Agrégation des similarités : une solution oubliée
Texte intégral
Figure
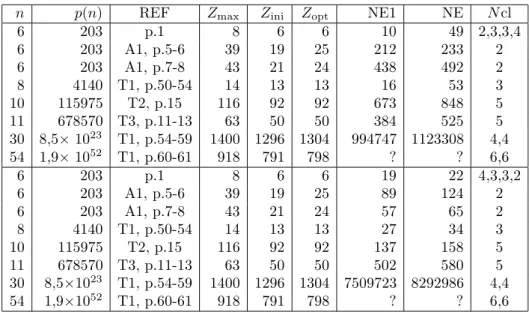
Documents relatifs
L’op´eration r´eciproque, de passage d’un arbre binaire de recherche `a un arbre balis´e, peut se faire en ajoutant d’abord des feuilles pour compl´eter l’arbre (au sens
En supposant que le tableau des coˆ uts sign´ es est lu en entr´ ee, l’espace utilis´ e pour impl´ ementer de l’algorithme comprend 6 ensembles de n(n − 1)/2 ´ el´ ements,
On ouvrira le fichier tp1.v ` a l’aide de la commande coqide, on pourra alors le compl´ eter dans la fenˆ etre de script de CoqIDE et utiliser le bouton ⇓ pour commencer la
Consid´ erons maintenant un pr´ edicat ` a deux arguments (autrement dit une relation) : Variable rel : nat -> nat -> Prop.. Prouvez le th´ eor` eme
El´ ements d’algorithmique. EA4 (3
Quels sont les ´ el´ ements nilpotents d’un anneau int`
Seul le couple (17,3) est à retenir car au moins un entier parmi les autres couples
Dans la logique du second ordre, on utilise un deuxi`eme type de variables, appel´ees variables du second ordre, qui repr´esentent des relations.. LIAFA, CNRS et Universit´ e
