Développement d’un questionnaire cognitif bref,
le FaCE (The Fast Cognitive Evaluation), selon la
modélisation Rasch adapté aux patients avec
cancer
Mémoire
Amel Baghdadli
Maîtrise en épidémiologie
Maître ès sciences (M.Sc.)
Québec, Canada
© Amel Baghdadli, 2016
Développement d’un questionnaire cognitif bref,
le FaCE (The Fast Cognitive Evaluation), selon la
modélisation Rasch adapté aux patients avec
cancer
Mémoire
Amel Baghdadli
Sous la direction de :
Bruno Gagnon, directeur de recherche
Résumé
Les déficits cognitifs sont présents chez les patients atteints de cancer. Les tests cognitifs tels que le Montreal Cognitive Assessment se sont révélés peu spécifiques, incapables de détecter des déficits légers et ne sont pas linéaires. Pour suppléer à ces limitations nous avons développé un questionnaire cognitif simple, bref et adapté aux dimensions cognitives atteintes chez les patients avec un cancer, le FaCE « The Fast Cognitif Evaluation », en utilisant la modélisation Rasch (MR). La MR est une méthode mathématique probabiliste qui détermine les conditions pour qu’un outil soit considéré une échelle de mesure et elle est indépendante de l’échantillon. Si les résultats s’ajustent au modèle, l’échelle de mesure est linéaire avec des intervalles égaux. Les réponses sont basées sur la capacité des sujets et la difficulté des items. La carte des items permet de sélectionner les items les plus adaptés pour l’évaluation de chaque aspect cognitif et d’en réduire le nombre au minimum. L’analyse de l’unidimensionnalité évalue si l’outil mesure une autre dimension que celle attendue.
Les résultats d’analyses, conduites sur 165 patients, montrent que le FaCE distingue avec une excellente fiabilité et des niveaux suffisamment différents les compétences des patients (person-reliability-index=0.86; person-separation-index=2.51). La taille de la population et le nombre d’items sont suffisants pour que les items aient une hiérarchisation fiable et précise (item-reliability=0.99; item-séparation-index=8.75). La carte des items montre une bonne dispersion de ceux-ci et une linéarité du score sans effet plafond. Enfin, l’unidimensionnalité est respectée et le temps d’accomplissement moyen est d’environ 6 minutes.
Par définition la MR permet d’assurer la linéarité et la continuité de l’échelle de mesure. Nous avons réussi à développer un questionnaire bref, simple, rapide et adapté aux déficits cognitifs des patients avec un cancer. Le FaCE pourrait, aussi, servir de mesure de référence pour les futures recherches dans le domaine.
Abstract
Cognitive deficits are prevalent in patient with cancer all along their trajectory. Specifics cognitive functions are affected in this population. Several questionnaires are used to assess the cognitive impairment but they are not adapted for this population. In order to provide a reliable tool, we developed an adapted, simple and fast questionnaire, the Fast Cognitive Evaluation (FaCE) by exploring its psychometric properties using the Rasch analysis.
The Rasch model (RM) is a psychometric mathematical method that establishes the conditions that a measurement tool has to satisfy to be considered a rating scale. Unlike traditional psychometric analysis, RM has the advantage of being sample independent. If the results fit the RM the numerical scale is linear with equal interval. RM response is based on the person-abilities and the item-difficulty. The item-map allows the selection of the best item that measures each cognitive aspect to reduce the number to the minimum. The dimensionality analysis estimates the possibility of measuring a secondary factor.
The analysis performed on 165 participants (49% male, median-age=64) show that the FaCE has a person-separation index=2.51 and a person-reliability=0.86 (the FaCE distinguish between high and low performers with enough levels). An item-separation index=8.75, an item-reliability=0.99 (the sample is large enough to confirm the item difficulty hierarchy with precisely located items). The map shows no considerable gap and no ceiling effect and the data fit the RM. Finally the unidemensionality was clinically respected.
By definition the RM ensures the linearity of the scale and allows us to generalize the results. We succeeded in developing a simple and fast questionnaire that takes less than 6 minutes to assess the cognitive failure from major to mild impairment. The FaCE could be used in all oncology departments to improve treatment or in future research that examines cognitive disorders in a population with cancer.
Table des matières
Résumé ... iii
Abstract ... iv
Table des matières ... v
Liste des tableaux ... ix
Liste des figures ... x
Liste des abréviations ... xi
Remerciements ... xii
Avant-propos ... xiii
Introduction ... 1
1. Chapitre 1 : Problématique ... 2
2. Chapitre 2 : Hypothèse de recherche et objectifs ... 4
2.1. Hypothèse de recherche ... 4
2.2. Objectifs principaux de recherche ... 4
3. Chapitre 3 : Modélisation Rasch ... 5
3.1. Notions générales sur les qualités d’un questionnaire et de la modélisation Rasch ………5
3.2. Notions statistiques de la modélisation Rasch ... 6
4. Chapitre 4 : Structure du questionnaire cognitif générique analysé ... 15
4.1. Construction du questionnaire cognitif générique ... 15
4.2. Description générale du questionnaire cognitif générique ... 16
4.2.1. Aspect orientation temporo-spatiale ...16
4.2.2. Mémoire immédiate ...16
4.2.3. Fonctions visuo-spatiales et exécutives ...17
4.2.4. Attention ...17 4.2.5. Langage et idéation ...18 4.2.6. Rappel différé ...18 5. Chapitre 5 : Méthodologie ... 19 5.1. Population ... 19 5.1.1. Processus de recrutement ...19 5.1.2. Critères d’éligibilité ...19 5.1.2.1. Critères d’inclusion ...19 5.1.2.2. Critères d’exclusion ...20
5.1.3. Procédure et déroulement de l’entrevue ...20
5.2. Analyse statistique descriptive ... 20
5.3. Application de la modélisation Rasch pour l’analyse des propriétés psychométriques du FaCE ... 21
5.3.1. Objectivité de mesure ...25
5.3.1.1. Hiérarchisation des réponses aux items ...25
5.3.1.3. Unidimensionnalité ...26
5.3.1.4. Indépendance locale ...27
5.3.2. Analyse de la qualité de la modélisation ...28
5.3.2.1. Vérification de l’ajustement des données aux exigences de la modélisation Rasch ...30
5.3.2.2. Analyse des statistiques d’ajustement ...33
5.3.2.2.1. Corrélation des scores attendus et observés ...33
5.3.2.2.2. Évaluation de l’ajustement (« Fit analysis »)...34
5.3.2.3. Qualité psychométrique du questionnaire FaCE ...36
5.3.2.3.1. Validité...37 5.3.2.3.1.1. Validité de contenu ...37 5.3.2.3.1.2. Validité prédictive ...37 5.3.2.3.1.3. Validité conceptuelle/théorique ...38 5.3.2.3.1.4. Validité apparente ...38 5.3.2.3.2. Fiabilité ...38 5.3.2.3.2.1. Fiabilité de reproductibilité ...39
5.3.2.3.2.2. Indice de séparation des personnes (« person-séparation-index ») indice de fiabilité des personnes (Person-reliability index (IFP)) ...39
5.3.2.3.2.3. Indice de séparation des items (« person-séparation-item ») ...39
5.3.2.3.3. La plus petite différence mesurable ...40
5.3.2.3.4. Le fonctionnement différentiel des items ...40
6. Chapitre 6 : Résultats ... 42
6.1. Population ... 42
6.2. Résultats descriptifs ... 42
6.2.1. Score total obtenu et le temps d’accomplissement du questionnaire cognitif générique ...42
