Faculté des Sciences, 4 Avenue Ibn Battouta B.P. 1014 RP, Rabat-Maroc
Tel +212 (0) 37 77 18 34/35/38, Fax : +212 (0) 37 77 42 61, http://www.fsr.ac.ma
RABAT
Numéro d'ordre : 2339
THESE DE DOCTORAT
Présentée par :
Mohammed BENABDELLAH
Discipline : Sciences de l'ingénieur
Spécialité : Informatique, Télécommunications et Multimédia
OUTILS DE COMPRESSION ET DE
CRYPTO-COMPRESSION : APPLICATIONS AUX IMAGES
FIXES ET VIDEO
Soutenue publiquement le 20 Juin 2007 à 16h30, devant le jury composé de :
Président :
El. H. BOUYAKHF
Professeur à la Faculté des Sciences de Rabat-Agdal.
Examinateurs :
F. REGRAGUI
A. TOUZANI
N. ZAHID
A. TAMTAOUI
Professeur à la Faculté des Sciences de Rabat-Agdal,
Professeur à l'Ecole Mohammadia d'Ingénieurs de Rabat,
Professeur à la Faculté des Sciences de Rabat-Agdal,
Professeur à l’Institut National des Postes et
Télécommunications de Rabat.
Mes travaux de recherche effectués au sein du Laboratoire d’Informatique, Mathéma-tiques Appliquées, Intelligence Artificielle et Reconnaissance de Formes (LIMIARF), sous la direction du Professeur d’Enseignement Supérieur Madame Fakhita Regragui, portent sur la compression et la crypto-compression des images fixes et aussi sur la compression des séquences vidéo. Ces trois volets de recherche ont fait l’objet de plusieurs publica-tions et communicapublica-tions. Pour la compression des images fixes, nous avons introduit deux articles. Le premier papier intitulé "adaptive compression of images based on wavelets" était publié par International Journal of Computer Sciences and Telecommunications (GESJ). Le deuxième article sous le titre "Adaptive compression of cartographic images based on Haar’s wavelets" était publié par The Morrocan International Journal Physical and Chemical News. Sur le deuxième axe concernant la crypto-compression des images, nous avons publié un article intitulé "Encryption-Compression of Echographic images using FMT transform and DES algorithm" dans le journal International INFOCOMP et un autre sous le titre "Encryption-compression of images based on Faber-schauder Multi-scale Transform and AES algorithm" qui a été publié par le Journal International Applied Mathematical Sciences. Quant au troisième volet traitant la compression vidéo, nous avons reussi à introduire deux papiers, le premier qui a pour titre "A method for choosing reference images based on edges detection for video compression" était publié par International Journal of Computer Sciences and Telecommunications, et le deuxième intitulé "Choice of reference images for video compression" qui se base sur la Transforma-tion Multi-échelle de Faber Schauder a été publié dans le Journal InternaTransforma-tional Applied Mathematical Sciences.
Ces travaux de recherche sont réalisés en co-direction de Professeur d’Enseignement Supérieur à la Faculté des Sciences de Rabat, Monsieur El Houssine Bouyakhf, et le
Professeur Assistant à la Faculté des Sciences de Rabat, Monsieur Mourad Gharbi, et aussi en collaboration et en co-direction, sur l’axe de crypto-compression, de Professeur d’Enseignement Supérieur à la Faculté des sciences de Rabat Monsieur Noureddine Zahid.
Je tiens à exprimer ma gratitude et mes vifs remerciements à :
Mon directeur de recherche, Madame Fakhita Regragui, Professeur d’Enseignement Supérieur à la Faculté des sciences de Rabat-Agdal, pour sa bienveillance et ses conseils avisés, pour l’aide et pour l’orientation durant ma préparation doctorale,
Mon Directeur des Ressources Humaines de Ministère de la justice, Monsieur Said Soufi, qui m’a beaucoup encouragé et aidé afin de pouvoir continuer mes recherches doc-torales,
Le président de jury, Monsieur El Houssine Bouyakhf, Professeur d’Enseignement Su-périeur à la Faculté des sciences de Rabat-Agdal et responsable du Laboratoire d’Informa-tique, Mathématiques Appliquées, Intelligence Artificielle et Reconnaissance de Formes, qui m’a aussi dirigé, en collaboration, durant ma préparation de thèse doctorale,
Monsieur Noureddine Zahid, Professeur d’Enseignement Supérieur au laboratoire LCS, à la Faculté des sciences de Rabat-Agdal, d’avoir accepter de rapporter ce travail, je le remercie également pour l’aide et la direction durant ma préparation doctorale surtout sur la partie de crypto-compression et aussi pour sa participation au jury afin de juger en totalité mes travaux de recherche.
Monsieur Abderrahmane Touzani, Professeur d’Enseignement Supérieur à l’Ecole Mo-hammadia d’Ingénieurs, d’accepter de participer au jury et de m’avoir honnorer en rap-portant cette thèse, je le remercie vivement pour ces cours de traitement d’images qui nous a donnée au cours de la préparation de mon DESA.
Monsieur Ahmed Tamtaoui, Professeur d’Habilitation à l’Institut National de Poste et Télécommunications, d’avoir examiner et juger mes travaux de recherche.
Je ne pourrai clôre ces remerciements avant de remercier vivement tous mes collègues de service informatique au DRH de la justice, surtout mon chef de service d’informatique, Madame Latifa Elharadji, qui m’a encouragé pour continuer ma préparation doctorale,
Avant Propos i
Résumé xii
Abstract xiii
Introduction 1
Objectifs et plan de thèse 5
1 Théorie de l’information, codages et définitions en imagerie 7
1.1 Approche historique de la théorie de l’information . . . 7
1.2 Codages des images binaires . . . 9
1.2.1 Définitions principales . . . 9
1.2.2 Codage par segments . . . 13
1.2.3 Codage par contours . . . 14
1.2.4 Codage par régions . . . 15
1.2.5 Codage par formes . . . 16
1.3 Notion de la lumière . . . 17
1.3.1 Définition . . . 17
1.3.2 Notion de la couleur . . . 17
1.3.3 Fonctionnement de l’œil humain . . . 18
1.3.4 Synthèse additive et soustractive . . . 19
1.4 Codage de la couleur . . . 21
1.4.1 Les représentations de la couleur . . . 21
1.4.2 Le codage RGB . . . 21 1.4.3 Le codage HSL . . . 22 1.4.4 Le codage CMY . . . 23 1.4.5 Le codage CIE . . . 24 1.4.6 Le codage YUV . . . 25 1.4.7 Le codage YIQ . . . 25
1.5 Image numérique, Informations et Médias . . . 26
1.5.1 Les images numériques . . . 26
1.5.2 L’évolution des informations . . . 33
1.5.3 Les médias . . . 33
1.6 Technologies d’affichage et Définitions en imagerie . . . 36
1.6.1 Les technologies d’affichage . . . 37
1.6.2 La notion de pixel . . . 38 1.6.3 Dimension . . . 38 1.6.4 Bruit . . . 38 1.6.5 Histogramme . . . 39 1.6.6 Contours et textures . . . 39 1.6.7 Contraste . . . 39
1.6.8 Images à niveaux de gris . . . 40
1.6.9 Images en couleurs . . . 40
1.6.10 La représentation en couleurs réelles . . . 40
1.6.11 La représentation en couleurs indexées . . . 41
1.6.12 Autres modèles de représentation . . . 41
1.6.13 Définition et Résolution . . . 41
1.6.14 Le codage de la couleur . . . 42
1.6.15 Poids d’une image . . . 43
1.6.16 Transparence . . . 43
1.6.17 Format de fichier . . . 44
1.7 Introduction à la vidéo numérique . . . 45
1.7.1 Définition de la vidéo . . . 45
1.7.2 Vidéo numérique et analogique . . . 45
2 Principes de la compression en imagerie 49
2.1 Introduction . . . 49
2.2 Intérêt de la compression . . . 50
2.3 La compression de données . . . 50
2.4 Caractérisation de la compression . . . 50
