DANIEL L AFONO
ABSTRACTION DE RÈGLES ET SIMILARITÉ RELATIVE DANS L’APPRENTISSAGE DE CATÉGORIES
Mémoire présenté
à la Faculté des études supérieures de !’Université Laval
pour l’obtention
du grade de maître ès arts (M.A.)
École de psychologie
FACULTÉ DES SCIENCES SOCIALES UNIVERSITÉ LAVAL
NOVEMBRE 2002
RÉSUMÉ
La présente recherche étudie l’apprentissage et la généralisation dans une tâche de catégorisation de stimuli visuels multidimensionnels. Il s’agit de vérifier si les patrons de classification identifiés pour chaque participant et la reconnaissance des stimuli peuvent être expliqués par l’emploi de règles et la mémorisation d’exceptions. Une méthode formelle de minimisation booléenne a permis d’effectuer la synthèse des différents types de représentation des catégories selon le nombre de classifications correctes observé. Trois types de représentation obtenus correspondent à !’utilisation d’une règle
unidimensionnelle, accompagnée d’aucune, d’une ou de deux exceptions apprises. L’analyse de la reconnaissance des stimuli, de !’apprentissage des exceptions et de la généralisation à de nouveau stimuli, suggèrent que !’apprentissage d’une exception peut reposer sur la formulation d’une nouvelle règle sans faire appel à un processus de mémorisation permettant !’identification d’un stimulus en particulier.
Daniel Lafond Yves Lacouture, Ph.D.
AVANT-PROPOS
À mon directeur de recherche, Yves Lacouture, j’aimerais faire part de ma
profonde reconnaissance pour la confiance et la liberté de création qu’il m’a accordé dans cette entreprise. Ta bienveillance m’a donné courage. Tes critiques et suggestions ont grandement contribué à donner forme et cohérence à cette recherche, mais aussi à mon attitude de chercheur. Je crois que tu as su comprendre ce dont j’ai besoin pour me permettre de vivre ce cheminement dans la plus grande joie possible.
À Claude Lamontagne, je tiens à faire part que ce que j’entreprend depuis quelques années tient avant tout du profond impact que m’ont laissé nos échanges. J’attends le grand plaisir de bénéficier à nouveau de ta résistance.
À mes parents et Nadine, merci de votre présence et de votre soutien, je ne me suis pas senti si loin que ça finalement. Vous me faites tellement de bien. Mon bonheur commence par vous trois. À mes amis, de Québec ainsi que de l’Outaouais, c’est bien grâce à la sincérité de votre amitié que j’ai si souvent le sourire accroché aux lèvres et queje rebondit un peu quand je marche. François, parmi tout ce qu’il y a de nouveau dans ma vie à Québec, tu es devenu très rapidement ce qu’il y a de plus précieux pour moi. Tu as un cœur d’or qui commande l’admiration. Geneviève G., parmi tant de choses, tu sais toujours me donner une énergie toute particulière, qui me ramène au présent et me permet d’apprécier celui-ci comme il se doit. Votre amitié m’est très chère et si j’ai peu manifesté le besoin de soutient ou de réconfort ces dernières années, c’est parce que j’en étais comblé d’avance grâce à vous. Eve, je te chéris de tout mon cœur. Jamais je n’ai éprouvé un amour aussi simple et vrai qu’avec toi. Ce queje ressens lorsque je suis avec toi me suit maintenant partout.
TABLE DES MATIÈRES
RÉSUMÉ... 1
AVANT-PROPOS... 2
TABLE DES MATIÈRES...3
LISTE DES TABLEAUX...5
LISTE DES FIGURES... 6
INTRODUCTION GÉNÉRALE... 7
La catégorisation... 8
- Stimulus intégral versus dimensions séparables...12
- L’attention sélective...12
- Les modèles d’exemplaires... 13
- Formalisation du modèle contextuel...14
- Critique du modèle contextuel... 16
- Règles et exceptions...19
- La complexité d’un concept... 20
- Critique de l’étude de Feldman... 23
- Les réseaux de neurones... 25
Objectifs... 27
Plan d’expérience et hypothèses...28
EXPÉRIENCE ... 30 Les règles...32 Méthode...33 - Participants... 33 - Stimuli... 33 - Matériel... 36 - Procédure... 36
Résultats et discussion... 37
- Analyse des patrons de classification... 38
- Niveau 8/10...38
- Niveau 9/10...39
- Niveau 10/10... 40
- Analyses sur la mesure de reconnaissance...42
CONCLUSION...43 LISTE DE RÉFÉRENCES... 47 ANNEXE A...63 ANNEXES... 65 ANNEXE C...67 ANNEXED...81 ANNEXEE... :... 87
LISTE DES TABLEAUX
Structure théorique des catégories dans l’Expérience 3 de Medin et Schaffer (1978 ) et dans l’étude de Medin et Smith (1981).
Résultats de l’expérience de Medin et Smith (1981) : Probabilité de classification correcte pour différents stimuli selon les consignes.
Description en algèbre booléenne des six types de tâches de catégorisation à trois caractéristiques et quatre exemples positifs étudiés par Shepard et al.(1961).
Type du stimulus selon la règle inférée (paires d’erreurs attendues).
Structure des catégories (selon !’Arrangement 1) et paires d’exceptions.
Liste des huit arrangements de l’ensemble stimulus dans !’expérience.
Formule booléenne minimale extraite pour chaque participant pour les trois différents niveaux de classifications correctes.
Tableau 1. Tableau 2. Tableau 3. Tableau 4. Tableau 5. Tableau 6. Tableau 7.
LISTE DES FIGURES
Les six types de classifications de l’étude de Shepard et al. (1961).
Illustration simplifiée des dix stimuli d’entraînement.
Figure 1.
Figure 2.
Stimuli présentés dans l’expérience selon !’Arrangement 1.
INTRODUCTION GÉNÉRALE
L’étude de !’apprentissage de catégories était à ses débuts dominée par des modèles simples de formation de règles et de tests d’hypothèses (Bruner, Goodnow & Austin, 1956; Hunt, Marin & Stone, 1966; Levine, 1975; Neisser & Weene, 1962; Restle, 1962; Trabasso & Bower, 1968). Influencé par les travaux de Posner et Keele (1968) et Rosch (1973), l’intérêt s’est tourné vers des tâches aux catégories « mal-définies » (en anglais « ill-defined »), où les frontières déterminant l’appartenance aux différentes classes sont floues. Dans ces tâches, il n’y a pas de règles simples permettant d’accomplir la classification. Ce changement de paradigme expérimental a contribué au
développement de nouveaux modèles, tels que les modèles d’exemplaires (Medin & Schaffer 1978), les modèles de prototypes (Reed, 1972), les modèles baysiens (J. R. Anderson, 1991) et les modèles connexionnistes (Knapp & J. A. Anderson, 1984) où les hypothèses de formation de règles logiques ont été remplacées par des processus
décisionnels qui dépendent de la similarité des stimuli et de la réponse à laquelle ils sont associés. Toutefois, dans plusieurs recherches récentes, la notion de règle reprend à nouveau de l’intérêt (e.g. Hahn & Chater, 1998; Smith, Palatano & Jonides, 1998; Sloman & Rips, 1998), souvent en opposition, parfois en complément, aux processus basés sur la similarité.
La présente étude vise à faire un rapprochement entre d’une part, l’emploi d’une stratégie de catégorisation reposant sur !’utilisation de règles et de mémorisation des exceptions, et d’autre part, la capacité d’une méthode algébrique de minimisation booléenne à décrire cette représentation formellement, et ce à partir de l’ensemble des classifications effectuées au niveau de chaque individu.
ABSTRACTION DE RÈGLES ET SIMILARITÉ RELATIVE DANS L’APPRENTISSAGE DE CATÉGORIES
La catégorisation
La catégorisation est une tâche qui consiste à assigner l’appartenance d’un
stimulus à un groupe, appelé une catégorie ou un concept. Plusieurs stimuli sont associés à une même réponse par opposition au cas particulier de !’identification où il n’y a qu’une seule réponse associée à chaque stimulus. Autre cas particulier, la discrimination, est un problème de catégorisation ne comprenant que deux catégories. Parmi les
différentes conceptualisations théoriques des processus de catégorisation, soulignons deux stratégies permettant de réaliser la tâche. Une première conceptualisation théorique propose que les processus de catégorisation s’effectuent sur la base d’un calcul de la similarité entre, d’une part, le stimulus à catégoriser et, d’autre part, les stimuli associés à chaque réponse, appelés exemplaires (Kruschke, 1992; Medin & Schaffer, 1978;
Nosofsky, 1986). L’autre conceptualisation théorique propose que les processus de catégorisation reposent sur !’utilisation de règles logiques (Martin & Caramazza, 1980; Nosofsky, Clark & Shin, 1989; Pavel, Gluck & Henkle, 1988; Ward & Scott, 1987).