6.2.2. Résultats de l’analyse des scores obtenus du questionnaire cognitif générique à chaque aspect cognitif évalué ...43
6.2.2.1. Orientation ...43
6.2.2.2. Mémoire immédiate et rappel différé ...43
6.2.2.3. Fonctions visuo-spatiales ...43
6.2.2.4. Attention ...43
6.2.2.5. Langage et idéation ...44
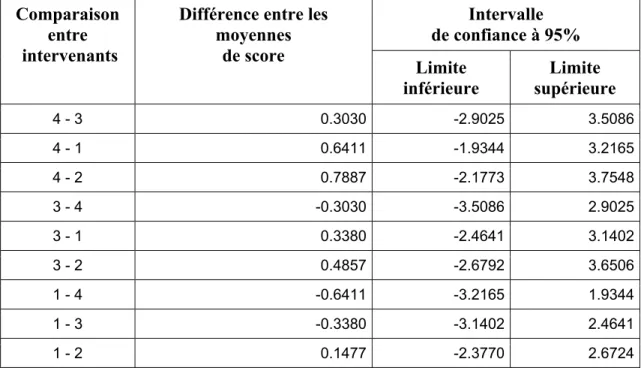
6.2.3. Résultats de l’analyse de l’influence des intervenants sur le score obtenu au questionnaire cognitif générique par les participants. ...44
6.2.3.1. Résultats de la vérification des postulats : ...44
6.2.3.1.1. Distribution normale ...44
6.2.3.1.2. Indépendance des groupes...44
6.2.3.1.3. Homoscédasticité ...45
6.2.3.2. Résultats d’analyses statistiques ...45
6.3.1. Résultats de l’analyse du questionnaire cognitif générique ...45
6.4. Analyse du FaCE ...46
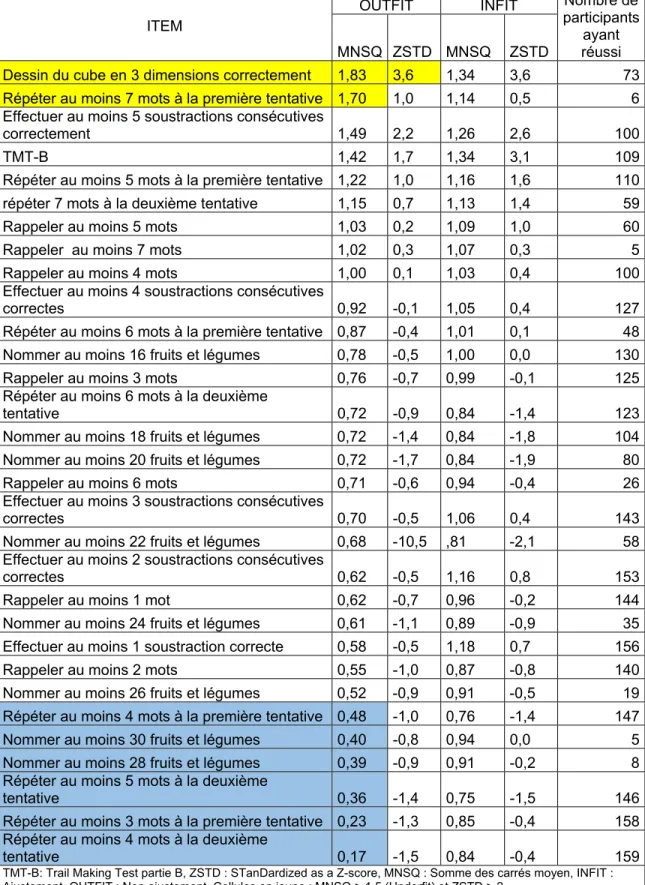
6.4.1. Hiérarchisation des réponses aux items ...46
6.4.1.1. Unidimensionnalité ...48
6.4.2. Qualité de la modélisation ...49
6.4.2.1. Vérification de l’ajustement des données aux exigences de la modélisation Rasch ...49
6.4.2.2. Résultat de l’analyse des statistiques d’ajustement ...49
6.4.2.2.1. Corrélation des scores attendus et observés ...49
6.4.2.2.2. Évaluation de l’ajustement (« Fit analysis »)...49
6.4.2.3. Résultats de l’analyse de la qualité psychométrique du FaCE ...50
6.4.2.3.1. Validité...50
6.4.2.3.2. Fiabilité ...50
6.4.2.3.2.1. Fiabilité de reproductibilité ...50
6.4.2.3.2.2. Indice de séparation des personnes (« person-séparation-index ») et indice de fiabilité des personnes («person-reliability index ») ...50
6.4.2.3.2.3. Indice de séparation des items (« person-séparation-item ») et indice de fiabilité de l’item (« item-reliability index ») ...50
6.4.2.3.3. La plus petite différence mesurable ...50
6.4.2.3.4. Le fonctionnement différentiel des items ...50
6.5. La conversion du FaCE en échelle de 0 à 100, sa comparaison avec le test cognitif générique et son utilisation clinique ou de recherche ... 51
7. Chapitre 7 : Discussion ... 53
7.1. Qualité de la modélisation Rasch du questionnaire FaCE ... 53
7.2. Qualités psychométriques du questionnaire FaCE ... 54
7.3. Points à investiguer ... 55
7.4. Limites du recours au questionnaire FaCE pour une évaluation des fonctions cognitives chez les sujets atteints d’un cancer ... 56
7.5. Avantages du recours au questionnaire FaCE pour une évaluation des fonctions cognitives chez les sujets atteints d’un cancer clinique ou de recherche ... 57
Conclusion ... 58
Bibliographie ... 59
Figures ... 71
Annexes ... 84
Annexe 1 : Questionnaire cognitif générique ... 84
Annexe 2 : Carte de répartition des sujets en relation aux différents items du MoCA .... 85
Annexe 3 : Carte des mesures empiriques des items du FaCE ... 86
Annexe 4 : Tableau des Résultats du test de normalité du score total et du temps questionnaire cognitif générique ... 87
Annexe 5 : Courbe caractéristique d’items de tous les items du questionnaire cognitif générique ... 88
Annexe 7 : Détail de la conversion du score du FaCE d’une mesure en Logit à un pourcentage ... 118 Annexe 8 : Étapes préliminaires au développement du FaCE ... 119
Liste des tableaux
Tableau 1 : Caractéristiques des participants ...63 Tableau 2 : Étendue du score total obtenu au questionnaire cognitif générique par les participants et du temps d’accomplissement ...64 Tableau 3 : Résultats de l’analyse ANOVA de comparaison du score obtenu par les participants en fonction des différents intervenants ...64 Tableau 4 : Table des variances résiduelles standardisées (analyse de la dimensionnalité) du FaCE ...65 Tableau 5 : Mesures (Logit) des items de la version finale du FaCE ...66 Tableau 6 : Tableau de corrélation des scores attendus et observés du FaCE ...67 Tableau 7 : Tableau des analyses d’ajustement (Fit-Analysis) de la version finale du FaCE ...69 Tableau 8 : Grille d’interprétation du score final du FaCE ...70
Liste des figures
Figure 1 : Courbe caractéristique d’un item suivant une formulation dichotomique de la modélisation Rasch ...71 Figure 2 : Distribution des types de cancer des participants ...72 Figure 3 : Distribution du score total obtenu au questionnaire cognitif générique par les participants ...73 Figure 4 : Distribution des scores des participants pour l’évaluation de l’aspect cognitif relatif à l’orientation ...73 Figure 5 : Distribution des scores (nombre de mots) des participants pour l’évaluation de l’aspect cognitif relatif à la mémoire immédiate (répétition des 7 mots cités par l’évaluateur, figures A et B) et évaluation du rappel différé (rappel des 7 mots, figure C) ...74 Figure 6 : Distribution des scores (réussite de la tâche) des participants pour l’évaluation de l’aspect cognitif relatif aux fonctionnements visuo-spatial et exécutives (TMT-B (1-8; A-H), dessin du cube en 3 dimensions, dessin de l’horloge) ...75 Figure 7 : Distribution des scores (réussite de la tâche) des participants pour l’évaluation de l’aspect cognitif relatif à l’attention ...76 Figure 8 : Distribution du nombre de fruits et de légumes nommés par les participants ....77 Figure 9 : Carte de répartition des sujets en relation aux différents items du FaCE ...78 Figure 10 : Combinaison de réponses aux items (sujets avec des combinaisons de réponse différentes de celle attendue) ...80 Figure 11 : Illustration du score total obtenu au questionnaire cognitif générique (converti en un score sur 100) et du score final au FaCE (linéaire) ...81 Figure 12 : Illustration d’un exemple d’utilisation du FaCE pour l’estimation du niveau cognitif d’un patient atteint de cancer,...82 Figure 13 : FaCE (Fast Cognitive Evaluation) ...83
Liste des abréviations
ANOVA : ANalysis Of VAriance (Analyse des variances) AVC : Accident vasculaire cérébral
CA : Capacité de la personne A
CCI : Courbe caractéristique de l’item CORR: Correlation (corrélation)
CRCEO : Centre de Recherches Clinique et Évaluative en Oncologie de Québec DX : Difficulté de l’item X
ET: Écart-Type
Exp: Expected (attendu)
FaCE: Fast Cognitive Evaluation
FDI : Fonctionnement Différentiel des Items ISP : Indice de Séparation des Personnes
Logit : logarithme odds unit (Unité de logarithme de cote) MMSE : Mini-Mental State Examination
MoCA: Montreal Cognitive Assessment
MNSQ : MeaN SQuare (Somme des carrés moyens) MR: Modélisation Rasch
Obs: Observed (observé)
P : Probabilité globale de réponse à deux items (X et Y) PAX0 : Probabilité d’échec
PAX1 : Probabilité de réussite
PX : Probabilité de réponse de l’item X
PY : Probabilité de réponse de l’item Y
RVAX1 : rapport de vraisemblance de réussite
TMT-B: Trail Making Test partie B (Test d’exécution de traces partie B) ZSTD : STanDardized as a Z-score (Standardise tel qu’un score “Z”)
Remerciements
Avant tout je tiens à remercier tous les membres actuels et passés de l’Équipe de Recherches Michel Sarrazin en Oncologie psychosociale et soins palliatifs (ERMOS). Vous avez été une deuxième famille pour moi et d’un grand soutien au quotidien durant mes années d’études. Un profond « Merci », à mon directeur de recherche, Dr Bruno Gagnon qui a su m’encadrer par ses connaissances et son expérience. Il m’a fait l’honneur de partager son savoir et a eu la patience de me guider. Merci de m’avoir fait repousser mes limites pour atteindre des objectifs que je pensais irréalisables et d’avoir été présent et disponible jusqu’à la fin.
