HAL Id: dumas-01835533
https://dumas.ccsd.cnrs.fr/dumas-01835533
Submitted on 11 Jul 2018HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
Étude des étapes de création d’une visite virtuelle :
application au projet LiDARRAS
Damien Houvet
To cite this version:
Damien Houvet. Étude des étapes de création d’une visite virtuelle : application au projet LiDARRAS. Sciences de l’ingénieur [physics]. 2017. �dumas-01835533�
CONSERVATOIRE NATIONAL DES ARTS ET METIERS ECOLE SUPERIEURE DES GEOMETRES ET TOPOGRAPHES
___________________
MEMOIRE
présenté en vue d'obtenir le DIPLOME D'INGENIEUR CNAMSPECIALITE : Géomètre et Topographe
par
Damien HOUVET
___________________
Etude des étapes de création d’une visite virtuelle :
application au projet LiDARRAS
Soutenu le 05 juillet 2017 _________________
JURY
PRESIDENT : M. José CALI
MAITRE DE STAGE : M. Pascal SIRGUEY
2
Remerciements
En guise de préambule de ce mémoire, j’adresserais simplement ma gratitude envers tous celles et ceux qui auront marqué sa réalisation. Cette dernière étape du cursus à l’ESGT marquant la fin de ma scolarité, j’ajouterais également quelques mots de remerciements à mon entourage.
Tout d’abord, je tiens à remercier les membres du projet LiDARRAS au sein duquel j’ai eu le plaisir d’être introduit depuis la phase d’acquisition des données de l’été 2016, à savoir Christophe CHARLET1, Ghyslain FERRE1, Richard HEMI2, Christopher PAGE2, Elisabeth SIMONETTO1 et Pascal SIRGUEY2 (1- ESGT – Laboratoire Géomatique et Foncier ; 2- Université d’Otago – School of Surveying).
Je remercie particulièrement mon maître de stage Pascal SIRGUEY, professeur à l’université d’Otago, de m’avoir proposé de poursuivre l’aventure du projet LiDARRAS à Dunedin, en Nouvelle-Zélande, et donc participer à la création de la visite virtuelle escomptée. Je le remercie pour son aide précieuse dans les démarches, pour son accueil chaleureux et pour avoir encadré mon travail de fin d’études. Je remercie naturellement Elisabeth SIMONETTO, mon professeur référent, pour ses conseils avisés et le suivi de mon travail pendant ces cinq mois. Je remercie Richard HEMI, professeur à l’université d’Otago, pour m’avoir gracieusement hébergé les premiers jours de mon arrivée à Dunedin. J’adresse mes remerciements à mon ami de l’Université d’Otago, Chris, avec qui j’ai partagé bon nombre d’aventures en France comme en Nouvelle-Zélande, à travers le projet LiDARRAS. Par ailleurs, je remercie les personnes qui ont soutenu, de près ou de loin, ce projet.
De plus, je souhaite exprimer toute ma gratitude à Christina HULBE, responsable du département « Surveying » de l’Université d’Otago, pour m’avoir permis de réaliser mon travail de fin d’études au sein de cette structure et à Hélène MASSOT qui m’a beaucoup aidé pour l’aspect administratif de ce travail de fin d’études.
Enfin, car il est important d’être soutenu dans le cadre de sa poursuite d’études, je souhaite adresser une pensée distinguée à ma chère infirmière Angélique, à mon canard d’eau préféré Moisés ainsi qu’à mon idole sevranaise Jonathan. Une pensée particulière est évidemment adressée à ma famille. De même, je remercie mes collègues de la salle T0 pour leur bonne humeur quotidienne tout au long de ce mois passé en leur compagnie.
Glossaire
3D Trois DimensionsASCII American Standard Code for Information Interchange CC50 Conique Conforme zone 50
CNAM Conservatoire National des Arts et Métiers ESGT Ecole Supérieure des Géomètres et Topographes FIG Fédération Internationale des Géomètres
GeF Géomatique et Foncier
GNSS Global Navigation Satellite System GPU Graphics Processing Unit
HDR High Dynamic Range
IGN Institut Géographique National
ISTI Istituto di Scienza e Tecnologie dell Informazione LIDAR LIght Detection And Ranging
NDDI Normalized Difference Density Index NDVI Normalized Difference Vegetation Index RAM Random Access Memory
RGB Red Green Blue
RGF93 Réseau Géodésique Français RVB Rouge Vert Bleu
4
Table des matières
Remerciements ... 2
Glossaire ... 3
Table des matières ... 4
Introduction ... 6
Le cahier des charges et les enjeux ... 9
I Etat de l’art ... 10
I.1 LE NUAGE DE POINTS ... 10
I.2 LE SOUS-ECHANTILLONNAGE ... 12
I.3 LA MODELISATION ... 15
I.4 LA TEXTURATION ET LA COLORISATION ... 16
I.5 LA VISITE VIRTUELLE ... 19
II De l’échantillonnage à la texturation/colorisation ... 21
II.1 PRESENTATION DE LA METHODE ... 22
II.1.1 LES HYPOTHESES ... 22
II.1.2 LES LOGICIELS UTILISES ... 24
II.1.2.1 CLOUDCOMPARE ... 24
II.1.2.2 MESHLAB ... 25
II.1.3 ELABORATION DES CRITERES ... 25
II.2 L’ECHANTILLONNAGE ... 28
II.2.1 LES METHODES REGULIERES ... 28
II.2.1.1 ETUDE DE LA REGULARITE D’UN NUAGE ... 28
II.2.1.2 CHOIX DES NUAGES POUR LES TESTS ... 30
II.2.2 LES METHODES IRREGULIERES ... 31
II.2.2.1 ETUDE DE LA COURBURE D’UN NUAGE ... 32
II.2.2.2 CHOIX DE LA METHODE DE DECIMATION ... 33
II.2.2.3 DEUX OPTIONS DE TRAITEMENT ... 34
II.2.3 L’ANALYSE DES CRITERES ... 35
II.3 LE MAILLAGE... 39
II.3.1 LE TYPE DE MAILLAGE CREE ... 39
II.3.1.1 LE CHOIX DE LA METHODE ... 39
II.3.1.2 LE CALCUL DES NORMALES ... 40
II.3.1.3 LE CHOIX DU NIVEAU D’OCTREE ... 41
II.3.2 LES ANALYSES COMPLEMENTAIRES A L’ECHANTILLONNAGE ... 43
II.3.3 L’ANALYSE DES CRITERES ... 46
II.3.4 CONCLUSION ... 49
II.4 LA TEXTURATION ... 49
II.4.1 LA METHODE ... 49
II.4.2 L’ANALYSE DES CRITERES ... 50
II.4.3 L’ANALYSE QUALITATIVE ... 50
II.4.4 CONCLUSION DE L’ETUDE ... 51
Conclusion ... 52
5
Table des annexes ... 57
Annexe 1 Bref historique ... 58
Annexe 2 Le projet LiDARRAS ... 60
Annexe 3 Calcul de la métrique densité : le NDDI ... 65
Annexe 4 Programme de calcul des angles de chaque faces voisines ... 72
Annexe 5 Les principaux outils de Meshlab v 1.3.3 ... 77
Annexe 6 Le rendu vidéo sous Bentley ... 80
Annexe 7 Questionnaire pour l’analyse qualitative ... 82
Annexe 8 Résultats détaillés de l’analyse qualitative ... 83
Annexe 9 Exemples de géométries de modèles... 84
Annexe 10 Exemples de rendus colorisés ou texturés ... 85
Liste des figures ... 86
6
Introduction
L’outil informatique s’est très largement développé ces dernières années. Dans un monde où l’information doit être transmise toujours plus vite, le virtuel a pris beaucoup d’ampleur. Ainsi, l’information géographique n’a pas échappée à cette forte avancée en la matière et il est désormais possible de découvrir et visualiser le monde en trois dimensions depuis un ordinateur. Les méthodes de création de rendus tridimensionnels sont multiples et elles existent à plusieurs échelles. Cependant, l’objectif premier est souvent le même : permettre à l’utilisateur de s’immerger virtuellement dans un lieu à distance et ainsi avoir un aperçu plus ou moins réaliste de l’endroit.
