FILTRAGE DE CONTENUS NUM ´ERIQUES CONNUS `A HAUTE VITESSE OPTIMIS´E SUR PLATEFORME GPU
JONAS LEREBOURS
D´EPARTEMENT DE G´ENIE ´ELECTRIQUE ´
ECOLE POLYTECHNIQUE DE MONTR´EAL
M´EMOIRE PR´ESENT´E EN VUE DE L’OBTENTION DU DIPL ˆOME DE MAˆITRISE `ES SCIENCES APPLIQU´EES
(G ´ENIE ´ELECTRIQUE) D´ECEMBRE 2012
c
´
ECOLE POLYTECHNIQUE DE MONTR´EAL
Ce m´emoire intitul´e:
FILTRAGE DE CONTENUS NUM ´ERIQUES CONNUS `A HAUTE VITESSE OPTIMIS´E SUR PLATEFORME GPU
pr´esent´e par: LEREBOURS Jonas
en vue de l’obtention du diplˆome de: Maˆıtrise `es Sciences Appliqu´ees a ´et´e dˆument accept´e par le jury d’examen constitu´e de:
M. BRAULT Jean-Jules, Ph.D., pr´esident
M. DAVID Jean Pierre, Ph.D., membre et directeur de recherche M. SAVARIA Yvon, Ph.D., membre
« Rendez vous compte ! sur Internet, n’importe qui peut dire n’importe quoi ! »
Un d´eput´e fran¸cais `a l’assembl´ee nationale durant les d´ebats sur HADOPI.
REMERCIEMENTS
J’aimerais remercier sinc`erement le professeur Jean Pierre David, mon directeur de re-cherche, pour son suivi et ses conseils. Il a toujours su r´epondre `a mes interrogations en pointant de nouveaux aspects, en proposant une solution innovante, m’incitant `a chercher plus loin, avec toujours perspicacit´e et rigueur. Sa disponibilit´e m’a donc permis de m’am´ e-liorer sans cesse, et la confiance qu’il m’a accord´ee tout au long de ma maˆıtrise s’est av´er´ee un pr´ecieux atout, duquel j’esp`ere avoir pu profiter `a la juste mesure.
Je souhaite ´egalement remercier le CRSNG, ainsi que NetClean et le Minist`ere des Fi-nances et de l’´Economie du Qu´ebec pour les financements qui ont ´et´e attribu´es au projet et desquels j’ai pu b´en´eficier. Ces financements ont permis de mener `a bien les exp´ erimen-tations, en travaillant sur du mat´eriel de pointe, pour obtenir des r´esultats originaux et de premier plan.
Mes remerciements s’adressent aussi aux autres ´etudiants sous la supervision du pro-fesseur David et avec qui j’ai eu la chance de travailler : Tarek Ould Bachir, Marc-Andr´e Daigneault, Adrien Larbanet, Mathieu Allard et Patrick Grogan. Mˆeme si nos projets ´etaient pour certains compl`etement diff´erents, ils ont toujours r´eussi `a m’aider `a prendre du recul et `a d´ebloquer des situations qui me paraissaient sans issue. Toute cette ´equipe a fait de notre laboratoire un espace de travail convivial. J’ai eu grand plaisir `a discuter avec eux, `a les connaˆıtre, et j’esp`ere ne pas les perdre de vue.
Je remercie encore ´Elise Mellon, Maeva Jaffar et Vincent Lecomte, qui ont toujours ´et´e mes plus assidus supporters, pour leur soutien continu. Ils m’ont donn´e beaucoup de leur temps et ont consid´erablement apport´e `a ce m´emoire par leurs commentaires in´enarrables et plus qu’exhaustifs, fruits de relectures scrupuleuses.
R´ESUM´E
Beaucoup de donn´ees transitent sur les r´eseaux informatiques tels que le r´eseau Internet, et une partie de celles-ci peut ˆetre ill´egale. Les autorit´es qui contrˆolent un r´eseau donn´e ont souvent besoin d’empˆecher la transmission de certains documents, qu’ils soient dangereux, illicites, ou simplement refus´es. Une entreprise pourrait par exemple vouloir empˆecher que certains documents sortent de leur r´eseau interne, de mˆeme que des ´ecoles pourraient chercher `
a filtrer l’acc`es `a des sites sensibles. Nous allons pr´esenter dans ce m´emoire un syst`eme de d´etection et de blocage qui vise `a rep´erer le passage de contenus sp´ecifi´es sur une connexion r´eseau. Le but est qu’un utilisateur ne puisse jamais charger ou envoyer une image, un film ou tout autre document r´ef´erenc´e comme interdit, quelle qu’en soit la source.
Suivant le contexte, il peut ˆetre utile de travailler `a grande ´echelle, c’est-`a-dire de contrˆoler le trafic d’une large population avec un syst`eme unique et centralis´e. On peut alors se placer au niveau des fournisseurs d’acc`es et de services Internet, ou encore sur la connexion `
a Internet d’une tr`es grande entreprise. On contrˆole ainsi l’ensemble des communications qui entrent et sortent de leurs r´eseaux sans avoir `a modifier la configuration des postes utilisateurs. Le nombre de ce type d’interconnexion est relativement r´eduit, ce qui simplifie le d´eploiement. En revanche, les d´ebits en ces points sont tr`es ´elev´es car ils concentrent le trafic de tous les utilisateurs. C’est l`a qu’apparait le principal d´efi, car les fibres optiques utilis´ees aujourd’hui permettent de faire passer 40 `a 100 Gb/s, ce qu’un processeur classique d’usage g´en´eral n’est pas capable de traiter.
Travailler avec de tels d´ebits de donn´ees demande ainsi une puissance de de calcul im-portante, et impose de r´eduire et optimiser les traitements au maximum. Les approches existantes pouvant filtrer autant d’information se basent souvent simplement sur les des-cripteurs des communications tels que l’adresse de l’´emetteur ou du destinataire. Lorsqu’un site internet est suspect´e d’envoyer aux clients du contenu interdit, c’est l’ensemble du site internet qui est bloqu´e, ou l’ensemble des connexions du client qui sont coup´ees, ce qui manque de pr´ecision. Dans notre cas, on cherche `a bloquer la transmission de certains conte-nus uniquement, pr´ealablement r´ef´erenc´es, en laissant passer le reste du trafic. Il faut donc ˆ
etre capable de rep´erer ces contenus (images, vid´eos, programmes, etc.) au milieu de l’en-semble des donn´ees ´echang´ees. De plus, dans la plupart des r´eseaux utilis´es aujourd’hui, les donn´ees ne sont pas transmises telles qu’elles en une seule fois, mais sont d’abord divis´ees en plusieurs petits fragments appel´es paquets, qui sont transmis ind´ependamment. Il faut ainsi d´etecter des extraits des contenus interdits parmi d’autres donn´ees fragment´ees, ce qui demande une plus grande pr´ecision de d´etection, ceci avec plusieurs millions de paquets de
donn´ees par seconde. On bloquera ensuite uniquement la connexion qui a transmis cette partie de document.
D’autre part, nous cherchons `a r´ef´erencer un nombre important de documents. Le sys-t`eme ne doit donc pas souffrir de ralentissement li´e au nombre de contenus `a bloquer. Les programmes antivirus ou de d´etection d’intrusion, qui fonctionnent sur le mˆeme mod`ele d’analyse des donn´ees transmises en temps r´eel, se r´ef`erent en g´en´eral `a des bases de don-n´ees de mod`eles d’attaques qui doivent ˆetre compil´ees avant d’ˆetre utilis´ees. Plus le nombre de r`egles `a tester est important, plus la compilation est difficile et longue. Les syst`emes qui se basent sur cette approche sont alors limit´es `a quelques dizaines de milliers de r`egles. Notre syst`eme peut en revanche stocker un nombre th´eoriquement infini de documents sources, la seule limite ´etant la m´emoire utilis´ee, sans impact sur les performances, grˆace `a un format de base de donn´ees de contenus interdits tr`es simple et efficace.
Pour relever le d´efi de traiter de tr`es hauts d´ebits sans limiter le nombre de documents r´ef´erenc´es, nous avons utilis´e l’algorithme de max-hashing. Cet algorithme a ´et´e sp´ecialement con¸cu pour d´etecter tr`es rapidement des fragments de documents connus, en un minimum d’op´erations. On distingue deux phases : le r´ef´erencement des documents `a d´etecter et blo-quer, puis l’analyse en temps-r´eel du flux r´eseau. Seule cette seconde partie est ´etudi´ee ici, le r´ef´erencement ´etant r´ealis´e hors ligne par les autorit´es qui d´ecident quels documents in-terdire. Nous l’avons impl´ement´e sur processeur graphique (GPU) afin de disposer de leur immense puissance de calcul parall`ele, tr`es adapt´ee pour l’analyse des innombrables paquets ind´ependants `a traiter. Nous pr´esentons dans ce m´emoire le fonctionnement de ce type de mat´eriel et les adaptations n´ecessaires pour qu’un algorithme utilise au maximum les res-sources disponibles et soit capable d’analyser le plus grand d´ebit de donn´ees possible.
Nous d´etaillons l’impl´ementation de l’algorithme de max-hashing sur les GPU de NVidia, ainsi que les performances que nous avons pu mesurer. Un seul processeur graphique peut ainsi traiter plus de 70 Gb/s de donn´ees sources tout en r´ef´eren¸cant plus d’un million de documents `a d´etecter. La vitesse de traitement est n´eanmoins limit´ee par le bus qui transmet les donn´ees vers la carte graphique. Apr`es ´etude des modes de ce bus, on parvient `a envoyer `a 45 Gb/s, ce qui offre tout de mˆeme les performances suffisantes pour analyser une connexion 40GbE, et est `a notre connaissance sans ´equivalent dans la litt´erature. De plus, lorsque la configuration du bus le permet, des configurations `a plusieurs cartes graphiques peuvent ˆetre mises en place, multipliant les d´ebits trait´es et le nombre de r´ef´erences enregistr´ees.
