Autonomous Navigation in Unknown Environments
Using Machine Learning
by
Charles Andrew Richter
Submitted to the Department of Aeronautics and Astronautics
in partial fulfillment of the requirements for the degree of
Doctor of Philosophy MASS
at the
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
June 2017
@
Massachusetts Institute of Technology 2017. All rights reserved.Author
KCHUM ETNSTITUTE 0 TEHNOLOGYJUL 112017
LIBRARIES
ARCHIVES
Signature redacted
. . . .
Department of Aeronautics and Astronautics
Certified by....
Signature redacted
May 25, 2017
Certified by.
Certified by.
Certified by.
Assoc
Accepted by .
Nicholas Roy
,Professor of Aeroautics and Astronautics
....
Signature redacted,...
Tnmni's Lo7ano-P0re7
Professor of Elgtrical Engin ering and Computer Science
...
Signature redacted...
Sertac Karaman
Associate Pffess
f
AeronXutics
and Astronautics
Signature redacted...
Ingmar Posner
iate Professor of EngineeringScie}pe, University of Oxford
...
Signature
redacted
.
...
6/
Youssef Marzouk
Autonomous Navigation in Unknown Environments Using
Machine Learning
by
Charles Andrew Richter
Submitted to the Department of Aeronautics and Astronautics on May 25, 2017, in partial fulfillment of the
requirements for the degree of Doctor of Philosophy
Abstract
In this thesis, we explore the problem of high-speed autonomous navigation for a dynamic mobile robot in unknown environments. Our objective is to navigate from start to goal in minimum time, given no prior knowledge of the map, nor any explicit knowledge of the environment distribution. Faced with this challenge, most practical receding-horizon navigation methods simply restrict their action choices to the known portions of the map, and ignore the effects that future observations will have on their map knowledge, sacrificing performance as a result. In this thesis, we overcome these limitations by efficiently extending the robot's reasoning into unknown parts of the environment through supervised learning. We predict key contributors to the navigation cost before the relevant portions of the environment have been observed, using training examples from similar planning scenarios of interest.
Our first contribution is to develop a model of collision probability to predict the outcomes of actions that extend beyond the perceptual horizon. We use this collision probability model as a data-driven replacement for conventional safety constraints in a receding-horizon planner, resulting in collision-free navigation at speeds up to twice as fast as conventional planners. We make these predictions using a Bayesian approach, leveraging training data for performance in familiar situations, and automatically reverting to safe prior behavior in novel situations for which our model is untrained. Our second contribution is to develop a model of future measurement utility, efficiently enabling information-gathering behaviors that can extend the robot's visibility far into unknown regions of the environment, thereby lengthening the perceptual horizon, resulting in faster navigation even under conventional safety constraints. Our third contribution is to adapt our collision prediction methods to operate on raw camera images, using deep neural networks. By making predictions directly from images, we take advantage of rich appearance-based information well beyond the range to which dense, accurate environment geometry can be reliably estimated. Pairing this neural network with novelty detection and a self-supervised labeling technique, we show that we can deploy our system initially with no training, and it will continually improve
Thesis Supervisor: Nicholas Roy
Title: Professor of Aeronautics and Astronautics Thesis Committee Member: Tomis Lozano-Phrez
Title: Professor of Electrical Engineering and Computer Science Thesis Committee Member: Sertac Karaman
Title: Associate Professor of Aeronautics and Astronautics Thesis Committee Member: Ingmar Posner
Acknowledgments
It has been an honor and a great privilege to be a student at MIT, in the Robust Robotics Group and the MIT robotics community, for the last six years. There are many people I would like to acknowledge for making MIT such a great experience. First and foremost, I would like to thank my advisor, Professor Nicholas Roy, for his insightful guidance at every stage of the research process, and for pointing me toward fascinating problems that would turn out to be productive lines of inquiry. I would also like to thank Nick for his constant and genuine support and sense of humor, which made the research process so much fun. I feel extremely lucky to have Nick as my advisor and to be a part of the Robust Robotics Group.
I would also like to thank my thesis committee for asking the challenging,
funda-mental questions that guided me to define and strengthen the research in this thesis. Professor Tomis Lozano-Perez encouraged me to clearly state the underlying prob-lem in its most general form in order to build practical methods on a solid theoretical foundation. Professor Sertac Karaman encouraged me to always start with the sim-plest instance of the problem containing the characteristics of interest. And Professor Ingmar Posner encouraged me to carefully examine the machine learning algorithms in this thesis to understand how and why they know what they know. These pieces of advice, along with all of our other great discussions, have clarified my understanding of my own work tremendously, and helped to define my approach to the research process in general. It has been a privilege to learn from such a great committee.
I would like to thank my labmates in the Robust Robotics Group and the MIT robotics community for being such an inspiring group of colleagues to work with. We have shared many great memories, flying autonomous drones and driving robots through the Stata Center late at night, and hashing out the deep questions of artificial intelligence and robotics every day. I would also like to thank all of my MIT friends, who made these years so special. I will always remember the great times we have had, and I look forward to many more. Finally, I would like to thank my family for supporting and encouraging my engineering pursuits, and everything else, all along.
