Sur l’évaluation de densités prédictives pour des modèles de loi Gamma
Texte intégral
Figure


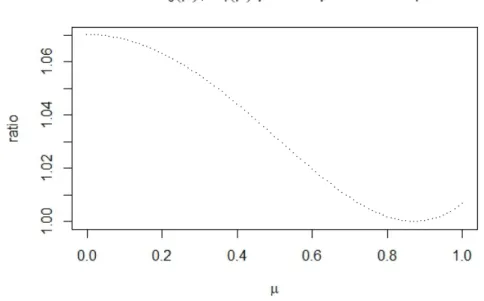
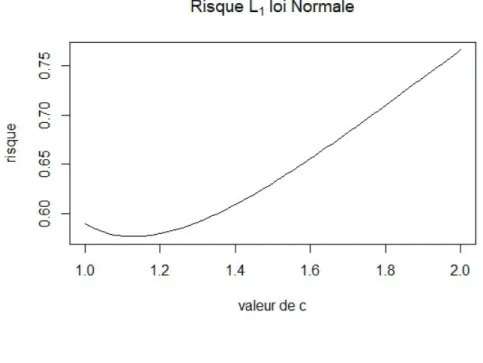
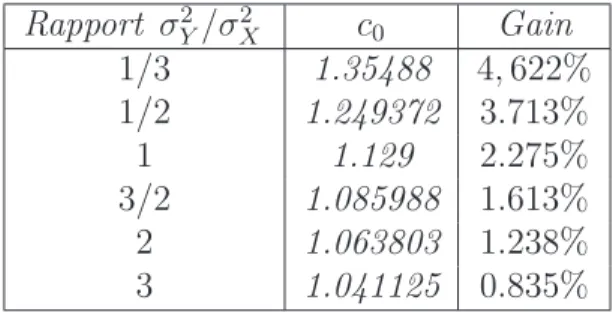

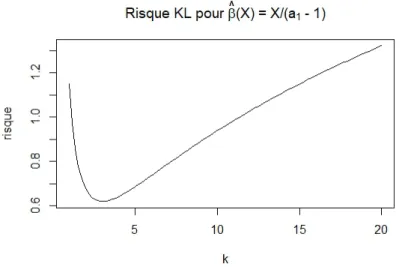
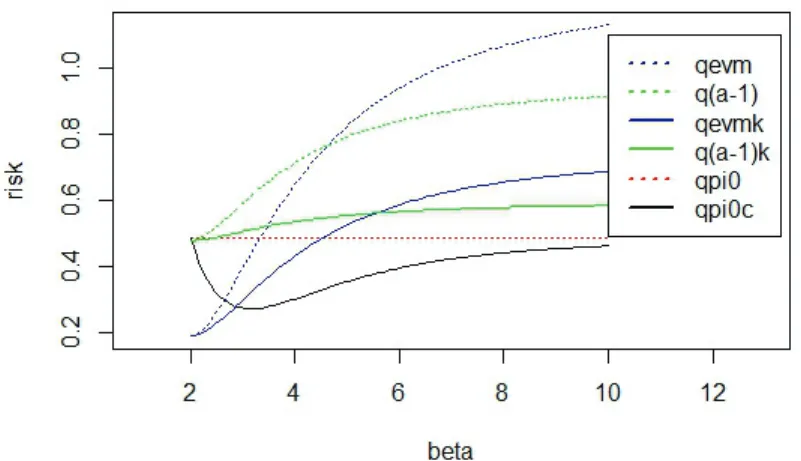

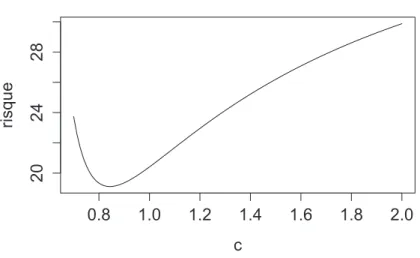
Documents relatifs
Une matrice sym´ etrique r´ eelle est dite positive si ses valeurs propres sont positives et elle est dite d´ efinie positive si ses valeurs propres sont strictement positives.. On
Proposer une situation, avec deux groupes de 12 personnes de moyennes d’ˆ ages 18 ans et 29 ans, o` u Max n’aurait pas du tout fait le
• Si les suites (u 2n ) et (u 2n+1 ) convergent vers une mˆeme limite ℓ, alors (u n ) converge ´egalement vers ℓ.. • Utilisation de suites extraites pour ´etablir la
Enfin, on remarque que pour les nombres auxquels on associe des groupes cycliques, l’intersection entre l’ensemble des g´ en´ erateurs du groupe et l’ensemble des nombres
Remarque Nous ne serons pas plus royaliste que le ”roi concepteur” et nous ne soul` everons pas de difficult´ e au niveau des probabilit´ es conditionnelles sur la nullit´ e de
Ces trois identit´es sont ` a connaˆıtre parfaitement et ` a savoir utiliser [comme dans l’exemple
´etabli dans [35] et [38], pour en tirer des r´esultats fins sur la g´eom´etrie des vari´et´es ou des fibr´es. Nous d´emontrons ainsi une version du th´eor`eme de Lefschetz
[r]
