Régularisation spatiale de représentations distribuées de mots
Texte intégral
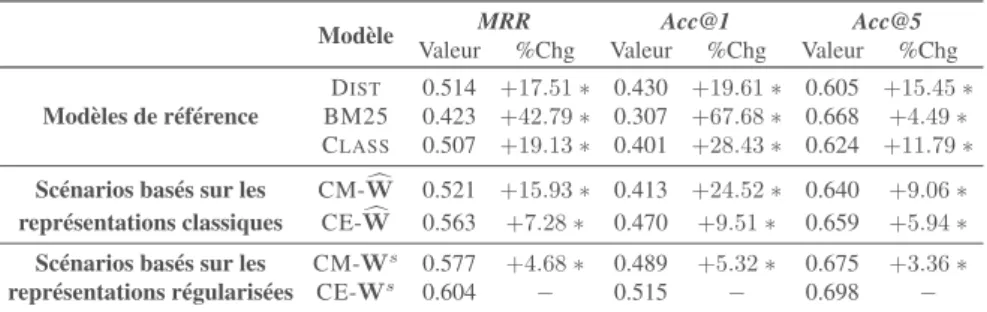
Figure

Documents relatifs
On peut remarquer en comparant les taux d’avancement des réactions pour un même acide à différentes concentrations que plus l’acide est diluée, plus sa dissociation est
Pour écarter cette possibilité et inciter les enfants à se focaliser sur la face plus sombre du dominant (il est égoïste), la tâche proposée dans la seconde expérience (Figure 2)
François-René Julliard fait remarquer que cette question est ancienne dans la littérature noire américaine : dans sa critique du livre Native Son de
Si l’Espagne est le pays où les travaux sur l’ancienne colonie sont les plus nombreux et connaissent un réel développement, il convient tout de même de remarquer que
Dans Et pour suite, tous les fragments sont de longueur équivalente, plus ou moins une pleine page, alors que dans Petites primeurs, l'étendue des textes est variable: d'une
Exemple : Dans les mots cités précédemment le radical est VILL, le mot le plus simple que l’on peut écrire à partir de ce radical est « ville ».. Consigne : Sur
savoir que la célérité est plus élevée dans un solide, que dans un liquide, elle même plus élevée que dans un gaz savoir que deux ondes peuvent se croiser sans se perturber.
Le diaphragme ne fait que limiter la quantité de lumière qui entre dans l’appareil photo, lorsqu’on le ferme, l’image est plus sombre et lorsqu’on l’ouvre elle est