Des tests sur un r´eseau r´eel `a 10 Gb/s ont ´et´e r´ealis´es, en transmettant les r´esultats du module de d´etection `a un logiciel d´edi´e au filtrage. Nous avons ainsi pu mettre en place tr`es rapidement un syst`eme complet fonctionnant en temps-r´eel avec une seule carte graphique. On mesure une latence minimale de 6 ms entre l’arriv´ee d’un paquet de donn´ees et la mise en
place du blocage si n´ecessaire. Ce syst`eme peut s’int´egrer de fa¸con totalement transparente sur le r´eseau `a contrˆoler, et stopper la transmission de tout document interdit.
ABSTRACT
More and more data are being transmitted every day through computer networks such as the Internet. Part of these data may be illegal and networks authorities often need active filtering so that unwanted contents would not enter the network, or private documents would not leave the intranet. This thesis proposes such a filtering appliance, able to efficiently detect and block known documents passing through a watched connection. The main goal is that users could not load or send any document that would be known as forbidden, regardless of its origin.
Working at large scales can be necessary when one wants to control large populations with no need to setup filters on every connected device. One unique and centralized service deals with the whole traffic. Internet services providers are good examples as they agglomerate all their subscribers’ communications. They link with each other using quite few interconnection points, which simplifies a global deployment. The first challenge is that these links use fast media with 40 to 100 Gbps bandwidths. Such high data rate cannot be handled by a standard general-purpose processor and filtering that information is therefore very challenging.
Previous approaches that are able to filter such amounts of data suffer two different limitations. First, some only use communication descriptors such as emitter and receiver addresses. When a website is suspected to send forbidden information to a network user, either the whole website or the whole user connections are blacklisted as no further investi-gation is possible. We ought to block specific and previously listed contents only, allowing all harmless data. We therefore need to spot these contents (images, videos, software...) among other flowing data. Moreover, network protocols require splitting sent data into small chunks, namely packets, which are transmitted independently. Thus, we more pre-cisely need to spot extracts of the referenced contents among other fragmented data, at rates of millions of packets per second. Greater precision is required, but we can then block the only flow that is sending the spotted content.
The second limitation is the number of referenced documents. We want to detect an important set of different contents and the system cannot loose performances when this set enlarges. Antiviral or anti-intrusion systems, which are based on the same real-time analysis model, often use regular expression patterns as rules. These patterns need to be compiled before they can be used, and large rule sets make compilation slower and harder. Such systems are therefore often limited to several thousand rules. Our system can reference millions of documents with no impact on its computation speed, thanks to our simple and efficient forbidden files database format.
We describe a parallel implementation of the max-hashing algorithm that enables the detection of known content by processing network packets individually. The final system rises to the challenge of processing ultra-high bandwidths while referencing millions of documents. The target architecture is based on Graphics Processing Units (GPUs), which are known to offer tremendous performances for highly parallel applications, at low cost. The algorithm first collects a set of fingerprints from the listed documents to detect. Fingerprints are small subsets of the reference documents supposedly unique to the documents and easily identifiable. At detection time, those fingerprints are detected in the network packets and reported to an application that correlates all the matches. Results demonstrate that a single GPU board can theoretically monitor the Internet traffic up to 70 Gbps, with the ability to host hundreds of millions of reference fingerprints. Strangely, the most challenging task is to feed the board at such bandwidths through a standard interface such as PCIe. In fact, the bus cannot transfer more than 45 Gbps, which thus is the system limitation. Nevertheless multi-GPU configurations can be set up depending on the PCIe bus architecture, which multiplies the processing rate and optimize the different resources use.
A complete filtering system demonstrates the functionality of the proposed approach over a 10GbE connection. We measure a minimum latency of 6 ms and the system can be installed on network connections transparently.
TABLE DES MATI`ERES
D´EDICACE . . . iii
REMERCIEMENTS . . . iv
R´ESUM´E . . . v
ABSTRACT . . . viii
TABLE DES MATI`ERES . . . x
LISTE DES TABLEAUX . . . xiii
LISTE DES FIGURES . . . xiv
LISTE DES ANNEXES . . . xv
LISTE DES SIGLES ET ABR´EVIATIONS . . . xvi
CHAPITRE 1 INTRODUCTION . . . 1
1.1 Concepts de base . . . 2
1.1.1 Transmission de donn´ees . . . 2
1.1.2 Filtrage de donn´ees . . . 3
1.2 Analyse des besoins . . . 4
1.2.1 D´etection de fragments de documents . . . 4
1.2.2 D´etection rapide pour filtrer efficacement . . . 5
1.2.3 R´ef´erencement de nombreux documents . . . 6
1.3 Objectifs de recherche . . . 7
1.4 Plan du m´emoire . . . 8
CHAPITRE 2 REVUE DE LITT ´ERATURE . . . 9
2.1 Protocoles r´eseaux . . . 9
2.1.1 Connexion Ethernet . . . 9
2.1.2 Protocole TCP/IP . . . 10
2.2 Algorithmes de d´etection de donn´ees connues . . . 13
2.2.1 Reconnaissance de chaˆınes de caract`eres . . . 13
2.2.2 M´ethodes de Hachage . . . 17
2.3 Syst`emes d’analyse de flux r´eseaux . . . 24
2.3.1 Retour sur incident . . . 25
2.3.2 Analyse en temps r´eel . . . 26
2.3.3 Mat´eriel sp´ecialis´e . . . 28
CHAPITRE 3 ARCHITECTURE PROPOS´EE . . . 32
3.1 Manipulations sur le trafic r´eseau . . . 32
3.1.1 Ecouter l’ensemble du trafic . . . .´ 33
3.1.2 Pont r´eseau . . . 34
3.1.3 Filtrage du trafic . . . 35
3.1.4 R´esum´e . . . 35
3.2 Processeur graphique . . . 36
3.2.1 Introduction . . . 36
3.2.2 Fonctionnement mat´eriel . . . 37
3.2.3 Programmation logicielle . . . 41
3.2.4 Conclusion . . . 44
3.3 Adaptation de l’algorithme de max-hashing . . . 45
3.3.1 Calcul des signatures . . . 45
3.3.2 Base de donn´ees . . . 53
3.4 Syst`eme complet . . . 56
3.4.1 R´epartition des tˆaches . . . 56
3.4.2 M´emoire n´ecessaire . . . 57
3.4.3 Mise en place finale . . . 57
CHAPITRE 4 ANALYSE DU SYST`EME POUR LE PROBL`EME POS´E . . . . 59
4.1 Performances du GPU . . . 60
4.1.1 Mesures de temps sur le GPU . . . 60
4.1.2 Transferts m´emoire . . . 61
4.1.3 Calcul des signatures . . . 62
4.1.4 Recherche des signatures . . . 63
4.1.5 Fonctions enchaˆın´ees . . . 65
4.2 Performances du r´eseau . . . 66
4.2.1 Pont r´eseau . . . 66
4.2.2 Copie du trafic . . . 67
4.2.3 Filtrage . . . 67
4.3 Choix de l’architecture . . . 69
4.3.2 Acquisition et filtrage du trafic . . . 70
CHAPITRE 5 CONCLUSION . . . 71
5.1 Synth`ese des travaux . . . 71
5.2 Limitations de la solution propos´ee . . . 72
5.3 Am´eliorations futures . . . 73
5.4 Neutralit´e . . . 73
5.4.1 Protection de la vie priv´ee . . . 73
5.4.2 Filtrage ou censure ? . . . 74
5.4.3 Risques inh´erents `a notre syst`eme . . . 75
BIBLIOGRAPHIE . . . 76
LISTE DES TABLEAUX
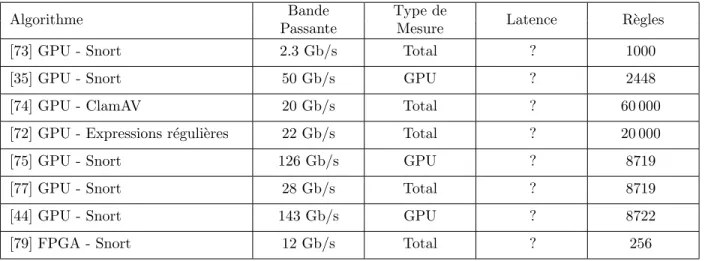
2.1 R´esultats observ´es dans la litt´erature . . . 29 3.1 Configurations des diff´erentes versions des processeurs NVidia . . . . 38 4.1 D´ebit du calcul des signatures . . . 62 4.2 Performances de la recherche de signatures . . . 64 4.3 Performances du pont r´eseau . . . 66
LISTE DES FIGURES
1.1 Carte 2012 de la connectivit´e Internet mondiale . . . 3
2.1 Mod`ele de paquet Ethernet II . . . 9
2.2 Mod`ele de paquet IP . . . 11
2.3 Mod`ele de paquet TCP et UDP . . . 11
2.4 Principe de comparaison directe . . . 14
2.5 Machines `a ´etats de l’algorithme d’Aho-Corasick . . . 15
2.6 Principe du hachage . . . 18
2.7 Principe du Tree Hash . . . 19
