HAL Id: tel-01931361
https://tel.archives-ouvertes.fr/tel-01931361
Submitted on 22 Nov 2018
HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
logique multivalente : cas d’une répartition non uniforme
des degrés de vérité
Nouha Chaoued
To cite this version:
Nouha Chaoued. Représentation et traitement des connaissances en logique multivalente : cas d’une répartition non uniforme des degrés de vérité. Autre [cs.OH]. Université Montpellier; Université Tunis El Manar. Faculté des Sciences Mathématiques, Physiques et Naturelles de Tunis (Tunisie), 2017. Français. �NNT : 2017MONTS048�. �tel-01931361�
Pr´epar´ee au sein des ´ecoles doctorales I2S et MISTM
Et des unit´es de recherche LIRMM et LIPAH
Sp´ecialit´e : Informatique
Pr´esent´ee par Nouha CHAOUED
nouha.chaoued@lirmm.fr
Repr´
esentation et traitement
des connaissances en logique
multivalente :
Cas d’une r´
epartition non
uniforme des degr´
es de v´
erit´
e
Soutenue le 30-11-2017 devant le jury compos´e de
M Christophe Marsala Pu Universit´e Pierre et Marie Curie Rapporteur Mme Nahla Ben Amor Pu Universit´e de Tunis Rapporteur Mme Carmen Gervet Pu Universit´e de Montpellier Pr´esidente du jury Mme Narjes Ben Rajeb Pu Universit´e Tunis Carthage Examinateur Mme Amel Borgi MCF, HDR Universit´e Tunis El Manar Directrice de th`ese Mme Anne Laurent Pu Universit´e de Montpellier Directrice de th`ese
`
A mes chers parents, `
A mon cher mari Abdelkader, `
A mes chers fr`eres Khaled et Haythem et ma soeur Hela, `
A mes chers Zouhour, Manel, Rim, Ouafa, Rabia, Djamel, Mehdi, Ibrahim, `
A mes coll`egues Wafa, Houda, Samira, Ikbel, `
A mes cousins et cousines, `
A tous mes amis en Tunisie et en France, `
Tout d’abord, je remercie les personnes `a qui je dois mon existence et mon succ`es ! Mes parents qui ont toujours ´et´e l`a pour moi pour me guider, me conseiller et m’encourager.
Je remercie mon mari pour son amour et pour sa patience en particulier durant les derniers mois. Je le remercie pour son soutien et encouragement surtout durant les moments de doutes.
Je remercie toute ma famille, mes fr`eres, ma soeur et ma cousine Zouhour pour leur incroyable soutien.
Durant ma th`ese, j’ai beaucoup appris de mes deux directrices de th`ese qui sont devenues pour moi des amies. Elles ´etaient toujours `a mes cˆot´es avec leurs conseils et leurs id´ees. Je n’oublierai jamais leur confiance en moi et leur soutien continuel.
Je tiens `a remercier messieurs Mohamed Kissi et Mohamed Ramdani de l’universit´e Hassan II Mohammedia - Maroc pour leur aide et leur soutien pour rendre possible ce travail en nous fournissant leurs donn´ees de test pour la perception des odeurs. Je remercie aussi monsieur Serge Guillaume pour ses explications par rapport `a FisPro et ses conseils pour la r´ealisation de mes tests. Mes remerciements vont ´egalement `a Docteur Manel Dardour Gaied et Docteur Nawfel Gaddour pour leurs conseils et leurs suggestions sur le traitement de l’autisme infantile.
J’aimerais exprimer ma plus profonde gratitude `a tous les membres du jury pour m’avoir fait l’honneur d’accepter d’´evaluer ma th`ese.
Je remercie aussi toutes les personnes du LIRMM pour leurs aide `a chacun de mes s´ejours `a Montpellier surtout Nicolas et Guylaine. Je remercie tous
Je remercie tous ceux avec qui j’ai collabor´e durant mes trois ann´ees de th`ese. C’´etait une exp´erience incroyable pour ˆetre en contact avec des personnes de diff´erents domaines. J’ai beaucoup appris durant cette p´eriode et pas qu’en informatique.
Je voudrais ´egalement remercier mes amis en Tunisie pour leur soutien. Et je ne regretterai jamais les nouveaux amis que j’ai rencontr´es `a Montpellier. Ces amis sont loin d’ˆetre oubli´es, ils ont leur place dans mon cœur et ma m´emoire. Nous avons pass´e trois ans de folies et d’aventures.
Je tiens `a remercier toutes les personnes qui m’ont aid´ees pendant ma th`ese et tous ceux que j’ai rencontr´es lors des conf´erences et des formations qui m’ont permis d’avoir un autre angle de vue sur mes travaux de recherche.
