Co-design of on-chip caches and networks for
scalable shared-memory many-core CMPs
by
Woo Cheol Kwon
B.S., Korea Advanced Institute of Science and Technology (1998)
M.S., Korea Advanced Institute of Science and Technology (2000)
Submitted to the Department of Electrical Engineering and Computer
Science
in partial fulfillment of the requirements for the degree of
Doctor of Philosophyat the
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
June 2018
@
Massachusetts Institute of Technology 2018.
Author ...
All rights reserved.
Signature redacted
Department of Electrical Engineering and Computer Science
Signature redacted
May 23, 2018
C ertified by ...
...
Li-Shiuan Peh
Visiting Professor of Electrical Engineering and Computer Science
Thesis Supervisor
Accepted by ...
Signature redacted
/
0
U
Leslie A. Kolodziejski
Professor of Electrical Engineering and Computer ScienceTE
Chair, Department Committee on Graduate Students
T MASSACHUSS INSWUOF TECHNOLOGY
Co-design of on-chip caches and networks for scalable
shared-memory many-core CMPs
by
Woo Cheol Kwon
Submitted to the Department of Electrical Engineering and Computer Science on May 23, 2018, in partial fulfillment of the
requirements for the degree of Doctor of Philosophy
Abstract
Chip Multi-Processors(CMPs) have become mainstream in recent years, providing increased parallelism as core counts scale. While a tiled CMP is widely accepted to be a scalable architecture for the many-core era, on-chip cache organization and co-herence are far from solved problems. As the on-chip interconnect directly influences the latency and bandwidth of on-chip cache, scalable interconnect is an essential part of on-chip cache design. On the other hand, optimal design of interconnect can be de-termined by the traffic forms that it should handle. Thus, on-chip cache organization is inherently interleaved with on-chip interconnect design and vice versa.
This dissertation aims to motivate the need for re-organization of on-chip caches to leverage the advancement of on-chip network technology to harness the full potential of future many-core CMPs. Conversely, we argue that on-chip network should also be designed to support specific functionalities required by the on-chip cache. We propose such co-design techniques to offer significant improvement of on-chip cache performance, and thus to provide scalable CMP cache solutions towards future many-core CMPs. The dissertation starts with the problem of remote on-chip cache access latency. Prior locality-aware approaches fundamentally attempt to keep data as close as possible to the requesting cores. In this dissertation, we challenge this design approach by introducing new cache organization that leverages a co-designed on-chip network that allows multi-hop single-cycle traversals. Next, the dissertation moves to cache coherence request ordering. Without built-in ordering capability within the interconnect, cache coherence protocols have to rely on external ordering points. This dissertation proposes a scalable ordered Network-on-Chip which supports ordering of requests for snoopy cache coherence. Lastly, we describe development of a 36-core research prototype chip to demonstrate that the proposed Network-on-Chip enables shared-memory CMPs to be readily scalable to many-core platforms.
Thesis Supervisor: Li-Shiuan Peh
Acknowledgments
First of all, I would like to thank my thesis advisor, Prof. Li-Shiuan Peh, for her patient guidance and advice. It was a great privilege to study and work under her supervision. I am extremely grateful for the encouragement that she has offered throughout my Ph.D. study.
I would also like to thank my thesis committee members, Prof. Saman
Amara-singhe and Prof. Srini Devadas. I am gratefully indebted to them for their invaluable comments on this thesis.
I have been very fortunate to have great colleagues and friends at LSP group and MIT: Niket Agarwal, Kostas Aisopos, Manos Koukoumidis, Tushar Krishna, Chia-Hsin Amy Chen, Bhavya Daya, Jason Gao, Sunghyun Park, Suvinay Subramanian, Pablo Ortiz and Pilsoon Choi. I would like to thank them for wonderful cooperation.
I would like to thank Ms. Maria Rebelo for all the help that she provided.
I would also like to thank Prof. Nancy Lynch-my graduate counselor, Ms.
Ja-net Fischer-graduate administrator at the EECS office and Dr. Suraiya Baluch-assistant dean at the office of graduate education, for helping and guiding me to successfully complete this thesis.
Last but not least, I would like to express deep gratitude to my family. This thesis would not have been possible without their patience and support.
Contents
1 Introduction
1.1 Thesis Statement and Overview . . . .
1.1.1 Locality-Oblivious Cache Organization . 1.1.2 Ordered Network-On-Chip . . . .
1.1.3 SCORPIO: A research chip prototype for
herence with in-network ordering . . . .
1.1.4 Dissertation Organization . . . . 1.2 Dissertation Contributions . . . . scalable 2 Background 2.1 Shared Memory CMP. . . . . 2.2 Cache Coherence . . . . 2.2.1 Cache Coherence and Memory Consistency 2.2.2 Snoopy Cache Coherence Protocol . . . . .
2.2.3 Directory Cache Coherence Protocol . . .
2.2.4 Scalable Cache Coherence . . . .
2.3 Network-On-Chip . . . .
2.3.1 Topology . . . .
2.3.2 Switching and Flow-Control . . . .
2.3.3 R outing . . . . 2.3.4 Router Microarchitecture . . . . 2.4 SM ART NoC . . . . snoopy co-17 19 19 20 21 21 22 23 23 26 26 28 32 35 37 37 39 41 42 46 . . . . . . . .
3 Locality-Oblivious Cache Organization 3.1 Introduction . . . . 3.2 Motivation . . . . 3.3 Related Work . . . . 3.3.1 Locality-optimi 3.3.2 Clustered Cach 3.3.3 Cache Search v 3.3.4 Co-Design of C 3.4 Design . . . . 3.4.1 Overview . . 3.4.2 Local Clusterin 3.4.3 Global Data Se 3.5 Walk-through Exampl 3.6 Evaluation . . . . 3.6.1 Methodology 3.6.2 Evaluation Res 3.6.3 Full-System Si 3.7 Discussion . . . . .... dtaplcen...
zed data placement . . . .
e Organizations . . . .
ith Flexible Location . . . . ache Organization with Novel Interconnects
.c...
es.... .u.ts. Tr.a.e. .... Sim.ao...
arch . . . .
es . . . .
ults: Trace-Driven Simulation . . . . mulation Results . . . . . . . . 51 51 53 54 54 56 57 57 58 58 60 61 65 67 67 72 84 87 91 91 93 94 95 97 97 102 102 103 113 115 115 4 Network-on-Chip for Cache Request Ordering
4.1 Introduction . . . .
4.2 Related W ork . . . .
4.2.1 Snoopy Cache Coherence on Unordered Networks . . . .
4.2.2 On-chip Network to improve Shared Memory Performance 4.2.3 NoC for heterogeneous CMP . . . . 4.3 Request Ordering by Notification Broadcast . . . . 4.4 Request Reordering in NICs . . . . 4.4.1 Request Reordering in Total Order . . . . 4.4.2 Reordering based on Ordering Conflicts Resolution . . .