Contents
1 Introduction 15
1.1 Safe Planning in Unknown Environments . . . . 17
1.2 Predicting Collisions . . . . 21
1.3 Predicting the Utility of Future Measurements . . . . 27
1.4 Learning Predictive Features from Raw Data . . . . 30
1.5 Contributions . . . . 32
1.6 Publications . . . . 33
2 Background 35 2.1 Safe Navigation for Dynamic Mobile Robots . . . . 35
2.1.1 Contingency Plans and Emergency-Stop Maneuvers . . . . 36
2.1.2 Probabilistic Notions of Safety . . . . 37
2.2 Navigating Unknown Environments . . . . 39
2.2.1 Exploration . . . . 40
2.2.2 Incremental Re-Planning in an Unfolding Map . . . . 41
2.2.3 POMDPs for Navigation in Unknown Environments . . . . 43
2.3 Learning to Control Highly Dynamic Robots . . . . 45
2.3.1 Learning Under Uncertainty of the System Dynamics . . . . . 46
2.3.2 Learning From Demonstrations . . . . 48
2.3.3 Safe Learning . . . . 49
2.4 Learning Visual Perception for Navigation . . . . 50
2.4.1 Near-to-Far Self-Supervised Learning . . . . 51
2.4.3 Mapping Images Directly to Actions . . . . 55
2.4.4 Quantifying Uncertainty in Learned Visual Models . . . . 57
3 Predicting Collisions from Features of a Geometric Map 65 3.1 POMDP Planning . . . . 66
3.1.1 Missing Prior Distribution Over Environments . . . . 70
3.1.2 Approximations to the POMDP . . . . 71
3.2 Predicting Future Collisions . . . . 74
3.2.1 Learning Problem . . . . 75
3.2.2 Advantage of the Bayesian Approach . . . . 77
3.2.3 Training Procedure . . . . 79
3.3 R esults . . . . 81
3.3.1 Simulation Results . . . . 82
3.3.2 Demonstrations on Autonomous RC Car . . . . 92
3.4 Chapter Summary . . . 101
4 Predicting the Utility of Future Measurements 105 4.1 Measurement Utility Modeling Approach . . . . 107
4.1.1 Training . . . 108
4.1.2 Prediction and Planning with the Learned Model . . . . 110
4.2 R esults . . . . 111
4.2.1 Learned M odels . . . . 111
4.2.2 Simulation Success Rates . . . . 112
4.2.3 Simulation Time-to-Goal as a Function of Visibility . . . . 114
4.2.4 Experimental Demonstration on Autonomous RC Car . . . . . 116
4.3 Chapter Summary . . . 118
5 Predicting Collisions from Learned Features of Raw Sensor Data 121 5.1 Visual Navigation Problem Formulation . . . 124
5.2 Learning to Predict Collisions . . . 127
5.2.2 Neural Network . . . . 131
5.2.3 Prior Estimate of Collision Probability . . . . 132
5.3 Novelty Detection . . . . 133
5.3.1 MNIST Examples . . . . 136
5.3.2 Robot Navigation Examples . . . . 137
5.4 R esults . . . . 138
5.4.1 Visualizing Neural Network Predictions . . . . 139
5.4.2 Neural Network Compared to Hand-Engineered Features . . . 141
5.4.3 Online Learning Simulation Results . . . . 142
5.4.4 Experimental Results using LIDAR . . . . 143
5.4.5 Experimental Results using Monocular VIO and RGBD . . . . 145
5.5 Generalization in Real Environments . . . . 146
5.5.1 Demonstrating Generalization . . . . 147
5.5.2 What Makes a Hallway Image Appear Novel? . . . . 151
5.5.3 Reconstruction Examples . . . . 152
5.6 Limitations and Future Directions for Novelty Detection Methods . . 154
5.7 Chapter Summary . . . . 156
6 Conclusion 159 6.1 Future Work: Predicting Collisions . . . . 160
6.2 Future Work: Predicting Measurement Utility . . . . 161
List of Figures
Baseline planner. . . . . Planning with collision prediction. . . . . Planning with measurement utility prediction.
Pre-computed action set. . . . . Collision labeling example. . . . . Example hallway and forest simulation maps. . . . .
Basic simulation results. . . . . Example simulation trajectories. . . . . Performance as a function of data volume. . . . .
Performance in simulated hallways as a function of sensor configuration.
1-1 1-2 1-3 3-1 3-2 3-3 3-4 3-5 3-6 3-7 3-8 3-9 3-10 3-11 3-12 3-13 3-14 3-15 3-16 3-17 4-1 Baseline planner. . . . . 4-2 Measurement utility training procedure. . . . .
. . . . 1 8 . . . . 22
. . . . 28
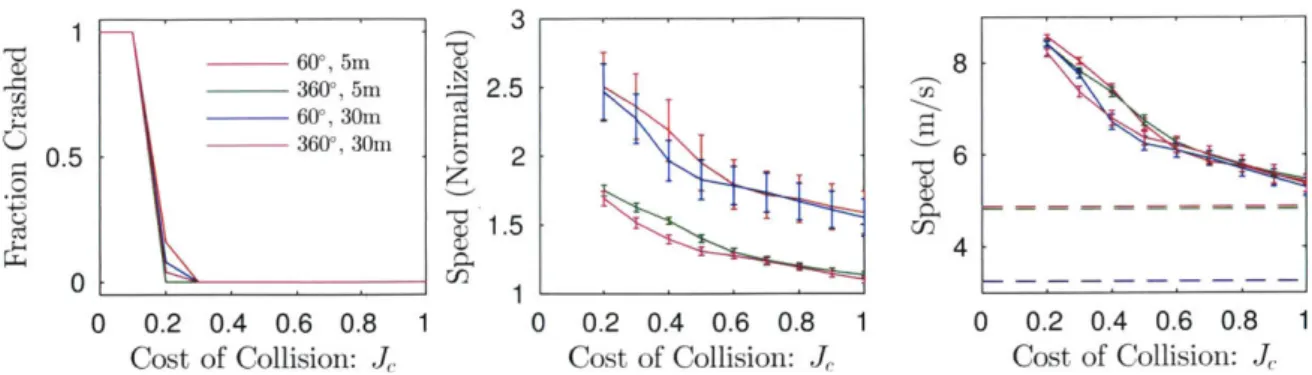
Effect of sensor field-of-view on the baseline planner in a hallway. . .
Performance in simulated forests as a function of sensor configuration. Effect of sensor range on the baseline planner in a forest. . . . . Simulated transition between familiar and unfamiliar environment types. Experimental autonomous RC car. . . . . Hallway-type experiment. . . . .
Experiment with restricted sensor range and field-of-view. . . . .
Experiment traversing multiple environment types. . . . . M aximum speed test. . . . . Example of wheel slip during an experiment. . . . .
68 80 82 83 84 86 87 88 89 90 91 92 93 96 98 99 100 106 109
4-3 Example learned models of measurement utility. . . . . 111
4-4 Baseline planner trapped having not observed key regions of the map. 113 4-5 Simulation results for measurement utility prediction. . . . . 114
4-6 Planning with measurement utility prediction. . . . . 115
4-7 Trajectories of planner while predicting measurement utility vs. baseline. 116 4-8 Experimental trials of measurement utility prediction. . . . . 117
5-1 Training examples for image-based collision prediction. . . . . 130
5-2 Autoencoder demonstration on MNIST and notMNIST datasets. . . . 137
5-3 Autoencoder demonstration on a hallway and a forest. . . . .. 138
5-4 Histogram of autoencoder loss on hallway training images. . . . . 138
5-5 Neural network collision prediction examples. . . . . 140
5-6 Neural network performance comparison to geometric features. . . . . 141
5-7 Simulation results of image-based collision prediction. . . . . 142
5-8 Environment used for image-based collision prediction experiments. 144 5-9 Experimental results of image-based collision prediction. . . . . 144
5-10 Novel environment used for image-based collision predictionexperiments. 144 5-11 Images taken from image-based collision prediction experiments. . . . 145
5-12 Histogram of autoencoder loss for experimental environments. .... 145
5-13 MIT hallways used for neural network generalization experiments. 147 5-14 Neural network generalization results. . . . . 148
5-15 Example of a novel segment of a hallway image. . . . . 151
5-16 Example of a familiar segment of a hallway image. . . . . 152
5-17 Autoencoder weights displayed as image filters. . . . . 153 5-18 Examples of inputs and reconstructions from non-hallway environments. 154
List of Tables
3.1 Collision prediction performance in a hallway environment. . . . . 94
3.2 Collision prediction performance with restricted sensing. . . . . 96
Chapter 1
Introduction
In this thesis, we study the problem of autonomous navigation through an environ-ment that is initially unknown, with the objective of reaching a goal in minimum
time. Without prior knowledge of the map, a fast moving robot must perceive its
surroundings through onboard sensors and make instantaneous decisions to react to obstacles as they come into view. This problem lies at the intersection of several
widely studied areas of robotics, including motion planning, perception, and
explo-ration. Yet, the particular task of navigating as fast as possible through an unknown environment gives rise to novel and challenging questions because it requires the robot
to select actions partially based on assumptions and predictions about the structure
of the environment that it has not yet perceived.
