Exploration opérationnelle de la prévision hydrologique
d’ensemble avec assimilation automatique de données
Thèse
Mabrouk Abaza
Doctorat en génie des eaux
Philosophiae doctor (Ph.D.)
Québec, Canada
iii
Résumé
Ce projet de recherche a pour but d’identifier une méthode d’assimilation automatique de données qui pourrait être utilisée dans le cadre de la prévision opérationnelle de crues. Le filtre de Kalman d’ensemble (EnKF) et l’assimilation variationnelle ont ainsi été comparés en premier lieu en utilisant le modèle GR4Jneige. Les résultats ont montré que l’EnKF fournit la meilleure performance pour tous les horizons de prévision lorsque comparé à différentes implantations de la méthode variationnelle. La performance de la méthode variationnelle varie toutefois d’un bassin à un autre. Les prévisions hydrologiques déterministes émises à partir de l’EnKF produisent une performance supérieure au scénario sans assimilation, ce qui n’est pas toujours le cas pour la méthode variationnelle. L’assimilation naïve des sorties ne donne pas des bons résultats au-delà du second jour de prévision.
L’EnKF a par la suite été mis en œuvre avec un modèle hydrologique semi-distribué (Hydrotel) afin d’améliorer les conditions initiales de la prévision hydrologique d’ensemble (PHE). La vérification de la qualité des PHE sur le bassin versant au Saumon, pour la période exempte de l’influence de la neige, a révélé une amélioration considérable de la performance et de la fiabilité par rapport aux résultats sans assimilation. L’assimilation manuelle fournit une performance similaire à l’EnKF, mais est beaucoup moins fiable que cette dernière. Les 1000 membres de la PHE générée par EnKF peuvent se réduire jusqu’à 50 sans perte de fiabilité ou de performance.
De bons résultats ont aussi été obtenus pour la période d’accumulation et de fonte de la neige, notamment par mise à jour de l’équivalent en eau de la neige en plus des variables identifiées précédemment : la teneur en eau du sol et l’écoulement terrestre.
Différents produits canadiens de prévision météorologique d’ensemble (PME) ont finalement été comparés pour évaluer l’impact de leur résolution spatiale sur la qualité de la PHE – ils ont aussi été comparés à des produits déterministes. Les résultats ont montré que la PME mène à une meilleure performance que les produits déterministes. Les PME globale et régionale partagent la même performance, par contre le produit régional s’est révélé plus fiable et a une meilleure capacité à caractériser l’incertitude de la prévision.
v
Abstract
The aim of this research project is to identify an automatic data assimilation method that could be used in an operational flood forecasting context. The Ensemble Kalman Filter (EnKF) and the variational assimilation method were first compared on the GR4Jsnow model. Results showed that the EnKF provides the best performance for all forecast horizons when compared to various implementations of the variational method. The performance of the variational method varied from one watershed to another. The deterministic hydrological forecasts issued from the EnKF generate better performance than forecasts without assimilation, which is not always the case for the variational method. The naïve output assimilation is not recommended for forecasts beyond a 2-day horizon.
The EnKF was next implemented on a semi-distributed hydrological model (Hydrotel) to improve the initial conditions of the hydrological ensemble predictions (HEP), for the snow-free flows on the au Saumon watershed. The verification of the quality of the HEP showed a considerable improvement in both performance and reliabilty in comparison to the results of model without assimilation. Manual assimilation provides performance similar to the EnKF, but with much less reliability. The 1000-member HEP obtained from the EnKF can be reduced up to 50 members without any loss of reliability or performance.
Similar results were obtained for snow accumulation and melt periods, especially when updating the snow water equivalent in addition to the state variables previously identified for the snow-free flows, namely the soil water content and the land flow.
Different Canadian meteorological ensemble prediction systems (EPS) were also compared to assess the impact of spatial resolution of these systems on the quality of the HEP – they were also compared to deterministic products. The results showed that EPS are superior to the deterministic products. Global and regional EPS share the same performance, in contrast the regional product that turned out more reliable and characterize the uncertainty of the forecast.
vii
Table des matières
Résumé ... iii
Abstract ... v
Table des matières ... vii
Liste des tableaux ... xi
Liste des figures ... xiii
Liste des abreviations... xvii
AVANT-PROPOS ... xxi
Chapitre 1. INTRODUCTION GÉNÉRALE ... 1
1.1 Prévision météorologique d’ensemble ... 2
1.2 Prévision Hydrologique d’Ensemble (PHE) ... 4
1.3 Vérification des prévisions hydrologiques ... 6
1.4 Problématique du projet de recherche ... 7
1.5 Objectifs de recherche ... 7
1.6 Plan de thèse ... 9
Chapitre 2. ASSIMILATION DE DONNÉES EN HYDROLOGIE ... 11
2.1 Principe et notations ... 11
2.1.1 États du système ... 12
2.1.2 Observations du système ... 13
2.1.3 Modélisation des erreurs ... 14
2.1.4 Récapitulatif des notations ... 14
2.2 Description de quelques techniques d’assimilation de données ... 15
2.2.1 Assimilation séquentielle ... 15
2.2.1.1 Le filtre de Kalman et ses variantes ... 17
2.2.1.2 Le filtre particulaire ... 20
2.2.2 Assimilation variationnelle ... 21
2.2.3 Assimilation manuelle ... 24
2.2.4 Assimilation naïve des sorties ... 24
2.3 Utilisation des techniques d’assimilation de données en hydrologie ... 24
2.3.1 Mise à jour des entrées ... 25
2.3.2 Mise à jour des paramètres ... 26
2.3.3 Mise à jour des variables d’état ... 26
2.3.4 Mise à jour des sorties... 27
2.4 État de progression de techniques d’assimilation de données en hydrologie ... 27
Chapitre 3. COMPARISON OF SEQUENTIAL AND VARIATIONAL STREAMFLOW ASSIMILATION TECHNIQUES FOR SHORT-TERM HYDROLOGICAL FORECASTING ... 29
3.1 Introduction ... 30
3.2 Material and methods ... 31
3.2.1 Watersheds and data ... 31
3.2.2 Model description and calibration ... 33
3.2.3 Ensemble Kalman filter... 36
3.2.4 Variational data assimilation ... 39
3.3 Experimental set-up ... 40
3.3.1 EnKF state variable updating ... 40
3.3.2 VDA updating ... 42
3.3.3 Naïve output assimilation ... 44
3.3.4 Model evaluation ... 44
viii
3.5 Conclusion ... 48
Chapitre 4. SEQUENTIAL STREAMFLOW ASSIMILATION FOR SHORT-TERM HYDROLOGICAL ENSEMBLE FORECASTING ... 51
4.1 Introduction ... 52
4.2 Material and Methods ... 54
4.2.1 Watershed and data ... 54
4.2.2 Model description... 56
4.2.3 Ensemble Kalman Filter ... 57
4.3 Experimental set-up ... 59
4.3.1 Identification of hyper-parameters and ensemble size ... 60
4.3.2 Quantifying the model error ... 61
4.3.3 Quantifying observations errors ... 62
4.3.4 EnKF implementation on a distributed hydrological model ... 62
4.3.5 Verification of ensemble forecasts ... 62