2.5 Types de compressions et de méthodes . . . 51
2.5.1 Compression physique et logique . . . 51
2.5.2 Compression symétrique et asymétrique . . . 51
2.5.3 Compression avec pertes . . . 51
2.5.4 Encodage adaptif, semi adaptif et non adaptif . . . 52
2.5.5 Filtrage . . . 52
2.6 Les principes de base . . . 54
2.6.1 Extraction de l’information pertinente et élimination de la redondance 54 2.7 Les mesures utilisées . . . 56
2.7.1 Evaluation de la compression . . . 56
2.7.2 La mesure de la qualité de l’image . . . 57
2.8 Cas des séquences animées . . . 60
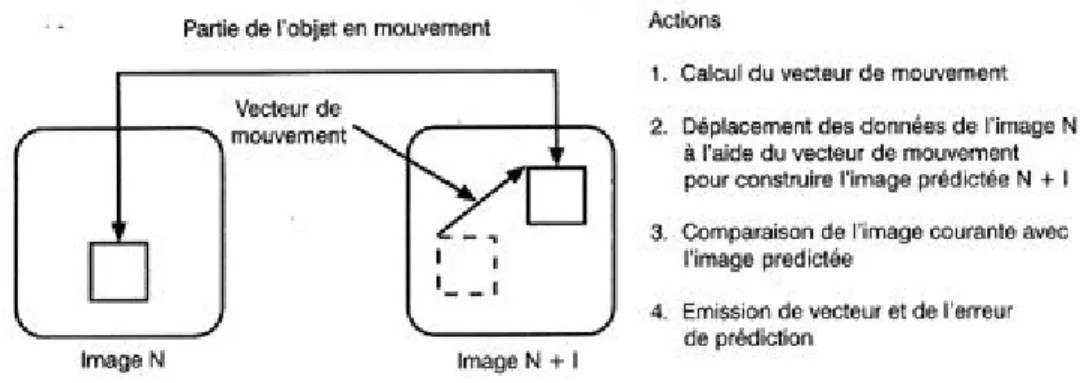
2.8.1 Analyse du mouvement . . . 60
2.8.2 Les méthodes de compensation de mouvement . . . 60
2.9 Les normes de compression des images . . . 66
2.9.1 La norme de compression JPEG . . . 66
2.9.2 La norme de compression JBIG . . . 67
2.9.3 La norme de compression H.26x . . . 67
2.9.4 La norme de compression MPEG . . . 69
2.10 Conclusion . . . 70
3 Compression des images fixes 71 3.1 Introduction . . . 71
3.2 Les diverses méthodes de compression . . . 72
3.2.1 Classification des méthodes de compression . . . 72
3.2.2 Méthodes sans distorsion des données . . . 73
3.3 Compression adaptative d’images basée sur les ondelettes . . . 103
3.3.1 Introduction . . . 103
3.3.2 Méthodes . . . 105
3.3.3 Applications et résultats . . . 116
3.4 Conclusion . . . 122
4 Compression des séquences vidéo 124 4.1 Introduction . . . 124 4.2 Le MPEG-1 . . . 125 4.2.1 Les frames I . . . 126 4.2.2 Les frames P . . . 126 4.2.3 Les frames B . . . 126 4.2.4 Les frames D . . . 127
4.3 Les différents codecs . . . 127
4.4 Modélisation du mouvement . . . 129
4.5 Estimation du mouvement . . . 129
4.6 Méthode de choix des images de référence . . . 130
4.6.1 Introduction . . . 130 4.6.2 Méthodes . . . 131 4.6.3 Applications et Résultats . . . 150 4.7 Conclusion . . . 154 5 Crypto-Compression d’images 155 5.1 Introduction . . . 155 5.2 Cryptographie . . . 156
5.2.1 Les techniques de cryptographie . . . 157
5.2.2 Quelques applications de la cryptographie . . . 162
5.3 Méthodes . . . 174
5.3.1 Transformation multi-échelle de Faber-Schauder . . . 174
5.3.2 Schéma de principe des approches de crypto-compression proposées 180 5.4 Résultats . . . 181
5.4.2 Comparaison . . . 184 5.5 Conclusion . . . 185
Conclusion générale et perspectives 187
Annexes 192
1.1 L’espace de rayonnements observés par l’œil humain. . . 18
1.2 Les composantes de l’œil humain. . . 18
1.3 Représentation de la Sensibilité de l’œil humain aux trois couleurs primaire. 19 1.4 Synthèse additive des couleurs. . . 20
1.5 Synthèse soustractive des couleurs. . . 20
1.6 Représentation graphique du codage RGB. . . 22
1.7 Représentation graphique du codage HSL. . . 23
1.8 Système colorimétrique CIE. . . 24
1.9 Détail d’une image binaire. . . 27
1.10 Détail d’une image en niveaux de gris. . . 27
1.11 Image binaire. . . 30
1.12 Image en niveaux de gris. . . 30
1.13 Image couleur. . . 30
1.14 Principe des moniteurs d’ordinateur. . . 37
1.15 Pixel : le plus petit élément constitutif d’une image numérique. . . 38
1.16 Processus de traitement d’information par l’ordinateur. . . 44
1.17 Champs des lignes paires et impaires en vidéo. . . 46
2.1 Evaluation en temps de calcul et en volume, de la compression symétrique. 51 2.2 Filtre 3 x 3 cœfficients. . . 53
2.3 Schéma de principe de la compensation de mouvement. . . 62
2.4 Sous-échantillonnage de chrominance 4 :2 :0 et 4 :2 :2. . . 63
2.5 L’ordonnancement du Flux vidéo. . . 65
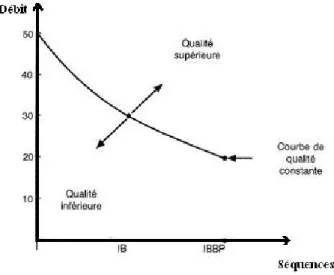
2.6 Le débit vidéo en fonction des types d’images utilisées. . . 65
2.7 Principe de l’algorithme JPEG avec pertes. . . 67
2.8 Principe de l’algorithme JPEG sans pertes. . . 67
3.1 Schéma d’un codeur source. . . 73
3.2 Principe de fonctionnement de LZ77. . . 76
3.3 Principe du quantificateur vectoriel. . . 85
3.4 Principe d’un système de codage par transformation. . . 86
3.5 Séquence ZigZag. . . 93
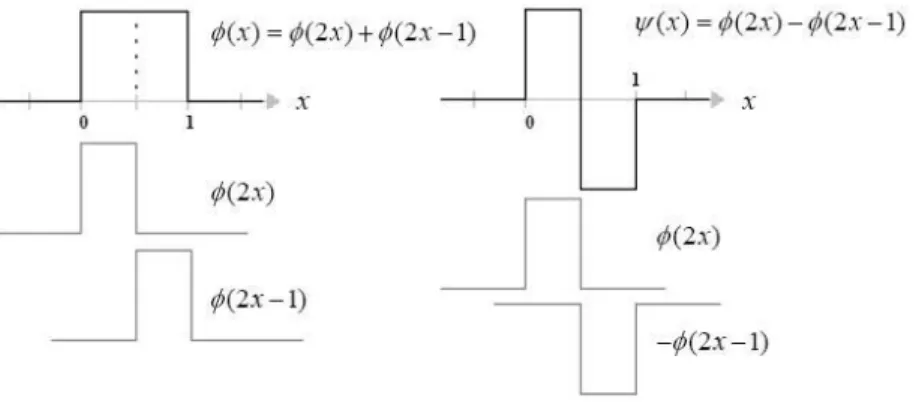
3.6 Construction de la fonction d’échelle et de l’ondelette de Haar. . . 97
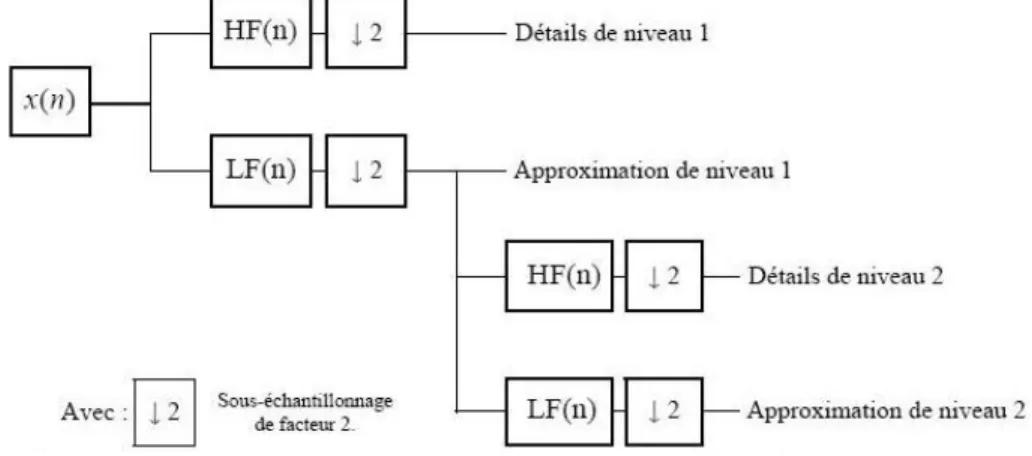
3.7 Décomposition par Analyse Multi-résolution. . . 99
3.8 Principe de décomposition 2D. . . 100
3.9 Diagramme de Mallat. . . 101
3.10 Analyse multirésolution par ondelettes de Haar d’une image de synthèse. . 101
3.11 Décomposition en sous-bandes par ondelettes. . . 102
3.12 Processus d’échange des données entre deux niveaux. . . 105
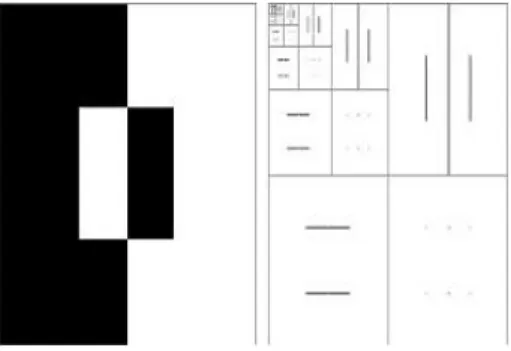
3.13 Génération des masques. . . 107
3.14 Sélection des Zones d’Intérêt. . . 108
3.15 Principe de la compression d’images par ondelettes. . . 111
3.16 Ondelette de Haar. . . 112
3.17 Construction de la base canonique de l’espace Ep à partir des vecteurs de sous-espaces Ep−1 et Fp−1. . . 112
3.18 Décomposition en 2D par ondelettes. . . 113
3.19 Schéma d’algorithme de la compression par ondelettes de Haar. . . 113
3.20 Traitement de deux couches d’ondelettes. . . 114
3.21 Schéma général de la méthode proposée. . . 116
3.22 Taux de compression théoriques obtenus en fonction du facteur de sous-échantillonage. . . 118
3.23 Résultats obtenus et publiés par le Journal International PCN. . . 122
4.1 La première et la deuxième dérivée du transition " Amplitude Jump ". . . 132
4.2 Logiciel contour2D. . . 133
4.3 Générateur du bruit gaussien. . . 134
4.5 Choix de la constante α du filte de Canny-Deriche. . . 137
4.6 Choix de rayon du cercle lié aux moments géométriques. . . 138
4.7 Configuration géométrique autour d’un pixel E. . . 139
4.8 Sous-échantillonnage de la chrominance. . . 142
4.9 Formats d’image numérique. . . 143
4.10 Schéma général d’un codeur vidéo. . . 144
4.11 Principe de codage. . . 145
4.12 Hiérarchique du codage MPEG. . . 145
4.13 Structure du GOP. . . 146
4.14 Allure typique d’une courbe du rapport débit/distorsion. . . 147
4.15 Images originales utilisées pour la constructions des images mosaïques. . . 148
4.16 Image mosaïque1. . . 148
4.17 Image mosaïque2. . . 148
4.18 Prédiction lors d’un changement de plan (Séquence News). . . 149
4.19 La séquence kiss cool. . . 150
4.20 Schéma de la méthode proposée. . . 151
4.21 Reconstruction d’une séquence. . . 152
4.22 Rapport débit/distorsion pour les différentes images Intra du GOP 78-90 de la séquence Kiss Cool. . . 152
4.23 Résultats obtenus et publiés par International Journal of computer sciences and telecommunications. . . 153
4.24 Résultats obtenus et publiés par le Journal International Applied Mathe-matical sciences. . . 154
5.1 Schéma de chiffrement et déchiffrement. . . 157
5.2 Schéma de chiffrement à clé symétrique. . . 158
5.3 Schéma de chiffrement à clé publique. . . 160
5.4 Schéma représentant l’algorithme D.E.S. . . 164
5.5 Schéma représentant le mode opérationnel C.B.C. . . 166
5.6 Schéma bloc de l’algorithme AES, version 128 bits. . . 168
5.8 Représentation à échelles séparées pour une image 9 × 9 transformée dans la base multi-échelle. . . 177 5.9 Représentation à échelles mixtes, les coefficients sont placés à l’endroit où
leurs fonctions de base sont maximales. . . 178 5.10 Représentation à échelles mixtes (en bas) et à échelles séparées (en haut) de
