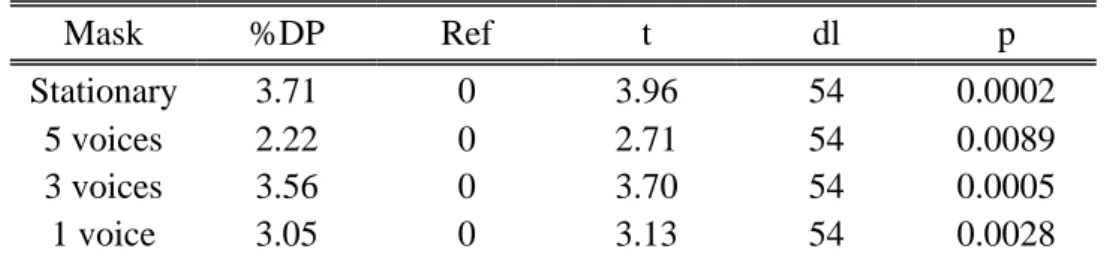
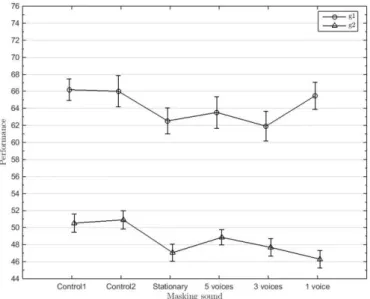
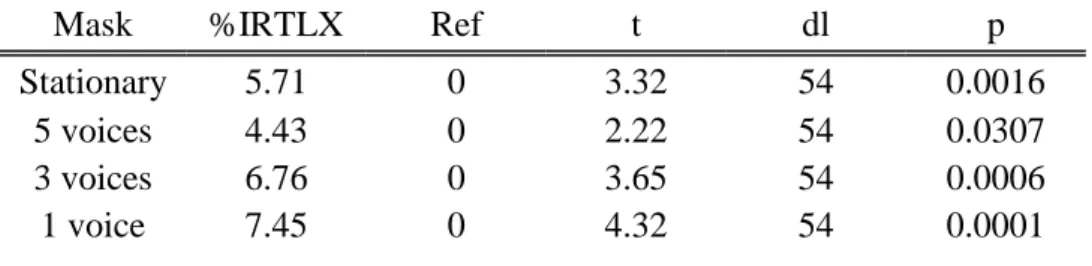
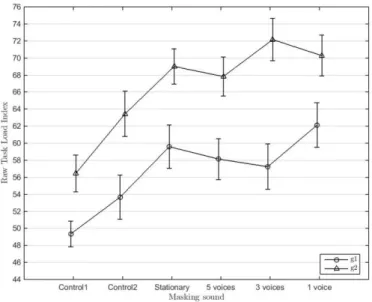
Effect of masking noise on cognitive performance and annoyance in open plan offices
Texte intégral
Figure

Documents relatifs
In figure 7 the curves for mechanically and chemically polished specimens intersect at a m a x = 1.8 kg ~ m - ~ , suggesting that the critical stress required to
An advisory committee, called the Bridge Design Review Committee (BDRC), was established after cities, local residents, business groups, and environmental advocacy
The question arose as to how to describe the experimental observations, in particular whether the energy transfer between the two localized states should be considered to be
Angstrom exponent (α) (upper left plot), α as a function of AOD (upper right plot), daily- averaged α as a function of temperature (T, lower left plot) and daily-averaged AOD as
Thanks to the separation between the composition laws and the behavioral framework, the latter, which is based on LTS, offers a unique LTS composition which is reused to
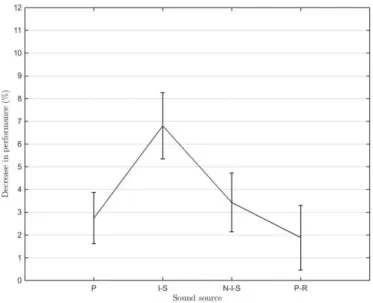
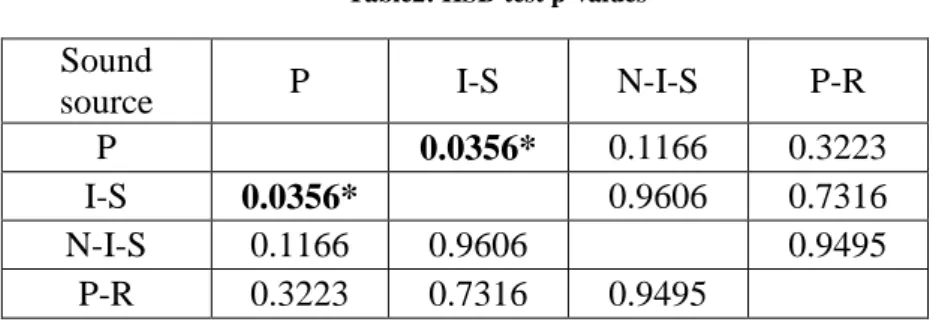
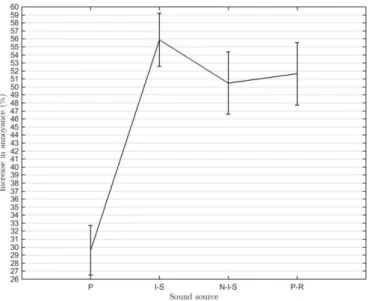
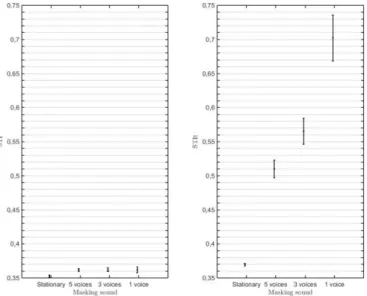
On the other hand verbal creativity is stimulated by moderate noise with ventilation (Figure 11), while speech intelligibility is more of a distraction than a
( ﺫﻴﻔﻨﺘ ﺭﺎﻁﺇ ﻲﻓ ﺔﻠﻴﺴﻭﻟﺍ ﻩﺫﻫ لﺎﻤﻌﺘﺴﺇ ﻯﺩﻤ ﻰﻠﻋ ﻑﻭﻗﻭﻟﺍ ﻱﺭﻭﺭﻀﻟﺍ ﻥﻤ ﻪﻨﺈﻓ ﻲﻟﺎﺘﻟﺎﺒﻭ ﻕﻭﺴﻟﺍ ﺩﺎﺼﺘﻗﺍ ﻯﻭﺤﻨ لﺎﻘﺘﻨﻹﺍ ﻭ ﺔﻴﺩﺎﺼﺘﻗﻹﺍ ﺕﺎﺤﻼﺼﻹﺍ. ﺔﺴﺍﺭﺩﻟﺍ ﺭﺎﻁﺍ ﺩﻴﺩﺤﺘ :
