HAL Id: hal-02794012
https://hal.inrae.fr/hal-02794012
Submitted on 5 Jun 2020HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
Portage d’un fichier Excel de Diagnostic
Multifonctionnel des systèmes fourrager (DIAM) en une
application JAVA
Yoann Alvarez, Raphaël Bevenot
To cite this version:
Yoann Alvarez, Raphaël Bevenot. Portage d’un fichier Excel de Diagnostic Multifonctionnel des systèmes fourrager (DIAM) en une application JAVA. Environnement et Société. 2014. �hal-02794012�
Rapport d’ingénieur Projet de 2ème Année
Filière : Systèmes d’Information et Aide à la Décision
Portage d’un fichier Excel de Diagnostic
Multifonctionnel des systèmes fourrager (DIAM) en
une application JAVA
Présenté par : Yoann ALVAREZ et Raphaël BEVENOT
Responsable ISIMA : Alain Tanguy
Responsables Projets : Pascal Carrère et Raphaël Martin
Institut National de la Recherche Agronomique Site de Crouël 5 Chemin de Beaulieu 63039 CLERMONT-FERRAND CEDEX 2 Institut Supérieur d’Informatique, de Modélisation et de leurs Applications
Campus des Cézeaux 24 avenue des Landais BP 100125
63173 AUBIERE Cedex
Soutenance du 21 mars 2014
i
Remerciements
Nous tenons à remercier d’une part nos encadrants de l’INRA : messieurs Pascal CARRERE et Raphaël MARTIN qui, par l’intermédiaire du projet DIAM nous ont mis à contribution pour améliorer cet outil.
D’autre part nous remercions notre enseignant tuteur, M. Tanguy, pour son engagement dans le projet et son aide pendant les différentes réunions.
ii
Résumé
L’objectif du projet est de finaliser le développement d’un logiciel en Java se basant sur l’outil DIAM (Diagnostic Multifonctionnel des exploitations agricoles) qui fonctionne actuellement sous forme de feuilles de calculs Excel. Cet outil permet de diagnostiquer l’autonomie fourragère, la cohérence du système fourrager et les services rendus par les surfaces herbagères d’une exploitation agricole.
Au début du projet, il existait une interface et une base de données en XML. Nous avons décidé de repenser l’architecture du programme dans le but de le rendre maintenable en gardant seulement la base de données. Après avoir analysé la structure du document Excel nous avons produit une application maintenable avec une interface graphique dans l’esprit du document initial.
Mots-clés : DIAM, INRA, Agriculture, Excel, Portage de Logiciel en JAVA
Abstract
The project goal is to finalize the development of software in Java based on the DIAM tool (Diagnostic Multifonctionnel des exploitations agricole) currently in Excel. This tool allow making a diagnosis that focuses on forage autonomy, system coherence and the services provided by grassland areas.
At the beginning, there was an interface and a database in XML. We decided to think again the architecture program to make it maintainable, we kept only the database. After analyzing the structure of the Excel document we produced a maintainable application with a graphical interface in the spirit of the original document.
iii
Table des matières
Remerciements ... i
Résumé ... ii
Abstract ... ii
Table des matières ... iii
Tables des figures ... iv
Introduction ... 1
I. Contexte du projet ... 2
1. Présentation de l’INRA et de l’UREP ... 2
2. Présentation du logiciel DIAM ... 3
Objectif ... 3
Fonctionnement ... 4
Projet Initial ... 7
3. Le projet ... 8
Cahier des Charges ... 8
Technologies utilisées ... 9
Organisation ... 10
II. Travail réalisé ... 11
1. Données en entrée ... 11
Analyse ... 11
Programmation ... 13
Interface ... 14
2. Formules de calculs et Résultats ... 18
Analyse des formules ... 18
Implémentation des formules ... 20
Tests ... 22
III. Résultats et suite du projet ... 24
1. Résultats ... 24
2. Suites possibles ... 25
iv
Tables des figures
Figure 1. Organigramme de l'UREP ... 3
Figure 2. Sommaire du Fichier Excel ... 5
Figure 3. Extrait d'une typologie du fichier Excel ... 6
Figure 4. Affichage des résultats du Module Environnement ... 6
Figure 5.Diagramme de Gantt Prévisionnel ... 10
Figure 6. Diagramme général du modèle ... 12
Figure 7. Exemple de sous division de la classe Terrain ... 13
Figure 8. Présentation de l'outils GUI Design de NetBeans ... 14
Figure 9. Onglet d'Accueil de l'application ... 15
Figure 10. Onglet de saisie des Troupeaux ... 17
Figure 11. Onglet Achats et Stocks ... 17
Figure 12. Onglet de gestion des Prairies ... 18
Figure 13. Exemple de Formule Complexe ... 19
Figure 14. Exemple de matrice d'indicateurs ... 20
Figure 15. Exemple d'indicateurs similaires présent dans des onglets différents ... 21
Figure 16. Diagramme UML de l'organisation des classes de calculs ... 22
Figure 17. Exemple d'un test réussi ... 23
Figure 18. Exemple d’un test partiellement échoué ... 23
1
Introduction
L’agriculture durable a pour objectif de réduire l’impact humain en matière environnementale. C’est dans cette optique que l’INRA a initié « Le développement durable en agriculture ». Cette ambition rend nécessaire la conception de systèmes de culture et d’élevage innovants.
Les recherches de l’INRA visent à inventer de nouvelles méthodes d’organisation pour les productions agricoles. Le but final étant de concilier compétitivité et qualités des produits tout en respectant l’environnement.
L’Unité de Recherche sur l’Ecosystème Prairial (UREP) participe à cet élan de gestion durable de l’écosystème prairial grâce à ses chercheurs. Leurs recherches permettent de comprendre les variables clés et les mécanismes liés à ces écosystèmes et de proposer des indicateurs aux agriculteurs.
C’est notamment l’objectif de l’outil DIAM. Ce dernier propose d’aider l’agriculteur dans les choix concernant son exploitation. Il permet en outre de garantir la qualité du lait et du fromage AOP du Massif Central.
Le but du projet est d’appréhender l’outil DIAM sous sa forme Excel et d’en créer un logiciel en langage Java. Ce logiciel devra se composer d’une interface utilisateur permettant la saisie des données, d’effectuer les calculs et de générer des fichiers de sortie. La finalité du projet est de développer une version mobile de l’outil et permettre une utilisation sur le terrain.