4.5 Ordering Network Construction for General Topology . . . . 4.6 E valuation . . . . 4.6.1 M ethodology . . . .
4.6.2 Evaluation Results . . . .1
5 SCORPIO 123 5.1 Introduction . . . . 123
5.1.1 Acknowledgment . . . . 124
5.2 Overview . . . . 124
5.3 Memory System Design. . . . . 127
5.3.1 Cache Coherence Protocol . . . . 127
5.3.2 Prioritized Writeback . . . . 130
5.3.3 Deadlock Avoidance . . . . 133
5.4 Design Space Exploration . . . . 136
5.4.1 On-chip Network . . . 137
5.5 Performance Evaluation . . . . 145
5.5.1 Methodology . . . . 145
5.5.2 Baselines . . . . 146
5.5.3 Evaluation Results . . . . 146
5.6 Interfacing with AMBA ACE . . . . 150
5.6.1 Overview . . . . 150
5.6.2 NIC Channels for ACE interface . . . . 151
5.6.3 Channel Dependence . . . . 153 5.6.4 Other Considerations . . . . 156 6 Conclusion 159 6.1 Dissertation Summary . . . . 160 6.1.1 LOCO . . . . 160 6.1.2 Ordered-NoC . . . . 161 6.1.3 SCORPIO . . . . 162
6.2 Future Research Direction . . . . 162
6.2.1 Ordered-NoC . . . . 162
6.2.2 Co-Design of On-Chip Cache and Interconnect . . . . 163
6.3 Advent of Heterogeneous Processors . . . . 164
List of Figures
2-1 Tiled CM P Architecture . . . . 25
2-2 Example of snoopy cache coherence protocol . . . . 29
2-3 State transition diagram for MOESI cache coherence protocol . . . . 31
2-4 Example of directory cache coherence protocol . . . . 34
2-5 NoC Topology Examples . . . . 38
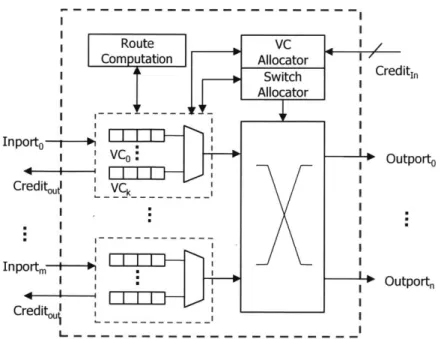
2-6 NoC router: Microarchitecture . . . . 43
2-7 Timing of NoC router pipeline . . . . 44
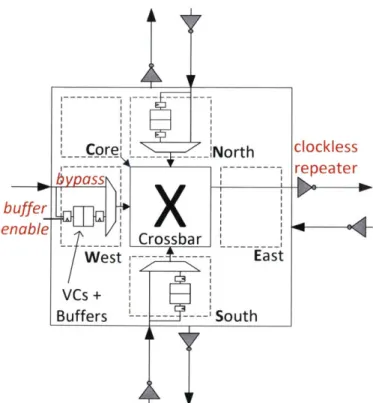
2-8 SMART Router Microarchitecture . . . . 47
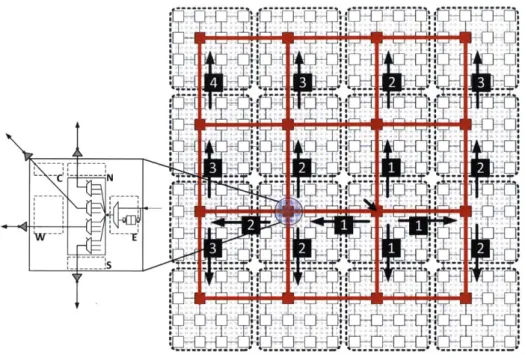
2-9 SMART: Single-cycle Multi-hop Asynchronous Repeated Traversal . . 48
3-1 Overview of LOCO . . . . 58
3-2 LOCO virtual topologies provide flexibility in choosing the cluster size. 59 3-3 Example broadcast over a VMS . . . . 62
3-4 LOCO Walk-through Example: Cache Hit . . . . 67
3-5 LOCO Walk-through Example: Cache Miss . . . . 68
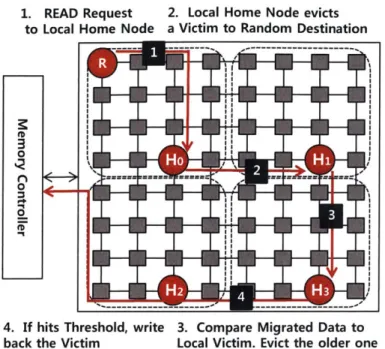
3-6 Inter-Cluster Victim Replacement Example . . . . 69
3-7 Normalized runtime of distributed private caches vs. distributed shared caches (64-core). . . . . 72
3-8 Increase of L2 access latency over Private Cache . . . . 73
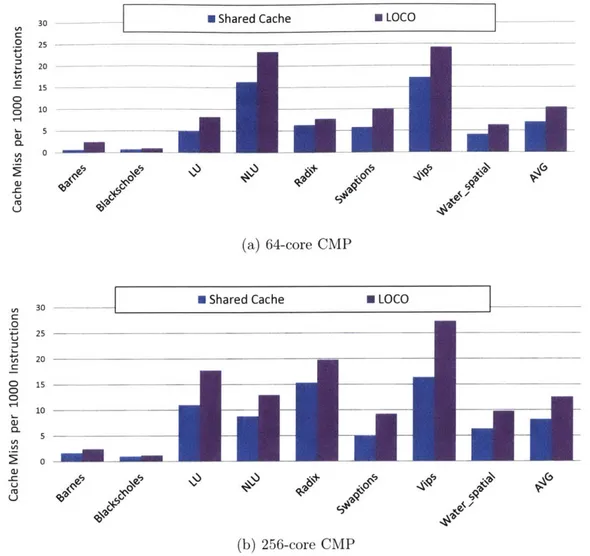
3-9 L2 Cache miss per a thousand instructions according to cache configu-ration s . . . . 74
3-10 Global search delay for data cached on-chip . . . . 75
3-11 Normalized off-chip memory access against baseline Shared Cache . . 76
3-13 Comparison to LOCO with Conventional NoC and with
routers: Memory Latency . . . .
3-14 Comparison to LOCO with Conventional NoC and with routers: Normalized Runtime . . . . 3-15 Performance of LOCO according to different cluster sizes 3-16 LOCO with multi-program workloads . . . . 3-17 Full system simulation of LOCO for 64-core CMP . . . .
High-Radix High-Radix . . . . 80 . . . . 82 . . . . 85 . . . . 86
Notification Bit-Vector for 16-core CMP . . . . Resolution of notification collision . . . . Notification broadcast is synchronized by maximum broadcast latency. Overview: Proposed Ordered-NoC for cache coherence request ordering The microarchitecture of Ordered-NoC router . . . . Microarchitecture of Network Interface Controller(NIC) . . . . Walk-through Example for Recover-Global-Order(First Part) . . . . . Walk-through Example for Recover-Global-Order(Second Part) . . . .
