Bandwidth steering in HPC using silicon nanophotonics
Texte intégral
Figure
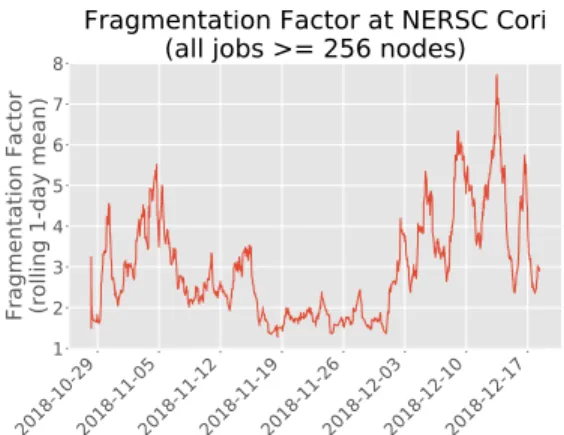

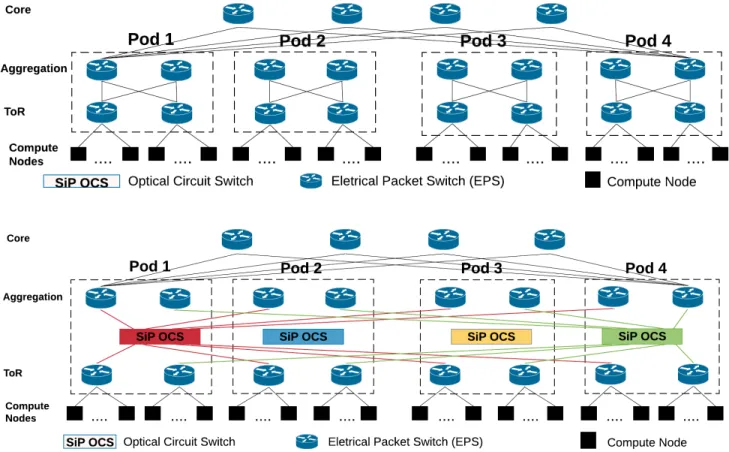

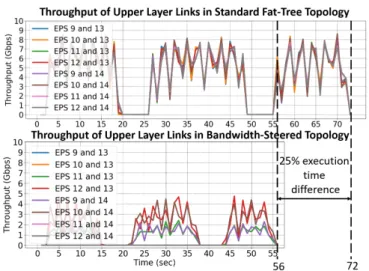

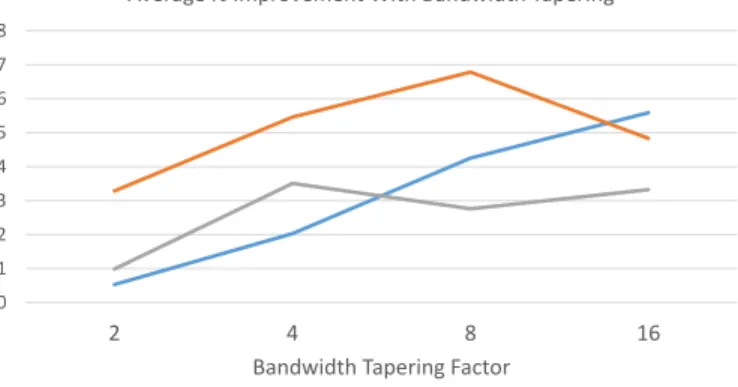
Documents relatifs
This work demonstrates that type I photoinitiators that are typically used in polymerization mixture to generate free radicals during monolith synthesis can
31.26% of our training dataset leads to Moderate response, mainly based on the main web page located in Europe or Asia, the requested Internet protocol being HTTP/1.1, HTTP/2 or
Here, we report on the study of its bulk magnetic and transport properties at ambient and elevated pressure, complemented by neutron diffraction measurements and ab
l'apprentissage moteur avec les étudiants phase moyenne, en plus de l'identification des différentes compétences de communication et le rôle efficace dans l'apprentissage
The system described in the following pages is an attempt to build an artificial agent that represents objects with a relational representation, builds a generative
For each simulated dataset, we estimated the trend of the rolling window metric (in particular we only tested for autocorrelation at-lag-1, standard deviation, and skewness)
The evolutionary radiation of Arvicolinae rodents (voles and lemmings): relative contribution of nuclear and mitochondrial DNA phylogenies...
reported ( Figure 1 , gray area marked as a), the question that arises is why the results for the spinning sample are so different (by a factor of ∼25) from the static sample
![[PDF] Débuter la programmation avec le langage Haskell | Cours informatique](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)