Rapidement, les applications se sont multipliées et le domaine de la visite virtuelle est, depuis, en pleine expansion, notamment grâce à l’essor et à la démocratisation des technologies d’acquisition. Il est de plus en plus fréquent de trouver un aperçu des lieux sous forme d’une immersion virtuelle sur des sites internet de musées, monuments nationaux ou même de magasins. L’utilisateur est alors irrésistiblement appelé à découvrir la configuration des lieux en se déplaçant de manière interactive.
Plusieurs techniques permettent de créer une visite virtuelle à l’échelon local. L’assemblage de photographies panoramiques sur 360 degrés est parfois choisi pour son coût abordable. Plus onéreux, le Lidar terrestre (par utilisation d’un scanner laser 3D) peut également subvenir à ce besoin en étant, ou non, couplé à l’utilisation de photographies. Le résultat est alors indéniablement plus réaliste puisqu’il offre une impression de relief. Le scanner laser 3D permet d’acquérir une multitude de points en peu de temps pour former un nuage de points très dense. Ainsi, l’appareil est capable de modéliser finement l’espace environnant en trois dimensions grâce à des mesures laser de distances et à des mesures d’angles réalisées à hauteur d’un million de points acquis par seconde. En sortie, l’utilisateur possède alors un nuage de points très dense, avec un pas de balayage pouvant être de l’ordre d’un point tous les millimètres. L’instrument est dorénavant utilisé dans de nombreux domaines, aussi variés soient-ils (architecture, archéologie, industrie, police scientifique, …) car les représentations en trois dimensions sont très prisées de par leur réalisme.
Le projet LiDARRAS, émanant de l’Université d’Otago en Nouvelle-Zélande et auquel l’ESGT participe, s’inscrit dans le développement de ce type de ressources puisqu’il vise à modéliser les carrières souterraines d’Arras (62) en trois dimensions. L’objectif est simple,
7
partager et promouvoir les richesses patrimoniales de ces cavités marquées par l’Histoire franco-néo-zélandaise1 ainsi qu’offrir la possibilité à divers professionnels d’étudier la configuration des lieux sans y descendre. Historiquement, ces galeries ont été façonnées par des soldats Néo-Zélandais pendant la première guerre mondiale lors de la préparation de l’offensive de la bataille d’Arras le 9 avril 1917. Etant donné que seule une petite partie de cet immense réseau souterrain est ouverte à la visite du public et donc sécurisée, le défi repose alors sur la volonté de figer l’ensemble des souterrains dans le temps afin d’en sauvegarder la mémoire.
Dans le cadre de ce travail, c’est l’utilisation de la technologie Lidar qui a été mise en œuvre. En effet, au cours de l’été 2016 a eu lieu une vague d’acquisition de données au sein des carrières d’Arras2. Plusieurs dizaines de milliards de points ont été acquis représentant au total un poids total de données colossal. C’est donc dans une perspective d’avenir que s’inscrit ce travail puisque la création d’une visite virtuelle avec ce nombre très important de points implique de mettre en place un protocole extrêmement bien défini. Ce protocole, basé sur maints tests et sur de multiples analyses, doit permettre de traiter l’entièreté des données tout en proposant à la fois un rendu réaliste et allégé pour une publication sur le net. C’est à partir de ce nuage de points géoréférencé et colorisé que débutent les analyses faisant l’objet de ce travail de recherche. Le processus de création de la visite virtuelle englobe plusieurs étapes importantes. Tout d'abord, il est nécessaire, sinon indispensable, de procéder à un sous-échantillonnage de la quantité considérable de points. Cette opération permet d’obtenir un nuage, avec une densité moindre certes, mais surtout largement réduit en poids et donc plus facilement manipulable. Dans le cadre d’une visite virtuelle au travers d’une représentation surfacique, la question de la création d’un modèle 3D proche du nuage de points se pose. Ce cas-là nécessite une étape de texturation ou colorisation des surfaces créées, c’est-à-dire l’application des couleurs issues des photographies. Ainsi, deux échantillonnages différents doivent donc être choisis en fonction des deux méthodes de visite virtuelle. Enfin, il s’agit d’étudier la possibilité d’intégrer ce modèle texturé et ce nuage de points dans un système d’immersion afin de proposer le rendu final de la visite virtuelle. Là encore, de multiples possibilités existent, comme limiter ou non les déplacements au sein du
1 Cf. annexe no1 pour un bref historique
8
modèle en créant une zone autorisée de déplacement ou en restreignant la visite à quelques points de vue bien positionnés.
Pour répondre à l’objectif de gestion de données lourdes dans le cadre de la création d’une visite virtuelle, il ne s’agit donc pas seulement d’étudier les différentes phases séparément mais également de chercher à connecter au mieux chacune d’elles. Il est intéressant de remarquer que la réalisation de toutes ces étapes avec autant de données est plutôt rare et donc que la pertinence des solutions apportées peut s’avérer très subjective à ce projet en particulier. De plus, ce projet fait le lien entre deux domaines très différents : celui de la topographie et celui de la modélisation virtuelle. D’une part, les géomètres souhaitent représenter l’environnement existant le plus fidèlement possible avec des mesures de haute précision tandis que, d’autre part, les infographistes cherchent à reproduire la réalité dans un environnement virtuel tel qu’un jeu vidéo. Les approches ne sont donc pas les mêmes. La problématique choisie est la suivante :
Quelles sont les méthodes à mettre en œuvre pour obtenir le protocole optimal de création des visites virtuelles finales, basées sur le nuage de points ou sur un modèle surfacique ?
Différentes questions découlent de cette problématique principale :
Quels sont les critères qualifiant cette optimalité ?
Quel sous-échantillonnage maximal peut-on proposer dans les deux cas ? Quel type de modèle est le plus adapté ?
Comment appliquer la couleur des photographies sur le modèle en tenant compte du poids que cela ajoute aux données ?
La démarche scientifique proposée s’articule alors autour du plan suivant. Tout d’abord, après une brève mise en contexte, un examen attentif de l’état de l’art va permettre de prendre connaissance de l’avancée des recherches en la matière et de formuler des hypothèses quant aux étapes de traitement. Puis, afin de réussir à optimiser le poids des données tout en conservant un réalisme correct, plusieurs critères comparatifs seront élaborés. Enfin, le développement d’une analyse des différentes étapes va permettre de répondre à la problématique de départ en se basant sur ces critères.
9
Le cahier des charges et les enjeux
L’enjeu de la valorisation des deux premières phases du projet
L’immense masse de données, telle qu’elle est issue de la deuxième phase du projet est peu exploitable ainsi. Le but de ce travail de recherche est donc de permettre une valorisation des nuages de points notamment grâce à la diffusion d’une visite virtuelle. La valorisation souhaitée peut se faire par une diffusion sur internet ou sur une plateforme de jeux vidéo qui puisse être accessible par un grand nombre de personnes. L’aspect interactivité est également recherché. Le problème actuel de ces données est qu’elles sont trop volumineuses pour être supportées par un serveur. En effet, pour rendre attractive une visite sur le net, il semble logique que le chargement ne dépasse pas plus de 1 ou 2 minutes suivant la capacité de l’ordinateur de l’utilisateur et de sa connexion.
Il s’agit alors de réduire leur poids, par exemple en allégeant le nombre de points du modèle ou en compressant les photographies lors de la texturation. Evidemment, jouer sur ces deux paramètres modifie la qualité du rendu. La troisième phase du projet consiste donc principalement à trouver une méthode de traitement offrant juste milieu entre un poids de données convenable et une qualité de rendu acceptable voire très peu altérée.
Les détails des deux approches pour la création de la visite virtuelle
Il existe plus ou moins deux approches pour réaliser cette visite virtuelle, au sein du nuage de points ou à travers la création d’une surface. En effet, le rendu du nuage de points seul étant très bon, il est possible d’agir au sein de ce nuage à l’aide de vidéos ou de « streaming » de nuage de points en ligne, grâce au développement de logiciels comme Itowns23 notamment. Mais le but premier reste tout de même de réussir à supprimer un nombre de points suffisant, et donc alléger le modèle, pour créer une représentation surfacique régulière qui puisse donner aux carrières un aspect très réaliste après texturation ou colorisation des faces, mais cette fois ci, imperméable et avec une sensation de relief. C’est cette approche qui est privilégiée dans la partie « démarche scientifique » puisque la création d’une visite virtuelle au travers du nuage de points peut être effectuée directement sans nécessiter de traitement supplémentaire4.