4.4 Results and Discussion ... 65
4.4.1 Setting of hyper-parameters ... 65
4.4.2 Ensemble streamflow forecasting ... 69
4.4.3 Ensembles with a lower number of members ... 72
4.4.4 Economic value ... 77
4.5 Conclusion ... 78
Chapitre 5. EXPLORATION OF SEQUENTIAL STREAMFLOW ASSIMILATION IN SNOW DOMINATED WATERSHEDS ………..81
5.1 Introduction ... 82
5.2 Material and Methods ... 83
5.2.1 Watershed and data ... 83
5.2.2 Hydrotel model ... 84
5.2.3 Ensemble Kalman Filter ... 84
5.3 Experimental set-up ... 86
5.3.1 Performance and reliability assessment of an assimilation run ... 86
5.3.2 Perturbations of model inputs ... 87
5.3.3 Quantifying observation errors ... 88
5.3.4 EnKF implementation ... 88
5.3.5 Verification of ensemble forecasts ... 89
5.4 Results and Discussion ... 90
5.4.1 Hyper-parameter identification ... 90
5.4.2 Impact of the EnKF on the H-EPS ... 91
5.4.3 Impact of ensemble size ... 95
5.5 Conclusion ... 98
Chapitre 6. A COMPARISON OF THE CANADIAN GLOBAL AND REGIONAL METEOROLOGICAL ENSEMBLE PREDICTION SYSTEMS FOR SHORT-TERM HYDROLOGICAL FORECASTING ... 101
6.1 Introduction ... 102
6.2 Material and Methodology ... 103
6.2.1 Watershed description and observation availability ... 103
6.2.2 Meteorological forecasting ... 107
6.2.3 Hydrological forecasting ... 108
6.2.4 Implementation and verification ... 109
6.3 Results ... 113
6.3.1 Performance ... 113
6.3.2 Reliability of the H-EPS ... 115
ix
6.4 Discussion and conclusion ... 122
Chapitre 7. CONCLUSIONS GÉNÉRALES ET PERSPECTIVES ... 125
BIBLIOGRAPHIE ... 131
ANNEXES ... 143
ANNEXE A. MODÈLES UTILISÉS ... 143
ANNEXE B. WHY SHOULD ENSEMBLE SPREAD MATCH THE RMSE OF THE ENSEMBLE MEAN? .... 149
xi
Liste des tableaux
Tableau 2.1 Un récapitulatif des différentes erreurs utilisées dans le processus d’assimilation de données .... 14 Tableau 2.2 Récapitulatif de différents termes utilisés dans l’assimilation de données ... 15 Tableau 3.1 (Table 3.1) GR4Jsnow Parameter Values ... 36 Tableau 3.2 (Table 3.2) Calibration and validation performance ... 36 Tableau 5.1 (Table 5.1) Assimilation ensemble size, hyper-parameters, NSE, and NRR (simulation) for the open-loop and three EnKF scenarios ... 91 Tableau 6.1 (Table 6.1) Characteristics of the eight watersheds ... 105
xiii
Liste des figures
Figure 1.1 Comparaison entre les prévisions d’ensemble et déterministe (Soubeyroux 2008) ... 2
Figure 1.2 Schéma d'un système de prévision hydrologique probabiliste, adapté de Schaake et al. (2007) ... 5
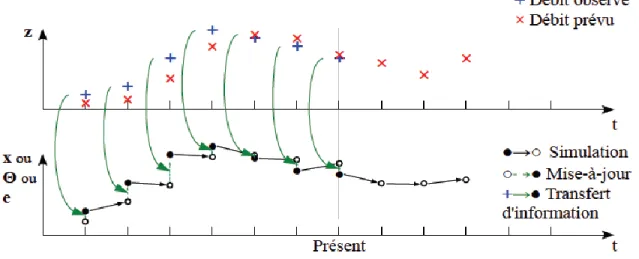
Figure 2.1 Approche d’assimilation séquentielle de données. Lorsqu'une observation est disponible (+), la prévision du modèle (cercle blanche) est mise à jour à une valeur plus proche de l'observation (cercle noire) et est ensuite utilisée pour la prévision suivante (Berthet 2010) ... 16
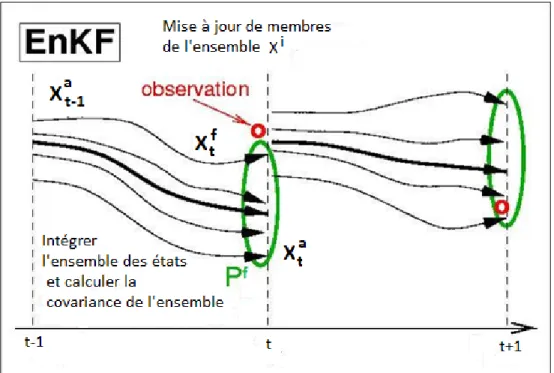
Figure 2.2 Principe de filtre de Kalman d’ensemble (f: prévision, a: mise à jour) (Reichle et al., 2002) ... 20
Figure 2.3 Approche d’assimilation variationnelle des données. Les observations dans les derniers pas de temps (+) sont utilisées pour mettre à jour l’état du modèle au moment de la prévision (Berthet, 2010) ... 22
Figure 2.4 Les différents moyens de modification du modèle dans le processus d’assimilation de données (Drécourt 2004) ... 25
Figure 3.1 Localisation of the au Saumon (Canada) and Schlehdorf (Germany) watersheds (reprinted from Seiller el al. 2012) ... 32
Figure 3.2 Climatic and hydrologic characteristics of the two watersheds ... 33
Figure 3.3 GR4J model (reprinted from Journal of Hydrology, Vol. 279, No. 1-4, Charles Perrin, Claude Michel, and Vazken Andréassian, “Improvement of a parsimonious model for streamflow simulation”, pp. 275-289, copyright (2003), with permission from Elsevier) ... 34
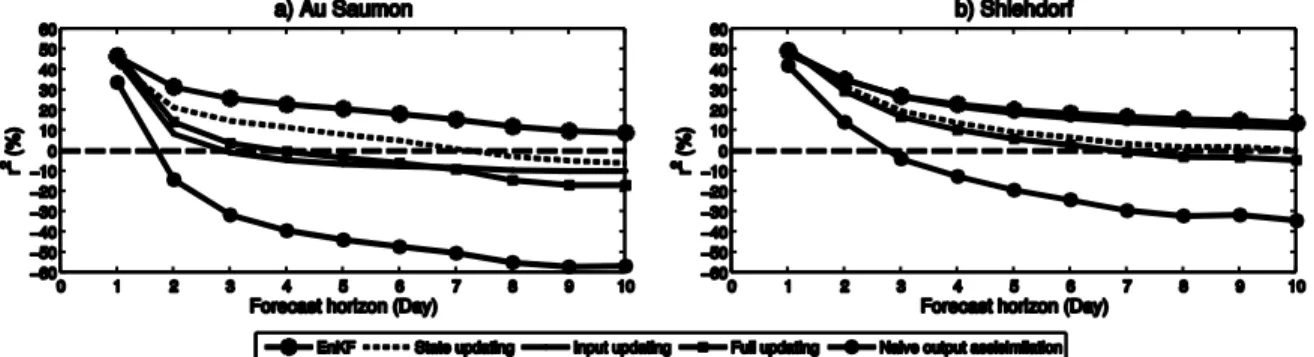
Figure 3.4 Sequential (EnKF) assimilation and no assimilation performance (RMSE), as a function of forecast horizon: (a) Au Saumon; (b) Schlehdorf ... 45
Figure 3.5 Variational (state, input, and full) updating, and no assimilation performance (RMSE), as a function of forecast horizon, for assimilation windows of 2, 5, and 10 days: (a) Au Saumon; (b) Schlehdorf ... 46
Figure 3.6 Sequential, variational (10-day window), and naive assimilation performance (𝑟2 criterion using no assimilation as a reference), as a function of forecast horizon: (a) Au Saumon; (b) Schlehdorf ... 47
Figure 4.1 Localisation of the au Saumon watershed (Province of Québec, Canada), soil type distribution, land cover distribution and gauge station location ... 55
Figure 4.2 Elements of the semi-distributed Hydrotel model ... 57
Figure 4.3 NRR and mean 𝑟2 for 50-member ensembles and a precipitation data perturbation of 10%, as a function of streamflow observation perturbation (%) ... 66
Figure 4.4 NRR and mean 𝑟2 for 50-member ensembles and a streamflow observation perturbation of 10%, as a function of precipitation data perturbation (%) ... 67
Figure 4.5 NRR and mean 𝑟2 for a streamflow observation perturbation of 10%, as a function of ensemble size (20 to 95) and precipitation data perturbation (5 to 25%) ... 68
Figure 4.6 As in Figure 4.5, but including a soil moisture perturbation of 3%... 69
Figure 4.7 MCRPS as a function of the forecast horizon for various scenarios ... 70
Figure 4.8 MCRPS gain (%) as a function of the forecast horizon for various scenarios ... 71
Figure 4.9 RMSE and spread as a function of the forecast horizon for various scenarios ... 71
Figure 4.10 Reliability diagram of 24-h forecasts for various scenarios – the shaded area depicts the 90% confidence interval ... 72
Figure 4.11 MCRPS as a function of the forecast horizon for a 50-member EnKF, the original 1000-member EnKF, and the manual and open-loop scenarios – boxplots illustrate the distribution of 200 repetitions of the 50-member EnKF ... 73
xiv
Figure 4.12 RMSE and spread as a function of the forecast horizon for a 50-member EnKF, the original 1000-member EnKF, and the manual and open-loop scenarios – boxplots illustrate the distribution of 200 repetitions
of the 50-member EnKF ... 74
Figure 4.13 Reliability diagram of 24-h forecasts for the same scenarios as in Figures 11 and 12 – the shaded area depicts the 90% confidence interval ... 75
Figure 4.14 Hydrograph of the observed (dark) and 24-h forecasted streamflow, comparing EnKF, manual assimilation, and open-loop ... 76
Figure 4.15 Semilog plot of H-EPS ratio 𝛿 as a function of forecast horizon - boxplots illustrate the distribution of 200 repetitions of the 20-member among the 50-member EnKF ... 77
Figure 4.16 Economic value V plotted against cost/loss ratio α for four forecast horizons (3h, 24h, 48h and 72h) ... 78
Figure 5.1 Localisation of the au Saumon and Des Anglais watersheds (Province of Québec, Canada): soil type distribution, land cover distribution, and gauge station ... 83
Figure 5.2 Schematic diagram of the EnKF implementation in Hydrotel model ... 89
Figure 5.3 MCRPS of the three EnKF scenarios as a function of forecast horizon ... 92
