REPUBLIQUE ALGERIENNE DEMOCRATIQUE ET POPULAIRE
Ministère de l’Enseignement Supérieur et de la Recherche
Scientifique
Université Africaine d’Adrar Faculté des Sciences et de la technologie Département de Mathématique et de l’Informatique
Mémoire de Fin d’Etudes
Pour l’Obtention du Diplôme Master en
Informatique
Option
: Réseaux et Systèmes Intelligents
Présenté par :
BENCHIKH
A
BDELHAMID
T
HÈME :L’UTILISATION
DE
LA
TECHNIQUE
SVM
POUR
LA
FUSION
BIOMETRIQUE
MULTIMODALE
Jury :
Président: Mr. Mohammed Amine CHERAGUI Maître assistant Université d’Adrar
Examinateur: Mr. Mohammed OMARI Maître de conférences Université d’Adrar
Encadreur: Mr. Youssef ELMIR Maître assistant Université d’Adrar
Remerciement
Avant tout, je remercie DIEU le Tout-puissant de m’avoir donné le courage, la volonté, la patience et la santé durant toutes ces années d’étude
Je tiens à remercier mes deux encadreurs :
Monsieur Youssef ELMIR, qui m’a ouvert la porte pour le domaine de recherche et m’a inspiré avec sa méthode de travail et son humanité Monsieur Mohammed DEMRI, de m’avoir guidé, encouragé, conseillé tout
en me laissant l’initiative. Je tiens à le remercier spécialement pour la confiance qu’il m’a accordée et à le féliciter pour sa patience
Mon remerciement est également aussi aux membres du jury qui m’ont fait l’honneur d’accepter d’évaluer ce travail
Enfin je remercie aussi :
Toutes les personnes avec qui j’ai eu la chance de travailler ou que j’ai eu l’honneur d’entourer avant et pendant mon mémoire
Tous mes amis, qui m’ont toujours soutenu et encouragé au cours de la réalisation de ce travail
Dédicace
A ma mère,
A mes frères et sœurs,
A ma famille et mes proches, A tout mes amis,
A tout mes maîtres et professeurs : du primaire au supérieur, A tous ceux qui ont contribué au développement des sciences en général et de l’informatique en particulier.
Résumé Savoir déterminer l’identité d’une personne de manière automatique est un problème toujours d’actualité. Dans un monde qui devient de plus en plus interconnecté, il est plus que nécessaire de reconnaître les personnes afin de leur autoriser l’accès à des ressources spécifiques. La biométrie est l’identification automatique de la personne basée sur ses caractéristiques physiologiques ou comportementales, Cependant, Un système biométrique unimodal souffre de certaines limitations. Pour remédier aux ces problèmes, des informations provenant de différentes sources biométriques sont combinés, et de tels systèmes sont appelés les systèmes biométriques multimodaux. Dans ce mémoire, on propose l’utilisation de la technique d’apprentissage statistique (SVM). La technique proposée est évaluée expérimentalement sur des scores publiquement disponibles (XM2VTS, TIMIT, le NIST et BANCA) et sous trois conditions de qualité de données à savoir, propres, variées et dégradées. Afin de réduire l’effet de variation de scores sur l’efficacité du système biométrique, nous utilisons un mécanisme de normalisation de cohorte sans contrainte (UCN). L’évaluation du système est basée sur les taux d’erreurs de vérification (EER), obtenus à travers des différents tests effectués.
Mots-clés: Biométrie multimodale ; Le visage ; La voix ; les scores; apprentissage statistique ; SVM ; UCN ; évaluation des performances.
Abstract Determining automatically the identity of a person is an ongoing problem. In a world which is becoming increasingly interconnected, it is necessary to recognize persons in order to give them access to specific resources. Biometrics is the automatic recognition of the person based on his physiological or behavioral characteristics, However, Unimodal biometric system suffers from several limitations, To alleviate this problems, information from different biometric sources are combined and such systems are known as multimodal biometric systems. In this memory, we propose the use of the statistical technique of training (SVM). The technique suggested is experimentally evaluated on publicly available datasets of scores (XM2VTS, TIMIT, NIST and
BANCA) and under three different data quality conditions namely, clean varied and degraded. In
order to reduce the effects of scores variations on the accuracy of biometric systems, we use Unconstraint Cohort Normalization (UCN) mechanism to normalize the matching scores before combining them. The evaluation of the system is based on the verification error rates (EER), obtained through various tests.
Keywords: Multimodal Biometrics; face; voice; Matching Scores; statistical learning; SVM; UCN;
Sommaire
Introduction Générale
Introduction générale ... 1
Chapitre 1: Généralités sur la biométrie 1.1 Introduction ... 4
1.2 Le marché mondial de la biométrie ... 4
1.3 Pourquoi la biométrie? ... 5
1.4 Définition De La Biométrie ... 6
1.5 Classification de la biométrie ... 6
1.5.1 Différentes modalités biométriques ... 8
1.6 Le système biométrique ... 11
1.6.1 Caractéristiques d’un système biométrique ... 11
1.6.2 Modes de fonctionnement ... 12
1.6.3 Types d’erreurs d’un système biométrique ... 13
1.7 Les applications de la biométrie ... 14
1.8 Les limites des systèmes biométriques monomodaux ... 15
1.9 Conclusion ... 18
Chapitre 2: La multimodalité 2.1 Introduction ... 20
2.2 Scénarios pour la fusion multimodale ... 20
2.3 Les modes de fonctionnement d’un système multimodal ... 22
2.4 Les architectures ... 23
2.5 Les niveaux de fusion ... 24
2.6 Normalisation de scores ... 27
2.7 Domaines d’application de la multimodalité ... 28
2.8 Les avantages de la multimodalité biométrique ... 30
2.9 Conclusion ... 31
Chapitre 3: Les machines à vecteur de support 3.1 Introduction ... 33
Sommaire
3.2 Apprentissage et classification ... 33
3.2.1 Notion d’apprentissage ... 33
3.2.2 Notion de classification ... 33
3.3 Les Machines à Vecteurs de Support (SVM) ... 34
3.3.1 Notion de base ... 34 3.3.1.1 Hyperplan séparateur ... 34 3.3.1.2 Vecteur de support ... 35 3.3.1.3 La marge ... 35 3.3.1.4 Fonction noyau ... 36 3.3.2 Principe de fonctionnement ... 36 3.3.3 Propriétés fondamentales ... 36 3.3.4 Fondement mathématiques ... 38 3.4 SVM à plusieurs classes ... 41
3.5 Les domaines d’application des SVM ... 42
3.6 Les avantages & les inconvénients ... 42
3.7 Conclusion ... 43
Chapitre 4: Implémentation et discution des résultats 4.1 Introduction ... 45
4.2 L’évaluation des performances du système ... 45
4.3 Implémentation et réalisation ... 48
4.3.1 Les outils de développement ... 49
4.3.1.1 L’environnement Matlab ... 49
4.3.1.2 Les bases de données biométrique multimodales ... 50
4.4 Processus de fusion ... 52
4.4.1 Phase d’apprentissage ... 52
4.4.2 Phase de test ... 54
4.5 Résultats et discussion ... 55
4.5.1 Fusion de données propres ... 55
4.5.2 Fusion de données variées... 57
Sommaire 4.6 Conclusion ... 61 Conclusion Générale Conclusion générale ... 63 Bibliographie Bibliographie ... 66
Sommaire
Chapitre 1 : Généralités sur la biométrie
Figure 1.1 : Evolution du marché international de la biométrie ... 5
Figure 1.2 : La Classification De La Biométrie ... 7