Je remercie aussi grandement Giovanni Arcuri qui a participé au développement du protocole initial de ce projet et qui s’est rendu disponible pour partager ses expériences et ses connaissances. Je tiens aussi à remercier les membres du Jury d’évaluation de cet ouvrage, Dr Denis Talbot, Dr Pierre R. Gagnon et Dr Robert Laforce Jr., qui ont pris le temps de lire et corriger ce mémoire pour l’améliorer par leurs connaissances et leurs expertises.
Un merci particulier à Renée Drolet, sans qui je n’aurais jamais entrepris ce projet, et à Gabrielle Dumas qui a participé à l’amorcer.
Merci à François Tardif, Joanie Lemoignan, Marie-Anik Robitaille, Sandy Lavoix, Véronique Turcotte, et à tous les autres pour leurs conseils éclairés, leur aide, leur soutien permanent et leur bonne humeur. Merci de m’avoir permis de ventiler quand j’en ai eu besoin.
Je remercie Cinthia Lacroix pour son soutien, son aide et pour son travail rigoureux durant les premières étapes du projet. Merci à Anne-Marie Veillette d’avoir grandement participé au maintien de ma forme physique et morale. Merci aux autres membres de l’équipe que je n’ai pas nommés, mais qui sont dans mes pensées.
Merci à Lynn Gauthier pour son soutien et sa grande compréhension pendant la finalisation de ce travail.
Enfin, et surtout, Je remercie ma famille adorée qui me manque énormément et qui croit en moi, quels que soient les défis que je me fixe. Elle m’a beaucoup encouragée et supportée même en étant de l’autre côté du monde. Et merci à ma toute nouvelle famille d’adoption qui m’a donné de l’énergie quand j’en eu besoin et qui m’a offert un support et un confort inestimables. Mes amis qui m’ont supporté tout au long de la réalisation de mes projets et à Guillaume qui partage mes craintes, mes doutes, mes espoirs et mes rêves au quotidien.
Avant-propos
Le projet de recherche décrit dans cet ouvrage est le résultat d’un travail rigoureux de la part d’une équipe dont la préoccupation principale était d’apporter de nouvelles connaissances fiables afin d’améliorer la prise en charge globale des patients souffrant d’un cancer.
Je suis convaincue que le résultat de ce travail aura l’impact souhaité et qu’il permettra de réfléchir à de nouvelles options pour l’amélioration de la qualité de vie des patients.
J’ai eu le privilège de travailler sur le projet ambitieux de développer un outil unique avec une équipe merveilleuse. Je suis très fière d’avoir réalisé ce projet jusqu’au bout et d’avoir apporté ma modeste contribution.
Cela a été un réel défi pour moi de découvrir une méthodologie d’analyse, la méthodologie Rasch, qui me paraissait insurmontable et que j’ai fini par trouver passionnante.
Mon travail dans ce projet a consisté à recruter certains participants et effectuer les entrevues, à collecter les informations médicales dans le dossier patient électronique, à performer des analyses statistiques et enfin réaliser la modélisation Rasch du questionnaire.
Les résultats de ce projet ont été et seront présentés à diverses rencontres scientifiques : ‐ Présentation par affiche :
Advanced Learning in Palliative Medicine Conference: New Frontiers in Palliative Medicine, 28-30 mai 2015, Calgary, Alberta
Journée Scientifique de la Maison Michel-Sarrazin, Université Laval, Québec 25 novembre 2015. Advance learning in palliative medicine conference, Ottawa, 12-14 mai 2016.
Congrès du département de médecine familiale et de médecine d’urgence, volet Érudition/Recherche, Université Laval, Québec 19-20 mai 2016.
16èmes journées annuelles de la recherche en santé, Université Laval, Québec 25-26 mai 2016. ‐ Présentation orale :
Évaluation d’un questionnaire cognitif bref conçu pour les patients atteints du cancer. Rencontre scientifique de l’Équipe de Recherche Michel-Sarrazin en Oncologie psychosociale et Soins palliatifs - ERMOS. CHU de Québec- L’Hôtel-Dieu de Québec. Vendredi 13 septembre 2013 Analyse des propriétés psychométriques d’un nouveau questionnaire cognitif bref adapté aux patients avec cancer, The Fast Cognitive Evaluation (FaCE) : Résultats préliminaires et aspects
cognitifs liés au cancer. Rencontre scientifique de l’Équipe de Recherche Michel-Sarrazin en Oncologie psychosociale et Soins palliatifs - ERMOS - CHU de Québec- L’Hôtel-Dieu de Québec. 9 avril 2015
‐ Présentation orale à venir : Atelier Rasch analysis basis to develop a brief cognitive questionnaire, The Fast Cognitive Evaluation (FaCE), 21e Congrès international de soins
palliatifs, Montréal, 18-21 octobre 2016.
Les prochaines étapes seront la rédaction d’un article scientifique qui présentera les différentes étapes de ce projet et qui aboutira, je l’espère, à une publication.
L’outil développé, le FaCE, va servir d’outil d’évaluation du statut cognitif des participants à un futur projet qui portera sur les options thérapeutiques de la perte cognitive chez les patientes en rémission d’un cancer du sein.
Dans les premières parties de cet ouvrage, les bases de la méthodologie Rasch seront présentées afin de faciliter la lecture des résultats. S’en suivront une discussion sur les objectifs et l'hypothèse de recherche ainsi qu’une conclusion qui permettra d’amener une réflexion sur de futurs sujets de recherche.
Introduction
L’espérance de vie après un cancer a nettement augmenté durant les dernières décennies1, 2. Les
troubles cognitifs, très fréquents chez les survivants au cancer3-9, sont présents à différents stades
de la maladie est à différents moments de sa trajectoire. Le « Brain Fog », ou brouillard cérébral, est l’ensemble des déficits cognitifs de cette population10. Selon les résultats d’études portant sur la
prévalence de ce phénomène10-12, il apparait que 4 à 75% des patients avec un cancer rapportent
une détérioration de leurs capacités cognitives. Le « Brain Fog » peut durer plusieurs années, même après la guérison du cancer13. Il en résulte une détérioration considérable de la qualité de vie de ces
patients5, 13-16.
Le phénomène du « Brain Fog » est évalué en utilisant, entre autres, des questionnaires tels que le Montreal Cognitive Assessment (MoCA) ou le Mini-Mental State Examination (MMSE) qui ont été développés pour l’évaluation des troubles cognitifs chez les patients âgés, et ne sont, donc, pas adaptés aux patients atteints d’un cancer. L’analyse des propriétés psychométriques du MoCA que nous avons menée dans une population atteinte de cancer17 a mis en évidence plusieurs limites. Il
est indispensable de travailler au développement d’un questionnaire adapté aux déficits cognitifs spécifiques aux patients avec un cancer qui soit linéaire, fiable et précis afin de pallier aux limites des outils présentement utilisés. Le développement d’un tel outil offrirait une échelle d’évaluation valide pour de futures recherches qui portent sur le suivi et l’évaluation des troubles cognitifs de cette population et pourrait améliorer la prise en charge globale et la qualité de vie de ces patients. Cet ouvrage présente les différentes étapes de l’analyse psychométrique d’un test cognitif générique basée sur la modélisation Rasch qui ont conduit au développement d’un questionnaire cognitif bref, Le FaCE (The Fast Cognitive Evaluation) qui pallie aux limites des tests cognitifs actuels. Le modèle Rasch constitue une approche mathématique simple appartenant aux concepts d’analyse de la théorie des réponses aux items18, 19. Son but est de modéliser la relation fondamentale entre le trait
latent d’un sujet (la capacité cognitive dans cet ouvrage) et sa probabilité de réussir un item avec une difficulté donnée. Il assure une linéarité et une continuité de l’échelle de mesure et permet d’apprécier la précision et la fiabilité de l’outil.
