En vue de l'obtention du
122
0
0
Texte intégral
(2)(3)
(4)(5)
(6)(7)
(8)(9)
(10)(11)
(12)
(13)
(14)
(15)(16)(17)
(18)
(19)
(20)
(21)
(22)
(23)
(24)
(25)
(26)
Figure

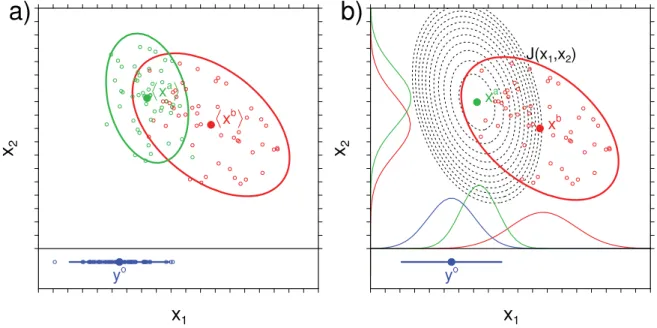

+7






Documents relatifs
Le séchage est l’une des méthodes les plus anciens et traditionnels pour préserver les herbes et les légumes. L’objectif de ce travail est d’étudié l’effet du séchage
Dans ce contexte, l’investissement étranger, sous forme de partenariat industriel est considéré comme un facteur de croissance, en raison notamment de son apport en épargne pour
Notre étude vise à contribuer à l’importance de la préservation de l’espace vert et de clarifier les lois de la protection juridique pour garder les espaces verts existants et
Il demande à son opticien que chaque verre soit maintenu dans une armature en forme de triangle rectangle et dont les longueurs des trois côtés soient entières?. Pouvez-vous
Il demande à son opticien que chaque verre soit maintenu dans une armature en forme de triangle rectangle et dont les longueurs des trois côtés soient
La distribution des femmes enceintes hypertendues en fonction de l’âge durant la période d’étude est représentée dans la Figure11. Figure 11 : Représentation graphique de
Avec le groupe, j’utilise cinq instruments de musique différents : la guitare, la Derbouka, le mélodica, le xylophone et le piano. Ils impliquent donc des
❏ Très satisfaisant ❏ Satisfaisant ❏ Insatisfaisant ❏ Très insatisfaisant ❏ Non Mesuré Item noté Non mesuré pour les bars sans offre de restauration.. Famille