Walk-through Example for Reorder-On-the-Fly(First Part) . . . . Walk-through Example for Reorder-On-the-Fly(Second Part) . . . . . Construction of ordering network . . . . NoC Topologies for evaluation . . . . Snooping Latency Breakdown for TSO . . . . Snooping Latency Breakdown for Relaxed Memory Consistency . . .
Norm alized runtim e . . . . 4-1 4-2 4-3 4-4 4-5 4-6 4-7 4-8 4-9 4-10 4-11 4-12 4-13 4-14 4-15 5-1 5-2 5-3 5-4 5-5 5-6 5-7 5-8 . . . . ordering designs . . . . 98 99 100 101 102 105 108 109 111 112 114 116 118 119 120 125 130 131 132 134 136 137 138 79
Floorplan for SCORPIO and Tile components Cache state transition for L2 Cache Controller WriteBack Ordering Issue . . . .
State transition for Directory . . . .
Virtual networks for Deadlock prevention . . . . . Dependencies of coherence messages . . . . Performance comparison to alternative in-network
5-9 Runtime with varying network channel-width . . . . 140
5-10 Performance impact of virtual channel count . . . . 141
5-11 Performance impact of Snoop Filter parameters . . . . 142
5-12 Performance impact of L2 cache size . . . . 144
5-13 Performance impact of directory cache size . . . . 145
5-14 Performance evaluation of SCORPIO against the baseline architectures 147 5-15 Latency breakdown for L2 cache miss . . . .. . . . . 148
5-16 Channels of ACE interface . . . . 149
5-17 ACE snoop transaction example . . . . 151
List of Tables
2.1 Ordering requirements according to memory consistency models . . . 27
2.2 MOESI cache coherence states . . . . 30
3.1 Target System Configuration . . . . 70
3.2 Multi-program workloads for 64-core CMP . . . . 83
4.1 Target System Configuration . . . . 117
5.1 SCORPIO specification . . . . 126
5.2 Description of Cache States . . . . 128
5.3 Cache Coherence Events . . . . 129
Chapter 1
Introduction
Continuous device scaling has managed to double transistor density every one or two years over last five decades. Throughout 80's and 90's, rapidly growing number of transistors were utilized to exploit instruction-level parallelism(ILP). Despite historic success, single-core performance scaling based on ILP eventually started to show diminishing returns from late 90's and has virtually stopped at present. Moreover, high power consumption has resulted in flattening of clock frequency, which was the other main driving force of single-core performance scaling. In order to satisfy ever-increasing computing demand, computer architects turned to explicit parallelism by applying surplus transistors to integrate multiple cores into a single chip. As a result, the past decade has witnessed every mainstream processor company producing Chip Multiprocessors(CMPs).
As of today, a tiled CMP arranged in a mesh topology is widely accepted to be a scalable architecture. Modularity of tiles eases the burden of design and verification of individual cores with CMPs, which enables ready scaling of core counts in a regular topology, leading to a many-core era. However, the increase of core count does not necessarily bring about as much performance gain. Communication overhead consi-derably affects the overall performance of multi-core computing, thereby being one of main performance bottlenecks.
On the other hand, shared memory has become the dominant programming model for CMP due to ease of programming and huge code base. Shared memory is especially attractive, since it allows multiprocessors to work on the same data structure as a single processor, which makes it easy to parallelize programs designed for a single processor. In shared memory CMPs, the memory system also takes on the role of communication architecture. Shared memory provides a single shared address space so that communication between processors implicitly happens by way of memory access.
For decades, the memory system has become a critical factor affecting the whole system performance. Accordingly, modern processors reserve significant die area for SRAM arrays, mostly in the form of on-chip caches, in order to mitigate the high delay of off-chip DRAM access. As is the case for any modern processor, on-chip caches play a key role in overall CMP performance. On-chip cache arrays are usually distributed to span across the entire chip, since a large many-ported central LLC(Last Level Cache) will lead to high delay, area and power penalties. On-chip cache acces-ses to remote tiles are handled by delivering the memory request-response pairs via on-chip network. Thus, the interconnect has a direct impact on on-chip cache per-formance. As bandwidth demand increases proportionally to the core count, scalable packetized network-on-chips(NoCs) have been adopted for various CMP platforms for both high-performance and mobile domain computing. However, on-chip cache and corresponding interconnect design still poses numerous design challenges and opportunities.
In shared memory CMP, communication between multiple cores implicitly occurs
by way of memory accesses, often involving long-range traversal over on-chip
inter-connect. As the on-chip interconnect directly influences the latency and bandwidth of on-chip cache, scalable interconnect that can efficiently transfer memory traffic is an essential part of on-chip cache design. On the other hand, optimal design of in-terconnect can be determined by the traffic forms that it should handle. For shared memory CMP, the interconnect performance depends on how well it can serve on-chip cache access which is the vast majority form of communication traffic. Thus, on-chip cache organization is inherently interleaved with on-chip interconnect design and vice
versa.
1.1
Thesis Statement and Overview
In this dissertation, we argue that co-design or co-optimization of on-chip cache and network can greatly improve the CMP performance. To harness the full potential of multiple cores, on-chip caches should be re-organized to leverage the advancement of on-chip network technology. Conversely, on-chip network should also be designed to support specific functionalities required by the on-chip cache.
The dissertation focuses on two important on-chip cache design problems to de-monstrate the power of co-design of on-chip cache and network. The dissertation starts with the problem of on-chip cache latency. Prior locality-aware approaches fundamentally attempt to keep data as close as possible to the requesting cores. In this dissertation, we challenge this design approach by introducing Locality-Oblivious Cache Organization, which leverages co-designed on-chip network that allows multi-hop single-cycle traversals. Next, the dissertation moves to tackle cache coherence request ordering. Without built-in ordering capability from on-chip network, cache coherence protocols have to rely on external ordering points which can forward the requests. In this dissertation, we propose a methodology that designs a scalable ordered Network-on-Chip providing coherence request ordering. Lastly, the disserta-tion describes development of a 36-core research prototype chip, named SCORPIO. With SCORPIO, we demonstrate that packetized on-chip networks with built-in ca-che request ordering capability can make shared memory CMPs readily scalable to a many-core platform with superior performance.
1.1.1
Locality- Oblivious Cache Organization
Scaling to many cores leads to higher remote cache access latency due to increased network hop count. To address this scalability issue, most prior efforts optimize data placement and locality so as to reduce communication overheads and ensure scala-bility. At the same time, there have been significant research into NoCs targeting on-chip communication latency. Over the years, researchers have aggressively
opti-mized router pipelines towards a single cycle pipeline latency [77, 78, 96, 98, 105]. However, even with single-cycle routers, delay inevitably increases with hop count as the number of cores grows.