Figure 5.4 RMSE and spread of the three EnKF scenarios as a function of forecast horizon ... 93
Figure 5.5 MCRPS of the EnKF3 and open-loop scenarios as a function of forecast horizon ... 94
Figure 5.6 RMSE and spread of the EnKF3 and open-loop scenarios as a function of forecast horizon ... 95
Figure 5.7 MCRPS as a function of forecast horizon for the 50-member and 1000-member EnKF3 and the open-loop – boxplots illustrate 200 repetitions of the 50-member EnKF3, for which the box depicts the central 50% of the MCRPS, the line inside the box is the median MCRPS... 96
Figure 5.8 RMSE and spread as a function of forecast horizon for the 50-member and 1000-member EnKF3 and the open-loop – boxplots illustrate 200 repetitions of the 50-member EnKF3 ... 97
Figure 5.9 RMSE and spread as a function of forecast horizon for the 20-member and 1000-member EnKF3 and the open-loop – boxplots illustrate 200 repetitions of the 20-member EnKF3 ... 98
Figure 6.1 Localization of the four selected river systems (Source: CEHQ) ... 104
Figure 6.2 Rainflall (bars) and accumulated rainfall (lines) observations for the study period ... 106
Figure 6.3 Standardized streamflow observations for the study period ... 107
Figure 6.4 Schematic of the hydrologic ensemble prediction system ... 108
Figure 6.5 (top) (a)–(h) MCRPS and MAE of H-EPS as a function of time of forecasting. (bottom) (a)–(h) MCRPS and MAE for the first 72 h ... 114
Figure 6.6 Evolution of RMSE and spread of H-EPS as a function of time of forecasting ... 115
Figure 6.7 H-EPS ratio 𝛿 as a function of time of forecasting ... 116
Figure 6.8 H-EPS 72-h rank histograms provided by (left) global and (right) regional M-EPS ... 117
Figure 6.9 H-EPS 72-h reliability diagrams provided by (left) global and (right) regional M-EPS. The gray area indicates the 90% confidence interval ... 118
Figure 6.10 Cumulative rainfall and streamflow predictions for the Saumon watershed issued on 30 Sep 2010 (the global forecasts stand on the left side and the regional ones, on the right side). (a),(b) Cumulative rainfall ensemble predictions are shown as a series of box plots, for which the box depicts the central 50% of the predictive distribution, the line inside the box is the median forecast, and the “X” illustrates the observation. (c),(d) The streamflow ensemble predictions are shown as thin lines, while the observation is the thicker line ... 119
Figure 6.11 As in Fig. 10, but for the Chaudière at Saint Lambert watershed ... 119
xv Figure 6.13 As in Fig. 11, but for 7 Oct 2010 ... 120 Figure 6.14 Economic value 𝑉 plotted against cost/loss ratio 𝛼. Lines show the overall relative value 𝑉 of the global hydrological ensemble prediction (heavy solid line), regional hydrological ensemble prediction (dotted line), and deterministic forecast (solid line) ... 121
xvii
Liste des abreviations
EPS Ensemble Prediction System SPE Système de Prévision d’Ensemble PHE Prévision Hydrologique d’Ensemble HEP Hydrologic Ensemble Prediction PME Prévision Météorologique d’Ensemble CEHQ Centre d’Expertise Hydrique du Québec EnKF Ensemble Kalman Filter
EKF Extended Kalman Filter VDA Variational Data Assimilation GEM Global Environnemental Multiscale EDS Environnement, Dévéloppement et Société UH Unit Hydrograph
UHRH Unités Hydrologiques Relativement Homogènes ASCE American Society of Civil Engineering
CRPS Continuous Ranked Probability Score NRR Normalized Root Mean Square Error Ratio RMSE Root Mean Square Error
NSE Nash Sutcliffe Efficiency
SGPE Système Global de Prévision d’Ensemble SRPE Système Régional de Prévision d’Ensemble
xix
xxi
AVANT-PROPOS
C’était une belle expérience pour moi de passer 4 années à l’Université Laval afin de réaliser mon projet de doctorat en génie des eaux. Ces quatre ans de doctorat m’ont permis d’apprendre beaucoup des concepts avancés dans la modélisation et programmation. J’ai réussi à accumuler de nouveaux bagages scientifiques par rapport à ce que j’ai déjà appris en France et en Tunisie. Je suis arrivé en session d’automne 2010 à l’Université Laval où j’étais très bien accueilli avec mon directeur de recherche François Anctil et j’ai rejoint une équipe très motivante et j’ai eu la chance de m’adapter plus rapidement.
Au terme de ce travail, j’aimerais rendre un grand hommage à tous ceux qui ont contribués d’une manière ou d’une autre à sa réalisation.
Je souhaite vivement remercier mon directeur Monsieur François Anctil qui m’a encadré tout au long de cette thèse, pour sa disponibilité et pour ses explications. Nous avons eu beaucoup de discussions très intéressantes qui m’ont permis d’envisager les choses sous un autre angle.
Je remercie également mon codirecteur Monsieur Vincent Fortin chercheur scientifique chez Environnement Canada pour son soutien, ses conseils et sa grande implication dans le projet.
Je tiens à remercier aussi la chaire de recherche EDS en prévisions et actions hydrologique (CRPAH) pour le financement de la grande partie de mon projet. Merci aussi au Centre d’Expertise Hydrique de Québec (CEHQ) et Environnement Canada (EC) qui m’ont facilité l’accès à leurs données météorologiques et hydrologiques.
Je vais remercier tous les membres de l’équipe sans exception pour leurs encouragements et leurs recommandations tout au long de ma thèse. Merci à Alain Royer de l’INRS pour son aide sur le modèle Hydrotel et Cyril Garneau pour son aide dans la compréhension de fonctionnement de la méthode d’assimilation variationnelle de données.
J’exprime toute ma gratitude aux membres de jury, qui ont bien voulu juger ce travail.
Enfin, j’adresserai mon dernier remerciement, mais non le moindre, à ma famille pour son indispensable soutien et pour tous mes amis qu’ils soient à Québec, France ou bien en Tunisie pour leurs aides morales. La thèse est organisée sous une forme un peu particulière, incluant à la fois des parties en français et des articles en anglais. Quatre articles sont présentés dans cette thèse. Le troisième chapitre présente les résultats d’un article qui a été publié dans Journal of Hydrological Engineering de l’ASCE dont je suis le
xxii
premier auteur, Cyril Garneau le deuxième auteur et François Anctil le troisième auteur. Le quatrième chapitre a fait l’objet d’un article dont je suis le premier auteur, François Anctil le deuxième auteur, Vincent Fortin le troisième auteur et Richard Turcotte le quatrième auteur, a été accepté dans le Journal of Hydrology. L’article présenté dans le cinquième chapitre, où je suis le premier auteur, François Anctil le deuxième auteur, Vincent Fortin le troisième auteur et Richard Turcotte le quatrième auteur, sera soumis prochainement dans une revue scientifique. Le sixième chapitre présente un article dont je suis le premier auteur, François Anctil le deuxième auteur, Vincent Fortin le troisième auteur et Richard Turcotte le quatrième auteur, qui a été publié dans Monthly Weather Review. Une équation et une figure ont été modifiées dans cet article parce qu’une erreur a été découverte après publication. Un corrigendum a été envoyé et publié par ce journal pour mentionner cette erreur.
