HAL Id: hal-02815570
https://hal.inrae.fr/hal-02815570
Submitted on 6 Jun 2020
HAL is a multi-disciplinary open access
archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
Evolution d’un modèle de bilan de gaz à effet de serre et
refonte de son paramétrage
Senoumi Kpamegan
To cite this version:
Senoumi Kpamegan. Evolution d’un modèle de bilan de gaz à effet de serre et refonte de son paramé-trage. [Stage] Institut Supérieur d’Informatique, de Modélisation et de leurs Applications (ISIMA), FRA. 2009, 65 p. + annexes 23 p. �hal-02815570�
KPAMEGAN Sénoumi Karel
Stage d’Avril à Septembre 2009
Institut Supérieur
d'Informatique, de
Modélisation et de
leurs Applications
Rapport d’ingénieur en stage de deuxième année
Filière Systèmes d’Information et Aide à la Décision
Evolution d’un modèle de bilan de gaz à effet de
serre et refonte de son paramétrage
TOME II ANNEXES
Lieu d’accueil : Institut National de la Recherche en Agronomie dans l’Unité de Recherche sur l’Ecosystème PrairialResponsables entreprise : Raphaël Martin Vincent Blanfort
KPAMEGAN Sénoumi Karel
Stage d’Avril à Septembre 2009
Institut Supérieur
d'Informatique, de
Modélisation et de
leurs Applications
Rapport d’ingénieur en stage de deuxième année
Filière Systèmes d’Information et Aide à la Décision
Evolution d’un modèle de bilan de gaz à effet de
serre et refonte de son paramétrage
TOME II ANNEXES
Lieu d’accueil : Institut National de la Recherche en Agronomie dans l’Unité de Recherche sur l’Ecosystème Prairial Responsables entreprise : Raphaël Martin Vincent Blanfort Tuteur I.S.I.M.A. : Philippe LacommeIntroduction générale
Les annexes sont composées de deux parties indépendantes l’une de l’autre.
La première annexe présente une introduction à trois outils permettant l’utilisation du langage XML et la création de tels fichiers en Java : JDOM, STAX et XSTREAM.
La seconde présente une comparaison des performances entre deux outils permettant la création et l’écriture de fichiers Excel en Java : POI et JEXCEL.
Sommaire
ANNEXE I
Outils pour manipuler le XML en java : JDOM, XSTREAM, STAX
ANNEXE II
Outils pour manipuler EXCEL en java : POI vs JEXCEL
1. Presentation de POI...Erreur : source de la référence non trouvée 2. Présentation de JEXCEL...Erreur : source de la référence non trouvée 3. Comparaison des performances...Erreur : source de la référence non trouvéeANNEXE I
Outils pour manipuler le
XML en java : JDOM,
XSTREAM et STAX
Ce dossier est issu de plusieurs recherches effectuées sur Internet ainsi que de nombreux essais réalisés par mes soins sur machine.Il présente différents objectifs, d’une part, c’est un recueil présentant les fonctionnalités et caractéristiques du langage XML. Ensuite, il expose divers outils existant pour utiliser le XML via le langage JAVA. En outre, ce document a pour but de permettre une prise en main et une manipulation plus ou moins aisée de ce langage.
1. Introduction aux deux grands modes de traitement du XML
A l'heure actuelle, le langage XML est de plus en plus présent dans le monde informatique. XML (eXtented Markup Language) est un langage à balises, employé pour le stockage et l’échange de données, contrairement au langage HTML qui est destiné à l’affichage via un navigateur web. La première ligne d’un document « .xml » permet de définir sa version ainsi que l’encodage des caractères (ex : <?xml version="1.0" encoding="ISO-8859-1"?>).La représentation sousjacente d’un document XML est un arbre ordonné, dont les noeuds internes sont les balises et les feuilles le contenu de ces balises (éventuellement vide). Il y a une balise particulière, la racine du document. Chaque balise doit être fermée (à une balise <a> doit correspondre une balise </a>). Cela n’est pas nécessaire en HTML (sauf dans sa version étendue). Une balise fermante clôt toujours la dernière balise ouverte. Une balise qui ne contient pas de données peut être écrite sous cette forme : <balise/>. Ceci est équivalent à : <balise> </balise>.