l’image Echographique. Les coefficients sont dans la base canonique dans (a) et (c) et dans la base multi-échelle de Faber-Schauder dans (b) et (d). . 179 5.11 Echantillon d’histogrammes de l’image " Lena " exprimée dans la base
canonique (à gauche) et dans la base multi-échelle (à droite). . . 179 5.12 Dégradation par FMT. Pourcentage de coefficients éliminées : (a) l’image
Arches originale, (b) 90%, (c) 93%. . . 180 5.13 Pourcentage des coefficients éliminés et PSNR de quelques images
recons-tituées. . . 180 5.14 Schéma de principe des approches de crypto-compression introduites. . . . 181 5.15 Les étapes suivies après application de la méthode AES-FMT sur les images
Lena, Echo.3, Flower et Arches. . . 182 5.16 Histogrammes des images originales et des images compressées et cryptées
par la méthode AES-FMT. . . 182 5.17 Les étapes suivies après application de la méthode DES-FMT sur les deux
autres images échographiques. . . 183 5.18 Histogrammes des images originales et des images compressées et cryptées
par la méthode DES-FMT. . . 183 5.19 Comparaison des methodes DCT-RSA, FMT-DES et FMT-AES
(Résul-tats publiés sur le Journal International INFOCOMP et sur le journal In-ternational Applied Mathematical Sciences). E.O.I. : Entropie de l’image originale. Q.O.I. : Qualité de l’image originale. E.R.I. : Entropie de l’image reconstituée. Q.R.I. : Qualité de l’image reconstituée. C.T. : Temps calculé. 184 5.20 Damier noir et blanc 10 × 10 pixels. . . 205 5.21 Codage de la chaîne : DU CODAGE AU DECODAGE. . . 207 5.22 Décodage de la chaîne : DU CODAGE AU DECODAGE. . . 209
Résumé
Dans ce travail, nous proposons le test de plusieurs techniques de compression sur des images fixes et animées et aussi la combinaison entre compression et cryptage des images.
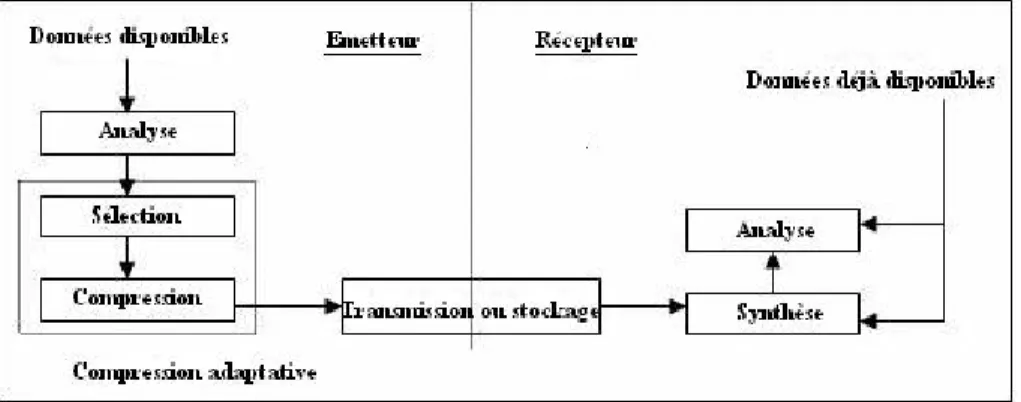
Pour la compression des images fixes, généralement, l’utilisateur ne s’intéresse qu’à certaines zones d’une même image. Ceci suggère que ces différentes zones peuvent être traitées par des approches différentes ré-versibles ou irréré-versibles. Nous proposons une approche de compression adaptative à l’aide de méthodes irré-versibles. Après sélection des zones qualifiées d’intérêt, l’approche consiste à appliquer une compression par ondelettes de Haar sur ces zones et une compression par la méthode classique JPEG avec pertes sur le contexte de l’image. Le test de cette approche sur des images avec une ou plusieurs zones d’intérêts, a révélé la supériorité de cette approche par rapport aux méthodes de compression classique en termes de taux de compression. En plus, comparée au technique adaptive basée sur LZ77, notre approche s’avère toujours plus efficace en termes de taux de compression pour une qualité visuelle comparable.
Pour la compression des images vidéo, nous proposons d’effectuer des tests sur la modification de la sé-quence d’encodage des images d’une sésé-quence vidéo, afin d’apporter un gain en termes de débit et de PSNR moyen. Les expérimentations réalisées utilisent seulement les images intra et prédites extraites de séquences sur lesquelles nous effectuons la détection de contours ou la transformation Multi-échelles de Faber-Schauder (FMT). Chacune de ces images est comparée aux autres en effectuant une soustraction des contours correspon-dants. Le choix de la meilleure image de référence, pour chaque image intra ou prédite, se base sur le critère de minimum de pixels dans le cas où les résultats après soustractions présentent uniquement des points et le critère du distance minimale entre les lignes s’ils présentent des lignes parallèles et éventuellement des points. Le test des deux approches proposées sur des séquences vidéo a révélé une amélioration de débit et du PSNR moyen par rapport à l’encodage original et à la méthode de choix des images de référence sur la base de l’erreur quadratique moyenne.
Enfin, pour la crypto-compression, Le développement des applications liées à plusieurs domaines de trai-tement d’images nécessite l’utilisation des technologies de l’information et des télécommunications qui ont évolué très rapidement ces dernières années. La compression et le cryptage de données sont deux techniques dont l’importance croit d’une manière exponentielle dans une myriade d’applications. L’usage des réseaux informatiques, pour la transmission et le transfert des données, doit satisfaire à deux objectifs qui sont la réduction du volume des informations pour désencombrer le maximum possible, les réseaux publics de com-munications et la protection en vue de garantir un niveau de sécurité optimum. Pour cela nous avons proposé deux nouvelles approches hybrides de crypto-compression, qui reposent sur un cryptage à base de l’algorithme DES et l’algorithme AES des cœfficients dominants, en représentation à échelles mixtes, de la compression par la transformation multi-échelle de Faber-Schauder. La comparaison de ces deux méthodes avec d’autres méthodes de crypto-compression a bien montré leur bonne performance.
Mots clefs : Compression adaptative, zones d’intérêt, ondelettes, images de référence, Compression vidéo, crypto-compressio.
H G
E F
Abstract
In this work, we propose the test of several compression techniques on still images and video sequences and we introduce an Encrption-compression mehtods of images.
For still images compression, the user is interested generally only in certain regions of the image. In these cases, it is reasonable to consider adaptive processing of different regions in the image. We propose an adaptive image compression technique for still images using irreversible methods. After the selection of regions of interest, the approach consists in applying wavelet compression to these regions and classical JPEG image compression with losses to the context of the image. Testing this approach on images with regions of interest produced good results. Preliminary results revealed the superiority of adaptive compression in terms of compression ratio for comparable visual image quality. Moreover, when the context is compressed using JPEG, the wavelet method on regions of interest always outperforms the reversible LZ77 method in terms of compression ratio and visual image quality.
In video compression, we propose carrying out tests on the encoding sequence of a video sequence to improve data flow and average PSNR. We experiment with the choice of reference images, in the process of video compression, by using only the intra and predicted images extracted from sequences. For each intra and predicted image, we perform edge detection or Faber-Schauder Multi-scales Transform. Each image of the sequence is compared with the other images by subtracting corresponding edges. The choice of the reference image is based on the result of subtraction. We adopt the criterion of minimum pixels if the resulting images present only points and the criterion of minimum distance between the lines if they present parallel lines and possibly points. Testing this approach on a video sequences revealed an improvement in data flow and average PSNR as compared to the original encoding and choosing reference images based on the mean square error.