Nous détaillerons dans un premier point le contexte du projet, en insistant sur les objectif et fonctionnalités du logiciel. Nous présenterons ensuite notre travail, en détaillant d’abord le travail réalisé sur les données saisies en entrée, puis celui réalisé sur les formules et calculs des indicateurs. Enfin nous détaillerons le résultat obtenus et les possibilités d’évolution futures.
2
I. Contexte du projet
1. Présentation de l’INRA et de l’UREP
L'Institut National de la Recherche Agronomique (INRA) est un organisme français de recherche en agronomie fondé en 1946. Il participe activement à l’innovation et au développement de la culture scientifique. L’INRA regroupe plus de 1800 chercheurs et près de 2500 ingénieurs. Les problématiques traitées par l’INRA sont nombreuses, et touchent à divers domaines : écologie, génétique, santé, mathématiques et informatique appliquée… Pour chacune de ces grandes problématiques l’INRA a mis en place un département.
Le département qui nous intéresse aujourd’hui est celui dédié à « l’Ecologie des Forêts, des Prairies et des milieux Aquatiques » (EFPA). Ce département a pour objectif de « gérer durablement, conserver et restaurer les écosystèmes forestiers, prairiaux et aquatiques, ainsi que les ressources physiques et biologiques qui en dépendent et les productions de biens et de services qui y sont associées. » Afin de travailler à cet objectif ambitieux, ce département a mis en place plusieurs Unités de Recherche (UR ou UMR, M pour Mixte). C’est pour une de ces Unité de Recherche que nous avons mené le projet : l’UREP, Unité de Recherche sur l’Ecosystème Prairial.
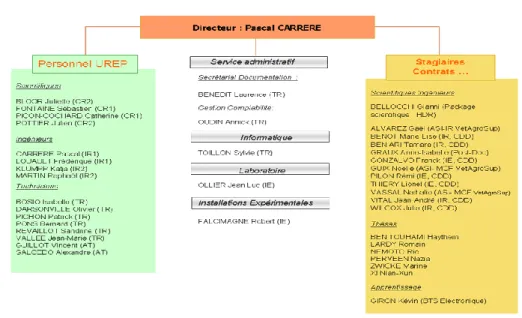
Située près de Clermont-Ferrand, sur le site INRA de Crouël, l’UREP se concentre principalement sur les problématiques liées aux prairies et en particulier sur « l'écologie, le fonctionnement et les services de la prairie permanente dans un contexte de changement global ». Elle est composée d’environ 40 personnes et est dirigée par M. Pascal Carrère, qui est à l’origine de ce projet. M. Raphaël Martin, qui nous a encadrés durant tout le projet, est un des ingénieurs travaillant à l’UREP.
3
Figure 1. Organigramme de l'UREP
Un autre acteur est également présent autour du projet DIAM, il s’agit de l’Unité Mixte de Recherche (UMR) sur les Herbivores est une autre unité de recherche de l’INRA. C’est une unité mixte entre VetagroSup (école d’ingénieur Clermontoise) et l’INRA qui travaille en particulier au « développement des systèmes durables d’élevage des herbivores tout en intégrant la viabilité socio-économique des exploitations ». Ce double objectif, environnemental et économique, est particulièrement important et prend tout son sens avec le projet DIAM.
Le projet DIAM étant un projet extrêmement transverse, d’autres acteurs y ont également contribué : le Pôle Fromager AOP Massif Central, diverses chambres d’Agriculture, le ministère de l’Agriculture ainsi que plusieurs éleveurs.
2. Présentation du logiciel DIAM
Objectif
DIAM est un outil de DIAgnostic Multifonctionnel du Système Fourrager. Il s’adresse en principalement aux éleveurs, et plus particulièrement à ceux dont la production est principalement laitière. L’outil permet d’établir un diagnostic complet et détaillé, à l’échelle de l’exploitation agricole entière.
L’outil prend en entrée plusieurs données : détails des prairies de l’exploitation, achat de consommables (engrais, fourrages…), détails des troupeaux, état des stocks de fourrages... À
4 partir des données saisies on génère ensuite des rapports complets détaillant la performance de l’exploitation sur divers aspects : autonomie fourragère, protection de l’environnement, qualité du lait et des fromages…
Le diagnostic ainsi généré permet à l’éleveur d’évaluer la cohérence de son exploitation et plus particulièrement de son système fourrager (la manière dont sont alimentés les troupeaux). L’éleveur pourra alors plus facilement identifier les éventuels problèmes de son exploitation, et pourra alors les résoudre. De même en procédant à une évaluation régulière d’une exploitation (1 fois par an), l’éleveur peut constater sa progression.
L’outil DIAM part également du constat que les prairies (utilisées soit pour faire paitre les animaux, soit pour faire du foin) ont un impact important sur la qualité du lait (et à terme du fromage) produit par les vaches. L’éleveur peut alors estimer la contribution de ses prairies à la qualité finale des fromages. Cette évaluation pouvant alors le conduire à changer l’utilisation de ses prairies afin d’améliorer la qualité de lait produit.
L’outil possède ainsi une double utilité: d’une part il concentre une grande partie des informations de l’exploitation, d’autre part il permet de générer des rapports et d’évaluer une exploitation. C’est donc à la fois un outil de stockage et un outil d’évaluation.
Fonctionnement
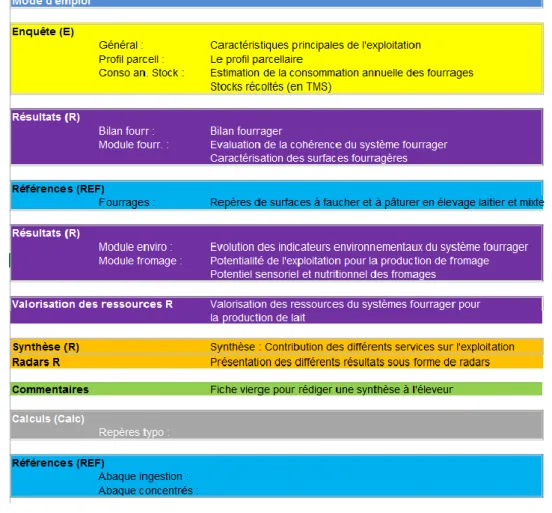
L’actuel outil DIAM prend la forme d’un fichier Excel très complet, composé d’une vingtaine de feuilles: feuilles de présentation/mode d’emploi, feuilles de saisie de données, feuilles de résultats, feuilles d’abaques et feuilles de calculs intermédiaires. Ce fichier est principalement utilisé par les techniciens agricoles liés à la chambre d’agriculture. Le fichier est rempli avec les agriculteurs qui pouvaient alors avoir un bilan des forces et faiblesses de leur exploitation, et obtenir des conseils de la part du technicien ou d’experts pour s’améliorer.