De plus, on fait, la distinction entre lettres majuscules et minuscules. Par exemple, les balises <jeu> et <Jeu> sont différentes. Exemple de code XML : <?xml version="1.0" encoding="ISO-8859-1"?> <segment> <point> <abscisse>0.0</abscisse> <ordonnee>0.0</ordonnee> </point> <point> <abscisse>1.0</abscisse> <ordonnee>2.0</ordonnee> </point> </segment>
Pour traiter ce format, il existe deux grandes méthodes : SAX et DOM.
De son coté, SAX (ou Simple API for XML) est de type évènementiel. Un parseur SAX va lire un document XML et va considérer l'ouverture d'une balise, sa fermeture et le début d'une zone de texte comme des évènements. Et, pour chacun de ceuxci correspond une méthode qui sera appelée par le parseur. C'est l'ensemble de ces méthodes qui devront être fournies par le développeur afin de traiter le document XML. L'avantage de cette méthode est qu'elle est très rapide et très peu gourmande en mémoire. En contre partie, le traitement est fait en une seule fois, et ne fournit pas d'accès direct (sans avoir à relire l’intégralité du fichier) à une donnée précise du fichier. De l'autre coté, DOM (ou Document Object Model) fonctionne différemment : un parseur DOM va lire un document XML et va créer la représentation mémoire de celuici sous forme d'un arbre. Cette représentation implique une forte utilisation mémoire ainsi qu'un temps de traitement plus long que SAX. Mais DOM a pour avantage de fournir un accès direct (instantané) et illimité aux données. De plus, DOM n'est pas limité à la lecture d'un fichier XML. En effet, une fois un arbre créé en mémoire, il est tout à fait possible de le modifier (supprimer, ajouter, modifier ses nœuds). 3
2. JDOM ou Comment manipuler le XML à partir du JAVA
2.1. Introduction à JDOM
Afin de manipuler les documents XML, il est nécessaire d’avoir à sa disposition des APIs efficaces. Il en existe deux principalement : DOM et SAX (Cf. partie précédente).
JDOM est une API écrite en java et pour java, qui passe outre les limitations inhérentes à DOM dont elle s’inspire. L’intérêt principal de JDOM est son extrême simplicité. C’est donc une librairie qui permet de créer des documents XML ou alors de les « parser ». Pour utiliser cette librairie il suffit de récupérer le fichier JAR correspondant et de l’associer au projet de développement. 2.2. Comment créer du code XML à partir du JAVA Autant montrer le code JAVA pour rentrer directement dans le vif du sujet. Voici le code XML à générer : <OVERVIEW> <LOCATION>
<ALTITUDE min="50" max="250" /> </LOCATION> </OVERVIEW> Voici le code correspondant : import java.io.*; import org.jdom.*; import org.jdom.output.*;
public class Overview {
static Element overview = new Element("OVERVIEW");
static org.jdom.Document document = new Document(overview);
public static void main(String[] args) {
Element location= new Element("LOCATION"); Element altitude= new Element("ALTITUDE"); Attribute min = new Attribute("min","50"); Attribute max = new Attribute("max","250"); altitude.setAttribute(min); altitude.setAttribute(max); location.addContent(altitude); overview.addContent(location); enregistre("overview_test.xml"); }
static void enregistre(String fichier) {
try
{
XMLOutputter out = new XMLOutputter(Format.getPrettyFormat()); out.output(document, new FileOutputStream(fichier));
catch (java.io.IOException e){} }
}
Pour l’arborescence
:
Chaque nœud/balise d’un document XML correspond à un objet « Element » dans le code précédent (classe écrite sous JDOM). Pour implémenter la notion d’arborescence, il faut ajouter des nœuds fils (toujours de type Element) à des nœuds pères (du même type), sachant que nous avons préalablement parlé d’une racine unique indispensable à tout document XML. Pour ajouter un nœud fils on utilise la méthode « addContent() ». Pour la valeur des balises : On peut attribuer une valeur ou un texte à une balise XML. Pour cela, on utilise la méthode « setText() ». Pour les attributs des balises : On peut ajouter des attributs à chaque balise. On peut donner autant d’attributs que souhaités. Un attribut est déclaré indépendamment de la balise à qui il va être
associé. Il est de type « Attribut » et on le crée de la manière suivante : new
Attribute("nom","valeur"); On associe l’attribut créé à la balise souhaitée via la
méthode « setAttribute() ». 2.3. Comment parser des données à partir du XML pour les utiliser en JAVA import java.io.*; import org.jdom.*; import org.jdom.input.*; import org.jdom.filter.*; import java.util.List; import java.util.Iterator;
public class JDOM2 {
static org.jdom.Document document; static Element racine;
public static void main(String[] args) {
SAXBuilder sxb = new SAXBuilder(); try
{
document = sxb.build(new File("overview_test.xml")); }
catch(Exception e){}
racine = document.getRootElement(); afficheALL();
} }
static void afficheALL() {
List listLocations = racine.getChildren("location"); Iterator i = listLocations.iterator();
while(i.hasNext()) {
Element courant = (Element)i.next();
System.out.println(courant.getChild("altitude"). getAttributeValue(“min”)); }
}
Encore une fois, rien de tel que du code pour comprendre concrètement les
choses. Dans un premier temps, on parse le document XML à analyser via SAX.