Dans une étude classique de !’apprentissage de catégories, Shepard, Hovland et Jenkins (1961) ont tenté de déterminer si les erreurs dans une tâche de catégorisation dépendent des relations de similarité entre les exemplaires, et si les réponses erronées peuvent être prédites comme dans une tâche d’identification selon le « principe de généralisation du stimulus » (Shepard, 1958b). Ce principe suggère que les erreurs d’identification reposent sur une « confusion » entre deux stimuli. La probabilité d’occurrence d’une « confusion » dépendrait du degré de similarité entre deux stimuli, c’est-à-dire de leur distance dans un espace des représentations psychologiques.
Shepard, Hovland et Jenkins ont examiné si ce principe s’appliquait au processus de catégorisation. Pour ce faire, ils ont effectué l’examen empirique du niveau de
deux catégories de quatre stimuli. De plus ils ont utilisé une tâche qui requérait !’identification de ces huit stimuli pour être réussie. L’ensemble des arrangements possibles de huit stimuli en deux catégories de même taille permettait de générer 70 problèmes de catégorisation différents. Ces auteurs ont utilisé un dispositif expérimental où les participants devaient apprendre à catégoriser les huit stimuli durant une série d’essais où chaque stimulus était présenté à deux reprises dans un ordre aléatoire. Les stimuli variaient selon trois caractéristiques binaires (forme, grandeur, couleur), et constituaient, par exemple, un « petit cercle blanc » ou un « grand carré noir ». L’ensemble stimulus regroupait toutes les combinaisons possibles à partir de ces
caractéristiques (23 = 8). La réponse correcte (Catégorie A ou Catégorie B) était indiquée aux participants après chaque essai. Cette procédure se poursuivait jusqu’à l’atteinte d’un critère de 32 réponses correctes consécutives. Dans cette expérience, la difficulté d’un problème de classification particulier était déterminée par le nombre moyen d’essais requis avant l’atteinte du critère. La variable indépendante dans cette étude était !’assignation des stimuli aux différentes catégories, autrement dit la structure du problème. Cette variable était constituée de six niveaux, correspondant à six types de problèmes identifiés Types là VL
Les 70 différents problèmes de classification pouvaient être réduits à six
structures distinctes formellement exprimées par six propositions de logique booléenne. Les problèmes de classification regroupés en un même « type » étaient dits isomorphes et possédaient une même « structure », dans le sens où la seule différence entre eux était !’assignation particulière des trois caractéristiques (forme, grandeur, couleur). La « structure » de ces problèmes de catégorisation pouvait également être représentée par un cube où chacun des trois axes représentait une caractéristique. Les huit sommets du cube représentaient ainsi les huit stimuli. Les stimuli assignés à la Catégorie A étaient représentés par des points blancs tandis que ceux assignés à la Catégorie B étaient représentés par des points noirs. Les problèmes de catégorisation d’un même type correspondaient à des rotations ou réflexions d’un même cube. Autrement dit, il ne s’agissait que d’échanges dans !’assignation des trois caractéristiques aux trois axes du cube.
Le principal résultat de cette étude est que la difficulté d’un problème de
catégorisation varie systématiquement en fonction du type de problème de catégorisation. Selon le « principe fort » de généralisation du stimulus, le taux de confusions obtenu pour les huit stimuli dans la tâche d’identification permettrait de prédire le taux d’erreurs dans un problème de catégorisation constitué de ces huit stimuli (en prenant en compte que les confusions entre deux stimuli d’une même catégorie résultent en une réponse correcte). Cette tentative d’expliquer la difficulté relative des six types de problèmes de
catégorisation a échoué. Le « principe faible » de la généralisation du stimulus suggère qu’au lieu d’être fixe, le « gradient de généralisation » changerait systématiquement lors de la conversion d’un problème d’identification en un problème de catégorisation. Un gradient de généralisation détermine l’occurrence des confusions entre deux stimuli selon le nombre de caractéristiques que ceux-ci ont en commun. Les auteurs ont noté qu’aucun gradient de généralisation ne permettrait d’expliquer la difficulté relative obtenue pour les six types de problèmes de catégorisation.
À l’examen des résultats, ces chercheurs interprètent l’incapacité de l’approche basée sur la similarité des exemplaires à expliquer la difficulté relative des six types de problèmes de catégorisation par !’intervention d’un processus d’attention sélective qu’on ne retrouvait pas dans une tâche d’identification. Les résultats de cette recherche
suggèrent aussi une forte corrélation entre la difficulté à résoudre un problème de classification et la simplicité des règles verbales que les participants peuvent formuler pour décrire ce problème de classification. Ces règles varient selon le nombre de caractéristiques binaires à considérer et conséquemment la longueur de la règle qui définit les classes. Cependant, aucune définition plus précise de la complexité d’une règle ne fut proposée. Shepard et al. (1961) proposent qu’un mécanisme d’attention sélective et qu’un processus de formulation de règles soient impliqués dans le processus de
catégorisation.
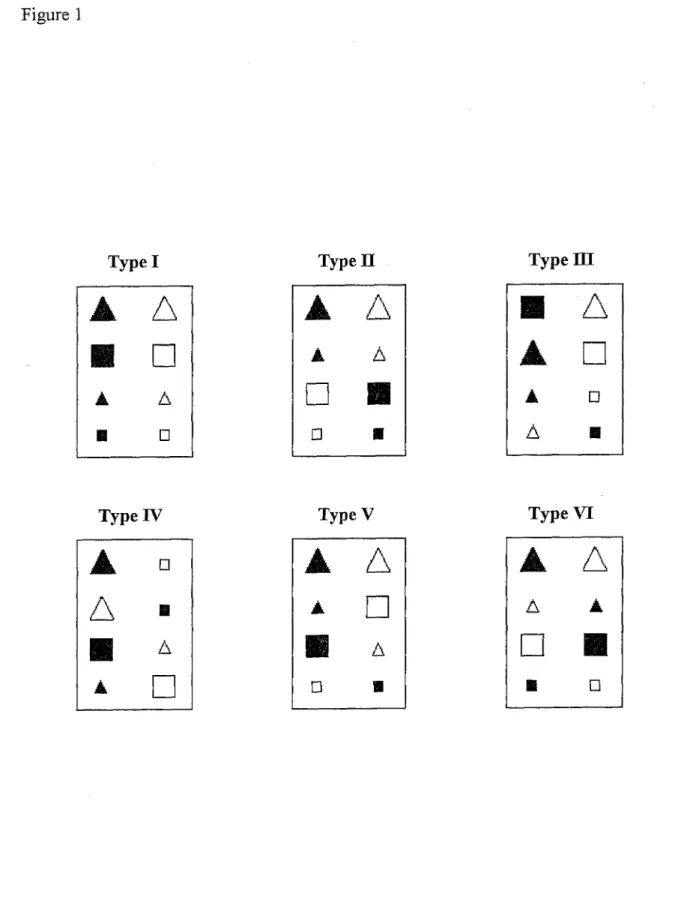
Les résultats de cette étude, reproduits par Nosofsky, Gluck, Palmeri, McKinley et Glauthier (1994), imposent des contraintes importantes pour la formulation de modèles des processus de catégorisation. La Figure 1 présente un exemple de chacun des six types
de problèmes de catégorisation proposés par Shepard, Ho viand et Jenkins. Dans chaque boîte de cette figure, les quatre éléments de gauche appartiennent à la première catégorie (A) et les quatre de droite à la seconde (B). Chaque élément correspond à un stimulus présenté aux participants sous forme d’une photographie projetée sur un écran (la réponse correcte était donnée verbalement). Dans l’ordre, les six types de problèmes de
classifications vont en difficulté croissante : I < II < (III, IV et V) < VI. Selon une stratégie par formulation de règles, la réussite d’un problème de Type I nécessite de prendre en compte une seule caractéristique distinctive (règle unidimensionnelle). Un problème de Type II requiert de prendre en compte deux dimensions, la réussite reposant sur une règle constituée d’une disjonction de deux conjonctions, par exemple
« triangulaire et noir OU carré et blanc ». Les problèmes de Type III à V exigent de considérer trois caractéristiques; il s’agit de catégories « mal-définies » requérant une règle unidimensionnelle ainsi que la mémorisation des exceptions. Une catégorie « mal- définie » signifie qu’il n’y a pas de caractéristique distinctive (voir le Type I), ni une combinaison quelconque de caractéristiques (voir le Type Π), permettant de définir l’appartenance à cette catégorie. Lorsque l’énumération complète des caractéristiques d’un stimulus est nécessaire, il semble plus juste de parler de la mémorisation (ou de !’identification) d’une exception. Finalement, le problème de Type VI requiert que le participant puisse identifier individuellement tous les stimuli appartenant à l’une des catégories.