Un autre article est présenté dans l’annexe B où je suis le deuxième auteur, Vincent Fortin le premier auteur, François Anctil le troisième auteur et Richard Turcotte le quatrième auteur, qui a été publié dans Journal of Hydrometeorology.
1
Chapitre 1. INTRODUCTION GÉNÉRALE
La protection contre les inondations a pris beaucoup d’importance dans l’agenda politique au cours de la dernière décennie, dans le but d’améliorer la prévision des crues (Demeritt et al. 2007; DKKV 2004; Parker et Fordham 1996; Pitt 2007; van Berkom et al. 2007).
La mise en place de systèmes de prévision opérationnels des crues constitue un élément essentiel pour bien se préparer aux inondations par une alerte précoce de plusieurs jours (De Roo et al. 2003; Patrick 2002; Werner 2005), ce qui permet de réduire l’impact de ces inondations. De nombreux systèmes de prévision des crues s’appuient sur des données de précipitation, à l’origine des réseaux d’observation pluviométrique ou radar. Ainsi, pour les prévisions à moyen terme (2 à 15 jours en avance), des modèles de prévision météorologique numérique sont requis, surtout lorsque les données de débit de la rivière à l’amont de bassin ne sont pas disponibles ou lorsque la transmission des informations hydrométrique échoue, ce qui survient souvent lors de crues extrêmes. En fait, les données provenant de modèles de prévision météorologique numérique sont essentielles pour établir des échéances de prévisions plus longues que le temps de concentration de bassin bassin. Même pour des horizons courts, elles permettent de fournir des informations sur les prévisions pour les sites les plus proches de l’exutoire.
Un système de prévision des crues est un mécanisme important pour réduire les effets néfastes de ces dernières. La prévision hydrologique ne permet pas d’éliminer toute l’incertitude, mais a le potentiel de la réduire considérablement (Krzysztofowicz 2001a). La majeure partie des recherches courantes est d’ailleurs consacrée à la réduction de l'incertitude et à l'amélioration de la capacité de prévision des modèles (Demeritt et al. 2007). L’une des voies les plus prometteuses de la recherche scientifique est le développement de systèmes de prévision d’ensemble (EPS en anglais : Ensemble Prediction System) pour succéder aux systèmes déterministes actuels qui n’informe pas sur l'incertitude. Il s’agit de méthodes développées par des météorologues pour combler les lacunes de la prévision déterministe face aux problèmes d’incertitudes (Leith 1974 ; Ehrendorfer 1997). En outre, générer un ensemble de prévisions plutôt qu'une prévision déterministe unique, fournit un moyen de quantifier et d’étudier la propagation de l'incertitude. Cette capacité de quantifier l’incertitude a reçu des bonnes appréciations par les utilisateurs (Palmer 2002). Il est d'un intérêt particulier pour l'hydrologue d’étudier à la fois le potentiel et l'implication des entrées d'ensemble, la précipitation et la température de l’air, pour les systèmes de modélisation hydrologique en termes de propagation d’incertitude. L’identification des conditions initiales est également un étément important de l’amélioration des prévisions. En météorologie, les méthodes d’assimilation sont utilisées depuis longtemps afin d’améliorer les états initiaux et de lancer la prévision depuis le meilleur état possible. Les hydrologues s’intéressent aussi à cette question et
2
plusieurs méthodes d’assimilation ont été évaluées, quelles soient séquentielles ou variationnelles. De telles études ont demontré le besoin de techniques d’assimilation efficaces afin de produire de meilleures prévisions hydrologiques et de réduire leur incertitude.
1.1 Prévision météorologique d’ensemble
Le principe de la prévision météorologique d’ensemble (PME) repose sur le fait que deux états initiaux très proches peuvent mener à des évolutions éloignées de l’état de l’atmosphère. La justification physique la plus souvent avancée est la conséquence parfois importante de petites erreurs dans les conditions initiales de l’atmosphère.
La prévision météorologique d’ensemble recourt plusieurs fois au même modèle numérique pour une situation à prévoir, en exploitant des conditions initiales chaque fois légèrement différentes (appelées ici perturbations initiales), compatibles avec les incertitudes existantes sur la connaissance de l’état initial de l’atmosphère (Palmer et al. 2002). La figure 1.1 illustre la différence entre les prévisions d’ensemble et déterministe.
Figure 1.1 Comparaison entre les prévisions d’ensemble et déterministe (Soubeyroux 2008)
De tels systèmes de prévision sont apparus vers la fin des années 1980. À partir de 1992, quelques agences comme le CEPMMT (Centre européen pour la prévision météorologique à moyen terme, Palmer et al. 1993; Buizza et Palmer 1995; Buizza et al. 2007), le NCEP (National Centers of Environmental Prediction, Toth et Kalnay 1993 et 1997), Meteo France (Bouttier 2010) et le Centre Météorologique Canadien (CMC) (Environnement Canada, Houtekamer et al. 1996) ont commencé à produire des prévisions d’ensemble météorologiques opérationnelles (Boucher 2010). La méthodologie appliquée pour la production de ces prévisions diffère d’un centre à un autre, soit par le nombre de membres, soit par leur méthode de perturbation
3 des conditions initiales (Buizza et al. 2005). Le nombre de membres ainsi générés varie typiquement entre 10 et 50.
Les prévisions météorologiques s’améliorent constamment. Par exemple, le modèle déterministe européen du CEPMMT montre une amélioration de sa capacité de prévision de la précipitation. Il faut noter, que dans certains cas, les améliorations à petite échelle ne sont pas évidentes à évaluer, ce qui pose problèmes dans les applications hydrologiques. Malgré cette amélioration, leur impact sur les modèles hydrologiques n’est pas certain. Un des plus grands défis de l’amélioration des prévisions consiste en l’augmentation de la résolution et en l’identification des représentations physiques adéquates à cette échelle spatiotemporelle. En revanche, ces avancées exigent une grande capacité de calculs et de stockage.
Une PME peut également être montée en combinant les prévisions de plusieurs centres. Par exemple Jasper et al. (2002) ont utilisé les prévisions provenant de 5 modèles différents pour prédire l’apport au lac Maggiore en Italie. Davolio et al. (2008) ont utilisé 6 prévisions météorologiques différentes pour prévoir les crues du nord de l’Italie. Il demeure toutefois difficile de combiner les prévisions de plusieurs modèles à cause de structures d’erreur différentes.
Une autre approche prometteuse dans l’utilisation de la PME dans la prévision des inondations est d’utiliser des ensembles décalés dans laquelle une prévision précédente est combinée avec une prévision plus récente (Dietrich et al. 2008; Hoffman et Kalnay 1983). Cette approche présente la même idée que la prévision de persistance (utilisé dans le projet EFAS, dans lequelle une alerte est émise seulement si une certaine persistance (réoccurrence de l’évènement) est atteinte). Il est important de capter les incertitudes de conditions initiales et de paramétrisation pour chacun des modèles de prévision météorologique numérique et aussi les incertitudes dans la structure du modèle. La meilleure façon de faire consiste en l’utilisation d’un « grand-ensemble » qui contient beaucoup de membres, c'est-à-dire d’utiliser plusieurs PME. Un pré-traitement de le PME est souvent nécessaire avant leur utilisation à des fins hydrologiques. Par exemple, des corrections d’échelle sont réquises lorsque l’échelle temps/espace du modèle hydrologique ne correspond pas à celle du modèle météorologique. La PME est alors désagrégée et son échelle réduite pour s’adapter au bassin versant. La sous-dispersion et le biais peuvent aussi être corrigés. Hagedorn et al. (2005) ont constaté que corriger le biais ne conduit pas forcément à l’amélioration de la compétence des prévisions. Cependant, Fortin et al. (2006) ont démontré qu’il est possible d’améliorer considérablement les prévisions de précipitations et de températures par pré-traitement. La correction du biais peut être réalisée dans la phase hydrologique de la prévision (Hashino et al. 2007a; Schaake et al. 2007; Carpenter et Georgakakos 2001; Wood et al. 2002).
