LB
5". S
UL
1113
T<?33
FACULTE DES SCIENCES DE L'EDUCATION
THESE PRESENTEE
A L'ECOLE DES GRADUES DE L'UNIVERSITE LAVAL COMME EXIGENCE PARTIELLE
POUR L'OBTENTION
DU GRADE DE MAITRE EN SCIENCES DE L'EDUCATION (pédagogie)
PAR
CLAIRE TURCOTTE
ETUDE EXPLORATOIRE COMPARATIVE DE QUELQUES FAÇONS DE CALCULER ET D'ANALYSER LE COEFFICIENT DE FIABILITE
D'UN SYSTEME D'ANALYSE DU COMPORTEMENT VERBAL DES ENSEIGNANTS EN RELATION AVEC DEUX TYPES D'ENTRAINEMENT
A L'UTILISATION DE CE SYSTEME
1973 I
Table des matières iii
INTRODUCTION vi CHAPITRE I Opportunité de justesse de l'utilisation de cinq
coefficients de fiabilité d'un système d'analyse
de l'enseignement 1 1. Position du problème 1
2. Différentes façons de calculer des coefficients de fiabilité d'un système d'analyse de
l'ensei-gnement 4 3. Critique des différentes façons de calculer . . . 8
4. Conclusion 13 CHAPITRE II Méthodes d'entraînement et description des tests . . 15
1. Travaux préléminaires sur le système de Joyce . . 15
2. L'entraînement systématique 16 3. Tests de fiabilité: description et buts 20
4. Conclusion 22 CHAPITRE III Les résultats des tests et leur signification . . . . 24
1. 1er test 24 2. 2e test 25
a) Comparaison des coefficients pour l'ensemble
des juges 27 b) Conclusion 30 c) Comparaison des résultats entre les 2 équipes . 31
d) Conclusion 35
3. 3e test 35 a) Comparaison des coefficients pour l'ensemble
des juges 37 iii
b) Conclusion 40 c) Comparaison des résultats entre les deux équipes 40
d) Conclusion 46
4. 4e test 47 a) Conclusion 51
CONCLUSION GENERALE ET APPLICATIONS 51 a) Le transfert des habiletés 51
b) La comparaison des coefficients 52
Bibliographie 56 Annexe A: Ententes relatives à l'interprétation de l'unité
d'ana-lyse et des catégories du système de Joyce 57
LISTE DES TABLES
Table 1: Résultats obtenus par les huit codeurs pour 4
communica-tions 24 Table 2: Coefficients obtenus pour l'ensemble des juges, pour
chaque cinq minutes du test no 2 28 Table 3A: Coefficients obtenus, pour chaque cinq minutes du test
no 2, par les juges de l'équipe A (oral) 32 Table 3B: Coefficients obtenus, pour chaque cinq minutes du test
no 2, par les juges de l'équipe B (oral-écrit) . . . . 33 Table 4: Coefficients obtenus par l'ensemble de juges, groupés
par deux, pour chaque cinq minutes du test no 3 . . . . 38 Table 5A: Résultats de tous les coefficients pour chaque cinq
mi-nutes pour les juges de l'équipe A (oral) groupés par
deux 42 Table 5B: Résultats de tous les coefficients pour chaque cinq
mi-nutes, pour les juges de l'équipe B (oral-écrit) groupés
par deux 43 Table 6: Codage par 4 juges de 40 secondes d'enseignement et
pour-centages d'accord pour chacune des permutations des juges 48
LISTE DES FIGURES
Figure 1: Catégories et sous-catégories du système de Joyce . . . 3 Figure 2: Comparaison du Scott, du Rho_, du W et du r pour chaque
cinq minutes du test no 2. fCoefficients obtenus par
l'ensemble des juges) 29 Figure 3: Comparaison du W obtenu par chacune des équipes . . . . 34
Figure 4: Comparaison du coefficient de Scott obtenu par chacune
des équipes 34 Figure 5: Comparaison du r de Pearson obtenu par chacune des
équi-pes 34 Figure 6: Comparaison des pourcentages d'accord, du Scott, du W,
du r, pour l'ensemble des juges pour le test no 3 . . . 39 Figure 7: Comparaison du % d'accord obtenu par chaque équipe pour
la nature de l'unité ; 45 Figure 8: Comparaison du W obtenu par chacune des équipes . . . . 45
Figure 9: Comparaison du r obtenu par chacune des équipes . . . . 45 Figure 10: Comparaison entre: le pourcentage d'accord, le W de
Kendall, le r de Pearson, le coefficient de Scott pour
INTRODUCTION
Depuis quinze ans, une nouvelle orientation de la recherche sur l'enseignement s'est concentrée sur l'observation de ce ^ui se passe en classe. Cette nouvelle orientation est devenue nécessaire lorsqu'après plus de cinquante ans de recherche sur l'efficacité de l'enseignement, on se rendit compte du peu de découvertes qui avaient été faites. Bruce J. Biddle écrit en ce sens: "Nous ne savons pas comment définir, ni assurer, ni mesurer la compétence d'un enseignant. La masse des recherches sur l'efficacité de l'enseignement n'a produit jusqu'à présent que des résul-tats négligeables."
2 3 Déjà en 1925 avec Puckett , puis en 1934 avec Wrightstone , des
premières tentatives avaient été ébauchées pour décrire ce qui se passe en classe, mais ce n'est que vers les années soixante que le mouvement prend plus d'envergure. Apparaît alors une variété de systèmes qui veut décrire la réalité de l'enseignement, définir et analyser les interactions qui peuvent être observées dans une classe entre enseignant et enseignés.
La plupart de ces systèmes s'attachent exclusivement à la commu-nication verbale. Flanders explique ainsi son choix: "Dans une classe,
Bruce J. Biddle, "The Integration of Teacher Effectiveness Research." Bruce J. Biddle and William J. Ellena, editors, Contemporary Research on Teacher Effectiveness, New-York: Holt, Rinehart and Winston, 1964, p.3.
2
R.C. Puckett, "Making Supervision Objective", School Review, 36:209-12, 1928.
J.W. Wrightstone, "Measuring Teacher Conduct of Class Discussion", Elementary School Journal, 34:454-460, 1934.
dix pour-cent des chances que ce soit l'enseignant." Il postule par la suite que cette communication verbale est en haute corrélation avec le non verbal, c'est-à-dire que ce qui se dit reflète très souvent les attitudes, les gestes, et inversement, que ces attitudes et ces gestes correspondent aux paroles émises. Bellack choisit également le langage qu'il considère comme le principal instrument de communication dans l'enseignement.
Cette communication verbale est analysée sous différents aspects selon le centre d'intérêt du chercheur. Ainsi certains systèmes se préoccupent de l'aspect cognitif de l'enseignement, d'autres considèrent
l'aspect affectif ou encore la procédure de travail.
Ces systèmes comprennent généralement un nombre défini de caté-gories, correspondant aux préoccupations de leur auteur. "Les termes ou concepts qu'ils emploient reposent sur une série de faits (acts) qui arrivent pendant une certaine période de temps. Quand une série se re-produit souvent, elle devient familière à un observateur et il peut l'identifier."6
L'utilisation de ces systèmes pour la recherche ou pour la for-mation des enseignants est rendue possible par l'apprentissage des diverses
catégories du système. Cet apprentissage se fait par la compréhension
4 Ned A. Flanders, Teacher Influence, Pupil Attitudes and Achievement, Cooperative Research Monograph No. 12, OE-25040, Washington, D.C.: U.S.
Department of Health, Education and Welfare, 1965, p.l.
Arno A. Bellack; Herbert M. Kliebard; Ronald T. Hyman; Frank L. Smith, Jr., The Language of the Classroom, Teachers College, Columbia University, New-York, 1966, p.l.
Flanders, op, cit., p.6.
puis la mémorisation des diverses catégories du système; cette étape franchie, ceux qui s'entraînent au système se servent d'enregistrements de cours pour s'habituer à coder. Leur période d'entraînement terminée, les codeurs doivent vérifier s'ils appliquent bien aux mêmes réalités les catégories du système qu'ils ont appris.