In most daily activities, humans use imprecise information derived from appreciation instead of exact measurements to make decisions. Various ap-proaches were proposed to deal with such knowledge, in particular, fuzzy logic and multi-valued logic. In this work, we treat the particular case of imprecise knowledge within multi-valued logic.
Taking into account imprecise knowledge by computer systems is based on their representation by means of linguistic variables. Their values form a set of words expressing the different nuances of the treated information. For example, to judge the beauty of the Mona Lisa or the smell of a flower, it is not possible to give an exact value but an appreciation is given by a term like “beautiful” or “floral”.
In the literature, dealing with imprecise information relies on an implicit assumption : the distribution of terms is uniform on a scale ranging from 0 to 1. Nevertheless, in some cases, a sub-domain of this scale may be more informative and may include more terms. In this case, knowledge are re-presented by means of an unbalanced terms set, that is, not uniformly nor symmetrically distributed.
We have noticed, in the literature, that in the context of fuzzy logic many researchers have dealt with these term sets. However, it is not the case for multi-valued logic. Thereby, in our work, we aim to establish a methodology to represent and manage this kind of data in the context of multi-valued logic. Two aspects are treated. The first one concerns the representation of terms within an unbalanced multi-set. The second deals with the treatment of such kind of imprecise knowledge, i.e. with symbolic modifiers and in reasoning process.
and treat such term sets. First of all, we introduce algorithms that allow representing unbalanced terms within uniform ones and the inverse way. Then, we describe a method to use linguistic modifiers within unbalanced multi-sets. Afterward, we present a reasoning approach based on the Ge-neralized Modus Ponens model using GeGe-neralized Symbolic Modifiers. The proposed models are implemented in a novel rule-based decision system for the camphor odor recognition within unbalanced multi-set. We also develop a tool for child autism diagnosis by means of unbalanced severity degrees of the Childhood Autism Rating Scale (CARS).
Durant nos activit´es quotidiennes, nous avons tendance `a utiliser des in-formations issues de constatations et non de mesures exactes. La prise en compte de ce type de connaissances, dites impr´ecises, par des syst`emes in-formatiques s’appuie sur une repr´esentation des donn´ees par des variables linguistiques. Leurs valeurs sont group´ees sous forme d’un ensemble de mots exprimant les diff´erentes nuances de l’information trait´ee. Par exemple, pour juger de la beaut´e de La Joconde ou de l’odeur d’un muguet, il n’est pas possible d’´enoncer une valeur exacte mais une appr´eciation est donn´ee par le biais d’un terme comme “beau” ou “floral”. De mˆeme, les d´ecisions sont prises en pr´esence d’un grand nombre de donn´ees impr´ecises en utilisant des notions qualitatives plus que quantitatives. Par exemple, l’odeur camphr´ee d’une mol´ecule d’alcool d´epend de sa forme et de sa taille. Ces deux donn´ees sont d´ecrites avec des termes telles que “sph´erique”, “petite” ou “moyenne”. Diverses approches ont ´et´e propos´ees pour traiter les connaissances impr´ecises, en particulier, la logique floue et la logique multivalente. La premi`ere se base sur les ensembles flous de Zadeh alors que la seconde uti-lise les multi-ensembles de De Glas. Dans la litt´erature, le traitement de l’information impr´ecise repose sur une hypoth`ese implicite de la r´epartition uniforme des degr´es de v´erit´es sur une ´echelle de 0 `a 1. N´eanmoins, dans certains cas, un sous-domaine de cette ´echelle peut ˆetre plus informa-tif et peut inclure plus de termes. Dans ce cas, l’information est d´efinie par des termes d´es´equilibr´es, c’est-`a-dire qui ne sont pas uniform´ement r´epartis et/ou sym´etriques par rapport `a un terme milieu. Par exemple, pour l’´evaluation des apprenants, il est possible de consid´erer un seul terme n´egatif F correspondant `a l’´echec. Quant `a la r´eussite, elle est d´ecrite par plusieurs valeurs de mention, i.e. D, C, B et A. Ainsi, si le terme D est le
Nous avons remarqu´e, dans la litt´erature, que de nombreux chercheurs ont trait´e ce type particulier d’ensembles de termes dans le contexte de la logique floue. Toutefois, ce n’est pas le cas pour la logique multivalente. Dans ce travail, notre objectif est d’´etablir une m´ethodologie pour repr´esenter et g´erer ce type de donn´ees dans le contexte de la logique multivalente. Dans ce travail, nous nous concentrons sur l’extension de cette logique au cas des ensembles non uniformes. En s’appuyant sur notre ´etude de l’art, nous proposons de nouvelles approches pour repr´esenter et traiter ces ensembles de termes. Tout d’abord, nous introduisons des algorithmes qui permettent de repr´esenter des termes non uniformes `a l’aide de termes uniformes et inversement. Ensuite, nous d´ecrivons une m´ethode pour utiliser des modi-ficateurs linguistiques initialement d´efinis pour les termes uniformes avec des ensembles de termes non uniformes. Par la suite, nous pr´esentons une approche de raisonnement bas´ee sur le mod`ele du Modus Ponens G´en´eralis´e `
a l’aide des Modificateurs Symboliques G´en´eralis´es. Les mod`eles propos´es sont mis en œuvre dans un nouveau syst`eme de d´ecision fond´e sur des r`egles pour la reconnaissance de l’odeur de camphre. Nous d´eveloppons ´egalement un outil pour le diagnostic de l’autisme infantile. Les degr´es de s´ev´erit´e de l’atteinte par ce trouble autistique sont repr´esent´es par l’´echelle d’´evaluation de l’autisme infantile (CARS). Il s’agit d’une ´echelle non uniforme.