Finally, The compression and the encryption of data are two techniques whose importance believes in an exponential way in a myriad of applications. The development of the applications related to several fields of image processing requires the use of telecommunication and information technologies which evolved very quickly these last years. The use of the data-processing networks, for the transmission and the transfer of the data, must satisfy two objectives which are : the reduction of the volume of information to free, the maximum possible, the public networks of communication, and the protection in order to guarantee a level of optimum safety. For this we have proposed a new hybrid approaches of encryption-compression, which are based on the DES and the AES encryption algorithms of the dominant cœfficients, in a mixed-scale representation, of compression by the multi-scale transformation of Faber-Schauder. The comparison of this approach with other methods of encryption-compression showed its good performance.
Keywords : Adaptive compression, Zones of Interest, Wavelets, Reference images, Video compression, Encryption-compression.
De nos jours, la puissance des processeurs augmente plus vite que les capacités de stockage, et énormément plus vite que la bande passante de reseaux informatiques, qui malgré les nouvelles technologies, a du mal à augmenter car cela demande d’énormes changements dans les infrastructures telles que les installations téléphoniques. Ainsi, on préfère réduire la taille des données en exploitant la puissance des processeurs plutôt que d’augmenter les capacités de stockage et de télécommunications.
Pour utiliser les images numériques, il faut comprimer les fichiers dans lesquels elles sont enregistrées. L’image consomme une quantité impressionnante d’octets quand elle est numérisée. Aujourd’hui, on parle de " qualité megapixel " pour les appareils photo numériques ; cela signifie que chaque image comporte environ un million de pixels dont chaque pixel nécessite trois octets pour les composantes RVB (rouge, vert, bleu). Donc, sans compression, cela représenterait un peu plus de 3 Mo pour une seule photographie. L’équivalent d’une pellicule de trente-six poses occuperait ainsi 100 Mo !.
Pour remédier à ces contraintes, il n’y a qu’une solution : comprimer les images. Les chercheurs ont imaginé de nombreuses méthodes de compression, que l’on classe en deux catégories : celles qui se contentent de comprimer les données sans les altérer, et celles qui les compactent en les modifiant. Les premières, dites non destructives, permettent de reconstituer, au bit près, le fichier dans l’état où il était avant la compression [123] .
Pour réduire le volume global des images tout en conservant l’image originale, un moyen consiste en la compression des images avec le minimum de dégradation et le maxi-mum d’efficacité possible.
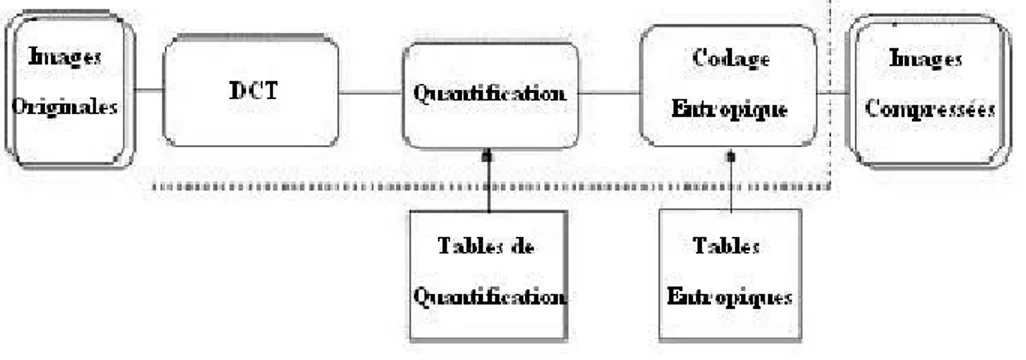
Les méthodes de compression et de codage réduisent le nombre de bits par pixel à stocker ou à transmettre, en exploitant la redondance informationnelle dans l’image.
Les principaux critères d’évaluation de toute méthode de compression sont :
– La qualité de reconstitution de l’image – Le taux de compression
– La rapidité du codeur et décodeur (codec).
Entre chacun des pixels et ses voisins, il existe une dépendance (la luminosité varie très peu d’un pixel à un autre voisin) traduisant une corrélation très forte sur l’image. On essaie donc de tirer partie de cette corrélation, pour réduire le volume d’information en effectuant une opération de décorrélation des pixels [124].
La décorrélation consiste à transformer les pixels initiaux en un ensemble de cœfficients moins corrélés, c’est une opération réversible [125].
La quantification des cœfficients a pour but de réduire le nombre de bits nécessaires pour leurs représentations. Elle représente une étape clé de la compression. Elle approxime chaque valeur d’un signal par un multiple entier d’une quantité q, appelée quantum élé-mentaire ou pas de quantification. Elle peut être scalaire ou vectorielle. Un des résultats fondamentaux des travaux de Shannon concernant la relation (Débit/distorsion) montre que l’on obtient de meilleures performances en utilisant la quantification vectorielle [126]. Une fois les cœfficients quantifiés, ils sont codés. Un codeur doit satisfaire à priori les conditions suivantes :
– Unicité : deux messages différents ne doivent pas être codés de la même façon. – Déchiffrabilité : deux mots de codes successifs doivent être distingués sans ambiguïté. L’exploitation de technologies multimédias pour une diffusion auprès du grand public, et notamment dans le secteur éducatif, suppose de disposer d’équipements d’utilisation simple et d’un coût raisonnable [127].
Pour tous les objets envisagés : sons, images naturelles fixes ou animées, réalisations infographiques..., les volumes de données générés sont considérables ; le stockage, notam-ment sur un support d’édition, le transport sur les réseaux publics, mêmes dits " à hauts débits ", voire la simple exploitation à partir d’un disque dur, supposent, dès lors qu’il s’agit par exemple de vidéo, la mise en œuvre de débits considérablement plus importants que ceux qui sont actuellement disponibles [128].
Une image au standard VGA+ (640 x 480, 256 couleurs) occupe un octet par pixel soit 300 ko. Dans cette définition, qui reste limitée par rapport aux standards audiovisuels, 25 images (soit une seconde de vidéo) occuperaient plus de 7 Mo, sans parler du son ! Il est aisé de comprendre que ces valeurs sont incompatibles avec la plupart des supports
infor-matiques actuels, et même avec les contraintes des réseaux publics ou privés envisageables à moyen terme.
La conclusion s’impose d’elle-même : en l’état, une telle technique de codage est inuti-lisable ; il est impératif de faire tenir ces informations dans un volume largement moindre, en un mot de les compresser.
Les développements technologiques et les exigences des utilisateurs conduisent à des quantités de données toujours plus importantes ; ainsi, depuis les débuts des technologies de l’information, le problème de l’exploitation optimale des voies de communication et des capacités de stockage, est toujours resté un sujet d’actualité [129]. Plusieurs études sont effectuées sur les algorithmes de compression, dans le but de mettre les données sous un format tel qu’elles occupent moins de volume. Une fois compressées, les données ne sont plus directement accessibles, et il est nécessaire de les décompresser pour qu’elles redeviennent intelligibles. La grande variété des domaines d’exploitation, chacun ayant ses contraintes spécifiques (nature des données, capacités de traitement), conduit aujourd’hui à un très grand nombre de procédés de compression [122].
Dans le multimédia, la plupart des données traitées sont volumineuses : une image 640x480 en 16 millions de couleurs approche le megaoctet. Pourtant, c’est dans le domaine de l’image animée, et en particulier de la vidéo, que le problème est particulièrement crucial : le débit nécessaire pour une séquence composée d’images VGA 256 couleurs serait de 56 Mbits/s, et les besoins d’une transmission selon la norme de vidéo numérique CCIR 601 s’élèveraient, quant à eux, à 166 Mbits/s ![117].
Les débits disponibles pour la transmission des données, constituent la contrainte principale à prendre en compte. C’est naturellement le CD-ROM simple vitesse, seul disponible il y a encore peu de temps, ainsi que le réseau Numéris (RNIS), qui ont servi de référence aux principaux travaux. Pour le CD-ROM, on obtient un débit d’environ 1,5 Mbits/s, soit à peu près 3% du flux nominal qui serait nécessaire pour transmettre des images VGA animées et moins de 0,6% si la base retenue est le format vidéo numérique normalisé CCIR 601. Pour une transmission sur le réseau Numéris, limité aujourd’hui à 64 kbits/s, ces valeurs devraient encore être divisées par près de 20 ![118].
Les ordres de grandeur de ces quelques valeurs montrent bien l’ampleur du problème à résoudre. Les techniques de compression, aussi élaborées soient-elles, ne peuvent à elles seules apporter une réponse à tous les besoins, et il sera nécessaire dans bien des cas de
faire des sacrifices sur la définition initiale. C’est ainsi que, dans le domaine de la vidéo, on a défini le format SIF (Source Intermediar Format) : retenant une définition inférieure, il exploite des flux et une qualité sensiblement plus réduits que le CCIR 601[119].
Aussi, une exploitation facile sur des matériels de grande diffusion suppose la disponibilité de composants électroniques peu onéreux, spécialisés dans la compres-sion/décompression. Les investissements nécessaires à leur fabrication en grande série ne peuvent être engagés en l’absence d’un standard reconnu, qu’il soit normalisé ou non. Pour l’heure, même si quelques solutions on fait l’objet de normalisations, et même de mise en production industrielle, les standards restent encore moins véritablement imposé, en particulier pour la vidéo [121].
Devant cette situation encore confuse, il convient sans doute de comprendre un peu les principes de fonctionnement des diverses techniques mises en œuvre. La multiplicité et la complexité des solutions ne permettent pas de dire celle qui sera la bonne. À l’heure des choix, tant pour un équipement matériel ou logiciel que pour un projet éditorial, il convient surtout de se méfier des promesses commerciales, et de privilégier, lorsque c’est possible, les options qui préserveront au mieux l’avenir [120].