C'est à ce niveau que se situe notre problême qui est particu-lièrement important pour la recherche sur l'enseignement. Quel est le niveau d'entente entre les codeurs? Lorsque deux ou plusieurs codeurs classifient une même communication, recourent-ils à la même catégorie? De par sa nature même un indice ou coefficient de fiabilité dé-bouche sur un estimé susceptible de fournir une réponse valable à la ques-tion qui nous intéresse. Le problème n'est pas pour autant résolu si on considère la variété des procédures proposées pour évaluer ce coefficient et les diverses contraintes à respecter au niveau de leur application respective.
Au problème du choix, de la pertinence et de l'estimation des différents indices de fiabilité nous ajoutons une dernière dimension à savoir la comparaison de deux méthodes différentes de s'entraîner:
- entraînement à un codage oral: les codeurs inscrivent directe-ment leurs catégories sur une feuille blanche, soit à partir des bandes sonores des cours, soit en classe au fur et à mesure que le cours se dé-roule ;
- entraînement à un codage oral-écrit: les codeurs inscrivent leurs catégories sur des protocoles (transcriptions dactylographiées des cours enregistrés) et utilisent également la bande sonore des cours. En effet, ces deux différentes manières de s'entraîner sont employées
couramment dans l'apprentissage de l'utilisation des catégories d'un système,
des habiletés acquises à la suite de ces deux types d'entraînement. Plan général du présent travail:
Nous verrons dans le premier chapitre quelle est exactement la nature de notre problème. Suivra une description de 9 coefficients et une critique de chacun d'eux. Le chapitre deux décrit tout d'abord de quelle manière s'est fait l'entraînement des codeurs puis donne une des-cription des tests auxquels ils sont soumis. Le chapitre trois donne les résultats obtenus aux quatre tests; suivra une discussion de ces ré-sultats qui permettent de comparer à la fois les coefficients de fiabi-lité et la possibifiabi-lité de transfert des habiletés acquises à la suite de deux types d'entraînement différents. Nous terminerons par une conclusion générale sur l'ensemble de la présente étude.
CHAPITRE UN
OPPORTUNITE ET JUSTESSE DE L'UTILISATION DE CINQ COEFFICIENTS DE FIABILITE D'UN SYSTEME D'ANALYSE DE L'ENSEIGNEMENT
SOMMAIRE. Dans ce chapitre nous expliquons tout d'abord les difficultés que nous avons à trouver un coefficient de fiabilité parfai-tement adapté à deux manières différentes de coder les communications verbales des enseignants au moyen d'un système d'analyse. Nous exposons ensuite la formule propre au calcul de six différents coefficients de fiabilité choisis pour cette étude. Une critique de chacun des coeffi-cients termine cette première partie.
Comme nous l'avons vu dans l'introduction, il existe différents systèmes d'analyse des communications orales des enseignants qui suppo-sent une observation systématique. La qualité de ces systèmes doit être évaluée au niveau de la validité qui demande entre autres choses que toutes les communications verbales des enseignants soient intégrées dans les
catégories du système, et au niveau de la fiabilité, sujet dont traitera le présent travail.
Position du problème:
L'emploi d'un coefficient de fiabilité adéquat est indispensable dans une recherche scientifique sur l'analyse du comportement verbal des enseignants. Un tel coefficient devrait donner la possibilité de connaître le niveau d'entente entre les codeurs par la vérification une à une de chacune des unités codées par deux ou plus de deux codeurs. Le calcul d'un coefficient qui permet de voir une à une les unités codées afin de vérifier la similitude des réponses données par les codeurs se résoud assez bien avec l'utilisation des protocoles (transcriptions dactylographiées des cours enregistrés), mais devient plus difficile si on utilise unique-ment le ruban sonore. En effet, cette manière de coder, orale, où les
suppose que nous ne pouvons pas suivre la démarche exacte des codeurs. L'étude du quatrième test présentée au chapitre deux tentera d'apporter une solution à ce problème.
En effet, un coefficient de fiabilité qui se calcule à partir de l'ensemble des unités codées dans chaque catégorie donne un portrait global de ce qui a été codé, alors qu'une méthode qui utilise le pourcen-tage d'accords et qui tient compte des unités codées une à une donne un portrait détaillé du codage. La comparaison de différentes manières de calculer le coefficient de fiabilité pourra nous dire s'il y a différence entre les coefficients obtenus et quelle en est l'importance.
Une étude comparative des coefficients de fiabilité nous permettra également de connaître quelle est la possibilité de transfert des habiletés acquises dans l'une et l'autre manière de s'entraîner au système. A cet effet, une équipe s'est entraînée en utilisant uniquement le magnétophone
(oral) tandis que l'autre équipe utilisait le magnétophone et les protoco-les (oral-écrit). Les tests utilisés pour calculer le coefficient de fia-bilité tiennent compte de cet élément; ainsi dans le deuxième test, les deux équipes de juges codent à la manière de l'équipe qui s'est entraînée à l'oral et l'étape trois est inversement codée par les deux équipes à la manière de l'équipe qui s'est entraînée à 1'oral-écrit.
C'est le système d'analyse du comportement verbal des enseignants de Bruce R. Joyce qui sera utilisé pour cette étude de quelques façons de calculer et d'analyser le coefficient de fiabilité. Ce système d'analyse n'utilise que les communications verbales des enseignants.
Bruce R. Joyce; Berj Harootunian, The Structure of Teaching, Science Research Associates, Inc., Chicago, 1967, pp.228-253.
Le système se divise en quatre grandes catégories, lesquelles se subdivisent en souscatégories pour former un total de dixsept sous catégories .
L'unité de communication employée pour le codage se définit comme étant une communication orale faite par un enseignant sur un sujet, à un auditoire, pour une période de temps ne dépassant pas quinze secondes
(elle peut être beaucoup plus courte). Pour les communications plus lon gues, une unité doit être enregistrée toutes les quinze secondes.
SANCTION INFORMATION PROCEDURE MAINTIEN
0 o 0 i u 0 T J « x> O .c 0 3* •- G C o 9* 3* 0 T J 3 3 0 0 3 0 r H 0 u o r H 0 h r i 0 G u *4 a - » r H u 0
2
0 0 u 0 0 <* • H 4J 0 0 C2
C O. 3 B a t » VU c M as G •B CU •0 U 0 0 . O (U \ 0 • H O C 0 •B 0 \ 0 0 r H * J •a o s G U 0 "J 0 i-l r H 0 «w r H G 0 \ 0 O r i 0 0 0 0 Vi 0 0 o « O H Û0 \ 0 0 W v H 0 4J > r i 0 C B G C * .c P . 4-1 CJ G MU Q) VU P. p . G « o 0 V U / 0 4-1 4-1 £\a> d O • 0 O T J O u •H 4J W r i G C 0 r i 0 • H C 0 0 0 0 u 4J ■H • H 0 S 0 O • H p . ■H co /0 0 / 0 r i G •a r i o 0 0 O Xe
i H •a 4-1 3 0 6 3 3 G 0 9* r H m 0 3 0 O 0 3 co 0 r H 0 6 W T 3 T J 0 P.e
0 3 P . 0 0 0 4 J 0 4-i <ua
O 4J O 4-1 VU 3 u • H o H vu 0 0 C 0 vu coa
C C"4H C 0 O 0 4J 0 u r i O «J u 0 U C 0 O 0 U 0 O u • H 0 0 O 0 3 i H P . 0 O MH O • H 0 • H r i C c 0 0 G 0 0 0 0 O •o X 0 P . C • 0 O . *o p. 0 0 C O •H I - l i H r H r H CO O 3 0 r H \ 0 • H CO 3 3 r H 4 J 0 X. 4J C c * J M » 0 4-> 0 4-1 a) P. 0 r i 0 3 0 0 0 0 O 0 \ 0 r H 0 r H • 0 V U T 3 vu c 4J O G C a G-H 0 G 0 3 G Ci 0 U G G c C * J G 0 Q) 4-1 C 0 0 0 0 * T J 0 3 3 0 •o o o o O U 3 0 0 G O T 3 • O 4J 0 r i 0 3 G 0 ■H ■ri ■ H • H 3 r H ■H 0 • H G r H 0 r H O 0 0 3 0 4J 4 J * J u •U h 0 r i - H 4 J J-l 0 0 •o co 0 4-1 3 a O u O 4J U 0 o*o 0 i H G 10 0 C 0 G O O 4J ■H O G C G C 0 M-i T J > 3 0 G G vu T 3 0 ' a coI-
§* • H 0 0 0 0 0 0 C «W3
0 4 - 1 3 0 O r i • H 4-1 ■ H r HI-
§* 0 r i • H CO CO CO C O - H O3
P n \ 0 C T 4 J O (X. < 0 < 0 . M M (>4 H P S - l S-2 S-3 S-4 S-5 î - i 1-2 1^31 1-4 1-5 P - l P-2 P-3 P-4 M - l M-2 M-3 FIGURE 1d'analyse de l'enseignement:
La fiabilité de l'utilisation d'un système du comportement verbal des enseignants peut être calculée et exprimée de diverses façons, qui ont chacune leurs avantages et leurs limites. C'est ainsi que nous pou vons avoir:
1) Une comparaison entre les pourcentages d'unités codées dans chaque catégorie. C'est le coefficient X d e Scott qui se calcule selon les deux formules suivantes :
1ère formule: *n = Po Pe ou
1 Pe
Po =■ le pourcentage d'accord, 100 % total de désaccords, Pe = le pourcentage d'accord attendu par le hasard. On
le calcule en utilisant la 2ième formule.