Prior locality-aware approaches fundamentally attempt to keep data as close as possible to the requesting cores while minimizing unnecessary replication. The un-derlying premise is that accessing a remote cache is expensive. This dissertation challenges this design approach by introducing Locality-Oblivious Cache Organiza-tion(LOCO) [80]. We observe that what causes high interconnect latency today in accessing remote caches are pipeline latencies at intermediate routers, rather than wi-res themselves. LOCO leverages a co-designed on-chip network that allows multi-hop single-cycle traversals by virtually bypassing intermediate nodes. Such an on-chip network makes remote cache access no worse than an access to the local cache, the-reby obviating the reason for keeping local data in the first place. This motivates us to co-design a new cache organization adopting a locality-oblivious approach.
1.1.2
Ordered Network-On-Chip
While on-chip caches are an indispensable part of processors, multiple caches in CMP require the system to maintain cache coherence and memory consistency by using cache coherence protocol. Traditionally, cache coherence protocols relied on the in-terconnect to order cache coherence requests. On-chip inin-terconnect solutions built with simpler, centralized topology structures such as shared bus or simple crossbar, inherently support request ordering. As the number of actors on a single chip in-creases significantly, these traditional interconnects are facing scalability issues and packetized on-chip networks are a solution.
However, such on-chip networks with distributed routers are inherently unordered. Without built-in ordering capability from on-chip network, cache coherence protocols have to rely on indirection to serialization or ordering points which can forward the requests to other processors in order. In this dissertation, we present a novel network-on-chip(NoC) design with cache request ordering capability [81].
1.1.3
SCORPIO: A research chip prototype for scalable snoopy
coherence with in-network ordering
Commercial cache coherence standards predominantly support snoopy coherence. Ho-wever, relying on broadcasting incurs serious power and latency overheads with tra-ditional on-chip interconnects such as shared buses or multi-staged crossbars. On the other hand, although directory-based protocol is a popular choice for multi-processor systems with higher core count, it also poses scalability issues for increased directory storage and indirection latency as the core count continues to grow.
While a packetized on-chip network provides sufficient bandwidth and moderate latency for efficient broadcast routing, request ordering is another key challenge to re-alize scalable snoop coherence in many-core CMPs. The dissertation presents SCOR-PIO(Snoopy COherent Research Processor with Interconnect Ordering), a 36-core research prototype chip
[41].
SCORPIO demonstrates that on-chip network with built-in ordering capability can enable a many-core platform where existing commer-cial cores and IPs can be readily plugged into.This is joint work with fellow students: Bhavya Daya, Chia-Hsin Chen, Suvinay Subramanian, Sunghyun Park and Tushar Krishna. My contributions for the SCOR-PIO project was architecting Ordered-NoC, performance simulations for architecture explorations, and cache coherence protocol design.
1.1.4
Dissertation Organization
The rest of this dissertation is organized as follows. Chapter 2 provides relevant back-ground on shared memory CMPs, cache coherence, on-chip networks and SMART NoC. Chapter 3 presents the design of LOCO in detail, and argues that it is a sca-lable cache solution for future many-core CMPs with experimental results. Next, Chapter 4 explains how Ordered-NoC performs coherence request ordering, and de-monstrates that it delivers better performance than other alternatives. In Chapter 5 describes implementation of proposed design concepts into SCORPIO. Finally, Chap-ter 6 concludes this dissertation, and discusses potential future research directions.
1.2
Dissertation Contributions
The major contributions of this dissertation are summarized as follows:
1. We propose a novel on-chip cache design with co-designed on-chip network,
providing a scalable cache management solution for future many-core CMPs. The dissertation presents the following new design schemes:
* Virtual cache clustering for fast cache access and high cache hit rate
" Efficient global data search across virtual clusters
2. We propose new coherence request ordering method for packetized on-chip net-work. The proposed method introduces on-chip network design schemes as
follows:
" Request ordering by notifications in a separate ordering network " Efficient notification routing methods across a range of NoC designs " Network interface design with reorder buffers for flexible request reordering 3. We explore various co-designs of on-chip cache and network architecture, and
present evaluation results with full-system simulations. The dissertation de-monstrates that on-chip cache can improve the CMP performance significantly
by leveraging innovations in on-chip network design.
4. We discuss theoretical and practical issues in our effort to implement the pro-posed design concepts in a research prototype chip.
Chapter 2
Background
This chapter provides a relevant background to understand the rest of this disserta-tion. An overview of shared memory CMP is presented in Section 2.1, and then cache coherence is discussed in Section 2.2. Section 2.3 provides an introduction to on-chip network. Finally, Section 2.4 explains SMART NoC.
2.1
Shared Memory CMP
Shared memory has become the dominant programming model due to ease of pro-gramming and lower communication cost. Shared memory is especially attractive since it allows multiprocessors to work on the same data structure as a single proces-sor, which makes it easy to parallelize programs designed for a single processor.
For decades, memory system has become a critical factor affecting the whole system performance. In shared memory CMP, the memory system also takes on role of communication architecture. Shared memory provides a single shared address space so that communication between processors implicitly happens by way of memory access. Memory operations are initiated issuing memory requests into the memory system specifying the source and destination addresses, which are followed by the responses from the memory system. Memory operations are done transparently to
the processors, even though the underlying memory system is physically distributed. Remote memory access can be handled by delivering the request-response pairs via on-chip network.
In lower levels of the memory hierarchy, DRAMs are usually used as off-chip memory with high density memory cell arrays focusing on larger capacity at the cost of slow speed, which could consume hundreds of cycles to access data. On the other hand, the higher level memories resort to faster storage cells to enhance memory performance at the cost of reduced storage. For any modern processor, on-chip caches made of SRAM arrays play a key role in mitigating the high latency of off-chip DRAMs. On-chip caches are classified into Li with the smallest capacity for high bandwidth and low latency, and L2 with balance between speed and capacity. Li caches typically allow a single cycle access latency, while L2 caches are designed to consume tens of cycles. Some system also provides L3 cache with more storage but higher latency.
CMPs have various configurations regarding L2 cache arrangement. In early de-signs, cores are often located in one side, while L2 caches are placed in the other side [71, 17]. The interconnect is located in the middle, providing required band-width and connections. Shared large L2 cache with central ports provided uniform latency for all memory accesses, which suffered from limited bandwidth. Further-more uniform access resulted in long latency and high power consumption for every
L2 access.
NUCA(Non-Uniform Cache Access) was introduced to enhance average latency
[68]
by optimizing latencies of most frequently accessed data . In NUCA, large L2 chunk is divided into smaller slices to reduce look-up latency and power. By allowing shor-ter latencies in accessing close L2 banks, average inshor-terconnect latency can be greatly improved, although worst case latency is still high when accessing distant ones. Since L2 access latency depends on the location, design challenges are to optimize average latency by intelligent mapping or relocation of data [68, 32, 33].
