de calcul, la seule supportée par l’ordinateur, implique donc un mode de fonc-tionnement strictement compositionnel, exclusivement adapté à la formalité logique. On est donc devant une apparente contradiction : il faut utiliser une plate-forme compositionnelle pour mettre en application une théorie qui récuse la compositionnalité. La conciliation ne peut donc se faire que par le déplacement de cette compositionnalité, dans les rapports de l’homme à sa machine.
Le problème existe pour d’autres disciplines que le TALN. Nous tâche-rons d’en tirer un enseignement et de proposer un rapport entre la machine et l’acte interprétatif. Nous envisagerons à la suite de cela les portes applica-tives qui se ferment, et celles qui s’ouvrent, en proposant de nouveaux types d’outils.
4.1 Coopération Homme / Machine
Avec la chute du paradigme cognitiviste premier, dont l’apogée prag-matique (ou plutôt applicative) fut atteinte avec les systèmes experts, et l’insuffisance de leur puissance inférentielle pour la modélisation d’un com-portement cognitif simple, d’autres aspects de l’outil informatique furent pris en compte. La modélisation complète et fidèle de la cognition devrait en ef-fet être abandonnée, au profit d’une véritable collaboration, en reconnaissant l’irréductibilité des activités mentales à un calcul symbolique (ni même sub-symbolique). C’est en ce sens que Y.-M. Visetti [65] commente le passage des systèmes experts aux systèmes à base de connaissances, première amorce de ce mouvement vers la coopération. Se situant à un niveau plus général que le nôtre (du point de vue des domaines d’application), il reconnaît les nui-sances d’une préconception logique majoritaire, dont les contraintes dans les systèmes dits cognitifs bloquent la communication entre la machine et son utilisateur. Ainsi, en restreignant la place de structures logiques complexes et par trop figées, et en accordant une priorité à la coopération plutôt qu’à une automatisation utopique, il trace les grandes lignes d’un nouveau type d’outil. Ce dernier, qu’il nomme «système interactif d’aide à la modélisation et à la validation des raisonnements» doit abandonner l’exigence de l’autono-mie. En réduisant la complexité et l’importance de la formalisation logique, il limite l’application de celle-ci à certaines parties restreintes d’un processus de raisonnement. Pour cet aspect, il faut entendre simplement une économie cognitive de l’utilisateur, exigeant par là même de celui-ci une connaissance suffisante du domaine et des limites même de ce type de coopération.
Mais d’un autre côté, en appliquant une rigueur logique (qui d’après l’auteur ne peut guère provenir de logiques non-standard, d’où une position affirmée dans la logique du premier ordre), il est envisageable de prendre en compte certaines suggestions de la part de l’automatisation comme Y.-M. Visetti l’énonce dans l’élégante analogie suivante :
Ils ont donc le statut ambigu d’oracles : qu’on prenne ou non le parti de les suivre, ce n’est pas d’eux que l’on attend véri-tablement un développement de la rationalité des organisations [...]
Concrètement, ces approches nécessitent une moins grande complexité technique (dans l’appareil logique), et une plus grande souplesse aussi, ainsi que la possibilité de rejeter l’adéquation de la représentation formelle avec une réalité intangible des structures cognitives supposées.
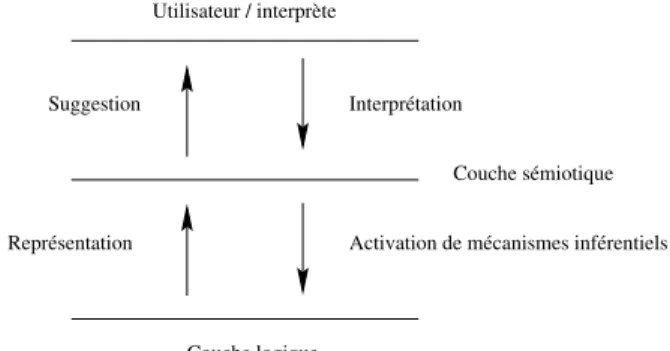
Schématiquement, et donc idéalement, un tel outil comporterait deux couches principales, auxquelles s’ajouterait bien entendu l’utilisateur si
cen-tral. Une première couche logique, support des représentations internes, d’une complexité réduite, et véhicule de rigueur et de robustesse. Une couche sémiotique, sorte d’intermédiaire, où se projettent les actions et conceptions humaines, qui doit donc être porteuse de grande souplesse, et d’interaction forte avec l’utilisateur. Une proposition de schéma est visible dans la figure 1.2.