D’intérêt particulier pour le présent projet de recherche est le fait que les problèmes de types III, IV et V présentent le même niveau de difficulté. Malgré le fait que les six types de problèmes de catégorisation correspondent à des règles d’algèbre booléenne différentes, les types III, IV et V sont de même « complexité ». Qu’ont-ils en commun? La résolution de ces problèmes repose sur une règle unidimensionnelle simple du type « les stimuli noirs vont dans la Catégorie A et les blancs vont dans B » et
seulement deux stimuli formant les exceptions, un pour chaque catégorie, nécessitent d’être identifiés ou « mémorisés » afin de réaliser la tâche sans erreur (voir Figure 1). Cette constatation nous portera à se demander qu’est-ce que la complexité d’une règle et comment conceptualiser la distinction entre une « règle » et une « exception ».
Stimulus intégral versus dimensions séparables
Dans l’étude de Shepard et al. (1961), les stimuli étaient constitués de dimensions dites analysables dans le sens qu’il était relativement facile de comparer les stimuli sur la base de leurs caractéristiques. Dans une autre étude, Shepard & Chang (1963) ont utilisé des stimuli aux dimensions plus difficilement analysables. Ces auteurs voulaient ainsi éliminer ou contrôler les processus d’attention sélective de sorte que la difficulté relative des différents problèmes de catégorisation pourrait être déterminée par les seules erreurs d’identification. Les résultats indiquent que la difficulté relative des différents problèmes de catégorisation peut assez bien être prédite par les relations de similarité entre les stimuli. De plus Shepard (1964), démontre que lorsque les stimuli sont facilement
analysables, les relations de similarité inter-items changent systématiquement en fonction de déplacements de !’attention (« shifts of attention ») d’une dimension à une autre.
Les tâches utilisées dans l’étude expérimentale des processus de catégorisation varient selon que les stimuli sont constitués de dimensions psycho logiquement distinctes appelées « séparable » ou encore perçus comme des entités relativement peu analysables, formant des stimuli « intégraux » (Garner, 1974). La désignation « stimulus intégral » impliquerait un processus de traitement où !’attention est portée sur le stimulus entier. L’utilisation de stimuli intégraux semble favoriser un traitement basé sur la similarité globale, appelé traitement « holistique ». L’emploi de stimuli aux dimensions
« séparables psychologiquement » favoriserait davantage un traitement analytique, et les stimuli seraient comparés et contrastés selon leurs caractéristiques ou éléments
constitutifs (Ward & Scott, 1987).
L’attention sélective
Selon Shepard et al. (1961), )’attention sélective est un processus d’abstraction des dimensions pertinentes utilisées dans le processus de catégorisation, qui permet de formuler et de tester des règles précisant comment se combinent et interagissent les valeurs des différentes dimensions dans le choix d’une réponse. Suite aux études de
Shepard et al. (1961, 1964), d’autres chercheurs ont aussi soulevé l’importance des processus d’attention sélective dans l’étude de la catégorisation, sans, toutefois, lier !’attention sélective à la formulation de règles (Garner, 1974; Medin & Schaffer, 1978; Nosofsky, 1986; Reed, 1972; Tversky, 1977). Selon McKinley & Nosofsky (1996), )’attention peut être conceptualisée comme l’importance « pondérée » donnée aux différentes caractéristiques d’un stimulus dans le choix d’une classe. Le « poids » relatif associé à chaque dimension relèverait d’un processus décisionnel plutôt que perceptif. L’attention sélective se développerait par apprentissage quand les catégories associées à
des exemplaires sont progressivement connues ou apprises. Le rôle de !’attention sélective serait de modifier les relations de similarité inter-item dans le processus de catégorisation de façon à « rapprocher » davantage les stimuli appartenant à une même catégorie en accordant plus d’importance à ce qu’ils ont en commun et à accroître la « distance » entre les stimuli de différentes catégories, en réduisant l’importance de ce qu’ils ont en commun (Nosofsky, 1987).
Les modèles d’exemplaires
Différents modèles d’exemplaires ont reproduit avec succès certains phénomènes comportementaux observés dans les tâches perceptives. Le principe fondamental de ces modèles est que le rappel et la généralisation pour un stimulus donné reposent sur une comparaison de la similarité de ce stimulus à l’ensemble des exemplaires (les stimuli déjà présentés) de chaque catégorie. Selon la théorie contextuelle de !’apprentissage de
classifications (Medin et Schaffer, 1978), un calcul de la « similarité relative » permet d’expliquer la difficulté à classifier correctement différents items. Cette approche, basée sur la mémorisation d’exemplaires, suggère que la difficulté à catégoriser un item est fonction de sa similarité avec l’ensemble des exemplaires mémorisés, et ceci que l’item soit déjà connu ou pas. Ce modèle de similarité repose sur un calcul multiplicatif ou interactif des caractéristiques binaires (ou dichotomiques) composant les stimuli. Ce principe est en opposition aux modèles additifs ou indépendants comme ceux utilisant un prototype (Franks & Bransford, 1971; Reed, 1972). Le GCM (generalized context
relative appliqué aux problèmes de catégorisation de stimuli présentant des dimensions (ou caractéristiques) continues plutôt que dichotomiques.
ALCOVE (attention learning covering map) développé par Kruschke (1992) ainsi que ATRIUM (attention to rules and instances in a unified model), par Erickson et Kruschke (1998), sont des modèles connexionnistes fondés principalement sur la méthode de comparaison d’exemplaires qui incorpore des paramètres d’attention sélective. En ajoutant au module ALCOVE des modules de règles unidimensionnelles, ATRIUM tente de combiner les deux stratégies d’apprentissage de catégories. Pour le moment, aucun processus d’acquisition de règles n’y est modélisé. Les modèles
connexionnistes de Kruschke reposent sur le calcul de similarité du GCM. Les modèles d’exemplaires fondés sur la similarité relative (ou contextuelle) incorporent tous un paramètre d’attention sélective pour chaque caractéristique (dimension) des stimuli. Dans la présente étude, une attention particulière est portée au modèle contextuel de Medin & Schaffer (1978) car l’intérêt est ici de contraster les fondements de l’approche basée sur la mémorisation d’exemplaires à ceux de la formulation de règles. Pour ce faire, nous étudions une situation simplifiée où les caractéristiques des stimuli sont dichotomiques. Il fut donc choisi de ne pas s’adresser aux autres types de modèles de la catégorisation dans le cadre de cette étude.
Formalisation du modèle contextuel
Le modèle contextuel (Medin & Schaffer, 1978; Medin & Smith, 1981) permet de calculer des probabilités de classifications correctes pour chaque exemplaire
d’entraînement (rappel) ainsi que chaque nouveau stimulus (généralisation). Pour chaque stimulus, il s’agit essentiellement de calculer la somme de sa similarité à chaque
exemplaire de sa propre catégorie, ce qui fournit un indice de similarité intra-classe. Cet indice est divisé par la somme des similarités intra et inter-classe. La similarité entre deux stimuli est inversement proportionnelle à la distance les séparant dans l’espace des
Les caractéristiques d’un stimulus sont définies par un code binaire. Si les exemplaires varient en grandeur (petit-0, grand-1), en forme (carré-0, cercle-1) et en couleur (blanc-0, noir-1), un grand carré noir sera décrit par la notation « 101 ». Cette notation permet de calculer la similarité entre deux stimuli en attribuant la valeur 1 pour deux caractéristiques identiques et en attribuant un paramètre de similarité lorsque la caractéristique particulière diffère entre les deux stimuli. Par exemple, les stimuli 111 et 101 diffèrent seulement en forme. La similarité entre ces deux stimuli peut être
représentée par 1/1. Le /(pour forme) est un paramètre de similarité représentant la différence perçue entre un cercle et un carré. Celle-ci peut prendre une valeur entre zéro et un (la différence s’accroît en se rapprochant de zéro). Lorsque plusieurs
caractéristiques diffèrent, comme par exemple l/c, la similarité diminue de façon encore plus prononcée puisque les indices de « différences » se multiplient entre eux.