K 2
2ième formule: Pe = S Pi où
i=l
Pi = proportion d'unités tombant dans chaque catégorie. K = nombre de catégories.
g i ■■ chacune des catégories.
2a) Le calcul de l'accord des codeurs unité par unité selon la formule utilisée par Bellack:
Accords X 100 = pourcentage d'accord
Accords + désaccords çj
2b) Variation (plus complexe mais fondamentalement identique) de la formule
g
Flanders, op. cit., pp.25 à 27. 9
précédente, proposée par Smith:
Pa = A où Tp
Pa = pourcentage d'accord. A = nombre d'accords.
Tp = total possible de codages et correspond à Tp = A + (Oi + Si) + (Oli + Sii), où
01 = total d'omissions par l'équipe 1.
Si = les cas de substitution par l'équipe 2. Oli — total d'omissions par l'équipe 2.
Sii = les cas de subtitution par l'équipe 1. 10
3a) Une corrélation de rangs ou rho, où tous les résultats sont traduits en termes de rangs, la catégorie utilisée la plus souvent occupant le dernier rang et celle utilisée le moins souvent le premier, et qui se calcule selon la formule:
< - 1 -/ô D
2V
N(N2 - 1)11
3b) Un rho, qui n'est pas un coefficient autonome, mais que l'on peut déduire à partir du W de Kendall:
*< - KW - 1 où K - 1
Tel que rapporté par: Karl V. Openshaw et R. Frederick Cyphert, "The Development of a Taxonomy for the Teacher Classroom Behavior",
Ohio State University, 1966, pp.105-106.
Lawrence T. Dayhaw, Manuel de Statistique, Ottawa: Editions de l'Univ. d'Ottawa, 1958, pp.217-218.
W = est calculé à partir de la formule no 4. 12
4) Le W de Kendall, calculé au moyen des rangs avec la formule: W = s
ou
\2 K2 (N3 - N)
la somme des carrés des déviations observées du Rj:
* ( " " * $
s =
ou
Rf — total des rangs dans une même catégorie, pour tous les juges.
K = nombre de juges.
N = nombre de catégories utilisées. 1 2 3
Y„ K (N - N) = la somme des s qui devrait se produire avec une parfaite entente à travers K juges.
13 5a) Un chi carré calculé soit avec la formule:
(i ±
2
-
*
2
V
\^ n N
7AIX
2= / V - B
2V
le nombre d'unités codées dans une catégorie pour
un juge b.
nombre total des unités pour une catégorie pour
12
S. Siegel, Nonparametric Statistics for the Behavior Sciences, Toronto, Me Graw Hill, Co., 1956, p.231.
tous les juges.
B = le nombre total des unités codées dans toutes les catégories du juge b.
N = le nombre total des unités codées dans toutco les catégories par tous les juges.
A =* nombre total des unités codées par l'autre juge pour l'ensemble des catégories.
14
5b) Un chi carré calculé à partir du W de Kendall et servant à l'inter-préter:
X2 - K(N - 1)W où
K — nombre des juges. N = nombre de catégories.
W = calculé avec la formule no 4.
15
6) Une corrélation de Pearson, au moyen des scores bruts, où le coefficient est calculé directement avec la formule:
rxy - N*XY - £X*Y
NN£X2 - (£X)2 M N2Y2 - (2Y)2 16
14
Dayhaw, op. cit., p.387. Siegel, op. cit., p.236. 16
Critique des différentes façons de calculer:
Nous reprenons maintenant les formules présentées ci-dessus pour discuter brièvement de l'opportunité et de la justesse de leur applica-tion au calcul du coefficient de fiabilité d'un système d'analyse de 1'enseignement.
1) Coefficient de Scott:
De son coefficient, Scott nous dit: "It can be roughly inter-preted as the extent to which the coding reliability exceeds chances."
Mitchell, critiquant l'utilisation du coefficient de Scott faite par Flanders, signale les inconvénients de ce coefficient, plus particu-lièrement son incapacité d'établir l'accord sur les mêmes événements pris un à un:
"The reliability coefficients that are provided are based on cumulative errors and not absolute errors, i.e. they represent percentage comparisons of the same categories for différents raters, but not the degree of0agreement between two raters on exactly the same observed
IIJLO
events.
De plus, un petit nombre de catégories utilisées par les codeurs ou encore peu d'événements classés dans une même catégorie sont deux fac-teurs susceptibles d'influencer le Ifou coefficient de Scott.
Les restrictions apportées sur l'emploi du coefficient de Scott nous font grandement douter de la justesse de son application. Toutefois
ce coefficient possède un intérêt historique puisque Flanders, l'un des pionniers des systèmes d'analyse des communications verbales des ensei-gnants, a jugé bon de l'utiliser. Il devient donc intéressant de comparer
William A. Scott, "Reliability of Content Analysis: The Case of Nominal Scale Coding", Public Opinion Quaterly, Fall 1955, p.323.
18
James V. Mitchell, Jr., "Education's Challenge to Psychology: The Prediction of Behavior from Person-Environment Interactions", Review of Education Research. Vol. 39, No 5, December 1969, pp.695-721.
sa valeur, jugée douteuse, avec celle d'autres coefficients. 2a) Méthode de Bellack ou pourcentage d'accord:
Cette méthode permet de trouver un coefficient basé sur la compa-raison uaité par unité, puisqu'elle suit la démarche de chaque codeur, et permet de comparer les unités codées une à une, sans en négliger au-cune.
Cette manière de calculer force cependant à utiliser un protocole écrit (transcription dactylographiée d'un enregistrement sonore). De plus le seuil en deçà duquel le pourcentage d'accord n'est pas acceptable est arbitrairement fixé à quatre-vingt pourcent, la statistique ne nous don-nant pas de façons de calculer la signification de ce pourcentage.
Malgré ces deux inconvénients, la méthode de Bellack, parce qu'elle nous permet de vérifier une à une les unités codées, nous semble être le plus sûr moyen de calculer le coefficient de fiabilité des codeurs. 2b) Méthode de Smith:
Nous avons ici une autre méthode qui suit exactement la démarche de chaque codeur et qui permet de découvrir les divergences entre les codeurs au fur et à mesure qu'elles se produisent. On y retrouve par con-tre les mêmes inconvénients que dans la méthode de Bellack. Le calcul du coefficient de Smith s'avère cependant plus long et plus compliqué que celui du coefficient de Bellack puisqu'il tient compte des omissions et des substitutions. Par contre, les résultats qu'il produit sont substan-tiellement semblables à ceux que fournit le calcul du coefficient de Bellack.
A cause de sa grande similitude avec la méthode de Bellack, nous n'avons pas cru bon l'utiliser.
Approximation commode du r de Pearson lorsqu'il y a moins de trente observations pairées, le rho sert surtout à découvrir s'il y a ou non liaison entre les traits considérés. Cette formule permet de "ne pas tenir compte de la continuité et de l'égalité des intervalles de
me-19
sure." Or il est plausible de soutenir que les catégories d'un système ne sont ni continues ni égales entre elles, (ex. une sanction négative n'offre ni continuité ni égalité avec une procédure de type non directif).