Les principes fondamentaux de la modélisation Rasch seront présentés et détaillés afin de faciliter la lecture des étapes de la méthodologie employée lors des analyses psychométriques du FaCE. Des étapes d’analyses précédant le développement du FaCE ont été nécessaires. Dans cet ouvrage, les résultats présentés sont ceux de la modélisation Rasch du FaCE qui permettent d’apprécier ses qualités psychométriques et d’avancer des conclusions éclairées.
1. Chapitre 1 : Problématique
Durant ces dernières décennies le nombre de survivants au cancer20 et leur espérance de vie1, 2 ont
augmenté. Cette population3-9 et en particulier les personnes sous ou ayant reçu de la
chimiothérapie21, 22 rapportent un ensemble de troubles cognitifs qui est un réel handicap à leur survie
et détériore considérablement leur qualité de vie5, 13-16.
Dans un premier temps cet ensemble de déficits des fonctions cognitives a été décrit comme étant en lien avec les traitements du cancer, plus précisément la chimiothérapie. Ce phénomène connu sous le nom de « Chemo Brain », ou « Chemo Fog », est plus généralement appelé aujourd’hui «Brain Fog » (brouillard cérébral) par le fait qu’il a été décrit par des personnes atteintes de cancer avant de recevoir de la chimiothérapies10, 23 et même au moment du diagnostic24, 25. Ce phénomène
a aussi été rapporté au cours de la grossesse26-28 et de la ménopause29 et au cours de différentes
pathologies, entre autres, la maladie cœliaque30, l’obésité31 et le syndrome de tachycardie
orthostatique posturale32.
La prévalence du Brain Fog est d’environ 50% selon certains auteurs4, 33, 34 et varie de 4 à 75% selon
d’autres études10-12, en fonction du type de cancer et de son pronostic. Il peut durer plusieurs années,
voire le reste de la vie, même après la guérison du cancer13. Sa physiopathologie est encore mal
connue35, 36 et son traitement est en cours d’investigation37-40.
Les aspects cognitifs les plus atteints dans le Brain Fog3, 4, 10, 13, 21, 41, 42 concernent des déficits de :
1- L’attention et de la concentration : c’est une difficulté à demeurer attentif sur une même tâche pour une période plus ou moins longue ou encore, une difficulté à rester concentré sur l’énoncé d’indications pour l’exécution d’une tâche donnée si celles-ci requièrent plusieurs étapes ou détails.
2- La mémoire immédiate et le rappel différé : c’est une difficulté à se rappeler des évènements ou des informations au-delà de quelques secondes après leur survenue. Les informations sont oubliées au fur et à mesure qu’elles se succèdent.
3- Le rappel différé : c’est une difficulté à se rappeler d’un évènement ou d’une information au-delà des quelques minutes qui suivent leurs survenues.
4- La fonction visuo-spatiale43 : c’est une difficulté à s’orienter dans l’espace, de percevoir les
objets de l’environnement et de les organiser en une scène visuelle cohérente ou d’imaginer mentalement un objet physiquement absent.
5- La rapidité à l’idéation et du langage: c’est un ralentissement de la formation et de l’enchaînement d’idées et de les formuler verbalement avec le mot adéquat.
6- La capacité à exécuter plusieurs tâches consécutives : c’est une difficulté à exécuter correctement plusieurs tâches successives dans le bon ordre et qui sont intriquées dépendantes les unes des autres.
Ces aspects spécifiques aux personnes atteintes d’un cancer sont différents des atteintes cognitives des personnes âgées. Même si ces déficits cognitifs peuvent être intriqués, les déficits cognitifs du Brain Fog, de la sénilité ou de la détérioration des capacités intellectuelles dans les dégénérescences cérébrales liées à l’âge ne sont pas superposables. Dans la maladie d’Alzheimer44, par exemple, les
premiers troubles cognitifs les plus atteints sont la mémoire épisodique, les fonctions exécutives et la vitesse de perception. L’attention les fonctions visuo-spatiales et la mémoire immédiate ne sont pas atteints dans les premières phases de la maladie contrairement au « Brain Fog ».
Pourtant, les outils d’évaluation utilisés présentement pour évaluer et identifier le Brain Fog sont ceux créés pour l’évaluation des troubles cognitifs chez les personnes âgées. Non seulement ils ne sont pas adaptés à la population avec un cancer, mais en plus ils ont des limites psychométriques importantes21, 45
Le MoCA est l’un d’entre eux, sa sensibilité est de 90% chez les personnes âgées, mais une différence importante4, 8, 41, 46 a été mise en évidence entre les signes subjectifs du Brain Fog
(rapportés par les patients atteints de cancer) et les signes objectifs rapportés par des questionnaires tels que le MoCA. Son utilisation chez cette population a été investiguée ; certaines études ont démontré qu’il était possible de se fier au MoCA47-49, mais l’analyse des qualités psychométriques de
ce test qui est acceptable dans une population âgée50 démontre plusieurs limites dans une population
avec un cancer17. Parmi ses limites, le MoCA montre une incapacité à détecter les troubles légers.
Son échelle de mesure n’est pas linéaire et présente des niveaux intermédiaires insuffisants. Devant ce manque24 de disponibilité de tests cognitifs adaptés aux patients avec un cancer, l’analyse
Rasch18, 51 des propriétés psychométriques d’un questionnaire cognitif générique a été conduite afin
de développer un questionnaire capable de pallier les limites des questionnaires actuels et d’apporter un test cognitif adapté et fiable. La modélisation Rasch basée sur la théorie des réponses aux items permet de fixer les conditions nécessaires pour qu’un questionnaire soit une réelle échelle de mesure52, 53. Il assure la linéarité de l’échelle de mesure afin de permettre une interprétation fiable
des résultats et permet d’apprécier les qualités du test, telles que sa précision, sa fiabilité et l’influence de biais externe sur les scores. Grâce à ce type de modélisation, les items les plus adaptés, discriminants et ajustés sont identifiés afin que le questionnaire construit soit le plus fiable possible. Si les items sont ajustés au modèle Rasch, ils composent une échelle linéaire avec des intervalles égaux qui mesure une seule dimension.
Le développement d’outil d’évaluation cognitive adapté aux troubles spécifiques liés au cancer ou à son traitement, permettrait non seulement une meilleure prise en charge de ces patients, une amélioration de leur qualité de vie et comblerait le manque actuel de mesure fiable et précise des fonctions cognitives. Ceci apporterait un outil de référence pour les recherches dans ce domaine en particulier.
2. Chapitre 2 : Hypothèse de recherche et objectifs
2.1. Hypothèse de recherche
L’analyse Rasch des propriétés psychométriques d’un questionnaire cognitif générique de patients avec un cancer permettra de développer un test cognitif adapté à cette population qui est une réelle échelle de mesure linéaire, fiable, précise, rapide et facile à administrer
2.2. Objectifs principaux de recherche
Objectif général : Développement d’un questionnaire cognitif bref adapté à une population de patients avec cancer, FaCE (the Fast Cognitive Evaluation), à partir de l’amélioration des propriétés psychométriques d’un questionnaire cognitif générique, basé sur les troubles cognitifs décrits chez les patients avec un cancer, avec la modélisation Rasch.
Objectifs spécifiques détaillés :
- Évaluer la capacité des patients à répondre à chacune des questions du test. - Évaluer le temps nécessaire pour répondre au test.
- Évaluer la difficulté d’administration du test.
- Évaluer les qualités générales de l’échelle de mesure avec la modélisation Rasch (linéarité, dimensionnalité, objectivité).
- Identifier les items les plus ajustés et discriminants de chaque aspect cognitif évalué avec la modélisation Rasch pour les conserver dans le questionnaire.
- Évaluer les propriétés psychométriques de l’échelle de mesure avec la modélisation Rasch (précision, fiabilité).
3. Chapitre 3 : Modélisation Rasch
3.1. Notions générales sur les qualités d’un questionnaire et de la modélisation Rasch
Afin, de comprendre ce qu’est une modélisation Rasch, il est important de se familiariser avec les propriétés d’un questionnaire et les impératifs d’un outil pour qu’il soit considéré comme un outil ou une échelle de mesure.