Le Tableau 1 présente la notation abstraite d’un problème de catégorisation utilisé dans l’étude de Medin & Schaffer (1978) et dans celle de Medin & Smith (1981). Dans le Tableau 1, la probabilité de rappel correct de la catégorie du Stimulus 1 (appartenant à la Catégorie A, donc : Ρα,ι) s’obtient en calculant la similarité intra-classe et en la divisant par la similarité à l’ensemble des exemplaires:
Ainsi,
Ρα,ι = [(1-1-1-1) + (1-6-1-1) + (1-6-1-/) + (1-1 ■c-d) + (a-1-1-/)]
/ [(l-l-l-l) 1־+־(1-6-1-1)+ (1-6־1·/)+(1־ ·c·/) + (a-1-1׳/)
+ (1-1-c-l) + (a-1-1-1) + (a-b'C-d) + (a-b-c-1)]. (1)
En simplifiant, nous obtenons :
Ρα,ι -___________ 1+b + bd+cd+ad________
1 + 6 + bd + cd+ ad + c + a + abcd + abc (2)
Cette équation incorpore quatre paramètres de similarité qui peuvent être estimés, pour )’ensemble des participants, des sous-groupes ou des individus, par minimisation
des moindres carrés de façon à reproduire les résultats empiriques. Les auteurs ne proposent pas une définition stricte des paramètres de similarité, suggérant que les paramètres estimés peuvent entre autres refléter les effets de la saillance ainsi que l’importance apprise de chacune des caractéristiques : ce qui correspond au concept d’attention.
Critique du modèle contextuel
L’adéquation du modèle de Medin et Schaffer peut toutefois être questionnée puisqu’il ne semble pas permettre d’expliquer la classification parfaite lors d’une tâche aux catégories floues, ce qu’un participant parvient éventuellement à produire (e.g., Shepard, Hovland, & Jenkins, 1961). En assignant la valeur zéro aux paramètres du modèle, l’indice de confusion inter-item devient zéro, ce qui permet de garantir une classification parfaite. Cependant, la classification de nouveaux stimuli ne serait possible autrement qu’en fonction du hasard (dans ce cas, une valeur près de zéro est requise pour chaque paramètre, sinon la similarité à la Catégorie A sera de zéro et sera divisée par une similarité aux exemplaires de A et B de zéro). Ce problème n’est pas apparent dans les études de Medin & Schaffer (1978) et Medin & Smith (1981), car le modèle n’est utilisé que pour reproduire la probabilité de classification correcte moyenne observée pour l’ensemble des participants. De plus, ce problème n’est pas facilement apparent car une proportion des participants n’a pas eu l’occasion d’atteindre un niveau de classification parfaite avant le nombre maximal d’essais. Ce problème est aussi peu apparent car l’estimation des paramètres de similarité est effectuée à partir de toute la série test, qui comprend à la fois les exemplaires d’entraînement et les nouveaux stimuli.
En vue d’étudier la nature de la représentation en mémoire dans cette tâche et afin de mieux cerner comment celle-ci influence la généralisation, il pourrait être plus
approprié de regrouper ensemble les résultats de différents participants seulement lorsque leur taux de classification correcte est comparable. De plus, il pourrait être préférable d’estimer les paramètres d’attention uniquement à partir des résultats observés pour les
stimuli d’entraînement et ainsi pouvoir prédire la performance de classification des nouveaux stimuli.
La seconde limite du modèle contextuel est qu’il décrit la performance moyenne des participants pour chaque item en ajustant, après coup, les paramètres d’attention. Si différents participants utilisent des règles différentes, tel que suggéré par Nosofsky, Palmed, & McKinley (1994), les paramètres d’ajustement moyen n’ont pas beaucoup de sens. Il vaudrait mieux s’intéresser aux différences de stratégie et regrouper les
participants selon la stratégie qu’ils utilisent pour ensuite estimer les paramètres
d’attention pour les différents groupes de participants formés en fonction des stratégies employées. Un excellent moyen de classifier les participants selon la stratégie employée (ou !’abstraction effectuée) fut proposé par Nosofsky, P aimed, & McKinley (1994). Ces chercheurs proposent de regrouper les participants selon le patron de généralisation obtenu pour les réponses aux stimuli test.
Lorsque deux modèles ont une même adéquation pour expliquer un phénomène, le principe d’Occam propose d’accorder une préférence au modèle le plus simple. Dans le cas présent, un modèle basé sur la formulation de règles semble plus économique et correspond davantage a !’impression subjective de formuler des règles rapportée par les participants (e.g. Shepard, Hovland, & Jenkins, 1961). Le calcul de la similarité relative n’a pas de valeur prédictive si la variation dans les résultats dépend essentiellement des spécificités de !’attention.
Dans l’Expérience 3 de Medin et Schaffer (1978) et dans l’étude de Medin et Smith (1981), nous pouvons remarquer que la structure des catégories (voir Tableau 1) permettait de formuler deux règles imparfaites avec une seule exception dans chacune des deux catégories. De plus, dans chaque étude, il est intéressant de noter que les quatre exceptions sont les items les moins biens classifiés. Il est ainsi possible qu’une partie des participants utilisaient l’une ou l’autre des règles. Le protocole expérimental comportait essentiellement une phase d’entraînement suivie d’une phase test. L’entraînement, avec rétroaction à chaque essai, présentait neuf exemplaires devant être associés à l’une de
deux catégories (A ou B). Les stimuli étaient présentés en blocs successifs, pour un maximum de 32 blocs ou jusqu’à la réussite d’un bloc sans erreur. La phase test, sans rétroaction sur la réponse donnée, présentait deux blocs de 16 stimuli : les neuf exemplaires et sept nouveaux stimuli. Les stimuli étaient des visages de Brunswick constitués de quatre caractéristiques binaires : la hauteur des yeux, l’écart entre les yeux, la longueur du nez et la hauteur de la bouche.
Dans l’étude de 1981, il y avait trois groupes soumis à différentes consignes pour la même tâche de catégorisation : une condition standard, une condition où les consignes indiquaient !’utilisation d’une règle spécifique (imparfaite) ainsi que la mémorisation des exceptions et une dernière condition où les consignes indiquaient la comparaison à un prototype. La consigne « standard » sert en quelque sorte de condition contrôle où aucune stratégie particulière n’est proposée. La consigne « règle plus exception » indique aux participants la procédure à suivre et comment appliquer cette stratégie à une
caractéristique particulière des stimuli. Dans la consigne « prototype », on explique aux participants comment comparer les stimuli à un prototype. Cette consigne demande aux participants de se former une impression générale des catégories, en retenant, au niveau de chaque caractéristique dichotomique, la valeur (i.e. nez long ou court) qui est la plus typique à chacune des deux catégories. Le Tableau 2 présente les probabilités de
classification correcte observées pour chacun des stimuli d’entraînement pour les trois consignes. Remarquez que peu importe les consignes, les quatre exceptions (13, 5, 12 et 2) sont toujours les moins bien réussies. Ceci pourrait indiquer qu’une proportion des participants aurait utilisé l’une ou l’autre des deux règles malgré une consigne neutre ou malgré Vindication de procéder à la comparaison avec un prototype.
Cet exemple illustre bien le problème posé par l’étude des moyennes de groupe : !’application de chacune de ces deux règles par la moitié des participants, produirait, en principe, une réussite moyenne de 50% des classifications pour chacun des quatre stimuli « exception » (et 100% pour les autres stimuli). Ceci suppose que les exceptions ne sont pas réussies et que la performance de chaque participant à la fin de l’entraînement soit donc fixe à sept stimuli correctement classifiés (sur neuf). Une procédure expérimentale
sera conçue dans la présente étude de façon à prévenir ce type de problème et mettre en évidence Γutilisation de règles par les participants.
Medin et Smith, quant à eux, concluent que la variabilité produite par les différentes stratégies (ou consignes) s’explique par des variations dans les différents paramètres d’attention, mais que le processus repose fondamentalement sur la mémorisation d’exemplaires.
Ayant remarqué ces particularités retrouvées dans les résultats de ces deux études, Nosofsky, Palmeri et McKinley (1994) et Palmeri et Nosofsky (1995) ont repris cette même structure des catégories dans leurs études pour tester le modèle RULEX.