3 https://github.com/iTowns/itowns2
10
I Etat de l’art
I.1 Le nuage de points
Pour bien comprendre l’étape de modélisation et pouvoir en étudier les résultats avec un œil critique, il est nécessaire de bien connaitre les caractéristiques d’un nuage de points, et plus particulièrement du nuage échantillonné en entrée du processus de modélisation.
Un point est une entité géométrique définie par trois cordonnées, X, Y, et Z, déterminant une position exacte dans l’espace. Un nuage de points est alors un ensemble plus ou moins dense de données tridimensionnelles représentant la surface d’un objet5. (LANDES et al., 2011) indiquent que dans ce cas, c’est le type de résultats obtenu à l’issue d’un relevé lasergrammétrique après que l’appareil ait rayonné tout son environnement. Un nuage de points est donc composé uniquement de points distincts et sans aucun lien entre eux. A ces points sont parfois rattachés des valeurs d’intensité (quantité de lumière reçue) et de couleurs RVB6 comme l’expliquent (LANDES et al., 2011). Par ailleurs, une géométrie compacte peut être créée en établissant des liens entre les points ou en s’aidant de l’allure générale du nuage pour créer une surface. Toutefois, avant d’entrer dans cette étape de modélisation, il est possible de s’intéresser à la forme décrite et aux caractéristiques du nuage de points. On en distingue principalement trois : la densité, la rugosité et la courbure7.
La densité représente le nombre de points présents par unité de surface. (LANDES et al., 2011) fournissent la définition suivante. Un nuage ayant une densité de X millimètres possède environ un point tous les X millimètres représentant l’objet mesuré. Plus la densité est élevée, plus l’objet mesuré est représenté finement. Le pas de balayage ainsi que la distance entre le scanner et l’objet déterminent cette densité. La densité est une caractéristique importante puisqu’elle est directement liée au nombre de points du nuage. C’est d’ailleurs en jouant sur ce nombre de points, et donc sur cette densité, qu’il est possible de réduire le poids des données. La densité est définie par la formule suivante dans (PAULY et al., 2002) : d = k/r2 avec k le nombre de voisins contenus dans une sphère de rayon r.
5 D’après la définition d’un nuage de points (géométrie) de wikipedia.org
6 Codage de la couleur à l’aide de trois composantes Rouge, Vert, Bleu (ou RGB en anglais) 7 D’après les outils définis dans le logiciel CloudCompare
11
Une surface mesurée n’est jamais parfaitement lisse. La rugosité du nuage représente les irrégularités, aussi fines soient elles, créant ce défaut de lisseur de la surface. Elle est donc exprimée pour chaque point comme l’écart vertical du point par rapport au meilleur plan de la surface calculé par moindres carrés8. Dans le cas de l’acquisition d’un nuage de points, de nombreux facteurs altèrent les mesures d’un scanner laser 3D et il n’est donc pas extraordinaire que les points possèdent un léger bruit d’après (AIT MENSOUR, 2015). De plus, sur des surfaces rocheuses notamment, les altérités présentes sur ces surfaces s’ajoutent au bruit de mesure pour former la rugosité. Cette rugosité du nuage peut suffire à poser problème lors de la modélisation, surtout dans le cas d’un maillage. En effet, si tous les points d’un nuage mesuré sont utilisés pour représenter une surface plane, l’apparence du modèle sera très rugueuse du fait de la présence de points s’éloignant de la surface théorique. La courbure d’un nuage de points correspond au caractère incurvé de l’objet9. Etant donné qu’un nuage de points représente la surface d’un objet mesuré, il est évident que les caractéristiques géométriques de l’objet seront reproduites sur le nuage. Ainsi, les courbures présentes sur l’objet sont modélisées par le nuage. Il est intéressant de prendre en compte ce paramètre puisqu’il établit un lien direct entre la forme de l’objet et la densité du nuage de points d’après (AIT MENSOUR, 2015). En effet, pour représenter correctement un objet incurvé, le traitement va nécessiter plus de points que pour un même objet plat. La courbure peut alors être estimée localement pour aider l’algorithme d’échantillonnage à retirer plus de points sur les parties planes et a en conserver davantage sur les parties incurvées afin de mieux les représenter. Elle s’exprime pour chaque point en calculant variation locale de surface des points du voisinage par rapport au plan tangent en ce point. Le voisinage et sa taille influence donc beaucoup ce calcul car si les points ne sont pas assez nombreux dans le voisinage, la valeur de la courbure ne sera pas représentative comme l’expliquent (PAULY et al., 2002). D’après (BENHABILES et al., 2012), des méthodes existent alors pour déterminer les k plus proches voisins utiles à une détermination correcte de la courbure, notamment la méthode kd-tree.
En outre, un nuage de points peut permettre le calcul de normales. Les normales sont alors attribuées à chaque point en fonction de son voisinage. Leur estimation repose donc beaucoup sur les caractéristiques du voisinage et notamment sur les valeurs locales de
8 D’après le wiki de CloudCompare (http://www.cloudcompare.org/doc/wiki/) et le site mesurez.com 9 D’après le wiki de CloudCompare (http://www.cloudcompare.org/doc/wiki/)
12
rugosité et de densité d’après (PAULY et al.). En effet, plus un nuage de points est dense, plus les normales sont moyennées et correctement estimées. De même, (AIT MENSOUR, 2015) explique que si de la rugosité est présente, cela influe sur la qualité de la détermination de la normale. Les normales constituent un premier pas vers la représentation surfacique puisqu’elles définissent des liens entre chaque point. En outre, elles peuvent permettre le calcul de la courbure d’un nuage. Il est important de noter que ces normales ont une orientation et que cette orientation doit être la même pour tous les points de l’objet sous peine d’aboutir à la création de défauts lors de la représentation surfacique10.
Le découpage en octree est un moyen de diviser le nuage de points total en plusieurs espaces cubiques équivalents en taille11. La méthode permet la création de 8n cubes, avec n le niveau d’octree et elle divise donc le nuage de points de manière récursive en une multitude de cubes. Cela permet de fixer un niveau de détails plus ou moins fin lors des études menées. Ces niveaux d’octree correspondent donc à différentes tailles de cubes.
Figure 1 : Découpage successif en octree d’un cube (sans découpage, niveau 1 et niveau 2)12
Comprendre toutes les caractéristiques d’un nuage de points est essentiel car la phase de sous-échantillonnage repose en grande partie sur celles-ci. Il s’agit en effet de trouver la meilleure solution permettant de conserver la géométrie des données et un grand nombre d’entre elles se basent sur ces caractéristiques.
I.2 Le sous-échantillonnage
Le sous-échantillonnage est une méthode de traitement d’un nuage de points consistant à retirer statistiquement ou géométriquement des points afin d’en alléger le poids et de préparer la phase de modélisation. C’est une phase déterminante pour la suite puisqu’elle permet de ne conserver qu’un certain nombre de points. Une simplification du nuage s’avère utile pour plusieurs raisons résumées par (PAULY et al., 2002). Cela permet d’atténuer la redondance des données, surtout aux endroits dépourvus de courbure. Il s’agit également de permettre la réalisation de la phase de modélisation dans de meilleures conditions et, même, éviter une phase de simplification du modèle par la suite. Egalement, cela permet de retirer
10 D’après le wiki de CloudCompare (http://www.cloudcompare.org/doc/wiki/) et (POUX, 2013) 11 D’après la définition d’un octree donnée par wikipedia.org
12 D’après l’Institut d’électronique et d’informatique GASPARD-MONGE. Page web visée : http://igm.univ-mlv.fr/~dr/XPOSE2013/spatial_indexes/page_structure.html
13
ou atténuer le bruit présent dans le nuage de points initial d’après (OLLIVIER, 2011). La sélection des meilleurs points est donc décisive pour pouvoir éliminer un maximum de données, tout en ne dégradant pas la géométrie du futur modèle, d’après (REMONDINO et al., 2003). Ainsi, lors de cette phase, la courbure locale du nuage de points joue un rôle important dans le choix de ces points et un grand nombre d’algorithme l’utilise.
(PAULY et al., 2002) expliquent l’enjeu de la simplification comme suit. Soit un nuage de points P représentant une surface S que l’on souhaite décimer au rang N. Il s’agit de trouver un nuage de points P’ représentant une surface S’ telle que la distance epsilon entre S et S’ soit la plus petite possible. Le choix de ces points se fait en retenant localement le meilleur point d’une surface donnée.