2.8 Principe du Context-Triggered Piecewise Hashing . . . 21
2.9 Principe du winnowing . . . 23
2.10 Principe du Max-Hashing . . . 24
3.1 Deux options pour surveiller une connexion . . . 32
3.2 Capture du r´eseau avec pcap . . . 34
3.3 Exemple d’utilisation d’ebtables . . . 35
3.4 Sch´ema de l’organisation d’un GPU . . . 38
3.5 Exemples de mod`eles d’acc`es `a m´emoire globale . . . 40
3.6 Lancement d’une fonction sur le GPU . . . 42
3.7 Exemple de kernel en CUDA C . . . 43
3.8 Les calculs de signatures dans le max-hashing . . . 45
3.9 Principe du calcul des signatures . . . 49
3.10 Calcul des signatures . . . 49
3.11 Evolution des acc`´ es m´emoire . . . 51
3.12 Introduction de divergences . . . 52
3.13 Base de donn´ees de signatures . . . 53
3.14 Principe de la recherche des signatures . . . 55
3.15 L’enchaˆınement complet des op´erations d’analyse . . . 56
4.1 Installation des serveurs pour les tests de r´eseau . . . 59
4.2 Mesure du temps sur le GPU . . . 60
4.3 Bande passante du PCI Express . . . 61
4.4 Temps de recherche d’une signature . . . 64
4.5 Pipeline de l’application . . . 65
4.6 Latence des ebtables . . . 68
LISTE DES ANNEXES
ANNEXE A Fonctions GPU . . . 83
A.1 Calcul des signatures . . . 83
A.1.1 D´efinitions pr´ealables . . . 83
A.1.2 Prototype . . . 83
A.1.3 D´eclarations et Initialisations . . . 84
A.1.4 Prise en compte des recouvrements . . . 85
A.1.5 Milieu du bloc de donn´ees . . . 86
A.1.6 Sauvegarde des maxima et de leurs positions . . . 87
A.2 Lecture et sauvegarde des octets entrants . . . 88
A.2.1 Cas complet . . . 88
A.2.2 Uniquement un octet entrant . . . 88
A.3 Mise `a jour de la signature . . . 89
A.4 Mise `a jour du maximum . . . 89
A.4.1 Avec un tableau de maxima . . . 89
A.4.2 Avec des registres . . . 90
A.5 Recherche de signatures . . . 91
ANNEXE B Fonctions CPU . . . 92
B.1 Analyse d’un buffer . . . 92
B.1.1 Prototype et initialisation . . . 92
B.1.2 Calcul des signatures . . . 93
B.1.3 Recherche des signatures . . . 93
LISTE DES SIGLES ET ABR´EVIATIONS
CPU Central Processing Unit
CUDA Compute Unified Device Architecture CTPH Context-Triggered Piecewise Hashing DFA Deterministic Finite Automaton DMA Direct Memory Access
DPI Deep Packet Inspection
FAI Fournisseurs d’Acc`es `a Internet FPGA Field-Programmable Gate Array
GPGPU General-Purpose computation on Graphics Processing Units GPU Graphics Processing Unit
IDS Intrusion Detection System IP Internet Protocol
IPS Intrusion Prevention System MAC Media Access Control
MD5 Message Digest #5
NFA Non-Deterministic Finite Automaton PCI Peripheral Component Interconnect PCIe PCI Express
SHA1 Secure Hash Algorithm
SIMD Single Instruction Multiple Data TCP Transmission Control Protocol UDP User Datagram Protocol
CHAPITRE 1
INTRODUCTION
En 2012, 2.5 exaoctets1 de donn´ees sont cr´e´ees chaque jour [32] et sont amen´ees `a
transi-ter sur des r´eseaux, notamment sur Internet. En cons´equence, on mesure que chaque ann´ee le trafic Internet augmente d’environ 35% [11]. Ces chiffres peuvent paraˆıtre impressionnants, ou finalement assez modestes rapport´es `a la population mondiale, mais il est certain que la d´emocratisation du num´erique entraˆıne un accroissement rapide des quantit´es de donn´ees produites et ´echang´ees. Une partie du contenu peut ˆetre ill´egale, la pornographie infantile en est un exemple, pr´esenter des risques comme les virus informatiques, ou ˆetre simplement gˆenante, comme le spam.
Contrˆoler les donn´ees qui transitent sur les r´eseaux devient primordial pour les adminis-trateurs. Plus encore, il est int´eressant de pouvoir en bloquer la transmission pour limiter leur propagation. Les fournisseurs de service d’email ont par exemple int´erˆet `a d´evelopper leurs contrˆoles pour r´eduire la quantit´e de spam car ces courriers ind´esirables, outre amoin-drir la satisfaction des utilisateurs, consomment une tr`es large part de leur bande passante, puisqu’ils repr´esentent entre 65 et 75% des messages [13]. Il y a donc des int´erˆets tant ´
economiques que judiciaires `a contrˆoler le trafic sur les r´eseaux.
Nous allons pr´esenter dans ce m´emoire une solution de blocage de contenus connus. Nous cherchons en effet un syst`eme capable d’ˆetre ins´er´e de fa¸con transparente dans un r´eseau, c’est-`a-dire sans en modifier la configuration. Il s’agira, apr`es r´ef´erencement du contenu de certains documents, images, vid´eos ou autres, de rep´erer ces contenus parmi les informations transitant sur le segment surveill´e et ´eventuellement de les bloquer. Le but est d’obtenir un syst`eme pouvant r´ef´erencer un tr`es grand nombre de documents diff´erents, de l’ordre de plusieurs millions, et capable de traiter les donn´ees avec des performances, latence et bande passante par exemple, assez importantes pour pouvoir offrir ce nouveau type de contrˆole `a de grands r´eseaux d’entreprises ou `a des Fournisseurs d’Acc`es `a Internet (FAI). Travailler `a ce niveau permet en effet une surveillance `a tr`es grande ´echelle, sans avoir `a installer d’autres protections sur les postes utilisateurs, nombreux et h´et´erog`enes. Une entreprise peut choisir de bloquer la diffusion de documents confidentiels vers l’ext´erieur, tandis qu’un FAI peut vouloir ou se voir imposer de bloquer la propagation de contenus illicites sur Internet.
1.1 Concepts de base
Avant de nous pencher sur la solution `a mettre en place, il est important de comprendre le fonctionnement des transmissions sur Internet et les enjeux d’un tel filtrage. Nous allons donc dans un premier temps passer rapidement en revue les d´efis actuels dans l’analyse des communications r´eseaux, avant d’insister sur l’int´erˆet qui existe dans le filtrage de contenu. Finalement, nous ´etudierons le fonctionnement des r´eseaux et les protocoles utilis´es pour l’´echange des donn´ees.
1.1.1 Transmission de donn´ees
Comme nous l’avons ´evoqu´e dans le paragraphe pr´ec´edent, la quantit´e de donn´ees qui transite en permanence sur l’ensemble des liaisons mondiales est immense. Des r´eseaux scien-tifiques ou industriels sont tr`es utilis´es pour le partage et la d´ecentralisation des informations. De plus, la d´emocratisation du cloud computing acc´el`ere cette tendance : les fichiers et les programmes ne sont plus sauvegard´es et ex´ecut´es sur l’ordinateur de l’utilisateur mais sur des serveurs distants. Ces services sont d’une grande qualit´e mais n´ecessitent une connexion `
a Internet puissante et imposent le transfert de beaucoup de donn´ees.
D’autre part, avec l’explosion de la connectivit´e (mobile comme fixe) de la population, chacun est `a mˆeme de partager tout contenu, en temps r´eel. Les technologies ´evoluent pa-rall`element : la r´esolution des appareils photos augmente, produisant des images de plus en plus volumineuses, les terminaux deviennent plus puissants, ce qui permet aux fournisseurs de proposer des plateformes en ligne de plus en plus ´elabor´ees. Les bandes passantes des r´eseaux de communication augmentent elles-aussi, ce qui permet aux utilisateurs d’acc´eder aux ressources disponibles en ligne de fa¸con similaire `a celles localis´ees directement sur leur ordinateur. Tous ces ´el´ements m`enent `a une utilisation de plus en plus grande des r´eseaux. De mˆeme, les entreprises, qui utilisaient historiquement des r´eseaux informatiques ferm´es pour plus de s´ecurit´e, s’ouvrent et s’´etendent sur des r´eseaux virtuels multisites. Beaucoup de donn´ees sont donc cr´e´ees et transmises, et doivent alors emprunter des voies de commu-nications adapt´ees, le r´eseau Internet en ´etant la principale composante.
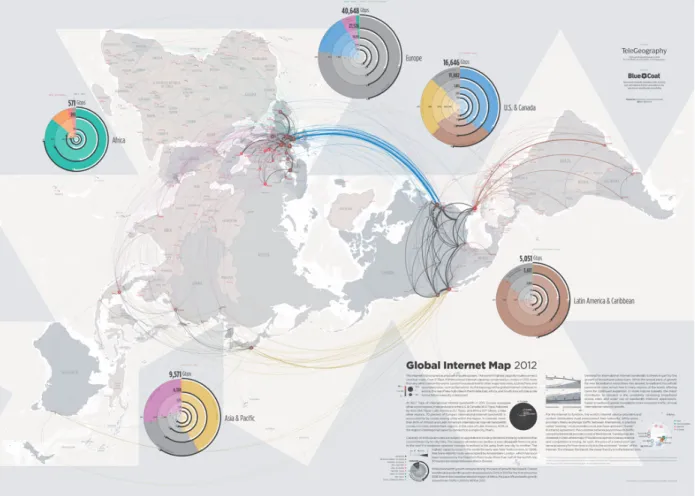
Plusieurs ´etudes ont regroup´e des donn´ees sur les d´ebits des communications `a l’´echelle mondiale. On trouve notamment sur le site Internet de TeleGeography des cartes tr`es claires sur la connectivit´e internationale, telles que celle reprise sur la figure 1.1. On constate qu’en 2011 l’Europe disposait d’une capacit´e globale de 40 Tb/s et l’Am´erique du nord de 16 Tb/s. Mˆeme en p´eriode de pointe, ces bandes passantes sont largement pr´evues pour le trafic actuel (47% d’utilisation en Europe, 53% en Am´erique du Nord en 2011) mais ces donn´ees donnent une id´ee claire du d´efi pour contrˆoler l’ensemble de ce trafic.