As we will observe in this thesis, standard motion planning techniques often limit
performance to be conservative when deployed in unknown environments, where every
unexplored region of the map may, in the worst case, pose a hazard. At the same time, standard planners do not typically take deliberate actions to observe key unknown regions, unless those planners have been designed for the task of mapping rather than high-speed goal-directed navigation. In order to guarantee that the robot will not collide with potential obstacles that may lie beyond the boundaries of the known
map, conventional planners limit the robot's speed such that it could come to a stop,
if need be, before entering the unknown. However, this constraint implies a
often it is indeed possible to plan actions that commit the robot to entering unknown regions, if guided by relevant experience suggesting that such actions will be safe. Furthermore, it is also possible, given some intuitive guidance, to plan in anticipation of advantageous future sensor views and project the knowledge horizon as far ahead as possible in order to enable faster navigation. As a result, there is a substantial gap between the limited navigation speeds achievable under standard constraints and assumptions, and what is truly possible for an optimal planner. In most cases, we do not even know where the limit of possibility lies, since it depends heavily on many factors like the physical properties of the environment, the physical limitations of the robot, and the types of knowledge and learning the robot can use.
Nevertheless, we have strong evidence that extremely agile high-speed naviga-tion, far exceeding today's state-of-the-art robots, is fundamentally possible. For instance, consider the goshawk, a bird of prey whose formidable hunting style fea-tures high-speed flight through dense woodland and nimble, aerobatic dives through tiny passages in the vegetation. Or, consider aerial drones racing at speeds up to
15 meters per second through cluttered buildings and obstacle courses, controlled by
expert human pilots using only a first-person onboard camera view. What is perhaps most fascinating about these examples is that animals and human pilots do not have the same types of high-precision sensing and computation as modern robotic systems and instead must make decisions based on a learned or intuitive understanding of the ways their actions and perceptual capabilities work in familiar types of environments. One of the goals of this thesis is to develop autonomous robotic planners and perception algorithms that help us to get closer to the levels of agility observed in nature and demonstrated by expert human pilots. We aim to develop a practical understanding of how fast it is possible to navigate with respect to a continually unfolding perceptual horizon, in which obstacles may appear from behind occlusion or come into range of the sensor. An intelligent planner must strike a careful balance between driving toward the goal as aggressively as possible and anticipating the risk of collision with yet-unseen obstacles and structures. This balance is a complex function of the vehicle's maneuverability at different speeds, the likelihood and placement of
obstacles that may appear, and the amount of time and distance that will be available to react as those obstacles come into view.
All of the problems we will study in this thesis take the form of minimum-time
navigation to a specified goal location. We will begin by demonstrating how con-ventional methods make overly conservative assumptions about the world, limiting performance in order to guarantee safety. Next, we will show how we can replace those assumptions with more accurate models of collision probability, learned from experience in the environment types of interest, thereby enabling faster navigation while remaining collision-free. Then, we will show that we can apply a similar learn-ing technique to predict measurement utility, guidlearn-ing robots to obtain advantageous sensor views that increase the range at which they can anticipate obstacles. Finally, we will show how we can learn feature representations for these learning problems directly from raw sensor data. We briefly outline these topics next.
1.1
Safe Planning in Unknown Environments
Faced with a partially unknown environment, a mobile robot must use its onboard sensors to perceive obstacles and incrementally update its internal map representation with each new piece of information. As the robot moves, observing more and more of the environment, it gradually expands the known regions of its map. However, if the map is incomplete, it is generally not possible to plan a detailed trajectory from the robot's location all the way to the goal, until the goal has come into view. Instead, a common planning strategy in unknown environments, and the technique we will use in this thesis, is the receding-horizon approach. In receding-horizon planning, the robot selects a partial trajectory extending to some short planning horizon given the current (partial) map knowledge, and begins to execute it while continuing to observe its surroundings and update its map. By continually re-planning, the robot can react to new information as it is observed and revise its trajectory.
However, avoiding collision in a receding-horizon setting can be difficult. The planner must not only ensure that its chosen actions are collision-free within the
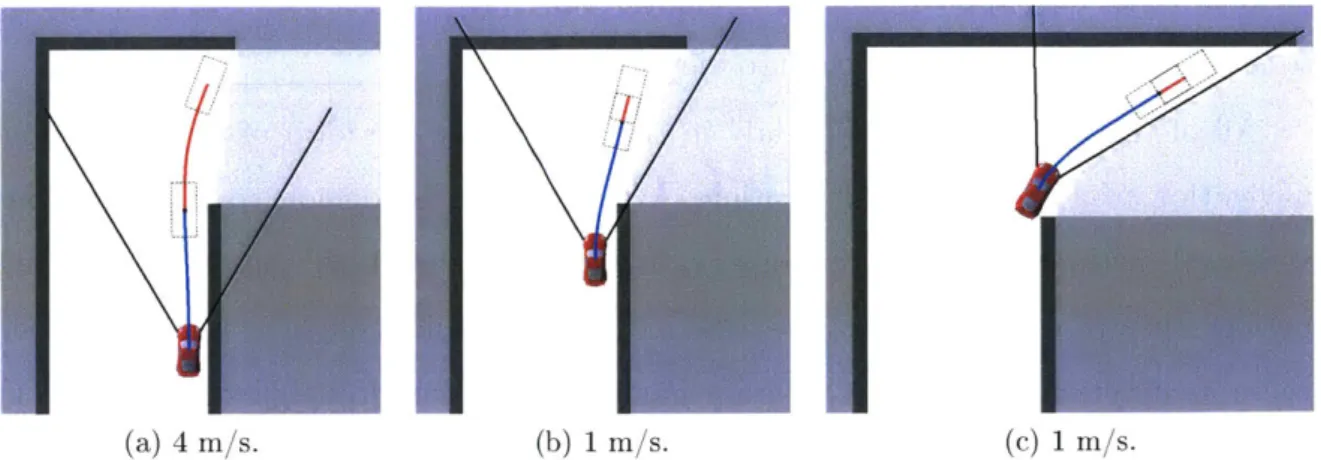
(a) 4 m/s. (b) 1 m/s. (C) 1 m/s.
Figure 1-1: A sequence of actions chosen for a robot approaching a blind corner while
guaranteeing safety with a 60' sensor field-of-view. Chosen trajectories are drawn
in blue, and feasible emergency-stop maneuvers are drawn in red. Black rectangles illustrate the outline of the robot, indicating the size of the required free space around each feasible action and emergency-stop action. The safety constraint requires the robot to slow from 4 m/s in (a) to 1 m/s in (b) to preserve the ability to stop within known free space. In (c), the planner must proceed slowly until it is able to complete its turn, pivoting its field-of-view (illustrated by the black cone), and observing more free space ahead. This is the guaranteed-safe "baseline" planner we will use for comparison in this thesis.
planning horizon, but must also ensure that there will exist collision-free options
beyond the end of the planned trajectory. More concretely, to guarantee safety,
a receding-horizon planner must plan trajectories that are known to be
collision-free for all time
136].
