Data-Mining Natural Language Materials Syntheses
by
Edward Soo Kim
B.S., Nanoscience, University of Guelph (2014)
Submitted to the Department of Materials Science and Engineering
in partial fulfillment of the requirements for the degree of
Doctor of Philosophy in Materials Science and Engineering
at the
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
June 2019
c
○ Massachusetts Institute of Technology 2019. All rights reserved.
Author . . . .
Department of Materials Science and Engineering
February 26, 2019
Certified by . . . .
Elsa Olivetti
Atlantic Richfield Associate Professor of Energy Studies
Thesis Supervisor
Accepted by . . . .
Donald Sadoway
Chairman, Department Committee on Graduate Students
Data-Mining Natural Language Materials Syntheses
by
Edward Soo Kim
Submitted to the Department of Materials Science and Engineering on February 26, 2019, in partial fulfillment of the
requirements for the degree of
Doctor of Philosophy in Materials Science and Engineering
Abstract
Discovering, designing, and developing a novel material is an arduous task, in-volving countless hours of human effort and ingenuity. While some aspects of this process have been vastly accelerated by the advent of first-principles-based com-putational techniques and high throughput experimental methods, a vast ocean of untapped historical knowledge lies dormant in the scientific literature. Namely, the precise methods by which many inorganic compounds are synthesized are recorded only as text within journal articles. This thesis aims to realize the potential of this data for informing the syntheses of inorganic materials through the use of data-mining algorithms. Critically, the methods used and produced in this thesis are fully automated, thus maximizing the impact for accelerated synthesis planning by human researchers. There are three primary objectives of this thesis: 1) aggregate and codify synthesis knowledge contained within scientific literature, 2) identify synthesis “driving factors” for different synthesis outcomes (e.g., phase selection) and 3) autonomously learn synthesis hypotheses from the literature and extend these hypotheses to predicted syntheses for novel materials.
Towards the first goal of this thesis, a pipeline of algorithms is developed in order to extract and codify materials synthesis information from journal articles into a structured, machine readable format, analogous to existing databases for materials structures and properties. To efficiently guide the extraction of materials data, this pipeline leverages domain knowledge regarding the allowable relations between different types of information (e.g., concentrations often correspond to solutions). Both unsupervised and supervised machine learning algorithms are also used to rapidly extract synthesis information from the literature.
To examine the autonomous learning of driving factors for morphology selection during hydrothermal syntheses, TiO2 nanotube formation is found to be correlated
with NaOH concentrations and reaction temperatures, using models that are given no internal chemistry knowledge. Additionally, the capacity for transfer learning is
shown by predicting phase symmetry in materials systems unseen by models during training, outperforming heuristic physically-motivated baseline stratgies, and again with chemistry-agnostic models. These results suggest that synthesis parameters possess some intrinsic capability for predicting synthesis outcomes.
The nature of this linkage between synthesis parameters and synthesis outcomes is then further explored by performing virtual synthesis parameter screening using generative models. Deep neural networks (variational autoencoders) are trained to learn low-dimensional representations of synthesis routes on augmented datasets, created by aggregated synthesis information across materials with high structural similarity. This technique is validated by predicting ion-mediated polymorph selec-tion effects in MnO2, using only data from the literature (i.e., without knowledge
of competing free energies). This method of synthesis parameter screening is then applied to suggest a new hypothesis for solvent-driven formation of the rare TiO2
phase, brookite.
To extend the capability of synthesis planning with literature-based generative mod-els, a sequence-based conditional variational autoencoder (CVAE) neural network is developed. The CVAE allows a materials scientist to query the model for syn-thesis suggestions of arbitrary materials, including those that the model has not observed before. In a demonstrative experiment, the CVAE suggests the correct pre-cursors for literature-reported syntheses of two perovskite materials using training data published more than a decade prior to the target syntheses. Thus, the CVAE is used as an additional materials synthesis screening utility that is complementary to techniques driven by density functional theory calculations.
Finally, this thesis provides a broad commentary on the status quo for the report-ing of written materials synthesis methods, and suggests a new format which im-proves both human and machine readability. The thesis concludes with comments on promising future directions which may build upon the work described in this document.
Thesis Supervisor: Elsa Olivetti
Acknowledgments
I’d first like to thank my thesis committee, my sponsors, and MIT libraries, as this thesis could not exist without them.
In addition to the aforementioned parties, a great number of people have supported me through this thesis. I’d like to thank:
∙ my labmates, classmates, research colleagues, and project collaborators, for forming an inspiring research community,
∙ my teachers, both in graduate school and prior to that, for providing me with the skills to research interesting questions,
∙ my project group members {Alex, Kevin, Zach}, for the solid team efforts in solving exciting (and often baffling) technical challenges,
∙ my friends (too many to name here!), for keeping me sane and reminding me to have a life outside of work,
∙ my bros {Akram, Bryan, Chris, Marko, Mike}, for always being a sounding board for all of life’s problems,
∙ my advisor, Elsa, for her infinite compassion and patience along with her un-paralleled scientific insight,
∙ my parents and siblings {Jong, Yeonhee, Dan, Sarah}, for encouraging me to push myself beyond my limits,
∙ and my partner, Danya, for always being my teammate through the glorious wins and the bitter losses.
Contents
1 Conceptual Groundwork for Data-Driven Materials Synthesis 11
1.1 Introduction . . . 11
1.1.1 Goals and Key Results of the Thesis . . . 11
1.2 Synthetically-Accessible Materials and Synthesis Routes . . . 14
1.3 Data-Driven Materials Science . . . 15
1.3.1 High-Throughput and Combinatorial Screening . . . 16
1.3.2 Theoretical and Computational Screening . . . 16
1.3.3 Materials Fingerprints and Representations . . . 17
1.3.4 Text-Mining Materials Data . . . 17
1.3.5 The Literature Gap . . . 19
1.4 Structure of the Thesis . . . 20
2 Materials Synthesis in the Framework of Statistical Learning 24 2.1 Introduction . . . 24
2.2 Representations of Synthesis Routes . . . 25
2.2.1 Synthesis as a Directed Graph of Reactions . . . 25
2.2.2 Approximate Synthesis Representations . . . 25
2.3 Synthesis Schema for Natural Language Synthesis Routes . . . 26
2.3.1 Vector Representations of Text . . . 26
2.3.2 Identifying Synthesis Descriptions . . . 27
2.3.3 Named Entity Recognition for Materials Synthesis . . . 27
2.4 Discriminative and Generative Models for Synthesis Insight . . . 28
2.4.1 Classifying Synthesis-Product Relationships . . . 28
2.4.2 Generating Novel Synthesis Parameters . . . 28
2.5 Conclusions . . . 29
3 Predictive Models for Synthesis Information Extraction 31 3.1 Introduction . . . 31
3.2 Word Representations and Context-Sensitive Text Classification . . . 34
3.2.1 Article Retrieval . . . 34