Utilisateur / interprète
Couche sémiotique
Couche logique
Suggestion Interprétation
Activation de mécanismes inférentiels Représentation
Figure 1.2 – Organisation d’un système interactif
Mais cette structure des couches logiques et sémiotiques ne peut se conce-voir que sous une thématisation de la composante humaine. Elle doit être recherchée à tous les niveaux et à toutes les périodes de la constitution d’un tel outil. La couche sémiotique n’est qu’une abstraction, son véritable statut est celui que lui confère l’utilisateur.
Pour terminer, la notion même de subjectivité, et de reconnaissance de la centralité humaine trouve des échos, puisqu’au moins des intentions transparaissent de reconnaître, et non plus de craindre, la variabilité inter-individuelle, mais également les variations temporelles intra-individuelles [67]. Les travaux en ergonomie dans le développement des interfaces homme-machine en témoignent également.
4.2 Informatique et interprétation
Assurément, les applications de ces idées générales couvrent un éventail plus large que celui que nous visons. Il à ce point opportun de revisiter les principes précédemment évoqués pour guider notre approche, en mettant en relief leur adéquation et en envisageant dans les grandes lignes leur mise en place.
Pour ce qui est de la couche logique, nous avons déjà discuté de l’intérêt d’une description formelle simple, se basant sur des concepts fondamentaux,
tels que ceux qui sous-tendent la vision différentielle. C’est à ce stade que nous entendons satisfaire le souci de rigueur. Cependant, cette notion de rigueur doit être étendue. Elle ne concerne pas que le régime du calcul -pour lequel elle est presque définitoire. Elle va jusqu’aux régimes multiples d’ajustement et d’adaptation mutuels entre calculatoire et sémiotique.
Pour la couche sémiotique, différentes considérations sont à prendre en compte.
Pour la souplesse, nous la capterons par le principe de description méta-linguistique. Quoi de plus souple en effet que la langue naturelle, à plus forte raison lorsque le discours qu’elle manipule s’adresse de façon privilégiée à son créateur ? Ainsi, sur la base des unités formelles citées plus haut (et dé-veloppées bien plus bas), l’utilisateur calquera donc ses propres descriptions langagières, avec la liberté que lui laissera leur incompréhensibilité par la ma-chine. Nous tâcherons donc de faire d’un vice une vertu, puisque la machine n’influencera pas la valeur fondamentale des ces descripteurs, respectant par là même la prédominance de l’humain dans cette relation. D’un point de vue interprétatif, l’utilisation de la langue comme descripteur rejoint la notion d’appropriation que F. Rastier énonce [53] pour traduire la prise en compte du contexte interprétatif. C’est ici par son propre langage que l’utilisateur décrira son interprétation.
Enfin, par le biais des relations mises en place au niveau formel, «tra-duites» par le méta-langage naturel de description, la porte est ouverte, sinon aux suggestions de source inférentielle, du moins aux facilités de représenta-tion et de synthèse que peut proposer un outil logiciel manipulant un texte. Quant à la volonté de construire l’identité sémantique des unités mises en œuvre dans la description interprétative, elle se traduira par un ensemble de contraintes formelles dans la définition de ces unités, qui, projetées à l’attention de l’utilisateur, seront autant de suggestions à la créativité et au repérage des nouvelles descriptions. Restons prudent toutefois sur l’origine de cette identité : sa construction n’est en fait qu’une conséquence de sa présupposition par l’utilisateur. Cette étincelle créatrice initiale entraîne par contre, d’un point de vue formel, des exigences de la couche logique.
Nous verrons au travers de la théorie linguistique motivant notre ap-proche, la traduction de ces principes sous un aspect herméneutique, justi-fiant tant la circularité méta-linguistique que l’infinité de ce type de proces-sus.
4.3 Quelles applications ?
Ce point de vue, centré sur la subjectivité dans la langue, si attrayant qu’il soit, limite tout de même, outre les objectifs concrets d’une applica-tion, ses domaines d’applications. Reprenons un argument de F. Rastier à propos des exemples littéraires qui illustrent ses travaux : «... Outre que ces textes [littéraires] sont des plus agréables à étudier, on peut prétendre que leur complexité met à rude épreuve les instruments descriptifs utilisés. Mais au contraire, choisir des textes littéraires, ne serait-ce pas une solution de facilité ? Leur cohésion guide le scholastique.» [50].
