A 10 000 fps CMOS Sensor With Massively Parallel Image Processing
Texte intégral
Figure
![Fig. 14. Schematic of the [AM] structure.](https://thumb-eu.123doks.com/thumbv2/123doknet/13434815.409149/8.891.476.807.92.471/fig-schematic-of-the-am-structure.webp)


Documents relatifs
Based on the HA substitution rate in the SO farm (subline- age B), it would have taken a minimum of 18 weeks for the south-west Nigerian strains (sublineages A and B) to evolve from
Pour réduire l'affichage d'une image - cliquer sur l'icône zoom arrière dans la barre d'outils.. - cliquer sur le menu [Affichage >
-Teneurs sériques moyennes en créatinine chez les patients atteints l’IRC et diabétiques avant et après de traités par hémodialyse (HD). Les valeurs moyennes de la créatinine
Avec ses 8000 membres répartis dans trente-neuf cercles fribourgeois disséminés dans notre pays - pour la plus grande partie en Suisse romande - il était dif¬. ficile pour
Glycosyl hydrolase family 1 Amino acid tRNA synthetase class I E and Q Homologous to ATPase AAA family Unknown function PPR repeats Homologous to calcineurin B Homologous
Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of
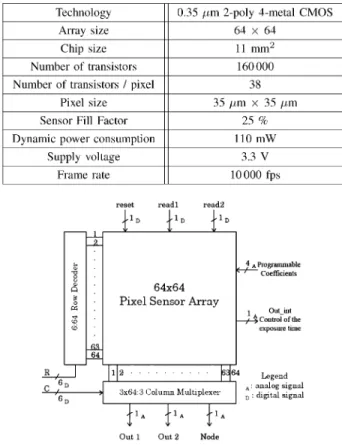
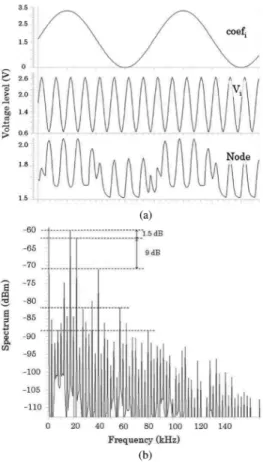
Half of the conversion time (200 ns) is used to perform the auto- zero operation. The other half is dedicated to the comparison. The working frequency of the counter is thus 2.4
Further works will concern on the one hand the generalization of electronic front propagation ma- nipulation (how to determine B is the key point) in order to expand the field