Participation `a des ouvrages
Nouha CHAOUED, Amel BORGI and Anne LAURENT. Representing and Managing Unbalanced Multi-sets In Knowledge Discovery, Knowledge Engineering and Know-ledge Management - 7th International Joint Conference, IC3K 2015, Lisbon, Portugal, November 12-14, 2015, Revised Selected Papers, pages 213-233. Springer International Publishing, Cham.
Conf´erences internationales
Nouha CHAOUED, Amel BORGI and Anne LAURENT. Symbolic Approximate Reasoning within Unbalanced Multi-Sets : application to Autism Diagnosis (regular paper- `a paraitre). In AICCSA 2017 - 14th ACS/IEEE International Conference on Computer Systems and Applications, Hammamet, Tunisia, October 30th to November 3rd (2017)
Nouha CHAOUED, Amel BORGI and Anne LAURENT. Camphor Odor Re-cognition within Unbalanced Multi-Sets (regular paper - `a paraitre) In Proceedings of Fuzz-IEEE 2017 - IEEE International Conference on Fuzzy Systems, Naples, Italy, July 09-12 (2017)
Nouha CHAOUED, Amel BORGI and Anne LAURENT. Linguistic Modifiers with Unbalanced Term Sets in Multi-valued Logic (regular paper). In Proceedings of the 7th International Joint Conference on Knowledge Discovery, Knowledge En-gineering and Knowledge Management (KEOD 2015), Lisbon, Portugal, November November 12-14, 2015. pp. 50–60 (2015).
Nouha CHAOUED and Amel BORGI. Representation of unbalanced terms in multi-valued logic (regular paper). In the 12th IEEE International Multi-Conference on Systems, Signals & Devices (SSD 2015)
1 Introduction g´en´erale 1
1.1 Repr´esentation des connaissances et raisonnement . . . 3
1.2 Ensembles non uniformes . . . 4
1.3 Probl´ematiques et contributions . . . 5
1.4 Organisation de la th`ese . . . 7
I Etat de l’art sur la repr´esentation et le traitement des connaissances impr´ecises 9 2 Repr´esentation des connaissances impr´ecises 9 2.1 Introduction . . . 9
2.2 Des logiques non classiques . . . 11
2.2.1 La logique Floue . . . 12
2.2.2 La logique Multivalente . . . 14
2.2.2.1 Notion de multi-ensemble . . . 14
2.2.2.2 Les modificateurs . . . 15
2.2.2.3 Agr´egation des degr´es de v´erit´e . . . 16
2.2.2.4 Similarit´e multi-ensembliste . . . 17
2.2.2.5 Rapports de cardinalit´e d’El Sayed . . . 17
2.3 La repr´esentation des connaissances impr´ecises non uni-form´ement distribu´ees . . . 22
2.3.1 En logique floue . . . 23
2.3.1.1 Approche de Herrera et Martinez . . . 23
2.3.1.2 Approche de Cabrerizo et al. . . 30
2.3.1.3 Approche de Abchir et Truck . . . 31 2.3.1.4 Comparatif des algorithmes de repr´esentation 35
2.3.2 En logique multivalente . . . 37
2.4 Conclusion . . . 43
3 Traitement des connaissances impr´ecises 45 3.1 Introduction . . . 45
3.2 Les modificateurs symboliques . . . 47
3.2.1 Approche d’Akdag et al. . . 47
3.2.2 Approche d’El Sayed . . . 55
3.3 Raisonnement approximatif symbolique . . . 59
3.3.1 R`egle simple . . . 66
3.3.1.1 R`egle simple avec multi-ensembles homog`enes 66 3.3.1.2 R`egle simple avec multi-ensembles h´et´erog`enes 66 3.3.2 R`egle complexe . . . 67
3.3.2.1 R`egle complexe avec multi-ensembles ho-mog`enes . . . 67
3.3.2.2 R`egle complexe avec multi-ensembles h´et´erog`enes . . . 68
3.4 Conclusion . . . 70
II Extension de la logique multivalente aux multi-ensembles non uniformes 71 4 Contributions th´eoriques pour la repr´esentation et le trai-tement des multi-ensembles non unifomes 71 4.1 Introduction . . . 71
