Improving mapping for sparse direct solvers: A trade-off between data locality and load balancing
Texte intégral
Figure
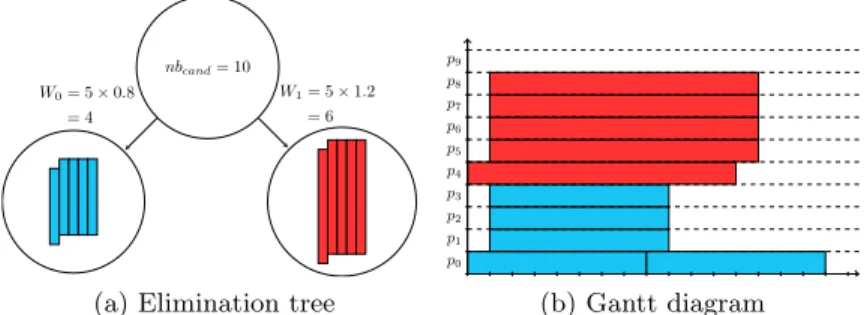
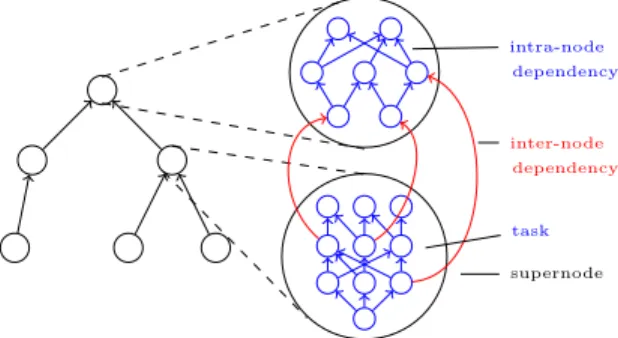
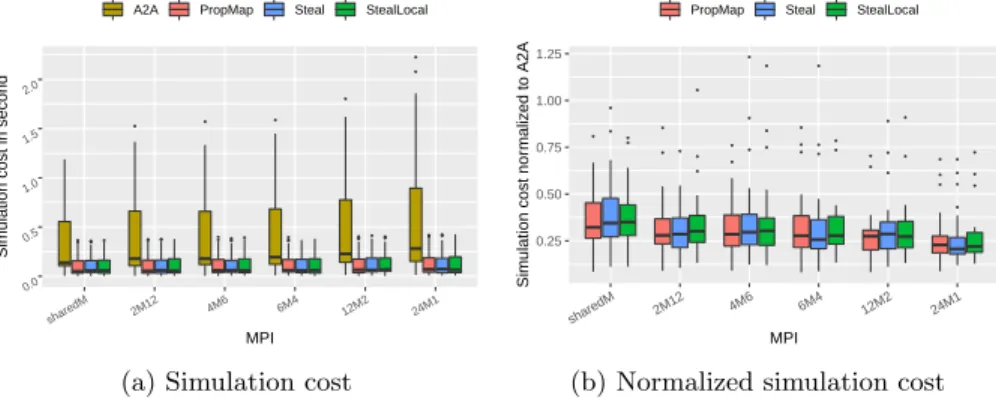
Documents relatifs
once deployed, the ability for the craft to move away from the hazard at the platform (eg: the heat and direct effects of a fire, smoke, a gas plume, etc.) in the ice conditions
For overcoming such problems, a combination of range camera and photogrammetry was developed, in order to merge the good local accuracy and point density of the former, with
/ La version de cette publication peut être l’une des suivantes : la version prépublication de l’auteur, la version acceptée du manuscrit ou la version de l’éditeur.. For
Taking into account all the previous considerations concerning interactions between the different kind of species and the dielectric surface, the equations for the boundary
Nous voulons donc nous assurer que dans deux comptes rendus différents, l’indexation choisie comme non-recouverte soit toujours la même lorsqu’un même groupe de concepts (avec
Dmitry Grishchenko, Franck Iutzeler, Jérôme Malick. Proximal Gradient methods with Adaptive Sub- space Sampling.. Many applications in machine learning or signal processing
Achieving Statistical Parity amounts to modifying the original data into a new random variable ˜ X such that the conditional distribution with respect to the protected attribute S
Among medical diagnoses, neurological disorders contributed to decisional incapacity, and among the psychiatric diagnoses, cognitive disorders were most frequently documented in