Pour reprendre la première réponse que l’auteur apporte ici à une cri-tique, nous ne pourrons que la renforcer en y ajoutant le statut socialement stabilisé des méthodes exhaustives d’analyse quand elles s’appliquent aux textes. Nombre de travaux littéraires mettent en exergue la rigueur néces-saire à une étude dans ce domaine, et une transversalité des études quant au niveau des entités linguistiques manipulées. Il devient donc plus accep-table de solliciter un utilisateur qui, lui, n’a pas besoin de la machine pour comprendre le texte, pour un poème ou un roman que pour une recette de cuisine ou pour une notice de montage d’un moteur d’avion. Pour ce qui est du deuxième argument, ne nous leurrons pas, l’application à de tels textes garantit également des résultats non triviaux, simplement parce que le style (au sens large) est important. Cependant, des méthodes similaires semblent trouver un écho appliqué à des textes techniques, lorsque les considérations pragmatiques sont l’extraction de connaissance, couplée aux systèmes de re-présentations plus classiques [2].
Bien sûr, nous ne pouvons prétendre en tout cas à une complète origina-lité des applications du TALN à la littérature. Au contraire, nous rejoignons en ce sens un mouvement assez riche de collaboration entre l’informatique et les sciences humaines. En effet, nombre de travaux en lexicométrie sont informatiquement appliqués à des études littéraires, pour lesquels l’outil au-tomatique est parfaitement justifié. Un exemple d’une telle mise en œuvre est le programme TACT (Text Analysis Computer Tools) du Center for Computing in the Humanities de l’Université de Toronto6. Constitué d’une grande famille d’outils d’analyse statistique des fréquences de mots, il per-met d’extraire des structures stylistiques de textes, basées essentiellement sur la syntaxe (en fait, sur la seule forme des chaînes de caractères), et sur quelques traits sémantiques essentiellement définis comme des classes abs-traites d’occurrences syntaxiques. Le principal reproche que nous pourrions
6. Vivons avec notre temps : le logiciel et sa documentation sont disponibles à l’adresse suivante : http ://www.chass.utoronto.ca :8080/cch/tact.html
porter à ces approches est la reprise de ce fameux principe issu des modèles cryptographiques, de ne regarder qu’une petite «fenêtre» pour expliciter un terme dans un corpus. La théorie initiale cherchait à définir le nombre de mots nécessaires dont il faut tenir compte avant et après l’occurrence consi-dérée pour la cerner complètement. Il s’agit du fameux KWIC (Key-Word In Context) des anglo-saxons, que la coutume a fixé à une taille de 11 mots (5 avant et 5 après). De telles considérations semblent donc peu respectueuses de l’intégrité du texte analysé.
Malgré le caractère essentiellement formel de ces analyses, nombreuses sont les applications de cet outil par des chercheurs en littérature. Il y a donc un besoin (ou du moins un besoin à créer) de l’autre côté de la barrière sciences dures / sciences humaines, de tels outils scientifiques. Ce que nous proposerons ici sera en comparaison un accompagnement de la machine au long d’un acte d’interprétation. Nous avons déjà énoncé un intérêt d’une telle situation dans la gestion de la cohérence de cette interprétation, et dans un pouvoir limité de suggestivité. Mais nous envisagerons également d’autres aspects, liés aux outils précédemment cités, dans la capacité de mémoire et de présentation de la machine.
Mais pas de précipitation dans ce domaine, dont les fondements mêmes sont remis en cause, comme l’explique Mark Olsen dans [43]. Dans cet article, il constate tout d’abord le manque d’innovation et de résultats probants dans le domaine de l’analyse littéraire informatisée, malgré les progrès technolo-giques et le nombre de travaux croissant. En résumé, rien n’est découvert via ces méthodes technologiques qui ne le serait par une lecture attentive d’une œuvre. Ses conclusions sont doubles : tout d’abord il prône une utilisation de l’ordinateur pour ce qu’il sait faire de mieux que l’homme : manipuler de grandes quantités de données, donc de nombreux textes. Mais surtout, il insiste sur le besoin de corrélation entre théories d’analyse et dévelop-pements informatiques, indiquant par là un mouvement dans lequel nous estimons nous situer. Nous expliciterons en effet, lors du prochain chapitre les inspirations théoriques qui ont guidé ce travail.
5
Conclusion
En achevant notre première étape, le but que nous nous étions fixé était de placer notre approche dans son contexte au sens large. Sans avoir détaillé exhaustivement les travaux connexes en TALN, nous espérons nous être situé par rapport aux grands axes qui l’organisent.
— Une prise de position envers les aspects interprétatifs, en rejetant tout d’abord la génération que nous n’envisageons pas comme le décalque de la compréhension.
— Dans cette même voie, un refus de la caractérisation des processus de compréhension comme décodage d’une réalité absolue ou même cognitive. D’où un choix de la notion d’interprétation, plus souple et plus ambitieuse à la fois, donnant une place centrale à la subjectivité dans la condition de l’objet linguistique.