4
En Juillet 2007, le CMC a considérablement amélioré son système de prévision d'ensemble, opérationnel depuis 1998, qui utilise le modèle GEM (Global Environnemental Multi-échelle) pour générer un ensemble de 20 membres sur une grille de 100 km et un horizon de 15 jours (Velázquez et al. 2009). Le modèle GEM peut être utilisé sur une vaste gamme d’échelles spatiales et pour une grande variété d’applications météorologiques (Toth et al. 2010).
Depuis novembre 2009, le CMC produit expérimentalement des prévisions régionales d’ensemble à courte échéance, soit 20 membres sur une grille de 33 km et un horizon de 3 jours. Un filtre de Kalman d’ensemble global (Houtekamer et al. 2009) fournit les conditions initiales au système régional de prévision d’ensemble à court terme. Ce produit est opérationnel depuis septembre 2011.
Le produit déterministe disponible à cette étude combine des prévisions régionales (15 km pour les 3 premiers jours) et globale (35 km pour le reste des horizons).
Les caractéristiques des systèmes de prévision d’ensemble d’Environnement Canada ont beaucoup évoluées ces dernières années où la résolution spatiale et la qualité des prévisions sont améliorées. Le système de prévision d’ensemble global a subi beaucoup de modifications pour arriver à la version actuelle (SGPE 4.0.0) avec une résolution horizontale de 50 km. Du son côté, le système de prévision d’ensemble régional a été amélioré pour arriver à la version actuelle (SRPE 2.0.1) avec une résolution horizontale de 15 km. Les résolutions des produits déterministes ont augmenté jusqu’aux 25 km pour le produit gloal et 10 km pour le produit régional. En plus de résolution, il y a d’autres améliorations qui concernent surtout l’assimilation.
1.2 Prévision Hydrologique d’Ensemble (PHE)
« Il est nécessaire d'intégrer l'ensemble des avancées de la recherche scientifique dans les procédures opérationnelles de prévision des crues, insistant sur l'aspect probabiliste et les incertitudes » (Schaake et al. 2007).
L’approche déterministe demeure insuffisante, l'incertitude sur les évènements futurs n'étant pas négligeable, elle justifie le besoin de prévisions probabilistes (Krzysztofowicz 2001a). Si la prévision d’ensemble est couramment utilisée en météorologie, son application à l’hydrologie est plus récente. On peut noter les initiatives internationales HEPEX (The Hydrologic Ensemble Prediction EXperiment) et européennes EFAS (European Flood Alert System). HEPEX est une initiative internationale lancée en 2004 (Schaake et al. 2007; Thielen et Schaake 2008) qui rassemble les communautés météorologiques et hydrologiques pour mener des recherches axées sur la promotion des techniques de prévisions hydrologiques probabilistes, ce qui permet d’étudier les prévisions d’ensemble sous des conditions climatiques variées et d’accroitre la communauté scientifique travaillant à cette question.
5 En Europe, le développement d’EFAS a débuté en 1993 sous l’égide de la Commission européenne, dans le but de mettre à disposition de l’ensemble des pays européens membres, des prévisions hydrologiques ensemblistes et homogénéisées. Les opérations ont été lancées en 2002 suite aux inondations dévastatrices du Danube. Le projet propose des produits facilement exploitables par les utilisateurs finaux (Thirel 2009). Le projet MAP D-PHASE (Mesoscale Alpine Programme, Demonstration of Probabilistic Hydrological and Atmospheric Simulation of flood Events in the Alpine region) origine du WWRP (World Weather Research Programme de l’Organisation météorologique mondiale). L’objectif principal de ce projet est de décrire les capacités d’un système d’alerte de crues qui produit à la fois des prévisions déterministes et ensemblistes pour des courtes (1-2 jours) et des moyennes échéances (3-5 jours) (Thirel 2009).
La figure 1.2 présente un schéma de système de prévision d’ensemble qui prend en compte les principales sources d’incertitude du processus de prévision.
Figure 1.2 Schéma d'un système de prévision hydrologique probabiliste, adapté de Schaake et al. (2007)
Prévisions météorologiques
d’ensemble
Observations, État du basin
(neige, débit,…)
Pré-traitement des PME
Système d’assimilation de
données hydrologiques
PME débiaisée
Ensemble débiaisé d’état de
surface
Modèle(s) hydrologique(s)
Prévision hydrologique d’ensemble
Post-traitement des ensembles hydrologiques
PHE débiaisée
Système de vérification
Utilisateurs
6
En plus du pré-traitement de la PME, le post–traitement de la PHE est considéré comme une étape importante. L’objectif du post-traitement est d’enlever les biais et d’ajuster la dispersion de l’ensemble. Il s’agit d’utiliser les données d’archive disponibles (prévisions et observations) afin d’estimer les paramètres du modèle de post-traitement retenu. Par la suite, ce modèle est appliqué aux prévisions lors de leur production. Il existe plusieurs méthodes de post-traitement dont la méthode du meilleur membre (Roulston et Smith 2003), la méthode de Wang et Bishop (2005), la méthode de Fortin et al. (2006) et la régression gaussienne non-homogène (Gneiting et al. 2005).
Dans le cadre de la PHE, l’objectif est de trouver la meilleure estimation des débits et de rechercher la meilleure estimation des incertitudes de prévisions. Mais au lieu d’avoir un seul débit prévu, un ensemble de 𝑁 membres est fourni pour chaque pas de temps, qui peut être utilisé pour ajuster la fonction de densité de probabilité et à son tour permettre d’évaluer les intervalles de confiance ainsi que d’autres mesures des incertitudes de prévisions (Boucher et al. 2009).
1.3 Vérification des prévisions hydrologiques
La vérification des prévisions opérationnelles est une activité assez récente et devrait faire partie de tout système de prévision parce qu’elle permet de déterminer la qualité des prévisions. La vérification a pour but d’aider les utilisateurs à comprendre à quel point les prévisions sont bonnes, quelles sont les sources d'erreurs et d'incertitudes et qu’est-ce qu'il faudrait faire pour améliorer le système. La PHE étant de nature probabiliste, sa vérification et son interprétation doivent être faites avec des scores adaptés (Martin et al. 2009). C’est pourquoi des scores ensemblistes doivent être définis et utilisés. L’évaluation de la performance des prévisions probabilistes implique la comparaison de fonctions de distribution de probabilités à des observations scalaires. Ensuite, l'erreur de prévision peut être estimée en comparant la valeur prévue et la valeur de vérification (Velázquez et al. 2009).
Le but des prévisions d’ensemble étant de donner au prévisionniste une image précise de la distribution de probabilité d’évènements possibles, il est important de vérifier cette distribution et ses qualités statistiques. On cherche donc, entre autres choses, à:
trouver où se situe la vérification (l’observation) par rapport à la gamme de valeurs prévues des différents membres de l’ensemble.
déterminer comment la probabilité des évènements prévus dans l’ensemble « correspond » à la fréquence à laquelle les évènements sont observés.
7 déterminer l’utilité de la prévision d’ensemble par rapport aux prévisions déterministes et à la
climatologie.
En plus de la performance, il faut accorder une grande importance à la fiabilité de l’ensemble; en d’autres termes la dispersion de l’ensemble doit représenter correctement l’erreur de prévision.
Beaucoup de scores ont été proposés dans la littérature pour évaluer la qualité de la PHE (par exemple Stanski et al. 1989; Wilks 1995). Parmi ceux-ci notons le Continuous Ranked Probability Score (CRPS) (Stanski et al. 1989; Hersbach 2000; Gneiting et Raftery 2007) et les outils graphiques tel que le diagramme de fiabilité (Boucher et al., 2009 ; Velázquez et al., 2009). Ceux-ci seront détaillés dans les chapitres qui suivent.