Un questionnaire est un outil de classement ou de mesure d’une caractéristique. Il permet d’ordonner des objets ou sujets selon une propriété ou aptitude choisie. Presque tous les questionnaires ou tests permettent ainsi de situer un sujet par rapport à un autre. Cependant, tous les outils de mesure n’ont pas les mêmes possibilités et ne mènent pas tous au même résultat. En sciences de la santé, le domaine concerné par cet ouvrage, l’objectif est de mesurer un trait latent des sujets. Dans le cas de ce présent projet en particulier, il s’agit des aptitudes cognitives. Afin d’ordonner les sujets en fonction de leur capacité, il est facile d’utiliser des questionnaires « standards » (qui ne répondent pas aux exigences d’une échelle de mesure) et il ne serait pas erroné de les classer les uns par rapport aux autres (ce sujet est meilleur que l’autre, car il a un score total supérieur). L’erreur serait, d’utiliser ces outils pour faire des comparaisons arithmétiques entre les sujets (exemple : 2 fois plus capable). Ainsi, créer un questionnaire en vue de mesurer un trait latent n’est pas aussi simple qu’il n’y paraît à première vue. Il ne suffit pas de faire l’addition des questions ou items réussis et d’en faire un score total. Une telle échelle ne ferait qu’ordonner les sujets les uns par rapport aux autres, il s’agirait dans ce cas d’une échelle ordinale.
Pour qu’une échelle puisse comparer des sujets entre eux de sorte qu’il soit possible d’estimer mathématiquement cette relation et qu’elle soit considérée une échelle linéaire, il lui est nécessaire de posséder une unité de mesure constante. Dans une telle échelle, contrairement aux échelles ordinales, il est donc possible d’affirmer que la quantité de changement entre 2 et 3 est la même qu’entre 3 et 4. C’est-à-dire qu’une perte cognitive de 3 points de 6 à 3 signifie la même dégradation des fonctions cognitives que si le score passait de 9 à 6.
De plus, cette échelle ne doit pas avoir de zéro absolu. Par exemple, dans les instruments de mesure de la température gradués en Celsius ou Fahrenheit, le zéro est placé de manière conventionnelle. Ainsi, un sujet qui, dans le type d’échelles qui nous intéresse, se classerait à zéro ne signifierait pas qu’il ne possède aucune aptitude cognitive, mais qu’il en possède bel est bien une, mais en dehors du seuil d’aptitude cognitive mesurée. Seules les échelles avec un point d’origine peuvent avoir un zéro absolu, comme dans le cas de l’échelle de température en Kelvin.
Une façon utilisée pour contourner les limites d’une échelle ordinale est d’attribuer aux items de celle-ci des coefficelle-cients de pondération, mais cette technique ne fait que prendre en considération la
difficulté théorique d’un exercice sans considérer d’autres paramètres pouvant influencer la réussite ou l’échec. Ainsi, il peut arriver que l’aptitude du sujet à répondre à une question puisse aussi dépendre de la réussite à une autre question. Il est ici question de la dépendance inhérente entre les items de tout questionnaire qui, si elle n’est pas prise en considération, dévie la mesure principale de l’échelle et détériore sa qualité essentielle qui est de donner un score total juste.
Face aux limitations des échelles numériques ordinales et des insuffisances de l’approche par attribution de coefficient de pondération, la modélisation Rasch permet de surmonter les premières et d’éviter les dernières. La modélisation Rasch fait partie de la famille des modèles probabilistes et particulièrement de ceux basés sur la réponse aux items. Elle permet de développer une échelle réellement linéaire mesurant une variable d’intérêt (dans le cas de cette étude, la capacité cognitive) à partir d’un questionnaire comprenant plusieurs items. Ainsi, la somme des valeurs des items composant le questionnaire est un score numérique « brut » et ne permet que d’ordonner les individus selon une échelle numérique ordinale. La modélisation Rasch permet la conversion de la valeur de chaque item en score numérique « relatif » créant une échelle de mesure linéaire à intervalles égaux.
Ce type de modélisation est le fruit du travail du mathématicien Danois Georg Rasch qui fut le premier, en 1960, à l’utiliser pour mesurer l’aptitude à la lecture18, 19. Il a démontré que la probabilité
de réussite à un item augmente de manière continue en fonction du niveau de la capacité de la
personne à réussir le test.
Comme il sera expliqué plus en profondeur plus bas, le principe majeur de ce type de modèle est que plus l’aptitude d’un sujet est grande, plus grande est sa probabilité de réponse correcte à un item, et vice versa. La probabilité de réussite est donc la probabilité de la différence entre l’aptitude du sujet et la difficulté de l’item.
3.2. Notions statistiques de la modélisation Rasch
La modélisation Rasch peut s’exécuter selon plusieurs formulations : La formulation dichotomique, la formulation polytomique54 dont le modèle « rating scale »55 et le modèle « partial credit »56. Il existe
aussi le modèle Rasch de comptage selon la loi de Poisson51 et le modèle binomial selon la loi de
Bernouilli53, 55. Enfin il existe un modèle Rasch dit « modèle à plusieurs facettes » où l’aptitude du
sujet et la difficulté de l’item ne sont pas les seuls paramètres pris en compte57. Dans cet ouvrage,
l’utilisation de la formulation dichotomique du modèle Rasch sera utilisée.
Une modélisation dichotomique signifie que tous les items mesurant la variable d’intérêt sont à deux niveaux. Conventionnellement, le niveau 0 signifie un échec ou une réponse négative, le niveau 1 signifie la réussite ou une réponse positive.
Selon le modèle Rasch la probabilité de réponse (PAX) d’une personne (A) à un item (X) est calculée
en fonction de la capacité de cette personne (CA) et de la difficulté de l’item (DX). Ces deux
paramètres sont les « points d’identité » de la probabilité. Puisque les items sont tous à deux niveaux, la probabilité de succès (PAX1) est le complément de la probabilité d’échec (PAX0).
Le concept principal sur lequel se base la modélisation Rasch est que plus la capacité du sujet est importante plus sa probabilité d’une réponse correcte à un item est haute, et vice versa. Conceptuellement, il est possible de formuler cette relation de la manière suivante : si la capacité de la personne A (CA) est supérieure à la difficulté de l’item X (DX) la probabilité de réussite (PAX1) est
supérieure à 0,5 (50% de chances).
Mathématiquement, l’ensemble des probabilités est défini de la façon suivante : Si : Ca > DX donc CA - DX > 0 alors PAX1 > 0,5 et PAX0 < 0
Si : Ca < DX donc CA - DX < 0 alors PAX1 < 0,5 et PAX0 > 0
Si : Ca = DX donc CA - DX = 0 alors PAX1 = 0,5 = PAX0
Par définition, toute probabilité varie de 0 à 1 (0% à 100%). Le résultat d’une différence mathématique entre deux nombres réels peut, lui, varier d’une différence infiniment petite à infiniment grande (-∞ à +∞). Afin que les deux paramètres de l’équation précédente (PAX et CA – DX) varient selon la même
plage, une fonction exponentielle est appliquée dans un premier temps pour imposer une borne inférieure, puis un facteur de normalisation est introduit pour limiter la borne supérieure.
Dans : PAX = (CA – DX)
0 < PAX < 1 et -∞ < (CA – DX)< +∞,
0 < exp (CA – DX) < +∞ (application de la fonction exponentielle
0 < [exp (CA – DX)] / [1 + exp (CA – DX)] < 1 (introduction d’un facteur de normalisation)
Ainsi, l’équation précédente dévie : PAX1 = [exp (CA – DX)] / [1 + exp (CA – DX)]
Et,
PAX0 = [1 - PAX1 = 1] / [1 + exp (CA – DX)]
Le rapport entre la probabilité (PAX1) (réponse correcte) et la probabilité (PAX0) (réponse incorrecte)
est appelé le rapport de vraisemblance de réussite (RVAX1) du sujet A à l’item X. Il peut être exprimé
mathématiquement comme suit :
Afin de normaliser ce rapport, le logarithme népérien est introduit dans l’équation :
Ln (RVAX1) = Ln (PAX1 / PAX0) = Ln {[(exp (CA – DX)) / (1 + exp (CA – DX))] / [1 / (1 + exp (CA – DX))]}
La résolution de cette équation conduit à Ln (PAX1 / PAX0) = CA – DX Par le fait même, CA – DX peut
être exprimé en Logit (logarithme odds unit) du rapport de vraisemblance.
Ainsi, l’unité de mesure utilisée par la modélisation Rasch est « le Logit » de la différence entre la capacité du sujet à répondre à un item spécifique et la difficulté de celui-ci (RVAX1).
De plus, si une capacité déterminée est comparée entre deux sujets A et B (CA - CB) à partir d’un
instrument de mesure basé sur la modélisation Rasch, la différence entre leur capacité respective serait :
CA - CB = (CA – DX) – (CB – DX) = LogitAX – LogitBX
Notons donc que le Logit en tant que mesure utilisée dans une modélisation Rasch correspond à la différence entre un seul paramètre, soit la capacité des sujets (CA - CB). C’est ce qui est appelé
l’unidimensionnalité statistique d’un instrument.