Figure 1.3 : Exemple D’analyse D’un Visage ... 9
Figure 1.4 : L’empreinte digitale ... 9
Figure 1.5 : Géométrie de la main ... 9
Figure 1.6 : Modalité d’œil ... 9
Figure 1.7 : Spectre d’un signal voix ... 10
Figure 1.8 : Modalité de signature ... 10
Figure 1.9 : Frappe du clavier ... 11
Figure 1.10 : La tâche d’identification d’un individu ... 13
Figure 1.11 : La tâche de vérification d’un individu ... 13
Figure 1.12 : Représentation du FRR, FAR et ERR ... 14
Figure 1.13 : Exemples d’applications de la biométrie ... 15
Figure 1.14 : Effet des images bruyantes sur un système biométrique ... 16
Figure 1.15 : Les variations d’intra-classe ... 17
Figure 1.16 : Limite de discrimination du trait biométrique ... 17
Figure 1.17 : La mauvaise qualité des minuties et arêtes ... 18
Chapitre 2 : La multimodalité Figure 2.1 : Exemple d’un système multimodal ... 21
Figure 2.2 : Les différents systèmes multimodaux ... 21
Figure 2.2 : Architecture de fusion en parallèle ... 24
Figure 2.3 : Architecture de fusion en série ... 24
Figure 2.4 : Les différents niveaux de fusion ... 25
Figure 2.5 : Schéma de la fusion de scores ... 27 Chapitre 3 : Les machines à vecteur de support
Sommaire
Figure 3.1 : Exemple d’hyperplan H ... 35
Figure 3.2 : Les vecteurs de support ... 35
Figure 3.2 : Hyperplan optimal, vecteurs de support et marge maximale ... 35
Figure 3.4 : Meilleur hyperplan séparateur ... 36
Figure 3.5 : La séparation linéaire et non linéaire ... 37
Figure 3.6 : Changement d’espace de représentation des données ... 38
Figure 3.7 : Cas linéairement séparable ... 39
Figure 3.8 : Espace de projection des données non linéairement séparable ... 43
Chapitre 4 : Impémentation et discution des résultats Figure 4.1 : L’organigramme du processus de fusion de scores ... 50
Figure 4.2 : Les courbes DET pour la fusion de données prpres sans/avec UCN (resp) ... 56
Figure 4.3 : Les courbes ROC pour la fusion de données propres sans/avec UCN (resp) ... 57
Figure 4.4 : Les courbes DET pour la fusion de données variées sans/avec UCN (resp) ... 58
Figure 4.5 : Les courbes ROC pour la fusion de données variées sans/avec UCN (resp) ... 59
Figure 4.6 : Les courbes DET pour la fusion de données dégradées sans/avec UCN (resp) ... 61
Sommaire
Chapitre 3 : Les machines à vecteur de support
Tableau 3.1 : Quelques fonctions de noyaux. ... 41 Chapitre 4 : Les machines à vecteur de support
Tableau 4.1 : Les différents taux d’erreur égaux (EERs) pour la fusion de données propres. ... 55 Tableau 4.2 : Les différents taux d’erreur égaux (EERs) pour la fusion de données variées. ... 57 Tableau 4.3 : Les différents taux d’erreur égaux (EERs) pour la fusion de données dégradées ... 59
INTRODUCTION
GÉNÉRALE
Introduction générale Dans ces dernières années, la vérification automatique des personnes devient un outil de plus en plus important dans beaucoup d’applications telles que l’accès à des services automatisés (retrait d’argent à partir des distributeurs automatiques) et à des endroits protégés comme les banques. Elles nécessitent des plans de sécurité fiables. En l’absence des plans de vérification robustes, ces systèmes sont vulnérables aux ruses des imposteurs. Introduction générale
Différentes techniques disponibles sont largement utilisées dans ce contexte par exemple: les mots de passe, les cartes magnétiques, les numéros d’identification personnelle (PIN). Comme c’est bien connu, ces simples mécanismes de control d’accès peuvent facilement conduire à des mauvais usages, induits par la perte ou le vol de la carte magnétique et le PIN correspondant. D’où, un nouveau type de méthodes est entrain de naître, basé sur ce qu’on appelle les caractéristiques ou bien les mesures biométriques, telles que la voix, le visage, l’œil (iris, rétine), l’empreinte digitale, la forme (la géométrie) de la main ou d’autres caractéristiques physiologiques ou comportementales de la personne.
En général les mesures biométriques, sont très intéressantes car elles ont le grand avantage qu’on ne peut pas les perdre ou les oublier, et elles sont vraiment personnelles (on ne peut pas les passer à quelqu’un d’autre), puisque elles sont basées sur une mesure d’aspect physique de l’être humain.
Si on emploie seulement une seule mesure biométrique (système monomodal), les résultats obtenus peuvent s’avérer pas assez bons. Ceci est dû au fait que ces mesures faciles à utiliser tendent à changer avec le temps pour une et la même personne, l’importance de cette variation est elle-même variable d’une personne à l’autre. Cela est particulièrement vrai pour la voix, qui montre une importante variabilité d’intra locuteur (speaker). Une solution possible pour remédier à ce problème est d’utiliser non pas une seule mesure biométrique mais plusieurs (systèmes multimodaux).
L’objectif de ce mémoire consiste à mettre en ouvre un système biométrique multimodal basé sur la fusion des deux systèmes monomodaux (visage et voix) afin d’améliorer le taux de l’authentification et les performances du système.
Ce mémoire est composé de deux parties : une partie théorique regroupant trois chapitres présentant les principaux concepts de la biométrie et la technique d’optimisation utilisés dans notre travail, et une autre partie pratique dont laquelle nous expliquons les différentes expérimentations que nous avons mises en œuvre. Notre manuscrit est organisé de la manière suivante :
Introduction générale
Chapitre 1 Généralité sur la biométrie.
Nous parlerons dans ce chapitre sur les notions fondamentales de la biométrie, ensuite nous verrons les différentes modalités biométriques, nous citerons aussi les systèmes biométriques, leurs architectures, ses modes de fonctionnement, et leurs domaines d’application et enfin nous verrons les inconvénients trouvés dans les systèmes monomodaux.
Chapitre 2 La multimodalité
Ce chapitre est consacré à la fusion de plusieurs modalités biométriques, nous commencerons par présenter les différentes scénarios pour la fusion multimodale, par la suite nous parlerons du système multimodale où l’accent est mis sur les niveaux de fusion des scores de différentes modalités et leurs normalisation, ainsi que les avantages trouvés dans ces systèmes.
Chapitre 3 Les machines à vecteurs de support (SVM)
Ce chapitre présente les fondements théoriques de la méthode de fusion utilisée dans ce mémoire, qui est SVM. Ainsi que son mode de fonctionnement, et enfin nous verrons les inconvénients et les avantages de cette méthode.
Chapitre 4 Implémentation et discussion des résultats
Ce chapitre introduit les outils de développement utilisés pour réaliser notre application, après nous donnons la structure de notre application, deux interfaces sont à distinguer : l’une pour la phase d’apprentissage et l’autre pour la phase du test est consacré aux différents tests effectués, ainsi qu’aux résultats obtenus par notre méthode de classification SVM, avec la visualisation de quelques illustration lors de cette phase.
Enfin, nous terminerons ce mémoire par une conclusion générale et quelques perspectives de ce travail.