D’autre part, si le but traditionnel de la cryptographie est d’élaborer des méthodes permettant de transmettre des données de manière confidentielle, la cryptographie mo-derne s’attaque en fait plus généralement aux problèmes de sécurité des communications. Le but est d’offrir un certain nombre de services de sécurité comme la confidentialité, l’intégrité, l’authentification des données transmises,.... Pour cela, on utilise un certain nombre de mécanismes basés sur des algorithmes cryptographiques. La confidentialité est historiquement le premier problème posé à la cryptographie. Il se résout par la notion de chiffrement. Il existe deux grandes familles d’algorithmes cryptographiques à base de clefs : les algorithmes à clef secrète ou algorithmes symétriques, et les algorithmes à clef publique ou algorithmes asymétriques.
Nos travaux de recherche portent sur la compression des images fixes et des images vi-déo. Ces deux volets de recherche ont fait l’objet de publications : Pour la compression des images fixes, nous avons introduit deux approches, la première " adaptive compression of images based on wavelets " publiée dans The Gergian International Journal of Computer Sciences and Telecommunications. La deuxième " Adaptive compression of cartographic images based on Haar’s wavelets " publiée à son tour dans le Journal International maro-cain Physical and Chemical News. Quant à la troisième méthode " A method for choosing reference images based on edge detection for video compression " appliquée sur la com-pression des images animées, a été publiée dans The Gergian International Journal of Computer Sciences and Telecommunications.
Le plan de la thèse sera décliné en cinq chapitres :
Le premier chapitre traite la théorie de l’information et le codage en imagerie, dans lequel nous passons en revue l’approche historique de la théorie de l’information puis nous discutons les différentes méthodes de codage des images numériques. Ensuite, nous expli-quons d’une part la notion et le codage de la lumière, la définition de l’image numérique, et d’autre part les informations, les médias, les formats de fichiers graphiques et nous donnons une introduction à la vidéo numérique en terminant par une conclusion.
Le second chapitre est reservé aux principes de la compression. Dans un premier temps, nous allons aborder l’intérêt de la compression, puis la compression de données, la carac-térisation, les types, les méthodes et les principes de base de la compression. Nous allons discuter le cas des séquences vidéo et nous terminons par une conclusion.
Pour le troisième chapitre qui discute la compression des images fixes. Nous allons parler des diverses méthodes de compression et nous détaillons le principe de base des méthodes introduites pour la compression adaptative, des images fixes, qui se base sur
les ondelettes de Haar. Dans ces méthodes, après sélection des zones qualifiées d’inté-rêt, l’approche consiste à appliquer une compression par ondelettes sur ces zones et une compression par la méthode classique JPEG avec pertes sur le contexte. Les résultats préliminaires obtenus ont révélé d’une part la supériorité des approches de compression adaptatives par rapport aux méthodes classiques en termes de taux de compression pour des qualités comparables. Enfin, nous terminons ce chapitre par une conclusion et quelques perspectives.
Le quatrième chapitre s’occupe de la partie compression des images vidéo. Dans ce cadre, nous allons parler, de la modélisation et de l’estimation du mouvement, de la méthode introduite concernant le choix des images de référence sur le processus de com-pression vidéo qui se base sur la détection des contours. L’objectif visé par cette méthode est d’effectuer des tests sur la modification de la séquence d’encodage des images d’une séquence vidéo, afin d’apporter un gain en termes de débit et de PSNR moyen. Il s’agit de réaliser des expérimentations sur le choix des images de référence en utilisant seulement les images intra et prédites extraites de séquences. Le choix de l’image de référence, pour une image donnée, se basera sur des critères selon l’aspect du résultat de la soustraction. Le test de cette approche sur des séquences vidéo a révélé une amélioration de débit et PSNR moyen par rapport à l’encodage original et à la méthode de choix des images de référence qui se base sur l’erreur quadratique moyen. Nous terminons ce chapitre par une conclusion et quelques perspectives.
Sur le cinquième chapitre, nous allons parler de la cryptographie, ses techniques et quelques algorithmes d’applications et nous expliquons les deux méthodes que nous avons introduit sur l’axe concernant la crypto-compression. Nous finalisons notre mémoire de thèse par une conclusion générale et quelques perspectives.
Théorie de l’information, codages et
définitions en imagerie
1.1
Approche historique de la théorie de l’information
L’étude scientifique de l’information a débuté en 1924 sous l’égide de mathématiciens et physiciens (Gabor, Hartley, Nyquist, Wiener), mais elle n’a pris toute sa dimension qu’avec l’élaboration de la théorie mathématique de l’information, publiée en 1949 par Shannon et Weaver. Le développement des transmissions télégraphiques imposait, déjà, d’optimiser l’utilisation des canaux de transmission offerts, et donc d’éliminer des données à transmettre tout ce qui n’était pas indispensable à la compréhension.
Ainsi, la théorie de l’information attribue à chaque signifiant élémentaire d’un message une mesure de sa quantité d’information théorique, d’autant plus élevée que ce signifiant est " nouveau ", c’est-à-dire non déductible des éléments précédents. Inversement, on attribue également une mesure de redondance à chaque élément de message, d’autant plus faible que son poids d’information est fort [2].
Pour faire comprendre le principe de sa théorie, on rapporte que Shannon se livrait à un petit jeu lors des soirées mondaines : un convive ayant choisi une phrase, les autres doivent, en connaissant uniquement le début, deviner le mot suivant. Le taux de réussite de l’assistance donne une idée de ce qu’est le " poids de redondance ", alors que son complément à 1 (100% - taux de réussite) illustre la notion de " poids d’information ". Bien que la " méthode " soit fort grossière, elle permet de mieux approcher des concepts,
par ailleurs fort compliqués...
Les systèmes organisés comme les langues naturelles offrent des caractéristiques de redondance bien précises, qui peuvent être exploitées par les systèmes de transport de l’information pour optimiser l’utilisation des canaux disponibles. La fréquence d’utilisa-tion de chaque lettre de l’alphabet, par exemple, constitue une première évaluad’utilisa-tion de sa probabilité d’apparition ; les caractères qui précèdent permettent également d’amélio-rer la " prédiction " (une voyelle, par exemple, est généralement suivie d’une consonne, et ce dans une proportion parfaitement mesurable). En faisant du caractère l’unité mi-nimale d’information, le message étant composé dans une langue donnée, on peut donc parfaitement évaluer ses caractéristiques de redondance.
De telles évaluations peuvent également être conduites en utilisant d’autres signifiants élémentaires, par exemple les mots dans le cadre de systèmes de communications utilisant un vocabulaire réduit [3].
Cependant, il ne faudrait pas déduire de ce qui précède que ce qui est redondant n’est qu’un " bruit " par rapport au " signal " principal, et peut donc être supprimé sans altérer le message. Seul un signifiant " totalement redondant " (situation impossible), qui serait l’illustration d’un événement certain (probabilité égale à 1), pourrait être considéré comme inutile. En outre, la redondance des langages naturels est souvent utile pour faciliter la compréhension d’un message, notamment en cas de dégradation partielle (communications téléphoniques dégradées). La mesure mathématique de la quantité d’information, on l’a compris, n’a qu’un très lointain rapport avec le " poids sémantique " du message dans son système d’origine.
Shannon définit également l’entropie d’un message, d’une manière comparable à la notion utilisée en thermodynamique. Dans cette discipline, il s’agit d’une grandeur phy-sique qui permet d’évaluer la dégradation de l’énergie d’un système ; on dit souvent que l’entropie mesure le degré de désordre d’un système. Dans la théorie de l’information, l’entropie d’un message indique le poids d’information mathématique qu’il porte, et donc sa " compressibilité " théorique [4].
D’un strict point de vue quantitatif, on ne peut que constater que la plupart des langues véhiculaires comprennent beaucoup moins de mots que les possibilités offertes par l’alphabet, et il en est de même de données organisées devant traduire des images et des sons.
Ainsi, les codages traditionnels, qui représentent ou cherchent à représenter toutes les combinaisons théoriques, se révèlent extrêmement simplistes et peu performants (voir codage sur annexes). Le codage ASCII sur 7 bits, par exemple, fournit plus de 4 000 milliards de possibilités pour coder les mots de 8 lettres, alors que les dictionnaires de la langue française en comptent moins de 3 000...[51].
En tenant compte des caractéristiques d’entropie des données à traiter, il est donc possible de définir des codages plus performants. Les travaux de Shannon et de ses col-laborateurs ont conduit à développer des codages statistiques fondés sur la fréquence d’apparition d’une information [2].
La théorie de l’information s’est attachée, dès les années vingt, à quantifier les flux nécessaires aux transferts d’information, ainsi qu’à optimiser l’utilisation des voies de communication en recherchant les codages les plus adaptés [51].
Shannon et Weaver ont développé une théorie mathématique qui attribue à chaque signifiant élémentaire un poids d’information d’autant plus élevé qu’il est non déductible du contexte. Le degré de complexité, ou, en référence à la thermodynamique, de désordre du message considéré est quantifié par son entropie [1].
Que chacun se rassure cependant, il n’est pas nécessaire d’avoir lu - et compris - les œuvres complètes de Shannon et Nyquist pour comprendre les principes fondamentaux des techniques de compression, pas plus d’ailleurs que pour utiliser un micro-ordinateur !.
1.2
Codages des images binaires
1.2.1
Définitions principales
Il existe un ensemble de notions propres aux images binaires. Soit I une image binaire et I(m) ou I(i,j) la valeur du pixel m de coordonnées (i,j) dans I.