3.2.2 Learning Word Representations . . . 34
3.2.3 Text Classification and Extraction . . . 35
3.3 Veracity of Extracted Syntheses . . . 36
3.4 Public Data Availability . . . 41
3.5 Conclusions . . . 41
4 Data Mined Synthesis-Product Relations 46 4.1 Introduction . . . 46
4.2 Quantitative Synthesis Trends in the Literature . . . 48
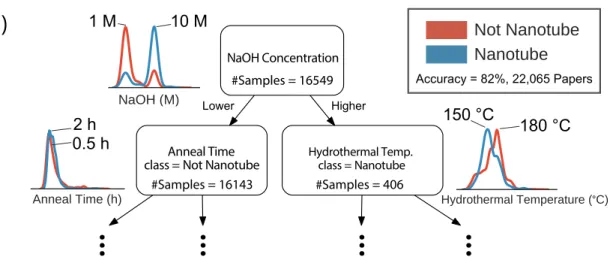
4.3 Conditions for Titania Nanotube Formation . . . 51
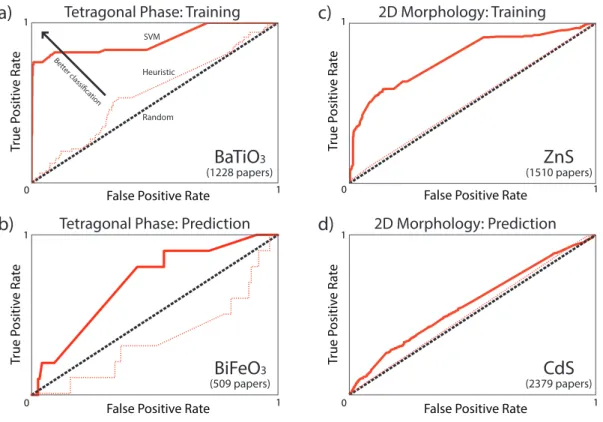
4.4 Transfer Learning Across Related Compounds . . . 54
4.5 Conclusions . . . 58
5 Synthesis Parameter Screening with Variational Autoencoders 63 5.1 Introduction . . . 63
5.2 Comparing Dimensionality Reduction Methods . . . 65
5.3 Data Scarcity, Sparsity, and Augmentation . . . 69
5.4 Synthesis Generation and Adversarial Screening . . . 76
5.5 Exploratory Latent Spaces for Synthesis Insight . . . 79
5.6 Conclusions . . . 82
6 Flexible Synthesis Prediction with Conditional Generative Models 89 6.1 Introduction . . . 89
6.2 Unsupervised Learning of Conditional Syntheses . . . 91
6.3 Synthesis Predictions for Unseen Materials . . . 96
6.4 Methods . . . 100
6.5 Model Validation . . . 102
6.6 Conclusions . . . 108
7 Outlook and Conclusions 113 7.1 Future Outlook . . . 113
7.1.1 Extracting Synthesis Knowledge from the Literature . . . 114
7.1.2 Outlook for Data-Driven Synthesis Planning . . . 122
7.2 Conclusions . . . 125
8 Appendix 128 8.1 Practical NLP for Materials Science Text . . . 128
List of Figures
1-1 Overall schematic diagram describing thesis methods . . . 13
3-1 Schematic overview of text extraction and database construction . . 33
3-2 Topic and synthesis target distributions within the database . . . 38
3-3 Top occurring material mentions per target material system . . . 39
3-4 Temperature and time distributions for titania . . . 40
4-1 Synthesis parameter distributions across metal oxide systems. . . 49
4-2 Autonomously learned decision boundaries for titania nanotubes. . . 52
4-3 Machine-learned classifiers and predictions across materials systems. 55 5-1 Schematic setup for variational autoencoder architecture . . . 66
5-2 Data augmentation for enabling deep learned synthesis parameter representations . . . 70
5-3 Setup and results for realistic synthesis data generation . . . 75
5-4 Latent space for TiO2 synthesis vectors and MnO2 synthesis vectors . 78 6-1 Schematic diagram of the CVAE architecture. . . 91
6-2 Graph representation of a phase diagram for InWO3 precursor chem-ical space . . . 96
6-3 Unsynthesized ABO3 perovskite compounds, labelled by their A-site and B-site elements. . . 99
6-5 Learning curves using feed-forward, fully connected one-hidden-layer autoencoders. . . 104 6-6 Conditional outputs generated by the model. . . 105 6-7 Projections of three example generated precursors in degenerate
la-tent space. . . 106 6-8 Latent citation nearest-neighbor schematic for synthesis actions. . . . 107 7-1 Lexical complexity literature syntheses. . . 116 7-2 A prototypical annotated synthesis excerpt . . . 119 7-3 Restructuring written recipes. . . 122
List of Tables
3.1 In-domain word categories and examples . . . 37 3.2 Schema of data records . . . 42 5.1 Prediction accuracies for determining correct synthesis target between
syntheses of SrTiO3 and BaTiO3. . . 68
5.2 Examples of literature-reported synthesis parameters and VAE-generated synthesis parameters for SrTiO3 synthesis. . . 77
6.1 Generated precursors for InWO3and PbMoO3, drawn from the CVAE
model. . . 93 6.2 NER model confusion matrix for test-set predictions. . . 103 6.3 Generated syntheses for InWO3 and PbMoO3, drawn from the CVAE
model. . . 104 6.4 Generated synthesis recipes for HgZrO3, drawn from the CVAE model. 106
Chapter 1
Conceptual Groundwork for
Data-Driven Materials Synthesis
This chapter serves as an introduction to the motivating perspectives, literature, and opportunities for this thesis. First, the goals of the thesis are summarized, along with the key results. After a brief conceptual introduction to materials syn-thesis, a survey of ongoing research efforts across the field is presented, including experimental, theoretical, and computational approaches to data-driven materials science. This discussion is followed by an explicit outline of the knowledge gap which this thesis seeks to fill. This introductory chapter also serves as a starting point for the reader by highlighting the main results of the other thesis chapters, and this chapter ends with an overview of the thesis structure.
1.1
Introduction
1.1.1
Goals and Key Results of the Thesis
1. Aggregate and codify synthesis knowledge contained within scientific litera-ture,
2. Identify synthesis “driving factors” for the selection between synthesis out-comes (e.g., phase selection),
3. Autonomously learn synthesis hypotheses from the literature and extend these to predicted syntheses for novel materials.
In the pursuit of these goals, this thesis explores a variety of critical questions re-garding the synthesis of various materials using the lens of data driven algorithms. A framework for automatically data-mining the materials science literature and ex-tracting synthesis insights is shown in Figure 1-1. A database of text-mined syn-thesis methods is first developed using natural language processing techniques. This unique, high volume source of knowledge is then used to investigate synthesis trends for a variety of inorganic materials syntheses: The driving factors for tita-nia nanotube formation via hydrothermal syntheses are uncovered by automated selection of synthesis variables. The synthesis of titania is then further examined by considering reported syntheses of the rare metastable phase, brookite. Possi-ble solvent-based driving factors for brookite phase selection are proposed by using unsupervised clustering algorithms trained on literature-reported synthesis param-eters across tens of thousands of titania syntheses. Ion-mediated phase selection are also uncovered for the case of MnO2 polymorphs, and the selection effects
un-covered by literature-driven models is found to be in strong agreement with den-sity functional theory (DFT) computations. The capacity for unsupervised transfer learning of chemically motivated synthesis patterns (e.g., solubility rules) is then ex-plored, and literature-based synthesizability screening is used to complement DFT computations for discovering novel, stable ABO3 perovskites. Finally, the structure
of synthesis ontologies is presented and a proposal for an alternative method of communicating experimental syntheses in the literature is proposed.
Numerical Text Encoding
Word2Vec
FastText
ELMo
Journal Articles (XML)
Journal Articles (HTML)
Recurrent Nets
Dependency
Parsers
Annotated Data
Text Classification & Extraction
Decision Trees
Support Vector
Machines
Text-mined Data
Synthesis Trend Discovery
Variational
Autoencoders
Support Vector
Machines
Generated Data
Virtual Synthesis Screening
Figure 1-1. Overall schematic diagram describing thesis methods. The key
methodological steps, algorithms, and data used in this thesis are highlighted. The automated workflow developed in the thesis is shown by the arrows, which demon-strates the connection between scientific literature and synthesis insights.
1.2
Synthetically-Accessible Materials and Synthesis
Routes
For any given collection of atoms, there is a thermodynamically stable equilibrium ground state corresponding to
𝜃* = arg min
𝜃
𝐺(𝜃)
where 𝜃 specifies the state of the material (e.g., atomic configuration, temperature) and 𝐺 is free energy.1,2 However, in practice, there exist additional states at local minima of 𝐺,
{𝜃𝑖′}𝑛, 𝜃′ 𝑖 ̸= 𝜃
* ∀𝑖,
𝑛 ∈ N
that can be realized under typical real-world conditions and timescales. Such local minimum states where 𝐺(𝜃′
𝑖) > 𝐺(𝜃
*)are said to be metastable.3 Thus, {𝜃*} ∪ {𝜃′ 𝑖}𝑛
represents the full set of synthetically-accessible materials for a given materials sys-tem.
