Implémenter le droit à l'oubli
Texte intégral
Figure
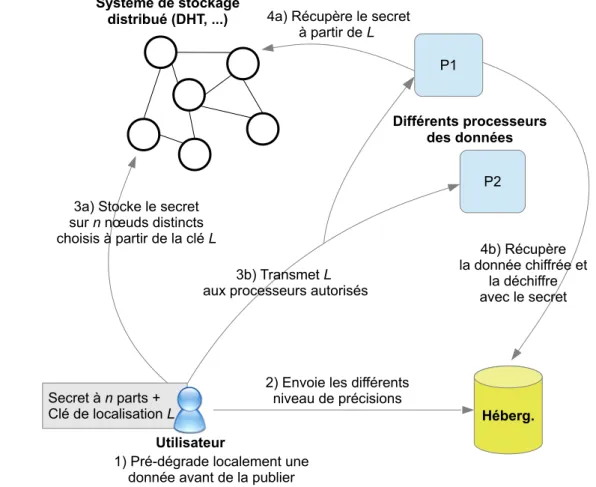
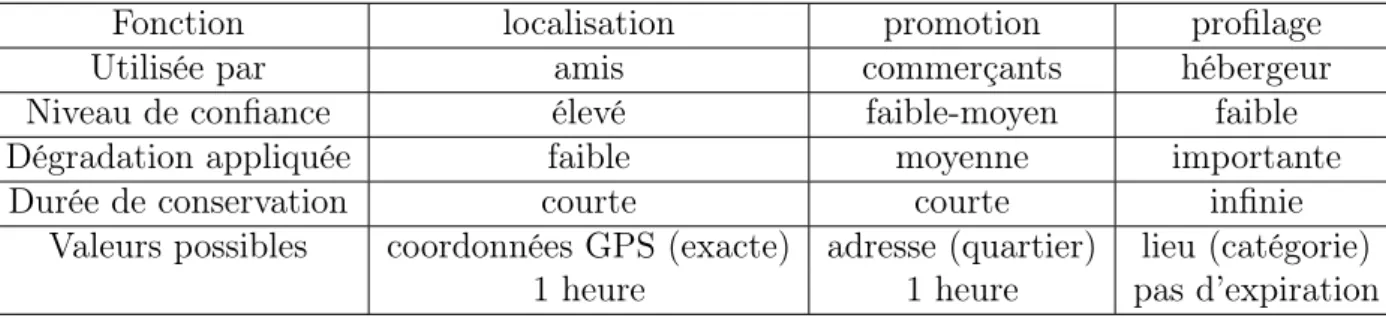
Outline
Documents relatifs
Utilisant le prisme du genre pour saisir la manière dont la production et la réception des textes et la conception de l’histoire littéraire (notamment l’institution de
Si cette avancée est notable pour la fréquentation de l’école maternelle, on remarque également une modification de la préscolarisation en milieu rural où il n’est plus rare
3 Indique le niveau de langage utilisé pour chaque phrase : familier, courant ou soutenu.?. LES NIVEAUX
3 Indique le niveau de langage utilisé pour chaque phrase : familier, courant ou soutenu!. Hâte-toi, nous allons
• Importance de la déduction logique et de la démonstration au sein d’un système.
Dans la lampe, les atomes du gaz reçoivent de l'énergie grâce à une décharge électrique et se trouvent alors dans un état excité d'énergie élevée. Ces différents états
Les ýravaux que nous avons exposé dans ceýýe ýhèse ainsi que les conclusions doný ils oný permis l'élaboraýion oný pour objeý l'éýude de l'efficaciýé du ýhéorème
transitions radiatives entre deux niveaux d’énergie peut donner lieu à des transitions à plusieurs quanta si, en plus, l’un au moins des deux niveaux