5
Figure 2. Sommaire du Fichier Excel
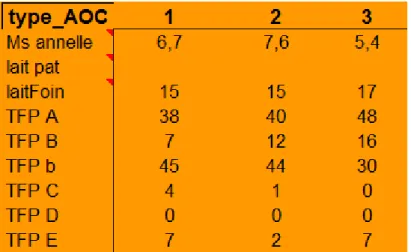
Les bilans permettant d’évaluer l’exploitation reposent principalement sur le typage des prairies présentes dans l’exploitation. En effet des travaux de recherche de l’INRA ont permis d’identifier différents types de prairies, appelés typologie de prairie. Ces typologies regroupent des indicateurs qui sont ensuite directement utilisés dans les rapports. Ces typologies sont directement présentes dans le fichier Excel. La typologie d’une prairie permet également de déterminer les fromages AOP (Appellation d’Origine Protégée) auxquels l’éleveur peut prétendre.
6
Figure 3. Extrait d'une typologie du fichier Excel
La figure ci-dessous est un extrait des typologies telles que présentes dans le fichier Excel. En haut on peut lire le numéro de la typologie (il y en a actuellement 23 de recenser dans le fichier), et à gauche les indices caractérisant les typologies. Ces typologies sont le fondement même du logiciel DIAM, 80% (si ce n’est davantage), des indicateurs reposent dessus.
Ces indicateurs sont regroupés dans le logiciel par catégories, à l’aide d’onglets. L’ensemble de ces onglets formant alors ce qu’on qualifie de rapport ou de diagnostic. Afin de donner de la lisibilité aux valeurs, des graphiques sont souvent utilisés pour afficher le résultat.
7 Le fichier Excel utilisé pour DIAM est donc un fichier Excel très dense, regroupant à la fois des données générales (typologies), des données saisies, des abaques et des guides pour aider le technicien agricole, des feuilles de calculs entières, et des feuilles de sorties. C’est ce mélange complexe qui est à l’origine du projet donné à l’ISIMA.
Projet Initial
Au fil du temps le projet DIAM a réussi à s’imposer et à être de plus en plus utilisé. Ce succès l’a conduit à s’enrichir de nouveau de calculs et de fonctionnalités. Le fichier Excel est alors devenu lourd à maintenir et à gérer. C’est pourquoi l’équipe en charge du projet a demandé que l’outil soit porté dans le langage de programmation JAVA. Le portage de l’outil avait alors pour objectifs:
fiabiliser l’outil: vérifier la cohérence des formules entre tous les onglets et centraliser les données (qui étaient souvent dupliquées dans le fichier Excel). Le portage devait également permettre également de vérifier et verrouiller davantage la saisie des données afin d’éviter ou de détecter la saisie de données incohérentes.
gagner du temps: les possibilités offertes par un langage de programmation permettent d’envisager des améliorations jusqu’alors difficiles voire impossibles à mettre en place avec Excel. Par exemple en informatisant les abaques utilisés pour remplir certaines données ou en offrant des listes de choix plutôt qu’une saisie manuelle.
séparer les données: le fichier Excel mélangeant de nombreuses données, le portage était l’occasion de mieux séparer les données. En particulier les typologies recensées étant communes pour toutes les exploitations, il a été décidé de créer une base de données externe pour les regrouper.
ouvrir de nouvelles possibilités : le portage devait également permettre d’envisager de nouvelles fonctionnalités telles que la comparaison des diagnostics effectués à des dates différentes, la mise en place d’une application mobile… Le premier projet de portage a été proposé fin 2012 à des étudiants de 3ème année à l’ISIMA (Alice Goret et Quentin Lorthiois). Ces étudiants ont travaillé sur une première version de DIAM, effectuant une analyse des formules du fichier Excel et codant un système de stockage pour les données des typologies en XML.
8 Afin de poursuivre le travail commencé en 2012, un nouveau projet a été proposé à l’ISIMA en octobre 2013. Nous avons choisi ce projet, géré par M. Pascal Carrère et M. Raphaël Martin et avec comme responsable ISIMA M. Alain Tanguy.
3. Le projet
Cahier des Charges
Au départ les objectifs du projet étaient de finaliser le travail commencé en 2012 avec en particulier les objectifs suivants :
rajouter les formules manquantes dans le logiciel
améliorer et compléter la saisie des données
créer des interfaces pour afficher les résultats
pouvoir exporter les résultats dans un fichier PDF
Néanmoins le cahier des charges et les objectifs ont rapidement dû être modifiés. En effet, il s’était écoulé un délai important entre la fin du projet précédent et ce projet (7 mois). Durant cette période le fichier Excel source a changé, et de nombreuses données (en saisie comme en résultats) ont été rajoutées. D’autre part il s’est avéré que le travail d’analyse des formules du groupe précédent était seulement écrit, et qu’il n’y avait pas eu d’implémentation logicielle de ces dernières.
Face à ces problèmes il a fallu reprendre une partie importante du projet à zéro. Seule la base de données XML des typologies ayant été conservée. Aussi l’objectif du projet, qui était au départ la mise en place d’une interface graphique complète, a été modifié. Les contraintes liées à l’interface et ont été réduites, tandis que la priorité devenait d’avoir un programme fonctionnel au niveau des données saisies et restituées.
Au cours des réunions, qui se sont tenues durant le projet, d’autres contraintes ont également été particulièrement mise en avant:
l’outil DIAM étant fréquemment mis à jour il fallait que le code soit facilement compréhensible, modifiable et maintenable.
l’interface type Excel était assez appréciée, aussi l’interface graphique du logiciel final devrait utiliser elle aussi un système d’onglets et des tableaux.
9
la partie interface, et en particulier l’affichage des résultats, était une priorité, même si elle n’était pas optimale. En effet le projet commençant à durer dans le temps, il fallait pouvoir montrer à des non informaticiens que le travail avançait. D’un point de vue technique nous avons également dû suivre certaines règles :
utilisation du langage JAVA
utilisation de la sérialisation XML pour l’enregistrement des fichiers
utilisation de la bibliothèque jFreeChart pour l’affichage des graphiques
utilisation du SVN de l’INRA pour versionner le projet
Sur le plan technique le projet était donc assez contraint, d’un côté par le code déjà existant, de l’autre par les demandes de l’INRA. Les technologies utilisées sont détaillées dans la partie suivante.