— Une orientation vers la sémantique, au détriment de la syntaxe au sens linguistique. Il s’agira cependant d’une vision structurale de la sémantique, faisant ainsi appel à une notion de syntaxe purement formelle, mais dont les principes plus élémentaires ne soient pas une gêne dans les implications au niveau du sens.
— La reconnaissance du texte comme objet privilégié (et exclusif) d’une vision linguistique du sens en situation.
— Et enfin, pour concilier ces positions, une application résolument tour-née vers la coopération entre l’homme et la machine, laissant la notion première de la signification à l’humain, limitant ainsi la machine à un rôle de suggestion et non de décision. Ce qui, de plus, nous pousse à envisager des domaines d’application plutôt littéraires.
Pour terminer, il nous semble intéressant, pour clore ces questions, de nous permettre une petite comparaison, en plaçant notre approche dans la déjà longue histoire du TALN, avec l’historique et la prospective que F. Varela propose pour les sciences cognitives.
Dans son ouvrage «Connaître : les sciences cognitives, tendances et pers-pectives» [63], F. Varela décrit avec clarté les grandes évolutions des sciences cognitives, de leur genèse à leur avenir supposé. Sans vouloir émettre d’hy-pothèses fortes quant aux relations réelles entre ces sciences et le TALN, il semble pourtant légitime d’appliquer son schéma à un rapide historique de le discipline qui nous intéresse. Nous reprendrons donc les étapes que l’auteur repère dans le passé, ainsi que la forme didactique qu’il emploie pour syn-thétiser sa critique, et comparerons enfin notre prise de position à la sienne, en ce qui concerne l’évolution supposée.
L’évolution ainsi présentée est résumée en quatre étapes : depuis les pé-riodes logiques et cybernétiques, en passant par le cognitivisme classique et le subsymbolisme vers la nébuleuse notion d’enaction.
Pour la première époque, où régnait l’optimiste cybernétique, cela se tra-duisit par la considération de la langue comme simple code. Les premières tentatives de traduction automatique dont nous avons parlé traduisaient bien cette absence de prise en compte de la réalité interne des phénomènes du
langage, traité comme de simple chaînes de caractères à mettre en corres-pondance par un mécanisme simple. Le paradigme de la boîte noire est ici projeté, et cédera sa place aux tentatives d’explicitation par le formalisme logique.
L’étape cognitiviste voit ensuite la notion de symbolisme et de représen-tation placée sur le devant de la scène. La cognition devient représenreprésen-tation et manipulation de symboles par des règles logiques. Quant au langage, il devient effectivement représentation, captable informatiquement par des lo-giques complexes, attribuant un sens décrit à des entités qui se combinent, et le sens se construit de façon déterministe. La plupart des formalismes clas-siques du TALN datent de cette époque, où les systèmes experts faisaient fureur.
Nous reprendrons ici (en les transformant) les questions que pose F. Va-rela, dont le texte initial était le suivant : Qu’est-ce que la cognition ? Com-ment cela fonctionne-t-il ? ComCom-ment savoir qu’un système cognitif fonctionne de manière appropriée ?
— Question 1 : Qu’est ce que la sémantique dans la langue ?
Réponse : Un mode de représentation des structures conceptuelles destinées à être transmises, de l’information.
— Question 2 : Comment cela fonctionne-t-il ?
Réponse : En traduisant les concepts par des entités linguistiques, dont les relations entre elles (syntaxiques) traduisent également la structuration des concepts.
— Question 3 : Comment savoir qu’un système de TALN fonctionne de manière appropriée ?
Réponse : Si l’information décodée et représentée par un formalisme logique permet d’aboutir à des inférences face à un objectif ou des représentations correctes face à une base de connaissances.
L’étape suivante, qui ne suit pas forcément une chronologie bien nette est l’apparition de la notion de subsymbolisme, avec comme plus célèbre mani-festation le connexionnisme. Inspiré par les découvertes en neuro-sciences, le principe en comparaison au cognitivisme classique est d’atteindre un résultat non par des règles de haut niveau s’appliquant à des entités bien définies et stables, mais de le faire apparaître ou plutôt émerger par la collaboration d’un grand nombre d’entités minimales, très locales et sans contenu propre. Sans proposer une nouvelle approche du calcul, il ne constitue pas moins un paradigme de représentation.
Nous nous risquerons donc à rapprocher de ce paradigme les travaux sus-cités sur les analyses distributionnelles. En effet, le principe y est aussi de voir «émerger» des considérations sémantiques sur un corpus à partir de la
prise en compte d’un grand nombre d’éléments locaux, sans qu’à ceux-ci soit attribué un véritable contenu (décrit de manière formelle). Il s’agit donc de se dégager d’une explicitation de la notion de sens, et de ne rechercher que sa manifestation, comme un principe organisateur sous-jacent.