Image :
Une image est une forme discrète d’un phénomène continu obtenue après discrétisation. Le plus souvent, cette forme est bidimensionnelle. L’information dont elle est le support est caractéristique de l’intensité lumineuse (couleur ou niveaux de gris).
I : [0, L-1] x [0, C-1] 7−→ [0, M ]p définit une image de L lignes et C colonnes dont l’information portée est définit dans un espace à p dimensions.
Si I est une image binaire, alors (p, M) = (1,1).
Si I est une image en niveaux de gris, alors p = 1 et le plus souvent M = 255. Si I est une image couleur, alors p = 3 et le plus souvent M = 255.
Maillage :
Le maillage est l’arrangement géométrique des pixels dans l’image. On utilise généra-lement un des trois types qui résultent de différentes tessélations du plan par des figures géométriques. Tout d’abord, le maillage carré qui correspond à la réalité physique du cap-teur CCD. On peut également utiliser un maillage hexagonal (maillage de référence pour le domaine de la morphologie mathématique). Le maillage triangulaire est plus confiden-tiel.
Distance :
Tout pixel d’une image est caractérisé par un couple de coordonnées (x,y). Il existe des distances pour tous les éléments d’une image. Pour les distances entre pixels, on se reportera aux définitions principales qui suivent. On notera par la suite d(p,q) la distance entre deux pixels.
– Soient m(x, y) un pixel et A un composant (segment ou objet) de I : D (m, A) = D (A, m) = min d(m,m’) pour tout m’ pixel de A. – Soient A et B deux composants (segments ou objets) de I :
D (A, B) = D (B, A) = min d (m, m’) pour tout pixel m de A et tout pixel m’ de B.
Les distances les plus courantes sont (pour deux pixels P (xp, yp) et Q(xq, yq) [99] :
– Distance de Manathan : d1(P, Q) = |xp − xq| + |yp − yq|
– Distance euclidienne : d2(P, Q) = [(xp− xq)2+ (yp− yq)2]1/2
– Distance de l’échiquier : dinf(P, Q) = M ax(|xp− xq|, |yp− yq|).
Ces distances sont reliées par la propriété : dinf(P, Q) ⇐ d2(P, Q) ⇐ d1(P, Q).
Voisinage d’un objet :
Par extension, on définit le voisinage de tout composant A de l’image I par l’union de tous les voisinages des pixels de A.
On peut définir un objet par la relation de voisinage. On dit que deux points P et Q sont connectés s’il existe un chemin connexe (suite de points P=P0, P1, ..., Pn−1, Pn=Q
telle que Pi est voisin de Pi−1) entre P et Q de points ayant la même valeur. Cette relation
voisinage utilisé influe bien sûr sur les objets résultants. Des algorithmes très efficaces permettent d’étiqueter les différents objets d’une image (Composantes connexes) (voir annexes)[101].
On appelle voisinage d’ordre k du pixel P et l’on note Vk(P) l’ensemble des pixels Q
définit par : Vk(P) = Q : 0 < d(P,Q) ⇐ k .
Connexité :
On appelle relation de connexité et l’on note C0(s,s’), la relation définie sur S de la
manière suivante :
a) C0(s,s’) ⇔ s dans S(i, x) et s’ dans S(i-1,x) et g(s’) < d(s)+1 ou g(s) < d(s’)+1.
On dit alors que s est connecté avec s’ ou que s et s’ sont connexes. b) C0(s,s’) ⇒ C0(s’,s).
La décomposition ligne à ligne est donc indépendante du choix de la ligne de départ. On note C0* la fermeture transitive de C0[100].
Ordre de connexité :
Il existe principalement deux ordres de connexité : 4 et 8. Ce nombre correspond à la taille du plus petit voisinage non vide d’un pixel. Un pixel a 4 voisins directs si l’on choisit la distance d1, il en a 8 avec la distance dinf [98].
Forme, Fond :
Ces deux classes forment une partition de l’image I. – Forme = m dans I : I(m) = 1
– Fond =m dans I : I(m) = 0
La forme peut représenter plusieurs objets (notion de composante connexe) ; certaines composantes du fond peuvent représenter des trous dans les objets.
Segment :
On appelle segment de l’image I, le quadruplet s = (g, d, l, v) vérifiant : Pour tout i dans [g, d], I (l, i) = v.
Un segment est donc une suite continue de pixel de même valeur sur une ligne donnée. Chaque élément du quadruplet porte un nom.
– g : gauche de s – d : droite de s – l : ligne de s – v : valeur de s
Bien sûr, cette décomposition de l’image en segments n’est pas unique car elle privilégie une analyse ligne à ligne. Une analyse colonne à colonne est tout aussi envisageable. Les éléments du quadruplet porteraient alors les noms haut, bas, colonne et valeur.
Soit S (i,x) l’ensemble des segments de la ligne i ayant pour valeur x : – S (i, x) = s : l(s) = i et v(s) = x
L’ensemble S des segments de l’image I est défini par : – S = U nioni,xS(i,x)
Région, Objet, Composante Connexe :
On appelle région ou objet, un ensemble de segments vérifiant une propriété commune. La décomposition d’une image en objets repose sur la notion de connexité. On appelle en effet objet de I tout classe d’équivalence de S par rapport à la relation C0*.
Courbe, Arc :
Une courbe est un chemin connexe dont tous les points possédant exactement deux voisins. Un arc est une courbe pour laquelle les deux points extrémités n’ont qu’un seul voisin.
L’information est codée en binaire (voir annexes). Le support évolue mais le principe est toujours le même : un même élément peut se trouver dans 2 états différents stables. Il constitue une mémoire élémentaire ou bit. Conventionnellement on attribue le symbole 0 à l’un de ces 2 états et le symbole 1 à l’autre.
A l’aide de 1 bit on a donc 2 possibilités 0/1 ou ouvert/fermé ou noir/blanc ; A l’aide de 2 bits on a 2x2 = 4 possibilités : 00/01/10/11 ;
A l’aide de 3 bits on a 2x2x2 = 23 = 8 possibilités : 000/001/010/011/100/101/110/111 ;
A l’aide de 8 bits on a 2x2x2x2x2x2x2x2 = 28 = 256 possibilités.
Cet ensemble de 8 bits est appelé " octet ". En général les informations sont regroupées par groupe de 8, 16, 24, 32 ou 64 bits c’est à dire 1, 2, 3 ou 4 octets.
Avec 16 bits ou 2 octets on a 2x2x2x2x2x2x2x2x2x2x2x2x2x2x2x2= 216 = 256x256 = 65536 possibilités.
Avec 24 bits ou 3 octets on a 256x256x256 = 16777216 possibilités (plus de 16 millions). On parle de KiloOctet : 1 Ko = 210 octets = 1024 octets (et non pas 1000...).
Mégaoctet : 1Mo = 220 octets.
L’un des points très important dans la manipulation des images binaires est leur codage, dans un but de compression de données, à partir de la matrice binaire. Un autre point important est bien sûr la description des objets codés. C’est pourquoi on recherche souvent dans bien des cas un codage qui fasse ressortir les caractéristiques et/ou facilite les traitements [95].
La représentation de départ est donc une matrice de pixels à 0 ou 1 dans laquelle apparaissent les objets. Il existe quatre types de codages :
– Codage par segments, – Codage par contours, – Codage par régions, – Codage par formes.
1.2.2
Codage par segments
Le codage d’une image binaire par segments lignes ou colonnes a déjà été abordés (voir Détail plus loin). Il peut être compacté de la manière suivante : on ne conserve pour chaque ligne que la valeur du premier segment et la liste des longueurs des différents segments (dont la valeur change obligatoirement à chaque nouveau segment). Par exemple, la ligne de pixel 1000110 sera codée par (1, 1, 3, 2,1) soit : première valeur 1, longueurs des segments successifs : 1, 3, 2, 1 soit 7 pixels au total. Sur un autre exemple :
1 1 0 0 (1, 2, 2)
0 1 1 0 (0, 1, 2, 1)
0 0 0 0 (1, 4)
1 0 0 0 (1, 1, 3)
Il est évident que plus les segments sont courts, moins le codage est efficace car les longueurs sont des entiers et non plus des valeurs binaires. Un codage équivalent est bien sûr possible avec une description en colonnes plutôt qu’en lignes. Ce codage est davantage utilisé pour réaliser des manipulations de type algébrique (complémentation, ...) que pour décrire les objets [97].
1.2.3
Codage par contours
Dans une image binaire, les points de contour sont reconnaissables au fait qu’un au moins de leurs points voisins appartient au fond. Il n’y a donc aucune ambiguïté de détection. Lors de la recherche du contour d’un objet, il est inutile de balayer toute l’image ; il existe des algorithmes de suivi de contour fournissant un codage sous forme de Freeman de la suite des points du contour.
Soit Pn un point contour courant, le point contour suivant Pn+1 est un voisin de Pn.
Le déplacement de Pn à Pn+1 ne peut se faire que dans une des 8 directions du voisinage
de Pn selon le codage de Freeman :
3 2 1
4 ∗ 0
5 6 7
Dans la majorité des cas le point Pn n’a que deux candidats potentiels pour Pn+1 dont
un est le point Pn−1. Il n’y a donc pas d’ambiguité. Cependant, il faut aussi prendre en
compte les points anguleux n’ayant aucun suivant. La technique la plus simple consiste à supprimer de l’image de départ toutes les configurations de ce type (transition L et transition I) :
0 0 0 0 0 0
0 1 0 0 1 0
0 1 1 0 1 0
Transitions en L (à gauche) et en I (à droite). Chacune de ces figures ne représente qu’un des configurations possibles. Il y a ainsi 8 configurations de chaque type, que l’on obtient par rotation de 45o.