Technologies utilisées
JAVA : Le Java est un langage de programmation orienté objet développé par Sun dans les années 1990, il a la particularité d’être devenu au cours du temps une technologie multiplateformes grâce à l’environnement d’exécution JRE (autrement appelée machine virtuelle Java) qui exécute les programmes écris dans ce langage. Il fonctionne donc aussi bien sous Windows que sous Linux.
NetBeans : NetBeans est un environnement de développement intégré (IDE) qui permet de développer en Java grâce à l’environnement de développement JDK. Il intègre aussi un environnement graphique exploitant Swing et facilitant la création d’interfaces.
Swing : Swing est une bibliothèque graphique pour le langage Java. Elle permet de créer des interfaces identiques quel que soit le système d’exploitation.
XML : Le XML est un langage informatique de balisage. Il permet entre autres le stockage de données et sert dans le cadre du projet de base de données.
XStream : XStream est une bibliothèque pour le langage Java pour faciliter l’utilisation de fichiers XML. Il permet la lecture et la modification des objets en XML.
10
Organisation
Avant de pouvoir planifier notre travail, il a d’abord fallu récupérer le travail effectué par nos prédécesseurs afin de comprendre ce qu’ils avaient exactement réalisé comment ils l’avaient fait. Malheureusement le code n’était pas commenté et aucun document spécifique (diagramme UML par exemple) n’avait été réalisé pour expliquer l’organisation du code.
Nous avons néanmoins réussi, après quelques efforts, à comprendre le code dont nous avions hérité. Nous avons alors pu sélectionner les parties à garder et les avons réorganisées (lorsque c’était nécessaire).
Comme indiqué précédemment, la seule partie qui était complète et qui a été conservée était celle de la gestion de la base de données des typologies.
Suite à la reprise du travail effectué, et par rapport aux exigences du projet nous avons découpé le projet en 4 grandes phases :
modélisation des éléments en entrée
codage des formules
création d’une interface graphique pour la saisie des données en entrée
création d’une interface graphique pour l’affichage des résultats. Nous avons ainsi planifié le diagramme de Gantt suivant:
Figure 5.Diagramme de Gantt Prévisionnel
Concernant les rapports avec les commanditaires du projet nous avons eu une première réunion au complet (avec M. Martin, M. Carrère et M. Tanguy). Les réunions suivantes se sont faites au rythme d’environ une par mois, et sans la présence de M. Carrère. Chaque réunion a fait l’objet d’un compte-rendu (disponible en annexe). En dehors des réunions nous avons communiqué par mail.
11
II. Travail réalisé
1. Données en entrée
Analyse
Avant de pouvoir coder il a donc d’abord fallu effectuer une analyse complète du fichier Excel utilisé pour DIAM. Cette analyse devait nous permettre à la fois de comprendre le fichier Excel et aussi de permettre de savoir comment coder notre logiciel, en établissant une modélisation des différents éléments intervenants dans le logiciel.
L’objectif d’un modèle informatique des données utilisées par le logiciel est de présenter et quantifier les différents éléments rentrant dans l’évaluation d’une exploitation (prairies, troupeaux, fourrages…), mais aussi de montrer les relations qu’entretiennent les éléments entre eux. Cette phase est très importante, car elle conditionne ensuite la manière dont sera développé le logiciel. Une modélisation réussie permet un développement plus rapide ainsi qu’une meilleure lisibilité et compréhension du code.
Pour réaliser cette analyse nous avons eu recours à UML : Unified Modeling Language (Langage de Modélisation Unifié) qui est un langage graphique de modélisation parfaitement adapté à ce type de problème. Nous avons en particulier utilisé les diagrammes de classes d’UML, dont l’objectif est la représentation des éléments d’un système ainsi que des liens généraux qu’ils entretiennent.
Cette phase d’analyse a été particulièrement difficile. Le modèle n’était pas très compliqué en lui-même, mais devoir le déterminer à partir d’un fichier Excel est relativement difficile. En effet, la modélisation d’un problème se fait classiquement à partir de zéro, en discutant avec les acteurs de leurs besoins et de leur manière de travailler. Cela permet de construire dès le départ un modèle, sans avoir trop de contraintes externes.
Ici la situation était complétement différente. Nous devions reprendre un outil déjà existant, qui n’avait pas été réalisé par des informaticiens, et sans contact direct avec les utilisateurs. Il fallait alors bien comprendre le fonctionnement de l’outil pour pouvoir le modéliser ensuite. Le risque était de ne pas parvenir à s’extraire suffisamment de la manière dont le fichier était organisé. En effet il fallait éviter de tomber dans le piège de reprendre la modélisation du fichier Excel (par exemple de faire une classe par Feuille), cette dernière
12 présentant quelques faiblesses. D’autre part il fallait comprendre une partie des sigles et termes utilisés afin d’avoir une modélisation cohérente et de bien repérer les dépendances entre les éléments.
La modélisation du système reposait principalement sur les données saisies en entrée, mais il a quand même fallu vérifier en parallèle les formules et les sorties afin de vérifier la cohérence de l’ensemble. Nous avons ainsi pu mettre en évidence que certaines données saisies étaient en réalité calculables à partir d’autres données déjà rentrées. L’analyse a donc permis de simplifier le modèle, et donc de permettre un gain de temps à l’avenir avec moins de valeurs à saisir.
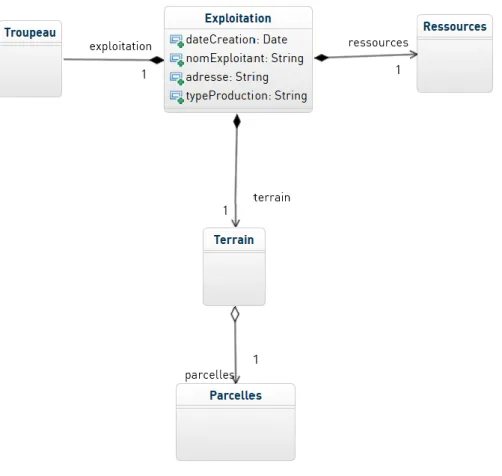
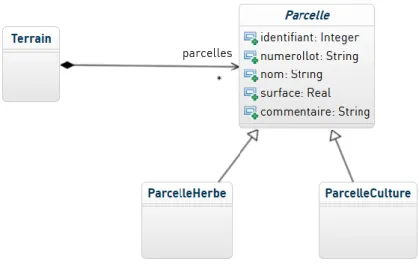
Figure 6. Diagramme général du modèle
Le modèle final n’est pas extrêmement complexe. Une exploitation est composée de 3 éléments principaux : un terrain, composé lui-même de parcelles, de troupeaux et de ressources (engrais, achat de fourrages…). Chacun de ces éléments est ensuite lui-même décomposé en sous-catégories. Par exemple le Terrain est composé de Parcelles, qui
13 peuvent être de différents types, soit dédiées à la culture, soit dédiées aux troupeaux (ce sont alors des prairies, appelées ici ParcelleHerbe.