1.4 Problématique du projet de recherche
Il est très important de quantifier l’incertitude reliée aux prévisions hydrologiques. Pourtant, très peu d'efforts sont généralement consentis à cette problématique, particulièrement au Canada. Toutefois, l’importance de ce problème et son influence sur la sortie des modèles hydrologiques expliquent la diversité des méthodes existantes de quantification de l’incertitude, dont le but est de décrire la propagation de cette incertitude et de l’intégrer à la prévision hydrologique. Celle-ci est affectée dans la plupart des cas par des problèmes d’incertitudes sur les conditions initiales. La mise en place de techniques d’assimilation de données a justement pour finalité de réduire de telles incertitudes mais la diversité des approches possibles complique sa mise en œuvre opérationnelle.
Encore aucune étude n’a comparé la prévision hydrologique d’ensemble déduite de différents types de prévisions météorologiques canadiennes. Ce projet se présente comme une occasion pour résoudre cette problématique en testant les différentes prévisions météo disponibles au Canada. Plusieurs types de scores sont définis pour évaluer la performance des prévisions déterministes et probabilistes. Tous ces scores peuvent être utilisés sur plusieurs bassins versants pour comparer la fiabilité et évaluer la performance entre prévision d’ensemble et prévision déterministe.
1.5 Objectifs de recherche
L’objectif principal de ce projet de recherche est d’identifier une méthode d’assimilation automatique des débits adaptée à la prévision probabiliste de débit et qui pourrait être utilisée dans un contexte opérationnel. Le choix de la méthode est effectué en comparant les techniques les plus utilisées dans la littérature. La technique d’assimilation automatique retenue doit avoir la capacité de fournir des prévisions hydrologiques d’ensemble avec la meilleure performance et la meilleure fiabilité.
8
La vérification et l’exploration de prévisions hydrologiques d’ensemble dans un contexte opérationnel, en comparant les produits météorologiques globaux et régionaux disponibles chez Environnement Canada, est aussi investiguée.
Cette étude est structurée autour des deux objectifs suivants:
Identifier une méthode d’assimilation des débits adaptée à la prévision hydrologique d’ensemble.
Cet objectif occupe la principale partie de cette thèse. Différentes méthodes d’assimilation, des plus simples aux plus complexes, sont alors comparées pour identifier la méthode la plus pertinente aux prévisions d’ensemble. Pour effectuer l’assimilation et réduire l’incertitude dans de bonnes conditions, trois actions devraient être prises en compte : (1) la disponibilité de données hydrologiques de bonne qualité, en développant des techniques de mesure et d’amélioration des réseaux d'observation, (2) l’utilisation de modèles hydrologiques qui représentent adéquatement les processus hydrologiques (aucun modèle est sans faille; les modèles Hydrotel (Fortin et al. 1995) et GR4Jneige (GR4J, 4 paramètres, Perrin et al. 2003; couplé avec le module de neige CemaNeige, 2 paramètres, Valéry 2010) seront considérés comme parmi les bons modèles), et (3) le développement de techniques efficaces qui permettent de mieux assimiler l'information à partir des données disponibles par l'identification du modèle et des processus de prévision. La troisième action nous semble la plus urgente. Cette problématique devient donc l’objectif principal de notre recherche. Les méthodes d’assimilation permettent de réduire les incertitudes et d’augmenter la fiabilité. Les méthodes d’assimilation qui sont testées dans le cadre de ce projet sont l’assimilation manuelle, le Filtre de Kalman d’ensemble, l’assimilation variationnelle et l’assimilation naïve des sorties.
Comparer la prévision hydrologique d’ensemble (PHE) fondée sur des prévisions météorologiques d’ensemble (PME) globales et régionales.
Ce deuxième objectif cible les progrès dans le domaine de l’hydrologie découlant de l’amélioration et de l’évolution de systèmes de prévision météorologique. Très peu d’études de ce genre ont été menées à ce jour et jamais pour la PME régionale canadienne dans un contexte de PHE. Ces dernières années, suite au développement de système de production de prévision météorologique et l’existence d’outils numériques de PME régionales, Environnement Canada a commencé de s’intéresser à produire des PHE qui proviennent de PME régionales. Il est intéressent d’étudier l’influence de la résolution spatiale sur les prévisions de modèle opérationnel comme Hydrotel. Il nous semble donc intéressant d’évaluer également les gains hydrologiques (PHE) des avancées canadiennes en PME globale.
Selon la revue de littérature sur la prévision hydrologique, il est démontré l’avantage des produits d’ensemble par rapport aux produits déterministes. Ainsi il est important de trouver une méthode d’assimilation qui s’adapte mieux à la prévision probabiliste de débit.
9
1.6 Plan de thèse
Le mémoire est organisé autour de six chapitres:
Le premier chapitre est consacré à l’introduction générale sur la prévision d’ensemble, qu’elle soit
météorologique ou hydrologique, et à la présentation des objectifs de la thèse.
Le chapitre 2 s’attarde à l’objectif principal de cette thèse : l’assimilation de données ayant pour but d’améliorer les conditions initiales de la prévision hydrologique.
Le chapitre 3 est consacré au développement d’un système d’assimilation des débits. En premier lieu, les résultats de comparaison de différentes méthodes d’assimilation qui ont été implémentés dans un modèle global conceptuel nommé GR4Jneige dans le cadre de prévision parfaite afin d’améliorer les états initiaux des prévisions sont présentés. Le texte est tiré d’un article publié par le Journal of Hydrological Engineering de
l’ASCE (Abaza et al. 2014).
En second lieu, dans le chapitre 4, la méthode d’assimilation la plus populaire, le « filtre de Kalman d’ensemble », est implémenté dans un modèle semi-distribué opérationnel nommé Hydrotel. Ce modèle est utilisé pour assimiler les débits observés pour des prévisions probabilistes du débit, en utilisant les prévisions météorologiques d’ensemble fournies par Environnement Canada. Dans ce chapitre, le filtre de Kalman d’ensemble est appliqué sur une période exempte de l’influence de la neige (été et automne). Ce texte a été accepté dans Journal of Hydrology.
Dans le chapitre 5, l’EnKF est cette fois-ci appliqué à la période d’accumulation et de fonte de la neige (hiver et printemps), en recourant au même modèle que le chapitre précédent. Le texte prend également la forme d’un article, bien qu’il ne soit pas encore soumis.
Au chapitre 6, différentes prévisions météorologiques d’ensemble globales et régionales fournies par Environnement Canada sont comparées afin d’identifier l’influence des progrès météorologique sur la prévision hydrologique. Ce texte a été publié par Monthly Weahter Review (Abaza et al. 2013).
Finalement, le chapitre 7 regroupe les conclusions générales de ce travail et propose des perspectives pour des travaux futurs.
11
Chapitre 2. ASSIMILATION DE DONNÉES EN
HYDROLOGIE
Un des principaux objectifs de cette thèse est de tester différentes méthodes d’assimilation de données pour améliorer les conditions initiales de prévision hydrologique. L’estimation du débit est ensuite améliorée en considérant les incertitudes liées aux observations et à la structure du modèle. Le principe de l’assimilation de donnée et les principales méthodes d’assimilation sont ici exposés.
2.1 Principe et notations
Selon Liu et Gupta (2007), le problème d'assimilation de données consiste en la jonction du modèle et des données. L’objet est d’intégrer au mieux deux informations de natures différentes, toutes deux entachées d'incertitude: celles issues du modèle et celles des observations (Walker et Houser 2005). Selon Thirel (2011), qui a utilisé le modèle SIM de Météo France pour assimiler les débits observés pour des prévisions hydrologiques probabilistes, l’assimilation améliore beaucoup les prévisions surtout pour les premiers jours de l’échéance. L’insertion directe d’observations dans un modèle est sans contredit la technique la plus simple d’assimilation, mais celle-ci ne permet pas de tenir compte des erreurs sur les observations et attribue toute l’incertitude au modèle. Elle suppose que l’observation est parfaite et que la différence entre la prévision du modèle et l’observation est uniquement due aux erreurs du modèle. La modélisation de la réponse d’un bassin versant aux forçages atmosphériques introduit beaucoup d’incertitudes dans les sorties en raison de la complexité des processus transformant la pluie en débit (Drécourt 2003). En effet, l’amélioration de la modélisation des processus hydrologiques et des systèmes d’observation des bassins versants a encouragé les hydrologues à implanter des techniques d’assimilation de données dans leurs modèles. En outre, les modèles hydrologiques distribués souffrent d’une grande demande de données, de problèmes d’échelle et de sur-paramétrisation. Pour faire face à ces problèmes, les techniques d’assimilation de données, initialement utilisées pour la prévision climatique, ont été intégrées aux modèles hydrologiques (Bessière 2008).