CHAPITRE 1
GÉNÉRALITÉS
SUR LA
1.1 Introduction
Les systèmes biométriques sont de plus en plus utilisés depuis quelques années. L’apparition de l’ordinateur et sa capacité à traiter et à stocker les données ont permis la création des systèmes biométriques informatisés. Il existe plusieurs caractéristiques uniques pour un individu, ce qui explique la diversité des systèmes appliquant la biométrie, selon ce que l’on prend en compte, tel que :
Le visage
La voix
L’empreinte digitale …etc.
Ce chapitre propose une introduction à la biométrie comme un outil pour la reconnaissance d’un individu, au lieu des moyens traditionnel tels que les mots de passes, les cartes d’identités, …etc.
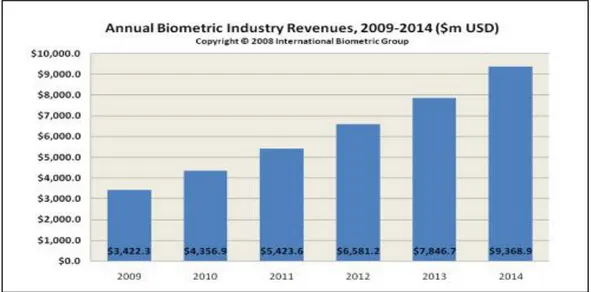
1.2 Le marché mondial de la biométrie
Régulièrement, un rapport sur le marché de la biométrie est édité par IBG (International Biometric Group)1. Cette étude est une analyse complète des chiffres d’affaires, des tendances de croissance, et des développements industriels pour le marché de la biométrie actuel et futur.
La lecture de ce rapport est essentielle pour des établissements déployant la technologie biométrique, les investisseurs dans les entreprises biométriques, ou les développeurs de solutions biométriques. Le chiffre d’affaires de l’industrie biométrique incluant les applications judiciaires et celles du secteur public, se développe rapidement. Une grande partie de la croissance sera attribuable au contrôle d’accès aux systèmes d’information (ordinateur/réseau) et au commerce électronique, bien que les applications du secteur public continuent à être une partie essentielle de l’industrie.
On prévoit que le chiffre d’affaires des marchés émergents (accès aux systèmes d’informations, commerce électroniques et téléphonie, accès physique et surveillance)
dépasse le chiffre d’affaires des secteurs plus matures (identification criminelle et identification des citoyens) (Figure 1.1).
1.3 Pourquoi la biométrie?
Les arguments pour la biométrie se résument en deux catégories: Praticité
Les mots de passe comme les cartes de crédit, les cartes de débit, les cartes d'identité
ou encore les clés peuvent être oubliés, perdus, volés et copiés. En plus, aujourd'hui tous et chacun doivent se rappeler une multitude de mots de passe et avoir en leur possession
un grand nombre de cartes. De son côté la biométrie serait immunisée contre ce genre de maux en plus qu'elle serait simple et pratique, car il n'y a plus ni cartes ni mots de passe à retenir2.
Sécurité
La biométrie serait plus sécuritaire que les méthodes actuellement utilisées. Elle permettrait une identification précise et possible même sans papiers d'identification qui peuvent être contrefaits. Aussi, elle permettrait d'améliorer la sécurité des documents protégés biométriquement, donc de limiter la fraude. Ensuite, elle pourrait éviter la fraude dans de nombreux systèmes en évitant les dédoublements. Par exemple, un prestataire de l'assistance sociale ne pourrait pas recevoir plusieurs prestations sous différents noms
[19]. La biométrie serait capable de réduire, sans l'éliminer, le crime et le terrorisme car, à
tout de moins, elle complique la vie des criminels et des terroristes.
2
GlobaISecurity.org, Biometries,
http://www.globalsecurity.org/security/systems/biometrics.htm. (Consulté le 22/05/2013).
1.4 Définition De La Biométrie
Le terme biométrie vient des mots Grecs bios (vie) et metrikos (mesure ou distance) selon3, qui veut dire distances biophysiques de l’être humain, ou en d’autre terme, c’est l’anthropométrie.
Il existe plusieurs définitions de la biométrie, en voici quelques unes : Définition 1
La biométrie est la science qui étudie à l’aide des mathématiques (statistiques, probabilités) les variations biologiques ou biophysiques à l’intérieur d’un groupe déterminé de personnes.
Définition2
Les mesures biométriques sont celles qui concernent l’ensemble des caractéristiques distinctives d’une personne. Elles peuvent être lues par des systèmes informatiques et utilisées afin d’identifier cette personne.
Définition 3
La biométrie permet l’identification d’une personne sur la base de caractères
physiologiques ou de traits comportementaux automatiquement reconnaissables et vérifiables4.
1.5 Classification de la biométrie
Une gamme de systèmes biométriques monomodal est à l’étude ou sur le marché, par ce qu’aucun système ne répond à tous les besoins seul. Les différences en développant ces systèmes impliquent le coût, la fiabilité, le manque de confort en utilisant l’appareil, et la quantité de données requise.
Les empreintes digitales, par exemple, font très peu d’erreurs de classification, mais le matériel utilisé pour les capturer était cher, et la quantité de données qui doit être stockée pour décrire une empreinte digitale (le modèle) avait tendance à être assez grande. En revanche, le matériel utilisé pour capturer la voix est moins cher (microphone à bon marché), mais elle change quand les émotions et les états de santé changent. Selon Miller la biométrie comprend des caractéristiques physiologiques et comportementales [21]. La Figure 1.2 illustre cela pour un nombre de biométries les plus fréquemment utilisées.
3Larousse, « Dictionnaire De La Langue Française », Edition Larousse/VUEF, Paris,
France, 2002.
4
Un trait physiologique est relativement stable tel que l’empreinte digitale, la géométrie de la main, l’iris, la rétine. En effet, toutes ces caractéristiques sont fondamentalement invariables sans blessure à l’individu. Un trait comportemental d’autre part, a une certaine base physiologique, mais reflète également l’état (émotif) physiologique d’une personne.
Le trait comportemental le plus commun et utilisé dans les systèmes biométriques automatiques est la voix humaine. D’autres traits comportementaux sont la démarche, la signature dynamique, la frappe du clavier.
Un des problèmes principaux des caractéristiques comportementales est qu’ils tendent à changer dans le temps. Donc les systèmes biométriques qui se fondent sur des caractéristiques comportementales devraient idéalement mettre à jour leurs bases de données de façon régulière.
Les différences entre les méthodes physiologiques et comportementales sont importantes. D’une part le degré de variabilité d’intra-personne est plus petit dans une caractéristique physiologique que dans une caractéristique comportementale. D’autre part, les machines qui mesurent des caractéristiques physiologiques tendent à être plus grandes et plus chères, et peuvent sembler plus menaçantes ou envahissantes aux utilisateurs (c’est par exemple le cas des scanners de rétine). En raison de ces différences, aucune méthode biométriques seule ne satisfera à tous les besoins [16].
Figure 1.2 : La Classification De La Biométrie [7].
Biométrie
Caractéristiques physiologiques Caractéristiques comportementales Visage Empreinte digitale Main L’œil Voix Signature Frappe de clavier
1.5.1 Différentes Modalités Biométriques
Chaque information biométrique qui peut discriminer les individus est considéré comme un biométrique modalité.
Visage
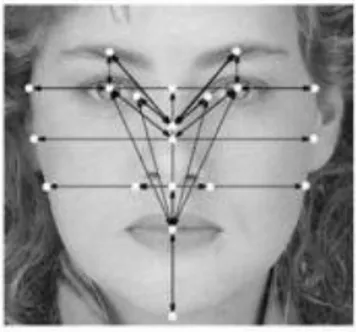
L’analyse de la forme du visage a souvent été utilisée pour identifier des criminels dans les lieux publiques, l’utilisation d’une caméra permet de capter la forme du visage d’un individu et d’extraire les caractéristiques significatives pour la reconnaissance du visage comme : les yeux, la bouche, le nez et le tour du visage (Figure 1.3).