Figure 7. Exemple de sous division de la classe Terrain
En procédant par affinements successif des classes, nous avons ainsi pu déterminer 15 classes représentant les données en entrée. Une fois le modèle déterminé, il fallait alors le programmer.
Programmation
La programmation du modèle a été relativement simple. L’analyse préalable ayant permis de bien appréhender le logiciel. Les structures utilisées pour coder le modèle étant des structures basiques en JAVA, nous n’avons pas eu de soucis majeurs.
Évidemment, lors de l’implémentation nous nous sommes rendu compte qu’il existait quelques petites erreurs dans le modèle que nous avons alors pu corriger. De même que nous avons pu trouver encore d’autres manières d’optimiser notre modèle.
Bien que la phase de programmation du modèle ne soit pas très dure, elle fut relativement longue, car il y avait un nombre important de classes et d’attributs à coder. De plus nous avons accordé une importance particulière à la vérification des valeurs qui pouvait être donnée et à la gestion des exceptions en cas d’erreurs. Cela permet de fiabiliser le logiciel, mais augmente de manière non négligeable le temps de développement.
14 En même temps que la programmation du modèle avançait, nous développions un jeu de données pour pouvoir effectuer ensuite des tests. L’INRA nous avait fourni des jeux de tests sous format Excel, que nous avons alors repris. En développant le jeu de données en parallèle du modèle, nous pouvions rapidement évaluer la qualité et la pertinence de notre modèle, et donc le corriger si nécessaire.
Interface
Le cahier des charges nous indiquait d’utiliser la bibliothèque graphique Swing pour réaliser cette interface. Nous avons utilisé l’outil GUI Design, disponible dans l’IDE Netbeans, pour faciliter la création d’une interface graphique et donc gagner du temps. Cet outil permet de créer des fenêtres graphiques par Drag and Drop (glissé/déposé).
Figure 8. Présentation de l'outils GUI Design de NetBeans
L’idée principale qui a guidé la création de l’interface a été la volonté de garder l’esprit initial du document Excel, les utilisateurs finaux étant les mêmes que les utilisateurs du document. Pour cela nous avons, comme dans le projet de l’année dernière, décidé d’utiliser un système d’onglet dans lequel nous avons mis les différentes catégories de données.
Nous trouvons en premier lieu les onglets permettant la saisie des données (Accueil, troupeaux, cultures, prairies, achats & stocks). Ils permettent à l’expert de rentrer toutes les
15 informations nécessaires aux calculs. Les onglets de calculs n’ont pas encore été implantés à l’heure où nous écrivons ce rapport.
Les différents onglets ne sont pas exactement les onglets disponibles dans le document Excel. En effet, après avoir analysé les différentes données disponibles dans le document Excel, nous les avons regroupées par catégorie comme expliqué dans la partie II.1.Analyse. Cette analyse a permis de créer des onglets plus épurés et rassemblant les informations essentielles de chaque catégorie. Cette amélioration a été possible grâce au langage Java et permettra un gain de temps dans la saisie des données. Des modifications sont toutefois possibles.
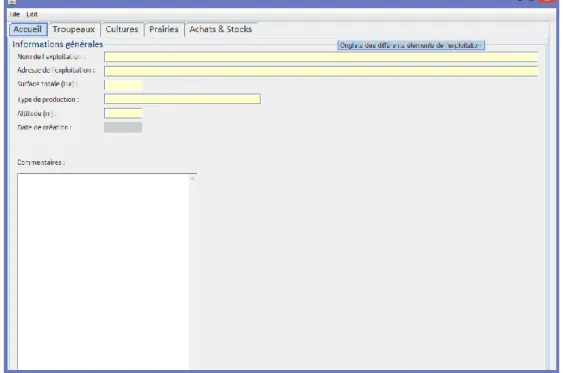
Plus spécifiquement l’onglet « accueil » permet à l’expert de créer un nouveau profil d’exploitation ou d’éditer une exploitation déjà créée. On retrouve dans cet onglet les informations principales de l’exploitation: son nom, son adresse et quelques informations générales. On enregistre par ailleurs la date de création du profil, cette dernière n’est pas modifiable et est générée dès la création du profil. Nous avons ajouté un espace pour indiquer des commentaires souvent nécessaires pour faire des annotations concernant l’exploitation.
Figure 9. Onglet d'Accueil de l'application
16
les cases jaunes sont à remplir avec l’éleveur
les cases blanches (bleu sur le document Excel) sont à remplir par le conseiller
les cases grises sont réservées pour les calculs
Cela a été mis en place pour ne pas déstabiliser les conseillers dans l’utilisation de l’application nous doutant que la transition entre un document Excel et une application puisse rebuter certaines personnes.
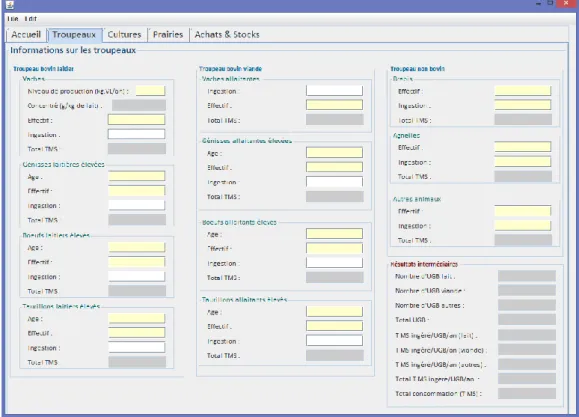
L’onglet « Troupeaux » se décompose en quatre parties comme on peut le voir dans la feuille « (E) Conso an. Stock » du document Excel. Il y a donc une partie pour les troupeaux bovins laitiers, une pour les troupeaux bovins élevés pour la viande et une autre pour les autres troupeaux (Brebis, Agnelles et autres animaux). Une dernière partie a été mise en place pour afficher des résultats intermédiaires relatifs aux troupeaux. On peut donc y voir rapidement la consommation en matière sèche des différents troupeaux ainsi que la consommation annuelle de fourrage. Cette volonté d’afficher des résultats intermédiaires permettra à l’expert de voir immédiatement si des erreurs ont été faites dans la saisie des données et aussi d’avoir un aperçu des premiers résultats, les calculs portant seulement sur les données de cet onglet.