L'inconvénient du rho est que deux distributions de fréquences fort différentes quant à la somme des fréquences peuvent être statistique-ment fort semblables; par exemple, cinquante unités observées par un co-deur et cinq cents par un autre, lors de l'observation d'une même réalité, pourraient à la limite être en très forte corrélation de rangs.
3b) Le rho calculé à partir du W de Kendall:
Cette formule présente les mêmes avantages et inconvénients que la corrélation de rangs (rho) présentée en 3a.
Ce rho"n'est pas une formule autonome puisqu'il est directement déduit du W. Il est plutôt un avantage du W de Kendall et offre la possi-bilité d'être calculé pour plusieurs juges simultanément alors que la for-mule précédente ne s'utilise que pour deux juges à la fois.
Pour l'un et l'autre rho, nous pouvons nous référer à la Table de 20
Thornton pour savoir si la corrélation trouvée s'écarte de façon signi-ficative de la corrélation nulle.
L'usage du rho et du r de Pearson (cf. formule 6) pour le calcul
1 Q
Fred N. Kerlinger, Foundations of Behavioral Research, New York: Holt Rinehart and Winston, Inc., 1966, pp.90-91.
20
11 du coefficient de fiabilité nous a été suggéré par un indice fourni par
T 21
Joyce.
4) Le W de Kendall:
Ce coefficient exprime le degré d'association entre deux ou plu-sieurs juges. Il permet également de découvrir le degré réel de concor-dance dans les données à partir du nombre maximum possible d'accords. Un W élevé signifie que les observateurs ou les juges appliquent les mêmes normes pour classer les mêmes événements dans les mêmes catégories.
Bien qu'utilisant les rangs avec les inconvénients que nous avons relevés plus haut, cette formule a été construite plus particulièrement pour des études de coefficient d'accord entre des juges utilisant des ca-tégories nominales. Elle semble donc respecter les conditions nécessaires pour découvrir le degré d'association entre des variables qui ne peuvent être catégorisées selon un ordre ordinal.
Il devient donc très intéressant de comparer les résultats obtenus par le W de Kerfdall aux résultats fournis par les autres formules, parti-culièrement celle de Bellack qui semble être la plus adéquate.
5a) Le chi carré:
"Technique plus particulièrement utile... quand les variables ne se prêtent pas à des mesures proprement dites, mais seulement à des
caté-22
gories mutuellement exclusives" le chi carré semble adapté à la nature des systèmes dont nous voulons calculer la fiabilité de l'emploi, puisque
21
"Reliability is established by correlations of frequency distributions within categories between two observers. The range of reliability reported is .85 to .95". (Anita Simon et E. Gil Boyer.
"Mirrors for Behavior: An Anthology of Classroom Observation Instruments", Classroom Interaction Newsletter, Vol. 3, No 2, janvier 1968, section 11, Joyce, p.3).
ces systèmes sont des ensembles de catégories.
Une des principales difficultés qui pourrait se rencontrer dans 2
la technique du X réside dans la détermination des fréquences théoriques. Cette difficulté est contournée par la formule qui permet de calculer le
2 „
X a partir de deux distributions réelles de fréquences, sans passer par les fréquences théoriques.
2
Lorsque le X n'est pas significatif, nous savons que les juge-2
ments des codeurs ne diffèrent pas significativement. Ce X ne nous dit pas, cependant, si les juges s'entendent bien sur une même réalité. 5b) Le chi deux calculé à partir du W de Kendall:
Pour utiliser cette formule, le nombre de catégories (N) doit 2
être supérieur à sept. Contrairement à l'hypothèse du X formulée en 5a,
^ 2
l'hypothèse du X calculé à partir du W de Kendall se vérifie si, dans la table qui lui est propre, le résultat est significatif. Ce niveau de signification nous permet de dire s'il y a entente entre deux ou plusieurs juges pour N catégories lorsque le W a été calculé.
6) La corrélation du moment des produits ou r de Pearson:
L'emploi d'une formule modifiée, en l'occurrence celle de la cor-rélation au moyen des scores bruts, simplifie les calculs puisqu'elle élimine l'emploi des écarts.
Cette corrélation repose cependant sur deux postulats: la recti-23
linéarité et l'homoscédasclté. Or, il semble difficile de supposer que les données, fournies par la catégorisation du langage des enseignants au moyen d'un système d'analyse, respectent ces deux postulats. Il est donc plausible de douter du r de Pearson comme coefficient de fiabilité dans
23
13 9 / le cas qui nous intéresse quoiqu'il ait déjà été utilisé à cette fin.
Nous avons donc présenté neuf méthodes différentes de calculer un coefficient de fiabilité des systèmes d'analyse de l'enseignement. La deuxième et la troisième méthode (2a et 2b) supposent que le codage se fasse à partir des protocoles; elles sont les seules méthodes qui permet-tent la comparaison des unités codées une à une. La première et les six dernières ne requièrent pas l'usage des protocoles; elles ne nécessitent que le codage des données orales, pendant un cours, ou en laboratoire si l'enseignement a été enregistré sur bandes sonores ou magnétoscopiques. Par contre, elles ne permettent qu'une comparaison globale du codage puis-qu'elles ne tiennent compte que de l'ensemble des données inscrites dans chaque catégorie.
Conclusion:
Voulant trouver un coefficient de fiabilité des systèmes d'analyse de l'enseignement qui nous donne la possibilité de connaître le niveau réel d'entente entre les codeurs, nous sommes forcés de reconnaître que chacun de ces coefficients possède à la fois des avantages et des incon-vénients. C'est ce que nous avons essayé de démontrer dans la critique des divers coefficients.
Cependant, il semble que la méthode de Bellack correspond à ce que nous recherchons d'un coefficient de fiabilité à savoir, la possibilité de vérifier les unités codées une à une. Parfaitement adapté à un codage qui utilise des protocoles, le calcul du pourcentage d'accord se complique lorsque nous voulons l'utiliser avec un codage fait uniquement à partir d'une bande sonore.
C'est pourquoi nous essayons de voir si d'autres méthodes de
cul d'un coefficient de fiabilité n'apporteraient pas une réponse qui pourrait être adéquate. Et, c'est ce que nous permettra une comparaison des résultats obtenus par le calcul de différents coefficients de fia-bilité.
RESUME. Dans ce chapitre, nous avons décrit et critiqué diverses formules qui permettent de calculer un coefficient de fiabilité applicable à un système d'analyse des communications verbales des enseignants, celui de Bruce R. Joyce. Chaque formule a des avantages et des inconvénients que nous avons essayé de démontrer.
Le chapitre deux décrira les procédures de l'entraînement au système de Joyce et les différents tests qui ont suivi l'entraînement, tests qui permettront à la fois de calculer les différents coefficients de fiabilité et de vérifier comment se fait le transfert des habiletés acquises à la suite de deux types d'entraînement différents.
CHAPITRE DEUX
METHODES D'ENTRAINEMENT ET DESCRIPTION DES TESTS
SOMMAIRE. Comme le titre l'indique, nous débuterons ce chapitre en décrivant de quelle manière s'est fait l'entraînement au système de Joyce. Nous verrons que le groupe qui s'entraînait était divisé en deux équipes, l'une utilisant les protocoles et le magnétophone (oral-écrit), l'autre utilisant uniquement le magnétophone (oral). Suivra la descrip-tion des tests qui viendront vérifier les résultats de l'entraînement et permettront l'exploration des coefficients de fiabilité.
Travaux préliminaires sur le système de Joyce:
Pour utiliser un système d'analyse des communications verbales des enseignants, des codeurs doivent s'y entraîner. Mais avant de passer à ce stade, il importe de savoir si le système est valide et fiable dans le milieu qui sera observé.
En effet, le système de Joyce, conçu aux Etats-Unis, en milieu
anglophone sera maintenant appliqué en milieu francophone. Un groupe de
neuf personnes composé de six professeurs et de trois étudiants gradués
des Sciences de l'Education étudient, dans un premier temps, le système
lui-même. Cette étude du système débute au trimestre d'automne 1970 par
la compréhension puis la mémorisation des 17 sous-catégories qui le
com-posent. Par la suite, le groupe tente d'appliquer les diverses catégories
à des situations d'abord factices, puis ensuite à deux situations réelles
de cours d'éducation physique. Le choix de cette matière est déterminé
par un membre du groupe qui veut savoir s'il est possible d'utiliser ce
système dans la formation des étudiants stagiaires du département
d'éduca-tion physique.