Selon le système utilisé, l’individu doit être positionné devant l’appareil ou peut être en mouvement à une certaine distance. Les données biométriques qui sont obtenues sont, par la suite, comparées au fichier référence. Le problème dans cette technique vient des possibles perturbations pouvant transformer le visage (maquillage, faible luminosité, présence d'une barbe ou lunettes,…).
Empreintes digitales
Les systèmes biométriques utilisant l’empreinte digitale sont les plus utilisés (Figure
1.4). Des solutions de plus en plus abordables et performantes sont proposées par les
constructeurs. On voit de plus en plus placer des lecteurs d’empreintes digitales sur des micros ordinateurs ou des téléphones portables pour sécuriser leurs utilisations et cela devient de plus en plus commode et accepté par le grand public.
Figure 1.4 : Modalité d’empreinte digitale Figure 1.3 : Exemple D’analyse D’un Visage
Main
La reconnaissance par géométrie de la main est un des systèmes biométriques commerciaux les plus anciens (Figure 1.5). Chaque individu à sa propre forme de la main. On peut l’acquérir en utilisant un scanner spécialisé. La longueur des doigts, leur épaisseur et leur position relative sont des paramètres qui sont extraits de l'image et comparés à ceux existant dans une base de données. Néanmoins, cette biométrie est sujette à certaines modifications qui sont dues au vieillissement.
L’œil :
Pour parvenir à authentifier l’identité d’une personne à l’aide de l’œil, les technologies biométriques utilisent deux méthodes : celle qui consiste à analyser l’iris et celle qui analyse la rétine (Figure 1.6). Dans tous les cas, cette technique est beaucoup plus sûre que la plupart des autres technologies biométriques, ceci grâce aux multitudes de caractéristiques qui peuvent varier d’un individu à un autre.
Voix :
L’identification de la voix est considérée par les utilisateurs comme une des formes les plus acceptables de la technologie biométrique, car elle n’est pas intrusive et n’exige aucun contact physique avec le lecteur d’un système. La voix d'une personne se caractérise par beaucoup de paramètres. Chaque personne possède une voix propre que nous pouvons analyser par enregistrement avec un micro. Les sons se caractérisent par une fréquence, par une intensité et par une tonalité (Figure 1.7).
Figure 1.6 : Modalité d’œil
Le traitement informatique tient compte des distorsions liées au matériel utilisé, et sait analyser un son de mauvaise qualité tel qu'une transmission téléphonique ou radiophonique. La fatigue, le stress ou le rhume, peuvent provoquer des variations de cette voix. La fraude est possible en enregistrant, à son insu, la voix d'une personne autorisée, à moins d'obliger la personne contrôlée à lire un texte aléatoire.
Signature :
Toute personne a son propre style d’écriture. A partir de la signature d’une personne, nous pouvons définir un modèle qui pourra être employé pour son identification. Signer un document pour s’identifier est un geste naturel. Dans la vie de tous les jours, nous signons régulièrement des documents très divers.
La reconnaissance de la signature est une des techniques biométriques comportementales. Elle consiste à faire signer l’utilisateur avec un stylo lecteur sur une tablette graphique. Ces deux objets analysent plus la façon de réaliser la signature que la signature proprement dite. En effet, le système analyse les variations de vitesse du stylo, la différence de pression sur la tablette graphique (Figure 1.8) au cours de la signature. Le point faible de ce procédé biométrique est qu’un individu qui ne signe pas toujours de la même façon se verra souvent refuser l’accès au système.
L’acceptation de cette technique est très bonne car la signature est un geste commun pour tout le monde [9].
Figure 1.8 : Modalité de signature Figure 1.7 : Spectre d’un signal voix
Frappe du clavier :
Cette technique est aussi appelée dactylographie dynamique. Elle mesure la façon dont l’utilisateur appuie sur les touches (temps d’appui et temps entre chaque frappe). Etant donné qu’une personne peut améliorer sa vitesse et sa technique de frappe sur un clavier, le système doit sans cesse renouveler son fichier référence.
1.6 Le système biométrique
Un système biométrique est un système de reconnaissance des formes qui procède en premier par l'acquisition des données biométriques de l’individu à reconnaître, puis extrait un ensemble de caractéristiques à partir de celles ci, enfin il compare ces caractéristiques avec les modèles de la base de données pour prendre de décision.
Tout système biométrique comporte deux processus qui se chargent de réaliser les opérations d’enregistrement et de tests :
Processus d’enregistrement
Ce processus a pour but d'enregistrer les caractéristiques des utilisateurs dans la base de données.
Processus de tests (identification /vérification)
Ce processus réalise l’identification ou la vérification d'une personne.
1.6.1 Caractéristiques d’un système biométrique
Dans chacun des deux processus précédents le système exécute quatre modules principaux [10] :
a. Le module de capture
Ce module est responsable de l’acquisition des données biométriques pourvu d'un capteur pour acquérir une caractéristique spécifique de l'individu, par exemple : un microphone dans le cas de la voix, une caméra de sécurité dans le cas de visage.
b. Le module d’extraction de caractéristiques
Après avoir fait l’acquisition d’une voix ou d’une image, on réalise l’extraction de la caractéristique (l’information pertinente) afin de former une nouvelle représentation des données. Par exemple: extraire le visage du fond d'une image dans le cas de l'identification de visage.
c. Le module de correspondance
En examinant les modèles stockés dans la base de données, le système collecte un certain nombre de modèles qui ressemblent le plus à celui de la personne à identifier, et constitue une liste limitée de candidats. Cette classification intervient uniquement dans le cas d'identification car l'authentification ne retient qu'un seul modèle (celui de la personne proclamée).
d. Le module de décision
Vérifie l’identité affirmée par un utilisateur ou détermine l’identité d’une personne basée sur le degré de similitude entre les caractéristiques extraites et le(s) modèle(s) stocké(s).
1.6.2 Modes de fonctionnement
Selon le contexte de l'application, un système biométrique peut fonctionner soit en mode identification ou vérification [5]:
En mode identification
Cette étape consiste à choisir l’identité correcte d’une personne inconnue parmi des identités enregistrées dans la base de données. Par conséquent, le système effectue une comparaison, du modèle de la personne, avec les autres modèles de la base de donnée pour établir son identité (Figure 1.10). Ici l’individu n’a pas à revendiquer une identité. L’identification de l'identité est généralement utilisée pour empêcher qu’une personne n’utilise plusieurs identités [4], En d'autres termes. Dans un tel mode, le système doit alors répondre à la question suivante: « Qui suis-je ? » [20].
En mode vérification
Cette méthode consiste à vérifier si une personne est vraiment celle qui prétend être (Figure 1.11). On l’appel «un à un », comme le système doit vérifie l'identité d'une personne en comparant les données biométriques acquises avec le modèle biométrique de cette personne enregistré dans la base de données du système. Dans un tel mode, le système doit alors répondre à la question suivante : «Suis-je réellement la personne que je suis en train de proclamer ?».
