A Fast Approximation of the Bilateral Filter using a Signal Processing Approach
Texte intégral
Figure




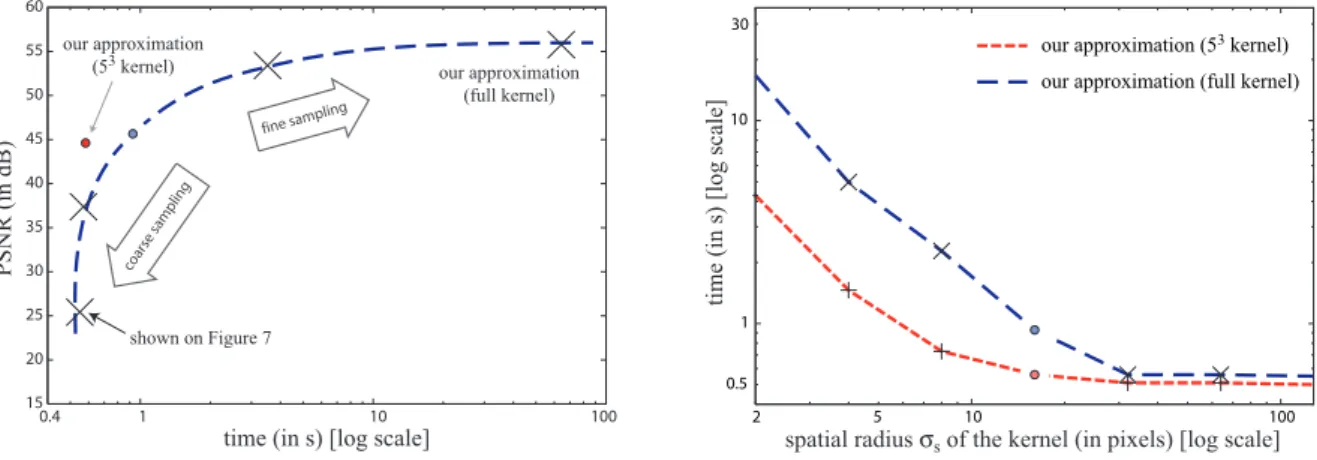




Documents relatifs
Regarding the theological understanding of this sacrament, the fact which should be stressed is that from the early Christianity Chrismation-Confirmation is the
We study the discrete-time approximation for solutions of quadratic forward back- ward stochastic differential equations (FBSDEs) driven by a Brownian motion and a jump process
In this paper, a 2D decomposition method is proposed to compute the static transmission error of gears with holes in the gear blanks without heavy computational effort1. The
For Lipschitz generators, the discrete-time approximation of FBSDEs with jumps is stud- ied by Bouchard and Elie [4] in the case of Poissonian jumps independent of the Brownian
Abstract—This paper considers a helicopter-like setup called the Toycopter. Its particularities reside first in the fact that the toy- copter motion is constrained to remain on a
3.1, we show that the discrete Steklov eigenfunctions, which are written with respect to the finite element basis, solve a discrete generalized eigenvalue problem, and in Sec.. 3.2,
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
In the most general case, as in the case of complex oscillations of continuous systems, there is no simple way of determining the shape of the complex oscillations (the ): one may