C'est au cours de ce premier stade de l'étude du système de Joyce que l'on s'entend pour classer dans l'une ou l'autre catégorie les
commu-nications verbales écoutées et que l'on commence à formuler certaines adaptations et indications supplémentaires (cf. annexe A) sur des points qui pourraient prêter à confusion. Ainsi, par exemple, une demande ex-presse qui amène une seule réponse précise sera codée 1-3; établir un barème de correction sera codé M-3. Ces ententes ne sont pas définitives et il demeure possible de les transformer ou de les éliminer au fur et à mesure que l'on avancera dans la compréhension du système.
A ce même stade, quelques membres du groupe font une traduction 25
du "Manual for Analyzing The Oral Communications of Teachers." Parce qu'il a été possible de catégoriser les communications des enseignants en éducation physique dans le système de Joyce, nous présumons qu'il est possible de l'utiliser en milieu francophone et nous passons à un entraî-nement systématique.
L'entraînement systématique:
Au semestre de l'hiver 1971, huit membres du groupe décident de passer à un entraînement systématique sur lequel est greffé la présente recherche. L'on détermina que quatre personnes s'entraîneraient unique-ment avec les bandes sonores des cours, les quatre autres utilisant les bandes sonores et les protocoles correspondants. Comme nous voulions vé-rifier divers coefficients de fiabilité et comparer les résultats des deux différentes manières de s'entraîner, il devenait très important de déter-miner une formule de travail qui soit identique pour les deux équipes.
La formule de travail adoptée pour les deux équipes fut la sui-vante:
- Les heures d'entraînement ne peuvent varier beaucoup d'une équipe à
25
17 1'autre.
- Les difficultés de codage sont transmises d'une équipe à l'autre au fur et à mesure qu'elles surviennent.
- Une période conjointe sera programmée si nécessaire pour discuter de ces difficultés.
- La matière et les cours employés pour l'entraînement seront les mêmes pour tous; Ils seront choisis au secondaire dans des cours de géogra-phie.
Ces premières directives concernaient l'ensemble du groupe. Nous verrons maintenant comment chaque équipe s'y est adaptée.
Pour l'équipe A qui utilise uniquement la bande sonore des cours de géographie, l'entraînement se déroule ainsi:
1. Deux rencontres d'une heure trente par semaine pour un total d'environ quarante heures, réparties de février à mai 1971.
2. Une première phase dans l'entraînement où les quatre membres codent individuellement les mêmes communications, arrêtent le magnétophone dès qu'ils ont inscrit quelques catégories, comparent et discutent leurs choix.
3. Une seconde phase, où les quatre membres de l'équipe codent toujours individuellement mais en arrêtant le magnétophone uniquement aux soixante secondes. Durant cette phase, ils utilisent un chronomètre pour tenir compte des unités de quinze secondes et de la période totale de soixante secondes.
4. Dans une troisième phase, les codeurs suivent toujours la démarche dé-crite en 3.; il n'y a que la durée de codage qui change, c'est-à-dire que de soixante secondes sans interruption du magnétophone, l'équipe passe graduellement à cinq minutes et plus. Chaque codeur a son
chrono-mètre pour minuter les communications de plus de quinze secondes et 26
les interruptions de plus de quatre à cinq secondes qui surviennent pendant les cours.
5. Pendant les phases deux et trois, la vérification des réponses de cha-cun se fait, au début en comparant l'une après l'autre les catégories inscrites et, à la fin, lorsque la période de codage devient plus lon-gue, les membres de l'équipe comparent le nombre total des catégories et le nombre d'unités dans chaque catégorie. S'il y a trop de diver-gences, l'équipe reprend la partie codée et essaie de déterminer les causes des mésententes.
L'entraînement de l'équipe B, se fait avec les bandes sonores des mêmes cours de géographie qu'emploie l'équipe A mais s'y ajoute
l'utilisa-tion des protocoles sur lesquels les codeurs inscrivent les catégories. 1. Cette équipe s'entraîne à raison d'une rencontre de trois heures par
semaine pour un total d'environ quarante heures.
2. Dans un premier temps, les membres s'entraînent à identifier les commu-nications et à rallier les points de vue sur les éléments de division. C'est également une période de sensibilisation au rythme des unités de communication de quinze secondes; un chronomètre permet l'adaptation au rythme des unités.
3. Dans un deuxième temps, l'entraînement se fait non plus à quatre mais à deux; chacun codant et comparant ses réponses avec un partenaire. Ce partenaire, le même au début, change par la suite après chaque séance. Le codage des deux sous-groupes est ensuite comparé et les divergences sont discutées.
26
Pour plus d'explications sur le quatre à cinq secondes, cf. annexe A.
19
4. Dans un troisième temps, chaque membre de l'équipe devient tour à tour codeur ou reviseur selon un horaire préalablement établi. Deux équipes codeur-réviseur sont fournies chaque fois. Le codage se fait isolé-ment, la revision également; suit une rencontre codeur-réviseur. La mise en parallèle des éléments du même protocole codé par les deux sous-groupes donne lieu au comptage des accords et des désaccords entre les deux groupes de codeurs et au calcul de leur pourcentage d'accord.
Selon ce qui avait été convenu dans la formule de travail pour les deux équipes, il y eut trois rencontres conjointes pour discuter des dif-ficultés de codage rencontrées au cours de l'entraînement. Une première rencontre fut demandée dès la deuxième semaine d'entraînement, une autre la sixième semaine. La dernière rencontre se fit vers la fin du semestre pour mettre une note plus définitive à toutes les ententes prises aupara-vant. Ce sont ces ententes finales que nous retrouvons dans l'annexe A
du présent travail.
Les autres conditions que les équipes s'étaient données furent également bien respectées si l'on regarde le nombre total d'heures d'en-traînement, environ quarante heures pour chacune, et le nombre d'heures par semaine qui était fixé à trois. Les équipes s'entraînèrent également
sur les mêmes enregistrements de cours, préparés pour elles à l'avance. Pendant l'entraînement systématique, on remarque une difficulté qui se pose pour l'équipe A qui n'utilise que les bandes sonores. Il est très difficile pour ses membres de vérifier une à une les unités codées et de les comparer. Pour connaître son niveau d'entente pendant l'entraî-nement, l'équipe se base sur les résultats du r de Pearson, qui sont très élevés. L'équipe B, utilisant alors la formule de Bellack ou pourcentage*. d'accord, a, comparativement au r de Pearson, des résultats inférieure, /\WHIm
ET ES MUES
mais beaucoup moins de difficulté à comparer les unités.
Après quarante heures d'entraînement, le groupe passa aux divers tests tel qu'il avait été prévu. La fin de ce chapitre comprend la des-cription des tests et ce que chacun d'eux nous permet d'observer.
Tests de fiabilité: description et buts:
Nous avons jugé que quatre tests étalent nécessaires pour recueil-lir nos données. Le premier test vise uniquement à identifier le niveau d'accord inter-équipes (A et B) avant la cueillette des données devant servir à l'étude des coefficients de fiabilité et du transfert des habi-r letés. Les trois autres tests permettront d'explorer les coefficients et de vérifier le transfert des habiletés.
1er test :
Ce test permet de voir si les codeurs s'entendent sur l'identifi-cation des communil'identifi-cations. Chaque codeur reçoit les mêmes protocoles avec 80 communications préalablement soulignées par un membre du groupe. Les communications "sont codées par chacun des huit membres selon le système de Joyce et les ententes qui ont été prises au cours de l'entraînement. Analyse : les données fournies par chaque codeur sont comparées et calculées en terme de pourcentage d'accord. Le niveau d'entente atteint par les huit juges nous renseignera sur la similitude de leurs habiletés.
2e test :
Le test: trente minutes d'enregistrement présentées aux codeurs par tranches de cinq minutes.
A code selon A 3 code selon A
Cette manière exigera:
27
- de l'équipe A: qu'elle recoure au codage oral ' auquel elle a été
21
entraînée;
- de l'équipe B: qu'elle recoure au codage oral auquel elle n'a pas été entraînée.