4.2 Les multi-ensembles non uniformes . . . 72
4.3 Repr´esentation des multi-ensembles non uniformes . . . 73
4.3.1 Repr´esentation des termes non uniformes avec des multi-ensembles uniformes : Approche num´erique . . . 74
4.3.2 Repr´esentation des termes uniformes avec un multi-ensemble uniforme : Approche symbolique . . . 80
4.3.3 Repr´esentation des termes uniformes avec des multi-ensembles non uniformes . . . 84
4.4 Modificateurs symboliques et multi-ensembles non uniformes 85 4.5 Raisonnement approximatif . . . 88
4.5.1 R`egle simple . . . 89
4.5.1.1 R`egle simple avec multi-ensembles homog`enes 90 4.5.1.2 R`egle simple avec multi-ensembles h´et´erog`enes 92 4.5.2 R`egle complexe . . . 96
4.5.2.1 R`egle complexe avec multi-ensembles
ho-mog`enes . . . 97
4.5.2.2 R`egle complexe avec multi-ensembles h´et´erog`enes . . . 100
4.6 Conclusions . . . 104
5 Perception de l’odeur de camphre 105 5.1 Introduction . . . 105
5.2 Perception des odeurs . . . 106
5.3 Construction d’un classificateur d’odeur . . . 108
5.3.1 Construction de la base de connaissances . . . 108
5.3.2 R´ealisation du syst`eme OPUM . . . 113
5.4 Etude exp´erimentale . . . 116 5.4.1 Proc`edure de test . . . 116 5.4.2 Pr´esentation de FisPro . . . 118 5.4.3 Premier test . . . 120 5.4.4 Deuxi`eme test . . . 124 5.4.5 Troisi`eme test . . . 126 5.4.6 R´esultats comparatifs . . . 126 5.5 Conclusion . . . 128
6 Diagnostic de l’autisme infantile 129 6.1 Introduction . . . 129
6.2 Diagnostic de l’autisme . . . 130
6.3 Construction du syst`eme . . . 132
6.3.1 Pr´esentation de RAMOLI . . . 132
6.3.2 Conception de la base de connaissances . . . 136
6.3.3 R´ealisation du syst`eme . . . 138 6.4 R´esultats Exp´erimentaux . . . 140 6.4.1 Proc`edure de test . . . 140 6.4.2 Premier test . . . 143 6.4.3 Deuxi`eme Test . . . 143 6.4.4 Troisi`eme test . . . 145 6.4.5 Quatri`eme test . . . 146 6.4.6 R´esultats comparatifs . . . 148 6.5 Conclusion . . . 151
III Conclusion g´en´erale 153
7 Conclusion g´en´erale 153
7.1 Synth`ese des contributions . . . 153
7.2 Perspectives . . . 155
IV Annexes 157 Annexe A Les modificateurs linguistiques flous 159 A.1 Les modificateurs de pr´ecision . . . 161
A.1.1 Approche de Despr`es . . . 161
A.1.2 La α-coupe . . . 166
A.1.3 L’approche de Bosc . . . 167
A.2 Les modificateurs de translation . . . 169
2.1 Ensemble non uniforme de 4 termes linguistiques . . . 10 2.2 Echelles multi-granulaires floues (Herrera et al., 2008) . . . . .´ 11 2.3 Variable linguistique d´ecrivant la superficie d’un logement
(Bouchon-Meunier, 1995) . . . 12 2.4 Echelle de 7 degr´es de v´erit´e symboliques . . . 15 2.5 Exemple d’une hi´erarchie linguistique de 3 niveaux(Herrera
et al., 2001) . . . 24 2.6 Hi´erarchie linguistique ´etendue(Espinilla et al., 2011) . . . 25 2.7 Exemple d’une repr´esentation d’un 2-tuple (s2,−0.3) (Herrera
et Mart´ınez, 2001) . . . 26 2.8 Repr´esentation des notes anglosaxones (Herrera et al., 2008) . 27 2.9 Partitionnement flou non uniform´ement distribu´e (Herrera
et al., 2001) . . . 29 2.10 Partitionnement flou non uniform´ement distribu´e . . . 31 2.11 Repr´esentation des taux d’alcool´emie selon la l´egislation
am´ericaine . . . 34 2.12 Partitionnement floue non uniform´ement distribu´e (Abchir et