Selon Nash et Sutcliffe (1970), « la prévision opérationnelle des crues exige, en plus du modèle hydrologique, une méthode pour la correction continue de la prévision à partir de l’erreur observée des premières prévisions (feedback) ». Ainsi avec l’aide de cette information provenant de ce feedback, la performance de la prévision des modèles hydrologiques peut être améliorée. L’assimilation de données permet non seulement de combiner l’information contenue dans le modèle et celle des observations afin d’effectuer des prévisions, elle permet aussi de diagnostiquer certains problèmes provenant du modèle ou des observations (Trudel 2010). L’assimilation de données a aussi été exploitée dans d’autres disciplines, y compris les sciences océaniques et météorologiques, pour améliorer les prévisions à court terme produites par des modèles de prévision météo (Moradkhani et al. 2005a). Différentes techniques d’assimilation de données ont été proposées.
12
2.1.1 États du système
État vrai
L’état d’un système est défini par une série de nombres ordonnés en une matrice colonne appelé vecteur d’état. L’état réel du système contient des états statiques et dynamiques qui varient de façon continue dans l’espace et/ou le temps. On cherche souvent à bien estimer cet état réel du système noté 𝑥̌. Des modèles numériques sont utilisés pour reproduire celui-ci. Par contre, ces modèles numériques ne manipulent que des variables discrètes dans le temps, ce qui signifie que 𝑥̌ est discrétisé pour donner le vecteur d’état vrai 𝑥𝑡. On
cherche donc à estimer cet état 𝑥𝑡 qui inclut les variables d’entrées, les variables d’état (qui caractérisent
l’état dynamique du système), les paramètres (qui caractérisent son état statique) ou les variables de sortie du modèle numérique.
) ~ (x
xt (2-1)
avec 𝑥𝑡 le vecteur de l’état vrai du système, Π l’opérateur provoquant la discrétisation et 𝑥̌ l’état réel continu
du système.
Ébauche
Généralement on dispose d’une première estimation des variables de l’état du système. Cette information a priori est représentée par le vecteur d’ébauche 𝑥𝑓 qui a le même taille que le vecteur 𝑥𝑡. Il estime l’état vrai
du système avec une erreur 𝜀𝑓 nommée erreur d’ébauche.
f xt xf
(2-2)Analyse
La mise en place de l’assimilation implique la création d’un nouveau vecteur d’état représenté par 𝑥𝑎 qui est
produit à partir de l’ébauche 𝑥𝑓et des observations et qui a le même taille que le vecteur 𝑥𝑡. Ce vecteur
d’analyse 𝑥𝑎 représente l’état vrai du système avec une erreur 𝜀𝑎 nommée erreur d’analyse.
t a
a x x
(2-3)Propagation des états du modèle
Les variables d’état du modèle évoluent en fonction du temps. Il existe donc une relation entre les états réels du système de deux temps d’observation consécutifs 𝑥𝑡 et 𝑥𝑡+1 :
1
t t
13 Avec 𝑔 une fonction continue qui provoque le passage de l’état observé au temps 𝑡 à celui observé au temps 𝑡 + 1. La physique est alors représentée par un modèle numérique 𝑓 appliqué au vecteur d’état vrai 𝑥𝑡. Il est
entaché d’une erreur 𝑤𝑡,𝑡+1 issue du modèle numérique (représentation approximative des processus physiques) et des erreurs de discrétisation.
1 , 1 , 1
t t
t t t t t t
x
f
x
w
(2-5)2.1.2 Observations du système
Les états du système ne sont pas (toujours) observables; par contre, le système peut être observé à travers d'autres grandeurs rassemblées dans le vecteur 𝑧. Les observations sont reliées aux états par l'équation d'observation :
( )
z h x
(2-6)avec ℎ une fonction continue qui représente la physique réelle impliquée dans l’observation des états 𝑥 du système. L’observation 𝑧 réellement disponible est entachée d’erreur 𝜀µ découlant des instruments de
mesure:
( )
z h x
(2-7)ℎ est représenté par un modèle numérique 𝐻 nommé l’opérateur d’observation qui ne manipule que des variables discrètes et ne représente que d’une façon approximative la physique inclue dans ℎ. Donc, l’observation 𝑧 est entachée d’une deuxième erreur dite de représentativité 𝜀𝑟 qui est liée à cet opérateur
d’observation:
( ) r
z H x
(2-8) L’erreur totale d’observation 𝜈 est alors égale à la somme des erreurs de mesure et de représentativité. La relation qui lie l’observation à l’état vrai est ainsi :( )
14
2.1.3 Modélisation des erreurs
Dans l’approche d’assimilation de données, on considère que l’estimation des états du système et les observations sont affectées par des erreurs déterminées par un écart par rapport à l’état vrai. Tableau 2.1 présente un récapitulatif des ces erreurs.
Tableau 2.1 Un récapitulatif des différentes erreurs utilisées dans le processus d’assimilation de données
Symbole
Nom
Définition
f
Erreur d'ébauche
fx
fx
t
Erreur d'observation
z H x( )t a
Erreur d'analyse
ax
ax
t , 1 t t w Erreur du modèle
, 1 t 1 , 1[ ]
t t t t t t tw
x
f
x
La matrice de covariance de l’erreur d’observation 𝑅 est donnée par :
cov( )
TR
E
(2-10) Les matrices de covariance d’erreur d’ébauche 𝑃𝑓 et du modèle 𝑄 s’expriment de la même façon que lamatrice de covariance d’erreur d’observation. La taille de ces deux matrices dépend du nombre d’éléments du vecteur 𝑥. Par exemple si 𝑥 contient 𝑛 éléments, les matrices 𝑃𝑓 et 𝑄 seront de dimension 𝑛 × 𝑛.
2.1.4 Récapitulatif des notations
Les principales notations employées dans les prochaines sections sont résumées au tableau 2.2. L’objectif de l’assimilation de données est d’améliorer l’état du système contenu dans le vecteur de contrôle 𝑥. L’assimilation permet de se rapprocher de l’état vrai de système 𝑥𝑡. Elle combine de façon optimale une
information de l’état à priori du système 𝑥𝑓 fournie par le modèle (état d’ébauche) à des observations 𝑧 en
tenant compte des erreurs de cette ébauche et des observations. Suite à cette combinaison optimale, on obtient l’état d’analyse 𝑥𝑎 et son erreur qui est représentée dans la matrice de covariance d’erreur d’analyse
𝑃𝑎. Pour calculer cette analyse, il faut tout d’abord calculer l’innovation 𝑑 qui est définie comme la différence
entre l’observation et l’état estimé du système, défini comme suit :
( )
d z H x
(2-11)Afin que 𝑧 et 𝑥 soient comparables, un opérateur d’observation 𝐻 est appliqué à 𝑥. On obtient ainsi un équivalent observable de l’état du système 𝐻(𝑥). Les états du système varient dans le temps et leur
15 propagation est effectuée en se basant sur un modèle 𝑓 qui permet de propager ces états d’un pas de temps à un autre. Ce modèle est caractérisé aussi par une erreur qui est représentée dans la matrice Q.