Règles et exceptions
Le modèle RULEX (Nosofsky & Palmeri, 1998; Nosofsky, Palmeri & McKinley, 1994) propose une procédure stochastique de production de règles et de mémorisation d’exceptions. Une simulation informatique reproduit un processus de tests d’hypothèses sous forme de règles logiques. Ce processus permet de générer différentes abstractions, pouvant servir à prédire les patrons de généralisation. Le modèle cherche (par des déplacements de !’attention sur les différentes caractéristiques des stimuli), en ordre de difficulté et de préférence, une règle unidimensionnelle permettant une classification parfaite, une règle imparfaite avec mémorisation des exceptions, puis une règle
conjonctive sans ou avec mémorisation d’exceptions. Les résultats moyens observés pour l’ensemble des participants dans une expérience de classification seraient le produit de !’application de différentes règles simples par différents participants complémenté, au besoin, par la mémorisation des exceptions. Nosofsky propose ainsi d’examiner les patrons de généralisation individuels plutôt que les moyennes du groupe, car ces dernières ne sont pas très utiles si elles résultent de !’utilisation de différentes stratégies par différents participants. Ce modèle s’est avéré capable de reproduire les différents patrons de généralisation au niveau individuel, les effets perceptifs (effet de prototype, effet d’exemplaire spécifique) retrouvés dans l’étude de Medin & Schaffer (1978) et
l’effet de la difficulté relative des six types de problèmes de catégorisation de Shepard et al. (1961).
La complexité d’un concept
Comme le suggèrent les résultats de l’étude de Shepard, Hovland et Jenkins (1961), la difficulté globale de différents problèmes de catégorisation refléterait la complexité de la règle à apprendre. Feldman (2000), présente des résultats fort intéressants concernant la difficulté, pour les participants, à apprendre différents
problèmes de catégorisation (formation de concepts). Le paradigme expérimental consiste à vérifier si la proportion de réponses correctes varie en fonction de la complexité du problème de catégorisation telle qu’elle s’exprime par une proposition d’algèbre booléenne. Comme dans l’étude de Shepard et al. (1961), l’ensemble des stimuli appartenant à chacune de deux catégories sont présentés. La phase d’entraînement présente simultanément et pour une durée limitée, tous les « membres » et « non- membres » d’une espèce fictive d’amibes définis, selon le problème de catégorisation présenté, par trois ou quatre caractéristiques binaires. La phase test mesure la proportion de réponses correctes pour l’ensemble stimulus. Tous les stimuli étant présentés durant la phase d’entraînement, la phase test ne présente aucun nouveau stimulus.
Les résultats de cette étude suggèrent que la difficulté d’apprentissage d’un problème de catégorisation est effectivement en relation avec la complexité booléenne de celui-ci. Par exemple, la difficulté relative obtenue pour les six types de problèmes dans l’étude de Shepard, Hovland et Jenkins (1961) s’explique de façon fort simple et élégante par leur complexité booléenne. L’étude de Feldman explore davantage cette relation en mesurant la difficulté d’apprentissage de divers problèmes de catégorisation, soit 41 types mathématiquement distincts, à travers six « familles » de problèmes.
Une famille regroupe toutes les classifications possibles pour un nombre de caractéristiques donné et un nombre d’exemples « positifs » donné. Le système de notation des familles proposé par Feldman permet d’identifier à l’aide de deux chiffres
les différents problèmes de catégorisation constitués de deux catégories (problèmes de discrimination). Le premier chiffre indique le nombre de caractéristiques (dimensions dichotomiques) décrivant les stimuli. Le second chiffre, placé entre crochets, indique le nombre de stimuli associés à la première catégorie, appelée catégorie « positive » (les stimuli sont présentés comme membres et non-membres d’un concept). Par exemple, la famille 3 [4] représente l’univers des différentes classifications des stimuli à trois caractéristiques binaires et comportant quatre stimuli appartenant à la catégorie
« membres » (et dans le cas présent quatre stimuli dans la catégorie « non-membres »). Cette famille regroupe les 70 problèmes de catégorisation représentant les différents arrangements possibles de huit stimuli (il y a trois caractéristiques binaires, donc 23 stimuli) en deux groupes de quatre. L’ensemble des problèmes de catégorisation d’une même famille peut être caractérisé par un certain nombre de structures distinctes, appelées « types » de problèmes.
Les six familles étudiées par Feldman sont 3[2], 3[3], 3[4], 4[2], 4[3], et 4[4]. Ces familles possèdent respectivement 3, 3, 6, 4, 6, et 19 types de catégorisations distinctes. Le Tableau 3 présente les six types de la famille 3[4], étudiée à l’origine par Shepard et al. (1961), ainsi qu’une représentation de leur structure et de leur complexité booléenne.
L’algèbre booléenne est un système mathématique abstrait principalement utilisé en science informatique et servant à formaliser la relation entre des groupes d’objets ou de concepts. Ce système de notation vise la manipulation algébrique d’énoncés logiques. Une proposition booléenne est constituée d’éléments symboliques, les variables (par exemple a, b, c, d, etc.) et de connecteurs logiques (« et », « ou » et « négation »). Si la variable a représente la caractéristique « grandeur » (petit/grand), « a » peut représenter « grand » tandis que « non a » peut représenter « petit ».
Trois connecteurs booléens fondamentaux, « et », « ou » et « négation », se combinent pour exprimer une fonction booléenne. Pour fins de simplicité, a a (« a et
b ») sera exprimé par ab, tandis que a v b (« a ou b ») sera exprimé par a+b et enfin ־־,a
catégorie peut ainsi être représenté et « simplifié » sans que son sens ne soit modifié. La « complexité booléenne » correspond à la formule d’algèbre booléenne minimale
représentant la catégorie positive, aussi appelée le concept (voir Tableau 3). Il s’agit d’une valeur correspondant au nombre de termes littéraux (non-logiques) dans la proposition, autrement dit le nombre de variables positives et négatives. Par exemple,
ab+ab ’ est l’équivalent de a(b+b ’), et se réduit donc à a. La complexité booléenne de ce
concept est de un. La proposition ab+a ’b ' étant irréductible, sa complexité est de quatre. Feldman souligne qu’en pratique, on obtient la formule minimale par des techniques de computation approximatives qui utilisent la factorisation et la négation-complémentation.
Une tâche particulière de catégorisation peut s’exprimer sous la forme d’une « formule normale disjonctive » (voir Tableau 3), équivalente à l’énumération des stimuli appartenant à l’une des deux catégories (les autres stimuli correspondent au complément de la première catégorie et se réduisent à la même structure logique). Cette expression étendue d’un problème de catégorisation se caractérise par une série de disjonctions (« ou ») de chaque stimulus d’une catégorie. Chaque stimulus est représenté sous forme d’une conjonction de ses propres caractéristiques (par exemple, petit et carré et noir). Par la suite, en simplifiant cette formule, nous obtenons la formule minimale correspondant à la complexité du problème de catégorisation. L’Annexe A présente un exemple détaillé de la représentation d’un problème de catégorisation sous forme d’algèbre booléenne et du calcul de sa complexité.
Dans le Tableau 3, en examinant la colonne des formules réduites, il est possible de faire une constatation surprenante et apparemment négligée par Feldman : cette simple réduction correspond à la règle verbale attendue pour les cinq premiers types de
problème. On retrouve la règle unidimensionnelle pour le Type 1, le biconditionnel (l’inverse du fameux OU exclusif) pour le Type 2, et une règle unidimensionnelle accompagnée des deux exceptions pour les Types III, IV et V. Par exemple, le Type III (voir Figure 1) est représenté par la proposition a ’ (bc) ' + ab ’c. Le a ’ correspond à la règle générale « Catégorie A si le stimulus est noir », le (bc) ’ correspond à la première exception à la règle « . ..mais pas s’il est carré et petit... » et le + ab ’c correspond à la
seconde exception « ...ou encore s’il est blanc et triangulaire et petit. ». Nous verrons plus tard que ces composantes logiques sont exactement ce que nous tentons de modéliser comme « représentation interne » dans un réseau de neurones.
L’étude de Feldman a aussi identifié un second facteur, orthogonal à la
complexité, appelé l’effet de polarité. Lorsque les deux catégories, « membres » et « non- membres », ne possèdent pas un nombre égal de stimuli, il se manifeste une plus grande facilité pour la tâche lorsque la catégorie positive contient le plus petit des deux groupes de stimuli et ce même si la complexité logique est identique pour ces deux propositions complémentaires. En d’autres mots, à complexité égale, il est plus facile d’apprendre à catégoriser l’ensemble de stimuli le plus petit. L’étude de Shepard et al. (1961), ainsi que la présente étude, sont exempts de l’effet de polarité puisque les catégories sont de même taille.