Systematically and comprehensively traversing all local minima of 𝐺 is tremen-dously difficult, since the number of potential states is infinite for practical pur-poses.4? Moreover, there are few principled methods for determining a priori whether
or not a state 𝜃 is synthetically accessible under practical conditions. Although small magnitudes of metastability (also known as the distance to a convex hull) offer use-ful guidelines for screening candidate materials to synthesize,5,6
this is indeed not a sufficient condition for determining real-world synthetic acces-sibility.3
Beyond the challenge of identifying synthetically-accessible materials, another prob-lem arises as a corollary: How can these materials be accessed? We seek a synthesis route 𝑆 that transforms 𝑚 known precursor materials {𝜃𝑖𝑝}𝑚 into a desired target
material 𝜃𝑡 ∈ {𝜃*} ∪ {𝜃𝑖′}𝑛,
𝑆(𝜃𝑝1, . . . , 𝜃𝑚𝑝) = 𝜃𝑡
where 𝜃𝑡 may not necessarily be the sole output of a synthesis route, as waste and
byproduct materials are also generated by 𝑆. There is no general approach for uncovering the nature of 𝑆 for arbitrary materials, and there are often multiple valid definitions of 𝑆 for accessing the same 𝜃𝑡.4,7Nonetheless, numerous advances
in theoretical,8,9 experimental,10–12and data-driven4,5,13–15techniques have
signifi-cantly accelerated the discovery of novel materials and their synthesis routes, and this thesis builds upon these prior works.
1.3
Data-Driven Materials Science
In a sense, all science is “data-driven,” as the scientific method is driven by empir-ical observations and the validation (or rejection) of hypotheses. For the purpose of this section and this thesis, “data-driven” refers to high-throughput, and partially (or wholly) automated use of data to derive scientific insight, whether by computa-tional or experimental methods.
1.3.1
High-Throughput and Combinatorial Screening
One method of screening materials is to examine a neighborhood of closely related definitions for 𝑆, which belong to the same category of synthesis methods but differ in their reaction conditions. For example, thin film sputtering syntheses may be performed in parallel with varying compositions and atmospheric conditions syn-thesized simultaneously.11 More generally, by using specialized equipment adapted
for rapid parallel synthesis and characterization of materials, a large set of mate-rial states 𝜃 may be sampled all at once, allowing for significantly faster results compared to traditional one-by-one synthesis methods.10,16
More recently, guided search of experimental parameters has been achieved by leveraging machine learning techniques in experimental settings.12,17 Combining
iterative machine learning (i.e., online or active learning) with experimental feed-back in this manner allows for efficient screening and optimization of materials with fewer sampling attempts.18
1.3.2
Theoretical and Computational Screening
A contrasting approach to materials screening is to consider a broad set of 𝜃 and suppose that an appropriate 𝑆 may exist if 𝜃 satisfies a particular constraint. A common choice for such a constraint is the aforementioned distance to convex hull, or magnitude of metastability. Indeed, formation energies computed by both machine-learned and density functional theory methods have been used to screen for potentially-synthesizable materials.5,6,9
Additionally, robust computational synthesis screening has been achieved for small organic molecules using reinforcement learning and Monte Carlo tree search,4,14
but similarly robust methods have not yet been produced for inorganic synthesis screening. Nonetheless, progress towards this goal has been made by using broad thermodynamic reasoning19,20and machine learning.21,22
1.3.3
Materials Fingerprints and Representations
A critical step towards applying and accelerating data-driven materials science is developing an appropriate numerical representation for materials, which generally corresponds to finding a function 𝑓 : 𝜃 ↦→ R𝑛.23 Indeed, in much the same way
that generalized word embeddings have accelerated a plethora of natural language processing (NLP) research areas,24 the same benefit may be achieved by
general-ized materials representations. Unlike other application domains where data repre-sentations are either unambiguous25 or have become canonicalized,26,27 materials
representations are still nascent and rapidly changing.
While small organic molecules may be represented as SMILES character strings28
or graphs29, inorganic materials cannot always easily be represented in such forms.
For bulk crystalline materials, compositional encodings15, band structure finger-prints,13 and multiply-connected graphs5 have each been shown as effective
meth-ods for producing representations that enable accurate machine-learned property predictions. However, the development of representations which can efficiently extend to amorphous, composite, and nanostructured materials remains an active area of research.
1.3.4
Text-Mining Materials Data
Not all materials science data is tabulated in machine-readable archives. Vast quan-tities of synthesis methods, reports of device performances, and historical failures are recorded only in natural language sources. Raccuglia et al. have shown that lab-oratory notebooks can provide an effective source of failed experimental protocols, which can then be used to train a machine learning algorithm for predicting exper-imental success.12 While the task of manually converting laboratory notebooks into
a machine readable format is tedious, enabling access to “negative” data allows for algorithms to distinguish between successful and failed experiments. This contrast
in experimental results is generally not available in the published literature, as there is a tendency in most disciplines to only publish “positive” results.
Additionally, Ghadbeigi et al. show that manual collection of data from the litera-ture unlocks new insights into device performances of electrode materials.30 Again,
human-guided data extraction is used in this study, and the volume of manually extracted data is relatively consistent with the work by Raccuglia et al. discussed previously. The practical upper bound for human-driven data extraction from sci-entific documents is, in some cases, no larger than a few thousand data points. Notably, it is often not practical to scale data extraction to non-expert individuals, as substantial domain knowledge is typically required for annotation of scientific text.?
To achieve scales far beyond human-driven text extraction, NLP algorithms have recently been applied. In one example, Young et al. use NLP algorithms combined with crowdsourcing to establish a large database of processing-property relation-ships for pulsed laser deposition syntheses of oxide films.31 In the field of
chem-istry, a number of NLP pipelines have been developed for identifying experimental parameters, named entities (i.e., chemical compounds), and characterization pa-rameters.32–34However, these algorithms are seldom directly applicable to materials
science text, due to subtle differences in the writing and formatting styles between chemistry and materials science.35
The work in this thesis has partially focused on advancing NLP and machine learn-ing methods for materials science, by developlearn-ing domain-adapted word represen-tations and named entity recognition algorithms,36 along with machine learning
1.3.5
The Literature Gap
To summarize the context of this thesis and the opportunities upon which the thesis is motivated, the following list of literature gaps is provided. Each boldface item denotes a concept which was not directly addressed or present in the literature at the outset of this thesis.
1. Broader scope for materials synthesis screening. While high-throughput
methods can effectively probe a “volume” of materials design space, this space is necessarily “local” as one is limited by discontinuous barriers between ex-perimental methods (such as hydrothermal versus solid state syntheses), or practical limits pertaining to the amount of experiments that can be run in a single laboratory.10,11,16
2. Machine learning for materials without guiding physical theories.
Al-though machine learning has been harnessed to screen materials by training on data computed by density functional theory, an analogously broad first principles technique does not exist for inorganic materials synthesis.5,6,9
3. Materials synthesis representations. Representations for materials, based
on chemistry or crystal structure, have been explored using a variety of math-ematical objects including graphs and discretized “fingerprints.” However, similar representations for synthesis routes and parameters have not been ex-plored in this manner.5,13,15
4. NLP for (inorganic) materials science. NLP algorithms for chemistry have
a long history of success, but many of these algorithms used hand-crafted patterns or highly-tailored training data which cannot transfer to the domain of inorganic materials science text.32–34
1.4
Structure of the Thesis
Chapter 1 (this chapter) provides background knowledge for understanding the contributions and results of this thesis in the context of the relevant literature. Chapter 2 presents an overview of the technical methods used throughout the the-sis. Chapter 3 describes text-mining algorithms used to extract and codify synthesis information from the literature. Chapter 4 presents data-mined results from a cod-ified synthesis database. Chapter 5 discusses novel data augmentation and deep learning techniques for generating synthesis parameters. Chapter 6 presents a gen-erative model for literature-based synthesis planning of novel materials. Chapter 7 outlines the overall conclusions and future outlook for this thesis.
Bibliography
[1] M. Jansen, Adv Mater27, 3229 (2015), ISSN 1521-4095.
[2] M. Jansen, Pure Appl Chem86, 883 (2014), ISSN 0033-4545.
[3] W. Sun, S. T. Dacek, S. P. Ong, G. Hautier, A. Jain, W. D. Richards, A. C. Gamst, K. A. Persson, and G. Ceder, Science Advances2, e1600225 (2016).
[4] M. H. Segler, M. Preuss, and M. P. Waller, Nature555, 604 (2018).
[5] T. Xie and J. C. Grossman, Physical Review Letters120, 145301 (2018).
[6] P. V. Balachandran, A. A. Emery, J. E. Gubernatis, T. Lookman, C. Wolverton, and A. Zunger, Physical Review Materials2, 043802 (2018).
[7] E. Kim, K. Huang, A. Saunders, A. McCallum, G. Ceder, and E. Olivetti, Chemistry of Materials29, 9436 (2017).