Deux comparaisons seront faites ici:
1) Une comparaison, lorsque A code selon A, entre les coefficients de Scott, le rho de Spearman, le r de Pearson et le W de Kendall, puisque les calculs se font toujours à partir des mêmes données.
2) Une comparaison qui nous permettra de constater le transfert des habi-letés acquises en B (oral-écrit) lorsque les sujets entraînés à cette manière codent de la façon A (oral).
3e test :
Le test: trente minutes d'enregistrement présentées aux codeurs par tranches de cinq minutes.
A code selon B B code selon B Cette manière exigera:
28
- de l'équipe A: qu'elle recoure au codage oral-écrit auquel elle n'a pas été entraînée;
- de l'équipe B: qu'elle recoure au codage oral-écrit auquel elle a été entraînée.
Il est à noter ici qu'il y aura permutation entre les codeurs à l'intérieur de chaque équipe afin d'éliminer l'effet systématique de la subjectivité de chaque codeur. Nous ferons, ici encore, deux comparai-sons:
1) Lorsque B code selon B, une comparaison du pourcentage d'accord selon Bellack avec les autres coefficients: celui de Scott, le rho de
Spearman, le r de Pearson et le W de Kendall, à partir des mêmes données.
2) Une comparaison qui permettra de constater le transfert des habiletés acquises en A (oral) lorsque les sujets codent de la façon B (oral-écrit).
4e test:
Dans ce dernier test, l'équipe A code selon la manière à laquelle elle a été entraînée, à partir de la bande sonore, mais avec divisions de l'enregistrement à analyser en périodes de vingt secondes. Il sera ainsi possible d'utiliser la formule permettant de calculer le pourcentage d'ac-cord ou méthode de Bellack en l'appliquant aux segments consécutifs de vingt secondes et en totalisant les résultats obtenus à chaque segment. Les pourcentages d'accord ainsi obtenus seront comparés aux autres coeffi-cients.
Ces tests, construits dans le but de nous permettre de recueillir les données nécessaires à notre étude sur des coefficients de fiabilité et sur le transfert des habiletés de l'une à l'autre manière de s'entraî-ner, ont permis d'obtenir les résultats que nous donnons dans les pages qui suivent.
Conclusions :
Le système de Joyce que nous voulions utiliser pour une étude ex-ploratoire des coefficients de fiabilité s'est donc, dans des travaux préliminaires, avéré applicable dans les milieux où nous voulions
l'uti-liser. C'est ce qui nous a permis de passer à une étude systématique de la fiabilité du système.
Cette étude s'est faite d'une manière différente par deux sous-groupes qui s'entraînaient l'un d'une manière orale, l'autre d'une manière orale-écrite. Les sous-groupes ont respecté les directives pré-déterminées qui leur avaient été imposées permettant ainsi, en plus d'une étude
explo-23
ratoire de coefficients de fiabilité, d'observer les possibilités de transfert des habiletés acquises à la suite de deux types d'entraînement différents.
Nous saurons également si, pour la recherche, un portrait global qui nous est donné par le coefficient de Scott, le rho, le r de Pearson et le W de Kendall est aussi fidèle que le portrait détaillé qui nous est donné par la méthode de Bellack. Au niveau de la recherche toujours, la décision d'employer l'une ou l'autre manière de coder sera déterminée par les résultats obtenus aux différents tests.
Les tests ont été construits dans le but de nous permettre de recueillir les données nécessaires à notre étude sur des coefficients de fiabilité et sur le transfert des habiletés de l'une à l'autre manière de s'entraîner.
RESUME. Nous avons, dans ce chapitre, décrit de quelle manière s'est fait l'entraînement et quelle a été la formule de travail employée par les deux équipes. Puis nous avons décrit les quatre étapes du tes-ting, ce que chacune de ces étapes vise et permet de vérifier. Suite à la description des tests nous donnons un aperçu de ce qui veut être observé par chacun d'eux.
Les résultats des quatre tests sont donnés et comparés dans le troisième chapitre de ce travail.
LES RESULTATS DES TESTS ET LEUR SIGNIFICATION
SOMMAIRE. Dans le présent chapitre, nous donnons les résultats obtenus aux quatre étapes du testing et nous les comparons entre eux. Nous y jugeons également de l'efficacité de deux manières différentes de s'entraîner à un système d'analyse du comportement verbal des ensei-gnants .
Avant de passer aux deuxième, troisième et quatrième tests de notre étude, nous avons vérifié à quel niveau d'accord inter-équipes
avait mené l'entraînement. C'est ce que nous avons mesuré dans un pre-mier test.
1er test:
Ce test nous permet de vérifier à quel niveau d'entente inter-équipes a mené l'entraînement. Il comportait quatre-vingt catégories préalablement soulignées afin d'obtenir une grande variété dans les ca-tégories. Chaque codeur y travaillait individuellement. Les résultats furent calculés en pourcentage d'accord de la manière suivante:
Table 1
R é s u l t a t s obtenus par l e s h u i t
codeurs pour quatre comrjuiiications.
Juge 3
- V
1 2 3 45
67
8£
Connu» 1 . F-3 F-3 F-3i:-i
K-l H-li:-i
K-l35
2,r-3
F-3 F-3 F-3 F-3 F-3 F-3 F-3 1003.
F-3 r-3
Ï:-3r-3
F-3 F-3 F-3 F-3 824.
...
1-3 1-3 1-3 1-3 1-3 1-3 1-3 1-3 100 iloy. t o t a l e : 79.2$25
La page vingt-six est la reproduction de la page de protocole qui a permis aux juges d'identifier les communications telles que nous les retrouvons inscrites sur la Table 1. Les juges avaient à identifier, et à diviser si nécessaire, les lignes soulignées.
Ainsi, dans la première phrase soulignée sur le protocole, cinq juges ont séparé le "Bon" du reste de la phrase, l'identifiant comme M-l, alors que les trois autres juges l'ont inclu dans la communication de type P-3, ce qui donne un pourcentage d'accord de 35%. Par contre, la dernière communication soulignée sur cette page de protocole a fait l'u-nanimité chez les codeurs qui l'ont tous identifiée comme étant du 1-3;
l'accord est donc ici à 100%.
29 Pour l'ensemble du test, le résultat est de 72%.
Ce premier codage, fait simultanément par les huit codeurs, nous permit de déceler certaines difficultés dont nous avons discutées afin de les résoudre. C'est à la suite de ces ententes que les trois autres tests ont été passésT
2e test:
Dans ce test, les juges codaient exactement le même 30 minutes de cours, divisé en six périodes de cinq minutes; chaque cinq minutes d'enre-gistrement était tiré d'un cours de géographie différent donné par divers enseignants. Les codeurs inscrivaient leurs catégories sur des feuilles
B. Othanel Smith et Milton Meux rapportent des coefficients sem-blables: "Coefficients (of agreement between pairs of judges) range from .62 to .73 -a fairly small range- with a median of .70... Coefficients (of agreement between pairs of judges) range from 0.00 to 1.00. The median is .67, and the middle 50% of the coefficients range from .62 to .84 -a
fairly high percentage of agreement for the present status of the categories... In Teaching Vantage Points for Study, edited by Ronald T. Hyman (Philadelphia and New-York: I.B. Lippincott Company, 1968), "A Study of the Logic Teaching", B.O. Smith and Wilton Meux, pp.106,113-114.
PorL'_ *"-a P^^io^0 d ' a u j o u r d ' h u i , on va l a diviner en deu
p a r t i e s , on va f i n i r d'abord l a discussion de du que {stionnaire du r a j p o r t de l ' e x p é r i e n c e t r o i s fois t r e i fee, et p u i s , on va f i n i r l a pCriode en corrigeant le: (problèmes t r e n t e - s i x à cuatante-deux. Donc, tout- le.mo nde a devant l u i son questionnaire l à ,
I
Irardon Monsieur
tLe rapport le rapport, auspitot que le questionnaire jera terminé, le rapport vous me le remettez» Attendes
I
I
p.a fin de l a d i s c u s s i o n . D'accord.
Alors, je c r o i s qu'hiei- npus é t i o n s rendus, à l a quest ion douze.
• I Douze
Cn é t a i t rendu à quinze .