17
Figure 10. Onglet de saisie des Troupeaux
L’onglet « Achats & stocks » est formé de deux parties, une partie sur les ressources achetées par l’agriculteur où l’on peut inscrire la quantité de concentrés, de fourrage ou encore d’engrais acheté comme présenté dans la feuille de calcul « (E) Général ». La deuxième partie se concentre sur les récoltes de l’agriculteur de la même manière que la feuille « (E) Conso an. Stock ». Encore une fois notre choix de regrouper différents éléments de feuilles distinctes a été fait afin de faciliter la saisie des données et de rendre l’application Java plus épurée.
18 Les autres onglets, « Cultures » et « Prairies », sont composées d’un tableau chacun issu de la feuille de calcul « (E) Profil parcell. ». Nous avons gardé la même présentation car elle semblait être la plus pertinente.
Figure 12. Onglet de gestion des Prairies
Nous avons aussi implémenté une fenêtre pour choisir les typologies des prairies. Cette fenêtre a été demandée dans le cahier des charges pour aider les conseillers à choisir les typologies. La méthode implémentait pendant le projet de l’année dernière ne fonctionnait pas toujours et n’était pas forcément pratique. En effet certains conseillers connaissent, sans avoir à remplir une table, la typologie des prairies qu’ils diagnostiquent et veulent vérifier les caractéristiques de cette typologie. Cette vérification n’était pas possible auparavant comme nous l’a constaté M. Martin. La nouvelle fenêtre se veut aussi simple que la précédente avec l’ajout d’une partie pour entrer un numéro de typologie.
Une fois la modélisation du système terminée, il fallait ensuite s’intéresser aux formules de calcul et aux indicateurs que doit générer le programme.
2. Formules de calculs et Résultats
Analyse des formules
Outre la modélisation du système il a également fallu effectuer une phase d’analyse des formules. Ici la démarche a également été complexe, mais pour d’autres raisons que précédemment. En effet, il ne s’agissait pas cette fois de déterminer les éléments du système, mais davantage de comprendre leur utilisation dans le cadre des calculs. Il ne s’agissait pas non plus de simplement comprendre les formules de calculs et ensuite de les coder. Le problème a donc représenté une triple difficulté.
19 Premièrement la complexité de certaines formules, les rendait longues à comprendre. Certaines formules étaient à la fois longues et faisaient appel à d’autres cellules, présentes sur d’autres feuilles, et elle-même étant issue d’une autre formule complexe. Il fallait alors « remonter » les formules en cascades afin de pouvoir déterminer la formule complète.
Figure 13. Exemple de Formule Complexe
Deuxièmement l’organisation et la modélisation du logiciel JAVA étant différentes de celles du fichier Excel, il fallait alors réaliser la conversion de l’un à l’autre. Cette conversion n’était pas difficile, mais elle était particulièrement longue à effectuer. De même que pour la modélisation des entités il ne fallait pas faire l’erreur
Enfin, certaines valeurs étaient parfois utilisées à de nombreuses reprises, de même que certains raisonnements mathématiques. Il fallait alors réussir à identifier les éléments récurrents, afin de pouvoir les factoriser ensuite dans le code. Il était préférable de réussir à voir ces factorisations en amont du développement mais ce n’était pas toujours facile. S’il est simple de voir que lorsqu’une cellule est utilisée à plusieurs reprises, il est en revanche plus difficile de voir que deux cellules sont identiques. Dans ce dernier cas l’analyse permet alors de fusionner ces cellules et donc de centraliser une partie des calculs afin d’éviter d’écrire plusieurs fois du code identique.
20
Figure 14. Exemple de matrice d'indicateurs
Dans cet exemple les indicateurs sont donnés pour quatre types de prairies différentes (toutes les prairies, celles dédiées à la pâture des vaches laitières, à la pâture des génisses et celles dédiées à la fauche). De même, la plupart des indicateurs affichés ici sont des moyennes d’un indicateur précis (souvent donné par la typologie de la prairie). Aussi plutôt que de créer une méthode pour chaque combinaison type de prairie/indicateur l’analyse a permis de préférer l'utilisation d’une méthode (formule de calcul) unique paramétrée par le type de surface et l’indicateur. On passe alors de plusieurs centaines de cellules Excel (celles utilisées pour les calculs des indicateurs) à quelques dizaines de lignes de codes, soit un gain de lisibilité et de réutilisabilité conséquent.
Une fois cette analyse effectuée il a fallu coder les formules dans le logiciel.
Implémentation des formules
La programmation des formules dans le logiciel a été une étape assez longue. L’analyse de départ permettait de savoir ce qu’il fallait faire, mais pas nécessairement comment il fallait le faire. Nous nous sommes posé de nombreuses questions quant à la répartition des tâches de calculs dans le logiciel. En effet, plusieurs cas étaient possibles. Nous allons détailler ici les 3 organisations envisagées et indiquer celui retenu.
La première organisation considérée était de déléguer les formules de calculs aux éléments sur lesquelles elles s’appliquent. Par exemple, on aurait mis dans la classe Troupeaux les formules liées aux troupeaux, dans la classe Terrain les formules liées aux prairies, etc… Ce scénario a vite été écarté, pour deux raisons. D’une part certaines formules touchaient plusieurs éléments bien distincts (Troupeaux + Prairie par exemple). D’autre part ce modèle liait trop les données aux formules, ce qui nuisait à la maintenabilité et à la lisibilité du code.
21 La seconde organisation était de créer des classes regroupant des calculs pour une problématique donnée. Par exemple une classe recensant toutes les données liées au module fourragé, une dédiée aux calculs pour le fromage, etc… Cette organisation reprenait beaucoup l’esprit de celle du fichier Excel. Elle était déjà meilleure que la précédente mais avait l’inconvénient de ne pas suffisamment factoriser certaines méthodes communes à plusieurs rapports. De plus, on mélangeait la notion d’affichage à celle des calculs.
La dernière organisation, celle finalement retenue, a été de créer des classes de calculs, et des classes paramétrant les calculs. Ainsi les classes de calculs factorisaient la quasi-totalité des méthodes de calcul. Et des classes dédiées à chaque problématique regroupent les méthodes dédiées à une problématique, qui elles, font appel aux méthodes calculs factorisés en leur donnant les bons paramètres. Ce scénario a l’avantage de bien séparer les éléments, le modèle de données, les formules et le regroupement d’indicateurs sont bien distincts. De plus les formules nécessitent parfois de « traverser » assez profondément certaines classes. En les ayant regroupé, on diminue le nombre de méthodes et d’appels à modifier en cas de modification du modèle.