Ensuite, on a accès aux différents éléments XML. Notons qu’il nous faut impérativement connaître la structure du document XML pour pouvoir l’analyser le plus efficacement possible.
Accès aux balises
:
D’abord, on récupère la racine par la méthode getRootElement(). Ensuite, on
accède aux différentes balises par la méthode getChildren(). On peut donc ainsi
parcourir l’arborescence.
Accès aux données des balises
:
Pour récupérer la valeur ou le texte associé à une balise, on utilise la
méthode .getText().
Accès aux attributs des balises
:
Pour récupérer les valeurs des attributs des balises on utilise la méthode
getAttributeValue() ;
CONCLUSION DE LA PARTIE
Pour conclure, on notera la simplicité d’utilisation de cette bibliothèque JDOM qui permet aisément de créer des documents XML et qui justifie pleinement l’avantage incontestable de l’utilisation de ce type de documents (XML). Cependant, on notera que le parsage d’un tel document est assez exhaustif et qu’il faut connaître minutieusement la structure du document XML pour le parser au mieux.
3. XSTREAM ou Comment manipuler le XML à partir du JAVA
3.1. Introduction à XSTREAM
XStream est une API Java qui permet de sérialiser et désérialiser des objets dans des fichiers XML. XStream est une librairie idéale pour les néophytes du DOM et SAX, on trouvera plus de facilités dans la création et les manipulations de fichiers XML en utilisant XStream.
Les finalités d'XStream sont très nombreuses, le transport de données, utilisation de fichiers de configuration, etc.
3.2. Comment créer du code XML à partir du JAVA
Il y a plusieurs étapes à respecter. Premièrement, on doit créer les classes que l’on va utiliser ; les classes à sérialiser. C’est la création de ces classes qui va déterminer l’arborescence du document XML généré. Prenons un exemple :
public class Altitude {
private float min;
private float max;
public Altitude(float max, float min) {
super();
this.max = max;
this.min = min; }
public float getMin() {
return min; }
public void setMin(float min) {
this.min = min; }
public float getMax() {
return max; }
public void setMax(float max) {
this.max = max; }
}
public class Location {
private Altitude altitude;
public Location(Altitude altitude) {
super();
this.altitude = altitude; }
public Altitude getAltitude() {
return altitude; }
public void setAltitude(Altitude altitude) {
this.altitude = altitude; }
public class Overview {
private Location location;
public Overview(Location location) {
super();
this.location = location; }
public Location getLocation() {
return location; }
public void setLocation(Location location) {
this.location = location; }
}
On a donc créé 3 classes en suivant le schéma suivant : un objet de type « location » possède un objet de type « altitude ». Un objet de type « overview » possède un objet de type « location ». Une « altitude » est composée d’une min et d’une max.
Après la déclaration et la définition de ces classes, on peut débuter l’implémentation du code visant à sérialiser nos données :
import com.thoughtworks.xstream.XStream;
import com.thoughtworks.xstream.io.xml.DomDriver;
public class Serialisation {
public static void main(String[] args) {
XStream xstream = new XStream(new DomDriver()); Altitude altitude = new Altitude(50, 250); Location location = new Location(altitude); Overview overview = new Overview(location); String xml = xstream.toXML(overview);
System.out.println(xml); } } Ce code est très concis et simple à comprendre. On définit notre arborescence, on construit un objet XSTREAM, on associe notre arborescence à l’objet et on l’affiche. Voici le code XML généré : <Overview> <location> <altitude> <min>250.0</min> <max>50.0</max> </altitude> </location> 11
Pour l’arborescence :
Chaque nœud/balise d’un document XML correspond à une classe préalablement créée ou dans le cas d’une feuille, la balise correspond à une variable de type primitif (entier, réel, string, etc ….). Pour implémenter la notion d’arborescence, il faut utiliser la notion de composition dans les classes. En d’autres termes, « Overview » est composé d’une « Location » ellemême composée d’une « Altitude » qui est composée d’une min et d’une max.