La complexité booléenne peut être vue comme un cas particulier de la notion plus générale de la complexité de Kolmogorov. La K-complexité représente le programme informatique le plus court permettant de générer un objet et n’est pas limitée en termes de type de représentation (logique, linguistique, probabiliste ou pictographique par
exemple). Chater (2000), discute de la relation entre l’étude de Feldman et la K- complexité. Il propose que le principe de la complexité minimale soit non-seulement caractéristique des processus de catégorisation mais aussi un principe fondamental de !’apprentissage humain.
Critique de l’étude de Feldman
En effectuant la minimisation booléenne des six types de problèmes de
catégorisation retrouvés dans le Tableau 3, nous avons obtenu des formules minimales différentes de celles obtenues par Feldman pour les types III et IV. L’Annexe B présente la minimisation effectuée. Le type ΠΙ peut être représenté par la formule minimale « a’c ’ + b ’c » de complexité quatre, plutôt que par « a ’(bc) ’ + ab’c », de complexité six. Le type IV peut être représenté par la formule minimale « a ’(bc) ’ + b’c’ », de complexité
cinq, plutôt que par « a ’(bc) ' + ab’c’ », de complexité six. Il semble que Feldman ait obtenu ces formules en se limitant à deux techniques de minimisation, soit la factorisation et la négation-complémentation. Cependant, en utilisant conjointement une plus grande variété de techniques, tel le principe d’adjacence et le théorème de DeMorgan (Lepage,
1995), nous pouvons obtenir des formules réduites davantage pour ces deux types de problèmes de catégorisation. En conséquence, la complexité des types ΠΙ, IV et V, plutôt que d’être constante à six, devient respectivement de quatre, cinq et six. Puisque les expériences de Feldman (2000), de Shepard et al. (1961) ainsi que de Nosofsky, Gluck, Palmeri, McKinley et Glauthier (1994), suggèrent que ces trois types sont de même difficulté, il semblerait que les solutions minimales des types III et IV ne sont pas employées par l’ensemble des participants. La représentation booléenne de complexité six pour les types ΠΙ, IV et V correspond à l’emploi d’une stratégie de catégorisation par règle et exceptions. La présence de solutions plus économiques à ces problèmes de catégorisation nous paraît un élément conceptuel important. La présente étude utilisera donc une tâche de catégorisation permettant à la fois l’emploi d’une stratégie basée sur une règle comportant deux exceptions et l’emploi d’une stratégie basée sur une règle de moindre complexité.
L’étude de Feldman appuie fortement l’hypothèse de formation de règles dans les tâches de catégorisation. Toutefois, elle n’ apporte pas d’indication comment les
participants généralisent leur apprentissage à d’autres stimuli. Dans la présente recherche, nous souhaitons examiner si ce modèle mathématique permet de prédire comment des participants humains classifient de nouveaux stimuli. Le passage d’une proposition « étendue », décrivant chaque stimulus, à une proposition minimisée, permettrait un passage du particulier (mémorisation des exemplaires), au général (règles et exceptions). Tandis qu’une formule normale disjonctive ne permet pas de classifier un nouveau stimulus, la formule minimisée possède alors une généralité lui permettant de classifier de nouveau stimuli. Il suffirait d’effectuer la minimisation booléenne d’une série de stimuli d’entraînement plutôt que de l’ensemble stimulus au complet. La règle booléenne ainsi obtenue pourrait servir à prédire le patron de généralisation pour des stimuli test. De
plus, il serait possible de mettre en place un tel processus à l’aide d’un réseau de neurones effectuant l’équivalent de la réduction booléenne proposée par Feldman.
Les réseaux de neurones
Parmi les différents types de modèles de la catégorisation, nous nous intéressons particulièrement, en vue d’étapes futures à la présente recherche, à la modélisation
connexionniste pour simuler les mécanismes d’apprentissage de catégories (e.g., Erickson & Kruschke, 1998; Gluck, 1991; Gluck & Bower, 1988; Knapp & Anderson, 1984; Kruschke, 1992; Shanks, 1991; Vandierendonck, 1995).
Un type de réseau de neurones appelé « réseau à couches multiples » (Rumelhart & McClelland, 1986) est un système formel constitué d’unités simples et de connexions unidirectionnelles, fonctionnellement analogue à certains aspects de la transmission neuronale. Ce système effectue un traitement en parallèle d’activations provenant d’une source externe et produit en réponse une certaine activation d’une ou plusieurs unités de sortie. L’activation de chacune des unités du réseau est représentée par une valeur numérique. D’un point de vue fonctionnel, chacune des unités transforme
mathématiquement la somme des activations qu’elle reçoit d’autres unités. Les unités sont liées par des connexions adaptatives qui multiplient l’activation reçue selon une valeur pouvant être positive ou négative, appelée le poids de la connexion. Pour une unité donnée, l’activation résultante est fonction de la somme pondérée de la stimulation reçue.
Ce type de modèle est surtout utilisé dans la recherche en sciences cognitives et en ingénierie. Le connexionisme est un courant qui utilise les réseaux de neurones pour modéliser certains aspects de la cognition. Il a connût une explosion en 1986 avec la publication du livre de McClelland et Rumelhart, Parallel distributed processing. Les réseaux utilisant des éléments simples de computation en parallèle remontent pourtant à quatre décennies plus tôt. Ainsi, McCulloch et Pitts (1943) ont démontré qu’un système d’unités neuronales artificielles pouvait effectuer des opérations logiques. Ceci est un résultat clé dans le développement du courant connexionniste. Ces premiers réseaux
étaient conçus arbitrairement pour effectuer une opération particulière (ils ne
comportaient par de règle dי apprentissage) et ressemblaient à des arbres de décision logique. Selon ces auteurs, la logique ne servirait pas simplement d’outil pour le
raisonnement, mais serait un principe fondamental des processus élémentaires du système nerveux.
Les modèles connexionnistes sont aujourd’hui développés sous forme de simulations informatiques. Les réseaux de neurones ont particulièrement servi à
modéliser la mémoire associative dans les processus de la perception, du jugement et du langage. Depuis Donald Hebb (1949), des règles d’apprentissage ont été développées permettant à ces réseaux, préalablement statiques, de s’adapter de façon automatisée à des contraintes extérieures. Une phase d’entraînement s’est ainsi ajoutée au protocole de simulation et ces réseaux peuvent dorénavant servir à étudier différents aspects de la cognition comme la mémoire et la généralisation.
Un réseau de neurones à couches multiples, entraîné avec succès pour prédire correctement une réponse à un problème de classification, représente en fait le passage d’un niveau sub-symbolique (un encodage distribué sur la couche d’entrée des
caractéristiques ou dimensions d’un objet) à un niveau symbolique (en sortie de réseau, chaque unité peut représenter une catégorie, autrement dit un concept.). La ou les couches intermédiaires sont généralement conceptualisées comme jouant le rôle de
représentations internes et sont souvent considérées comme des « boîtes noires ».
Dans la présente étude, un premier pas dans l’effort de modélisation du processus de catégorisation visera à démontrer qu’une formule booléenne minimale peut
correspondre à la représentation mnésique du problème de classification à l’étude. Cette étape sera en vue d’effectuer ultérieurement la modélisation de !’apprentissage permettant d’obtenir ce type de représentation dans un réseau de neurones à couches multiples.
Objectifs
Ce projet de recherche a pour objectif d’étudier le processus d’apprentissage et de généralisation dans une tâche de discrimination de stimuli visuels multidimensionnels assignés à deux catégories floues. Il s’agit de confronter les principes du modèle
contextuel de Medin et Schaffer, fondé sur la similarité avec des exemplaires mémorisés, à celui d’une stratégie de formulation d’une règle accompagnée de la mémorisation des exceptions. L’objectif spécifique est de vérifier si une stratégie par formulation de règles et mémorisation d’exceptions est retenue par les participants, lorsqu’ils effectuent une tâche de catégorisation avec des stimuli aux caractéristiques séparables permettant la formulation de quatre règles présentant une même structure logique mais qui ne permettent pas une classification parfaite.
La structure des catégories utilisée dans la présente étude a été établie de façon à permettre aux participants d’identifier des règles de catégorisation. Elle offre une
situation optimale pour vérifier si les erreurs retrouvées et les patrons de généralisation relèvent de !’application systématique d’une règle. De plus cette structure permet à la fois de formuler l’une de quatre stratégies de « règles et exceptions » ou encore l’une de trois règles de moindre complexité.