1.6.3 Types D’erreurs d’un système biométrique
Pour comprendre comment déterminer la performance d’un système biométrique, il nous faut définir clairement trois critères principaux [10] :
Figure1.11 : La tâche de vérification d’un individu [22] Figure1.10 : La tâche d’identification d’un individu [22]
Taux de faux rejet (False Reject Rate ou FRR)
Ce taux représente le pourcentage de personnes censées être reconnues mais qui sont rejetées par le système,
Taux de fausse acceptation (False Accept Rate ou FAR)
Ce taux représente le pourcentage de personnes censées ne pas être reconnues mais qui sont tout de même acceptées par le système,
Taux d’égale erreur : (Equal Error Rate ou EER)
Ce taux est calculé à partir des deux premiers critères et constitue un point de mesure de performance courant. Ce point correspond à l’endroit où FRR = FAR, c’est-à-dire le meilleur compromis entre les faux rejets et les fausses acceptations (Figure1.12).
Ils existent d’autres critères, pour déterminer la performance d’un système biométrique, qui seront détaillées par la suite dans le Chapitre 4.
1.7 Les applications de la biométrie
L’authentification par la biométrie est utilisée dans tous les domaines nécessitant un accès contrôlé tels que celui des applications bancaires, les endroits hautement sécurisés comme les sièges du gouvernement, parlement, armée, service de sécurité…etc. Quant à la reconnaissance, elle est souvent utilisée par la police et les services d'immigration dans les aéroports, ainsi que dans la recherche de bases de données criminelles. On la retrouve aussi dans les applications civiles où l'authentification des cartes de crédit, de permis de conduire et des passeports est de plus en plus courante. Avec l'avènement d’Internet et sa
l’émergence du commerce électronique (E-commerce), tous les fournisseurs de produits et de ces services sont en train de fournir des efforts considérables afin de se sécuriser contre toutes les intrusions frauduleuses possibles [8].
Voici quelques exemples où nous pouvant utiliser la biométrie pour contrôler tout accès (Figure 1.13) :
Contrôle d'accès physiques aux locaux
Salle informatique, site sensible (service de recherche, site nucléaire, bases militaires...).
Contrôle d'accès logiques aux systèmes d'informations
Lancement du système d'exploitation, accès au réseau informatique, commerce électronique, transaction (financière pour les banques, données entre entreprises), tous les logiciels utilisant un mot de passe.
Equipements de communication
Terminaux d'accès à internet, téléphones portables…etc. Machines & Equipements divers
Coffre fort avec serrure électronique, distributeur automatique de billets, contrôle des adhérents dans un club, carte de fidélité, gestion et contrôle des temps de présence, voiture (anti démarrage) …etc.
1.8 Les limites des systèmes biométriques monomodaux
La réussite d’installation des systèmes biométriques dans diverses applications civiles, n’implique pas que la biométrie est un problème entièrement résolu. Il est clair qu’il y a beaucoup de possibilités pour l’amélioration dans la biométrie.
Les chercheurs n’abordent pas seulement les problèmes liés à la réduction des taux d’erreurs, mais ils essayent de voir d’autres façons pour améliorer la rentabilité des systèmes biométriques [7]. Les systèmes biométriques qui fonctionnent en utilisant n’importe qu’elles caractéristique seule (système biométrique monomodaux) ont les limites suivantes :
Le bruit sur la donnée capturée
La donnée capturée peut être bruyante ou endommagée. Une empreinte digitale avec une cicatrice ou une voix modifiée par le froid (le rhume) sont des exemples de données bruyantes. Elles pourraient être aussi le résultat d’un capteur défectueux ou mal entretenu (par exemple : accumulation de la saleté sur le capteur d’empreinte digitale) ou des conditions ambiantes défavorables (mauvais éclairage du visage d’un utilisateur dans un système de reconnaissance de visage) (Figure1.14).
La donnée bruyante peut être incorrectement comparée avec les modèles de la base de données ayant pour résultat un rejet incorrect de l’utilisateur.
Les variations d’intra-classe
Les données biométriques d’un individu acquises pendant la vérification peuvent être très différentes des données qui ont étaient employées pour générer le modèle pendant l’identification, cette variation est typiquement causée par un utilisateur qui agit incorrectement avec le capteur (Figure 1.15) ou quand les caractéristiques du capteur sont modifiées.
Figure1.14 : Effet des images bruyantes sur un système
Unicité
Tandis qu’on s’attend a ce qu’un trait biométrique change de manière significative a travers les individus, il peut y avoir de grandes similitudes d’interclasse dans les ensembles des caractéristiques employés pour représenter ces traits (Figure 1.16). Cette limitation limite la distinction fournie par le trait biométrique [11].
Non-universalité
Tandis qu’on s’attend a ce que chaque utilisateur possède le trait biométrique étant acquis. En réalité il est possible qu’un sous ensemble des utilisateurs ne possède pas une biométrie particulière.
Un système biométrique d’empreinte digitale, par exemple peut ne pas pouvoir extraire des caractéristiques à partir des empreintes digitales de certains individus, dû à la qualité inférieur des arêtes (Figure 1.17). Ainsi, il y a un taux d’échec d’inscription (EDI) associé avec l’utilisation d’un trait biométrique seul. On a empiriquement estimé que pas moins de 4% de la population peut avoir des arêtes d’empreinte digitale de qualité inférieure qui sont difficiles à être capturées par les capteurs d’empreintes digitales actuellement disponibles [6, 13, 14].
Figure 1.16 : Limite de discrimination du trait biométrique. Figure1.15 : Les variations d’intra-classes
Les attaques
Un imposteur peut essayer de mystifier le trait biométrique d’un utilisateur légitime inscrit afin de tromper le système. Ce type d’attaque est particulièrement approprié quand des traits comportementaux tels que la signature [9] et la voix [12] sont utilisés. Cependant les traits physiques sont également susceptibles aux attaques par exemple : on l’a démontré qu’il est possible (bien que difficile et encombrant et exige l’aide d’un utilisateur légitime) de construire des doigts ou des empreintes digitales artificielles dans un temps raisonnable pour mettre en échec le système de vérification d’empreinte digitale [15].
1.9 Conclusion
Dans ce chapitre, nous avons introduit le concept de la biométrie, modalités biométriques, le système biométrique, leurs caractéristiques, ses modes de fonctionnement et leurs différents domaines applications. Nous avons aussi souligné que les performances des systèmes biométriques dépendent de plusieurs critères et qu’ils varient d’un système à un autre. Enfin on a cité que les systèmes biométriques monomodaux ont des limites.
L’une des solutions pour améliorer les performances des systèmes biométriques était l’utilisation de plusieurs modalités biométriques, c'est pourquoi nous aborderons dans le chapitre suivant, la biométrie multimodale.
CHAPITRE 2
LA
2.1 Introduction
Bien que les techniques de reconnaissance biométrique promettent d’être très performantes, on ne peut garantir un excellent taux de reconnaissance avec des systèmes biométriques unimodaux, basés sur une unique modalité biométrique. De plus, ces systèmes sont souvent affectés par les problèmes suivants : Bruit introduit par le capteur, Non-universalité, Manque d’individualité, Manque de représentation invariante, Sensibilité aux attaques. Pour pallier ces inconvénients, une solution est l’utilisation de plusieurs modalités biométriques au sein d’un même système, on parle alors de système biométrique multimodal. Dans ce mémoire, le choix a été fait de combiner la modalité du visage avec celle de la voix.
2.2 Scénarios pour la fusion multimodale
Les systèmes biométriques multimodaux diminuent les contraintes des systèmes biométriques monomodaux en combinant plusieurs systèmes (Figure 2.1).
Figure 2.1 : Exemple d’un système multimodal.