Pour la valeur des balises :
On peut attribuer une valeur ou un texte à une balise XML. Pour cela, la balise doit correspondre à une variable de classe et non pas à une classe proprement dite. Par exemple min et max dans notre situation.
Pour les attributs des balises :
Ca se complique car ce n’est pas dans le formalisme de la déclaration d’une classe.
3.3. Comment parser des données à partir du XML pour les utiliser en JAVA
C’est une opération très simple à faire, cependant, il faut impérativement connaître la structure du document à parser sous forme d’une classe. import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import beans.Article; import com.thoughtworks.xstream.XStream; import com.thoughtworks.xstream.io.xml.DomDriver;
public class Deserialisation {
public static void main(String[] args) {
try {
XStream xstream = new XStream(new DomDriver());
FileInputStream fis = new FileInputStream(new
File("c:/temp/overview.xml"));
try {
Overview nouvelOverview = (Overview) xstream.fromXML(fis); System.out.println(nouvelOverview.getLocation());
} finally { fis.close(); } 13
}
catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException ioe) { ioe.printStackTrace(); } } } CONCLUSION DE LA PARTIE Pour conclure, on notera qu’il est assez complexe de créer un document XML. Effectivement, il faut préalablement créer toutes les classes nécessaires. L’avantage incontestable est la simplicité du parsage du document XML qui se fait en une seule instruction. Néanmoins, le parsage du document peut être qualifié de statique : pas de place pour l’imprévu.
4. STAX ou Comment manipuler le XML à partir du JAVA
4.1. Introduction à StAx Issu du succès de DOM et SAX, StAx a emprunté des qualités à l’un comme à l’autre tout en créant des originalités. En effet, dans SAX, le traitement est dirigé par le parseur SAX. C'est lui qui va lire le document et générer les évènements au fur et à mesure qu'il progresse dans le document XML. Le code du développeur a un rôle passif : il traite les évènements du parseur mais ne possède aucun contrôle sur l'avancement dans le document. Dans StAx, c'est au contraire le code du développeur qui va faire les demandes au parseur, afin que celuici fournisse l'élément suivant dans le document.La fonctionnalité d'écriture de StAx diffère aussi de celle de DOM. DOM a besoin que l'arbre soit complètement construit avant de pouvoir l'exporter sur un flux. Ce qui peut parfois prendre énormément de temps. De son côté, StAx permet d'envoyer sur un flux les éléments directement à leur création, ce qui a comme contrainte qu'il faut s'assurer que la construction sera séquentielle, et qu'aucune balise ne sera ajoutée dans une section déjà envoyée. Cette contrainte mise à part, l'optimisation mémoire est importante, spécialement lors de l'écriture de gros documents XML.
En plus de fournir des fonctionnalités de lecture et d'écriture, StAx est composée de deux API.
La première est l'API Curseur : c'est une API de bas niveau, dont le fonctionnement se base sur un curseur virtuel qui permet de connaître la position dans le document XML et ainsi, autorise l'utilisation de certaines méthodes pour récupérer les informations.
La seconde est dite événementielle. Elle est de plus haut niveau, l'API va créer des objets représentant l'élément sur lequel elle se situe. Elle est un peu plus gourmande en mémoire (mais nettement moins que DOM) et un peu plus lente à cause de la création de ces objets.