Tableau 2.2 Récapitulatif de différents termes utilisés dans l’assimilation de données
Symbole Nom
𝑥
Vecteur de contrôle
𝑥
𝑡Vecteur d'état vrai
𝑥
𝑓Vecteur d'ébauche
𝑥
𝑎Vecteur d'analyse
𝑧
Vecteur d'observation
H
Opérateur d'observation potentiellement non linéaire
H
Opérateur d'observation linéaire
𝐻(𝑥)
Équivalent observable de l'état du système
f
Modèle de propagation potentiellement non linéaire
f
Modèle de propagation linéaire
ḟ
Jacobienne du modèle de propagation
𝑑
Vecteur d'innovation
𝑃
𝑓Matrice de covariance d'erreur d'ébauche
𝑃
𝑎Matrice de covariance d'erreur d'analyse
𝑅
Matrice de covariance d'erreur d'observation
𝑄
Matrice de covariance d'erreur du modèle
2.2 Description de quelques techniques d’assimilation de
données
2.2.1 Assimilation séquentielle
Dans l’assimilation séquentielle, les observations sont utilisées dès qu'elles deviennent disponibles pour corriger l'état actuel du modèle. Ces méthodes entrainent aînsi à des discontinuités dans les séries chronologiques de l'état corrigé (Drécourt 2004). La figure 2.1 détaille le principe de ces méthodes d’assimilation séquentielle.
16
Figure 2.1 Approche d’assimilation séquentielle de données. Lorsqu'une observation est disponible (+), la prévision du modèle (cercle blanche) est mise à jour à une valeur plus proche de l'observation
(cercle noire) et est ensuite utilisée pour la prévision suivante (Berthet 2010)
L’assimilation séquentielle à l'aide d'algorithmes de filtrage a attiré l'attention des hydrologues en raison de sa flexibilité à intègrer toutes les sources d'incertitudes et de la possibilité de gérer les données séquentiellement dès qu'elles sont disponibles (Moradkhani 2008). Il existe plusieurs méthodes d’assimilation séquentielle. Parmi celles-ci, notons le filtre de Kalman qui repose sur une approche statistique. Le principe de cette méthode est simple : il s’agit de corriger la trajectoire du modèle en combinant les observations avec l'information fournie par le modèle de façon à minimiser l'erreur entre l'état vrai et l'état filtré (Berrada 2006). « Le filtre fournit une estimation du vecteur d’état et de sa matrice de covariance des erreurs qui contient les informations concernant la précision des variables » (Ouachani et al. 2007).
Pour les systèmes linéaires, le filtre de Kalman standard est fonctionnel. Par contre, pour les systèmes non linéaires, d’autres méthodes sont préférables comme le filtre de Kalman étendu et le filtre de Kalman d’ensemble. Depuis la fin des années 1970, plusieurs études ont exploré le filtre de Kalman pour la modélisation pluie–débit (Bàlint 2002). La majorité des modèles hydrologiques utilisés pour l’assimilation des données sont simples, tels que les modèles à moyenne mobile auto-régressive (ARMA) et les modèles à réservoir linéaire. Peu d’études ont intégré le filtre de Kalman à des modèles hydrologiques complexes. Wood et Szollosi-Nagy (1978) et Kitanidis et Bras (1980a,b) sont des exemples typiques. Lee et Singh (1999) ont testé le filtre de Kalman standard avec quelques modèles pluie-débit et ont constaté une augmentation de la précision et une diminution de l’incertitude suite à son application. Schreider et al. (2001) ont tiré des
17 conclusions semblables. Dans le cas du filtre de Kalman étendu, les tests ont davantage porté sur des modèles hydrologiques conceptuels non linéaires (Quesney et al. 2000 ; Georgakakos et Smith 1990). Ces auteurs ont montré une amélioration dans le processus de prévision en utilisant cette méthode, qui est considérée comme efficace dans un environnement opérationnel pour la prévision en temps réel. Pour leur part, Moradkhani et al. (2005a) et Meier et al. (2011) ont utilisé le filtre de Kalman d’ensemble (EnKF : Ensemble Kalman Filter) pour estimer à la fois les paramètres et les variables d’état d’un modèle hydrologique conceptuel. Hartnack et Madsen (2001) ont effectué plusieurs tests pour améliorer la performance de la partie hydraulique du modèle hydrologique distribué MIKE 11. Tous ces chercheurs se sont déclarés satisfaisants de la performance du filtre de Kalman d’ensemble.
2.2.1.1 Le filtre de Kalman et ses variantes
Le filtre de Kalman est défini comme un ensemble d’équations mathématiques qui permet une meilleure estimation de l’état futur d’un système malgré l’imprécision des mesures et de la modélisation (Enzo et al. 2010). Il décrit le modèle et le système dans l'espace des états et permet d’assimiler les données d’une facon séquentielle. A chaque fois qu’une observation 𝑧 est disponible, le vecteur d’état de prévision du modèle 𝑥𝑡𝑓 au temps 𝑡 est mis à jour en tenant compte des erreurs sur les observations et le modèle afin d’obtenir le vecteur d’état d’analyse 𝑥𝑡𝑎. Les observations sont reliées aux états par l'équation d'observation:
H( )
t t t
z x
(2-12)Où H est l'opérateur d'observation et 𝜈𝑡 le bruit correspondant à l'incertitude d'observation. La représentation de l’espace d’état est définie comme suit;
1 f, 1( )
t t t t
x x (2-13)
Avec 𝑥𝑡 le vecteur d’état à l’instant 𝑡 de dimension (n × 1); f représente la mise en équation des processus reliant l’état de système entre le temps 𝑡 et temps 𝑡 + 1.
Le filtre comporte deux étapes :
Phase de correction: cette phase a lieu si une base de données extérieure (mesures) est disponible et on suppose connue les matrices de covariance d’erreur 𝑃𝑡𝑓 associée à 𝑥𝑡𝑓 et 𝑅 associé à 𝑧. Dans cette phase, le gain de Kalman et le vecteur d’état a posteriori 𝑥𝑡𝑎 sont estimés en se basant sur le
18
Ainsi, la matrice de covariance 𝑃𝑡𝑎 (mise à jour) est calculée;
T T 1 H (H H ) f f t t K P P R (2-14) [ H( )] a f f t t t t x x K z x (2-15) ( H) a f t t P I K P (2-16)
Phase de propagation: au niveau de cette phase les incertitudes évoluent dans le temps et le vecteur d’état a priori pour le pas de temps suivant est calculé. Donc, le vecteur d’état a priori 𝑥𝑡+1𝑓 et la propagation de variance 𝑃𝑡+1𝑓 sont déterminées comme suit :
1
f [ ]
t,t+1 f a t tx
x
(2-17) T 1f
f
f a t tP
P
Q
(2-18)avec ḟ le jacobien du modèle de propagation ft,t+1, 𝑄 la matrice de covariance d’erreur du modèle.
Le terme [𝑧𝑡 − H(𝑥𝑡𝑓)] représente l’innovation qui définit l’accord entre les quantités observées 𝑧𝑡 et leur équivalent issu de la simulation H(𝑥𝑡𝑓).
Puisque la plupart des modèles hydrologiques sont des modèles non linéaires, il n’est pas possible de leur appliquer le filtre de Kalman directement (Enzo et al. 2010). Ce pour cela que plusieurs auteurs ont adapté les filtres à ces nouvelles conditions. Parmi ces variantes, notons le filtre de Kalman d’ensemble (EnKF) qui sera utilisé dans le cadre de ce projet. La méthode EnKF a reçu une attention considérable par les hydrologues ces dernières années car elle est facile à mettre en œuvre et présente beaucoup d’avantages par rapport au filtre de Kalman traditionnel (Moradkhani 2008; Evensen 1994). L’avantage de cette méthode par rapport aux autres variantes de filtre de Kalman est qu’elle n’est pas limitée à la présence d’une approximation linéaire du modèle pour la propagation de l’erreur (Slater et Clark 2006). La méthode statistique de Monte Carlo forme la base pour la prédiction d’erreur dans le filtre de Kalman d’ensemble (EnKF). Donc le système n’est plus représenté par un vecteur d’état mais par un ensemble de vecteurs d’états. Chaque état initial présente un membre (𝑖) d’un grand nombre d’ensemble. Les points initiaux qui présentent une moyenne 𝑥 et une covariance 𝑃0𝑓 se propagent d’une façon indépendante dans le temps sans aucune linéarisation jusqu'à une mesure extérieure sera disponible (Daget 2007). La déformation de nuage permet de déterminer la propagation des erreurs, alors la propagation de matrice de covariance d’erreur 𝑃𝑓 n’est pas calculée mais