However, finding optimal location is hard for data shared by multiple cores as shared data might relocate to the center, giving long latency for all sharers. Further-more, with the trend of increasingly large number of cores being integrated, larger
L2 Cache Core
LU =/D Cache Tags Data
Router
Directory
Figure 2-1: Tiled CMP Architecture
chip size can result in significantly high latency even for best cases.
Tiled CMP approach places a large cache chunk along with a processor in each tile, which provides short latency at least for data cached within the same tile, as shown in Figure 2-1. With minimal redesign and verification effort, the tiled CMP allows multiple identical tiles to be integrated into a single chip. Each tile also incorporates an on-chip network router providing point-to-point communication across the chip, which makes tiled CMPs readily scalable toward many-core CMP. This dissertation explores optimal cache design focusing on co-design with the on-chip network for tiled CMP with 2D-mesh topology which has been the norm for future many-core CMP research [112, 57, 127, 58j.
For tiled CMPs, L2 cache can be configured for two extreme baselines. Private cache uses local L2 slices exclusively for the core in the same tile, guaranteeing a minimal access latency to the local cores. However, shared data are duplicated in the L2 cache slice of each sharer, leading to low effective cache capacity. Private cache performs well with small working sets fitted in each local L2 cache slice, but may suffer from frequent off-chip memory access with larger working sets. In contrast, shared cache combines L2 cache slices of each tile into a large distributed shared L2, where each data has unique location. Cores are allowed to access L2 slices of other tiles, which usually statically mapped by the memory address. Since there are no
duplicate data copies, shared cache has maximum storage capacity which reduces off-chip memory access penalties for large working sets. However, increased cache capacity also results in higher interconnect latency in accessing L2.
Hybrids of private and shared cache were also proposed targeting at low hit latency like private cache as well as larger capacity like shared cache [130, 129, 20, 541. Hybrid caches attempt to increase locality, keeping data close to the requestors by intelligent replication and migration into local L2 cache slices. In future many-core CMPs, we expect smaller or not much increased L2 cache capacity per tile even with continuing device scaling, which hinders capability to utilize local L2 slices for controlled repli-cation. This observation motivates this dissertation to design locality-oblivious cache to obviate the need to replicate data in the local tiles in the first place.
2.2
Cache Coherence
2.2.1
Cache Coherence and Memory Consistency
The intuitive view of shared memory expects that read requests will always observe the latest write value to the memory. However, implementation of this intuitive shared memory is not straightforward in the presence of multiple local caches. While caches are an indispensable part of processors to alleviate high off-chip DRAM access delay and to reduce the communication traffic on the interconnect, they create cache coherence problem. If a variable is replicated into multiple local caches, processors can retain different values for the same variable in their local caches. Moreover, if two or more processors attempt to store new values into the same memory location simultaneously, processors might observe write values in different orders from each other. Thus, we need well-defined rules specifying correct shared memory behavior so as to provide a basis in writing parallel programs. These rules are often described in two separate concepts: cache coherence and memory consistency.
Cache coherence defines memory access ordering for the same memory location restricted by two constraints: (1) write must be eventually propagated to the system;
(2) writes to the same location must be observed in the same order by all processors.
Memory Consistency Total Ordering Program Write Early
for the same access to its
Model adesOrder Atomicity owWrt
address own Write
Cache Coherence /
Sequential Consistency
TSO, Intel x86/x64, RAR,WAR,
Sun Sparc v8 WAW
Processor Consistency V/ RAR, WAR, V
WAW
Sun PSO S RAR, WAR /
Weak Ordering,
Release Consistency, / /
IBM 370/Power, ARM
Table 2.1: Ordering requirements according to memory consistency models
location appear to occur in a single order which is consistent with memory request issuing order of each processor. In contrast, memory consistency model specifies behavior of shared memory across different memory locations.
Table 2.1 summarizes various memory consistency models classified according to their ordering requirements. In the table, if a memory consistency model enforces a specific ordering constraint, then it means that the order of corresponding memory accesses should conform to program order of each processor. A program order is the total order of memory operations specified by a sequence of loads and stores in the
control flow of program. There are four types of memory ordering (RAR, RAW,
WAR, and WAW), each of which indicates that a previous operation must complete before serving subsequent one, where R represents read and W write. Since processors can observe memory behavior only by issuing read and write requests to the memory system, each memory consistency model also specifies a rule about memory request ordering. For example, RAW(Read-After-Write) indicates that the memory system should serve read request after completing all preceding write requests.
The most straightforward memory consistency model is sequential consistency, in which memory operations are observed by all processors in a single sequence where
all four types of program order are preserved [83J. While sequential consistency corresponds to intuitive understanding of shared memory behavior, it leads to severe performance degradation by serializing all memory accesses. To alleviate performance impact of sequential consistency, techniques like hardware prefetching and speculative execution can be employed
[5,
1081. However sequential consistency also hinderscompiler optimizations from performing memory operations in parallel and exploiting out-of-order instruction execution.
As shown in Table 2.1, various relaxed consistency models are used for higher performance by allowing out-of-order completions of memory accesses. The multi-processors employ different memory consistency model by relaxing specific memory ordering constraints. In TSO(Total Store Order), for example, WAR(Write-After-Read) can be violated to allow buffering of writes; subsequent read operations can be processed before completion of preceding buffered writes, which helps to hide la-tencies of writes. Processors support special synchronization primitives when there needs to enforce additional ordering between memory accesses. The memory system should not complete all memory operations ahead of a memory fence or barrier before serving any subsequent one. Also, the compiler should support the memory fence by not relocating any memory operation across the fence.
2.2.2
Snoopy Cache Coherence Protocol
Multiprocessor systems maintain cache coherence and memory consistency by ap-plying cache coherence protocol. Traditionally cache coherence protocol assumed a shared bus as the underlying interconnect. A shared bus is a natural broadcast me-dium providing total request ordering, where all processors observe or snoop broadcast memory requests simultaneously. In a snoopy cache coherence protocol, all memory requests are broadcast through the interconnect. Processors snoop the memory re-quests in the same order, and take appropriate actions such as invalidating cache lines or forwarding memory values to the requesting processor. The cache state is also transited accordingly.