4.2. Comment créer du code XML à partir du JAVA
Voici un exemple de code permettant de générer du XML :
import javax.xml.stream.XMLOutputFactory;
import javax.xml.stream.XMLStreamException;
import javax.xml.stream.XMLStreamWriter;
public class Ecriture {
public static void main(String[] args) { XMLOutputFactory outputFactory = XMLOutputFactory.newInstance(); XMLStreamWriter writer; try { writer = outputFactory.createXMLStreamWriter(System.out); writer.writeStartDocument(); writer.writeStartElement("Overview"); writer.writeStartElement("Localisation"); writer.writeStartElement("Altitude"); writer.writeAttribute("Min","50"); writer.writeAttribute("Max","250"); writer.writeEndElement(); writer.writeEndElement(); writer.writeEndElement(); writer.writeEndDocument(); writer.close(); } catch (XMLStreamException e) { e.printStackTrace(); } } } Ce code n’est pas très complexe mais demande quand même à faire attention lors de l’implémentation, à l’ouverture et la fermeture des balises. De plus, il faut placer les attributs au bon endroit. Voici la sortie observée :
<?xml version="1.0" ?><Overview><Localisation><Altitude Min="50" Max="250"></Altitude></Localisation></Overview>
Cette sortie n’est pas formatée/indentée (ce qui est un inconvénient important), certains outils tels qu’Internet Explorer permettent un affichage formaté/indenté : <?xml version="1.0" ?> - <Overview> - <Localisation>
<Altitude Min="50" Max="250" /> </Localisation>
</Overview>
Pour l’arborescence
:
Chaque nœud/balise d’un document XML est créé par une instruction « writer.writeStartElement("nomBalise"); ». Pour fermer une balise on utilise
l’instruction « writer.writeEndElement(); ». Pour implémenter la notion
d’arborescence il faut ajouter des nœuds fils à des nœuds pères.
Pour ajouter un nœud fils, il suffit de l’implémenter avec l’instruction précédente entre le début et la fin des instructions définissant la balise parente.
Pour la valeur des balises
:
On peut attribuer une valeur ou un texte à une balise XML. Pour cela, on utilise
la méthode « writer.writeCharacters("Coucou");». Il faudra faire attention au lieu
où l’on écrit cette instruction (ie. Dans quelle balise on se trouve). Pour les attributs des balises
:
On peut attribuer des attributs à une balise XML. Pour cela, on utilise la
méthode « writer.writeAttribute("Nom","Valeur"); ». Il faudra faire attention au
lieu où l’on écrit cette instruction (ie. à quelle balise on associe ces attributs).
4.3. Comment parser des données à partir du XML pour les utiliser en JAVA import java.io.File; import java.io.FileNotFoundException; import java.io.FileReader; import javax.xml.stream.XMLInputFactory; import javax.xml.stream.XMLStreamException; import javax.xml.stream.XMLStreamReader;
public class Lecture {
public static void main(String[] args) {
XMLInputFactory factory = XMLInputFactory.newInstance(); XMLStreamReader reader;
try {
reader = factory.createXMLStreamReader(new FileReader(new
File("overview_StAx.xml")));
boolean state = true;
while (reader.hasNext() && state) {
int type = reader.next();
switch (type) {
// Si c'est un début de Balise
case XMLStreamReader.START_ELEMENT:
if (reader.getLocalName().equals("Overview")) System.out.println("deb Overview");
else if (reader.getLocalName().equals("Localisation")) System.out.println("--deb Location");
else if (reader.getLocalName().equals("Altitude")) {
System.out.println("---- deb Altitude");
if (reader.getAttributeLocalName(0).equals("Min")) System.out.println("--- att Min : " + reader.getAttributeValue(0));
if (reader.getAttributeLocalName(1).equals("Max")) System.out.println("--- att Max : " + reader.getAttributeValue(1));
}
else System.out.println("deb Balise inexistante");
break;
// Si c'est une zone CDATA
case XMLStreamReader.CDATA: break;
// Si c'est du texte
case XMLStreamReader.CHARACTERS: break;
// Si c'est la fin d'une balise
case XMLStreamReader.END_ELEMENT:
if (reader.getLocalName().equals("Overview")) {System.out.println("fin Overview"); state=false;}
else if (reader.getLocalName().equals("Localisation")) System.out.println("-- fin Location");
else if (reader.getLocalName().equals("Altitude")) System.out.println("---- fin Altitude");
else System.out.println("fin Balise inexistante");
break; } } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (XMLStreamException e) { e.printStackTrace(); } } }
Pour l’arborescence :
On reconnaît le début d’une balise par le flag « XMLStreamReader.START_ELEMENT ». Il n’y a pas vraiment de réelle notion
d’arborescence en lecture ici avec StAx. On lit séquentiellement le fichier XML et on reconnaît les balises à partir de « if » et « else » sur le nom de la balise courante. Ce
nom est obtenu par la méthode « getLocalName() ».