1.1.2 Filtrage de donn´ees
Pourquoi alors vouloir contrˆoler tant de donn´ees ? Deux buts principaux justifient sou-vent cette demande. La protection des r´eseaux et des utilisateurs contre les contenus ill´egaux ou dangereux est pr´edominante. Par exemple, les entreprises, ´ecoles ou autres collectivit´es utilisent souvent un proxy pour filtrer les requˆetes `a Internet avec une liste de sites inter-dits. Cela permet aussi de limiter l’acc`es `a des sites sensibles ou la transmission de fichiers ex´ecutables et notamment de virus. Dans un autre contexte, rep´erer la diffusion de contenus interdits tels que les abus sexuels sur les enfants permet aux services de police de tracer les auteurs ainsi que d’en limiter les “utilisateurs”.
La copie et le plagiat menacent certains int´erˆets financiers en allant notamment contre le droit d’auteur. Le second but de l’inspection des flux de donn´ees est ainsi d’encadrer la reproduction incontrˆol´ee de tout contenu. Par exemple, un ´editeur peut v´erifier la source des fichiers envoy´es et publi´es, `a la recherche d’extraits de contenus existants. On peut alors
Carte par Telegeography (“Global Internet Map 2012 ”) Contenu sous licence Creative Commons BY-NC-ND 3.0
combattre le plagiat efficacement, voire limiter les tentations des auteurs directement en les avertissant. On met alors en place des outils d’analyse de r´eseau, `a plus ou moins grande ´
echelle, qui se chargent d’analyser les donn´ees transmises.
Les solutions existantes capables de travailler `a de tels d´ebits sont g´en´eralement bas´ees sur uniquement l’analyse de la source et/ou de la destination des messages. On bloque ainsi une image ou un site Internet complet via leur adresse. Ces m´ethodes sont simples car elles ne s’int´eressent qu’aux descriptions des transmissions, sans avoir `a en reconnaˆıtre le contenu. Des syst`emes de listes noires existent dans beaucoup de pays et sont impos´es aux fournisseurs d’acc`es `a Internet. Ils sont rapides `a mettre en place mais ne peuvent pas combattre l’apparition de sites miroirs par exemple, ou le d´em´enagement d’un site interdit `a une autre adresse. La Chine est l’exemple le plus connu, o`u des lois r´egissent directement la liste des sites autoris´es ou non pour les internautes de ce pays. Elle a cependant aussi mis en place d’autres techniques plus avanc´ees qui permettent de terminer une connexion lorsqu’un certain nombre de mots-cl´es y ont ´et´e d´etect´es. Un tel contrˆole demande alors d’ˆetre capable d’analyser les communications de l’ensemble de la population.
C’est cette derni`ere approche qui nous int´eresse, en ´elargissant les mots cl´es `a tout contenu num´erique. En terminant la connexion assez rapidement d`es qu’un fragment interdit est rep´er´e, on empˆeche tout passage d’un document complet.
1.2 Analyse des besoins
Diff´erents besoins cl´es doivent imp´erativement ˆetre int´egr´es `a un syst`eme de filtrage r´eseau. Nous allons dans cette partie les mettre en exergue afin de les ´etudier pr´ecis´ement. Nous pourrons alors les garder `a l’esprit tout au long de la conception et de la validation. Une fois ces bases pos´ees, nous pourrons justifier l’emploi des technologies choisies. Nous avons d´ej`a ´evoqu´e les motivations et les protocoles `a utiliser, nous d´etaillerons dans cette partie les besoins qu’ils entraˆınent : la d´etection de fragments de documents, le r´ef´erencement de nombreux documents, et la d´etection en temps r´eel.
1.2.1 D´etection de fragments de documents
Le r´eseau Internet, de mˆeme que la grande majorit´e des r´eseaux actuellement, est bas´e sur le protocole Ethernet. Celui-ci impose que les documents transmis soient d’abord divis´es en plusieurs sous-blocs envoy´es successivement. Chaque bloc peut avoir une taille quelconque inf´erieure `a 1500 octets, et est int´egr´e dans une “trame”, qui contient en particulier l’adresse de la machine et du destinataire ainsi que la taille du bloc. Nous pr´esenterons les protocoles utilis´es dans les r´eseaux `a la section 2.1. Notons que les trames ne sont pas n´ecessairement
de la taille maximale autoris´ee, mais peuvent ˆetre plus petites, la taille ´etant d´efinie par les capacit´es respectives de tous les interm´ediaires du r´eseau et adapt´ee au cours des commu-nications. Une application de d´etection doit alors ˆetre capable de rep´erer des fragments de documents de petite taille.
La recherche de texte dans une page web ou tout autre document est une illustration du rep´erage d’extraits. Les utilisateurs sont capables de retrouver tout extrait exact dans leur document source. On cherche dans ce m´emoire `a appliquer le mˆeme principe avec les trames passant sur le r´eseau : chercher le contenu des trames dans un ensemble de documents de r´ef´erence.
Pour simplifier les traitements, on pourrait ´etudier la taille id´eale des fragments `a d´etecter et extraire uniquement ce fragment des trames re¸cues avant de le chercher dans les documents sources. Aux deux extrˆemes, des extraits de tr`es grande taille seraient difficilement rep´erables du fait du peu de chances qu’ils soient contenus en entier dans une trame, mais des extraits de toute petite taille produiraient beaucoup de faux-positifs du fait du peu d’´el´ements vraiment repr´esentatifs du document original. Il faut donc soit choisir une taille de fragments assez importante pour ˆetre repr´esentative du document et assez faible pour ˆetre contenue dans une trame, soit trouver des m´ethodes pour outrepasser cette question. Nous ´etudierons des m´ethodes existantes au chapitre 2.
1.2.2 D´etection rapide pour filtrer efficacement
Les Fournisseurs d’Acc`es `a Internet (FAI) g`erent les connexions des utilisateurs au r´ e-seau Internet. Ils se chargent donc de faire l’agr´egation du trafic et la bande passante qu’ils utilisent est la somme de toutes les bandes passantes de leurs clients. Les FAI sont g´en´ era-lement reli´es entre eux et aux fournisseurs de services par des fibres optiques qui autorisent des connexions `a 40 Gb/s, voire 100 Gb/s. Le r´eseau d´eploy´e par la soci´et´e Cogent [14] en est un bon exemple.
Nous avons besoin d’un point de passage des donn´ees pour pouvoir les observer et les filtrer. Les liaisons entre FAI paraissent int´eressantes car il s’agit de points de passage pr´ e-existant regroupant beaucoup de trafic, et le nombre de ces liaisons est relativement limit´e. Il faut alors viser leur gamme de d´ebits pour obtenir un syst`eme utilisable `a grande ´echelle. De mˆeme, il devient imp´eratif de traiter les paquets tr`es rapidement puisque leur passage prend tr`es peu de temps. En effet, les abonn´es disposent couramment de bandes passantes de l’ordre de 10 Mb/s. Les paquets sont transmis `a cette vitesse en 0.1 ms. Du fait des ´
etapes par les diff´erents ´el´ements des r´eseaux pour atteindre le serveur destinataire, les utilisateurs observent en g´en´eral une latence de l’ordre de quelques dizaines de millisecondes entre le d´epart du paquet de leur machine jusqu’`a l’arriv´ee sur la machine vis´ee. Une latence
trop ´elev´ee diminue le confort de l’utilisateur en le faisant patienter entre chacune de ses action. Des domaines n´ecessitant une bonne r´eactivit´e comme la vid´eoconf´erence, le contrˆole `
a distance ou les jeux vid´eos en ligne sont tr`es vite impact´es par une augmentation de la latence. Il est alors important de prendre en compte cet aspect et de cr´eer un syst`eme qui ne bloque pas, ou tr`es peu, les paquets pendant leur analyse.
Pour augmenter les d´ebits trait´es sans impacter la latence, on peut utiliser du mat´eriel capable d’analyser les paquets en parall`ele. Nous avons ´evoqu´e `a la section 1.2.1 que les docu-ments sont divis´es en paquets avant d’ˆetre envoy´es. Les paquets d’une source sont m´elang´es avec d’autres lorsque les trafics sont regroup´es, notamment au niveau des routeurs. Deux paquets qui se suivent ne sont donc pas li´es entre eux. De plus, la n´ecessit´e de reconnaˆıtre des fragments de documents abord´ee `a la section 1.2.1 a ´et´e ´etablie dans le but de travailler uniquement sur le contenu des paquets, sans devoir reconstruire le document original. Ces ´
el´ements nous offrent la possibilit´e de travailler sur les diff´erents paquets en parall`ele. Avec du mat´eriel compatible, on multiplie le d´ebit par le nombre d’unit´es de traitement sans aug-menter la latence. Ce type de mat´eriel est tr`es en vogue actuellement et se d´eveloppe tr`es vite. Les plus communs sont les CPU, compos´es aujourd’hui de deux `a douze cœurs de calcul, et les processeurs graphiques (Graphics Processing Unit (GPU)) qui comprennent plusieurs centaines d’unit´es de calcul plus limit´ees. D’autres dispositifs plus sp´ecifiques existent. Les processeurs r´eseaux sont des puces tr`es sp´ecialis´ees dans le traitement de flux de donn´ees, utilis´ees principalement dans les routeurs ou cartes r´eseaux haut de gamme. Finalement, les Field-Programmable Gate Array (FPGA) pr´esentent aussi l’int´erˆet d’un parall´elisme intrin-s`eque tr`es adaptable puisque l’on peut impl´ementer autant d’instances que n´ecessaire d’une mˆeme unit´e de calcul dans la seule limite de la taille de la puce. Nous nous focaliserons dans ce m´emoire sur les GPU, dont nous ´etudierons les atouts au chapitre 2.
1.2.3 R´ef´erencement de nombreux documents
Notre syst`eme est vou´e `a filtrer un nombre de documents quelconque, potentiellement important suivant la politique de contrˆole appliqu´ee. Il convient donc de garantir que les performances finales ne diminueront pas avec l’augmentation du nombre de documents. Les originaux `a filtrer doivent ˆetre r´ef´erenc´es, dans une base de donn´ees qui sera consult´ee pour identifier les donn´ees analys´ees. Plusieurs points entrent en compte dans les performances de cette base de donn´ees. Tout d’abord, il faut sp´ecifier dans quel format sont enregistr´es les do-cuments r´ef´erenc´es (ou les r´ef´erences `a ces documents). Leur lisibilit´e peut ˆetre un probl`eme puisque l’on cherche `a traiter du contenu sensible. Si les administrateurs peuvent acc´eder `a ces informations, on s’expose `a des fuites de documents, ce que l’on cherche pr´ecis´ement `a endiguer.