[8] A. Jain, S. P. Ong, G. Hautier, W. Chen, W. D. Richards, S. Dacek, S. Cholia, D. Gunter, D. Skinner, G. Ceder, et al., APL Materials1, 011002 (2013).
[9] S. Kirklin, J. E. Saal, B. Meredig, A. Thompson, J. W. Doak, M. Aykol, S. Rühl, and C. Wolverton, npj Computational Materials1, 15010 (2015).
[10] R. Potyrailo, K. Rajan, K. Stoewe, I. Takeuchi, B. Chisholm, and H. Lam, ACS combi-natorial science13, 579 (2011).
[11] C. Suh, C. Gorrie, J. Perkins, P. Graf, and W. Jones, Acta Materialia59, 630 (2011).
[12] P. Raccuglia, K. C. Elbert, P. D. Adler, C. Falk, M. B. Wenny, A. Mollo, M. Zeller, S. A. Friedler, J. Schrier, and A. J. Norquist, Nature533, 73 (2016).
[13] O. Isayev, D. Fourches, E. N. Muratov, C. Oses, K. Rasch, A. Tropsha, and S. Curtarolo, Chemistry of Materials27, 735 (2015).
[14] C. W. Coley, R. Barzilay, T. S. Jaakkola, W. H. Green, and K. F. Jensen, ACS Central Science3, 434 (2017).
[15] B. Meredig, A. Agrawal, S. Kirklin, J. E. Saal, J. Doak, A. Thompson, K. Zhang, A. Choudhary, and C. Wolverton, Physical Review B89, 094104 (2014).
[17] J. M. Granda, L. Donina, V. Dragone, D.-L. Long, and L. Cronin, Nature 559, 377
(2018).
[18] J. Ling, M. Hutchinson, E. Antono, S. Paradiso, and B. Meredig, Integrating Materials and Manufacturing Innovation6, 207 (2017).
[19] M. Aykol, S. S. Dwaraknath, W. Sun, and K. A. Persson, Science Advances4, eaaq0148
(2018).
[20] W. Sun, A. Holder, B. Orvañanos, E. Arca, A. Zakutayev, S. Lany, and G. Ceder, Chem-istry of Materials29, 6936 (2017).
[21] M. Aykol, V. I. Hegde, S. Suram, L. Hung, P. Herring, C. Wolverton, and J. S. Hum-melshøj, arXiv preprint arXiv:1806.05772 (2018).
[22] E. Kim, K. Huang, S. Jegelka, and E. Olivetti, npj Computational Materials 3, 53
(2017).
[23] L. M. Ghiringhelli, J. Vybiral, S. V. Levchenko, C. Draxl, and M. Scheffler, Physical review letters114, 105503 (2015).
[24] T. Mikolov, K. Chen, G. Corrado, and J. Dean, arXiv preprint arXiv:1301.3781 (2013). [25] D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. Van Den Driessche, J. Schrit-twieser, I. Antonoglou, V. Panneershelvam, M. Lanctot, et al., nature529, 484 (2016).
[26] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, in Advances in neural information processing systems (2014), pp. 2672–2680.
[27] Y. Taigman, M. Yang, M. Ranzato, and L. Wolf, in Proceedings of the IEEE conference on
computer vision and pattern recognition (2014), pp. 1701–1708.
[28] R. Gómez-Bombarelli, J. N. Wei, D. Duvenaud, J. M. Hernández-Lobato, B. Sánchez-Lengeling, D. Sheberla, J. Aguilera-Iparraguirre, T. D. Hirzel, R. P. Adams, and A. Aspuru-Guzik, ACS Central Science4, 268 (2018).
[29] D. Duvenaud, D. Maclaurin, A. Jorge, G. Rafael, T. Hirzel, A. Alán, and R. P. Adams (2015).
[30] L. Ghadbeigi, J. K. Harada, B. R. Lettiere, and T. D. Sparks, Energy Environ Sci 8,
1640 (2015), ISSN 1754-5692.
[31] S. R. Young, A. Maksov, M. Ziatdinov, Y. Cao, M. Burch, J. Balachandran, L. Li, S. Som-nath, R. M. Patton, S. V. Kalinin, et al., Journal of Applied Physics 123, 115303
(2018).
[32] L. Hawizy, D. M. Jessop, N. Adams, and M. Peter, J Cheminformatics3, 1 (2011), ISSN
1758-2946.
[33] T. Rocktäschel, M. Weidlich, and U. Leser, Bioinformatics28, 1633 (2012), ISSN
[34] M. C. Swain and J. M. Cole, Journal of chemical information and modeling56, 1894
(2016).
[35] E. Kim, K. Huang, A. Tomala, S. Matthews, E. Strubell, A. Saunders, M. Andrew, and E. Olivetti, Sci Data4, sdata2017127 (2017), ISSN 2052-4463.
[36] E. Kim, K. Huang, A. Tomala, S. Matthews, E. Strubell, A. Saunders, A. McCallum, and E. Olivetti, Scientific Data4, 170127 (2017).
Chapter 2
Materials Synthesis in the
Framework of Statistical Learning
2.1
Introduction
In this chapter, we briefly explore materials synthesis from the perspective of sta-tistical learning. More specifically, we consider definitions, sub-problems, and algo-rithms which are relevant to data-driven predictive materials synthesis. We high-light several materials informatics challenges explored in this thesis, and discuss their representation as statistical learning tasks. While this chapter does not directly address any of the thesis goals, it provides a shared methodological background by which the thesis goals are achieved. The mathematical notations used in this chap-ter are intended to be consistent with articles published based on the results of this thesis.1–3
2.2
Representations of Synthesis Routes
2.2.1
Synthesis as a Directed Graph of Reactions
Recent work in chemical informatics has framed the representation of small-molecule organic synthesis as a directed graph of different compounds.4,5In such a
represen-tation, a synthesis graph 𝐺 is composed of a set of molecules 𝑉 = {𝑚}, which may be precursors, intermediates, or the final target, along with a set of directed reac-tion edges 𝐸 = {𝑟}. Thus, the complete path of transformareac-tions from precursors to final product can be determined by traversing 𝐺.
While an identical representation is theoretically valid for the syntheses of inorganic materials, it is intractable in practice. Seldom do inorganic syntheses measure or report intermediate states, unless characterization is being performed in situ. Thus, for a graph 𝐺𝑖 which represents inorganic syntheses, we consider an augmented
set of vertices 𝑉𝑖 = {𝑚} ∪ {𝑜}, where {𝑜} are unit operations (e.g., calcination).
Consequently, the directed reaction edges 𝐸𝑖 = {𝑟} denote inputs and outputs to
unit operations. Typically, for most syntheses of solid inorganic materials, precur-sors and solvents are specified along with operations (usually in a linear order) and a final synthesized set of products.1 Although the change in mathematical
repre-sentation is subtle, the essential difference is that 𝐺 emphasizes traversal through intermediate physical and chemical states, while 𝐺𝑖 emphasizes traversal through
externally applied in-lab operations.
2.2.2
Approximate Synthesis Representations
Inferring connected graphs of synthesis information from natural language text is a difficult one-shot problem, and recent approaches have not yet attained human-level accuracies.6Accordingly, this thesis uses two different approximations for
1. “Bag of synthesis parameter” vectors are used where each synthesis is defined as a vector of 𝑛 distinct, unordered synthesis variables (e.g., sintering temper-ature): 𝑆bag = R𝑛. This definition is used in Chapters 4 and 5.
2. Synthesis routes are also defined as a linear chain of actions (𝑎𝑘)𝑛acting upon
a set of precursors {𝑝𝑗}𝑙 to produce a final synthesized target material 𝑚:
𝑆𝑚
chain =(︀(𝑎𝑘)𝑛, {𝑝𝑗}𝑙)︀. This definition is used in Chapter 6.