On é t a i t rendu à quinze, Monsieur. quinze
lion, non, non Question quinze:
•Fas à quinze
I I I
Quelles sont les diverses, les températures d'ébulliti
; , .,
-on de s divers liquides? Rép-onse?
l e s l i q u i d e s un, cent cirJq, le liquide deux, cent deux , le liquide t r o i s c e n t .
I
Une réponse, d ' a u t r e s réponses?
? '. I une réponse générale. Cn d i t i c i que c ' e s t une réponse générale qu'on doit s
I
•attendre â trouver. Sst-cc que tout le monde e s t d'à
ccord avec ça? ou s i VOUEJ ê t e s en contradiction?
27
blanches au fur et à mesure que se déroulait la bande sonore qui ne fut écoutée qu'une seule fois. C'est ce que nous qualifions de "codage oral." Comparaison des coefficients pour l'ensemble des juges:
La Table 2 donne les résultats globaux pour tous les juges, pour chaque coefficient, pour chaque cinq minutes.
Ce qui frappe au premier abord, c'est que le coefficient de Scott, le Rho„, et le W sont plus bas dans les deuxième et sixième cinq minutes que dans les autres. Or, dans ces deux cinq minutes, le nombre des caté gories est égal ou inférieur à sept, constatation qui peut être faite à partir du X^2 qui n'a pu être calculé; le X^2 ou x2 qui découle du W de Kendall ne peut être calculé que lorsque le nombre de catégories est su périeur à sept. Nous pouvons donc nous demander si le nombre des catégo ries utilisées n'affecterait pas le calcul des coefficients.
Le coefficient de Scott, pour le sixième cinq minutes, a une va leur négative, phénomène que nous retrouvons dans d'autres données de ce même coefficient. D'après les statisticiens consultés, le rationnel de ce coefficient de Scott est à peu près impossible à interpréter, et chose surprenante, les résultats qu'il donne peuvent être inférieurs à 0. L'é cart moyen obtenu à partir de ses données est de .263, chiffre qui laisse supposer une faible stabilité de ce coefficient particulièrement si nous le comparons aux écarts moyens des autres coefficients qui sont de .111, .130 et .083 dans le cas du W, du Rho2 et du r de Pearson respectivement.
On retrouve une constance dans ses résultats, à savoir qu'ils sont tou jours plus bas que ceux obtenus au moyen des autres coefficients, ce qui permet de constater qu'il est très sévère.
Avant de passer aux comparaisons des coefficients entre eux, nous
■ ' ' 2
Table 2
Coefficients obtenus par l'ensemble des juges, pour chaque cinq minutes du test no 2.*0
Cinq minutes Scott Rho.
w
Rho2k 2 * 1 J.
1.
.586 .822 .810 .779 s. à ,001 n.s. .9632.
.017 .768 .577 .506 - 18 n.s. .9593.
.688 .914 .934 .923 s. à .001 n.s. .9004.
.357 .553 .647 .588 s. à .001 18 n.s. .9075.
.530 .71V .766 .727 s. à .001 n.s. .9176.
-.123 .492 .616 .553 - 15 n.s. .775 moyennes des cinq minutes. .342 .710 .725 .679 .904 écarts moyens .263 .111 .130 .044 30Rho^: calcule au moyen de la formule originale en tenant compte des permutations entre les juges. C'est la moyenne des résultats ainsi obtenus que nous donnons.
RÎK>2: est calculé à partir du W de Kendall.
X ^ : est calculé au moyen de la formule originale. Sur 21 possibilités de permutation, toutes ne sont pas "non significatives" à
chaque cinq minutes. C'est pourquoi nous inscrivons n.s. lorsque tous les résultats sont non significatifs; dans les cas contraires, nous ins-crivons le nombre de fois sur 21 (sur 6 dans les autres tables) où le ré-sultat est non significatif.
X ^ : est calculé à partir du W de Kendall et donne immédiate-ment le résultat pour tous les juges. Les deuxième et sixième cinq minu-tes n'ont pas de résultat parce que le nombre de catégories était égal ou inférieur à sept, et qu'une condition pour calculer ce x2 est que le nombre de catégories soit supérieur à sept.
Ces remarques valent également pour les Tables 3A, 3B, 4, 5A, 5B et 7.
29 2
Le X i est non significatif aux premier, troisième et cinquième cinq minutes, ce qui signifie que dans ces cas, les résultats de toutes les permutations sont non significatifs et que le codage des observateurs ne diffère pas significativement. Le X ^ nous permet de dire qu'au pre mier, troisième, quatrième et cinquième cinq minutes, les codeurs se sont bien entendus et que leurs jugements sont significativement semblables.
Si l'on compare le Rhoi et le Rhoj, on observe une différence due au fait que le Rho^ est une moyenne obtenue à partir des résultats de toutes les permutations, tandis que le Rho2 est calculé directement à par tir des résultats de chaque juge. Le Rh02 est donc plus juste puisque les résultats des juges n'y sont utilisés qu'une seule fois. Donc, même s'il apparaît intéressant de voir la différence qui pourrait exister en tre les deux, nous ne tiendrons pas compte du Rho^ dans nos figures.
Pour comparer les coefficients entre eux, nous avons cru bon d'u tiliser une figure.
Ainsi,*la figure 2 montre que le W et le Rho2 s'apparentent et
Figure 2
Comparaison du Scott, du Rho?, du W et du r
pour chaque cinq minutes du test no 2.
(coefficients obtenus par l'ensemble des juges)
Scott '■"■' " ■' ■ Rho2
que les observations que nous ferons pour le W vaudront également pour le Rho».
Le coefficient de Scott suit à peu près la même courbe que le W mais il est cependant beaucoup plus faible dans les deuxième et sixième cinq minutes où le nombre des catégories employées est égal ou inférieur à sept. On peut donc supposer que le coefficient de Scott est influencé par la variété des catégories utilisées pour le codage.
Le r de Pearson se situe au-dessus des autres coefficients et la courbe qu'il suit est différente de celles suivies par les autres coeffi-cients, particulièrement aux points marqués par les deuxième, troisième et quatrième cinq minutes. On peut donc observer ici que le r de Pearson suit une courbe différente des trois autres coefficients soit le R1K>2» le
W et le coefficient de Scott puisque les analyses précédentes avaient démontré la similitude des courbes dans ces trois cas. L'écart moyen de
.083 obtenu à partir de ces données nous montre que le r est stable et qu'il se rapproche de la ligne droite, mais il semble y avoir un biais orienté vers une surestimation de l'accord entre les juges.
Conclusion;
Quelques remarques générales se détachent des analyses qui précè-dent:
- Il semble que la variété des catégories utilisées durant le codage
influence les coefficients de Scott, le Rho2 et le W de Kendall. Cette remarque ne vaut cependant pas pour le r de Pearson.
- Le coefficient de Scott, qui peut avoir des valeurs négatives, est
tou-jours inférieur aux autres coefficients même s'il suit une courbe
sem-blable au W et au Rho2. L'écart moyen indique d'ailleurs la faible
31
- Le X'jL indique que dans trois cinq minutes, les résultats obtenus par les codeurs ne se distinguent pas significativement pour les 21 permu-tations possibles.
- le X^2 dans les cinq minutes où il a été possible de le calculer, nous montre que les codeurs ont des jugements qui sont significativement semblables.
- Le r de Pearson se distingue passablement des autres indices et il sera intéressant de le comparer particulièrement au pourcentage d'accord. Comparaison des résultats entre les deux équipes:
Les résultats de l'ensemble du groupe ayant été analysés, il de-vient intéressant ici de comparer les résultats des deux équipes.
Dans les Tables 3A et 3B, on remarque immédiatement le même phé-nomène que dans la Table 2, c'est-à-dire que lorsque la variété des caté-gories est égale ou inférieure à 7, les coefficients sont en général plus faibles. On note quand même une petite différence dans la Table 3A au niveau du 4ièmê cinq minutes où les coefficients sont inférieurs au 21ème cinq minutes, à l'exception du Scott, même si la variété des catégories est supérieure à 7.
Si nous observons maintenant les chi carrés, nous voyons qu'ils ont des résultats qui concordent plus ou moins à ceux des autres coeffi-cients, particulièrement dans la Table 3B.