D’autre part, il faut tenir compte du fait que stocker beaucoup de documents peut n´ eces-siter beaucoup de m´emoire, particuli`erement s’il s’agit d’images ou de vid´eos. Les dispositifs de stockage disposant de beaucoup d’espace, comme les disques durs ou encore des espaces de stockage en r´eseau, souffrent souvent de temps d’acc`es assez longs. Il faudra donc chercher `
a r´eduire les besoins en espace de stockage ou le nombre d’acc`es n´ecessaires `a la m´emoire pour masquer la latence induite par ces acc`es. L`a encore le parall´elisme peut ˆetre utile car une application massivement parall`ele a toujours des calculs en attente qui peuvent combler les temps de latence de la m´emoire. La bande passante diminue alors moindrement mˆeme si la latence augmente.
Finalement, il faudra prendre en compte le probl`eme de redondance entre les documents. En effet, des documents semblables, ne serait-ce que par l’application dans laquelle ils ont ´et´e cr´e´es ou par leur type, comporteront de nombreuses parties identiques comme les entˆetes, formatages ou autres m´eta-donn´ees. La d´etection de ces parties pourra donc facilement induire des faux-positifs, c’est-`a-dire des alertes lanc´ees sur des donn´ees qui ne pr´esentent en r´ealit´e pas de risque. Disposer d’une base de donn´ees assez importante peut permettre d’´eviter ces d´esagr´ements en effectuant une analyse statistique et en ne prenant pas en compte les parties redondantes des documents lors du r´ef´erencement. Nous consid´ererons ici que seules les parties hautement repr´esentatives des documents et donc a priori uniques, sont r´ef´erenc´ees. Nous nous concentrerons ainsi sur le travail de d´etection et de blocage en temps r´eel plutˆot que sur la s´election des “meilleures” parties des documents qui pourra ˆetre effectu´ee s´epar´ement.
1.3 Objectifs de recherche
Finalement, en reprenant les ´el´ements pr´ec´edents, nous pouvons formuler la probl´ ema-tique de ce m´emoire comme suit :
Comment rep´erer et bloquer efficacement des contenus num´eriques connus transitant sur un r´eseau, en travaillant en temps r´eel avec des bandes passantes tr`es ´elev´ees (40 `a 100 Gb/s) tout en gardant une latence assez faible pour ne pas
influer sur le confort des utilisateurs du r´eseau ?
On proposera ainsi une solution de filtrage de contenus pr´ealablement r´ef´erenc´es, capable de travailler `a grande ´echelle sur le r´eseau Internet ou les r´eseaux de grandes entreprises ou universit´es.
L’un des points principaux sera l’analyse des solutions parall`eles qui paraissent pro-metteuses, ainsi que l’adjonction d’une base de donn´ees sans pertes de performances avec l’augmentation de sa taille.
1.4 Plan du m´emoire
La suite de ce m´emoire, s’articulera en quatre chapitres. Tout d’abord, nous ´etudierons au chapitre 2 les solutions existantes, tant au niveau de l’algorithme que de l’architecture du syst`eme complet. Nous ferons ainsi ressortir l’int´erˆet de l’algorithme de Max-Hashing et des syst`emes bas´es sur des processeurs graphiques (GPU). Nous commencerons cette sec-tion par un rappel sur les protocoles utilis´es dans les r´eseaux. Nous pr´esenterons ensuite au chapitre 3 l’impl´ementation et l’optimisation de cet algorithme pour de tels processeurs, en d´etaillant les adaptations n´ecessaires pour obtenir une impl´ementation efficace. Nous nous int´eresserons aussi aux m´ethodes de r´ecup´eration du trafic r´eseau, et aux moyens simples pour filtrer ce trafic. Nous pourrons ensuite construire un banc de tests pour analyser le syst`eme au chapitre 4. Nous mesurerons les performances et r´epondrons ainsi `a la probl´ e-matique. Finalement, nous conclurons au paragraphe 5 sur l’ensemble des travaux, sur les limitations et les am´eliorations restantes. Nous signalerons aussi les probl`emes de neutralit´e qui existent sur un tel syst`eme.
Le lecteur trouvera en annexe le code annot´e d´ecrivant l’analyse les donn´ees re¸cues du r´eseau pour y rechercher les correspondances avec les documents originaux.
CHAPITRE 2
REVUE DE LITT´ERATURE
Le but de ce m´emoire est de pr´esenter un syst`eme fonctionnel de filtrage de contenus num´eriques connus sur un flux r´eseau. Pour ce faire nous allons d’abord ´etudier les algo-rithmes de reconnaissance existants qui pourraient ˆetre adapt´es `a ce domaine, avant de nous int´eresser aux m´ethodes d’analyse de flux r´eseaux. Nous insisterons sur les diff´erents types de mat´eriel commun´ement utilis´es et nous pourrons analyser les forces et les faiblesses de chacune des approches pour finalement constituer la meilleure r´eponse possible `a notre probl`eme.
2.1 Protocoles r´eseaux
Comme nous l’avons ´evoqu´e en introduction, les r´eseaux utilisent en g´en´eral le protocole Ethernet. D’autres protocoles s’ajoutent dans celui-ci pour masquer les adresses mat´erielles et abstraire les communications. Nous allons d´etailler ici leur fonctionnement car nous serons amen´es `a les utiliser tout au long de ce m´emoire. Le lecteur d´ej`a `a l’aise avec les protocoles Ethernet, IP, TCP et UDP pourra toutefois passer cette section sans incidence sur la suite de la lecture.
2.1.1 Connexion Ethernet
Ethernet est un protocole de communication au niveau physique normalis´e en 1985 [33]. On construit les messages en commen¸cant par un en-tˆete identifiant l’´emetteur et le r´ ecep-teur, avant de placer le contenu (ou payload ). L’ensemble transmis est appel´e une “trame”. La taille du contenu est limit´ee `a 1500 octets. Si les informations `a transmettre sont trop volumineuses, alors elles sont divis´ees en plusieurs paquets de taille inf´erieure ou ´egale `a 1500 octets. Le destinataire se charge de reconstruire l’information compl`ete apr`es avoir re¸cu l’ensemble des paquets correspondants.
Chaque machine est identifi´ee par une adresse unique, appel´ee adresse Media Access
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 . . . 1 2 3 4
Pr´eambule Adresse MAC Adresse MAC Taille Donn´ees Signature
source destination Type
Control (MAC), constitu´ee de six octets. Il y a plusieurs types de trames Ethernet, avec chacune leur en-tˆete sp´ecifique. La plus utilis´ee est Ethernet II. Son en-tˆete est tr`es simple, comme l’indique la figure 2.1 :
– Adresse MAC de la machine destinataire – Adresse MAC de la machine source
– Type/Taille : d´etermine quel type de donn´ees est contenu dans la trame :
→ valeur ≤ 1500 : il s’agit directement de donn´ees brutes de la taille correspondante → valeur > 1500 : il s’agit du type de protocole utilis´e dans le champ donn´ees – Donn´ees, jusqu’`a 1500 octets
– Signature pour v´erifier l’int´egrit´e des donn´ees re¸cues
Il ne transite donc sur les r´eseaux que des trames de ce mod`ele ou ´equivalent. Il suffit alors de pouvoir les r´ecup´erer pour acc´eder `a leur contenu. Il n’y a aucun contrˆole ni restriction quant `a la lecture par une autre entit´e que le destinataire. Les deux machines concern´ees ne sont pas n´ecessairement reli´ees directement l’une `a l’autre et le message peut ˆetre retransmis par plusieurs interm´ediaires, qui ont alors pleinement acc`es au contenu.
2.1.2 Protocole TCP/IP
On l’a vu, un protocole peut ˆetre indiqu´e dans les entˆetes des trames Ethernet. Les donn´ees sont en effet tr`es rarement transmises directement. Des abstractions sont ajout´ees au dessus de l’Ethernet pour faciliter le routage des trames. La plus courante est l’Internet Protocol (IP). Il s’agit d’ins´erer un nouvel en-tˆete dans les donn´ees de la trame Ethernet. On communique alors entre machines non plus avec l’adresse MAC, consid´er´ee comme une adresse mat´erielle, mais avec une adresse logicielle, l’adresse IP. Plusieurs contrˆoles existent avec ce protocole comme la recherche de destinataires avec le DNS pour retrouver l’adresse IP `a partir du nom de la machine ou l’ARP pour en retrouver l’adresse MAC `a partir de l’adresse IP, ou encore l’assignation dynamique d’adresse avec le DHCP, qui permettent d’´etendre les possibilit´es de communication. La version 4 de L’IP utilise 32 bits pour coder les adresses, la version 6 en cours de d´eploiement utilise dor´enavant 128 bits. L’augmentation de la taille des adresses permet d’autoriser la connexion simultan´ee de beaucoup plus de p´eriph´eriques dans un mˆeme r´eseau.