2.3
Synthesis Schema for Natural Language
Synthe-sis Routes
2.3.1
Vector Representations of Text
In order to apply numerical methods to human-readable natural language text, it is a necessary step to first convert words into numerical, machine-readable data. This is accomplished throughout this thesis by the use of word embedding mod-els, which capture contextual similarity between words in an unsupervised man-ner.7–10 In brief, word embedding models map natural language words to
real-valued vectors such that similar words are grouped together. For example, if 𝑒(𝑤) ∈ R𝑛 is an embedding function for words, and if the following is found for words (𝑤1, 𝑤2, 𝑤3):
cos(𝑒(𝑤1), 𝑒(𝑤2)) > cos(𝑒(𝑤1), 𝑒(𝑤3))
then this suggests that the meanings of 𝑤1 and 𝑤2 are more similar to each other
than 𝑤1 and 𝑤3. To give a concrete example using real data from this thesis,
“cal-cine” and “anneal” have a higher pairwise similarity than “cal“cal-cine” and “wash” when using cosine similarity applied to word2vec embeddings.2,7
2.3.2
Identifying Synthesis Descriptions
Synthesis descriptions (e.g., “Experimental methods” sections in journal articles) are identified by solving a many-to-one sequence classification problem. A model is learned in order to approximate the distribution that a paragraph, expressed as a sequence of words, (𝑤𝑖)𝑛 belongs to the “synthesis recipe” class, 𝑟: P(𝑟|𝜃, (𝑤𝑖)𝑛)
where 𝜃 are the model parameters. In practice, we use a recurrent neural network trained on human-annotated data to evaluate these probabilities, although a dilated convolutional neural network produces similar results with better computational efficiency.6
2.3.3
Named Entity Recognition for Materials Synthesis
Named entity recognition, in the context of extracting synthesis information from written text, is used to identify important keywords in the synthesis route (e.g., “Barium titanate,” “dissolved”). This is solved as a many-to-many sequence la-belling task, where a sequence of words (𝑤𝑖)𝑛 are mapped to a sequence of word
classes (e.g., “reaction condition”) (𝑐𝑖)𝑛. Similar to the process for identifying
syn-thesis descriptions, this is accomplished throughout this syn-thesis using recurrent neu-ral networks trained on human-annotated data.
2.3.4
Extracting Synthesis Schema with Grammatical Parsing
Associating different named entities, such as temperatures with heating actions, is a critical step in correctly extracting a synthesis schema. In this thesis, grammat-ical dependency parsing11 is used to determine pairwise relations between named
entities. Grammatically parsing a sentence resolves a sequence of words (𝑤𝑖)𝑛 into
a “parse tree” with 𝑛 nodes, where each node is labeled by a word from the sen-tence.
The hierarchy of a parse tree denotes the grammatical structure of the sentence: for example, if 𝑤𝑗 = “NaOH” and 𝑤𝑘 = “dissolved” then, in a sentence that describes
the dissolution of NaOH, IS_CHILD(𝑤𝑗, 𝑤𝑘) = TRUE. Given the difficulty of
devel-oping accurate and robust machine-learned methods for resolving named entity relations6, grammatical parsing is instead used to resolve all named entity relations in this thesis, including temperatures of heating steps, concentrations of solvents, and morphologies of materials.
2.4
Discriminative and Generative Models for
Syn-thesis Insight
2.4.1
Classifying Synthesis-Product Relationships
Given the lack of negative data in the literature,1,12 data-driven synthesis insights
in this thesis are gained by building models to understanding driving factors which differentiate between contrasting synthesis outcomes. As an example, given a set of synthesis parameters as a single feature vector 𝑆bag= R𝑛, a model may be learned to
approximate the distribution for achieving certain target phases 𝑝 of a material (e.g., 𝛼 versus 𝛽-phase MnO2): P(𝑝|𝜃, 𝑆bag). Indeed, this approach is used throughout
Chapter 4.
2.4.2
Generating Novel Synthesis Parameters
Generative models seek to learn distributions of data such that novel data points can be sampled.3,13,14 Using the bag of synthesis parameters representation 𝑆
bag = R𝑛,
a variational autoencoder is one such algorithm that can be used to learn and gen-erate representations of synthesis routes.13Critically, the variational autoencoder is
subject to an auxiliary loss term which penalizes diverging from a Gaussian-like dis-tribution, and this allows for generation of novel synthesis parameters by sampling from a multivariate Gaussian distribution and decoding the data using a trained variational autoencoder. This technique is used in Chapter 5 to generate synthesis parameters for various inorganic materials.
While a variational autoencoder can be used to model a distribution of synthesis pa-rameters, P(𝑆), this is often only practical when modeling the synthesis parameter distribution for a single material.3 One approach towards simultaneously modeling
the synthesis parameter distributions of multiple materials is to learn a conditional distribution P(𝑆|𝑐), where 𝑐 is the conditional data jointly-observed with 𝑆. For example, a conditional variational autoencoder can be used to model synthesis ac-tion sequences (𝑎𝑘)𝑛 conditional on the target synthesized material 𝑚: P((𝑎𝑘)𝑛|𝑚).
This approach is used in Chapter 6 to develop models which can effectively cap-ture and transfer knowledge between loosely related synthesis routes using only unsupervised training data.
2.5
Conclusions
In this Chapter, the core definitions and algorithms used to translate materials sci-ence problems into statistical learning problems have been summarized. Rather than highlighting formal definitions of known algorithms (e.g., neural networks), the focus of this Chapter has been the application and utility of these algorithms in solving problems related to data mining materials science literature.
Bibliography
[1] E. Kim, K. Huang, A. Saunders, A. McCallum, G. Ceder, and E. Olivetti, Chemistry of Materials29, 9436 (2017).
[2] E. Kim, K. Huang, A. Tomala, S. Matthews, E. Strubell, A. Saunders, A. McCallum, and E. Olivetti, Scientific Data4, 170127 (2017).
[3] E. Kim, K. Huang, S. Jegelka, and E. Olivetti, npj Computational Materials 3, 53
(2017).
[4] B. A. Grzybowski, K. J. Bishop, B. Kowalczyk, and C. E. Wilmer, Nature Chemistry1,
31 (2009).
[5] M. H. Segler, M. Preuss, and M. P. Waller, Nature555, 604 (2018).
[6] S. Mysore, E. Kim, E. Strubell, A. Liu, H.-S. Chang, S. Kompella, K. Huang, A. McCal-lum, and E. Olivetti, arXiv preprint arXiv:1711.06872 (2017).
[7] T. Mikolov, K. Chen, G. Corrado, and J. Dean, arXiv preprint arXiv:1301.3781 (2013). [8] P. Bojanowski, E. Grave, A. Joulin, and T. Mikolov, Transactions of the Association for
Computational Linguistics5, 135 (2017), ISSN 2307-387X.
[9] A. Joulin, E. Grave, P. Bojanowski, and T. Mikolov, arXiv preprint arXiv:1607.01759 (2016).
[10] M. E. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, and L. Zettlemoyer, in Proceedings of the 2018 Conference of the North American Chapter of the Association
for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers)
(2018).
[11] M. Honnibal and M. Johnson (2015).
[12] P. Raccuglia, K. C. Elbert, P. D. Adler, C. Falk, M. B. Wenny, A. Mollo, M. Zeller, S. A. Friedler, J. Schrier, and A. J. Norquist, Nature533, 73 (2016).
[13] D. P. Kingma and M. Welling, in International Conference on Learning Representations (2014).
[14] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, in Advances in neural information processing systems (2014), pp. 2672–2680.
Chapter 3
Predictive Models for Synthesis
Information Extraction
The content of this chapter is partially based on the journal article, “Machine-learned and codified synthesis parameters of oxide materials,” by Edward Kim et al. that originally appeared in Scientific Data.1 This chapter discusses the
compu-tational techniques used in this thesis, and includes the methods used at the time of publication along with updated methods developed through the course of this thesis. This chapter discusses results that are primarily in service of the first the-sis goal, by presenting a variety of novel algorithms and techniques for automated aggregation of synthesis knowledge from the literature.
3.1
Introduction
Materials Genome Initiative efforts have led to the proliferation of open-access ma-terials properties databases, resulting in the rapid acceleration of mama-terials discov-ery and design.2–7 Given these advances in screening for novel compounds, the
a primary bottleneck in materials design.8Recent high-throughput and data-driven explorations of materials syntheses have focused on optimizing a particular mate-rial system of interest.9,10 Yet, the general landscape of synthesizable materials11,12 spanning across material systems remains largely unexplored. To further encourage rapid and open synthesis discovery in the materials science community, we present here a dataset which collates key synthesis parameters aggregated by chemical com-position (e.g. BiFeO3) across 30 commonly-reported oxide systems.