This constraint is often satisfied by ensuring the existenceof a collision-free emergency-stop maneuver or safe holding pattern that could be executed, if need be, after the current action has been completed [6, 72, 105, 1231. Additionally, if the map is only partially known, a planner constrained to guarantee safety must conservatively assume that every unknown map region may, in the worst case, contain an obstacle, and therefore must confine its trajectories and emergency-stop maneuvers to lie within observed free space. This observed free space may, in turn, be limited by sensor range and occlusion.
Figure 1-1 illustrates this scenario for a robot approaching a blind corner while
guaranteeing safety with respect to the perceived map. In these figures, the white regions represent observed free space, the black regions are observed obstacles, and
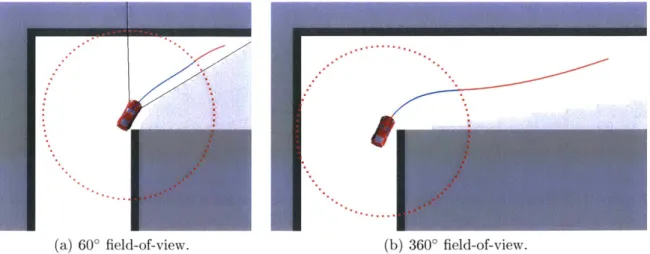
the gray regions are unknown. Light gray indicates the true hidden structure of the hallway around the blind corner, which has not yet been observed. The straight black lines indicate the robot's 60' sensor field-of-view, which approximately corresponds to a common RGBD camera, although the general principles described here also affect any form of geometric sensing, including 3600 scanning LIDAR.
In Figure 1-1(a), for example, the blue line represents the chosen trajectory from the robot's current state to a planning horizon of 2 m. The red line extending from the end of the blue trajectory is a feasible emergency-stop action that would bring the robot to a stop without collision, entirely within known free space. The black rectangles illustrate the bounding box of the robot at the beginning and end of each feasible emergency-stop action to show that it lies entirely within known free space.
This red emergency-stop action would be executed if, as the robot proceeds along its chosen trajectory, all subsequent re-planning attempts fail to find a feasible tra-jectory with its own subsequent emergency-stop action. Requiring the planner to guarantee a feasible emergency-stop action places an implicit limit on the robot's speed since higher speeds require greater stopping distances. Assuming constant de-celeration due to braking, the stopping distance grows quadratically with speed, which makes this constraint more and more restrictive as the robot moves faster. As the robot approaches the corner, it must slow from 4 m/s to 1 m/s to preserve its ability to complete a feasible emergency-stop maneuver before entering unknown space.
We refer to this guaranteed-safe planning approach as the "baseline" planner and use it for comparison in this thesis. While Figure 1-1 illustrates the baseline planner with a 60' field-of-view, we will explore a variety of sensor ranges and fields-of-view. When we perform a comparison, we will impose the same sensor limitations on the baseline planner as on our method. The baseline planner represents state-of-the-art planning in unknown environments without the benefit of any additional domain-specific information or hand-engineered behaviors. It is simply designed to drive toward the goal as fast as possible while observing a safety constraint that ensures that it can always stop before colliding with observed obstacles or entering unknown regions of the map. This baseline planner repeatedly selects actions according to the
following optimization problem:
a*(bt) =argmin{ Ja(at) + h(bt, at)} (1.1)
at EA
s.t. g(bt, at) = 0. (1.2)
Here, we select an action a* at time t, from a set A of pre-computed motion primitives, that minimizes the cost function in equation (1.1), subject to a safety constraint expressed in equation (1.2). This choice of action depends on the robot's belief, bt, which contains its knowledge of its own state as well as its (partial) knowledge of the map accumulated from sensor measurements obtained up to time t. We will discuss the belief bt in greater detail when we introduce the problem description in Chapter 3. The objective function, equation (1.1), is an estimate of the time required to reach the goal if the planner selects action at, given belief bt. However, since the environment between the robot's position and the goal is largely unknown, we can only estimate most of the remaining time. Therefore, we split the cost into two terms that facilitate this approximation. The first term in the cost function, Ja(at), represents the time duration of action at. The second term, h(bt, at), represents a heuristic estimate of the remaining time required to reach the goal after at has been completed. This heuristic can be computed, for example, by assuming that the robot will maintain its current speed along the shortest piecewise straight-line path to the goal, respecting the observed obstacles but assuming that all unknown parts of the map are free and traversable. Roughly speaking, minimizing Ja(at) encourages the robot to go fast, while minimizing h(bt, at) encourages the robot to drive toward the goal.
This heuristic is simple and efficient, but is a poor approximation in a few key respects that we will explore in this thesis. It fails to account for the future evolu-tion of the robot's dynamics or map knowledge, although doing so would amount to solving an intractable continuous-valued partially observable Markov decision process (POMDP), which is a formidable challenge. Since this heuristic attempts to minimize time (and therefore distance) to the goal, it has a tendency to guide the robot toward the inside of turns, as seen in Figure 1-1, which is disadvantageous both for vehicle
maneuverability and for sensor visibility. The techniques we will outline below can be interpreted as ways to improve or augment this heuristic to make it more closely approximate the true, optimal cost-to-goal.
One of the key components of the optimization problem in equations (1.1) and (1.2), and the element that restrains the robot from recklessly traveling at its maximum speed at all times, is the constraint g(bt, at). We define g(bt, at) = 0 if there exists a feasible emergency-stop maneuver that can bring the robot to rest within the known free space contained in bt after completing action at, and g(bt, at) = 1 otherwise. This constraint imposes the speed limit observed in Figure 1-1.
While the constraint g(bt, at) = 0 requires that there must exist a collision-free emergency-stop trajectory beyond the end of action at, we also perform conventional collision checking along the length of at itself, distinct from g(bt, at). We assume that the robot will always have some knowledge of obstacles in its immediate vicinity, and should not consider actions known to intersect them. Since conventional collision checking is enforced throughout this thesis, we omit it from equation (1.2), and all subsequent optimization problem statements. However, we will state the constraint g(bt, at) explicitly in order to clarify when it is being enforced and when it is not.