Cette formule est valable, quel que soit le niveau de capacité des sujets comparés.
En pratique, l’intérêt de considérer le « Logit » comme unité de mesure réside dans le fait de pouvoir certifier que la différence d’une «unité» de capacité entre deux sujets est constante quel que soit le niveau où cette différence se situe dans l’échelle de mesure.
La modélisation Rasch en plus de situer sur une courbe les sujets en fonction de leur capacité permet de situer de façon linéaire sur l’échelle les items en fonction de leur difficulté. L’espacement de deux sujets dont la différence de capacité est égale à exactement une unité Logit, correspond à la quantité d’augmentation du rapport de vraisemblance d’un item pour que la capacité des deux sujets devienne égale. Cette quantité d’augmentation nécessaire est de 2,71 (exp(1)) exactement. De la même façon, si deux items sont espacés d’une unité Logit exactement, cela signifie que leur difficulté diffère d’une unité Logit. Dans ce cas, pour qu’un sujet réussisse aux deux items, les rapports de vraisemblance de réussite du sujet à chacun des deux items devraient être égaux. Pour ce faire, il faudrait que le rapport de vraisemblance de réussite à l’item le plus difficile diminue de 2,71 équivalent à la diminution d’une unité Logit.
Cette différence unitaire du Logit est vraie, quel que soit l’endroit où le sujet se situe dans l’échelle de mesure. C’est-à-dire que, quelle que soit la capacité du sujet en fonction d’un item donné ou quelle que soit la difficulté de l’item en fonction de la capacité d’un sujet. C’est ce principe qui est appelé « Linéarité », pour plus de détails se référer au point 5.3.1.4 de la partie méthodologie.
Connaissant la probabilité de réussite et d’échec d’un sujet à un item (tel que vu précédemment). Il est possible de calculer le score attendu de chaque sujet à chacun des items.
Il est égal à la probabilité de réussite d’un sujet à un item. La relation entre le score attendu d’un item et la mesure réelle d’un sujet est schématisée par une courbe appelée « courbe caractéristique de l’item » (CCI) (figure1). Dans le cas d’une formulation dichotomique du modèle, les courbes de chaque item sont identiques et parallèles, car le point de coupure entre réussite et échec est toujours à une probabilité égale à 0.5. Cette courbe modélise la relation entre la capacité cognitive d’un sujet, dans le cas de cet ouvrage, et sa probabilité de réussite à un item. La probabilité de réussite à un item augmente de façon monotone et continue en fonction de la capacité du sujet. Cette relation est le principe fondamental de la modélisation Rasch. En abscisse, on retrouve la différence entre l’aptitude du sujet et la difficulté d’un item (CA – DX), autrement dit la probabilité de réussite du sujet
à l’item.
Tel que constaté sur la figure 1 représentant une CCI, plus la différence (CA – DX) est positive (ce qui
signifie aussi que la capacité du sujet est supérieure à la difficulté de l’item) plus la probabilité de réussite est haute et tend vers 1, et vice versa.
Un exemple simple peut être considéré afin d’illustrer ces principes de base. Admettons que 100 personnes passent un test composé de 5 questions et que 10 personnes d’entre elles obtiennent le même score total égal 3. Il serait erroné de penser que leur aptitude est similaire, car plusieurs combinaisons de réponses sont possibles et de ce fait, des probabilités de réussite à chaque item différentes. Ainsi, pour un item donné de ce test, la réussite ou l’échec à cet item dépend de l’aptitude du sujet à y répondre et de la difficulté propre de cet item, chaque sujet ayant une aptitude particulière et chaque item, une difficulté propre. Si à un item donné, 3 des 10 personnes qui ont un score total égal à 3 ont répondu correctement, la probabilité de répondre correctement à cet item est de 3/10. Si, toujours pour ce même item, mais cette fois pour 10 personnes qui ont obtenu un même score total égal à 4 et que 6 de ceux-ci y ont répondu correctement, la probabilité de réussite d’un de ces sujets à y répondre correctement est de 6/10.
Par la modélisation Rasch, les probabilités sont formulées d’une manière continue résultant en une courbe sigmoïde : la probabilité de réussite d’un item variant de manière continue permettant de différencier les niveaux d’aptitude sur l’échelle de mesure.
Ce principe du modèle Rasch est la linéarité et la répartition en continu de la mesure (ce point sera détaillé dans le chapitre « Méthodologie »).
Un autre principe important de la modélisation Rasch est l’objectivité spécifique. Il a été convenu que ce type de modèle illustre la probabilité de réussite ou d’échec selon deux qualités : l’aptitude du sujet et la difficulté de l’item. Le principe d’objectivité spécifique signifie que ces deux paramètres ne s’influencent pas. Autrement dit, l’aptitude du sujet est indépendante de la difficulté de l’item. Enfin, l’unidimensionnalité du test est, aussi, un principe majeur de la modélisation Rasch. Elle est définie comme la capacité d’un outil de mesure à évaluer une seule qualité de la propriété mesurée. Dans les paragraphes précédents, cette notion a été abordée. La modélisation Rasch, prend en compte la capacité ou l’aptitude des personnes uniquement, lors de la comparaison des performances de 2 sujets à un item donné. Cette propriété est une notion statistique de probabilité. En pratique il est difficile, voire, impossible, d’isoler une seule qualité d’un sujet afin de la mesurer elle uniquement. Ainsi, cette notion d’unidimensionnalité est un idéal difficile à atteindre, voire même impossible, mais il est important et primordial de s’en approcher au maximum lors de la construction d’une échelle de mesure basée sur une modélisation Rasch.
Lors de la mesure de la longueur d’une table, par exemple, il est facile de certifier que le nombre rapporté concerne sa longueur uniquement et qu’elle n’est influencée par aucune autre qualité de cette table (hauteur, largeur, etc.).
Lors de la mesure d’un trait latent, cela devient un sujet à discussion. Si le but d’une étude est de mesurer à quel point les enfants aiment aller au zoo. La mesure pourrait être influencée par le fait d’apprécier d’être en groupe et de partager des moments plaisants lors des trajets. De même, le fait
d’être en plein air pourrait influencer la mesure obtenue, ou encore, la phobie des animaux, etc. Ainsi, nous ne pouvons pas être certains que la réponse, en demandant à un groupe d’enfants à quel point ils aiment aller au zoo, ne soit pas influencée par d’autres paramètres. Le mieux est de s’assurer que la question est posée dans un contexte limitant l’influence d’autres paramètres, ou de la mesurer par des questions plus précises. Si la mesure est le plus proche possible d’une réponse non influencée par d’autres caractères, en d’autres termes, une réponse unidimensionnelle, l’objectif d’isoler la qualité mesurée et de la mesurer en se focalisant dessus est atteint et ainsi, limitant l’influence d’autres caractères.
Lors de l’analyse de cette notion d’unidimensionnalité, il faut que la performance au test soit influencée de manière dominante par la variable mesurée ou que les dimensions surajoutées sous des « sous-dimensions » qui forment un ensemble menant à la mesure d’une seule propriété58 (par
exemple, la longueur et la largeur d’une table sont deux dimensions différentes, mais elles sont indissociables pour mesurer la forme globale de la table). L’unidimensionnalité est donc un concept relatif58, 59.
La mesure concernée par le questionnaire FaCE est l’aptitude cognitive des sujets. Une capacité cognitive comporte plusieurs dimensions. Si les dimensions qui influencent la mesure du FaCE sont des dimensions prévues ou attendues, la mesure de l’item sera considérée unidimensionnelle conceptuellement même si la modélisation Rash suggère le contraire. Ces possibles dimensions surajoutées composent le statut cognitif global des sujets et ne font que préciser des aspects propres à la capacité cognitive. En outre, il est évident que si pour un item donné, l’existence d’un autre paramètre, tel que la capacité motrice, prend le dessus sur la capacité cognitive, ce dernier sera retiré de l’échelle, car il faussera la mesure.
Ainsi, même si une capacité cognitive implique plusieurs composantes, il peut être utile de considérer sa mesure comme unidimensionnelle. Cette notion d’unidimensionnalité est largement sujette à la subjectivité des évaluateurs et à ce qu’on s’attend à mesurer.
L’unidimensionnalité de l’ensemble du questionnaire est explorée par la variance résiduelle standardisée(VRR). C’est la somme des carrés des analyses Rasch observées et prédites. Elle est basée sur la variance expliquée par la mesure, celle expliquée par les sujets, celle expliquée par les items et enfin celle non expliquée par l’un des derniers paramètres.