Pour les attributs des balises :
Ils sont propres à la balise courante qui peut avoir ou non des attributs. On les reconnaît avec des « if » et « else » encore une fois. On récupère le nom de l’attribut
par la méthode « getAttributeLocalName(index) » et la valeur de l’attribut par
« getAttributeValue(0) ». Il faut noter qu’il faut impérativement récupérer les attributs quand on lit la balise qui nous intéresse. Si l’on passe à une autre balise on ne pourra plus accéder aux attributs de la balise précédente. CONCLUSION DE LA PARTIE Pour conclure, on notera qu’il est très simple de créer un document XML. Effectivement, quelques instructions suffisent. Un large problème réside dans le fait qu’il ne faut pas se louper quand à l’ordre d’écriture des balises sinon la structure du document XML sera changée. Dans le même style, en ce qui concerne les attributs d’une balise il faut veiller à les déclarer au bon endroit pour les affecter à la balise souhaitée. L’énorme avantage concerne le parsage du document XML qui permet de parser de la même manière plusieurs documents qui ont les mêmes balises mais pas nécessairement dans le même ordre. StAx autorise donc l’utilisateur à créer un fichier XML en instanciant les balises dans l’ordre qu’il veut. 19
5. Synthèse
J’ai étudié les temps d’écriture et de parsage de documents XML avec les différentes méthodes étudiées précédemment. Pour cela, j’ai créé le même document XML avec les différentes méthodes et je l’ai parsé de manière à afficher à l’écran ce fichier. Voici le fichier XML étudié ainsi qu’un tableau récapitulatif des performances : <?xml version="1.0" ?> - <OVERVIEW> - <SYSTEM><COUNTRY>FRANCE</COUNTRY> <REGION>AUVERGNE</REGION>
<FARM_SYSTEM>Notre ferme</FARM_SYSTEM> <USER_NAME>Karel</USER_NAME>
<USER_MAIL>[email protected]</USER_MAIL>
<USER_INSTITUTE>UREP INRA</USER_INSTITUTE>
</SYSTEM>
- <LOCATION>
<LATITUDE Degree="45" Min="22" Sec="39" /> <LONGITUDE Degree="70" Min="13" Sec="55" /> <ALTITUDE Min="50" Max="250" />
<ANNUAL_RAINFALL>870</ANNUAL_RAINFALL> <MEAN_ANNUAL_TEMP>12,7</MEAN_ANNUAL_TEMP>
</LOCATION>
- <CROSSING_PLAN>
<FALLOW_SURFACE>3,2</FALLOW_SURFACE>
<FALLOW_COMMENTS>une jachere</FALLOW_COMMENTS> <CLIMZONEINDEX>3</CLIMZONEINDEX> </CROSSING_PLAN> - <GRASSLAND> <NUMBER>4</NUMBER> </GRASSLAND> </OVERVIEW>
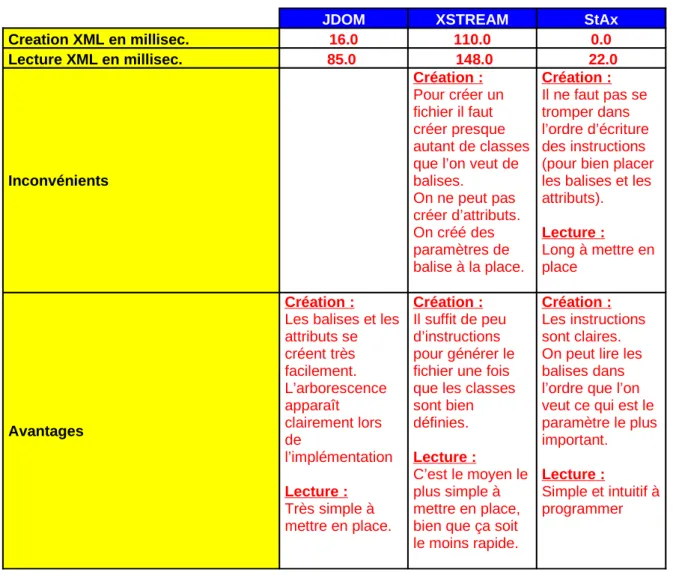
Tableau de performances :
JDOM XSTREAM StAx
Creation XML en millisec. 16.0 110.0 0.0 Lecture XML en millisec. 85.0 148.0 22.0 Inconvénients Création : Pour créer un fichier il faut créer presque autant de classes que l’on veut de balises. On ne peut pas créer d’attributs. On créé des paramètres de balise à la place. Création : Il ne faut pas se tromper dans l’ordre d’écriture des instructions (pour bien placer les balises et les attributs). Lecture : Long à mettre en place Avantages Création :
Les balises et les attributs se créent très facilement. L’arborescence apparaît clairement lors de l’implémentation Lecture : Très simple à mettre en place. Création : Il suffit de peu d’instructions pour générer le fichier une fois que les classes sont bien définies. Lecture : C’est le moyen le plus simple à mettre en place, bien que ça soit le moins rapide.