L’en-tˆete, sch´ematis´e `a la figure 2.2, reprend le mˆeme principe que l’en-tˆete Ethernet, avec de nouveaux param`etres. Les param`etres communs aux deux versions sont les plus utiles :
– Version : sp´ecifie quelle version de l’en-tˆete IP est utilis´ee – Taille
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 Version Long. en-tˆete Type de service Cong Longueur totale
Identification Flags Fragment offset
Dur´ee de vie Protocole Somme de contrˆole de l’en-tˆete
Adresse IP source Adresse IP destination Options (facultatif) Donn´ees (a) IP v4 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
Version Classe de trafic Flow label
Taille des donn´ees Protocole Limite de renvois
Adresse IP source
Adresse IP destination
Donn´ees (b) IP v6
Figure 2.2 – Mod`ele de paquet IP
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
Port source Port destination
Num´ero s´equentiel R´ef´erence
Data offset Flags Taille de fenˆetre
Somme de contrˆole Pointeur d’urgence
Options (facultatif) Donn´ees (a) TCP
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
Port source Port destination
Taille Somme de contrˆole
Donn´ees (b) UDP
– Adresses IP de l’´emetteur et du destinataire
Lors de transferts de donn´ees entre deux machines, on utilise en g´en´eral une abstraction suppl´ementaire, dite couche de transport, telle que le Transmission Control Protocol (TCP) ou l’User Datagram Protocol (UDP). Le TCP comprend des accus´es de r´eception et est donc utilis´e dans la majorit´e des cas, d`es lors que l’on veut s’assurer que les donn´ees arrivent toutes `
a destination L’UDP, qui n’a aucun contrˆole de ce type, est pr´ef´er´e dans la transmission de flux en temps r´eel. L’un comme l’autre utilisent l’adressage du protocole IP et ajoutent des “ports” aux machines, qui peuvent ˆetre consid´er´es comme des acc`es ind´ependants, chacun d´edi´e `a une application logicielle sur ces machines. On adresse ainsi chaque paquet `a un service donn´e sur la machine destinataire et on isole les services les uns des autres. Comme indiqu´e sur la figure 2.3, le port est identifi´e par un num´ero compris entre 0 et 65535 La plupart des identifiants inf´erieurs a 1024 sont standardis´es [31] et r´eserv´es `a certains services courants. La connexion aux serveurs web pour naviguer sur un site Internet se fait par exemple usuellement par le port 80.
On arrive alors `a un niveau o`u des programmes s’adressent aux programmes d’autres machines, grˆace au couple adresse IP et port. Les abstractions suppl´ementaires qui existent sont des couches applicatives que nous ne consid`ererons donc pas puisque nous n’avons pas besoin de nous sp´ecialiser sur l’´ecoute des communications d’un programme sp´ecifique. Une connexion est alors d´efinie par les quatre param`etres suivants :
– Adresse IP de l’´emetteur – Port de l’´emetteur
– Adresse IP du destinataire – Port du destinataire
2.2 Algorithmes de d´etection de donn´ees connues
Reconnaˆıtre des motifs (en anglais “Pattern recognition”) dans un flux de donn´ees est `
a la base de nombreux algorithmes, depuis la d´etection de plagiat jusqu’aux antivirus. Il s’agit de balayer un texte, un fichier, ou n’importe quel ensemble de donn´ees pour y trouver un motif ou pattern, ou l’ensemble de ses occurrences. Nous cherchons ici `a analyser une connexion r´eseau. Le protocole le plus r´epandu est l’IP, lui-mˆeme int´egr´e dans le protocole Ethernet. Comme nous l’avons ´evoqu´e `a la section 2.1, les donn´ees transf´er´ees selon ces protocoles sont divis´ees en paquets. On peut facilement “´ecouter” une connexion r´eseau et r´ecup´erer les paquets qui y transitent pour analyser leur contenu. Nous pr´esenterons ces m´ethodes dans le chapitre suivant. Il paraˆıt alors int´eressant d’appliquer les m´ethodes de reconnaissance de documents au contenu des paquets IP pour d´etecter le passage de donn´ees connues (interdites, ill´egales, secr`etes ou autres) sur un flux r´eseau. Il suffirait alors de comparer ce contenu avec une liste de fichiers `a rep´erer et de lancer des alertes en cas de correspondance.
`
A partir de ces id´ees, on peut ´etablir un premier cahier des charges pour caract´eriser simplement l’algorithme de d´etection des donn´ees :
– Possibilit´e de rep´erer des fragments de documents et pas uniquement des documents complets, pour travailler avec le contenu de chaque paquet individuellement.
– R´ef´erencer un nombre important et quelconque de documents, quels que soient leur type et leur taille, sans perte de performance.
– Bande passante tr`es importante pour pouvoir travailler `a l’´echelle de grandes entre-prises ou de FAI.
2.2.1 Reconnaissance de chaˆınes de caract`eres
Les chaˆınes de caract`eres sont tr`es simples `a repr´esenter et `a traiter, d’autant plus que nous pouvons facilement les appr´ehender. Chaque caract`ere est repr´esent´e par un octet, et tout ensemble de donn´ees peut alors ˆetre consid´er´e comme une chaˆıne de caract`eres pas n´ecessairement lisible, il suffit pour s’en convaincre d’ouvrir un fichier quelconque avec un ´
editeur de texte. Il n’est donc pas surprenant que celles-ci aient ´et´e `a la base des recherches dans le domaine. Le probl`eme consiste `a localiser une chaˆıne de caract`eres ou toutes ses occurrences dans un texte. On trouve notamment deux ´etudes sur les ´evolutions de tels algorithmes par Baeza-Yates [3] et Michailidis et Margaritis [50].
A7 BC 56 F7 79 00 8A DD 7D 9D 6B EF 12 AC CA 4C 6B F8 0A
= ? = ? = ? = ? = ? = ? = ? = ? = ? 9D 6B EF 12 AC CA 4C 6BChaque octet est compar´e avec le mod`ele recherch´e.
Figure 2.4 – Principe de comparaison directe Comparaison directe
La premi`ere m´ethode adopt´ee a ´et´e une simple comparaison de la chaˆıne de caract`eres recherch´ee avec chaque partie du texte analys´e. Cette approche a ´et´e utilis´ee d`es les d´ebuts de l’informatique mais n’a ´et´e ´etudi´ee rigoureusement que plus tard par Barth [4]. Elle est tr`es simple, puisqu’il s’agit de d´eplacer le mod`ele recherch´e tout au long des donn´ees ´etudi´ees en comparant tous les caract`eres `a chaque it´eration. Elle se classe donc parmi les m´ethodes de force brute, avec un temps d’ex´ecution proportionnel `a la taille du texte ainsi qu’`a celle de la recherche. La figure 2.4 d´ecrit le principe de base.
Pour r´eduire le nombre de comparaisons, diff´erents algorithmes ont ´et´e propos´es, opti-misant le d´eplacement du mod`ele au long du texte analys´e. Ceux de Boyer et Moore [6] et Knuth et al. [41] sont devenus les r´ef´erences dans le domaine, et furent ensuite am´elior´es par Horspool [28] ou encore Takaoka [68]. Ces approches ajoutent un traitement pr´ealable visant `a r´eduire le nombre d’it´erations, par exemple en rep´erant des parties redondantes. On obtient par ce biais des m´ethodes de moindre complexit´e par rapport `a la longueur du texte et/ou du mod`ele.
Expressions r´eguli`eres
Pour r´eduire l’encombrement et la diversit´e des chaˆınes de caract`eres recherch´ees, des m´ethodes de repr´esentation de ces chaˆınes de caract`eres ont ´et´e pr´esent´ees. Il devient par exemple possible de sp´ecifier qu’un caract`ere peut ˆetre r´ep´et´e, que n’importe quel caract`ere peut ˆetre plac´e `a certains emplacements, etc. pour finalement d´ecrire beaucoup plus large-ment des recherches qui peuvent s’adapter `a diff´erents cas. Une explication tr`es compl`ete est donn´ee par Aho [1].
`
A l’origine, cette approche n’´etait pas d´edi´ee `a la comparaison de documents. En effet, McCulloch et Pitts [47], puis Kleene [40] ont ´erig´e les fondements th´eoriques dans le domaine
* * b a c abc abc bc bccbcc cc cc ab abc ou bcc ou cc
Inspiré de l’article « Algorithme d'Aho-Corasick » de Wikipedia
Une machine `a ´etats est cr´e´ee `a partir du mod`ele recherch´e. La lecture des donn´ees fait ´evoluer l’´etat courant jusqu’`a aboutir `a un ´etat final.
Figure 2.5 – Machines `a ´etats de l’algorithme d’Aho-Corasick
des automates, en se basant sur des ´etudes et simulations de neurones. Leurs neurones for-mels pouvaient ˆetre excit´es ou inhib´es, et produisaient une sortie en cons´equence. Plusieurs ´
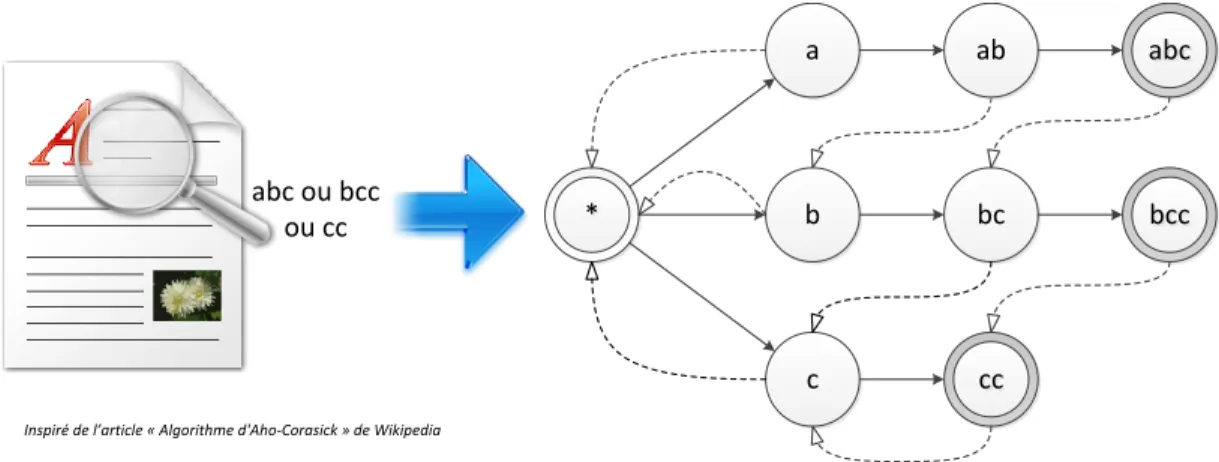
evolutions et simplifications ont ensuite men´e aux travaux de Rabin et Scott [60], qui ont repris, ´elargi et prouv´e les th´eories pr´ec´edentes. Plusieurs m´ethodes de traitement ont ´et´e propos´ees, bas´ees sur un principe g´en´eral commun : cr´eer des machines `a ´etats pour repr´ e-senter l’ensemble des objets recherch´es. On lit ensuite les donn´ees ´etudi´ees, et les caract`eres rencontr´es activent certaines transitions des machines `a ´etats, dont l’´etat courant ´evolue au fur et `a mesure de la lecture. Lorsque celles-ci rencontrent un ´etat final, alors un pattern recherch´e a ´et´e trouv´e.