Visage
Géométrie du main
Empreinte digitale
On peut différencier Cinq types de systèmes multimodaux selon les systèmes qu'ils combinent (Figure 2.2) :
a. Multi-capteurs
Correspondant à l’utilisation de plusieurs capteurs pour l’acquisition de la même modalité biométrique. Pour la reconnaissance du visage, par exemple, il est possible d’utiliser plusieurs caméras 2D, des capteurs 3D ainsi que des capteurs infra-rouges.
b. Multi-instances
Lorsqu’ils associent plusieurs instances de la même modalité, par exemple l'acquisition de plusieurs images de visage avec des changements de pose, d'expression ou d'illumination.
c. Multi-algorithmes
Utiliser différents algorithmes de reconnaissance sur la même modalité, par exemple, combiner les deux méthodes GMM (Gaussian Mixture Models) et SVM (Support Vecteur Machines) pour la reconnaissance du locuteur.
d. Multi-échantillons
C’est le cas où un même capteur est utilisé pour obtenir plusieurs variantes ou représentations complémentaires d’une seule modalité biométrique, par exemple, lors de la reconnaissance du visage en se basant sur les images du visage de face et selon les profils droit et gauche afin de prendre en compte les variations de la pose faciale.
Dans ce cas les données sont traitées par le même algorithme mais nécessitent des références différentes à l'enregistrement contrairement aux systèmes multi-instances qui ne nécessitent qu'une seule référence.
e. Multi-biométries
Utiliser en même temps plusieurs modalités biométrique du corps humain, par exemple, combiner le visage, les empreints digitales ainsi que la voix. Un système multimodal peut bien sûr combiner ces différents types d'associations, par exemple l'utilisation du visage et de l'empreinte mais en utilisant plusieurs doigts. Tous ces types de
systèmes peuvent pallier à des problèmes différents et ont chacun leurs avantages et inconvénients. Les quatre premiers systèmes combinent des informations issues d'une
seule et même modalité ce qui ne permet pas de traiter le problème de la non-universalité de certaines biométries ainsi que la résistance aux fraudes, contrairement aux systèmes "multi-biométries". En effet, les systèmes combinant plusieurs informations issues de la même biométrie permettent d'améliorer les performances en reconnaissance en réduisant l'effet de la variabilité intra-classe. Mais ils ne permettent pas de traiter efficacement tous les problèmes des systèmes monomodaux. C'est pour cette raison que les systèmes multi-biométries ont reçu beaucoup d'attention de la part des chercheurs [23].
2.3 Les modes de fonctionnement d’un système multimodal
Mode sériel
On exploite une source d’information biométrique à la fois, en cascade - acquisition les mesures de sources à différents moments
- utile comme technique d’indexation dans un système d’identification (avec grande base) permet de réduire le nombre d’identités qu’on explore avec la prochaine source, - permet de converger vers une seule identité avec la dernière source biométrique.
Mode parallèle
Chaque source est exploitée simultanément par un système indépendant - On acquiert tous les sources biométriques en même temps
Mode hiérarchique
C’est une extension du parallèle où chaque source est exploitée simultanément par un système indépendant. Mais, on combine un grand nombre de systèmes selon une structure en arbre.
2.4 Les architectures
Les systèmes multimodaux associent plusieurs systèmes biométriques et nécessitent donc l'acquisition et le traitement de plusieurs données. L'acquisition et le traitement peuvent se faire successivement, on parle alors d'architecture en série, ou simultanément, on parle alors d'architecture en parallèle. L'architecture est en réalité surtout liée au traitement. En effet, l'acquisition des données biométriques est en général séquentielle pour des raisons pratiques. Il est difficile d'acquérir en même temps une empreinte digitale et une image d'iris dans de bonnes conditions. Il existe cependant certains cas où les acquisitions peuvent être faites simultanément lorsque les différentes données utilisent le même capteur par exemple les capteurs d'empreintes multi-doigts qui permettent d'acquérir plusieurs doigts simultanément ou même les empreintes palmaires.
L'architecture est donc en général liée au traitement et en particulier à la décision. En effet la différence entre un système multimodal en série et un système multimodal en parallèle réside dans le fait d'obtenir un score de similarité à l'issue de chaque acquisition (fusion en série) ou de procéder à l'ensemble des acquisitions avant de prendre une décision (fusion en parallèle).
L'architecture en parallèle (Figure 2.2) est la plus utilisée car elle permet d'utiliser toutes les informations disponibles et donc d'améliorer les performances du système. En revanche, l'acquisition et le traitement d'un grand nombre de données biométriques est coûteux en temps et en matériel, et réduit le confort d'utilisation. C'est pour cela que l'architecture en série (Figure 2.3) peut être privilégiée dans certaines applications ; par exemple si la multimodalité est utilisée pour donner une alternative pour les personnes ne pouvant pas utiliser l'empreinte digitale. Pour la majorité des individus seule l'empreinte est acquise et traitée mais pour ceux qui ne peuvent pas être ainsi authentiqués on utilise un système à base d'iris alternativement.
2.5 Les niveaux de fusion
La combinaison de plusieurs systèmes biométriques peut se faire à quatre niveaux différents [7]: au niveau des données, au niveau des caractéristiques extraites, au niveau des scores issus du module de comparaison ou au niveau des décisions du module de décision (Figure 2.4).
Figure 2.3 : Architecture de fusion en série [23]. Figure 2.2 : Architecture de fusion en parallèle [23].
Ces quatre niveaux de fusion peuvent être classés en deux sous-ensembles : la fusion pré-classification (avant comparaison) et la fusion post-pré-classification (après la comparaison).
La fusion pré-classification
Correspond à la fusion des informations issues de plusieurs données biométriques au niveau du capteur (images brutes) ou au niveau des caractéristiques extraites par le module d'extraction de caractéristiques.
- La fusion au niveau du capteur ou des données brutes est relativement peu utilisée car elle nécessite une homogénéité entre les données. Par exemple il est possible de combiner plusieurs images de visages dans des canaux de couleurs différents ou en visible et en infrarouge s'ils correspondent à la même scène. Il est également possible de faire une mosaïque à partir d'images prises de différents points de vue.
- La fusion au niveau des caractéristiques est moins limitée par la nature des données biométriques. Cependant une certaine homogénéité est nécessaire pour la plupart des méthodes de fusion au niveau des caractéristiques comme par exemple la moyenne de plusieurs "templates" d'empreintes ou de visage. Un exemple de fusion au niveau des caractéristiques qui ne nécessitent pas vraiment d'homogénéité est la concaténation de plusieurs vecteurs de caractéristiques avant le traitement par l'algorithme de comparaison.
Les méthodes de fusion pré-classification sont assez peu utilisées car elles posent un certains nombre de contraintes qui ne peuvent être remplies que dans certaines applications très spécifiques.
la fusion post-classification
Cette fusion peut se faire au niveau des scores issus des modules de comparaison ou au niveau des décisions. Dans les deux cas, la fusion est en fait un problème bien connu de la littérature sous le nom de « Multiple Classifier systems ».
- La fusion au niveau des décisions est souvent utilisée pour sa simplicité. En effet, chaque système fournit une décision binaire sous la forme OUI ou NON que l'on peut représenter par 0 et 1, et le système de fusion de décisions consiste à prendre une décision finale en fonction de cette série de 0 et de 1. Les méthodes les plus utilisées sont des méthodes à base de votes telles que :
le OR (si un système a décidé 1 alors OUI),
le AND (si tous les systèmes ont décidé 1 alors OUI),
le vote à la majorité (si la majorité des systèmes ont décidé 1 alors OUI).