Une VRR est la variance équivalant à la différence entre la variance attendue du modèle et la variance observée du modèle60, 61. Cette variance résiduelle est standardisée pour correspondre au nombre
des items compris dans l’échelle. Elle indique de combien d’item le modèle s’éloigne de l’unidimensionnalité. L’unité mesurant cette différence est appelée l’ « eigenvalue ». Si l’eigenvalue est égale à 2,8 ou moins, ceci implique qu’il y a environ 2,8 items qui dévient le modèle par l’implication d’au moins une autre dimension. Dans ce cas, cette différence est imputée au hasard et
n’a pas besoin d’être plus amplement investiguée. Une dimension surajoutée ne peut être considérée réelle que si au moins 3 items forment un ensemble considéré assez important pour dévier la mesure de la variable à l’étude. Ainsi, si l’eigenvalue est supérieure à 2,8, il est recommandé d’investiguer les items concernés. Les unités d’eigenvalue sont ajustées au nombre d’items de l’échelle afin que leur interprétation ait une logique pratique.
Avant de commencer à investiguer les items suspectés d’ajouter une dimension non attendue au modèle, il faut examiner les proportions de variances du modèle.
Une variance observée expliquée par le modèle dont la valeur est très supérieure à la valeur de la variance observée inexpliquée par le modèle atténue l’importance d’une dimension surajoutée présumée. Sachant que la variance expliquée par le modèle est composée de la variance expliquée par les sujets, celle expliquée par les items et celle expliquée par la mesure, il va de soi qu’un nombre important d’items peut mimer une possible multidimensionnalité. De même que des sujets peu nombreux.
Comme une espèce d’effeuillement du modèle, la modélisation Rasch va procéder en analysant le modèle de la construction la plus éloignée de l’unidimensionnalité, ce qui est appelé « le premier contraste », à une construction de plus en plus proche du modèle unidimensionnel. Un « contraste » dans l’exploration de la dimensionnalité est le contraste entre les items qui s’éloignent le plus du modèle de part et d’autre de la construction et qui seraient suspects d’ajouter une ou plusieurs dimensions non attendues. Afin d’apprécier l’importance de chaque contraste, le nombre d’items qui forme ces ensembles éloignés du modèle unidimensionnel doit être apprécié. Pour ce faire, chaque eigenvalue supérieure à 2,8 est suspecte. L’étape qui suit consiste à comparer la proportion de variances observées inexpliquées du modèle qui est attribuable aux items identifiés lors de chaque contraste à la variance observée expliquée par les items. Si la première est très inférieure à la seconde, l’importance d’une potentielle dimension surajoutée est atténuée. Les ensembles d’items les plus éloignés du modèle sont identifiés comme des groupements. Trois groupements sont identifiés pour chaque contraste, le premier et le dernier correspondent aux items aux deux pôles (qui s’éloignent le plus du modèle), et l’autre groupement identifie le reste des items du test. Les groupements des deux pôles doivent être identifiés. Ce sont les items qui sont susceptibles d’ajouter une dimension au test. Un test de corrélation entre chacun des groupements, deux à deux, permet d’évaluer si les items mesurent de la même façon la capacité des sujets. Si l’indice de corrélation désatténuée (qui fait fi de l’erreur standard) est entre 0,5 et 1, les items des groupements comparés mesurent de la même façon la capacité des sujets et appartiennent à la même dimension. Si l’indice de corrélation est inférieur à 0,5, une dimension influençant la mesure est très probable et correspond aux items de l’un des groupements d’items les plus éloignés du modèle. Les contrastes suivants sont examinés de la même façon jusqu’à ce que l’eigenvalue du contraste en question soit inférieure à 2,8.
Après avoir identifié sur la carte des contrastes les groupements d’items suspects, leur dimensionnalité propre doit être explorée, d’abord en examinant la Courbe caractéristique d’item (CCI) de chaque item. Si une tendance opposée à la tendance de réponse globale (correspondant à la courbe sigmoïde caractéristique, figure1.) est constatée, cela signale, sans toutefois le certifier, qu’une potentielle dimension autre que celles mesurées compose la réponse à un item. L’analyse de la corrélation statistique entre les items des groupements suspects par l’indice de corrélation de Pearson ou l’indice de corrélation désatténuée (qui fait fi de l’influence des erreurs de mesure pour calculer la vraie corrélation) permet de certifier la présence ou absence d’une dimension surajoutée. Plus les statistiques de corrélation sont proches du zéro, plus la corrélation est inexistante entre les items, donc, le groupement d’items mesure une dimension indépendante des autres items et leur impact est suffisamment important pour dévier la mesure (la mesure n’est pas focalisée sur le trait mesuré seulement) du modèle par une dimension surajoutée. La suite de l’analyse consiste à juger en fonction de l’importance de la dimension surajoutée, si celle-ci est une dimension acceptable qui est considérée comme faisant partie de la dimension mesurée par la variable étudiée, ou si elle n’est pas acceptable et devrait faire l’objet d’une échelle de mesure indépendante.
En résumé, l’unidimensionnalité selon le modèle Rasch est le fait de focaliser ou préciser la mesure de la propriété du sujet qui est étudiée (ou mesurée), sans prendre en compte les autres possibles caractéristiques qui pourraient faire dévier, ou dégrader la qualité de la mesure.
Une possible multidimensionnalité peut être explorée par la variance résiduelle standardisée qui est le résidu généré par la différence entre la variance observée et celle attendue.
L’existence d’une multidimensionnalité doit être investiguée lorsqu’un groupement de 3 items ou plus contraste avec le modèle unidimensionnel. L’unité illustrant le nombre d’item est appelée l’« eigenvalue ».
L’identification et l’investigation de l’importance d’une possible multidimensionnalité se basent sur la comparaison de la variance observée expliquée par les items à celle inexpliquée à chaque contraste. Si l’eigenvalue est supérieure ou égale à 3, cela signifie qu’il y a un groupement d’au moins 3 items qui constitue une possible dimension surajoutée. Cette possibilité est assez importante pour justifier le fait d’investiguer davantage ou d’amener des ajustements au modèle. Il faut s’intéresser à la carte des items de chaque contraste. Identifier les groupements d’items les plus éloignés verticalement et qui semblent former un groupement. Si les items identifiés sont corrélés et que cette corrélation est avérée, il faut la quantifier grâce au coefficient de corrélation de Pearson, ou mieux encore par le coefficient de corrélation désatténuée qui est une corrélation atténuée (corrigée par l’erreur de mesure) dont on supprime l’atténuation et donc la part de la valeur de la corrélation attribuable à l’erreur de mesure. Elle est ainsi nommée corrélation désatténuée et elle a toujours une valeur plus importante (plus extrême dans le cas des analyses de dimensionnalité) que la corrélation observée.
Si ces coefficients sont proches de 1, une forte corrélation est probable entre les items du groupement. Ceci pourrait signifier que la dimension apportée par ces items est assez importante pour faire dévier la mesure de la qualité étudiée. La question quant au fait que la possible dimension surajoutée fait partie intégrante de la mesure à l’étude est sujette à discussion. Des experts du sujet doivent se réunir et décider par consensus si, oui ou non, la deuxième dimension identifiée est réellement une dimension surajoutée ou est-ce simplement une partie de la dimension de la mesure de la qualité étudiée.
La vraie question à se poser est : cette possible deuxième dimension va-t-elle améliorer la qualité de mesure du trait étudié ou va-t-elle au contraire la dévier? Est-il nécessaire de supprimer les items des groupements identifiés de l’échelle principale pour les mesurer dans une échelle indépendante? Si les réponses aux questions soulevées sont :
- Oui, les groupements d’items apportent une dimension qui ne fait pas partie de la mesure principale.
- Oui, le fait de laisser ces items dans notre échelle dégraderait la mesure de la qualité à l’étude. - Oui, ces items mériteraient d’être évalués dans une échelle indépendante de l’échelle principale.
Alors, l’échelle de mesure principale est multidimensionnelle en pratique et il est nécessite d’effectuer des changements à l’échelle.
Si au contraire, ces items définissent une dimension faisant partie intégrante de la mesure étudiée, ils ne nécessitent pas une échelle d’évaluation indépendante puisqu’ils améliorent la qualité de la mesure à l’étude. Alors, l’échelle de mesure principale est considérée unidimensionnelle en pratique et ce peu importe les statistiques. Ainsi, les analyses statistiques servent de guide exploratoire, sans toutefois permettre de confirmer l’existence d’une unidimensionnalité.
Les notions statistiques importantes de la modélisation Rasch sont en résumé:
- Une échelle n’est pas nécessairement une échelle de mesure linéaire, et ce particulièrement lorsqu’il s’agit de mesurer des traits latents (capacité cognitive, en ce qui concerne cet ouvrage), ce qui rend impossible la réalisation de comparaisons arithmétiques.