Les algorithmes sont souvent class´es en deux cat´egories :
– Deterministic Finite Automaton (DFA) [47] : La m´ethode d’origine dans laquelle les ´etats repr´esentent les avanc´ees caract`ere par caract`ere. On ne peut alors ´evoluer dans la machine que d’un ´etat `a la fois, `a la lecture de chaque caract`ere, avec des transitions exclusives. Le syst`eme n’est constitu´e que d’une machine `a ´etat.
– Non-Deterministic Finite Automaton (NFA) [60] : Th´eorie plus g´en´erale selon laquelle les ´etats sont beaucoup plus ouverts, on peut effectuer une ou plusieurs transitions `a chaque lecture, voire mˆeme sans lire de caract`ere. De plus, plusieurs transitions peuvent ˆetre activ´ees simultan´ement `a la sortie d’un ´etat et plusieurs petites machines peuvent ˆetre ex´ecut´ees simultan´ement.
L’impl´ementation des automates a ´et´e tr`es largement ´etudi´ee par la suite. Aho et Corasick ont propos´e un arbre de caract`eres [2] qui est devenu l’approche classique car tr`es simple et efficace. Chaque ´etat repr´esente un caract`ere des motifs recherch´es, mutualisant les pr´efixes identiques pour r´eduire le nombre de branches. La figure 2.5 pr´esente ce principe. Plusieurs
´
evolutions se sont bas´ees sur ces travaux pour ajouter certaines propri´et´es sp´ecifiques. On citera par exemple des impl´ementations comme celle de Liu et al. [44], autorisant des re-cherches `a tr`es haute vitesse sur GPU (de l’ordre de 80 `a 100 Gb/s) en divisant le texte ´
etudi´e en segments de la longueur maximale d’un motif, tout en optimisant la machine `a ´
etats et l’algorithme pour les sp´ecificit´es des processeurs graphiques.
Les expressions r´eguli`eres permettent de limiter le stockage n´ecessaire tout en offrant des recherches beaucoup plus g´en´erales puisque l’on remplace la multitude d’´el´ements recher-ch´es par un mod`ele unique. On simplifie alors la maintenance mais on ajoute un processus n´ecessaire de v´erification pour s’assurer de l’exhaustivit´e du mod`ele.
Le traitement par machine `a ´etats requiert que les mod`eles soient assez courts et peu nombreux (quelques milliers de mod`eles d’une centaine de caract`eres), sans quoi les calculs pour r´esoudre ces machines `a ´etats deviennent tr`es complexes, longs, voire impossibles. De plus, d`es lors que les patterns utilis´es sont de petite taille pour ˆetre efficaces, il est difficile de les adapter `a la d´etection de fichiers plus volumineux tels que des rapports ou des images. Reconnaissance approximative
Il existe un grand nombre de m´ethodes pour comparer des chaˆınes de caract`eres et d´ etec-ter les ressemblances en autorisant un certain nombre d’erreurs, qu’on appelle “Approximate String Matching”. Elles sont tr`es utilis´ees pour d´etecter les fautes d’orthographe ou pour re-chercher des fragments d’ADN avec la possibilit´e d’une mutation. L’id´ee est de calculer le nombre de diff´erences entre deux chaˆınes de caract`eres (modification, suppression ou ajout d’un caract`ere). On compare ainsi un mod`ele avec tous les originaux puis on compare les r´esultats pour trouver les plus proches.
De nombreux algorithmes impl´ementant des distances diff´erentes ont ´et´e propos´es. Une revue tr`es compl`ete a ´et´e publi´ee par Navarro [52], retra¸cant plus en d´etail les possibilit´es offertes dans ce domaine. Cette approche est aussi souvent utilis´ee pour de la recherche de plagiat ou de la copie illicite de documents [18].
Stockage de chaˆınes de caract`eres
Rechercher des chaˆınes de caract`eres, ou des mod`eles de chaˆınes demande de stocker ces mod`eles, qui sont des chaˆınes de caract`eres dont la longueur est ind´etermin´ee. Leur stockage peut donc poser plusieurs probl`emes. Tout d’abord, rechercher un document reviendrait `a stocker la quasi-totalit´e de ce document dans une nouvelle base de donn´ees, ce qui peut rapidement demander un espace de stockage gigantesque lorsque le nombre de documents `a rep´erer devient important. Il faut alors utiliser des stockages de plus grande taille (disques
durs, espaces de stockage en r´eseau, etc.) qui sont souvent beaucoup plus lents. Les perfor-mances du syst`eme complet sont alors rapidement limit´ees par la faible bande passante et surtout les latences importantes des acc`es `a la m´emoire.
D’autre part, stocker des donn´ees h´et´erog`enes m`ene souvent `a des impl´ementations de bases de donn´ees moins efficaces. Les op´erateurs de comparaison par exemple, doivent connaˆıtre la taille de la plus grande valeur stock´ee afin de comparer les autres sur la mˆeme base, qui revient `a effectuer des comparaisons sur des donn´ees de tr`es grande taille, ra-lentissant ainsi leur fonctionnement. On pr´ef`ere souvent indexer des donn´ees de taille fixe, id´ealement assez limit´ee, pour que les processeurs puissent les traiter efficacement.
La sensibilit´e des documents `a stocker est elle-aussi un point important. `A partir du moment o`u des donn´ees sensibles (interdites ou confidentielles par exemple) sont regroup´ees, il convient de les entourer de beaucoup plus de s´ecurit´e contre les vols ou les acc`es non autoris´es. La constitution de telles bases de donn´ees peut mˆeme ˆetre interdite dans certains cas.
L’utilisation directe des chaˆınes de caract`eres constitue donc un inconv´enient et une limitation majeure. Il apparaˆıt d`es lors plus int´eressant d’utiliser des repr´esentations illisibles des donn´ees, cod´ees et ne pouvant ˆetre d´ecod´ees.
2.2.2 M´ethodes de Hachage
Pour acc´el´erer les comparaisons de documents et simplifier la base de donn´ees de r´ef´ e-rence, on utilise souvent des signatures (“hashes”), aussi appel´ees empreintes ou cl´es, qui sont calcul´ees `a partir du contenu du fichier ou de l’ensemble de donn´ees trait´e. Dans la majorit´e des cas, on cr´ee une signature de taille fixe, quelle que soit la taille des donn´ees sources. La principale propri´et´e recherch´ee est l’injectivit´e : si deux empreintes sont identiques alors la source qu’ils repr´esentent doit ˆetre la mˆeme. Ceci n’est vrai qu’avec une certaine probabilit´e ´
etant donn´e le nombre fini de valeurs diff´erentes de taille fixe. Par exemple, la probabilit´e que deux mots al´eatoires cod´es sur 64 bits soient identiques est 2−64. Malgr´e tout, la grande majorit´e des applications utilisant le hachage se base sur cette propri´et´e, avec des signatures de plus grande taille pour limiter la probabilit´e de collision, c’est-`a-dire que deux sources diff´erentes soient repr´esent´ees par la mˆeme signature.
On l’a vu, sauvegarder des signatures `a la place des donn´ees d’origine pr´esente plusieurs int´erˆets. Cela permet tout d’abord de ne pas travailler avec du contenu potentiellement confidentiel et/ou priv´e mais avec des repr´esentations plus ou moins d´echiffrables de ce contenu. Ensuite, cette approche rend les traitements beaucoup plus efficaces car le type des donn´ees est connu et uniforme. On peut par exemple d´efinir les signatures comme des entiers positifs cod´es sur 128 bits et ainsi optimiser la recherche et l’indexation pour ce type
de donn´ees. Finalement, le stockage est l`a encore facilit´e car tous les ´el´ements sont d’une taille fixe (ou au moins connue et born´ee), ce qui permet une meilleure utilisation de l’espace m´emoire, pour finalement r´ef´erencer un nombre quasi-illimit´e de documents.
Le domaine judiciaire, auquel peut s’apparenter notre syst`eme, utilise largement le ha-chage pour les recherches de preuves parmi de grandes quantit´es de donn´ees ou l’analyse en temps r´eel de communications pour pr´evenir les menaces. Roussev a beaucoup travaill´e sur ce type d’application dans ses articles [63, 64, 65]. L’auteur cite notamment des enquˆetes impliquant d’immenses quantit´es de donn´ees `a analyser, comme une saisie de 60 To de do-cuments `a propos de la guerre en Irak [61]. Calculer les signatures de fichiers permet d’en ´
ecarter rapidement les plus communs, tels que les fichiers des syst`emes d’exploitation ou de programmes r´epandus. Le NIST (National Institute of Standards and Technology) [51] maintient pour cela une base de donn´ees qui contient les signatures de tels fichiers. Les en-quˆeteurs peuvent la consulter afin de trier rapidement le contenu de disques durs saisis et de concentrer leurs recherches sur les fichiers les plus int´eressants.