Une fois le contour extrait, on peut se contenter de ne mémoriser que les coordonnées du point de départ et la suite des directions d (d dans 0, ..., 8) plutôt que les coordonnées des points successifs.
La suite des directions, traduit la forme et le point de départ sa localisation spatiale. Ce type de codage est très utile pour la reconnaissance de formes car beaucoup y ont vu une signature invariante d’une forme. De plus, de très nombreux paramètres de forme
peuvent être mesurés directement sur le codage de Freeman (périmètre, aire, centre de gravité, axes d’inertie, ...).
Le codage sera d’autant plus efficace en termes de compression que les objets seront gros. Soit O un objet comportant A pixels dont P sont des pixels de son contour. Le codage binaire classique nécessite A bits dans l’image de départ. Le codage de Freeman a lui besoin de 3P bits + les coordonnées d’un point de référence. Le facteur de compression sera donc directement lié au ratio P/A [96].
1.2.4
Codage par régions
Il est bien sûr possible de généraliser le codage par segments au codage des entités surfaciques bidimensionnelles. Parmis les nombreuses techniques de codage par région, la plus connue fait appel aux quadtrees. Il s’agit d’un découpage récursif du support image jusqu’à obtention de blocs homogènes (ayant tous la même valeur). A la ième itération, on définit les carrés de côté 2n−i (où 2n est le côté de l’image initiale) ; le plus petit bloc possible est le pixel. Ces primitives sont ensuite organisées de façon arborescente.
Exemple :
Pour le codage, on utilise une technique de parenthésage (une parenthèse équivaut à un niveau de récursivité dans l’algorithme de recherche de blocs homogènes) et on mémorise uniquement la valeur du bloc.
1 2
3 4
On obtient alors le codage suivant :
I = (((0001)(0)(0111)(1))((0010)(0)(1000)(0))(1)(0))
Cette représentation permet des opérations ensemblistes (intersection, union,...), la recherche de contours, ... ; mais elle n’est pas vraiment adaptée à la description de formes de par sa non invariance en translation.
D’autres types de pavages peuvent être définis, par exemple en polygones de Voronoï, à partir de germes prédéfinis dans l’image [99].
1.2.5
Codage par formes
Parmis les méthodes tenant davantage compte de la morphologie de l’objet, on trouve en premier lieu les codages par squelettes.
Un squelette est une représentation filiforme en centrée de l’objet initial, obtenu par amincissements successifs. Cet amincissement se réalise sous la contrainte de préservation des points significatifs de son élongation, ou nécessaires à la connexité du squelette ré-sultant (transformation homotope). De très nombreux travaux portent sur la recherche d’algorithmes efficaces (temps de calcul, qualité du résultat), en particulier pour le traite-ment en reconnaissance des caractères. En effet, si le squelette est unique et sans problème dans un espace continu, il est beaucoup moins facile à trouver dans un espace discret qu’est une image numérique. Sa définition plus précise nécessite de redéfinir les concepts de base de la géométrie, ce qui a donné naissance à la géométrie discrète [8].
La transformation produisant le squelette d’un objet n’est pas réversible (on ne peut revenir à l’objet en partant de son seul squelette) mais elle donne un résultat significatif de l’allure de l’objet codé et est donc particulièrement adapté aux objets minces.
Bien sûr, la réversibilité du codage est primordiale pour des objets que l’on souhaite stocker. La notion d’axe médian est à ce titre intéressante : on recouvre l’objet par des boules de taille maximale incluses dans l’objet et centrées sur les points de l’objet. L’axe médian est ensuite formé des centres des boules qui ne sont pas incluses dans aucune autre et l’on associe aux centres conservés la taille de leurs boules. Dans l’exemple suivant,
on représente en chaque point la taille de la plus grande boule centrée sur le point et complètement contenue dans la forme (une taille de 1 équivaut à un carré 1x1, 2 à un carré 3x3 et 3 à un carré 5x5) :
Les points en noirs sont les trois points de l’axe médian nécessaire pour reconstruire la forme initiale. La taille de la boule correspond en fait à la notion de distance au contour. Le résultat final dépend de la distance utilisée. Le problème de l’axe médian est qu’il n’est pas formé de points consécutifs. Pour le faire " ressembler " à un squelette, on reconnecte les poins de l’axe médian par un chemin de crète. On obtient alors la ligne médiane que l’on peut voir comme un squelette pondéré de l’objet initial. La ligne médiane et l’axe médian sont des codages réversibles [98].
1.3
Notion de la lumière
1.3.1
Définition
C’est une forme d’énergie issue de deux composantes : – une onde électromagnétique ondulatoire
– un aspect corpusculaire (les photons)
La lumière a une vitesse de déplacement d’environ 300000 km/s, et une fréquence d’environ 600000 GHz.
1.3.2
Notion de la couleur
Elle est caractérisée par sa fréquence, elle-même conditionnée par la longueur d’onde et la célérité de l’onde. On caractérise généralement la longueur d’onde d’un phénomène oscillatoire par la relation :
λ = CT , où :
– λ désigne la longueur d’onde
– C désigne la célérité de l’onde (pour la lumière 3 × 108 m/s) – T désigne la période de l’onde (en secondes)
L’œil humain est capable de voir des lumières dont la longueur d’onde est comprise entre 380 et 780 nanomètres. En dessous de 380 nm se trouvent des rayonnements tels que les ultraviolets, au-dessus de 780 on trouve les rayons infrarouges.
Fig. 1.1 – L’espace de rayonnements observés par l’œil humain.
1.3.3
Fonctionnement de l’œil humain
Grâce à la cornée (l’enveloppe translucide de l’œil) et de l’iris (qui en se fermant permet de doser la quantité de lumière), une image se forme sur la rétine. Celle-ci est composée de petits bâtonnets et de cônes.
Fig. 1.2 – Les composantes de l’œil humain.
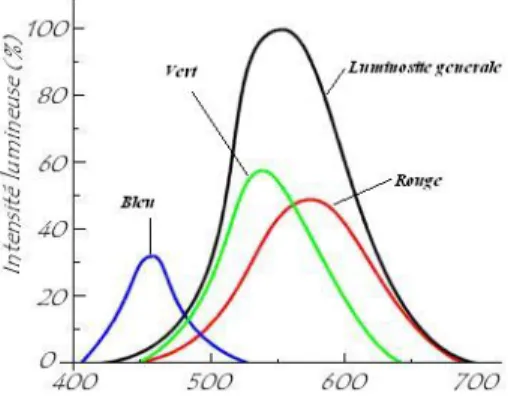
Les bâtonnets permettent de percevoir la luminosité et le mouvement, tandis que les cônes permettent de différencier les couleurs. Il existe en réalité trois sortes de cônes :
– Une sorte pour le rouge (580 nm) – Une sorte pour le vert (540 nm) – Une sorte pour le bleu (450nm)
Ainsi, lorsqu’un type de cône fait défaut, la perception des couleurs est imparfaite, on parle alors de daltonisme (ou dichromasie). On distingue généralement les personnes présentant cette anomalie selon le type de cône défectueux :
– Les protanopes sont insensibles au rouge – Les deutéranopes sont insensibles au vert – Les trinatopes sont insensibles au bleu
D’autre part il est à noter que la sensibilité de l’œil humain aux intensités lumineuses relatives aux trois couleurs primaire est inégale :
Fig. 1.3 – Représentation de la Sensibilité de l’œil humain aux trois couleurs primaire.
1.3.4
Synthèse additive et soustractive
Il existe deux types de synthèse de couleur :
La synthèse additive est le fruit de l’ajout de composantes de la lumière. Les compo-santes de la lumière sont directement ajoutées à l’émission, c’est le cas pour les moniteurs ou les télévisions en couleur [11]. Lorsque l’on ajoute les trois composantes Rouge, vert et bleu (RVB), on obtient du blanc. L’absence de ces trois composantes donne du noir. Les couleurs secondaires sont le cyan, le magenta et le jaune car :
– Le vert combiné au bleu donne du cyan – Le bleu combiné au rouge donne du magenta – Le vert combiné au rouge donne du jaune
Fig. 1.4 – Synthèse additive des couleurs.
La synthèse soustractive permet de restituer une couleur par soustraction, à partir d’une source de lumière blanche, avec des filtres correspondant aux couleurs complémen-taires : jaune, magenta et cyan. L’ajout de ces trois couleurs donne du noir et leur absence produit du blanc. Les composantes de la lumière sont ajoutées après réflexion sur un objet, ou plus exactement sont absorbées par la matière. Ce procédé est utilisé en photographie et pour l’impression des couleurs. Les couleurs secondaires sont le bleu, le rouge et le vert car [14] :
– Le magenta (couleur primaire) combiné avec le cyan (couleur primaire) donne du bleu,
– Le magenta (couleur primaire) combiné avec le jaune (couleur primaire) donne du rouge,
– Le cyan (couleur primaire) combiné avec le jaune (couleur primaire) donne du vert.
Fig. 1.5 – Synthèse soustractive des couleurs.
synthèse additive, ou du noir en synthèse soustractive.
1.4
Codage de la couleur
1.4.1
Les représentations de la couleur
Pour pouvoir manipuler correctement des couleurs et d’échanger des informations concernant celles-ci il est nécessaire de disposer de moyens permettant de les catégori-ser et de les choisir. Ainsi, il n’est pas rare d’avoir à choisir la couleur d’un produit avant même que celui-ci ne soit fabriqué. Dans ce cas, une palette de couleurs nous est présen-tée, dans laquelle nous choisissons la couleur convenant le mieux à notre envie ou notre besoin. La plupart du temps le produit (véhicule, bâtiment, ...) possède une couleur qui correspond à celle que l’on a choisie.