Depuis une dizaine d’années, de nombreuses méthodes ont été créées pour alléger des nuages de points. Bon nombre d’algorithmes reprennent les méthodes de simplification des maillages, pour lesquelles les recherches ont été bien plus précoces d’après (SONG et al., 2009). Aujourd’hui, il existe une multitude de méthodes de calcul ayant chacune leurs spécificités puisque chaque algorithme répond à un objectif de modélisation différent. Dans tous les cas, effectuer la simplification sur le nuage même plutôt que sur le modèle offre un certain nombre d’avantages décrits par (PAULY et al., 2002). Cela permet principalement d’obtenir une réduction de la rugosité, d’améliorer grandement le temps de traitement lors de la modélisation voire même d’éviter la phase de simplification du modèle créé. Il existe plusieurs méthodes de simplification de nuage de points. (BENHABILES et al, 2012) les classent selon trois catégories : les méthodes de « clustering » (regroupement), les méthodes « coarse-to-fine » (grossier au fin) et les méthodes itératives, dont voici les définitions données par (PAULY et al., 2002) et (BENHABILES et al, 2012)).
Le « clustering » permet d’étudier le nuage de points en effectuant des regroupements de plusieurs points à l’aide d’un critère spécifique. Puis, chaque regroupement est sous-échantillonné pour n’obtenir qu’un seul point représentatif du groupe, potentiellement son barycentre. Généralement, la courbure influence grandement la création des groupes mais ce découpage peut se faire plus simplement avec une méthode de division en octree. De nombreux algorithmes existent et ont tous une approche différente pour créer ces groupes. En général, ce procédé est rapide et préserve correctement la forme de l’objet. Toutefois, le nouveau nuage de points peut posséder une erreur quadratique importante par rapport à l’ancien, ce qui signifie qu’il en est quelque peu éloigné.
14
Le « coarse-to-fine » traite en premier lieu une petite partie aléatoire du nuage. Cette approche permet de calculer une fonction de distance entre points à l’aide de la partie étudiée et d’un diagramme de Voronoi 3D. La fonction sert ensuite à effectuer la simplification sur tout le nuage. Cette méthode permet de conserver une densité de points bien plus élevée aux endroits de fortes courbures et de retirer un maximum de points dans les régions planes, comme le précisent (BENHABILES et al, 2012). C’est une méthode utilisant donc beaucoup le paramètre de la courbure. L’inconvénient majeur réside dans le fait que la simplification dépende beaucoup des caractéristiques du sous-ensemble choisi par l’algorithme.
Les méthodes itératives, comme leur nom l’indique, utilisent un processus itératif pour réduire le nombre de points par attribution d’un poids aux points représentant leur importance. Les points ayant l’importance la plus faible sont éliminés jusqu’à ce que le niveau de simplification souhaité soit atteint. Si ce procédé conserve un grand nombre de caractéristiques essentielles du nuage, il n’en réside pas moins qu’il s’avère très couteux en temps de traitement et en mémoire puisqu’il est basé sur des mises à jour en continu après chaque itération. La qualification de l’importance d’un point dépend de sa position et de son proche voisinage car (SONG et al., 2009) indiquent qu’une comparaison entre points est nécessaire pour marquer l’importance de tel ou tel point.
Pour chacune de ces méthodes, un grand nombre d’algorithmes ont été développés et cela offre la possibilité de créer différents types d’échantillonnages plus ou moins adaptés en fonction des caractéristiques des données en entrée. (PAULY et al., 2002) arguent que si la réduction est faite avec la bonne méthode, le nuage peut conserver toutes ses caractéristiques initiales. Il faut toutefois veiller à ne pas retirer trop de densité car, passé un certain seuil, cela est synonyme de perte de qualité lors de la création des surfaces. En théorie, un sous-échantillonnage ne doit se faire qu’une seule fois pour être plus efficace, c’est-à-dire à partir du nuage initial. Le choix de la meilleure méthode reste cependant largement dépendant de l’application que l’utilisateur souhaite faire du nuage de points. D’après (POUX, 2013), la méthode de Disk-Poisson est particulièrement efficace pour conserver les caractéristiques des points par exemple mais ce n’est qu’un simple exemple parmi tant d’autres. Il est donc intéressant de se pencher un peu plus sur les différences entre les méthodes existantes. D’après l’étude menée par (PAULY et al., 2002), lors de l’analyse de la distance entre le nuage de points initial et ceux issus des différents algorithmes, les méthodes de « clustering » testées fournissent une erreur moyenne assez forte alors que les deux autres méthodes sont
15
un peu plus efficaces. D’autre part, la distribution de la simplification obtenue après un « clustering » est intimement liée à celle du nuage de départ. Les autres méthodes tendent à répartir uniformément les points. En revanche, c’est cette méthode qui est la moins couteuse en temps et en mémoire.
I.3 La modélisation
La modélisation est la création d’un objet 3D d’un seul tenant. C’est donc une technique de représentation d’objets en trois dimensions. Dans le cas d’un nuage de points, les points étant tous indépendants et sans lien direct avec leur voisin, il s’agit alors de créer un modèle imperméable à l’aide des points du nuage. Il existe trois grandes catégories de modèle 3D décrites par (LANDES et al., 2011) :
Le modèle « reconstruit » correspond à un modèle souvent basé sur des mesures mais complété par des analyses de spécialistes. Le principal exemple est la reconstitution d’artefacts en archéologie pour modéliser l’objet dégradé tel qu’il eût été.
Le modèle « tel que saisi » est le modèle le plus fidèle à la réalité puisqu’il est directement et uniquement issu des mesures effectuées sur l’objet.
Le modèle « tel que construit » représente l’objet dans son idéal, par exemple un objet imaginé par un architecte. Il peut être élaboré à l’aide de mesures mais celles-ci seront approximées pour rendre les formes de l’objet les plus parfaites possibles. Egalement, (REMONDINO et al., 2003) résument que deux grandes approches différentes sont utilisées pour créer une surface à partir d’un nuage de points suivant les caractéristiques mathématiques.
Premièrement, la modélisation géométrique, volumique ou surfacique, offre la possibilité de décrire une forme grâce à la résolution d’équations mathématiques. En effet, à chaque forme géométrique correspond une équation qui la caractérise. Ainsi, l’utilisation de primitives géométriques (formes sphériques, cylindriques, planes, coniques ou encore pyramidales) permet de représenter le nuage de points de manière simple et approximée. L’algorithme de l’utilisateur tente d’abord de reconnaitre l’allure décrite par chaque partie du nuage de points et d’y faire correspondre une forme géométrique, puis établit des relations topologiques entre chacune d’elles. Ce type de modélisation rentre plutôt dans la catégorie des modèles « tels que construits » puisque l’esthétisme final du modèle est sobre et dénué d’artefacts. Les formes créées étant parfaites, cette méthode modélise très bien les objets simples mais elle n’est pas adaptée pour identifier des surfaces plus complexes. Son principal avantage réside en la réduction considérable du poids de la modélisation finale, uniquement paramétrée par
16
quelques équations. Une segmentation du nuage peut s’avérer utile avant de lancer la modélisation dans le but de séparer plusieurs parties du nuage et ainsi mieux reconnaitre les formes. (ALBY et al., 2012) décrivent bien cette méthode et expliquent que l’avantage du maillage sur celle-ci se situe principalement dans sa fidélité au nuage de points
Deuxièmement, la modélisation par maillage consiste à représenter une surface à l’aide de polygones reliant les entités d’un nuage de points entre elles pour constituer des faces13. D’après (GRUNBERG, 2006), chaque point se retrouve alors être un sommet de polygone. L’association de ces polygones, généralement des triangles, construit ainsi le maillage. Ces triangles forment un modèle appelé modèle maillé ou « mesh » en anglais. Le maillage se base donc sur la création de liens topologiques entre chaque point pour modéliser la surface de manière continue. Il est utilisé pour représenter des objets plus complexes et correspond donc à un modèle « tel que saisi ». Ses composantes fondamentales sont les sommets, les arrêtes et les faces14. Par ailleurs, les normales des faces, à différencier des normales des points, sont également très importantes car elles définissent leur orientation (notamment pour la texturation).