En effet, dans la Table 3B, le X2, nous dit que les juges ont des
résultats qui ne se distinguent pas significativement, même dans le cas du 6ième cinq minutes où les résultats du Scott, des Rho et du W sont plutôt faibles; ce X2 a cependant des résultats plus près de ceux des
autres coefficients dans la Table 3A.
coefficients de la Table 3A; cependant, les X^2 de la Table 3B accusent une diminution de l'accord entre les juges qui n'est pas justifiable si nous les comparons aux autres coefficients. Ce fait peut s'expliquer par le nombre de juges qui n'est que de trois pour l'équipe B. Sachant que le X 2 se calcule à partir du W et que le W est particulièrement utile dans les cas où il y a plusieurs juges, nous pouvons avancer que la dimi-nution du nombre de juges a influencé le X ^ *
Si nous observons maintenant les figures, la figure 3 ou compa-raison du W de Kendall montre que les deux équipes ont des résultats plu-tôt identiques.
Ayant vu dans la figure 2 que le W de Kendall et le RI102 offraient peu de différence, nous jugeons que ce qui s'applique à la figure 2 s'ap-plique tout aussi bien dans le cas actuel.
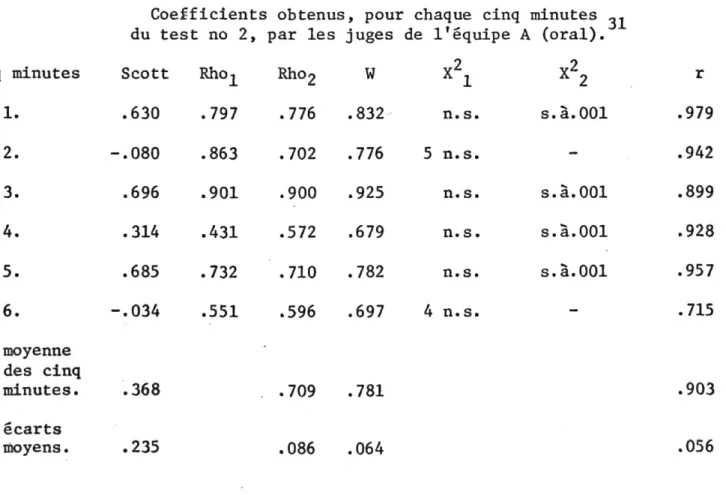
Table 3A Coefficients obtenus
du test no 2, par les juges
, pour chaque cinq minutes .. juges de l'équipe A (oral). minutes Scott Rho-L Rho 2 W
A 1 X2 r 1. .630 .797 .776 .832 n.s. s. à.001 .979 2. -.080 .863 .702 .776 5 n.s. - .942 3. .696 .901 .900 .925 n.s. s.à.001 .899 4. .314 .431 .572 .679 n.s. s.à.001 .928 5. .685 .732 .710 .782 n.s. s.à.001 .957 6. -.034 .551 .596 .697 4 n.s. - .715 moyenne des cinq minutes. .368 .709 .781 .903 écarts moyens. .235 .086 .064 .056
33 Table 3B
Coefficients obtenus, pour chaque cinq minutes du test no 2, par les juges de l'équipe B (oral-écrit).
Cinq minutes Scott Rho1 Rho2 W X2± X2 2 r
1. .464 .851 .742 .828 n.s. s.à.01 .935 2. .211 .710 .488 .658 n.s. - .989 3. .616 .953 .928 .952 n.s. s.à.01 .894 4. .413 .532 .608 .738 n.s. s.à.02 .904 5. .363 .700 .728 .819 n.s. s.à.01 .871 6. -.023 .435 .354 .569 n.s. - .967 moyenne des cinq minutes. .340 .641 .760 .926 écarts moyens. .165 .158 .158 .037 La comparaison du coefficient de Scott dans la figure 4 permet
de constater une différence entre les deux équipes. L'équipe A dont l'é-cart moyen est de .229 a des résultats qui varient beaucoup plus que l'équipe B dont l'écart moyen est de .164. La variation est particuliè-rement forte pour l'équipe A dans le deuxième cinq minutes, où le pi est négatif, et le cinquième cinq minutes, où il est de .685 comparativement au cinquième cinq minutes de l'équipe B qui est de .363.
La figure 5 ou comparaison du r de Pearson présente des courbes assez rapprochées pour les deux équipes. Les résultats du sixième cinq minutes ont cependant une différence de .252, différence assez importante puisque le r de Pearson varie très peu, ses écarts moyens étant de .064
31
Les explications inscrites au bas de la Table 2 sont également valables pour les Tables 3A et 3B.
Figure 3
Comparaison du W ob-tenu par chacune des
équipes .4* • »> o i *. 3 4 «r t Equipe A Equipe B Figure 4
1.°°
Comparaison du coef- ^ ficient de Scott ob- ' tenu par chacune des .&>équipes
»a°
Equipe A Equipe B I x 1 + S- <> Figure 5 i Comparaison du r de #3° Pearson obtenu par ^ chacune des équipes.a>
o
Equipe À Equipe B
35
pour l'équipe A et de .049 pour l'équipe B. Conclusion:
Devant le peu de différence qui existe entre les résultats des deux équipes dans le codage oral, l'on est porté à conclure que le trans-fert des habiletés s'est fait sans difficulté pour l'équipe B.
On se souvient que cette équipe (B) s'est entraînée à coder avec des protocoles et des bandes sonores alors que l'équipe A s'est entraînée uniquement avec les bandes sonores. Dans cette étape où les codeurs ont inscrit leurs réponses uniquement à partir de bandes sonores, on réalise que l'équipe B n'a pas rencontré plus de difficultés que l'équipe A. C'est du moins ce que nous laissent voir les divers coefficients de fiabilité.
Donc les codeurs qui se sont entraînés à l'oral-écrit ont pu fa-cilement transposer leurs habiletés au niveau d'un codage uniquement oral. 3e test:
Les données de ce test devaient être codées selon la méthode sug-gérée par Bellack avec les étapes précises suivantes:
1) Il y a toujours deux équipes de deux codeurs chacune. 2) Dans chaque équipe, il y a un codeur et un réviseur.
3) Le codeur prend le temps qu'il lui faut pour coder le protocole, y In-diquant la nature des communications et le nombre de lignes de chacune de celles-ci. Le codeur peut écouter l'enregistrement autant de fois qu'il le désire.
4) Le codeur une fois qu'il a terminé son travail, transmet à son réviseur le protocole codé et l'enregistrement.
5) Le réviseur écoute l'enregistrement et "revise" le codage indiquant ou prenant note des désaccords. Le réviseur peut écouter l'enregistrement aussi souvent qu'il le désire.
6) Lorsque le réviseur a terminé son travail, il en informe le codeur. 7) Codeur et réviseur se rencontrent pour régler leurs différends. Encore
ici protocole et enregistrement sont utilisés. On doit alors arriver 32
à une version finale unique.
Comme nous l'avons signalé dans la description du 3e test, il y a permutation entre les codeurs à l'intérieur de chaque équipe afin d'é-liminer l'effet systématique de la subjectivité de chaque codeur.
Ce test nous permet de calculer le pourcentage d'accord, selon la méthode originale; il faut compter les accords (A) et les désaccords (D) des sous-groupes pour la nature de l'unité et pour le nombre de lignes. Exemple :
Bon, il te manquerait le mouvement de rotation. Oui, très bien, à part çà? Oui?
Nature l ' u n i l Ï de té Nombre de l i g n e s A D A D 1 1 1 1 1 1 1 1 1 1 4 1 4 1 Bon (M-l, M-l)
il te manquerait le aouvemeni de rotation(l-4. Oui, très bien (S-3+, S-3+)
à part ça? (1-3. I-l) Oui? (P-3. P-3)
Total
Pour obtenir le pourcentage d'accord entre les codeurs, il faut diviser le nombre des accords par la somme des accords et des désaccords. Dans l'exemple, nous avons quatre accords (A) et un désaccord (D) pour la
La démission d'un membre du groupe a forcé l'équipe B à procéder différemment. Ne se retrouvant plus que trois membres, un protocole sur deux était codé par un seul juge sans revision. C'est ce qui expliquerait peut-être certaines faiblesses de cette équipe.