Création :
Les instructions sont claires. On peut lire les balises dans l’ordre que l’on veut ce qui est le paramètre le plus important. Lecture : Simple et intuitif à programmer Selon l’utilisation que l’on veut en faire, libre à l’utilisateur de choisir son outil pour implémenter du XML. Je recommande néanmoins l’utilisation de StAx pour toutes les raisons évoquées dans le tableau. Sources : http://smeric.developpez.com/java/cours/xml/sax/ http://cynober.developpez.com/tutoriel/java/xml/jdom/ http://ericreboisson.developpez.com/tutoriel/java/xml/xstream/#LV http://hikage.developpez.com/java/articles/xml/stax/ 21
ANNEXE II
Outils pour manipuler EXCEL en
java : POI vs JEXCEL
Ce dossier n’a pour objectif que d’exposer des résultats concrets visant à démontrer les différences de performances entre les 2 outils de manipulation des fichiers Excel en Java. Ce document n’a en aucun cas la prétention ni la volonté d’exposer en détail les outils en question.
Dans un premier temps, nous verrons brièvement quelques notions sur POI et JEXCEL, et enfin nous comparerons les performances de ces deux outils.
1. Presentation de POI
POI (Poor Obfuscation Implementation ou mise en œuvre de l'obfuscation pauvre) est un projet de Jakarta d'Apache Software Foundation, permettant de manipuler avec le langage Java divers types de fichiers créés par Microsoft Office. L'ensemble des noms de cette bibliothèque se moque des formats de fichiers de Microsoft Office. Cette nomenclature n'est pas mise en avant par la fondation Apache pour des raisons commerciales. POI permet de travailler avec des fichiers Excel et Word. Il est constitué de plusieurs composants : POIFS (Poor Obfuscation Implementation File System ou système de fichier de POI) : Lien entre objets OLE2 et java. HSSF (Horrible SpreadSheet Format ou Format horrible de feuilles de calcul) : permet de travailler avec des fichiers excel (XLS) en écriture et lecture. HWPF (Horrible Word Processor Format ou Format horrible de traitement de texte) : permet de travailler avec des fichiers word en écriture et lecture.
HPSF (Horrible Slide Layout Format ou Format horrible de présentation) : permet de faire un lien avec les propriétés des OLE2 et Java.
2. Présentation de JEXCEL
JEXCEL permet aux développeurs Java de lire les feuilles de calcul Excel et de générer dynamiquement des feuilles de calcul Excel. En outre, il contient un mécanisme qui permet aux applications java de lire des données dans une feuille de calcul, de modifier certaines cellules et d’enregistrer la nouvelle feuille de calcul. Inconvénient principal : JEXCEL ne génère pas de graphiques ou macro informations.