Composé de nombreuses faces, le maillage est beaucoup plus volumineux que la modélisation géométrique. Une réduction du nuage de points grâce à un sous-échantillonnage est toujours pratiquée avant la phase de modélisation. En effet, mailler un nuage de points très dense s’avère ne pas être plus précis du fait de la présence de rugosité. Toutefois, il existe plusieurs méthodes de simplification du maillage et également des méthodes hybrides. D’après (LIU et al., 2007), l’enjeu de cette phase est d’obtenir un modèle 3D simplifié, lissé, imperméable (c’est-à-dire ne possédant pas de trous) mais également une forme proche de celle de l’objet. Identifier les formes de l’objet est alors indispensable pour mieux les modéliser grâce au choix de la méthode la plus adaptée.
I.4 La texturation et la colorisation
La texturation et la colorisation sont des procédés visant à donner un aspect réaliste à un modèle 3D. Dans le cadre de ce travail, la colorisation des nuages de points ayant déjà eu lieu, seule l’application de la couleur sur les surfaces est étudiée. La colorisation consiste simplement en l’application de la couleur des points sur les faces. La texturation d’un modèle est plus complexe puisqu’elle peut se faire à l’aide de différents types de textures comme
13 (Florent POUX, 2013) livre un inventaire des principales méthodes de maillage 14 Cf. wiki du logiciel Blender : https://wiki.blender.org/
17
cela est décrit dans (LANDES et al., 2011). Il peut s’agir d’une texture quelconque ou d’une texture réaliste. La texture quelconque peut être donnée grâce à l’application sur le modèle d’une couleur, éventuellement associée à un ombrage, ou d’un motif provenant d’une bibliothèque de textures. De nos jours, elle n’est plus très utilisée car elle n’offre pas de rendu réaliste. A l’inverse, la texture réaliste consiste en l’utilisation de photographies et offre, elle, un rendu très proche de la réalité puisque photo-réaliste. Dans la suite, on ne s’intéresse donc qu’à l’utilisation de photographies pour texturer les faces d’un modèle ou à leur colorisation grâce à la couleur des points.
Deux procédés résumés par (HOPPE et al., 2009) peuvent être utilisés pour coloriser un modèle 3D. Premièrement, la texture peut être appliquée en reprenant la couleur des points utilisés lors de la création du modèle. Bon nombre de solutions ne le permettent pas car elles ne font pas le lien entre le modèle créé et la couleur des points. La couleur de chaque face est alors interpolée à l’aide des valeurs RVB des points utilisés pour sa création. Cette technique s’éloigne donc du rendu photo-réaliste mais offre un résultat très peu volumineux. Deuxièmement, l’application de la texture peut se faire directement à l’aide des photographies sur les faces du modèle, ce qui donne au modèle la qualité du rendu de la photographie mais également son poids.
La texturation est aussi un moyen de compenser la perte de données due au sous-échantillonnage d’après l’étude de (HOPPE et al., 2009). Dans le cas d’un maillage, donner la couleur aux faces augmente considérablement la taille des données mais permet de réduire son nombre de polygones d’un autre côté. L’application d’une texture sur un modèle requiert l’utilisation d’une technique spécifique nommée le « mapping ». En effet, les photographies sont des images en 2D que l’on souhaite appliquer sur un modèle tridimensionnel et pour qu’elles s’adaptent parfaitement aux différentes faces, il est nécessaire de les déformer. Il existe plusieurs méthodes.
L’« UV Mapping » est une méthode qui intervient à l’aide de transformations. Elle est très utilisée et peut être apparentée au problème des projections terrestres comme cela est expliqué par (POUX, 2013). Elle tire son nom du passage de coordonnées tridimensionnelles d’un point en des coordonnées planes « u » et « v » comprises entre 0 et 1 et inversement. Lors de cette transformation, il s’agit alors de prendre en compte les déformations engendrées par la mise à plat du modèle de la même manière que lorsqu’on représente la Terre avec des planisphères. Bien entendu, il existe alors un grand nombre de possibilités
18
possédant chacune leurs avantages et inconvénients mais le but reste de faire correspondre les coordonnées des sommets du maillage avec des points sur l’image. Comme l’explique Guillaume Gilet dans l’un de ses cours15, et à la manière de la classification des projections de la Terre, ces habillages peuvent être de forme plane, cylindrique, sphérique ou cubique (entre autres). Les déformations sont importantes avec cette méthode.
Figure 2 : Problématique de l’application d’une image 2D sur un objet en 3D16
Une autre méthode consiste en trouver mathématiquement « une représentation explicite de la projection », c’est la paramétrisation. Comme l’explique (POUX, 2013), cela consiste en la subdivision d’un objet en sous-groupes identifiables de par leurs caractéristiques et pour lesquels il est plus facile d’appliquer de mêmes paramètres. Le modèle est donc découpé et mis à plat. Cette méthode n’est pas efficace pour des objets complexes. Il existe un grand nombre d’autres méthodes recensées mais celles-ci sont trop complexes pour être mises en œuvre sur de grands objets.
Enfin, d’après les recherches de (OLLIVIER, 2011), s’aider des normales peut s’avérer utile lors de la texturation avec la création d’une « normal map ». En effet, en répartissant différentes valeurs de normales sur une seule face, la face peut alors donner une impression de relief lors de l’application des photographies. En comparant deux modèles d’un objet ayant un niveau de détail différent, il est possible d’associer les directions des normales du modèle possédant beaucoup de détails aux faces du modèle simplifié. Grâce à cette méthode, on peut représenter un objet avec beaucoup moins de polygones mais le même réalisme. Sur la figure suivante, les normales en rouge, issues du modèle aux nombreux détails, sont appliquées sur le modèle grossier de manière orthogonale.
Figure 3 : Application des normales issues d’un modèle « high-poly » sur un modèle « low-poly »17
15 Cf. : http://www.unilim.fr/pages_perso/guillaume.gilet/Enseignement/Cours/M1/Moteurs3D/Textures.pdf 16 Idem
17 « high-poly » signifie ici la présence de beaucoup de formes tandis que « low-poly » indique le contraire Source : http://blogs.wefrag.com/divide/2005/01/
19
I.5 La visite virtuelle
Par définition, une visite virtuelle est un moyen de représentation d’un site à l’aide d’un outil numérique permettant une certaine interaction de l’utilisateur. En général, le but est de donner un aperçu réaliste d’un lieu existant grâce à une interface graphique18. Il existe donc plusieurs formats de support pouvant accueillir une visite virtuelle mais également plusieurs façons de la créer. Dans la suite, on ne s’intéresse qu’aux méthodes de création de visite virtuelle à partir d’un modèle 3D (ou plus sommairement son nuage de points) en temps réel. Au travers d’un modèle 3D, l’aspect immersif est très recherché. Donner à l’utilisateur la sensation qu’il visite le lieu est important et cela inclut le fait de lui laisser des libertés de déplacement. La 3D temps réel est donc fondamentale, mais cela implique des restrictions en termes de poids de la visite19. Le but de la création d’une visite virtuelle est aussi de faire un lien entre le modèle 3D créé et sa diffusion à grande échelle. Pour cela, le concepteur doit s’intéresser aux sciences du graphisme et de l’infographie et plus largement à l’industrie du jeu vidéo car des logiciels d’infographie sont indispensables et leur utilisation nécessite souvent de bonnes connaissances en programmation. (OLLIVIER, 2011) indique que l’immersion 3D peut être proposée sur un grand nombre de plateformes. Il peut s’agir d’une console de jeu vidéo, d’un ordinateur, d’une tablette et bien d’autres. Il est également possible de procéder à une mise en ligne. Dans le cas d’une publication sur internet, (POUX, 2013) explique que des contraintes conséquentes s’ajoutent puisque, pour ne pas restreindre la fluidité de la visite, il est nécessaire d’avoir un poids de fichier réduit.
En se basant sur (OLLIVIER, 2011), les différents formats de visite virtuelle qui existent pour diffuser ce type de données sont principalement l’animation vidéo, la réalité augmentée et la réalité virtuelle.