Un exemple de cette organisation est donné ci-dessous :
22 La figure ci-dessus, présente des indicateurs liés à l’environnement (au-dessus), et des indicateurs liés au fromage (au-dessous). Ils sont présents sur deux feuilles de calculs différentes, mais utilisent des formules très proches. En effet la plupart de ces indicateurs sont des moyennes de valeurs données par les typologies. Avec notre organisation on se retrouve avec les classes suivantes :
Figure 16. Diagramme UML de l'organisation des classes de calculs
On voit bien ici le découpage entre les classes. Les classes de Bilan font appel à la classe CalculsTerrain en lui passant les bons paramètres, et cette dernière réalise les calculs en utilisant la classe Terrain et les Typologies des prairies.
Une fois l’implémentation réalisée, il a fallu vérifier que les formules donnaient les bons résultats.
Tests
Comme nous avions déjà réalisé un jeu de test dans le cas de la programmation du modèle, et que nous connaissions grâce au fichier Excel les résultats à obtenir, nous pouvions vérifier le bon fonctionnement de nos formules.
Afin de réaliser les tests nous avons utilisé l’outil JUnit, directement intégré dans NetBeans. Cet outil permet de vérifier facilement si les résultats fournis correspondent à ceux qui devraient être obtenus.
23
Figure 17. Exemple d'un test réussi
Dans le cas où il y a une erreur on obtient une fenêtre de ce type :
Figure 18. Exemple d’un test partiellement échoué
Ici on remarque que deux méthodes ont échoué (GetSurfaceTotale et GetSurfaceCulture). Le programme indique ce qui était attendu, et ce qui a été finalement renvoyé. On peut ainsi facilement voir les méthodes qui posent problème et les corriger.
Les tests JUnit présentent aussi l’avantage de permettre de vérifier que les formules fonctionnent toujours après une modification du code (ce sont des tests de non-régression). Nous avons ainsi pu détecter et corriger rapidement nos erreurs lorsque nous programmions. L’intégralité des indicateurs utilisés dans le logiciel a été portée dans le logiciel, et ils fournissent tous les résultats attendus. D’autre part l’affichage des résultats n’est pas terminé à l’heure où ce rapport est écrit, mais nous espérons pouvoir les finir avant la remise finale du projet.
24
III. Résultats et suite du projet
1. Résultats
Présentons d’abord le diagramme de Gantt final :
Figure 19. Diagramme de Gantt Final
Par rapport au diagramme initial, deux choses importantes sont à souligner. D’une part à l’heure de la publication de ce rapport, la génération des sorties n’est pas encore en place. Nous espérons néanmoins pouvoir en réaliser une, avant la fin du projet afin d’avoir un logiciel complet (même si non optimal). D’autre part, nous avions sous-estimé la charge de travail sur certains points. Nous avons eu de nombreuses surprises lors du projet qui nous ont fait perdre un temps conséquent. Par exemple nous avons dû refaire une partie de la base de données des typologies, car il manquait certains indicateurs, ou parce que certains types de données étaient erronés (entier au lieu de nombres réels).
Le modèle est complet, et possède bien toutes les données en entrée. Toutes les classes issues du modèle que nous avons réalisé ont été implémentées. L’objectif principal de la modélisation était de faciliter la poursuite du projet sachant que nous n’aurions pas pu implémenter la totalité du cahier des charges. Ainsi toutes les classes sont complètement commentées.
Les méthodes de calcul ont elles aussi étaient totalement implémentées et ont été vérifiées à l’aide du framework de test unitaire JUnit. Là encore un soin particulier a été porté sur l’organisation du code et aux commentaires. En effet, si on peut s’attendre à ce que le modèle ne soit pas trop changeant, les formules sont en revanche susceptibles d’être modifiées plus souvent. Par exemple dans le projet, une quinzaine de formules ont été modifiées, nous obligeant à reprendre notre code pour impacter les modifications. Grâce à un code propre et maintenable, les modifications futures seront aisées. Le prochain groupe pourra se focaliser sur les fonctionnalités annexes comme l’amélioration de l’interface.
25 La présence des tests unitaires et du jeu de test permettra également de facilement mettre à jour le logiciel à l’avenir tout en vérifiant l’impact des modifications. C’est un gain de temps pour la maintenance ou la reprise du projet.
La possibilité de sauvegarder les diagnostics des différentes exploitations a aussi été implémentée (à l’aide de la bibliothèque XStream). Le format XML a été choisi pour la sauvegarde afin que les utilisateurs puissent ouvrir les fichiers de sauvegarde et comprendre le contenu.
L’interface de saisie des données est complète, bien qu’encore améliorable. Elle a l’avantage de correspondre aux habitudes des utilisateurs de l’application DIAM et sera surement une bonne manière d’effectuer la transition du fichier Excel vers le logiciel JAVA.
2. Suites possibles
Le projet actuel est fonctionnel mais il subsiste quelques améliorations possibles. Étant donné l’état initial du projet nous avons voulu recréer une structure plus adaptée à la maintenabilité du code. Cette étape nous a pris un temps conséquent ne permettant pas d’atteindre les objectifs initiaux du projet. Nous nous sommes focalisés sur la création de classes facilement modifiables et sur l’écriture systématique de commentaires pour expliquer les rôles de chaque méthode et attribut.
Quelques améliorations peuvent donc être effectuées sur le projet notamment pour améliorer l’interface utilisateur. Les calculs ont été implémentés dans le code mais il n’y a toujours pas de fenêtre permettant de les voir. Cette amélioration est donc primordiale pour que les experts de l’INRA puissent utiliser l’outil. De plus certaines facilités d’utilisation n’ont pas été mises en place. Il faudrait analyser plus en profondeur les besoins des experts pour avoir une interface qui réponde à leurs besoins. On peut penser notamment à l’ajout plus intuitif de ligne dans les tableaux des onglets « Cultures », « Prairies » et « Achat et stocks ».
Une autre amélioration possible est la génération de fichiers montrant les résultats des analyses. L’agriculteur a besoin d’avoir après son rendez-vous avec l’expert des schémas récapitulatifs sur son exploitation. Cela lui permet de garder en tête les résultats fournis par le diagnostic DIAM. Cette génération pourra se faire au format PDF par exemple. En particulier c’est une génération de rapports paramétrable qui intéresserait l’INRA. Il faudrait que l’on puisse choisir les graphiques et indicateurs à afficher dans le rapport afin de donner à chaque
26 éleveur un rapport personnalisé, centré sur ses attentes. Cet aspect de personnalisation était difficilement réalisable avec Excel, mais devient parfaitement envisageable avec ce programme Java.