Many of the largest-volume databases consist primarily of data which are computed ab initio (e.g., using density functional theory).2,13 There are, however, ongoing
ef-forts which make use of human-collected information extending beyond what can be computed from first principles: Ghadbeigi et al. provide human-retrieved per-formance indicators for Li-ion battery electrode materials, extracted from ∼200 articles,5and Raccuglia et al. apply a similar human-data-retrieval technique to lab
notebooks to compile ∼4000 reaction conditions for training machine-learned syn-theses of vanadium selenite crystals.10 Additionally, high-throughput experimental
syntheses are capable of producing vast combinatorial materials ‘libraries’ for the purposes of materials screening.9,14,15 These approaches lay the groundwork
to-wards a broader approach using automated data collection techniques.
To accelerate the materials science community towards the goal of rapidly hypoth-esizing viable synthesis routes, a method for programmatically querying the body of existing syntheses is necessary. Such a resource may serve as a starting point for literature review, or an initial survey of “common” and “outlier” synthesis pa-rameters, or as supplementary input data for other large-scale text mining studies on materials science literature. Indeed, approaches to high-throughput synthesis screening have seen recent success in organic chemistry,16–23since organic reaction
data is well-tabulated in machine readable formats.24
In this chapter, we provide a set of tabulated and collated synthesis parameters across 30 oxide systems commonly reported in the literature. This data is retrieved
Journal Articles (XML)
Journal Articles (HTML)
FastText
Word Embeddings
GRU Recurrent Net
Annotated Paragraphs
Synthesis Text
GRU Recurrent Net
Annotated Synthesis Sentences
Grammatical Dependency Parser
Named Entities
Text-mined Synthesis Database
INPUT
OUTPUT
ELMo
Word Embeddings
Figure 3-1. Schematic overview of text extraction and database construc-tion. Materials synthesis articles are fed into a NLP pipeline, which computes a
machine-readable database of synthesis parameters across numerous materials sys-tems. These parameters can then be queried to produce synthesis planning re-sources, including, empirical distributions of real-valued parameters and ranked lists of keywords.
by first training machine learning (ML) and natural language processing (NLP) al-gorithms using a broad collection of over 2.5M materials synthesis journal arti-cles. These trained algorithms are then used to parse a subset of 76,000 articles discussing the syntheses of our selected oxide materials. Figure 3-1 provides a schematic overview of the methods used for transforming human-readable articles into machine-readable synthesis parameters and synthesis planning resources. No direct human intervention is necessary in this methodology: Our automated text processing approach downloads articles, extracts key synthesis information, cod-ifies this information into a database, and then aggregates the data by material system.
3.2
Word Representations and Context-Sensitive Text
Classification
3.2.1
Article Retrieval
Using the CrossRef search Application Programming Interface (API),25 journal
ar-ticles are programmatically queried and downloaded using additional API routes, approved individually by each publisher we access. These articles are downloaded in HTML, XML and PDF formats.
3.2.2
Learning Word Representations
Word2Vec Prior to training downstream machine learning models for text extrac-tion, the corpus is used to train, in an unsupervised fashion, a neural network model based on the Word2Vec model introduced by Mikolov et al.26 This model
learns a low-dimensional and continuous vector representation for words, based on observing similar contexts (i.e., words which appear in similar locations in similar
sentences). These word vectors, called word embeddings, are then used as inputs for other machine learning models. As an example, a sentence may be represented as a two-dimensional 𝑛 × 𝑚 matrix of word embeddings, where 𝑛 is the number of words in the sentence and 𝑚 is the dimensionality of the embeddings. One major shortcoming of Word2Vec is the inability to represent words which have never been observed by the model previously; this shortcoming is a major bottleneck for ma-terials text extraction, as novel compounds are, by definition, always unobserved during algorithm training.
FastText and ELMo FastText and ELMo are two additional word embedding mod-els that, similar to Word2Vec, project words into 𝑚-dimensional vectors. Both of these models are capable of representing previously unseen words, since FastText leverages substring-based representations (e.g., “TiO2” contains substrings “Ti” and “O2”), while ELMo is entirely character-based. The FastText and ELMo models were both fine-tuned on our collection of 2.5M+ materials science journal articles, start-ing from random weights for FastText and standard pre-trained weights for ELMo.27
In practice, the authors found that fine-tuning an ELMo model to materials science literature improved performance on NER tasks by upwards of 10% in some cate-gories.
3.2.3
Text Classification and Extraction
A Bidirectional-GRU28 recurrent neural network is trained to classify all paragraphs
of a journal article using FastText word embeddings as input features. An anno-tated collection of 4000 paragraphs were used to train the paragraph classification model. This model has an overall accuracy of 92% across eight classes (abstract, introduction, synthesis recipe, characterization and other methods, results, conclu-sions, captions, and miscellaneous) and achieves a recall and precision of 96% and 81% for classifying synthesis recipes, respectively. For the purposes of analyzing
synthesis text, recall is the most relevant metric, as false-positive synthesis recipes have minimal effect on downstream NER processes (with the exception of increas-ing overall computation time). Although dynamically-computed ELMo embeddincreas-ings achieve higher accuracies than static FastText embeddings, FastText embeddings are used for this paragraph classification task since computation time for character-based embeddings is intractable for a full-text corpus of this size.
Word-level labels are applied using a neural network which predicts the category of each word (e.g., material, amount, number, irrelevant word), using word em-bedding vectors: in order to predict word-level labels, a transfer learning setup is used,29 in which we first learn, in an unsupervised manner, a feature mapping
function for words using unlabeled data. Then, we use these learned features to create context-sensitive word inputs during supervised training on a smaller set of data with high-accuracy labels applied by humans. A Bidirectional-GRU, oper-ating at sentence-level context, is trained on character-based ELMo word embed-dings, while ChemDataExtractor is used for tokenizing sentences and words.30 The
macro-averaged categorical accuracy of the trained model is 93%. The NER labels are produced from a manual annotation process where 230 journal articles were annotated word-by-word.
Finally, word relations are extracted using a grammatical dependency parser.31This
parser is applied to each sentence in a synthesis paragraph, and dependent relations between named entities (e.g., a material and its amount) are resolved by traversal of the dependency parse tree.
3.3
Veracity of Extracted Syntheses
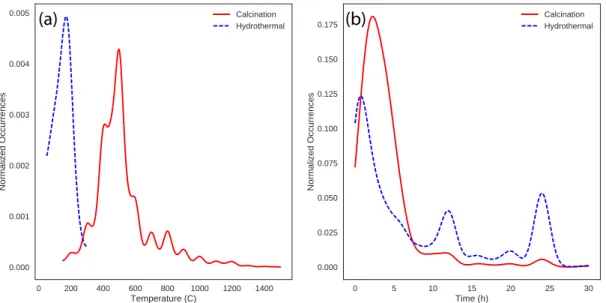
For scientific validation, we briefly compare the aggregated data in our provided dataset to known results. As an example, Figure 3-4a displays frequent usages of temperatures near the anatase-rutile phase boundary for titania.33 This data thus
Table 3.1. In-domain word categories and examples. Word-level labels and
examples of words belonging to each label. Each word in an article is assigned to exactly one of these labels.
Word Label Interpretation Examples
TARGET Final synthesized material TiO2, BiFeO3
UNSPECIFIED Generic references to materials solution, powder
MATERIAL Non-target named materials TiCl4, NaOH
OPERATION Action on a material dissolve, sinter
AMOUNT MISC Unspecified amount Several, dropwise
AMOUNT UNIT Amount-type unit mL, mmol
CONDITION MISC Unspecified parameter of an action slowly, ambient
CONDITION UNIT Unit for parameter of an action hours, C
EXPR. APPARATUS Synthesis equipment autoclave, furnace
CHARACTERIZE Experimental techniques SEM, XRD
DESCRIPTOR Qualitative material morphology layered, nanorods
PROPERTY MISC Qualitative aspect of a material denser, brittle
PROPERTY UNIT Quantitative aspect of a material MPa, cm2
PROPERTY TYPE Type of aspect of a material strength, area
NUMBER Numerical words 120, five
META Synthesis route type solvothermal, sol-gel
BRAND Commercial brand Sigma, Fisher
REF Citation or reference [14], 2007
Figure 3-2. Topic and synthesis target distributions within the database.