Le choix d’un problème de catégorisation pour lequel il existe quatre différentes règles de classification présente deux avantages. Premièrement, la possibilité d’utiliser l’une de quatre règles permet de vérifier si la proportion moyenne de classification
correcte pour chaque stimulus reflète, tel que suggéré par Nosofsky, Palmeri et McKinley (1994), !’utilisation de différentes règles par différents groupes de participants. Par
exemple, si un stimulus peut être classifié correctement à 100% en utilisant trois des quatre règles possibles et à 0% en utilisant la quatrième (pour cette règle ce stimulus est l’exception), il n’est pas utile d’expliquer la performance moyenne de l’ensemble des participants (qui sera 75% si le quart des participants utilise l’une des règles). Le second avantage est de permettre de prédire quatre différents patrons de réponses, en fonction de la règle utilisée, lors d’un test de généralisation.
Plan d’expérience et hypothèses
Le déroulement de Γexpérience comporte une phase d’entraînement, une phase de maintien du niveau de performance et une phase test. Le niveau de performance est évalué par le nombre de classifications correctes observées dans un bloc de dix stimuli. Trois conditions quasi-expérimentales sont définies, à posteriori, en fonction du nombre de stimuli classifiés correctement par chaque participant durant la phase test. Les
participants ayant correctement classifié huit des dix stimuli d’entraînement (soit aucune des deux exceptions) constituent un premier groupe. Un second groupe est constitué des participants ayant correctement classifié neuf des dix stimuli d’entraînement (soit l’une des exceptions). Un troisième groupe est constitué des participants ayant correctement classifié les dix stimuli d’entraînement (incluant les deux exceptions). En vue de provoquer une auto-assignation à chacun de ces trois groupes, les participants sont assignés aléatoirement à une phase d’entraînement caractérisée par l’un de deux critères de fin d’entraînement (soit un niveau de performance d’au moins 8 ou d’au moins 9 stimuli sur 10). Ceci permet, d’une part, de vérifier si les erreurs commises relèvent effectivement de l’utilisation d’une règle imparfaite, sans que !’apprentissage des exceptions n’ait été possible. D’autre part, lorsqu’une ou les deux exceptions sont
apprises, il s’agit de déterminer si la reconnaissance de celles-ci, comme étant des stimuli d’entraînement plutôt que des stimuli test, est supérieure à la reconnaissance des stimuli « réguliers ». Mis à part une nouvelle structure des catégories limitant la variété des règles applicables, ce nouveau contrôle méthodologique consiste à cesser l’entraînement lorsque les participants atteignent un niveau de performance prédéterminé plutôt qu’après un nombre fixe d’essais.
La mesure de reconnaissance (discrimination entre les stimuli d’entraînement et les nouveaux stimuli) sert ici à vérifier si les exceptions sont identifiées, même si les stimuli pouvant être classifiés correctement par la règle ne le sont pas. Enfin, les patrons de généralisation observés pour chaque condition seront comparés afin de déterminer si !’apprentissage des exceptions a eu un effet sur la classification des stimuli test.
Le devis expérimental se résume à deux variables indépendantes et à deux variables dépendantes. Une première variable indépendante invoquée, de type inter- groupe, est constituée par le nombre de classifications correctes atteint dans la phase d’entraînement. Elle comporte trois niveaux (8,9 et 10). Une seconde variable indépendante intra-groupe est le type de stimulus employé. Elle comporte aussi trois niveaux (Régulier/Exception/Test). Une première variable dépendante est la catégorie sélectionnée, c’est-à-dire la réponse modale (A ou B) pour un stimulus donné, sur un total trois essais. Cette variable est plus utile que la proportion correcte, qui est utilisée
habituellement, lorsque l’objectif est d’effectuer une analyse des patrons de
classifications pour chaque participant. Une seconde variable dépendante est le niveau de reconnaissance, c’est-à-dire le nombre de réponses « stimulus d’entraînement » par opposition à « nouveau stimulus », pour un stimulus donné, sur un total de trois essais.
Cette étude examine principalement la pertinence des règles utilisées par les participants et leur effet attendu sur la classification des stimuli test. Il s’agit de vérifier si les réponses à de nouveaux stimuli varient de façon conforme à la règle utilisée par un participant.
La logique fondamentale de ce plan d’expérience vise à comparer les différences systématiques attendues lors de la catégorisation de chaque stimulus test en fonction des quatre règles utilisées par les participants. Il est attendu que les quatre différents patrons de généralisation ne différeront pas en fonction des les trois niveaux de performance prédéterminés. Autrement dit, !’apprentissage des exceptions ne devrait aucunement altérer la classification des nouveaux stimuli.
La capacité à discriminer les stimuli faisant partie de l’ensemble d’entraînement de ceux qui sont nouvellement présentés lors de la phase test, représente un argument en faveur d’une stratégie de mémorisation d’exemplaires par opposition à une stratégie de classification par règles où les exceptions classifiées correctement devraient être les seuls stimuli pouvant être reconnus (étant les seuls stimuli identifiés).
Expérience
Dans cette expérience, les participants effectuent une tâche de catégorisation de stimuli visuels, comportant quatre caractéristiques dichotomiques, assignés à l’une de deux catégories (A et B). La structure des catégories est choisie de sorte à ce que les participants ne puissent pas utiliser une règle simple appliquée sur une caractéristique des stimuli, ou à une conjonction de deux caractéristiques, pour effectuer une classification parfaite. Par exemple, si les stimuli sont des visages, la longueur du nez ne doit pas être la même pour l’ensemble des stimuli dans la Catégorie A, ni prendre toujours la valeur inverse dans la Catégorie B. Il ne doit pas y avoir de caractéristiques distinctives
définissant les catégories. Les stimuli à catégoriser sont assignés aux deux catégories de façon à ce que l’ensemble du problème de catégorisation ne permette la formulation que de quatre règles imparfaites, chacune basée sur l’une des caractéristiques des stimuli, et de trois règles « parfaites » de moindre complexité, correspondant à la disjonction de deux conjonctions. Pour chaque règle imparfaite, chacune des deux catégories comporte une exception, c’est-à-dire un stimulus ne pouvant être catégorisé correctement en utilisant cette règle. Les deux exceptions sont différentes pour chacune des quatre règles. Le Tableau 4 présente comment les dix stimuli d’entraînement peuvent être soit une « exception », soit un stimulus « régulier » selon la règle utilisée. Le statut d’exception est donc relatif à la règle employée.
La Figure 2 présente une schématisation des dix stimuli d’entraînement. Les quatre caractéristiques (bouche, nez, yeux, oreilles) peuvent ici prendre la valeur « blanc » ou « noir ». Cette illustration permet de mieux saisir comment chaque caractéristique prend une même valeur pour tous les stimuli dans une catégorie, à l’exception d’un stimulus qui forme une exception dans chaque catégorie. Les visages à la gauche appartiennent à la Catégorie A et ceux à droite forment la Catégorie B. Les valeurs noir/blanc ne peuvent servir qu’à des fins de simplification pour faciliter la compréhension du lecteur car ceci permettrait !’utilisation d’une stratégie basée sur le calcul du nombre de caractéristiques d’une certaine couleur, devenant en soi une
dimension suffisante pour effectuer la discrimination (e.g. « Catégorie A si aucune ou une caractéristique en noir » et « Catégorie B si trois ou quatre caractéristiques en noir »).
Dans la Figure 2, les quatre chiffres adjacents à chaque visage représentent la structure abstraite du stimulus. Ici, la valeur « 0 » représente « blanc » et « 1 » représente « noir ». Le premier chiffre correspond à la bouche, le second au nez, le troisième aux yeux et le quatrième aux oreilles. En portant attention à une seule caractéristique, les oreilles par exemple, il devient évident qu’une règle simple (« si les oreilles sont blanches donc Catégorie A... sinon Catégorie B ») permet de classifier correctement huit des dix stimuli.
Trois phases se succèdent lors du déroulement de l’expérience. Dans un premier temps, une phase d’entraînement a pour fonction de permettre aux participants de former les associations entre les dix stimuli d’entraînement et les réponses à produire (la
catégorie correcte). Une série d’essais est effectuée. Les visages sont présentés un à la fois et les participants ont à indiquer si ce stimulus appartient à la Catégorie A ou à la Catégorie B. Une rétroaction indique si la réponse est correcte ou incorrecte. Cette phase se poursuit jusqu’à ce qu’un niveau de performance prédéterminé (8 ou 9 réponses correctes) soit atteint à l’intérieur d’un même bloc d’essais. Ensuite, une phase de maintien a pour fonction d’assurer la stabilité des réponses. La phase test permet d’étudier la généralisation, c’est-à-dire les réponses fournies à de nouveaux stimuli. La capacité des participants à reconnaître si un stimulus est nouveau ou s’il faisait partie de la série d’entraînement est aussi étudiée dans la troisième phase. Durant cette troisième phase, les seize stimuli (soit les dix stimuli d’entraînement et six stimuli de
généralisation) sont présentés à trois reprises afin d’obtenir une réponse modale (la plus fréquente de trois essais) pour déterminer la catégorie sélectionnée par le participant et tester la reconnaissance.