De plus la possibilité d’enregistrer plusieurs diagnostics pour une même exploitation devient envisageable. Cette fonctionnalité pourrait ainsi permettre de voir l’évolution d’une exploitation au cours du temps, et donc de quantifier les progrès accomplis par un éleveur.
L’idée initiale qui a impulsé le projet est la volonté de l’INRA d’ajouter à l’outil DIAM des fonctionnalités tel que le stockage et la séparation des données ainsi que de gagner du temps. Sur le long terme, l’INRA envisage de porter le logiciel en Android. Ce portage est un axe d’amélioration non négligeable car il permettrait la portabilité de l’outil et donc l’augmentation de l’utilisation et de l’utilité de ce dernier. On pourrait ainsi imaginer des rendez-vous avec l’éleveur directement sur son exploitation, ce qui permettrait à un expert de mieux évaluer les prairies et leur typologie. Cela améliorerait ensuite la précision des indicateurs et les conseils donnés à l’éleveur.
27
Conclusion
La première partie du projet a consisté en une longue analyse de l’outil qui a permis la conception d’un modèle (Diagramme UML). Cette modélisation a permis de clarifier le fonctionnement de DIAM et a facilité par la suite le développement de l’application.
Le temps imparti pour la réalisation de ce projet nous a permis de réaliser une interface utilisateur permettant la saisie des données et d’effectuer les calculs. La sauvegarde des diagnostics est aussi possible. L’accent a été mis sur la maintenabilité du code sachant que nous ne pouvions satisfaire la totalité du cahier des charges.
Le logiciel actuel a donc un code implémentant la totalité du document Excel calculs compris, la base de données XML, l’interface graphique permettant la saisie des données et la fenêtre de typage.
Ce logiciel peut donc servir de base pour un futur projet qui sera orienté sur la mise en place d’une interface plus étoffée permettant de générer un fichier de sortie.
28
1
3
Compte rendu de la réunion du 05/11/2012
Présents : Raphaël MARTIN, Pascal CARRERE, Alain TANGUY, Yoann ALVAREZ, Raphaël BEVENOT
Philosophie : L'outil de Diagnostic Multifonctionnel des exploitations agricole (DIAM) est né il y a cinq ans. C'est un outil qui, à l'heure actuelle, fonctionne et permet de caractériser le type d'une prairie (rendement, quantité de fourrage produit etc.). Cela permet de développer les filières de qualités et de garantir une valorisation du potentiel d'une exploitation. Cest aussi bénéfique pour le consommateur qui a une garantie de la qualité du produit. Il permet d'un autre côté d'évaluer les impacts des exploitations agricole et donc de conseiller les agriculteurs
DIAM est un outil prospectif qui à partir de données récoltées permet de déterminer le type d'une parcelle. A partir de ce typage on peut déterminer le rendement de cette patûre et par la suite réfléchir à des scenari possible. DIAM devient donc un outil de conseil essentiel pour les exploitants.
Attentes
:
Il faut arriver à une version finale qui affiche un résultat à partir des entrées. La version doit être stable et fonctionnelle. Le maintien sera assuré par l'INRA.
L'application doit rester sobre, dans l'esprit de la première version JAVA.
Le projet final doit être évolutif et donc garantir une maintenabilité. En effet seulement 21 types de prairies ont été répertorié sur les 61 actuellement existante. Un projet portera sûrement sur cet ajout l'année prochaine.
Générer des fichiers de sortie (pdf) en accord avec la charte graphique. A terme faire une application Android permettant la mobilité de l'outil.
Outils utilisés :
4
L'environnement graphique sera Swing
L'IDE conseillé/utilisé sera Eclipse.
Les bases de données sont en xml
A venir :
S'imprégner du sujet, du code, du fichier excel
Se documenter sur les parutions à propos de DIAM pour garder la philosophie du projet
S'imprégner de la charte graphique
5
Compte rendu de la réunion du 13/12/2012
Présents : Raphaël MARTIN, Alain TANGUY, Yoann ALVAREZ, Raphaël BEVENOT
Ce que nous avons fait :
• Diagramme UML
• Restructuration des programmes avec création de nouvelles classes • Ajout de commentaires
• Mise en place de tests des valeurs rentrées
• Analyse des données à donner pour permettre une maintenabilité de l'outil • Enlever les redondances de saisie de données
• L'interface n'as pas encore été touché • L'idée était de remodélisé DIAM
Peut-être faire :
• Sauvegarde ? Faire un conteneur pour l'exploitation, sérialisé ? • SerialUID version de la classe. Vérifier la version.
• Première version qui fonctionne de A à Z pour être montré. Tous les onglets disponibles. • Générer le rapport et l'esthétique n'est pas prioritaire
• Faire une checkbox pour les prairies semés et les prairies permanentes. • Cliquer sur le type ouvre le PDF du type de la prairie
• Rendre la selection du typage plus pratique (arbre de décisions ?) • Faire en sorte que l'utilisateur puisse choisir manuellement le typage
• Bouton + pour ajouter une ligne, poubelle pour supprimer (fenêtre confirmation), autre bouton pour supprimer, bouton typo (renseignement sur la typo), crayon pour editer, bouton + en fin de ligne pour dupliquer
6 • Tortoize (SVN), checkout, ecraser données avec ce qui a été fais
7
Compte rendu de la réunion du 05/01/2013
Présents : Raphaël MARTIN, Alain TANGUY, Yoann ALVAREZ, Raphaël BEVENOT
Ce qu’on a fait :
Modification du diagramme UML selon les modifications que l’on fait
Le bilan fourrager a été fait
Une partie du modèle pour le diagnostic aussi
Une classe pour chaque feuille de résultat a été faite
On n’a pas réussi à utiliser la JFreeChart, utilisation de Xchart pour l’instant
La sérialisation se fait avec Xstream (Il faudra insister sur le fait que l’expert ne devra pas modifier ce fichier)
Ce qu’on va faire :
Utiliser JFreeChart que vous nous avez donné
Travailler sur l’interface (juste entrée les données, afficher les résultats)
Commencer le rapport (intro, contexte, plan, partie modélisation, description des fonctionnalités)
Remarques :
Les sorties sont un objectif secondaire