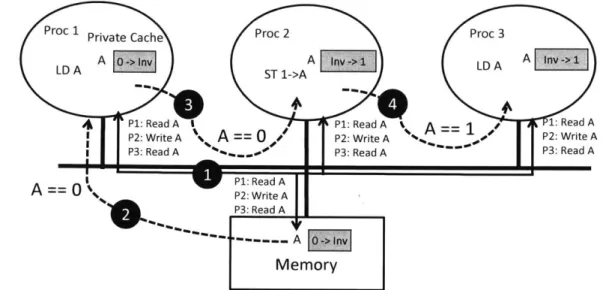
There is a basic. design choice about how to enforce write value propagation for snoopy coherence protocols. In the invalidation-based protocol, before overwriting
Proc 1 Private Cache Proc 2 Proc 3
LD A LAST ->Inv 1->A A InV>1 E LDA A Inv ->1
-~0 4 h
Pl: Read A I P1: Read A -- 1: Read A
P2: Write A
\
== 0 P2: WriteA AP2:WriteAP3: Read A adA P3: Read A
A == 0 131: Read A
P2: Write A
P3: Read A
Memory
Figure 2-2: Example of snoopy cache coherence protocol. 1) All memory access requests are broadcast in a single order and all processors snoop the same sequence of requests. 2) Memory responds to the first read request, and send the data to Processor
1. 3) Processors invalidate the cache line when receiving a write request from other
processors, thus maintaining cache coherence. The data response is delivered from Processor 1. 4) Processor 2 serves the last request by providing the latest value to Processor 3.
new values into any local cache, data copies must be invalidated from all other caches. After invalidation, other caches will result in read miss when accessing the cache line, and eventually fetch new values by invoking cache coherence protocols. In the write-update protocol, every write requires broadcasting the write-updated value to the entire system. Although write-update protocol has advantage that other caches can access latest values without cache misses, it can cause high amount of unnecessary network traffic. Accordingly most cache coherence protocols in practice adopt invalidation-based approach.
Figure 2-2 illustrates how invalidation-based snoopy coherence protocol resolves cache coherence problems. All processors snoop the same sequence of memory reque-sts in the example, and invalidate their own caches when receiving a write request from other processors. Processor can write new value only after receiving its own request from a bus, which guarantees that all other caches have been invalidated by receiving the same request from the bus. Then processor 3 can get the latest value
Cache Meaning Description
State
I Invalid The cache line is not present.
S Shared The cache line is clean, and can be shared by other caches.
The cache line can be clean or dirty, and can be shared by other caches. It is responsible for performing write-back when evicting the cache line, if the cache line is dirty. It must respond to a data request from other caches.
E Exclusive The cache line is clean, and is not present in other caches. It must respond to a data request from other caches.
The cache line is dirty, and is not present in other caches. It is
M Modified responsible for write-back when evicting the cache line. It must respond to a data request from other caches.
Table 2.2: MOESI cache coherence states
from processor 2, maintaining cache coherence.
Another design choice for handling write is write-thru and write-back. In the write-thru protocol, every write value is written back through all memories in the
memory hierarchy, including L2 cache and off-chip DRAMs. While write-thru is
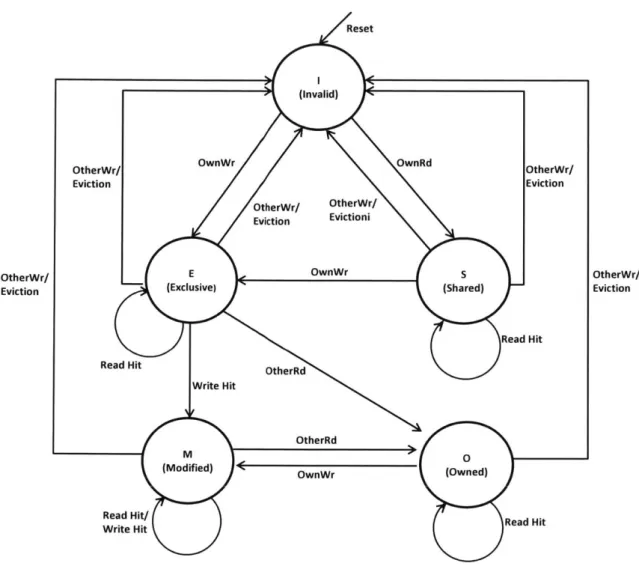
simple to implement, it makes write highly costly by generating network traffic for every write, thereby consuming huge bandwidth and power. Accordingly, most cache coherence protocols employ write-back approach instead. In the write-back cache, the data is written back to the memory hierarchy, only when the cache is flushed, which significantly reduces network traffic. Throughout this dissertation, we assume that the cache coherence protocol applies invalidation-based write and write-back policies. Figure 2-3 shows a state transition diagram for snoopy cache coherence protocol. that will be frequently referenced for the rest of this dissertation. The protocol has 5 states called MOESI (Modified-Owned-Exclusive-Shared-Invalid) described in Table 2.2. The protocol is based on write-invalidation. Before writing new value,
Reset
(invalid)
OtherWr/ OwnWr OwnRd OtherWr/
Eviction Eviction
OtherWr/ OtherWr/
Eviction Evictioni
OtherWr/ E OwnWr S OtherWr/
Eviction (Exclusive) (Shared) Eviction
Read Hit
Read Hit oherRd
Write Hit
OtherRd
M 3
(Modified) e OwnWr (Owned)
Read Hit/
Read Hit
Write Hit
Figure 2-3: State transition diagram for MOESI cache coherence protocol
cache controllers broadcast their own write requests to other caches. On snooping a
write request from others, the cache line in the local cache must be invalidated. It also supports cache-to-cache data transfer to reduce off-chip memory access latency. When there are multiple sharers of data, O(Owned) state is responsible for supplying the value to new requestor.
For correct operation of snoopy cache coherence protocol, it is crucial for all proces-sors to snoop the memory requests in the same order. Many existing commercial
ca-che coherence protocols such as MOESI in Intel QPI
[60],
AMD HyperTransport[35],
AMBA ACE[12] and OCP 3.0[4], are also based on snooping, and require theinter-connect to order memory requests, so that all processors observe the requests in the same order, at least, for the same cache line address.
Snoopy cache coherence protocols require every coherence request to be broadcast to all processors in the system. Relying on broadcasting over the entire system poses a serious scalability problem with rapidly growing core count. To cope with ever in-creasing bandwidth demand, on-chip interconnects, which used to be based on shared buses or rings with central arbiters, have gradually become more like a small-scale network with hierarchical buses or cascaded crossbars with distributed arbitrations, and then evolved to adopt full-fledged network-on-chips(NoCs).
For cascaded buses or rings, snoopy cache coherence protocols can be implemented
by maintaining connections in a tree structure. Snoopy cache coherence protocol is
locally applied to a bus or ring at each level, and global request broadcasting is ordered in up-and-down propagations through the hierarchy. Hierarchical snooping is a relatively simple extension, but it has inherent bandwidth limitation and high latency problems due to the tree topology.
Snoopy coherence protocols can be implemented even atop unordered on-chip networks; coherence requests are first sent to ordering point, often referred to as home node or directory, and forwarded to the processors in a single order. However, although the ordering point allows the system with higher core count to functionally work with snoopy protocols, it aggravates the scalability problems such as indirection latencies and serialization delays. In this dissertation, we will tackle this challenge by proposing scalable on-chip network with built-in request ordering capability(Chapter 4).