L’entraînement pour un participant cesse dès que sa performance est de huit sur dix (pour la moitié des participants) ou encore de neuf sur dix (pour l’autre moitié des participants). Il s’agit d’un critère de performance minimale, en conséquence, trois
niveaux de performance pourront être obtenus, soit de huit, neuf ou dix classifications correctes. Une série d’essais sans rétroaction (phase de maintien) permet alors de vérifier si la performance demeure au même niveau ou si l’entraînement doit se poursuivre. Le niveau de classifications correctes doit ainsi, pour chaque participant, demeurer stable durant les deux blocs de la phase de maintien, sans quoi la phase d’entraînement est reprise.
Les règles
Pour les fins de cette recherche, nous inférerons qu’un participant a identifié ou abstrait une règle lorsque son taux de classification correcte sur les stimuli
d’entraînement atteint au moins 80%. Dans ce cas, huit stimuli sur dix sont correctement classifiés et les deux stimuli incorrectement classifiés devraient être les exceptions à cette règle. Une règle prend la forme d’une proposition conditionnelle telle « si x donc
Catégorie A... sinon Catégorie B». Autrement dit, si le Stimulus 1 possède la Caractéristique x (grands yeux par exemple), il appartient donc à la Catégorie A.
En vue d’obtenir une définition opérationnelle de !’application d’une règle, les réponses fournies permettent d’identifier un patron d’erreur pour chaque participant. Ceci permet d’inférer à posteriori quelle règle fut utilisée par chaque participant, dans la mesure où les erreurs de classification commises correspondent aux exceptions
spécifiques à l’une des quatre règles de classification (voir Tableau 4). L’identification d’une règle particulière utilisée par un participant permet de prédire son patron de
généralisation. Le patron de généralisation d’un participant est défini par la classification effectuée pour les six stimuli test. La phase test comporte au total trois présentations de chaque stimulus. Le patron de généralisation d’un participant est inféré à partir de la réponse observée le plus fréquemment durant ces trois essais (le mode).
Une formule booléenne minimale présentant une description formelle de la
Catégorie A (et de son complément, la Catégorie B) s’obtient, pour chaque participant, en effectuant une minimisation booléenne d’une formule décrivant le patron de
classifications observé. Le patron de classifications d’un participant est défini par les réponses observées pour tout l’ensemble stimulus durant la phase test. Une formule minimisée est une expression qui correspond toujours à une règle quelconque (une série de conditions d’appartenance à la Catégorie A). Il s’agit ensuite de déterminer si cette dernière correspond, ou non, à une série de règles et d’exceptions.
Méthode
Participants
Seize participants (7 hommes et 9 femmes, d’âge moyen de 27,7 ans) sont recrutés à l’aide d’affiches, parmi la population universitaire. Huit participants sont assignés aléatoirement au critère de fin d’entraînement de huit classifications correctes (dans un bloc de dix essais) et huit participants sont assignés au critère de fin
d’entraînement de neuf classifications correctes. Chacun des huit participants dans un groupe est assigné aléatoirement à l’un de huit problèmes de classification présentant la même « structure » mais constitués de différents arrangements des stimuli. Les
participants prennent part à une seule session expérimentale, sans session de pratique, d’une durée pouvant varier entre trente et soixante minutes en fonction du nombre de blocs d’entraînement requis pour atteindre le critère de performance. Chaque participant reçoit 5$ pour sa participation.
Stimuli
Il s’agit de schémas de visages similaires aux visages de Brunswick (Medin & Schaffer, 1978), où varient la hauteur de la bouche, la forme du nez, l’écart entre les yeux et la grosseur des oreilles. Les stimuli à catégoriser varient selon quatre caractéristiques pouvant prendre l’une de deux valeurs. L’ensemble stimulus est formé de 16 visages différents représentant l’ensemble des agencements possibles des quatre caractéristiques. La Figure 3 présente les 16 schémas de visages. Cinq visages sont associés à la Catégorie A, cinq à la Catégorie B et six visages non-assignés sont réservés pour étudier la
généralisation. Dans la Figure 3, F attribution des visages aux catégories correspond à l’un des arrangements des stimuli parmi un total de huit possibilités d’arrangements isomorphes.
Le Tableau 5 présente formellement les catégories selon le premier arrangement, c’est-à-dire !’assignation des valeurs abstraites définissant les caractéristiques de chaque stimulus. Les valeurs de « un » et « zéro » décrivent les caractéristiques des schémas de visages présentés. Le Stimulus 16 possède la valeur « un » aux Caractéristiques 1 et 3, ainsi que la valeur « zéro » aux Caractéristiques 2 et 4. Si par exemple la Caractéristique 1 correspond à la hauteur de la bouche, le chiffre « zéro » représente une bouche basse et le chiffre « un » représente une bouche haute. Il s’agit simplement d’une convention arbitraire sur la notation abstraite des caractéristiques. Pour la forme du nez, « zéro » représente un nez en losange et « un » représente un nez carré. Pour l’écart entre les yeux, « zéro » représente un grand écart et « un » un petit écart. Pour la grosseur des oreilles, « zéro » représente de grandes oreilles et « un » de petites oreilles.
Dans le Tableau 5, la colonne « statut » indique l’étiquette associée aux stimuli, afin de clarifier quels items font exception à quelle règle. El par exemple, signifie que ces stimuli sont des exceptions selon la règle basée sur la Caractéristique 1. Le statut « R » signifie ici que ces items sont toujours des items réguliers, peu importe la règle choisie par le participant.
Huit différents arrangements permettront d’effectuer un plan d’équilibration tout en préservant la structure fondamentale des catégories. Pour tous les arrangements, les caractéristiques de la notation pour chaque stimulus sont dans l’ordre : Bouche (0-basse, 1-haute), Nez (0-losange, 1-carré), Yeux (0-écartés, 1-rapprochés), Oreilles (0-grandes, 1 -petites). Le Tableau 6 présente les huit arrangements utilisés dans l’expérience. La fonction de ces huit différents arrangements est essentiellement de tenter de mettre en relief !’utilisation des mêmes règles par les participants pour des catégories pourtant constituées de différents stimuli d’entraînement.
La structure logique de cette tâche de catégorisation (selon !’Arrangement 1) s’exprime en algèbre booléenne par la formule normale disjonctive suivante :
Catégorie A -a’b’c ’d’+ ab ’c ’d’+ a ’bc ’d’+ a ’b ’cd’+ a ’b ’c ’d.
Les variables a, è, c et d correspondent respectivement à la valeur de la
Caractéristique 1, 2, 3 et 4 (0 = a’ et 1 = d). Il s’agit effectivement d’énumérer les cinq stimuli appartenant à la Catégorie A (voir Tableau 6). La notation abstraite de ces cinq stimuli : 0000, 1000, 0100, 0010, 0001 est représentée par cette formule normale disjonctive.
La technique de minimisation booléenne ne permet pas de prédire la classification des stimuli test à partir d’une classification particulière de la série d’entraînement, tant qu’il y a des réponses « indéterminées ». Tout stimulus qui n’est pas inclut dans la formule normale disjonctive appartiendra à la catégorie par défaut, c’est-à-dire la
Catégorie B. Il est cependant possible d’effectuer une description de la représentation des catégories lorsque toutes les réponses sont déterminées. Il est aussi possible de tenter de prédire les résultats en effectuant une minimisation booléenne à partir de la classification des stimuli test attendue en fonction de !’utilisation de l’une des quatre règles. Les quatre représentations suivantes sont donc dérivées des quatre patrons de généralisation attendus par une représentation où les exceptions sont identifiées et les stimuli test sont catégorisés selon une règle unidimensionnelle.
Représentation 1 : a ’(bed) ’ + b’c ’d’ Représentation 2 : b ’(acd) ’ + a’c ’d’ Représentation 3 : c ,(abd) ’ + a’b’d’ Représentation 4 : d’(abc) ’ + a’b’c’
Pour chaque représentation, ou formule booléenne, nous pouvons identifier trois composantes, soit la règle générale et ces deux exceptions. Par exemple, pour la