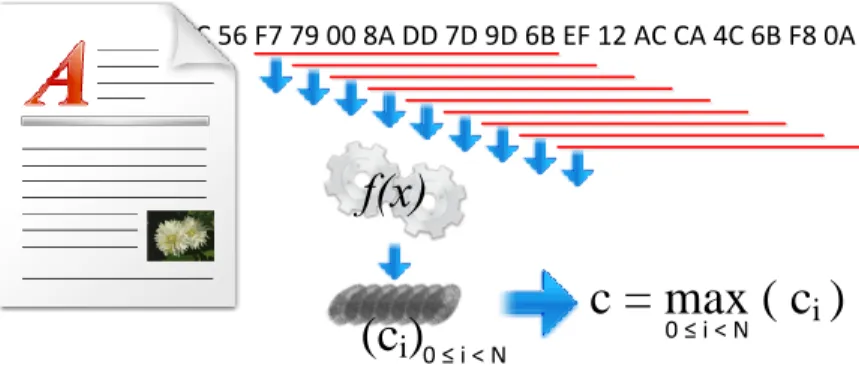
M´ethode de base
La m´ethode de base, telle qu’on l’utilise dans les exemples pr´ec´edents, consiste `a calculer les signatures de chacun des documents recherch´es, puis celles des documents analys´es et de les comparer. La figure 2.6 r´esume le principe. Lorsque les signatures sont identiques, on peut affirmer que les documents sont les mˆemes selon la probabilit´e expos´ee dans le paragraphe pr´ec´edent. Ce principe est souvent utilis´e sur Internet pour t´el´echarger de gros fichiers, avec lesquels on fournit la signature afin que l’utilisateur puisse v´erifier que son fichier n’a pas ´et´e corrompu lors du transfert. Les algorithmes les plus utilis´es sont Message Digest #5 (MD5) et Secure Hash Algorithm (SHA1).
Une premi`ere limitation intervient dans le traitement des documents : la moindre modifi-cation implique une valeur de signature diff´erente. Si cette propri´et´e est utilis´ee pour v´erifier
1B86EAAFE6789BA40E
5F6CCFFF89C0021BDE
f(x)
BC45D878FF07C31A
M´ethode de base : on calcule une empreinte par fichier, `a partir de l’ensemble du fichier.
l’int´egrit´e d’un ensemble de donn´ees, elle devient une contrainte lorsque l’on veut comparer des documents proches, ou l´eg`erement corrompus. Des changements seront invisibles pour l’utilisateur, par exemple un octet ajout´e `a la fin du fichier, mais sa signature sera diff´erente et il ne pourra donc pas ˆetre rep´er´e. Plus important pour notre ´etude, on ne peut pas re-trouver des fragments de documents avec cette approche mais uniquement les documents complets. Or, comme on l’a annonc´e au chapitre pr´ec´edent, nous devons travailler sur les paquets r´eseaux, qui sont pr´ecis´ement des fragments de ces documents. Il n’est pas possible de reconstituer les originaux envoy´es et nous devons donc raffiner cette m´ethode.
Fragmentation
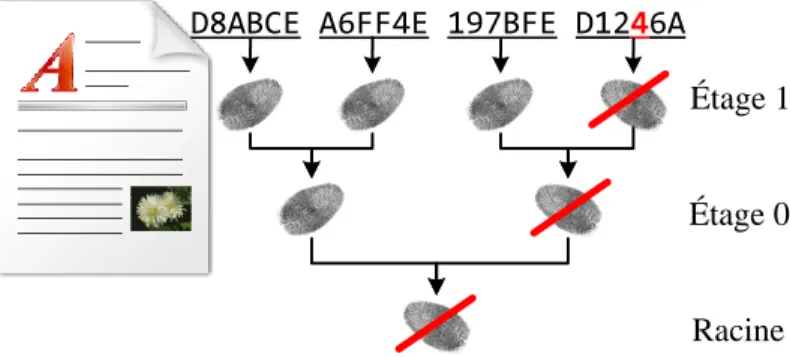
Une premi`ere r´eponse au probl`eme de fragmentation des donn´ees a ´et´e propos´ee par Merkle [49] avec son “hash tree” aussi appel´e “arbre de Merkle”. Le principe consiste `a diviser la source en plusieurs blocs de taille constante avant de calculer l’empreinte de chacun de ces blocs. On cr´ee ensuite plusieurs ´etage en calculant `a chaque fois une nouvelle empreinte `a partir de pairs de l’´etage pr´ec´edent. On divise ainsi par deux le nombre de valeurs de chaque ´
etage jusqu’`a arriver `a la racine de l’arbre.
Cette m´ethode permet de v´erifier l’int´egrit´e de documents de mani`ere efficace. En effet, lorsqu’une partie du document est alt´er´ee, seule la signature correspondant au bloc concern´e est modifi´ee, ainsi que toutes les cl´es des ´etages sup´erieurs qui m`enent `a celle-ci. On n’a alors plus qu’`a redescendre l’arbre depuis la racine vers les feuilles pour trouver le bloc mis en cause, ce qui r´eduit le nombre de comparaisons n´ecessaires. Cette m´ethode est utilis´ee pour transf´erer des ensembles importants de donn´ees, pour n’avoir qu’`a renvoyer la partie alt´er´ee au lieu de l’ensemble de la source. La figure 2.7 illustre le principe.
D8ABCE A6FF4E 197BFE D1246A
Racine Étage 0 Étage 1
On divise cette fois le fichier en blocs de taille fixe et on calcule ensuite une signature pour chacun d’eux, puis on cr´ee un arbre de signatures. Une erreur est facilement rep´erable dans la source, il suffit de remonter
l’arbre.
Pourtant, cette m´ethode ne peut s’appliquer facilement aux paquets transmis sur un r´eseau du fait de la taille variable de ceux-ci et de la division impr´evisible lors de la cr´ ea-tion des paquets. On ne peut pr´evoir ni le fractionnement ni la configuration des blocs qui seront transmis. Il paraˆıt impossible de sp´ecifier une taille fixe qui garantirait que ces blocs soient transmis align´es correctement dans les paquets sur le r´eseau. Il faut donc trouver une m´ethode plus pr´ecise, qui ne se contentera pas de diviser un document en blocs fixes. Contexte
Dans la m´ethode pr´ec´edente, la moindre suppression ou insertion de donn´ees dans un fichier modifie tous les blocs subs´equents ainsi que toutes les signatures correspondantes. Par exemple, si un octet est ins´er´e au d´ebut d’un document, toutes les signatures le caract´erisant seront modifi´ees car le contenu de chaque bloc sera d´ecal´e. Le document modifi´e sera donc consid´er´e comme un document enti`erement nouveau, sans aucun lien avec l’original. La mˆeme id´ee s’applique pour les paquets Internet, puisqu’il s’agit de travailler sur un extrait quelconque (en taille et emplacement) du document, les blocs n’ont que tr`es peu de chances de se trouver plac´es correctement dans des paquets Internet pour ˆetre d´etect´es.
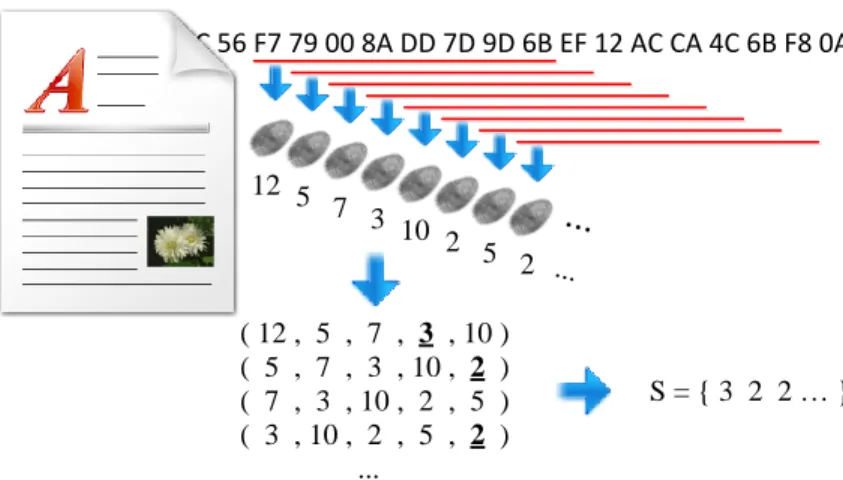
Les premiers `a avoir propos´e une solution `a ces d´efis sont Hunt et McIlroy [29], qui ´ etu-diaient les textes par ligne, en recherchant la plus longue suite de correspondances. Tridgell a pr´esent´e en 2002 un logiciel appel´e “SpamSum” [71] permettant de d´etecter les spams, textes g´en´eralement semblables les uns aux autres sans ˆetre r´eellement identiques. Sa m´ e-thode, proche du travail de Rabin [59], consiste `a calculer des signatures ne d´ependant que d’une petite fenˆetre de calcul glissant sur l’ensemble des donn´ees. Cette id´ee sera reprise dans le domaine de la s´ecurit´e par Kornblum qui la baptisera “Context-Triggered Piecewise Hashing (CTPH)” [42], puis am´elior´ee par Long et Guoyin en 2008.
Cette m´ethode d´eveloppe la pr´ec´edente : le document est divis´e en blocs et les signatures sont calcul´ees sur ces blocs uniquement. Ici les blocs sont beaucoup plus petits, on parle plutˆot de contextes ou de fenˆetres. Leur taille n’est pas constante et toutes les fenˆetres ne donnent pas n´ecessairement lieu au calcul d’une signature. Tout revient `a d´eterminer l’em-placement de ces fenˆetres dans un ensemble de donn´ees, puis `a d´eterminer quelles signatures seront conserv´ees, `a l’aide de propri´et´es et param`etres facilement r´eutilisables et applicables partout. Un premier exemple simple consisterait `a garder l’id´ee de blocs de taille fixe, mais de tr`es petite taille, en ne conservant que les signatures v´erifiant une propri´et´e donn´ee (par exemple un r´esultat modulo un param`etre). De mani`ere plus ´elabor´ee et en illustrant l’id´ee de blocs de taille ne pouvant ˆetre pr´ed´etermin´ee, on pourrait d´ecider de calculer une signature par phrase dans un texte. Ce principe est illustr´e sur la figure 2.8.