Extraction de nouvelles connaissances d'une imagevidéo indexée par le contenu: Implémentation d'un nouvel algorithme du Data Mining
Texte intégral
Figure






Outline
Documents relatifs
Avec cinq graduations intermédiaires au minimum, celui-ci donne 40 configurations possibles qui incluent les deux qui viennent d’être mentionnées.. Pour L variant de 24
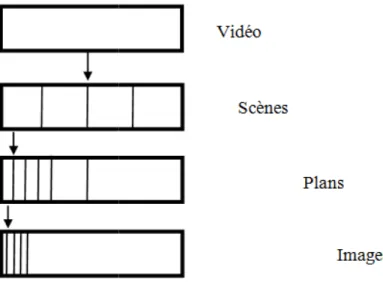
La méthode de segmentation que nous proposons d’étudier repose sur l’algorithme de calcul de l’arbre des composantes (algorithme développé au laboratoire A2SI). Travail
Obtenir une figure de diffraction (en utilisant des moyens très simples, peu coûteux) de manière à pouvoir déterminer le mieux possible la largeur d'une fente très fine
Cette phrase montre que Solvay prend appui sur son référentiel de compétences dans son nouvel accord de GPEC pour saisir les différentes sources de compétences : lors de la
Ils sont ensuite émis sans vitesse par la source S, puis accélérés par un champ électrostatique uniforme qui règne entre S et P tel que.. U sp
Vérification graphique : Utilisation de GeoGebra Il faut trouver la valeur du rayon du cylindre qui donne comme volume
Bousculé, apostrophé, harcelé, l'auditeur ne sait plus si le bulletin météorologique qui annonce la neige a trait à la journée d'hier ou à celle de demain ; et il se retrouve en
Des cellules qui n’ont jamais été exposées aux UV, sont prélevées chez un individu sain et chez un individu atteint de Xeroderma pigmentosum.. Ces cellules sont mises en