Another scalability problem for snoopy coherence protocols arises from the re-quirement that all processors should snoop every coherence request, which leads to high network traffic and energy consumption. To alleviate the broadcasting over-head, various snooping filtering techniques have been also proposed, as explained in Chapter 2.2.4.
2.2.3
Directory Cache Coherence Protocol
There is an alternative implementation of cache coherence protocol designed to avoid costly broadcasting. In the directory cache coherence protocol, all coherence
reque-sts are first routed to the directory which performs request ordering. Further, the
directory maintains a table to keep tracks of sharing status of each cache line, and forwards the requests only to the sharers of the cache line. The directory stores cache sharing information with a bit-vector where sharing status of each core is represented
by a corresponding bit presence.
The directory protocol does not require broadcast medium or global request orde-ring. When the protocol has an additional requirement, the unordered interconnect can be implemented to preserve point-to-point ordering for each source-destination pair. Since the directory protocol can implemented with unordered networks, it is re-adily scalable to the system with higher core count. Nonetheless, it also cannot avoid performance degradation, since the directory essentially works as ordering points in the snoopy protocol, which causes indirection latencies and serialization delays in forwarding memory requests. Tracking cache sharing status also comes with the cost of extra complexity in both design and verification. Figure 2-4 illustrates how the directory protocol operates to maintain cache coherence. Unlike the snoopy protocol, the directory has an exact cache status information of all cores, and thus avoids un-necessary broadcasting. However, it also incurs additional directory indirection step, while the snoopy protocol enables direct cache-to-cache transfers.
There are many design issues that can greatly affect cache coherence and overall shared memory performance. One such problem occurs from concentrated network traffic for the directory. As every cache request must be forwarded from the direc-tory, centralized directory easily becomes a communication bottleneck. To mitigate network congestion, directory can be organized in a distributed way so that partiti-oned directory slices are located across the chip. The directory partition is usually statically determined by the cache line address, and the node containing the direc-tory entry corresponding to the cache line is called the home node for the coherence request.
The disadvantage of distributed directory organization is to lose a single ordering point that can give a global request order. In contrast, distributed directories can enforce request ordering only for the same memory region, while a global request order is useful to implement strong memory consistency models such as sequential
Proc 1 Private Cache Proc 2 Proc 3
LD A A InvST 1->A A LDA
LDA %\ _P1: Read A P2: Write A A ==0 Pl: Read A A I A o o o 0 Me mory Directory (a)
Proc 1 Private Cache Proc 2 Proc 3
LD A A L+Inv ST 1->A A Inv1 LD A
A== 0 %\ A==1 P2: Write A P3 edA P3: Read A A A 0 011 -0 Memory Directory (b)
Figure 2-4: Example of directory cache coherence protocol. 1) 2) 3) Coherence re-quests are sent by point-to-point communication to the directory. 4) Directory serves the requests in the receiving order. Initially, there is no sharer for the address A. It forwards the read request to Memory. 5) Memory returns the data response to Processor 1. 6) Directory serves the next write request. It forwards the request to Processor 1, the only sharer. 7) Processor 1 invalidates its own cache copy, and re-turns the data to Processor 2. 8) 9) Directory serves the last request, and Processor 2 receives the forwarded request and returns the data response to Processor 3.
consistency. In the distributed directory scheme, the directory can also be organized hierarchically to enhance scalability. Directories are organized in a tree structure,
where higher level directories keep track of lower level branches to determine whether having a cache copy. Directory look-up traverses the tree from the root to leaves to find sharers, where internal nodes are directories and leaves are processors.
2.2.4
Scalable Cache Coherence
The directory protocol has generally superior scalability to the snoopy counterpart since it does not require request broadcasting. However the directory protocol has its own scalability issues as well. First, directory storage requirements increase pro-portionally to on-chip cache size and core count. In a full-bit vector scheme, sharing statuses of all cores are recorded by corresponding bits. When a full-bit vector is used, a directory entry for 64-core CMP requires 64 bits per cache line, which amounts to a half of typical cache line size for x86 processors. The total storage requirement is given by C - P, where C is the total number of cache lines on the system and P is the total core count.
The most common techniques to reduce the directory storage overhead is to limit number of the directory entries by utilizing on-chip directory as a cache, while the the main directory is stored in off-chip main memory. When a directory miss occurs, directory entry is replaced to fetch the corresponding entry from the main memory. Another common technique is to use limited pointers instead of full-bit vectors. Limi-ted pointer scheme can be implemenLimi-ted in various ways according to how to manage the overflow when the number of sharers exceeds the limit. When more sharers exist in the system than the the directory can track, the protocol can invalidate one of sharers to maintain the maximum number of sharers within possible range. In anot-her implementation, it can revert back to broadcasting when the directory entry can no longer accept new sharer.
In coarse vector scheme, each bit in the bit-vector represents a group of multiple nodes instead of one core. Invalidation and forwarding should be multicast to all those nodes represented by the same bit in a trade-off between performance and storage overhead. Dynamic pointer scheme creates links to free space in the directory to store additional sharers when the overflow occurs.
sea-lability problem, as core count continues to scale. The directory protocol requires a directory forwarding step, thereby causing additional latency, which adversely af-fects overall system performance. In contrast, snoopy protocol allows direct cache-to-cache transfers by the design. This dissertation tackles aggravated communica-tion cost for many-core CMPs in two different approaches. With LOCO, we present new on-chip cache and network design to enable fast memory access even to a re-mote L2 cache(Chapter 3). We also show that snoopy protocol can be realized in many-core CMPS without performance degradation by indirection to the ordering points(Chapter 4).
On the other hand, there have been various proposals to reduce broadcasting overhead of the snoopy protocol by snoop filters. Similar to the directory, snoop filters track cache sharing status for the purpose of filtering irrelevant snooping of coherence requests. While directory maintains exact sharing information per cache line, snoop filters are designed usually in coarse granularity for a moderate storage overhead. Snoop filters have been proven to be very effective in mitigating broadcasting overhead for scalable snoopy coherence protocol.
In the destination snoop filter, a filtering table is placed at the snooping interface of each core. The table contains cache sharing information of the corresponding core, preventing the core from snooping coherence requests for non-shared cache lines [27]. These destination snoop filters can save energy for unnecessary cache tag look-up, and reduce cache bank conflicts. On the other hand, source snoop filters placed at the source side, can even reduce overhead of interconnect energy and bandwidth by filtering out irrelevant requests before issuing broadcast through the interconnect.
For a scalable snoopy protocol for many-core CMPs, various on-chip network techniques have also been proposed. In-network Cache Coherence
[441
embeds the cache sharing information through the on-chip network routers. Similarly, snoop filters can be implemented by in-network embedding of cache sharing status[8].