L’animation vidéo consiste à créer un rendu maniable et réaliste grâce au déplacement d’une caméra et à l’enregistrement d’images au sein d’un modèle 3D (24 images par seconde minimum). La longueur et la vitesse de l’animation caractérisent la volonté de montrer plus ou moins de choses dans le modèle, de s’attarder plus ou moins sur des détails voire même d’inciter le spectateur à la relancer pour en obtenir davantage. C’est une méthode extrêmement répandue car elle est facile à mettre en œuvre et elle permet de donner un
18 D’après la définition de visite virtuelle donnée sur wikipedia.org 19 D’après la définition de 3D temps réel donnée sur wikipedia.org
20
premier rendu d’un modèle 3D largement diffusable (streaming sur internet, diffusion à l’aide d’un support multimédia, etc…). Toutefois, cela n’offre pas de possibilités d’interaction et permet seulement de guider la personne comme dans un film. Il faut donc faire attention de ne pas frustrer le spectateur lors de sa création, en ne modifiant jamais l’orientation de la caméra ou en ne montrant qu’une partie infime du modèle par exemple. Cette solution offre tout de même un gain de temps et de poids non négligeable par rapport à la création d’une véritable solution d’interactivité de l’utilisateur.
La réalité augmentée est un procédé informatique consistant à intégrer des objets virtuels sur des images du monde réel. (FROMENT, 2013) explique que l’utilisateur évolue alors dans un univers réel dans lequel ont été ajoutés des éléments fictifs. A l’aide d’un appareil muni d’un écran et d’une caméra, ou de lunettes spéciales, il peut donc se promener dans son environnement et percevoir, en plus de la réalité, des éléments ajoutés numériquement. La réalité augmentée créé donc un lien entre réel et virtuel en incluant une image ou un modèle conçu à la réalité de la vision de l’utilisateur.
La réalité virtuelle permet une immersion de l’utilisateur dans un monde virtuel. Elle se caractérise par l’interactivité de la visite offrant des degrés de liberté importants puisque le système prend en compte les déplacements de l’utilisateur. La réalité est donc procurée par les déplacements de l’utilisateur et l’aspect fictif par l’immersion visuelle dans un environnement tridimensionnel. Cette méthode fonctionne de manière continue dans toute la scène créée, c’est-à-dire sans temps de chargement. Les plateformes d’accueil sont nombreuses (ordinateurs, tablettes, etc…) et cela peut même être réalisé grâce au port de lunettes à vision stéréoscopique permettant une sensation de 3D.
Pour rentrer un peu plus dans les détails de la mise en ligne de données, il existe deux principales approches, citées dans (SIMONETTO et al., 2013). Il s’agit de proposer une visite virtuelle basée sur le téléchargement des données par l’utilisateur dans le premier cas. Cela implique, pour l’utilisateur, un temps de téléchargement souvent conséquent (en fonction de la taille de la visite) et la possession d’une capacité de mémoire graphique suffisante. En effet, l’appareil de l’utilisateur accueille alors localement tout le poids des données. Dans le cas de la deuxième approche, il s’agit au contraire de visualiser la visite virtuelle à distance par utilisation d’un navigateur internet combiné à un plugin. C’est cette seconde approche qui est préférée car, selon (SIMONETTO et al., 2013), « elle est plus
21
accessible pour l’utilisateur et elle préserve mieux les propriétés des données ». Cette méthode repose principalement sur le web 3D.
Le web 3D regroupe tout ce qui touche à l’intégration web de données tridimensionnelles interactives (3D temps réel). Cela correspond aux contenus visualisables sur internet directement, à l’instar d’autres méthodes requérant un logiciel spécifique20. Le domaine est assez large puisqu’il existe un nombre important de formats et de techniques. Selon Vincent Bonneau21, cette multiplicité des techniques découle de deux approches différentes. La première inclut les techniques basées sur « la représentation complète de tout [ou partie de] l’environnement », c’est le paramètre de degré d’immersion. La seconde se concentre sur le paramètre de degré de sophistication de la 3D, c’est-à-dire l’utilisation de différentes solutions allant de vraie 3D à des solutions plutôt orientées 2.5D. Parmi les nombreux formats, on peut distinguer le VRML (Virtual Reality Modeling Language, format et langage originel de représentation d’univers 3D sur internet), Java 3D (langage de programmation), Unity web player (plugin) ou encore le WebGL22.
II De l’échantillonnage à la texturation/colorisation
Le but de ce travail est de trouver le moyen de représenter au mieux les carrières, c’est-à-dire de manière réaliste certes, mais surtout de manière précise. C’est pour cette raison que l’approche « géomètre » a été choisie plutôt que l’approche « jeux vidéo » dans un premier temps. Au contraire de ce que pourrait faire un infographiste, il est important de privilégier un résultat qui ne soit pas fabriqué virtuellement mais qui soit une représentation réelle et concrète des souterrains basée sur des données fiables et précises. L’approche scientifique du professionnel de la mesure consiste alors à tout mettre en œuvre pour conserver un maximum de précision dans les traitements divers, et c’est cette approche qui a été suivie lors de chaque traitement. La suite de ce développement est exclusivement consacrée à l’étude de la création d’un modèle surfacique en 3D. En effet, la création d’une visite virtuelle au travers d’un nuage de points ne nécessite pas la réalisation de traitements supplémentaires. Elle est donc directement expliquée dans la partie visite virtuelle. En revanche, les différentes étapes menant à l’obtention d’une modélisation surfacique sont détaillées ci-après et les résultats sont analysés à l’aide de critères d’étude bien déterminés.
20 D’après la définition de web 3D donnée sur wikipedia.org
21 D’après http://www.zdnet.fr/blogs/digiworld/web-3d-du-monde-virtuel-au-web-immersif-39711859.htm 22 Cf. TFE de Florent POUX pour plus de détails sur cette approche
22
II.1 Présentation de la méthode
II.1.1 Les hypothèses
En se basant sur l’état de l’art, il a été formulé les hypothèses suivantes, divisées en deux groupes : des suppositions et des postulats.
Un Maillage
Tout d’abord, il est supposé que la modélisation des carrières ne peut s’effectuer que par un maillage. Cette hypothèse provient du fait que les souterrains aient des formes très variées et des détails nombreux dont on souhaite conserver un réalisme important. La possibilité de créer un modèle mixte, utilisant les méthodes du maillage et de la reconnaissance de formes, est écartée pour plusieurs raisons. Etant donné la complexité géométrique des parois rocheuses, cette technique de modélisation serait plutôt une source d’erreurs, son avantage résidant en une modélisation rapide et légère des formes géométriques connues.
Miser sur l’échantillonnage
Afin de créer un modèle maillé, la réduction des nuages de points, au travers d’un sous-échantillonnage, est donc essentielle et la qualité de la modélisation repose énormément sur cette phase. Il est alors nécessaire de mener d’importantes analyses du nuage de points afin de traiter les données de manière optimale avant la création d’un modèle maillé. L’avantage est que de nombreuses méthodes existent. Bien choisir l’algorithme d’échantillonnage permettrait de retirer un grand nombre de points aux endroits souhaités. De plus, d’après l’état de l’art, miser sur cette étape est primordial afin d’alléger la phase de maillage et celle de traitement post modélisation, consistant à nettoyer le modèle des artefacts.
Un échantillon représentatif
L’intégralité des carrières représentant 24 milliards de points répartis sur une surface de près de 15000 m2, il a également été choisi de se baser sur un échantillon estimé représentatif du reste des carrières pour effectuer les tests de traitement. En effet, de nombreux traitements seraient très chronophages s’ils étaient appliqués sur des nuages de points très grands cela ne permettrait pas de mener les analyses dans de bonnes conditions. Un morceau estimé représentatif a été découpé à l’aide du logiciel CloudCompare23 et enregistré au format .ply. Celui-ci à la particularité d’être plutôt fermé puisqu’il représente une partie située à la sortie du tunnel entre les carrières Wellington et Nelson (côté Nelson). Ce morceau du nuage de
23 Détection de Changement sur des Données Géométriques 3D, thèse de Daniel GIRARDEAU-MONTAUT, 2006 (élaboration du projet CloudCompare). Version 2.7.0 utilisée
23
points échantillonné à deux millimètres possède 106 500 798 points et est issu du nuage de points Wellington 5 contenant lui environ 805 millions de points. L’importation de ce nuage de taille conséquente (20 Go) fut un peu longue et le logiciel a souvent cessé de fonctionner au moment de la découpe de l’échantillon. Cet échantillon (4.5 Go) inclut des formes et des détails plutôt représentatifs du reste des carrières puisque le sol y est plutôt plat et les parois rocheuses caractéristiques. Il contient une porte, un mur de briques, un morceau de tunnel et une salle avec une hauteur de plafond plus importante. Quelques inscriptions et des fils électriques y sont présents ainsi qu’une partie éboulée où l’acquisition des points fut compliquée. Cet échantillon offre alors un certain nombre de trous, utiles pour observer le traitement de ces artefacts dans la suite des opérations.