1.2
Predicting Collisions
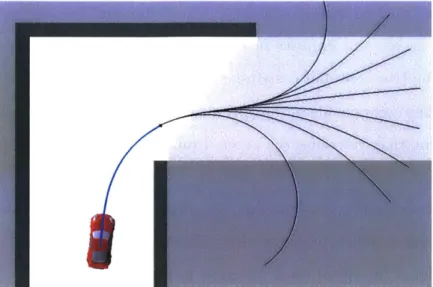
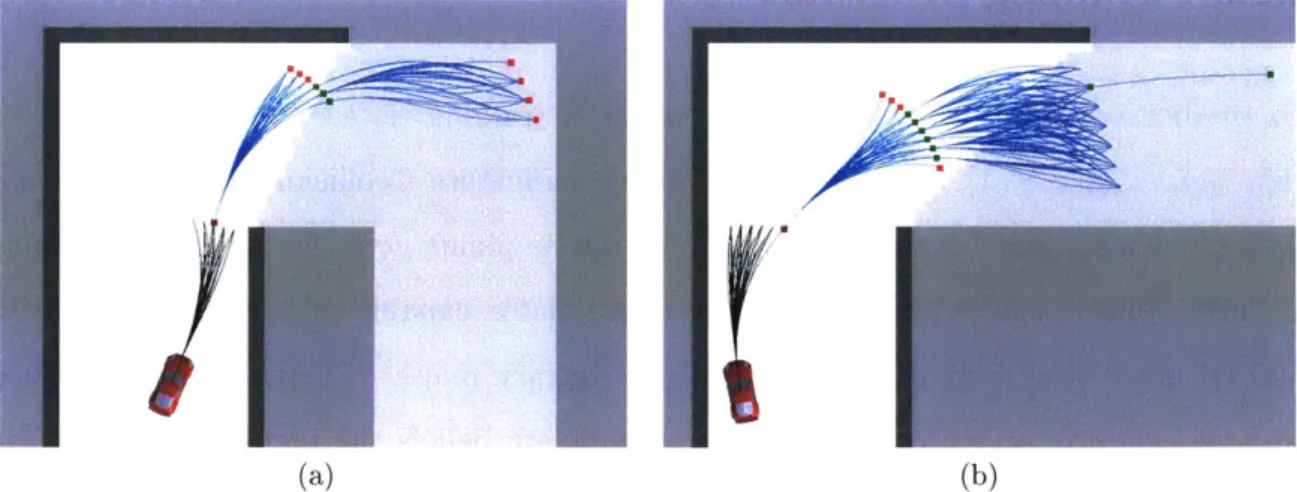
Conventional planning constraints, derived from worst-case assumptions that any unknown region of the environment may contain an obstacle, imply that driving into unknown regions is dangerous. However, one of our central claims is that this assumption may be overly conservative. In many cases, the robot can drive at high speeds into the unknown if it is equipped with an accurate model of the risk associated with such actions, based on previous experience in similar situations. For instance, many buildings have straight hallways with 90' turns and intersections. If a robot observes a hallway with a turn, and has trained in similar environments, it should be able to reason with high certainty that the hallway will continue, and that there will be free space around the turn. Figure 1-2 shows our proposed solution planning a
high-Figure 1-2: Planning a trajectory (blue) that rounds a blind corner at 6 m/s using a learned model of collision probability. The true, hidden map is illustrated in light gray. The set of potential emergency-stop maneuvers (black) all enter unknown space, so this trajectory would be disallowed by a safety constraint, however several of them are indeed collision-free with respect to the true map, indicating that the planned action is correctly predicted to be feasible. This is the planner we develop in Chapter 3.
speed turn around a blind corner at 6 m/s, much faster than the safety-constrained baseline planner would allow. The set of emergency-stop trajectories (illustrated in black) from the chosen action (blue) all enter unknown space, indicating that the chosen action is unavoidably committing the robot to entering the unknown. Yet, this type of maneuver is often empirically collision-free for hallway environments. Our solution correctly infers that this maneuver is not excessively risky. Indeed, Figure 1-2 shows that some of the emergency-stop trajectories lie entirely within the free space around the turn (light gray) and are collision-free, although this free space has not yet been observed. Many other common environment structures make up the natural and man-made environments we frequently navigate, and these structures can be exploited by planners that are familiar with them.
In general, there are several types of assumptions that a robot could make about the unknown parts of the environment, given the set of partial observations already obtained. For instance, the robot could optimistically assume that all unobserved regions are free and traversable, implying the existence of many feasible routes to the goal. This assumption could lead to very reckless planning, since it would imply
that the robot could drive at full speed without risking collision. Or, like the base-line planner discussed in Section 1.1, the robot could conservatively assume that all unobserved regions may be occupied, implying that there are no feasible trajectories beyond the free space that has already been observed. Bachrach [8] provides a com-pelling illustration of these two types of assumptions and their effects on planning.
However, in almost all realistic environments, the reality lies somewhere in between these two extremes. Therefore, in order to plan trajectories that are likely to avoid obstacles and lead to the goal faster than the conservative assumptions of the baseline planner would allow, the robot must perform some form of inference over the unknown regions of the environment. The objective of this inference problem is ultimately to determine which action choices will safely lead to the goal, and which action choices are infeasible with respect to yet-unseen obstacles. Performing this inference accurately will enable the planner to exploit the difference between the conservative assumptions of the baseline planner and the true characteristics of the environment.
One way to estimate the feasibility of actions through unknown space might be to directly predict the occupancy of the unknown parts of the environment, using sensor measurements combined with an accurate prior distribution over maps. Using an accurate prior, a measurement of some portion of the environment would allow the robot to infer something about the adjacent regions. This inference problem would be high-dimensional and computationally expensive, but in principle, it could be done. Indeed, POMDP solvers perform this type of inference in order to compute optimal policies by effectively searching forward through every possible action-observation sequence to enumerate the probabilities of all possible future maps the robot might encounter. However, it is only possible to perform this kind of inference for very small or coarsely discretized problems, rendering these methods inapplicable for realistic dynamical systems with continuous-valued states and observations.
Perhaps a more fundamental difficulty, however, is that we do not know the dis-tribution over real-world environments in which we would like our robots to operate. Accurately modeling real-world environment distributions would be extremely diffi-cult due to the high dimensionality of building-sized occupancy grid maps, the strong
assumption of independence between map cells, and the richness of man-made and natural spaces that resist compact parameterization. Without significant modeling effort, or restriction of the problem domain to specific types of environments, the best prior knowledge we can reasonably provide is to say that every map is equally likely.
Of course, this prior is very inaccurate and completely unhelpful for planning, and
prevents the agent from exploiting any intuitive knowledge of "typical" environments. To compensate for this missing knowledge of the environment distribution, we reformulate the problem from high-dimensional map inference to direct prediction of local action feasibility-in other words, collision probability-using supervised learn-ing. Our goal is to implicitly capture the relevant traits of our training environments needed for collision prediction through training examples, rather than modeling the map distribution explicitly. This approach leads to a much lower-dimensional model that is vastly easier to learn and, unlike high-dimensional inference over maps, is effi-cient enough to run online. Using this learned model of collision probability, we plan in a receding-horizon fashion according to the following control law:
a*(bt) = argmin{ Ja(at) + h(bt, at) + Jc - fc(bt, at)}. (1.3) at EA
This control law is similar to the optimization problem for the baseline planner, spec-ified in equations (1.1) and (1.2), but differs in one key respect. In this control law, we replace the safety constraint, g(bt, at) = 0, with an expected collision penalty,
Jc -fc(bt, at), where Jc is a cost applied to collision, and fc(bt, at) is a model of colli-sion probability. This modification changes planning from a problem of constrained optimization to one of minimizing cost in expectation over the unknown environ-ment. In Chapter 3, we will derive this objective function as an approximation of a full POMDP problem statement and describe how to learn this model of collision probability from training data. We will show that our method results in collision-free navigation in some cases more than twice as fast as the baseline planner in a variety of simulation and real-world tests.
uncon-strained system can travel faster, which would be trivially true. The hard question is to reason about how much faster the planner should choose to go given its current surroundings and the state-dependent limitations on its maneuvering capabilities. For instance, the turning radius for realistic ground vehicle models increases with speed due to tire friction limitations. Therefore, the vehicle in Figure 1-2 may be able to negotiate its turn at 6 m/s, but it would be risky at 8 m/s, and it would certainly crash if it attempted the turn at 10 m/s. Yet, in a long straightaway, 15 m/s would be perfectly safe. These are complex relationships that our models must capture.