- Le recours à une modélisation Rasch permet de convertir des scores totaux en probabilités de réussite ou d’échec et de les formuler selon une unité de mesure (le Logit) qui transforme un questionnaire « standard » (ordinal) en une mesure linéaire à intervalles égaux.
- Le modèle Rasch prend en compte deux paramètres, l’aptitude propre du sujet à réussir un item donné et la difficulté de cet item. Le principe de base est que la probabilité de réussite d’un sujet à un item augmente plus sa capacité de réussite en lien avec le trait mesuré est importante.
- Les deux paramètres précédents sont indépendants l’un de l’autre ce qui confère à la mesure une objectivité spécifique, dénommée «invariance».
4. Chapitre 4 : Structure du questionnaire cognitif générique analysé
4.1.
Construction du questionnaire cognitif génériqueLe questionnaire cognitif générique (Annexe 1) a été créé en s’inspirant des résultats obtenus précédemment de l’analyse des propriétés psychométriques du MoCA17 administré à une population
de patients atteints du cancer grâce à la modélisation Rasch. Cette analyse a permis de conclure que le MoCA avait plusieurs limites :
Un effet plafond : c’est une incapacité à distinguer entre eux les sujets avec des déficits très légers. Plus simplement, une fois le score maximal du MoCA atteint il est impossible de distinguer les sujets qui auraient pu mieux performer de ceux qui étaient aux limites de leurs capacités. Prenant l’analogie d’un escalier, les patients avec un déficit léger se retrouveraient tous à la dernière marche, peu importe si certains sujets avaient la capacité de monter encore des marches supplémentaires.
Des niveaux de difficulté intermédiaires insuffisants : ceci signifie que le MoCA ne peut pas classifier adéquatement des sujets ayant des capacités cognitives distinctes à l’intérieur de ses valeurs possibles, ce même escalier manquant de marches. Si, par exemple, les marches 5 et 6 sont manquantes, tous les sujets capables de monter 4, 5 ou 6 marches se retrouvent tous à la 4ième marche. Ces deux derniers, pouvant théoriquement montrer 5 à 6 marches, seraient
considérés de façon erronée comme ayant une capacité équivalente à ceux ne pouvant monter qu’à la 4ième marche.
Après avoir identifié les limites du MoCA, la construction d’un questionnaire, le FaCE, qui puisse, en théorie, suppléer à ces lacunes s’imposait si l’on voulait disposer d’un instrument simple et rapide d’évaluation de la fonction cognitive des patients avec cancer n’ayant pas les limites du MoCA. La description détaillée du processus de développement du questionnaire cognitif générique analysé afin de développer le FaCE dépasse le cadre de ce mémoire.
En résumé, c’est en se basant sur les conclusions d’une revue de la littérature traitant des troubles cognitifs spécifiques aux patients avec un cancer, sur les propriétés psychométriques des instruments disponibles et sur l’opinion d’experts qu’un test cognitif générique a été développé. Théoriquement, ce questionnaire générique a été conçu de façon à comprendre des items plus difficiles à réaliser par les sujets que le MoCA afin d’éviter un effet plafond. De plus, certains items ont été modifiés et d’autres, ajoutés pour assurer des niveaux de difficulté intermédiaires suffisants afin de mieux classifier les sujets, entre eux. Enfin, certains items du MoCA ont été retirés, car ils évaluaient des domaines de difficultés cognitives non reliés au cancer et à son traitement. L’évaluation abstraite en est un exemple, son atteinte est présente lors des démences62, mais ne fait
l’analyse des propriétés psychométriques du MoCA17 a identifié une redondance entre le premier
item évaluant la capacité d’abstraction et le dessin de l’horloge et entre le deuxième item évaluant la capacité d’abstraction et le TMT-B.
Le questionnaire cognitif générique (Annexe 1) évalue avec 24 questions, 6 dimensions cognitives, résultats en un score maximal de 38 points :
L’orientation temporo-spatiale La mémoire immédiate
Les fonctions visuo-spatiales et exécutives L’attention et la concentration
Langage et idéation. Le rappel différé
4.2. Description générale du questionnaire cognitif générique
Les questions et les tâches pour chaque aspect sont ordonnées de la plus facile à la plus difficile.
4.2.1. Aspect orientation temporo-spatiale
Le score maximal possible est de 6 points.
Six questions sont posées au participant : la date du jour de l’entrevue, le mois, l’année, la journée de la semaine, la saison et enfin la ville où l’entrevue se déroulait. Ces questions ont été choisies pour leur niveau de difficulté relativement bas, afin de détecter les déficits cognitifs très importants et, aussi, de permettre au participant de relaxer dès le début du questionnaire puisque ces questions sont simples à réaliser et n’entrainent pas un sentiment d’inaptitude courant chez les patients lorsque leurs fonctions cognitives sont évaluées. Cela permet que le niveau de stress ou d’anxiété soit amoindri limitant ainsi l’influence de ces facteurs sur la qualité des réponses. Un point est accordé par bonne réponse avec un maximum de 6 points.
4.2.2. Mémoire immédiate
Le score maximal possible est de 7 points.
Deux tâches évaluent cet aspect : l’assistante de recherche nomme 7 mots, chacun représente une chose ou un concept différent (« Jambe » - une partie du corps; « Laine » - une matière; « Château » - un bâtiment ou édifice; « Tulipe » - une fleur; « Bleu » - une couleur; « Cheval » - un animal; « Patate » - un légume). Afin de réussir cette tâche au score maximal, le participant doit se souvenir et répéter les 7 mots, l’ordre n’ayant pas d’importance. La deuxième tâche consiste à répéter le processus de la tâche précédente une deuxième fois (répéter 7 mots après que l’évaluateur les ait cités à nouveau).
Contrairement au MoCA, cette tâche contient 7 mots et qu’il faut remarquer que chaque mot répété avec succès alloue un point au score de cette tâche jusqu’à un maximum de 7 points. Cette différence a été introduite afin d’aller chercher des items avec des difficultés au haut de l’échelle, ce que le MoCA ne faisait pas bien.
4.2.3. Fonctions visuo-spatiales et exécutives
Le score maximal possible est de 6 points.
Trois tâches indépendantes permettent d’évaluer cet aspect : la première est le test « Trail Making
Test partie B » qui consiste à relier un chiffre et une lettre en dessinant des flèches tout en les
alternant dans un ordre croissant. Le premier chiffre est le « 1 », le dernier, le « 8 », la première lettre est le « A » et la dernière, le « H ». Le début de la tâche est donné (le « 1 » relié au « A » et le « A » relié au « 2 » afin qu’elle soit bien comprise. Le score maximal de cette épreuve est de 1 si la tâche est réussie jusqu’au bout et sans erreur.
La deuxième tâche consiste à reproduire le dessin d’un cube en 3 dimensions identique au modèle présenté au participant. Le score maximal pour cette épreuve lorsque la reproduction du cube est sensiblement identique au modèle est de 2. Si le dessin n’est pas sensiblement reproduit, mais que les erreurs sont mineures, 1 point est accordé. Aucun point n’est accordé par ailleurs.
La dernière tâche est de dessiner une horloge avec tous les chiffres et d’indiquer par des aiguilles 14h40. Un score maximal de 3 est attribué lorsque l’horloge est correctement dessinée (ronde, tous les chiffres présents et à la bonne place, une petite aiguille et une grande aiguille indiquant 14h40). L’absence de chaque élément entraine une perte d’un point. Aucun point n’est accordé si tous les éléments sont manquants.
4.2.4. Attention
Le score maximal possible est de onze (11) points (6 pour la première partie + 5 points pour la deuxième partie). Onze questions sont posées au participant comme suit :
Six questions pour la première partie de cette évaluation. Le participant doit répéter 4 chiffres qui lui sont nommés par l’assistante de recherche. Par la suite, le participant doit répéter d’autres chiffres nommés, mais en sens inverse (un exemple est donné au participant : « Si je vous dis « 1, 2, 3 »,
vous devez me répondre « 3, 2, 1 » ».) Cette répétition en sens inverse est demandée pour 3 chiffres,
puis 4, 5, 6, et 7 chiffres. 1 point est accordé pour chaque répétition correcte pour un total de 6 points. La deuxième partie de cette évaluation consiste à demander au participant de soustraire 7 du nombre « 101 », et de continuer à soustraire 7 du résultat obtenu jusqu’à ce que l’assistante de recherche lui demande de s’arrêter. 1 point est accordé pour chaque bonne réponse. Si le patient se trompe à la première soustraction, mais que lorsqu’il accomplit la deuxième soustraction à partir du résultat