Figure 4 : Capture d’écran de l’échantillon utilisé
Une texturation par photographies peu dégradées
Pour la phase de texturation/colorisation, l’application des photographies sur les faces du modèle maillé offre bien plus de réalisme qu’une autre technique. Cette hypothèse sera vérifiée même s’il est logique qu’une photographie apporte plus de détails visuels que l’interpolation des couleurs de trois points appliquée sur chaque face du maillage. Cependant, l’hypothèse principale exprimée est que la qualité de ces photographies doit être au maximum conservée. Il est jugé préférable d’élaborer un maillage moins complexe mais d’y appliquer une qualité optimale de textures, plutôt que de conserver un maximum de détails lors du maillage et d’y appliquer des images plus dégradées par retouches. Le paramètre du poids des données interfère également dans la problématique de la texturation car utiliser des photographies de grande qualité suppose accepter le poids qu’elles engendrent. En outre, il est supposé que plus le modèle maillé est proche de la réalité, plus le réalisme est correct lors de la texturation. Cette supposition permet de penser qu’il faudra trouver un juste milieu entre la taille des faces du maillage et une qualité des photographies suffisante, malgré la dégradation nécessaire à l’allègement du maillage.
24 II.1.2 Les logiciels utilisés
II.1.2.1 CloudCompare
CloudCompare est un logiciel de traitement de nuage de points qui a rapidement acquis une certaine renommée du fait de son caractère libre, de sa capacité à traiter des fichiers de taille importante et de sa facilité d’utilisation. Tous les outils sont détaillés dans un wiki et il existe un forum dans lequel des réponses sont apportées aux utilisateurs. Le logiciel permet d’effectuer les principales opérations de traitement de nuage de points, de sortir des statistiques et même de créer un maillage. La version utilisée dans ce projet est la version 2.7.0, bien qu’une version 2.8.1 ait été développée.
L’un des principaux outils est l’outil « subsampling ». Il permet de sous-échantillonner le nuage de points de plusieurs manières : en choisissant le nombre de points à conserver, en paramétrant le pas d’échantillonnage souhaité (conserver un point tous les x cm) ou en utilisant le niveau d’octree (conserver un point au sein de chaque cube). L’algorithme s’apparente donc à une méthode de « clustering ».
Des outils de calcul de densité, rugosité et courbure sont disponibles. Ils permettent d’attribuer un ou plusieurs champs de valeur (« scalar field ») à chaque point. Ces outils nécessitent d’entrer une « cell size », c’est-à-dire une taille de voisinage à prendre en compte. Tous les points présents dans une sphère de diamètre défini par la « cell size » sont pris en compte dans les calculs. Le choix de ce voisinage est donc très important, notamment pour la détermination de la courbure car celle-ci peut vite varier suivant la taille du voisinage. L’attribution de valeurs statistiques à un nuage de points est un avantage considérable. En effet, il est possible de sortir des histogrammes et de pouvoir étudier les valeurs plus en avant. Il est également possible de sélectionner et même de filtrer certains points à l’aide de cet histogramme. Par exemple, si la densité obtenue suit une représentation gaussienne entre 10 et 30 voisins avec un maximum à 20, le logiciel offre la possibilité de ne sélectionner que les points situés entre 15 et 25 voisins et d’éliminer le reste du nuage grâce à la fonctionnalité « filter by value » (filtrer par la valeur). Il est donc possible de segmenter le nuage de points en plusieurs parties suivant la valeur du « scalar field », d’effectuer des traitements différents sur chacune de ces parties puis de les regrouper pour former un nouveau nuage modifié. D’autres outils comme des calculs de distances sont utilisables, le logiciel est plutôt complet. Enfin, le secret de la réussite de l’import de nuage de points ayant de grandes coordonnées réside en le fait qu’une transformation est appliquée en entrée et en sortie du logiciel. Le
25
logiciel utilise la fonctionnalité « global shift » (translation) pour appliquer des paramètres de translation voire même homothétie visant à réduire la taille des coordonnées. Cette opération est recommandée car les valeurs sont alors encodées en 32 bits, permettant un gain en temps et mémoire lors d’un traitement. Dans le même souci, il est à noter que le logiciel Meshlab24, ne supporte pas les données possédant des coordonnées trop grandes encodées en 64 bits. En sortie du logiciel CloudCompare, il a alors été utile de ne pas réappliquer la transformation inverse mais de conserver les coordonnées ainsi, en prenant, toutefois, bien note des paramètres de transformation appliqués en entrée du logiciel.
II.1.2.2 Meshlab
Meshlab est également un logiciel libre et gratuit développé en Italie par l’ISTI25. C’est un outil plutôt puissant et très technique qui permet d’effectuer la plupart des traitements nécessaires dans une phase de modélisation. Il permet par exemple l’ouverture de plusieurs formats de nuage de points pour ensuite créer un maillage après le calcul des normales. De nombreux algorithmes y sont inclus pour le nettoyage, la simplification, le remaillage ou encore la texturation d’un modèle (cf. descriptif des méthodes en annexe no5). Bien que le logiciel soit difficile à prendre en main et soit sujet à des bugs, il reste un outil incontournable pour l’étude de la modélisation de par la richesse de traitements possibles. Son outil de calcul des normales est plutôt puissant mais le logiciel n’offre pas de réel avantage pour la création d’un maillage à partir d’un nuage de points. En effet, ce logiciel est plutôt utile pour des traitements post-modélisation. Seul le maillage par reconstruction de surface de poisson est adéquat. Cependant, cette option est également disponible dans CloudCompare mais avec la possibilité d’interagir plus facilement avec le résultat. Pour cette raison, Meshlab a principalement été utilisé pour manipuler les modèles issus de CloudCompare et les étudier grâce à l’affichage du « wireframe »26 notamment.
II.1.3 Elaboration des critères
A la suite de l’élaboration de ces hypothèses et postulats, il est important de fixer des critères d’étude. Ceux-ci vont pouvoir caractériser les différents résultats, permettre des analyses comparatives et, à terme, déterminer quelle méthode est la plus adaptée pour ce projet. Ces critères ne sont en aucun cas sélectifs mais permettent plutôt une évaluation.
24 http://www.meshlab.net/ Version 1.3.3 utilisée
25 Istituto di Scienza e Tecnologie dell Informazione (Institut des Sciences et Technologies de l’Information) 26 Squelette tridimensionnel d’un maillage laissant apparaitre les sommets et les arrêtes des faces
26
Sous-échantillonnage
Dans le but de réduire le nuage de points en poids et donc en données, deux étapes se distinguent. La première vise à choisir la méthode d’échantillonnage en fixant un nombre de points et en comparant plusieurs manières de réduire le nuage, tandis que la seconde détermine la valeur de cette réduction en fixant la méthode choisie et en ne faisant varier que les termes liés au nombre de points. De fait, ces deux étapes étant très dépendantes l’une de l’autre, le choix de la méthode influe beaucoup sur le choix de la densité, qui, lui, caractérise la valeur du sous-échantillonnage. Les mêmes critères de densité et de pourcentage de réduction sont donc utilisés deux fois pour déterminer cette valeur, mais en faisant varier différents paramètres. Pour traiter le choix de la méthode d’échantillonnage et de la valeur du sous-échantillonnage, il a été décidé de se baser sur les critères suivants :
- Pourcentage de réduction : cela correspond à une estimation de la quantité de points
décimés par la méthode sous forme de pourcentage. La plupart des logiciels fournissent le nombre de points, il suffit alors de le transformer en ratio à l’aide du nombre de points initial.
- Densité : critère défini à l’aide d’un indice (le NDDI) calculé en tenant compte de la
densité générale du nuage de points mais également de la différence de densité dans les courbures et aux endroits plats (cf. annexe no3).
Ainsi, ces deux critères permettent, dans un premier temps, de déterminer la meilleure méthode et, dans un second temps, de choisir un juste milieu entre une décimation démesurée et une décimation trop légère (bonne réduction contre bonne préservation de la densité).
