Solving Inverse Problems by Joint Posterior Maximization with a VAE Prior
20
0
0
Texte intégral
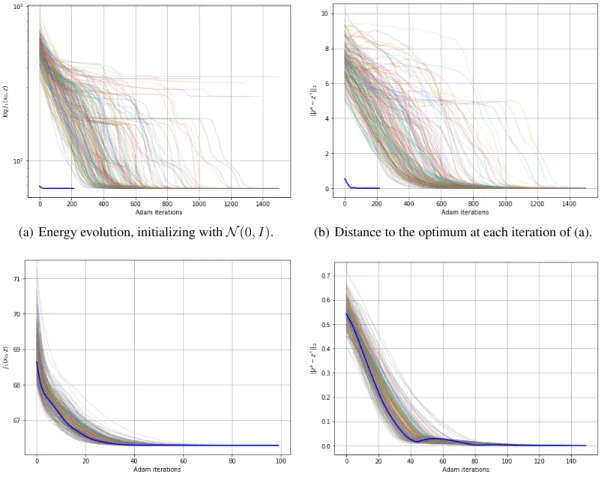
Figure

Documents relatifs