There are a number of useful points of view from which to interpret our overall approach of collision prediction. First, we are replacing a safety constraint derived from worst-case assumptions with a data-driven "soft constraint" that more accurately represents the true properties of our training environments. Second, we are using a learned function to extend the effective planning horizon beyond the extent of the perceptual horizon. By this, we mean that our planner uses learning to augment its partial map knowledge to make reasonable judgments about hazards that may lie beyond what can be directly perceived, either due to sensor range or occlusion. For example, our planner can judge an appropriate speed at which to approach and round a corner before the occluded space around the corner has been observed, because it has been trained on datasets containing many similar blind corners. This capability is perhaps more fundamental than reacting to observed obstacles because no increase in planning horizon or sensor range can enable the baseline planner to reason about occluded regions. Third, our collision probability model serves an analogous role to an evaluation function in games like chess, backgammon or go, in that it encapsulates the results of many training examples gathered offline that can be used to approximate the value of a game state beyond some finite sequence of moves, which would be difficult or impossible to compute online.
Another way to interpret our approach is through the viewpoint of reinforcement learning (RL), which has provided many methods of learning to act optimally in do-mains with various forms of uncertainty. Since we learn a model of some aspect of robot-environment interaction, and then plan in a conventional manner using that
model, our approach could be considered a special case of model-based reinforcement learning. However, since we are only learning a single specific type of state transi-tion from normal operatransi-tion into a collision state, rather than a full model of state transition probabilities, we do not generally refer to our method as model-based RL. Furthermore, since our learning problem takes the form of a supervised probabilistic classification problem, it is one of the easiest forms of learning problems in terms of reward/label complexity and has none of the very difficult RL challenges associated with sequential or delayed rewards
163].
In contrast with model-based RL, model-free approaches are attractive for their simplicity and because they assume very little knowledge of the structure of the sys-tem, but do not have the advantage of a model class to determine which data are useful for learning and are usually less data efficient [31]. Furthermore, for on-policy RL algorithms, the distribution of training data and resulting rewards are are gener-ated by a complex and changing function of the policy as it is learned and refined. Without some assumed structure in the problem, the policy learned in a model-free context is not as easily transferred across tasks and domains, and is not as transpar-ently understandable as the models we learn in this work. In Chapter 3, we will show how our method enables us to collect labeled training data in a simple, offline, policy-independent batch process, requiring only a training map and the robot's dynamics. While our method improves performance in familiar types of environments that resemble the training data, real-world scenarios are highly varied, unpredictable, and outside the control of the robot. Therefore, it is likely that we will query the learned function fc(bt, at) to make a prediction in a scenario unlike any it has encountered during training. However, when the learned model is being used for collision avoid-ance, an incorrect prediction could be catastrophic. We need some way to recognize when the robot is in a situation for which it is untrained, and protect against making an uninformed or dangerous prediction. Therefore, rather than asking the learned function to extrapolate from its training data in novel scenarios, we instead take a Bayesian approach. We introduce a prior over collision probability that mimics the safety constraint g(bt, at), so that fc(bt, at) can blend the influences of its training data
and prior in proportion to how much relevant training data are available for a given prediction. In familiar scenarios, the prior will have very little influence, whereas in completely novel scenarios, the robot will still be able to navigate in a slow but safe manner using the prior alone, without any relevant data. Unlike many robot learning methods, this approach enables us to safely deploy our system in any environment, without regard for whether it has been appropriately trained. In Chapter 3, we will demonstrate this method in simulation and real-world trials showing automatic safe transition between familiar and unfamiliar environment types.
1.3
Predicting the Utility of Future Measurements
We have just outlined a method of predicting collisions on the basis of the robot's state, choice of action and current knowledge of the map. This method exchanges a guarantee of safety in favor of a more accurate data-driven risk model that enables faster navigation while remaining empirically collision-free. However, in some cases, no amount of risk is acceptable and we wish to guarantee safety with respect to unknown regions in the environment. Are there other ways we can use learning to improve planning without sacrificing the safety guarantee?
We observe that the baseline planner in Figure 1-1(b) is highly constrained by the fact that it has not observed the free space around the blind corner. However, map knowledge at any point in time depends on the sequence of measurements that have been obtained by the robot, which can be strongly influenced by the choice of actions that move the sensor. We now ask the question: Can we train a planner to take actions that yield improved views into the unknown regions of the environment?
If so, how much can such a method improve navigation performance?
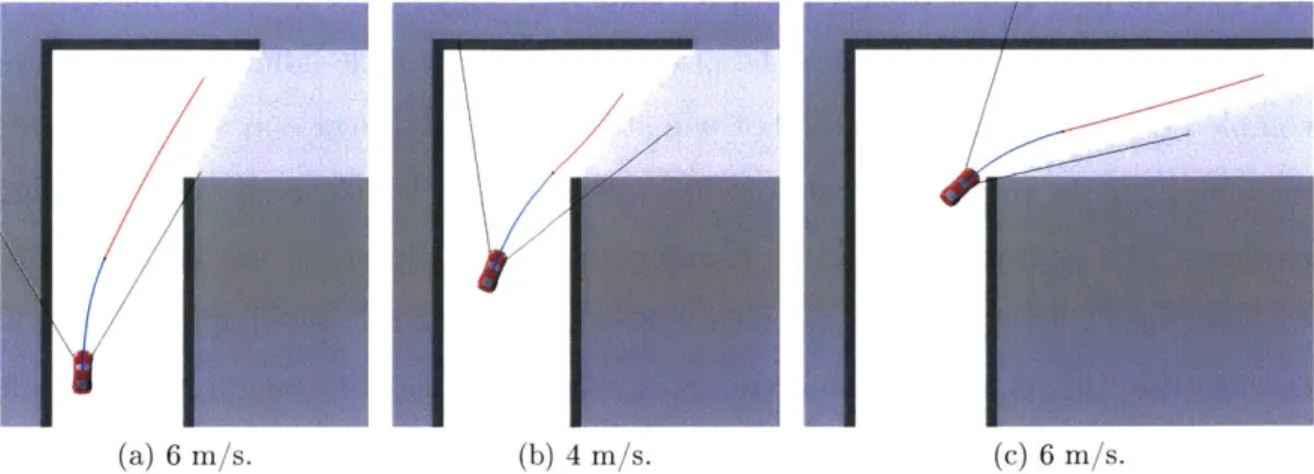
Figure 1-3 demonstrates a sequence of actions for a safety-constrained robot round-ing a blind corner, just as in Figure 1-1. However, the difference is that in this case, the robot has been guided to take a slightly longer route, approaching from the out-side of the turn. The consequence is that along this route, it is able to observe some of the free space around the corner much earlier, and therefore has a considerably
U'-(a) 6 i/s. (b) 4 m/s. (c)6 r/s.