Maillage
Pour pouvoir analyser correctement les méthodes de création de maillage, de nombreux critères existent. Il a alors fallu effectuer une sélection plus avancée pour baser les analyses sur les critères les plus pertinents et relevant plutôt de domaines différents :
- Ecart maillage / nuage : ce critère permet de s’assurer de la préservation des
caractéristiques géométriques du nuage en analysant l’écart moyen quadratique entre le nuage de points non échantillonné et le maillage créé. Ce critère est donc à double tranchant puisqu’il permet aussi de caractériser l’échantillonnage effectué en amont. Il est issu de l’outil du même nom du logiciel CloudCompare.
- Nombre de faces : le nombre de faces influe directement sur le poids d’un modèle
3D. Il faut tenter d’en disposer le moins possible. Ce nombre est affiché par les logiciels CloudCompare ou Meshlab.
27
- Aspect du maillage : ce critère englobe des analyses visuelles du lissage général du
maillage et de la qualité de la forme des triangles obtenus. En effet, il est par exemple considéré qu’un triangle obtus ou qu’un triangle ayant une base largement inférieure aux autres cotés n’est pas gage de qualité. En ce qui concerne le lissage, un programme sous Python27 a été élaboré pour le caractériser mathématiquement mais n’a finalement pas été utilisé (cf. annexe no4). Son fonctionnement est de calculer les angles formés entre les normales d’un triangle et de ses trois voisins.
- Temps de traitement : le temps que met le logiciel à procéder à la création du maillage
est un bon indicateur.
- Qualité du traitement : les maillages créés offrent un aperçu de la quantité d’artefacts
générés et du temps nécessaire au nettoyage des données. Ce critère vise donc à évaluer, visuellement et grâce au nombre de trous, la charge de travail nécessitée lors d’une phase de post modélisation. Evidemment, le critère sera positif pour une charge de post traitement réduite.
Texturation
Lors de la phase de texturation, plusieurs critères permettent de juger si une méthode est préférable à une autre :
- Poids des images : le poids ajouté au modèle en le texturant est le principal enjeu de
cette phase. En jouant sur la compression des images, il est possible de le réduire. Ce critère est donc estimé par le taux de compression des images.
- Réalisme : l’aspect donné par la texture doit rester photo-réaliste. Cela inclut des
qualités de couleur et de relief correctes. Ce critère est estimé visuellement.
Modèle texturé (ou colorisé) final
Enfin, en ce qui concerne le modèle final, les deux critères suivants ont été retenus :
- Aspect : le réalisme étant un enjeu phare de la modélisation, le premier critère
consiste à mener une étude qualitative statistique au travers d’un questionnaire proposé à plusieurs personnes (cf. annexe n°7).
- Poids final : enfin, le deuxième enjeu clé est d’obtenir un poids de fichier raisonnable
pour une publication en ligne. Ce critère correspond donc au poids du modèle.
28
II.2 L’échantillonnage
Dans le cas de ce mémoire, il s’agit de mettre en place une méthode propre à ce projet, privilégiant les moyens gratuits à disposition (logiciel CloudCompare notamment). Pour faire évoluer les nuages de points, il existe des techniques de décimation dites régulières et d’autres non régulières. Les méthodes régulières permettent de conserver ou d’établir une répartition des points uniforme. A l’inverse, il existe des méthodes irrégulières s’aidant de plusieurs paramètres pour effectuer la décimation, comme la courbure notamment. Si aucune hypothèse n’était privilégiée quant à la méthode, il était évident qu’une méthode irrégulière allait être choisie pour conserver plus de points à certains endroits particuliers. En théorie, le nuage de points recherché à la fin de cette étude est un nuage reprenant les formes principales du nuage initial mais largement réduit en poids, c’est-à-dire en nombre de points. II.2.1 Les méthodes régulières
II.2.1.1 Etude de la régularité d’un nuage
Dans un premier temps, il a été choisi d’effectuer une batterie de tests sur l’échantillon pour avoir un aperçu des résultats obtenus après un premier échantillonnage régulier. Sous CloudCompare, le nuage de points échantillonné à 2 mm a été décimé successivement de manière régulière avec plusieurs valeurs de pas d’échantillonnage. Le tableau suivant récapitule les résultats de ces nuages de points qui ont été enregistrés au format .ply ASCII.
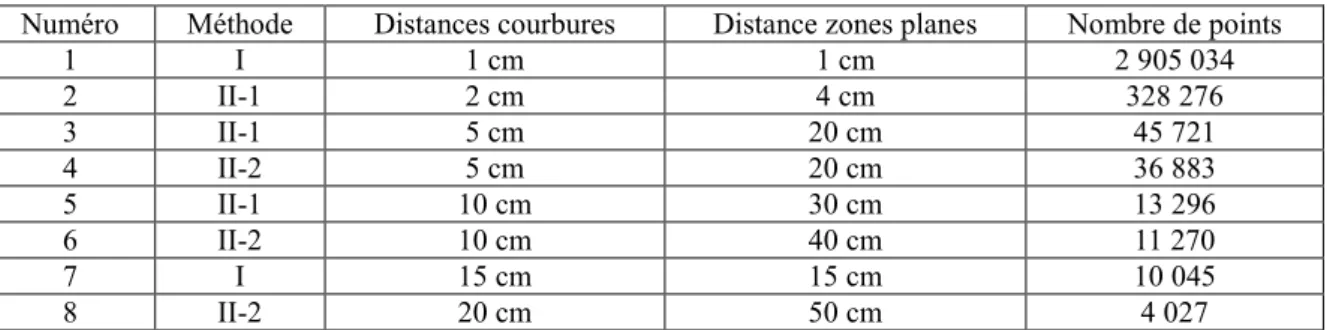
Pas d’échantillonnage (en mm) Nombre de points Poids du fichier .ply (en Ko)
2 106 500 798 4 482 647 4 21 023 109 756 728 6 8 715 803 312 666 8 4 678 900 167 499 10 2 905 034 103 848 20 672 863 23 974 40 157 937 5 615 80 37 134 1 319 120 15 973 567
Tableau 1 : Nombre de points et poids de fichier en fonction de la valeur du pas d’échantillonnage
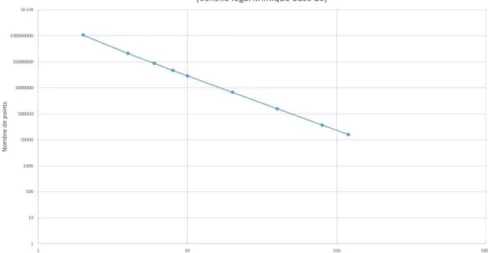
Afin d’identifier une potentielle loi mathématique, il a été décidé de tracer l’allure de graphiques avec ces données. Un premier graphique représentant le nombre de points en fonction de la valeur du sous-échantillonnage a été créé en figure 5. Celui-ci semble dessiner une loi en 1 / xn. Pour le montrer, un changement d’échelle pour une échelle logarithmique de base 10 a eu lieu. En effet, le logarithme décomposant les produits en sommes et les puissances en produits, on doit donc obtenir une équation de type log (1 / xn) = -n * log(x), représentée linéairement avec le changement d’échelle (cf. figure 6).
29
Figure 5 : Graphiques des nombres de points en fonction du niveau d’échantillonnage
Figure 6 : Graphique des nombres de points en fonction du niveau d’échantillonnage en échelle logarithmique
En fait, les valeurs des abscisses ont été conservées sans transformation logarithmique pour obtenir graphiquement une équation linéaire du type y = -n * x (d’après la transformation d’une puissance en produit). La linéarité de ce graphique montre bien que le sous-échantillonnage suit une loi en 1 / xn et donc qu’une fonction puissance représente la décroissance du nombre de points. L’équation de la première courbe est : 4 * 108 / x2.132. Elle se rapproche bien de la forme 1 / x2. De plus, on observe que le poids des fichiers suit approximativement la même allure. Une corrélation entre poids du fichier et nombre de points est donc montrée, même si il est évident que plus il y a de points, plus un fichier de nuage de points est volumineux (codage des points en 16 bits).
Ces valeurs de sous-échantillonnage sont intéressantes car elles permettent d’avoir des valeurs de référence et donc des bases utiles pour les tests de mise au point d’une méthode irrégulière d’échantillonnage. En effet, grâce à ces premiers tests, il est plus facile de se rendre compte de l’efficacité ou non d’une méthode d’échantillonnage. A l’aide de l’étude