En informatique, de la même façon, il est essentiel de disposer d’un moyen de choisir une couleur parmi toutes celles utilisables. Or la gamme de couleur possible est très vaste et la chaîne de traitement de l’image passe par différents périphériques : par exemple un numériseur (scanner), puis un logiciel de retouche d’image et enfin une imprimante. Il est donc nécessaire de pouvoir représenter fiablement la couleur afin de s’assurer de la cohérence entre ces différents périphériques [18].
On appelle ainsi espace de couleurs la représentation mathématique d’un ensemble de couleurs. Il en existe plusieurs, parmi lesquels les plus connus sont :
– Le codage RGB (Rouge, Vert, Bleu, en anglais RGB, Red, Green, Blue),
– Le codage TSL (Teinte, Saturation, Luminance, en anglais HSL, Hue, Saturation, Luminance), – Le codage CMY, – Le codage CIE, – Le codage YUV, – Le codage YIQ.
1.4.2
Le codage RGB
Le codage RGB correspond à la façon dont les couleurs sont codées informatiquement, ou plus exactement à la manière dont les tubes cathodiques des écrans d’ordinateurs
représentent les couleurs. Il consiste à affecter une valeur à chaque composante de Rouge, de Vert et de Bleu.
Ainsi, le modèle RGB propose de coder sur un octet chaque composante de couleur, ce qui correspond à 256 intensités de rouge (28), 256 intensités de vert et 256 intensités de bleu, soient 16777216 possibilités théoriques de couleurs différentes, c’est-à-dire plus que ne peut en discerner l’œil humain (environ 2 millions). Toutefois, cette valeur n’est que théorique car elle dépend fortement du matériel d’affichage utilisé [18].
Etant donné que le codage RGB repose sur trois composantes proposant la même gamme de valeur, on le représente généralement graphiquement par un cube dont chacun des axes correspond à une couleur primaire :
Fig. 1.6 – Représentation graphique du codage RGB.
1.4.3
Le codage HSL
Le modèle HSL (Hue, Saturation, Luminance, ou en français TSL), s’appuyant sur les travaux du peintre Albert H.Munsell (qui créa l’Atlas de Munsell), est un modèle de représentation dit " naturel ", c’est-à-dire proche de la perception physiologique de la cou-leur par l’œil humain. En effet, le modèle RGB aussi adapté soit-il pour la représentation informatique de la couleur ou bien l’affichage sur les périphériques de sortie, ne permet pas de sélectionner facilement une couleur [80]. En effet, le réglage de la couleur en RGB dans les outils informatiques se fait généralement à l’aide de trois glisseurs ou bien de trois cases avec les valeurs relatives de chacune des composantes primaires, or l’éclaircis-sement d’une couleur demande d’augmenter proportionnellement les valeurs respectives de chacune des composantes. Ainsi le modèle HSL a-t-il été mis au point afin de pallier à cette lacune du modèle RGB [18].
Le modèle HSL consiste à décomposer la couleur selon des critères physiologiques : – La teinte (en anglais Hue), correspondant à la couleur de base (T-shirt mauve ou
orange),
– La saturation, décrivant la pureté de la couleur, c’est-à-dire son caractère vif ou terne (T-shirt neuf ou délavé),
– La luminance, indiquant la brillance de la couleur, c’est-à-dire son aspect clair ou sombre (T-shirt au soleil ou à l’ombre).
Voici une représentation graphique du modèle HSL, dans lequel la teinte est représentée par un cercle chromatique et la luminance et la saturation par deux axes :
Fig. 1.7 – Représentation graphique du codage HSL.
Le modèle HSL a été mis au point dans le but de permettre un choix interactif rapide d’une couleur, pour autant il n’est pas adapté à une description quantitative d’une couleur [80].
Il existe d’autres modèles naturels de représentation proches du modèle HSL : – HSB : Hue, Saturation, Brightness soit Teinte, Saturation, Brillance en français. – HSV : Hue, Saturation, Value soit Teinte, Saturation, Valeur en français.
– HSI : Hue, Saturation, Intensity soit Teinte, Saturation, Intensité en français.
1.4.4
Le codage CMY
Le codage CMY (Cyan, Magenta, Yellow, ou Cyan, Magenta, Jaune en français, soit CMJ) est à la synthèse additive, ce que le codage RGB est à la synthèse soustractive. Ce modèle consiste à décomposer une couleur en valeurs de Cyan, de Magenta et de Jaune.
1.4.5
Le codage CIE
Les couleurs peuvent être perçues différemment selon les individus et peuvent être affichées différemment selon les périphériques d’affichage. La Commission Internationale de l’Eclairage (CIE) a donc défini des standards permettant de définir une couleur indé-pendamment des périphériques utilisés. A cette fin, la CIE a défini des critères basés sur la perception de la couleur par l’œil humain, grâce à un triple stimulus [18].
En 1931 la CIE a élaboré le système colorimétrique xyY représentant les couleurs selon leur chromaticité (axes x et y) et leur luminance (axe Y). Le diagramme de chromaticité, issu d’une transformation mathématique représente sur la périphérie les couleurs pures, repérées par leur longueur d’onde. La ligne fermant le diagramme (donc le spectre visible) se nomme la droite des pourpres :
Fig. 1.8 – Système colorimétrique CIE.
Toutefois ce mode de représentation purement mathématique ne tient pas compte des facteurs physiologiques de perception de la couleur par l’œil humain, ce qui résulte en un diagramme de chromaticité laissant par exemple une place beaucoup trop large aux couleurs vertes [80].
En 1960 la CIE a mis au point le modèle Lu*v*.
Enfin en 1976, afin de pallier aux lacunes du modèle xyY, la CIE développe le modèle colorimétrique La*b* (aussi connu sous le nom de CIELab), dans lequel une couleur est repérée par trois valeurs :
– a et b deux gammes de couleur allant respectivement du vert au rouge et du bleu au jaune avec des valeurs allant de -120 à +120.
Le mode Lab couvre ainsi l’intégralité du spectre visible par l’œil humain et le re-présente de manière uniforme. Il permet donc de décrire l’ensemble des couleurs visibles indépendamment de toute technologie graphique. De cette façon il comprend la totalité des couleurs RGB et CMY, c’est la raison pour laquelle des logiciels tels que PhotoShop utilisent ce mode pour passer d’un modèle de représentation à un autre [80].
Il s’agit d’un mode très utilisé dans l’industrie, mais peu retenu dans la plupart des logiciels étant donné qu’il est difficile à manipuler.
Les modèles de la CIE ne sont pas intuitifs, toutefois le fait de les utiliser garantit qu’une couleur créée selon ces modèles sera vue de la même façon par tous ! [14].
1.4.6
Le codage YUV
Le modèle YUV (appelé aussi CCIR 601) est un modèle de représentation de la couleur dédié à la vidéo analogique. Il s’agit du format utilisé dans les standards PAL (Phase Alternation Line) et SECAM (Séquentiel Couleur avec Mémoire) [80]. Le paramètre Y représente la luminance (c’est-à-dire l’information en noir et blanc), tandis que U et V permettent de représenter la chrominance, c’est-à-dire l’information sur la couleur. Ce modèle a été mis au point afin de permettre de transmettre des informations colorées aux téléviseurs couleurs, tout en s’assurant que les téléviseurs noir et blanc existant continuent d’afficher une image en tons de gris [16].
Voici les relations liant Y à R,G et B, U à B et à la luminance, et enfin V à B et à la luminance :
– Y = 0.299R+0.587G+0.114B
– U = - 0.147R - 0.289G + 0.463B = 0.492(B - Y) – V = 0.615R - 0.515G - 0.100B = 0.877(B - Y)
1.4.7
Le codage YIQ
Le modèle YIQ est très proche du modèle YUV. Il est notamment utilisé dans le standard vidéo NTSC (utilisé entre autres aux États-Unis et au Japon).
Le paramètre Y représente la luminance. I et Q représentent respectivement l’Inter-polation et la Quadrature. Les relations entre ces paramètres et le modèle RGB sont les suivantes [79] :
– Y = 0.299R + 0.587G + 0.114B – I = 0.596R - 0.275G - 0.321B – Q = 0.212R - 0.523G + 0.311B
1.5
Image numérique, Informations et Médias
1.5.1
Les images numériques
Avant toute chose, mettons-nous d’accord sur le terme " image " ; en effet, le traitement d’images fait appel non pas à des images optiques classiques (telles que notre œil les perçoit), mais à des images numériques. Les logiciels de traitement d’images travaillent sur des données chiffrées contenues dans l’image, modifient ces données qui sont ensuite utilisées pour construire une seconde image " transformée " visualisable. La représentation numérique des images permet de combiner des images obtenues sous différents modes de macro ou de microscopie, de représenter une organisation spatiale (3D) à partir d’un ensemble de clichés successifs (2D), d’archiver les images et de les transférer par les réseaux informatiques [13].
Les calculs effectués sur ces données numériques, par un logiciel de traitement d’images ou par un logiciel d’analyse d’images, vont permettre de modifier l’aspect visuel de l’image et d’extraire des données quantifiées sur cette image [17].
Il existe 2 types d’images :
– les images vectorielles : utilisées principalement dans le monde du graphisme et de la conception assistée par ordinateur,
– les images bitmap ou matricielles : utilisées dans le domaine du traitement et de l’analyse d’images ; ce sont celles qui seront décrites dans ce support.
Définition de l’image numérique
L’image numérique correspond à une matrice (ensemble ordonné à deux ou trois di-mensions) de données numériques. Nous nous intéresserons uniquement aux images en