Figure 1-3: An example planning sequence using our method of learning measurement utility, which guides the robot wide around corners to project sensor visibility into occluded space. The sensor in this figure is restricted to a 60' field-of-view, illustrated with black lines. This is the planner we develop in Chapter 4.
longer available stopping distance by the time it reaches the turn. By anticipating the utility of a few sensor measurements, the robot is able to round the corner at a rapid 4 m/s, compared to 1 m/s with the baseline planner.
We might consider applying existing next-best-view or information-theoretic tech-niques to guide the robot to obtain advantageous views of unknown space. However, these methods are typically designed to discover as much map knowledge as possible, and do not necessarily consider the implications that certain specific pieces of map knowledge may have on future planning options because they do not reason directly in terms of cost-to-goal. Therefore, using next-best-view or information-theoretic guidance, it is not known how helpful particular measurements will actually be for the task of reaching a goal in minimum time.
It is possible to manually assign some value to information, for the purpose of combining information-theoretic quantities with physical quantities like cost-to-goal into a single cost function [80, 110]. The problem with this approach is that, for navigation, certain measurements are much more valuable than others, even if they all reveal the same amount of new map knowledge. For high-speed navigation, the most valuable measurements are the ones that reveal a corridor of free space in the direction the robot would like to travel.
To add to this difficulty, as we have noted in Section 1.2, we assume that we have no explicit knowledge of the distribution over environments, and therefore we have no direct means of estimating the likelihood of potential future measurements. We must instead learn to predict the usefulness of measurements from experience, using only the robot's current map knowledge combined with the potential placements of the sensor within that current partial map. For instance, an action that aims the sensor toward a map frontier in the direction of the goal is probably a valuable information-gathering action, which could enable the robot to continue moving fast and therefore reduce its cost-to-goal. On the other hand, an action that occludes the map frontier from view would likely be disadvantageous, requiring the robot to slow down as it approaches the frontier.
Following this intuition, we propose a learned model that approximates the utility of the robot's next sensor observation directly in terms of cost-to-goal. Since our method learns from training examples, it does not require access to an explicit dis-tribution over environments or a measurement likelihood function. Our method is in some ways analogous to next-best-view planning, but the learned quantity reflects the change in expected cost-to-goal that will result from the measurements taken along a chosen action, rather than an information-based score. Therefore, we can incorporate the learned quantity directly into our receding-horizon control law:
a*(bt) =argmin{ Ja(bt, at) + h(bt, at) + fh(bt,at) (1.4)
atE A
s.t. g(bt, at) = 0. (1.5)
This control law differs from the baseline optimization problem in equations (1.1) and (1.2) only in that we have added a learned measurement utility term, fh(bt, at), that augments or refines the heuristic estimate, h(bt, at).
As we will show in Chapter 4, accounting for the next sensor observation has several important effects. First, it encourages the robot to perform the intuitive information-gathering maneuver of swinging wide around corners while maintaining visibility of the map frontier. Second, we will show that by predicting future
mea-surement utility, our robot navigates up to 40% faster than it does under the myopic guidance of the baseline planner. Finally, we will show that in some relatively benign cases, the baseline planner becomes trapped and is unable to make progress to the goal because it fails to foresee the need to observe key regions of the environment. Our solution largely overcomes this problem due to its information-gathering behavior.
1.4
Learning Predictive Features from Raw Data
We have now introduced two learned functions, fc(bt, at) and fh(bt, at), that take a belief-action pair as input. However, we have not described how these belief-action pairs are represented for the purposes of learning and inference. In the methods described in Sections 1.2 and 1.3, we condense belief-action pairs into a small set of predictive features that were manually designed for their respective prediction problems. In other words fc(bt, at) and fh(bt, at) are shorthand for the more explicit notation, fc(0c (bt, at)) and fA(Oh(bt, at)), where
#
0(bt, at) and Oh#(bt, at) compute low-dimensional sets of real-valued features.Our feature functions represent predictive quantities that we selected, and are by no means the only features that could be used. For collision prediction, 0c(bt, at) computes the following features: (1) The minimum distance to the nearest known obstacle along action at; (2) the mean range to obstacles or frontiers in the 600 cone emanating forward from the robot's pose, averaged over several points along action at; (3) the length of the straight free path ahead of the robot, averaged over several points along action at; and (4) the speed of the robot at the end of action at. For measurement utility prediction,
#h
(bt, at) extracts: (1) The fraction of map frontier locations that will be within the field of view of the sensor along action at; and (2) the average distance from the action to the frontier. While reasonably effective for their respective purposes, these feature functions are difficult to design and require specific intuition about the problems.Hand-engineered features may be feasible for simple 2D geometry, but what if we wish to make predictions directly from a camera image? It would be very challenging
to manually design a small set of visual features that could reliably predict collisions. Instead, in Chapter 5, we will describe how to train a deep neural network to predict collisions using images and actions as input. One of the primary advantages of using a deep neural network is that it adapts its internal feature representation in response to its training data, which enables it to work well on high-dimensional but highly structured data such as images. By using images, this method helps to alleviate the need for large and expensive sensors such as LIDAR for collision avoidance, and significantly extends the effective perceptual range beyond the dense depth estimates that can be computed from visual SLAM or RGBD point clouds.
However, like all learning approaches, neural networks may make inaccurate pre-dictions when queried with inputs that differ significantly from their training data. And, unlike the Bayesian method outlined in Section 1.2, neural networks do not naturally have a means of accurately determining their own confidence, or assessing how well they have been trained to make a certain prediction. Therefore, in Chap-ter 5, we will describe how we can use a separate autoencoder neural network to protect against erroneous predictions in novel situations. If our autoencoder detects an input for which the collision predictor is untrained, our planner will switch to a prior estimate of collision probability that is conservative but safe. This approach is analogous to the Bayesian approach in Section 1.2, but because it utilizes deep neural networks, it is able to operate on raw sensor data without the computationally demanding intermediate step of inferring the environment geometry from images.
As we will show in Chapter 5, we can deploy our deep learning system in an arbitrary environment, initially with no data. At first, all images observed by the autoencoder-based novelty detector will appear novel, so the planner will navigate purely based on its conservative prior. However, it will record all images, label them using a self-supervised technique, and periodically re-train itself, becoming more and more familiar with the types of environments it has observed. Our method of novelty detection extends the early work of Pomerleau
[94],
who used autoencoders to indicate when a vision-based controller was untrained for a particular scenario. We build upon these techniques by enabling the robot to continually improve without additionalmanual training or hand-engineered training simulators for each type of environment. Once our system has obtained a sufficient amount of data-roughly 10,000 images collected over several minutes of driving-most images with similar appearance to the training environments will appear to be familiar, and the collision prediction network will be able to make reliable predictions. At this point, the planner will be able to drive almost entirely based on the learned model, approximately 50% faster than what is possible under the safety constraint or conservative prior.