FA-NIN/FANOUT mechanisms are proposed to provide efficient routing of concurrentnetwork flows of 1-to-many and many-to-1 communications generated by coherence request broadcasting and response collection
[761.
novel on-chip cache and interconnect designs. These filtering and network techni-ques are orthogonal and complementary to our solutions. They can be applied to the proposed cache designs to achieve further improved scalability, by alleviating communication overhead of the underlying snoopy protocols.
2.3
Network-On-Chip
In a traditional multiprocessor system with small core count, on-chip communication architecture mostly relied on a shared bus. As increasingly large number of cores are integrated, bus-based interconnects have become a primary bottleneck with limited bandwidth and prohibitive power consumption. NoCs(Network-On-Chips) have emer-ged as a scalable on-chip communication solution for many-core CMPs. An NoC is an embedded network on the chip, applying the techniques adopted from large-scale computer networks, such as data packetization and distributed routing. The NoC utilizes concurrent point-to-point communications to provide scalable bandwidth and energy efficiency. This section provides an overview of state-of-the-art NoC design.
2.3.1 Topology
The NoC topology is concerned with how routers are arranged and wired with each other. The topology significantly affects bandwidth, latency and ease of layout. Net-work topologies are assessed based on several criteria. The bisection bandwidth is the minimum bandwidth over all possible bisections, where a bisection partitions a network into equally-sized two parts and the bandwidth of bisection is measured by the sum of channel capacities between two bisected parts. Diameter is the maximum
hop-distance over all pairs of two nodes, where hop-distance of a pair of nodes is
given a smallest count of hops over all possible paths between two nodes. Cost of network is measured by the number of wire connections, represented by asymptotic notation where N is the total number of cores.
Figure 2-5 shows most common types of NoC topologies. Ring is relatively simple with O(N) cost, as illustrated in Figure 2-5a. It is also easy to implement cache coherence with a centralized arbiter. Ring has been adopted for many commercial
DComputing
NodeERouter
(a) Ring (b) 2D-mesh
H
I I
H
H
'I:"
I I(c) 2-ary n-fly Butterfly
(d) Tree (e) Irregular Topology
Figure 2-5: NoC Topology Examples
systems such as IBM Cell/Power5 [64, 66] and Intel Haswell/Larrabee/Skylake [56,
110, 122]. However, ring is not scalable for many-core, as bisection bandwidth remains
constant and the network diameter grows only linearly as core count increases. Figure 2-5b shows 2D-mesh. It has identical link lengths which eases physical
If
design and layout. The area and link cost grows linearly while the diameter is within
O( N). 2D-mesh is the most popular topology in CMP research, and has been adopted in MIT RAW, Intel TeraFlops, Tilera and many other many-core CMP pro-totypes 1125, 57, 127]. However, 2D-mesh is asymmetric and communication latency is affected by node locations. To overcome these limitations, 2D-torus provides with long links connecting two nodes at the opposite edges. However, 2D-torus is not as wi-dely employed as 2D-mesh, since it has unequal link lengths which brings unfavorable effect for physical layout.
We have so far discussed direct topologies where computing cores are connected to all network nodes. Tree is an example of indirect topology where computing cores are connected only to end points(tree leaves). It has only 0(log N) latency as well
as cheap link cost of O(N). However, higher traffic requirements at upper level links easily lead to network congestion. Fat tree was also proposed to address congestion problem by providing more links near root nodes. Figure 2-5c shows another popular indirect topology, k-ary n-fly butterfly network. The butterfly network is a multi-stage network with n stages, each of which consists of k x k crossbars. It has 0(N log N)
link cost with O(log N) latency.
In regular topologies, node and link connections are designed to follow structured connection rules. On the other hand, irregular topologies are customized and opti-mized at design time to result in irregular structures, as depicted in Figure 2-5e. We can tailor the NoC topology to specific core types or applications, which is widely used for heterogeneous computing cores and System-On-Chips(SoCs).
In this dissertation, we mainly focus on 2D-mesh topology, as it is the most popular choice for many-core CMPs with moderate linear cost growth and ease of physical design.
2.3.2
Switching and Flow-Control
Switching establishes path connection for the message delivery. Switching is classified in two broad categories:
Circuit-switching establishes the entire source-destination path. The path is reserved for specific messages so that they can be sent without intermediate ar-bitrations and interference from other traffics. However circuit-switching causes
high path set-up overhead and inefficient link utilization.
e Packet-Switching
In packet-switching, messages are divided into packets, and each packet is routed independently to the next router. While packet-switching requires arbitration overhead at each router, it is more flexible and the links can be more efficiently shared and utilized. As a result, most NoCs adopt packet-switching for higher bandwidth with multiple network traffics.
For packet-switching NoC, arbitration and switching can be performed on smaller units of flow control. The smallest unit that can be managed by flow control is called flit(flow control unit), and each packet comprises of multiple flits. We call the first flit the header and the last the tail. Packet-switching can be further classified according to buffer management schemes as the following:
" Store-and-Forward switching
In store-and-forward, entire packet is buffered before proceeding to the next router. The buffer at each router should be sized to contain the whole packet.
" Cut-through switching
Cut-through switching reduces transmission latency by forwarding flits to the next router before storing the whole packet. In virtual cut-through switching, the buffer size is still required to hold the entire packet, as flow control is applied to the packet level. In contrast, wormhole switching has no restriction to the buffer size as the flit is the unit of flow control.
Flow control allocates network resources like buffer capacity and channel band-width to the messages, to prevent overflowing of channel buffers and dropping of flit.
" Ack-Nak
The receiver sends Ack or Nak signals to confirm that the flit is received. One drawback is that sender buffers can be emptied only after getting a confirm signal, leading to inefficient buffer utilization.
" On-Off
The sender continues to send flits until receiving back pressure signal from the receiver. If the receiver buffer level reaches the threshold, the receiver sends off
signal to the sender. After the buffer is sufficiently drained, the receiver toggles the signal to on. The signal toggling should be early enough to make up for turn-around delay, which may lead to underutilization of buffers.
" Credit-based
The sender knows the exact number of available buffers at the receiver by col-lecting credits. The receiver sends a credit to the sender when there is new buffer entry available, and the sender consumes credits for sending subsequent flits. Credit-based scheme can also incur underutilization of buffers by turn-around delay including credit generation and processing delays.
2.3.3
Routing
Routing selects a message path from source to destination with goals to minimize latency and to maximize bandwidth. Deterministic routing algorithms always choose the same path for given source-destination pair, which leads to simpler implemen-tation with less area and power consumption. In contrast, adaptive algorithms can produce different routing paths based on the network status feedback. They involve higher logic complexity, but potentially reduce network congestion by distributing traffics across the network.
Routing can cause deadlock when packets wait for buffers occupied by other pac-kets in a circular waiting chain. To prevent deadlock, routing algorithm can prohibit certain turns to avoid circular waiting relation between routing paths. XY-routing in 2D-mesh, for example, packets always traverse first in X-dimension, then in Y-dimension. XY-routing is widely used for its simplicity and deadlock-free property.