3. Comparaison des performances
Nous allons ici comparer deux codes réalisant le même travail. On va comparer les vitesses de construction des fichiers de sortie : vitesse de création du document en mémoire et vitesse d’écriture du document sur le disque. On construira une page Excel contenant les mêmes données, l’une générée avec JEXCEL et la seconde avec POI. Ce code consiste en l’écriture du nombre Pi et «Hello world! » successivement 35 fois chacun sur 8000 lignes. 23Code JEXCEL :
private void startGenerate(String fileName) {
WritableWorkbook workbook = null; WritableSheet sheet = null;
double timeStartGenerate = 0; double timeEndGenerate = 0; double gapGenerate = 0; double timeStartWrite = 0; double timeEndWrite = 0; double gapWrite = 0; timeStartGenerate = System.currentTimeMillis(); try {
workbook = Workbook.createWorkbook(new File(fileName)); sheet = workbook.createSheet("First Sheet", 0);
for (int idRow = 0; idRow < 8000; idRow++) {
for (int idCol = 0; idCol < 70; idCol = idCol + 2) { WritableFont arial10font = new WritableFont(WritableFont.ARIAL, 10); WritableCellFormat arial10format = new WritableCellFormat (arial10font); WritableFont arial10font2 = new WritableFont(WritableFont.ARIAL, 15); WritableCellFormat arial15format = new WritableCellFormat
(arial10font2);
jxl.write.Number number = new jxl.write.Number(idCol, idRow, 3.1459, arial10format);
Label label = new Label(idCol+1, idRow, "Hello world!", arial15format); sheet.addCell(label); sheet.addCell(number); } } } catch (RowsExceededException e) {
System.out.println("RowsExceededException : " + fileName); System.out.println(e);
}
catch (WriteException e) {
System.out.println("WriteException : " + fileName); System.out.println(e);
}
catch (IOException e) {
System.out.println("IOException : " + fileName); System.out.println(e);
}
timeEndGenerate = System.currentTimeMillis(); gapGenerate = timeEndGenerate - timeStartGenerate; timeStartWrite = System.currentTimeMillis();
try {
workbook.write(); workbook.close(); }
catch (IOException e) {
System.out.println("IOException : " + fileName); System.out.println(e);
}
catch (WriteException e) {
System.out.println("WriteException : " + fileName); System.out.println(e);
}
timeEndWrite = System.currentTimeMillis(); gapWrite = timeEndWrite - timeStartWrite;
System.out.println ("====> Durée génération JExcel : " + gapGenerate); System.out.println ("====> Durée Ecriture JExcel : " + gapWrite); }
Code POI :
private void startGenerate(String fileName) {
HSSFWorkbook wb = new HSSFWorkbook();
HSSFSheet sheet = wb.createSheet("new sheet");
double timeStartGenerate = 0; double timeEndGenerate = 0; double gapGenerate = 0; double timeStartWrite = 0; double timeEndWrite = 0; double gapWrite = 0; timeStartGenerate = System.currentTimeMillis();
for (int idRow = 0; idRow < 8000; idRow ++) {
for (int idCol = 0; idCol < 70; idCol = idCol+2) { HSSFRow row = sheet.createRow((short)idRow);
HSSFFont font1 = wb.createFont();
font1.setFontHeightInPoints((short)10); font1.setFontName("Arial");
HSSFCellStyle style1 = wb.createCellStyle(); style1.setFont(font1);
HSSFFont font2 = wb.createFont();
font2.setFontHeightInPoints((short)15); font2.setFontName("Arial");
HSSFCellStyle style2 = wb.createCellStyle(); style2.setFont(font2);
HSSFCell cell1 = row.createCell((short)idCol); cell1.setCellValue(3.1459);
HSSFCell cell2 = row.createCell((short)(idCol+1)); cell2.setCellValue("Hello world!");
cell1.setCellStyle(style1); cell2.setCellStyle(style2); } } 25
timeEndGenerate = System.currentTimeMillis(); gapGenerate = timeEndGenerate - timeStartGenerate; timeStartWrite = System.currentTimeMillis();
try {
FileOutputStream fileOut = new FileOutputStream(fileName); wb.write(fileOut);
fileOut.close(); }
catch (IOException e) {
System.out.println("IOException : " + fileName); System.out.println(e);
}
timeEndWrite = System.currentTimeMillis(); gapWrite = timeEndWrite - timeStartWrite;
System.out.println ("====> Durée génération POI : " + gapGenerate); System.out.println ("====> Durée Ecriture POI : " + gapWrite); } D’une manière générale, le code est relativement plus simple à implémenter sous JEXCEL. L’écriture dans les cellules et la mise en forme sont plus faciles à réaliser que sous POI même si ce dernier n’est pas non plus si complexe que ça. En termes de performances : Durée génération = durée de construction du document en mémoire Durée Ecriture = durée de l’écriture sur le Disque Dur POI
====> Durée génération POI : 450918.0 ====> Durée Ecriture POI : 1295.0 ====> Durée totale POI : 452309.0
JExcel
====> Durée génération JExcel : 2616.0 ====> Durée Ecriture JExcel : 3212.0 ====> Durée totale JExcel : 5829.0
On observe donc que JEXCEL est nettement plus rapide que POI. De plus, cette librairie étant moins complexe à utiliser que POI, je conseillerais donc d’utiliser cette API.
Sources :
http://www.developpez.net/forums/d254949/java/general-java/apis/documents/conso-memoire-poi-vs-jexcel/ http://dictionnaire.sensagent.com/Jakarta%20POI/fr-fr/