On peut également utiliser des méthodes plus complexes qui pondèrent les décisions de chaque sous-système ou qui utilisent des classifieurs dans l'espace de décisions telles que BKS (Behaviour Knowledge Space) [25]. Les méthodes de fusion au niveau des décisions sont très simples mais utilisent très peu d'information (0 ou 1) [24].
- La fusion au niveau des scores est le type de fusion le plus utilisé (Figure 2.5) car elle peut être appliquée à tous les types de systèmes (contrairement à la fusion pré-classification), dans un espace de dimension limité (un vecteur de scores dont la dimension
est égale au nombre de sous-systèmes), avec des méthodes relativement simples et efficaces mais traitant plus d'information que la fusion de décisions. La fusion de scores
consiste donc à la classification : OUI ou NON pour la décision finale, d'un vecteur de nombres réels dont la dimension est égale au nombre de sous-systèmes.
Dans ce mémoire, nous appliquons la fusion post-classification au niveau des scores. A ce niveau, les scores de chaque modalité sont combinés de manière à former un unique score qui est ensuite utilisé pour prendre la décision finale. Afin de s’assurer que la combinaison de scores provenant de différentes modalités soit cohérente, les scores doivent d’abord être transformés dans un domaine commun, on parle alors de la normalisation de scores.
2.6 Normalisation de scores
Les scores au niveau des sorties des modules de correspondances peuvent ne pas être homogènes. Par exemple, un module de correspondance peut donner en sortie une mesure de distance (dissimilarité) pendant qu’un autre donne en sortie une mesure de proximité (similarité). A cause de ces raisons, la normalisation de score est essentielle pour transformer les scores des modules de correspondances dans un domaine commun avant de les fusionner. La normalisation de score est une étape critique dans la conception d’un schéma de combinaison pour la fusion au niveau score.
Il existe plusieurs techniques de normalisation de scores, tel que : Min-Max, Z-score, Tanh, …etc.
Dans ce mémoire, nous utilisant la technique de normalisation la plus simple, qui est la normalisation Min-Max. Elle est la plus adaptée dans le cas où les bornes (valeurs minimales et maximales) des scores produits par le module de correspondance sont connues. Dans ce cas, on peut facilement translater les scores minimums et maximums respectivement vers 0 et 1.
𝐧 = 𝐬 − 𝐦𝐢𝐧(𝐒) 𝐦𝐚𝐱 𝐒 − 𝐦𝐢𝐧(𝐒)
Quand les valeurs minimales et maximales sont estimées à partir des données d’apprentissage, cette méthode n’est pas robuste (c’est à-dire que cette méthode est fortement sensible aux valeurs aberrantes dans les données utilisées pour l’estimation). La normalisation Min-Max conserve la distribution de scores originale à un facteur d’échelle près, et transforme tous les scores dans l’intervalle [0, 1] sous forme de score de similarité, c'est-à-dire, avec les clients proches de la borne supérieure (1) et les imposteurs proches de la borne inférieure (0).
- Mécanisme de Cohorte sans contrainte (Unconstraint Cohort Normalization) Les variations de données biométriques sont considérées comme un des problèmes principaux dans la fusion multimodale. Ces variations sont présentées dans le bruit, qui peut être présent dans les données biométriques acquises.
Bien que, UCN est montré des améliorations considérables à la performance des systèmes biométriques multimodaux sur des différentes conditions de données, où les scores mal classifiés sont éloignées de leur classe originale (clients/ Imposteurs). Alors, les scores mal classifiés de client seraient décalés vers la classe d'imposteur tandis que les scores mal classifiés d'imposteur seraient poussé vers la classe de client. Ceci réduit la chance de corriger les scores normalisés mal classifiés à l'étape de fusion. Donc UCN est très utile pour séparer entre les scores de clients et ceux des imposteurs.
2.7 Domaines d’application de la multimodalité
Dans de nombreux domaines, l’utilisateur est confronté à des sources d’informations multiples et hétérogènes. Il a donc été nécessaire de mettre en place des outils pour exploiter conjointement ces sources de données. Le concept de multimodalité répond à ce besoin. Nous proposons ici un tour d’horizon de plusieurs domaines dans lesquels la multimodalité a fait son apparition [26]:
Interfaces homme-machine
Le terme de multimodalité dans le domaine des interfaces homme-machine (IHM) se rattache aux interfaces multimodales. Ces dernières se basent sur le caractère multimodal de la communication humaine, avec par exemple l’utilisation combinée de la parole et de la gestuelle, et multisensoriel de l’être humain pour améliorer et rendre plus naturelle la communication homme-machine.
La multimodalité dans le domaine des IHM a ceci de particulier, contrairement aux autres domaines, elle apparaître pour les interfaces tant d’entrée que de sortie. Les interfaces d’entrées multimodales ont pour objectif de fiabiliser ou de rendre plus naturel le contrôle de la machine. Elles utilisent généralement les dispositifs classiques de commande (tels que clavier et souris), mais aussi la gestuelle ou encore la parole. Les interfaces de sorties multimodales visent, quant à elles, à tirer avantage des différentes modalités pour présenter des résultats à l’utilisateur.
Identification biométrique
L’identification biométrique consiste à identifier une personne au moyen de l’une de ses caractéristiques : voix, empreintes digitales, visage, signature…etc. Toutefois, un tel processus n’est pas infaillible et une personne mal intentionnée peut parvenir à contourner le processus d’identification. Afin de pallier un tel inconvénient, l’utilisation de plusieurs modalités a été proposée et développée dans de nombreux travaux. Le principe général est basé sur une prise de décision pour chaque modalité. Ces décisions partielles sont ensuite fusionnées pour aboutir à la décision finale.
Imagerie médicale
L’imagerie médicale offre désormais de multiples possibilités en termes d’observation du corps humain, que ce soit en imagerie 2D ou 3D. Les différentes technologies développées, de par leurs propriétés, permettent de visualiser des informations différentes mais souvent complémentaires, que ce soient des tissus, comme les vaisseaux sanguins ou l’activité cérébrale par exemple. L’imagerie médicale est cruciale pour poser un diagnostic, mais aussi pour la localisation de zones particulières, par exemple des tumeurs en vue d’une intervention chirurgicale. L’utilisation d’une seule technique peut cependant ne pas être suffisante, d’où la nécessité de combiner des clichés issus de plusieurs techniques en les alignant spacialement. Cette tâche est délicate, à la mesure de la précision requise. La combinaison des informations issues de ces différentes sources est généralement appelée alignement multimodal (multimodal registration), cette expression recouvrant les différentes techniques mises en œuvre pour atteindre cet objectif. Les modalités sont alors les différents types d’images à aligner [27]. L’alignement multimodal est généralement basé sur la maximisation de l’information mutuelle [28].
Télésurveillance
Le domaine de la télésurveillance, qu’elle soit à visée sécuritaire (surveillance de lieux publics) ou médicale (maintien de personnes à domicile), a pour objectif la détection de situations de crise par une analyse de l’environnement et de ses acteurs. Elle est de plus en plus utilisatrice de capteurs divers (caméras, microphones, capteurs de mouvements…) et nécessite donc l’emploi de techniques appropriées pour l’exploitation conjointe de ces dernières.
Analyse des contenus multimédias
Ces dernières années, la multimodalité a fait son apparition dans le domaine de l’analyse des contenus multimédias. L’une des premières applications en a sans doute été la reconnaissance audiovisuelle de la parole pour laquelle on utilise non seulement l’information sonore mais aussi les mouvements des lèvres pour reconnaître la parole.
