Espaces vectoriels
25
0
0
Texte intégral
Figure
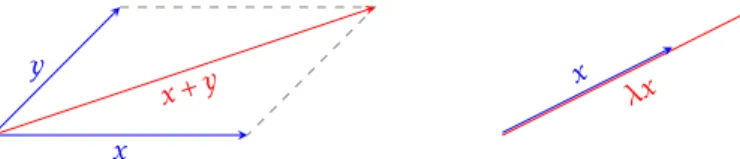
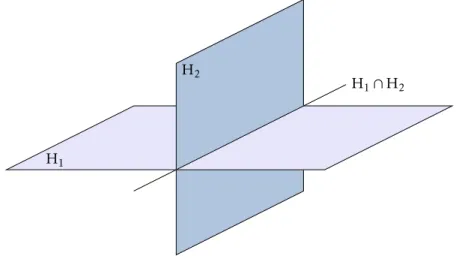
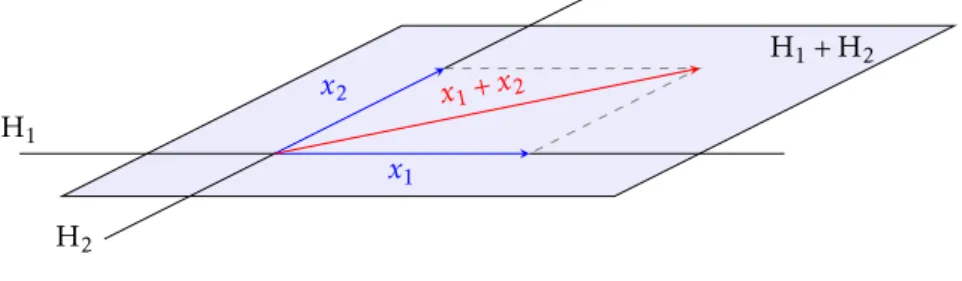
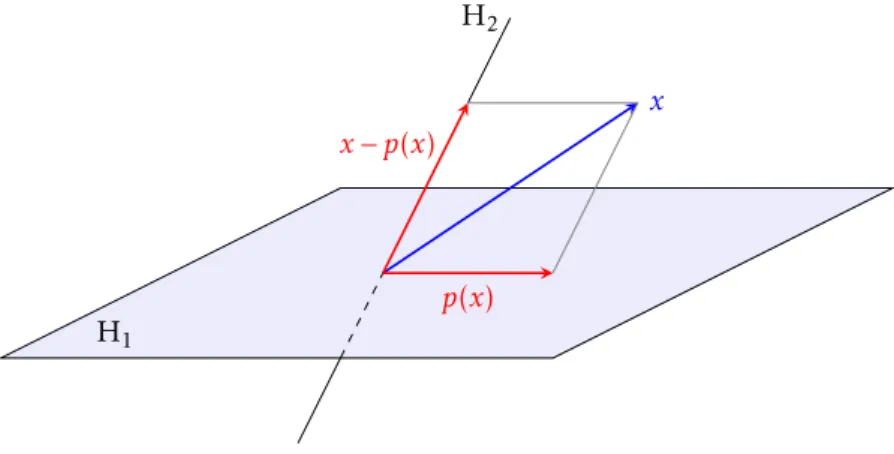
+3
Documents relatifs
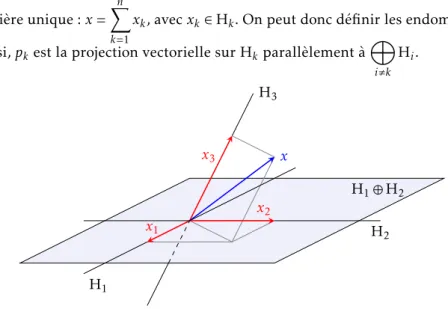
Il existe un et un seul plus petit sous-espace vectoriel (pour l’inclusion) de E contenant les vecteurs de F (ou contenant X) et noté Vect( F ) (ou Vect(X)). Vect F est l’ensemble
dans R 2 , la r´ eunion du premier et du troisi` eme quadrant est stable par multiplication externe mais pas par addition.. Et ¸ ca
Les ensembles suivants sont-ils des R - espaces vectoriels?. Si oui, en donner
Les ensembles suivants sont-ils des R - espaces vectoriels?. Si oui, en donner
Les ensembles suivants sont-ils des R - espaces vectoriels?. Si oui, en donner
[r]
[r]
x et y ne sont pas colinéaires, donc {x ; y} est libre et forme une base de F qui est de dimension 2.?. N° 11 ESPACES