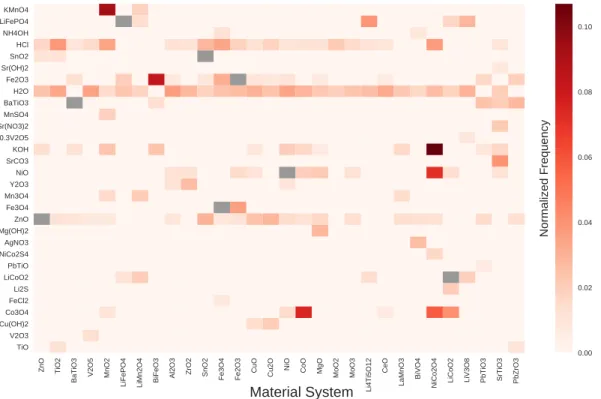
Heatmap showing a sample of topic distributions plotted against material systems of interest. Topics are computed from training a Latent Dirichlet Allocation model on all retrieved journal articles, and are labeled by their top-ranked keywords32.
Val-ues of the heatmap represent column-normalized counts across all articles within a material system.
Figure 3-3. Top occurring material mentions per target material system.
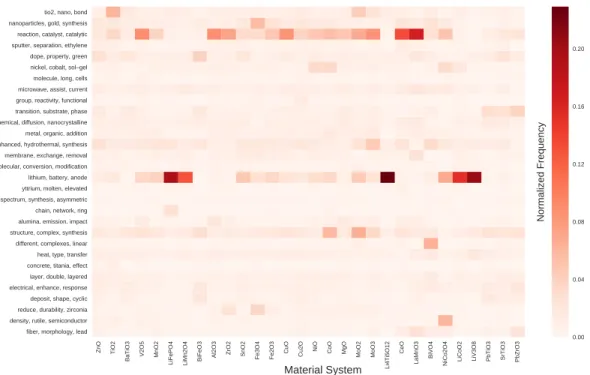
Heatmap showing a sample of co-occurring mentions of materials within synthesis routes for material systems of interest. Values of the heatmap represent column-normalized counts across all articles within a material system. Counts of self-mentioning co-occurrences (e.g., ZnO mentioned in papers synthesizing ZnO) are fixed to zero prior to column normalization and plotted in grey.
agrees with the intuitive reasoning that such temperatures are used to either crys-tallize an anatase-phase product, or convert to a rutile-phase product.34 We also
observe additional patterns which agree with intuitive expectations: Figure 3-4a shows that hydrothermal reactions are confined to a narrow temperature range, peaking between 100-200 ∘C, and Figure 3-4b confirms that hydrothermal reac-tions more typically occur for long periods of time compared to calcination.
Besides validating the accuracy of the text extraction and word-labeling methods, we reiterate here the accuracy of the parsing algorithm used, which is reported as 91.85%.31 We use this parsing algorithm as a dependency to resolve higher-level
relations in our extracted text data (e.g., relating “500 C” to “heated” in the same sentence).
(a) (b)
Figure 3-4. Temperature and time distributions for titania. (a) Calcination and
hydrothermal temperature kernel density estimate for titania, normalized to unit area. (b) Calcination and hydrothermal time kernel density estimate for titania, normalized to unit area. All density estimates are computed using Gaussian kernels computed from counts of temperatures and times extracted from synthesis sections of journal articles.
3.4
Public Data Availability
The data are provided as a single JSON file, available at www.synthesisproject. org and through figshare (10.6084/m9.figshare.5221351). Each record, corre-sponding to data for a single material system, is represented as a JSON object in a top-level list. The details of the data format are given in Table 3.2.
Metadata for each material system is provided in the JSON dataset, including topic distributions computed with Latent Dirichlet Allocation.32 These topic distributions
are visualized as a heatmap in Figure 3-2, and demonstrate correlations between material chemistries and device applications, experimental apparatuses, and prod-uct morphologies.
Numerical synthesis parameters (e.g., calcination temperatures) for each material system are provided as kernel density estimates, computed across all journal articles discussing the synthesis of a given material. Such a format allows for rapid visu-alizations to aid high-level synthesis planning: for example, Figure 3-3 shows co-occurrences between materials systems and mentions of other materials extracted from synthesis sections of articles.
3.5
Conclusions
As this data is provided in the language-agnostic JSON format, no specific technical setup is required as a dependency. The authors have found it useful to load the data into the Python programming language, especially for downstream integration with data from the Materials Project provided via their pymatgen library.35
A detailed, web-accessible Python tutorial for loading and analyzing the dataset is available at https://github.com/olivettigroup/sdata-data-plots/. This web tutorial provides the exact Python code used to generate the figures in this article,
Table 3.2. Schema of data records. Overview of formatting for each data record,
with each row representing a data record key. For each key, the key label name is provided, along with the data type.
Data Description Data Key Label Data Type
Name of materials system name String
Number of papers used to com-pute synthesis parameters
num_papers Integer
Top occurring synthesizing ac-tions used for a material system
associated_operations Array of string Top co-occurring materials in
synthesis sections for a material system
associated_materials Array of strings
Topic distribution for a material system
topics Dictionary of topic
strings and frequency floats
All temperatures reported in syn-theses for a material system, ag-gregated as a kernel density esti-mate
temperature_kde Dictionary of x and y
floats
Hydrothermal temperatures and times reported in syntheses for a material system, aggregated as a kernel density estimate
hydrothermal_kde Dictionary of x and y
floats
Calcination temperatures and times reported in syntheses for a material system, aggregated as a kernel density estimate
calcine_kde Dictionary of x and y
along with commentary which explains the technical setup.
Empirical histograms provided in this dataset, along with ranked lists of frequent synthesis parameters, serve as useful starting points for literature review and syn-thesis planning: for example, selecting the most frequent synsyn-thesis parameters (e.g. most common reaction temperatures and precursors) would yield a starting point for a viable synthesis route.
Additionally, the topic labels provided in this dataset may prove useful in studies related to metadata and text mining in the materials science literature. As a mo-tivating example, authorship and citation links have been analyzed in biomedical papers to reveal insights related to the impact of papers over time;36 such analyses
Bibliography
[1] E. Kim, K. Huang, A. Tomala, S. Matthews, E. Strubell, A. Saunders, M. Andrew, and E. Olivetti, Sci Data4, sdata2017127 (2017), ISSN 2052-4463.
[2] A. Jain, S. Ong, G. Hautier, W. Chen, W. Richards, S. Dacek, S. Cholia, D. Gunter, D. Skinner, G. Ceder, et al., Apl Mater1, 011002 (2013), ISSN 2166-532X.
[3] S. Curtarolo, G. L. Hart, M. Nardelli, N. Mingo, S. Sanvito, and O. Levy, Nat Mater12,
191 (2013), ISSN 1476-4660.
[4] P. E. O, K. Li, and A. Alan, Adv Funct Mater25, 6495 (2015), ISSN 1616-301X.
[5] L. Ghadbeigi, J. K. Harada, B. R. Lettiere, and T. D. Sparks, Energy Environ Sci 8,
1640 (2015), ISSN 1754-5692.
[6] J. Saal, S. Kirklin, M. Aykol, B. Meredig, and W. C. Jom, Jom (2013). [7] J. P. Holdren (2011).
[8] B. G. Sumpter, R. K. Vasudevan, T. Potok, and S. V. Kalinin, Npj Comput Mater 1,
15008 (2015).
[9] R. Potyrailo, K. Rajan, K. Stoewe, I. Takeuchi, B. Chisholm, and H. Lam, Acs Comb Sci
13, 579 (2011), ISSN 2156-8952.
[10] P. Raccuglia, K. C. Elbert, P. D. Adler, C. Falk, M. B. Wenny, A. Mollo, M. Zeller, S. A. Friedler, J. Schrier, and A. J. Norquist, Nature533, 73 (2016), ISSN 1476-4687.
[11] M. Jansen, Adv Mater27, 3229 (2015), ISSN 1521-4095.
[12] M. Jansen, Pure Appl Chem86, 883 (2014), ISSN 0033-4545.
[13] D. Gunter, S. Cholia, A. Jain, M. Kocher, K. Persson, L. Ramakrishnan, S. Ong, and G. Ceder, 2012 Sc Companion High Perform Comput Netw Storage Analysis pp. 1244– 1251 (2012).
[14] C. Suh, C. Gorrie, J. Perkins, P. Graf, and W. Jones, Acta Mater59, 630 (2011), ISSN
1359-6454.