1.5
Contributions
We have now described the high-level problem setting for this thesis and outlined the limitations of standard approaches such as the baseline planner. In the subsequent chapters, we will develop three different ways that we can modify the baseline planner to improve navigation speed. The unifying paradigm of this thesis is that in unknown environments, there is not enough information observable through the robot's sensors to navigate as fast as is physically possible. Instead, we must augment or replace components of the baseline planner using supervised learning to more accurately capture the true characteristics of the environments in which we hope to operate. These learned models provide the planner with additional information, trained on data from similar types of environments, that can help to close the gap between the performance of the baseline planner and the performance that is truly possible for our robotic systems. Toward this goal, this thesis makes the following contributions:
" A problem statement of minimum-time navigation in unknown environments as
a partially observable Markov decision process (POMDP), and approximations that allow it to be converted to a receding-horizon control law (Chapter 3).
" A method of training a model to estimate collision probability efficiently in
simulation, using either synthetic or real maps (Chapter 3).
* An application of Bayesian inference to combine training data for collision pre-diction with a safe but conservative prior that enables navigation in any type
of environment, automatically transitioning between the high performance of the learned model in familiar environment types and the safe prior in novel or unfamiliar environment types (Chapter 3).
" A method of learning to predict future measurement utility that can encourage
information-gathering actions leading to faster navigation by effectively extend-ing the perceptual horizon (Chapter 4).
* A neural network formulation allowing a robot to predict collisions directly from raw sensor data such as camera images (Chapter 5).
" A novelty-detection approach, coupled with an offline training method, which
enables a robot to navigate slowly but safely in unfamiliar environments, col-lecting data and periodically re-training to automatically improve as it becomes familiar with each new environment type (Chapter 5).
1.6
Publications
The work presented in Chapter 3 was originally presented in Richter et al. 1101]. The work presented in Chapter 4 was originally presented in Richter and Roy [98]. Finally, the work presented in Chapter 5 will appear in Richter and Roy [991.
Chapter 2
Background
Navigation is one of the most studied problems in robotics, serving as a test domain for motion planning, control, perception, mapping, and learning techniques. Navigation is a multi-faceted challenge, which means that algorithms for planning and perception are not always developed in isolation and simply combined. Rather, algorithms are often developed jointly for the problem domain of interest, leading to a wide variety of combinations of techniques with advantages and disadvantages that depend on the
particular demands and assumptions of a given problem.
In this chapter, we will review the areas of robot navigation literature that are most relevant to this thesis and point out the differences and shortcomings that help to motivate this work. In particular, we will focus on methods of enforcing safety, reaching a destination when the environment is unknown, and machine learning for control and perception. While these are all very broad topics, we will emphasize their importance for highly dynamic robotic vehicles where relevant.
2.1
Safe Navigation for Dynamic Mobile Robots
The aim in most robot navigation problems is to guide a robot between start and goal locations without colliding with obstacles in the environment, perhaps minimiz-ing some objective such as time. This task requires the robot to have some means of representing the environment and planning paths through free space that do not
intersect obstacles. Simmons [107], Fox et al. [35], and Brock and Khatib [241 de-veloped some early examples of collision avoidance for mobile robots with non-trivial and actuator-limited dynamics by planning in the space of curvatures and velocities, not merely positions. Although we focus on static environments in this thesis, Fior-ini and Shiller [341 developed a similar method for avoiding collision with moving obstacles by projecting the future motion of mobile obstacles into state space. One of the essential characteristics of planning in the space of velocities and curvatures with finite actuator limits is that a robot must begin slowing down or initiating a turn well in advance of an obstacle in order to have the necessary time and space to avoid collision. To do so requires foresight that is not necessary for quasi-static kinematic planning for robots that can stop or turn nearly instantaneously.
Unifying these notions of safety, Fraichard and Asama [37] introduced the concept of an "Inevitable Collision State" (ICS), which articulates the conditions under which a dynamic robot will be unable to avoid collision with the environment. To guarantee that it can avoid collision, a planner must limit its action choices to those that do not place the robot in an ICS. In Chapters 3 and 5, we will utilize the ICS notion extensively in computing labels for supervised learning problems. As we shall discuss, collision prediction can be framed as a probabilistic classification problem to decide which actions, when taken in a given scenario, would place the robot in an inevitable collision state with (yet unseen) obstacles. One of the primary benefits of predicting future inevitable collision states is that it gives the robot information about hazards that may lie beyond the explicit planning or sensing horizon, or in occluded regions of the environment, allowing the planner extended time and space to react.
2.1.1
Contingency Plans and Emergency-Stop Maneuvers
Unlike the work presented in this thesis, planners in general cannot anticipate future collisions that might occur beyond their perceptual horizon, either beyond the sensor range or into occluded regions of the environment. Therefore, they are forced to make some assumptions about what might happen if they drive into unknown regions of the environment. If the environment is static but unknown and only partially visible,it is common to plan trajectories that make progress toward the goal, but never enter (or dynamically commit the robot to entering) unknown parts of the environment before they have been observed [16, 123]. This method ensures the existence of a safe contingency plan that could bring the robot to a stop within the known free space of the environment if need be, in the event that future re-planning attempts fail to find a collision-free trajectory. We have expressed this constraint in equation (1.2).
For dynamic vehicles with significant maneuvering constraints, such as helicopters, it may be useful to compute an emergency-maneuver library that can be used during planning
[7],
and for vehicles that cannot stop, such as fixed-wing aircraft, it is also possible to use circling loiter maneuvers as contingency plans [105]. The Closed-Loop RRT planner for the MIT DARPA Urban Challenge entry used a similar safety condition, ensuring that the vehicle could always stop in known free space by setting the speed of every leaf node in the trajectory tree to zero [72].If the evolution of a dynamic environment can only be predicted to some finite
time horizon, or if computational constraints prohibit planning a complete path to the goal, then a planner may enforce what is known as T-safety, where a (partial) plan of duration T is guaranteed to be collision-free with respect to the possible future motions of dynamic obstacles [391. The assumption is that T should be sufficiently long for planner to generate another safe trajectory to follow the current one.
These methods all share the common assumption that planned trajectories must be verifiably collision-free, and so the planner is restricted to plan actions that will keep the robot within the regions of the environment that are known to be unoccupied at the time of planning. However, there are many cases where some uncertainty in the environment or the future evolution of the system prohibits this strict guarantee, and the planner must accept some risk of failure. We will discuss these cases next.
2.1.2
Probabilistic Notions of Safety
In the preceding discussion, we considered safety with respect to the particular en-vironment in which the robot is navigating. However, if knowledge is presented in the form of a distribution over environments, then it is possible to make statements