— Question 1 : Qu’est ce que la sémantique dans la langue ?
Réponse : Un système trop complexe et ouvert pour être décrit direc-tement, dont la seule manifestation permet de découvrir l’organisation générale.
— Question 2 : Comment cela fonctionne-t-il ?
Réponse : En analysant sans hypothèses fortes la distribution des entités linguistiques, en utilisant des relations simples entre ces unités (identité, co-occurrence, etc.) pour les caractériser à un niveau global. — Question 3 : Comment savoir qu’un système de TALN fonctionne de
manière appropriée ?
Réponse : Si les classifications issues de ces traitements distribution-nels sont interprétables comme des classes sémantiquement valides. Enfin, F. Varela conclut par la perspective de l’enaction, ou le faiémerger. Sans vouloir trop nous avancer sur cette notion opaque, nous re-tiendrons quelques aspects que nous pensons intéressants, et proches de nos préoccupations et de nos prises de position. Tout d’abord, les liens avec l’étape précédente sont importants : il y a ici refus d’une explicitation trop forte et figée d’un mécanisme général, et donc d’une description exclusive-ment logique du sens. L’aspect central de la création que l’auteur accorde à ce paradigme trouve également des échos dans la notion d’interprétation. Il remplace également la notion de validité d’un modèle par une viabilité, que nous aimerions concevoir comme cohérence par rapport à l’interprète.
Vouloir y trouver d’autres liens serait hasardeux et sans doute inutile, mais appliquons le jeu des trois questions à notre approche, dans un souci de résumé.
— Question 1 : Qu’est ce que la sémantique dans la langue ?
Réponse : Une structure qui se construit, intégrant à partir de données linguistiques les intentions et connaissances de l’interprète.
— Question 2 : Comment cela fonctionne-t-il ?
Réponse : Par projection de ces données générales sur la structura-tion linguistique de l’énoncé, sur les entités locales, et permet de voir apparaître des données globales structurées.
— Question 3 : Comment savoir qu’un système de TALN fonctionne de manière appropriée ?
préfé-rons d’ailleurs refuser l’intérêt de celle-ci. Comme nous l’avons déjà évoqué, la notion de performance n’est sans doute pas adaptée au langage. Dans le TALN, bien souvent, la notion d’application directe sert de bouclier face à des remarques théoriques sur une conception sous-jacente de la langue sou-vent trop pauvre et simpliste. Nul doute qu’ici nous pêcherons par excès inverse...
À notre connaissance, au sein de cette discipline, il ne se trouve pas d’approche susceptible de capter les aspects de la textualité tels que nous les avons énoncés. Une première explication peut se trouver dans la faiblesse du nombre de théories linguistiques qui traite de ces problèmes d’une manière au moins minimalement formelle. Au cours du prochain chapitre, nous nous pencherons donc de plus près sur les travaux de F. Rastier sur la sémantique interprétative, en envisageant sa mise en place formelle et informatique au vu des grandes lignes que nous avons tracées ici.
Une approche linguistique du
TALN : La Sémantique
Interprétative
Dans ce chapitre, nous tenterons, au vu des lacunes et nécessités du TALN exposées précédemment, de justifier l’intérêt d’une théorie linguistique avant tout, mais surtout d’une théorie s’intéressant à l’interprétation. Nous allons donc exposer les principales idées de la Sémantique Interprétative de François Rastier [49], [50], et la façon dont elle peut être appliquée au traitement automatique de la langue tel que nous l’avons envisagé [52].
Dans une première partie, nous expliciterons les origines de la théorie, et les diverses influences qu’elle revendique, puis nous tenterons de mettre en évidence les intérêts majeurs qu’elle présente pour aborder formellement le problème de l’interprétation. Nous rentrerons plus en détail dans cette théorie en en répertoriant les concepts et les outils que ceux-ci peuvent mettre à la disposition du traitement informatique. Enfin, nous parlerons des possibilités concrètes de son utilisation, et bien entendu des limites de celle-ci. Nous nous inspirerons pour ce rapide exposé des enseignements linguistiques des ouvrages [17], [39], [40], [6] entre autres.
1
Approche structuraliste et herméneutique
Dans cette partie nous allons approfondir les diverses influences de la théorie de la sémantique interprétative, à savoir la linguistique structurale et l’herméneutique. La première annonce une volonté de s’ancrer de plain-pied dans le domaine de la linguistique, au détriment des disciplines connexes