[15] M. L. Green, I. Takeuchi, and H. J. R, J Appl Phys113, 231101 (2013), ISSN
[16] L. Hawizy, D. M. Jessop, N. Adams, and M. Peter, J Cheminformatics3, 1 (2011), ISSN
1758-2946.
[17] D. Duvenaud, D. Maclaurin, A. Jorge, G. Rafael, T. Hirzel, A. Alán, and R. P. Adams (2015).
[18] T. Rocktäschel, M. Weidlich, and U. Leser, Bioinformatics28, 1633 (2012), ISSN
1367-4803.
[19] M. C. Swain and J. M. Cole, J Chem Inf Model (2016), ISSN 1549-9596.
[20] Y. Kano, J. Björne, F. Ginter, T. Salakoski, E. Buyko, U. Hahn, B. K. Cohen, K. Verspoor, C. Roeder, L. E. Hunter, et al., Bmc Bioinformatics12, 1 (2011), ISSN 1471-2105.
[21] S. Szymku´c, E. P. Gajewska, T. Klucznik, K. Molga, P. Dittwald, M. Startek, M. Bajczyk, and B. A. Grzybowski, Angewandte Chemie Int Ed55, 5904 (2016), ISSN 1433-7851.
[22] S. V. Ley, D. E. Fitzpatrick, R. J. Ingham, and R. M. Myers, Angewandte Chemie Int Ed
54, 3449 (2015), ISSN 1521-3773.
[23] M. H. Segler, M. Preuss, and M. P. Waller, Nature555, 604 (2018), ISSN 1476-4687.
[24] J. Goodman, J Chem Inf Model49, 2897 (2009), ISSN 1549-9596.
[25] R. Lammey, Sci Ed2, 22 (2015), ISSN 2288-8063.
[26] T. Mikolov, K. Chen, G. Corrado, and J. Dean (2013).
[27] M. E. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, and L. Zettlemoyer, in Proceedings of the 2018 Conference of the North American Chapter of the Association
for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers)
(2018).
[28] J. Chung, C. Gulcehre, K. Cho, and Y. Bengio, in NIPS 2014 Workshop on Deep
Learn-ing, December 2014 (2014).
[29] S. Pan and Q. Yang, Ieee T Knowl Data En22, 1345 (2010), ISSN 1041-4347.
[30] M. C. Swain and J. M. Cole, Journal of chemical information and modeling56, 1894
(2016).
[31] M. Honnibal and M. Johnson (2015).
[32] D. M. Blei, A. Y. Ng, and M. I. Jordan, Journal of machine Learning research3, 993
(2003).
[33] R. Ren, Z. Yang, and L. Shaw, J Mater Sci35, 6015 (2000), ISSN 0022-2461.
[34] A. Primo, A. Corma, and H. García, Phys Chem Chem Phys 13, 886 (2011), ISSN
1463-9076.
[35] S. Ong, W. Richards, A. Jain, G. Hautier, M. Kocher, S. Cholia, D. Gunter, V. L. Chevrier, K. A. Persson, and G. Ceder, Comp Mater Sci68, 314 (2013), ISSN 0927-0256.
[36] C. Catalini, N. Lacetera, and A. Oettl, Proc National Acad Sci 112, 13823 (2015),
Chapter 4
Data Mined Synthesis-Product
Relations
The content of this chapter is based on the journal article, “Materials Synthesis Insights from Scientific Literature via Text Extraction and Machine Learning,” by Edward Kim et al. that originally appeared in Chemistry of Materials.† Using the
text-mining techniques discussed in Chapter 3 to construct a database of mate-rials synthesis parameters, several machine-learned models are then trained for synthesis-property prediction. This chapter primarily addresses the second thesis goal, by demonstrating the capacity for autonomous, quantitative identification of synthesis driving factors for morphology selection.
4.1
Introduction
First principles materials design, open access materials property databases,1–3 and
machine learning4,5 have accelerated novel compound identification for a variety
of applications, including energy storage, catalysis, thermoelectrics, and hydrogen
†Reproduced in part with permission from Kim et al., Chem. Mater.,2017 29 (21), 9436-9444.
storage.6–14 To fully realize the vision of the Materials Genome Initiative of acceler-ating materials development15–18, we must, in a comprehensive and accessible way,
link the compositions, structures, and morphologies of these computationally dis-covered materials to the synthesis conditions that can produce them. This chapter represents a small step in the direction towards this goal of systematically under-standing the relationships between synthesized materials and reaction conditions, by broadly data mining the literature.
The materials design community remains gated by the use of heuristic synthesis guidelines once a particular material of interest has been identified, either by direct first-principles computations or screening methods.6,19,20 As a result, the synthesis
of targeted novel compounds is rapidly becoming the slow step in computationally driven materials design. With direct modeling of the complex kinetic processes oc-curring during synthesis out of reach, a data-driven, machine learning approach that learns from the hundreds of thousands of published synthesis recipes may be more productive. As a step towards this objective, we use recent advances in full-text publisher application programming interfaces (APIs)21 and natural language
processing (NLP)22–26 to develop a statistical learning approach to materials
syn-thesis. While numerous studies have focused on text extraction from scientific liter-ature,22–24,27–29 we present here a framework focused on the problem of extracting
and data-mining materials synthesis conditions.
Using a variety of machine learning and natural language processing techniques, our platform automatically retrieves articles and then extracts and codifies the ma-terials synthesis conditions and parameters found in the text. By combining these text-mined synthesis parameters at large scale, this synthesis database can be mined to discover the underlying relationships between synthesis conditions and the ma-terials they produce. This literature-based data mining strategy also complements and benefits from current combinatorial and in situ synthesis studies, which pro-duce ‘libraries’ of materials with varied compositions in order to explore a materials parameter space.30–32
Here we present a platform that leverages the large body of published synthesis recipes through natural language processing, and uses these recipes to train ma-chine learning models that aid in developing insights into the key parameters that drive the synthesis of specific, technologically-relevant materials at a high level of automation.33–35
4.2
Quantitative Synthesis Trends in the Literature
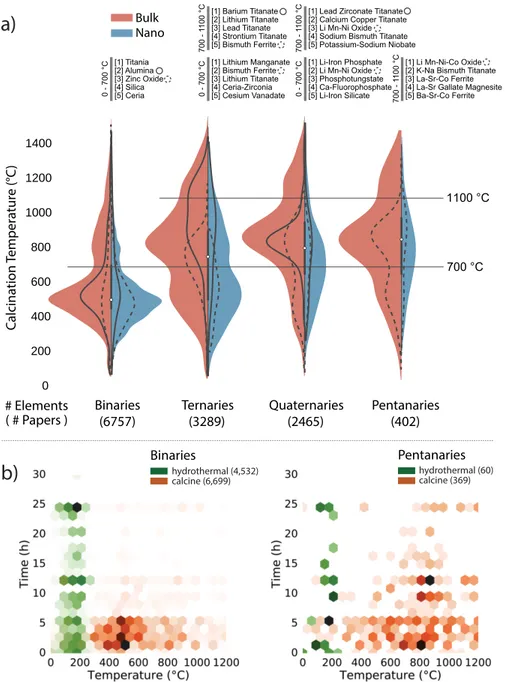
From a collection of over half a million journal articles in our database, we first apply topic and material-level text queries to select a set of articles in which metal oxides are synthesized. As an example of basic information that can be retrieved and examined in an exploratory manner, we present in Figure 4-1a the distribu-tion of calcinadistribu-tion temperatures used in 12,913 syntheses recipes of metal oxides, grouped by their number of constituent elements and whether or not the targets are nanostructured.
In each category we list the top 5 materials, by occurrence, and we delineate arbi-trary temperature windows 0-700∘C and 700-1100∘C to make the peaks easier to
see. We also show example curves for specific materials (with a solid or dashed line) within each distribution. Each pair of ‘nanostructured’ versus ‘bulk’ distributions is scaled by paper count.
Several interesting observations can already be made from these plots. High calci-nation temperatures are found more frequently in the synthesis of bulk materials with greater elemental complexity. The difference in calcination temperature is par-ticularly pronounced between the binaries and higher-component systems. Indeed, a binary oxide is often formed by straightforward substitution of the carbonate, hydroxyl, or similar anion group in the precursor by oxygen. In contrast, the phase-pure synthesis of multi-component systems additionally requires the inter-diffusion of multiple metals from the precursors, necessitating higher temperature. The