Contribution à la commande adaptative robuste d’une classe de systèmes non linéaires.
Texte intégral
Figure
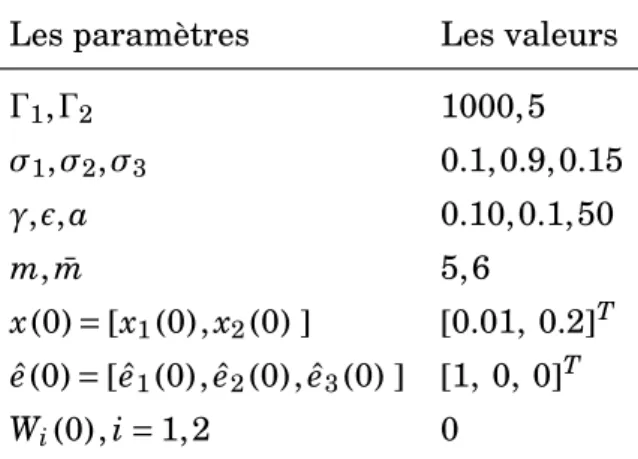
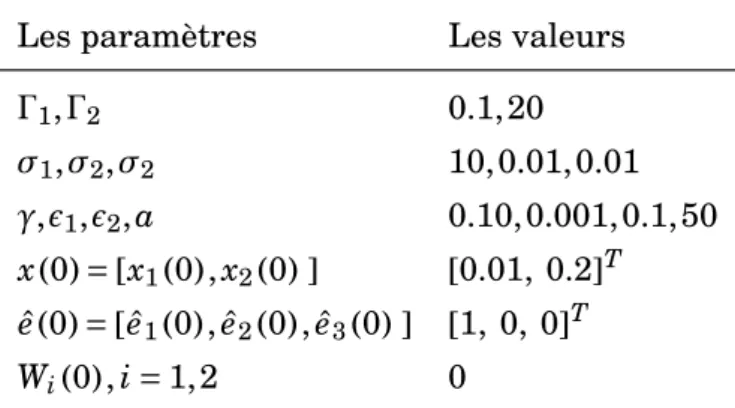
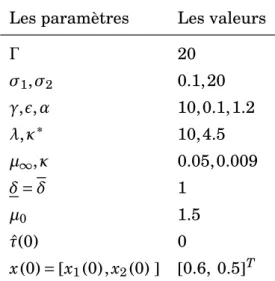
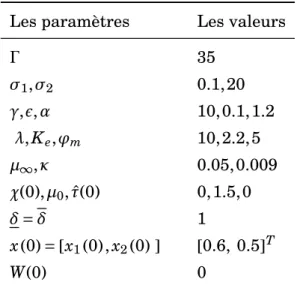
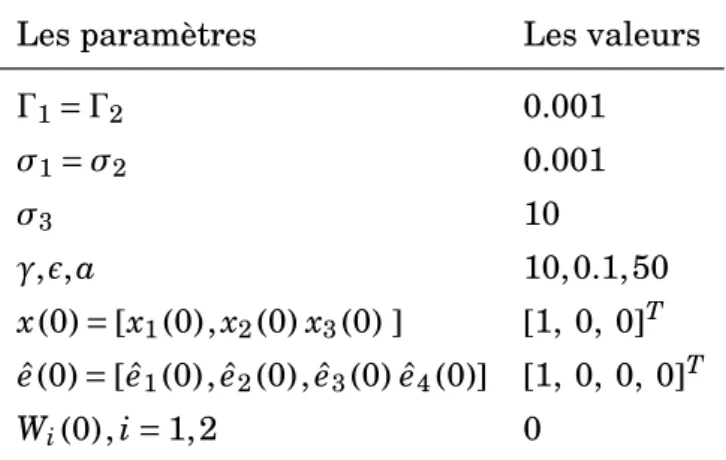
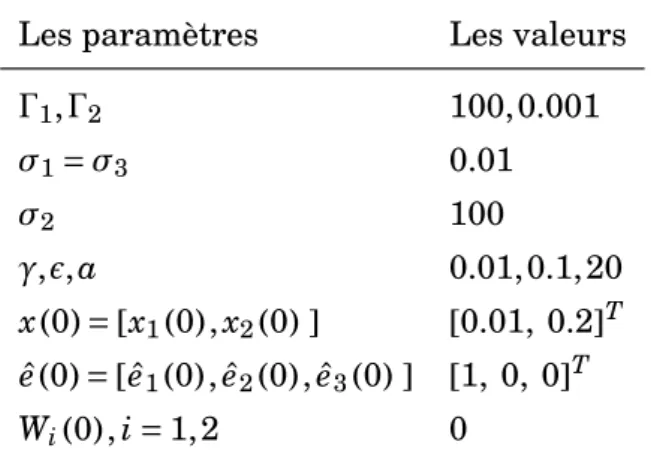


Documents relatifs
Dans ce travail, nous présentons le développement de structures de commande adaptative floue basées sur les systèmes flous type-1 et les systèmes flous type-2 pour
Les travaux présentés dans cette thèse de Doctorat ont pour objectif principal le développe- ment de structures de commande adaptative floue combinées à différentes approches
Dans cette section, nous avons proposé un schéma de commande pour une classe de systèmes non linéaires. On a utilisé pour cela un système de réseau de neurone RBF en ligne basé
Dans ce chapitre, une nouvelle structure de commande neuronale permettant de rendre une adaptation directe des poids du réseau de neurones est introduite. La méthode
Résumé –Ce travail porte essentiellement sur l’introduction de techniques d’optimisation dans les systèmes
Dans le prochain chapitre, nous allons introduire une approche de commande L1 adaptative floue pour une classe des systèmes MIMO avec une application sur un
Les résultats que nous avons développés dans le cadre des travaux de la thèse, ont permis dans un premier temps d’approcher des systèmes non linéaires de dimension infinie par des
Dans ce mémoire, nous allons appliquer la commande adaptative directe à modèle de référence (CAMR) d’ordre entier et d’ordre fractionnaire sur quelques