2.8 Les avantages de la multimodalité biométrique
Problème de précision
- augmente la précision et la robustesse car on intègre plusieurs sources
d’informations biométriques indépendantes,
- peut atteindre le niveau précision ciblé par plusieurs applications. Problème de manque d’universalité
- la possibilité de capter efficacement pour une plus grande proportion de la population
Problème de vulnérabilité aux imposteurs
- il est plus difficile d’imiter plusieurs sources biométriques simultanément, - procédure d’authentification: on peut demander un sous-ensemble aléatoire de
2.9 Conclusion
Dans ce chapitre, nous avons parlé sur la fusion de plusieurs modalités biométriques, où nous citons, les différents scénarios pour la fusion multimodale, et aussi, les niveaux de fusion des scores de différentes modalités et leurs normalisations, ainsi que les avantages de ces systèmes.
Dans le chapitre suivant, nous nous intéresserons au Support Vector Machine (SVM), puisque ce dernier a été utilisé afin de fusionner les scores de différente modalité biométrique.
CHAPITRE 3
LES MACHINES
À VECTEUR
3.1 Introduction
L’enjeu essentiel de l’apprentissage artificiel est l’aptitude à généraliser des résultats obtenue à partir d’un échantillon limitée. Dans ce travail, nous choisissons la méthode à base des machines à vecteurs de support (SVM) comme un moyen opérationnel. Nous allons présenter dans ce chapitre le fondement théorique de cette méthode ainsi que sa mise en œuvre dans notre problème de fusion des modalités biométrique.
3.2 Apprentissage et classification
3.2.1 Notion d’apprentissage
L’apprentissage est l’acquisition de connaissances et compétences permettant la synthèse d’information [31]. Un algorithme d’apprentissage va permettre de passer d’un espace des exemples X à un espace dit des hypothèses H. L’algorithme SVM va explorer l’espace H pour obtenir le meilleur hyperplan séparateur.
L’apprentissage peut être supervisé, non supervisé, semi-supervisé ou par renforcement. Les SVM se situent dans le groupe des algorithmes d’apprentissage supervisés puisque qu’il a besoin d’une base d’exemples étiquetés pour générer la règle de classification.
Apprentissage supervisé
Dans ce type d'apprentissage, on cherche à estimer une fonction f(x) qui représente la relation entre la donnée et sa classe. Cette fonction est appelée fonction de décision.
X : L’ensemble des données à classifier (appelé espace d'entrée), Y : L’ensemble des classes (appelé espace d'arrivée).
Apprentissage non supervisé
Dans ce cas, on ne cherche pas à estimer une fonction mais, on cherche à regrouper les données ayant des caractéristiques communes.
3.2.2 Notion de classification
Effectuer une classification, c’est mettre en évidence, d’une part, des relations entre les données et, d’autre part les relations entre ces données et leurs paramètres. Il s’agit de construire une partition de l’ensemble des données en un ensemble de classes qui soient les plus homogènes possible. La classification, a donc deux objectifs à atteindre :
Trouver un modèle capable de représenter la répartition des données (catégorisation).
Définir de manière formelle l’appartenance à l’une ou l’autre des classes de toute nouvelle donnée (généralisation).
3.3 Les Machines à Vecteurs de Support (SVM)
Les Machines à Vecteurs de Support ou Support Vector Machines (SVM), appelé aussi Séparateur à Vaste Marge est une méthode de classification binaire par apprentissage supervisé, Ce sont des techniques discriminantes inspirées de la théorie statistique de l’apprentissage, elles ont été proposées en 1995 par V. Vapnik. Elles permettent d’aborder plusieurs problèmes divers et variés comme la régression, la classification, la fusion etc. [29]. Cette méthode repose sur l’existence d’un classificateur linéaire dans un espace approprié. Puisque c’est un problème de classification à de classes, cette méthode fait appel à un jeu de données d’apprentissage pour apprendre les paramètres du modèle. Elle est basée sur deux notions : celle de marge maximale et celle de fonction noyau (kernel) qui permet une séparation optimale des données.
Nous nous intéressons ici à l’application des SVM dans le domaine de la biométrie.
3.3.1 Notion de base
3.3.1.1 Hyperplan séparateur
Plaçons-nous dans le cas d’une classification binaire (les exemples à classifier réparties en deux classes). On appelle hyperplan séparateur un hyperplan qui sépare les deux classes, en particulier il sépare leurs points d’apprentissage. Comme il n’est en générale pas possible d’en trouver un, on se contentera donc de chercher un hyperplan discriminant qui est une approximation au sens d’un critère à fixer (maximiser la distance entre ces deux classes) [32,33].
3.3.1.2 Vecteur de support
Les éléments d’apprentissage les plus proches (les points de la frontière entre les deux classes des données) à l’hyperplan sont appelés vecteurs de support, car c'est uniquement sur ces éléments de l'ensemble d'apprentissage qu'est optimisée la séparatrice (Figure 3.2).
3.3.1.3
La marge
Il existe une infinité d’hyperplans capable de séparer parfaitement les deux classes d’exemples. Le principe des SVM est de choisir celui qui va maximiser la distance minimale entre l’hyperplan et les exemples d’apprentissage (i.e. la distance entre l’hyperplan et les vecteurs de support), cette distance est appelé la marge(Figure 3.3) [32].
Figure 3.3 : L’hyperplan optimal, vecteurs de support et marge
maximale
3.3.1.4
Fonction noyau
Cette méthode d'apprentissage supervisée peut apprendre un séparateur plus ou moins complexe selon la nature du noyau choisi. Le noyau le plus simple est le noyau linéaire qui correspond à chercher un séparateur linéaire dans l'espace à N dimensions des scores. Le but des fonctions noyau est de transformer l'espace initial (des scores à N dimensions) en un espace de dimension plus grande dans lequel les données pourraient être linéairement séparables. Le séparateur est donc toujours linéaire dans l'espace transformé par la fonction noyau, mais ne l'est plus dans l'espace des scores [33].
3.3.2 Principe de fonctionnement
Les SVM constituent une classe d’algorithmes basée sur le principe de minimisation de risque structurel décrit par la théorie de l’apprentissage statistique qui utilise la séparation linéaire. Cela consiste à séparer par un hyperplan des individus représentés dans un espace de dimension égale au nombre de caractéristiques, les individus étant alors séparés en deux classes. Cela est possible quand les données à classer sont linéairement séparables. Dans le cas contraire, les données seront projetées sur un espace de plus grande dimension afin qu’elles deviennent linéairement séparables.
3.3.3 Propriétés fondamentales
La maximisation de la marge
Intuitivement, le fait d'avoir une marge plus large procure plus de sécurité lorsqu’on classe un nouvel individu. De plus, si l’on trouve le classificateur qui se comporte le mieux vis-à-vis des données d'apprentissage, il est clair qu’il sera aussi celui qui permettra au mieux de classer les nouveaux individus (Figure 3.4).
![Figure 1.2 : La Classification De La Biométrie [7].](https://thumb-eu.123doks.com/thumbv2/123doknet/2314869.27576/19.893.133.850.126.416/figure-classification-de-biometrie.webp)





![Figure 2.2 : Les différents systèmes multimodaux [23].](https://thumb-eu.123doks.com/thumbv2/123doknet/2314869.27576/33.892.179.853.219.724/figure-systemes-multimodaux.webp)
![Figure 2.3 : Architecture de fusion en série [23]. Figure 2.2 : Architecture de fusion en parallèle [23]](https://thumb-eu.123doks.com/thumbv2/123doknet/2314869.27576/36.892.182.867.126.433/figure-architecture-fusion-serie-figure-architecture-fusion-parallele.webp)
