Incertitudes
Texte intégral
Figure
![Figure 3 – Exemples, tirés de [2], de fonctions de répartition d’une variable aléatoire continue (à gauche) et discrète (à droite).](https://thumb-eu.123doks.com/thumbv2/123doknet/2258439.19436/7.892.163.741.660.860/figure-exemples-fonctions-repartition-variable-aleatoire-continue-discrete.webp)
Documents relatifs
Le cas le plus simple est celui d’un couple de variables aléatoires que l’on va considérer comme une variable aléatoire mais à valeurs dans R 2.. Dans ce cas, on n’étudie
En particulier, dans le cas où la variable aléatoire peut prendre toute valeur réelle (son ensemble de définition contient un intervalle de R), on parle de variable aléatoire
Moyenne qui résulterait d’un nombre infini de mesurages du même mesurande, effectués dans les conditions de répétabilité, moins la valeur conventionnellement vraie du
Lorsque toutes les issues d’une expérience aléatoire ont même probabilité, on dit qu’il y a équiprobabilité ou que la loi de probabilité est équirépartie.. Dans ce cas, la
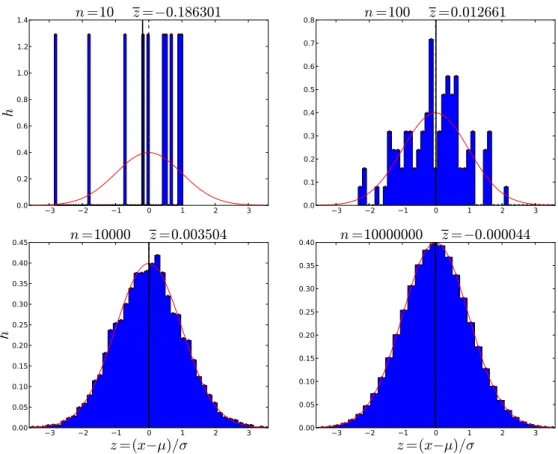
Montrer que, si une suite de variables aléatoires (X n ) converge presque sûre- ment vers une variable aléatoire X , alors elle converge en
Elle résulte de diverses erreurs qui peuvent être classées en deux grandes catégories: les erreurs systématiques, qui se produisent toujours dans le même sens et les
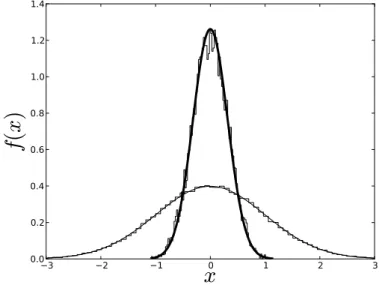
Dans le cas d'une variable aléatoire continue qui prend pour valeurs les réels d'un intervalle I, sa loi de probabilité n'est pas associée à la probabilité de chacune de ses
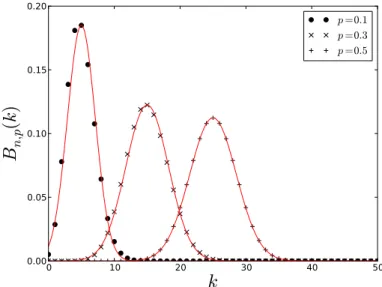
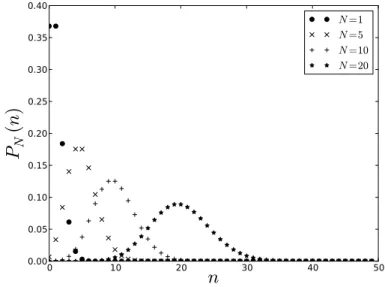
Dans les cas de lois de probabilité discrètes comme la loi binomiale, chaque expérience aléatoire conduit à un univers fini et chaque variable aléatoire prend un nombre fini