Truck, 2013) . . . 36 2.13 R´esultat du partitionnement flou (Abchir et Truck, 2013) . . 38 2.14 Exemple d’utilisation du Stretch Factor (Abchir et Truck, 2013) 39 2.15 Exemple d’application de l’approche de Abchir utilisant les
MSG (Abchir, 2013) . . . 40 2.16 Deuxi`eme exemple d’application de l’approche de Abchir
uti-lisant les MSG (Abchir, 2013) . . . 41 2.17 Exemple complet de l’approche de Abchir(Abchir, 2013) . . . 42
3.1 Effets des modificateurs g´en´eralis´es affaiblissant et
ren-for¸cants (Truck, 2002) . . . 52
3.2 Effets des modificateurs g´en´eralis´es EC et EC′ (cas opti-miste) (Truck, 2002) . . . 53
3.3 Effets des modificateurs g´en´eralis´es DC et DC′ (cas opti-miste)(Truck, 2002) . . . 54
3.4 R´eglette repr´esentant un multi-ensemble (a) Les degr´es d’ap-partenances, (b) Les objets (El-Sayed, 2001) . . . 57
3.5 Modificateurs de pr´ecision (El-Sayed, 2001) . . . 58
3.6 Modificateur de translation (El-Sayed, 2001) . . . 58
3.7 Modificateurs de translation (El-Sayed, 2001) . . . 59
4.1 D´efinition d’un multi-ensemble non uniforme . . . 75
4.2 Multi-ensemble non uniforme de 7 termes linguistiques . . . . 77
4.3 Les multi-ensembles uniformes LMk . . . 78
4.4 Repr´esentation de termes non uniformes dans une ´echelle uni-forme . . . 78
4.5 Repr´esentation du multi-ensemble non uniforme L8 . . . 79
4.6 Repr´esentation du multi-ensemble non uniforme L8 . . . 79
4.7 Repr´esentation du multi-ensemble uniforme L9 . . . 81
4.8 Repr´esentation avec le multi-ensemble uniforme L9 . . . 83
4.9 R´esultat de l’agorithme UniformToUnbalanced . . . 85
4.10 Application du modificateur CR6 au terme non uniforme τ2 . 89 4.11 Repr´esentation de la variable Sph´erique . . . 94
4.12 Repr´esentation de la variable Camphr´ee . . . 94
4.13 Tranformation de Ls 3 . . . 95
4.14 Tranformation de Lc3 . . . 95
4.15 Ensemble non uniforme de 7 termes . . . 98
4.16 Repr´esentation de la variable Autiste . . . 102
5.1 Extrait du fichier de donn´ees utilis´e . . . 109
5.2 Fonction d’appartenance floue de la variable Sph´erique . . . . 110
5.3 Fonction d’appartenance floue de la variable Surface . . . 110
5.4 Fonction d’appartenance floue de la variable Camphr´ee . . . . 111
5.5 Transformation d’un ensemble floue en un multiensemble -cas de 2 termes . . . 111
5.6 Transformation d’un ensemble floue en un multiensemble -cas de N termes . . . 112
5.7 Repr´esentation du multi-ensemble Sph´erique . . . 112
5.9 Repr´esentation du multi-ensemble Camphr´ee . . . 112
5.10 Repr´esentation du multi-ensemble Dense . . . 113
5.11 Exemple des multi-ensembles utilis´es . . . 114
5.12 Liste des pr´edicats . . . 114
5.13 Liste des variables linguistiques . . . 115
5.14 Liste des faits . . . 115
5.15 Exemple d’une base de r`egles . . . 116
5.16 R´esultat de la classification . . . 116
5.17 Protocole de test en logique multivalente . . . 117
5.18 Protocole de test en logique floue . . . 118
5.19 Interface utilisateur de FisPro . . . 119
5.20 Interface pour les performances d’une inf´erence . . . 120
5.21 Exemple d’un syst`eme d’inf´erence . . . 120
5.22 Exemple d’une entr´ee . . . 121
5.23 Exemple d’une sortie . . . 122
5.24 Exemple d’une base de r`egles . . . 122
5.25 Repr´esentation du multi-ensemble Camphr´ee . . . 123
5.26 Fonction d’appartenance floue de la variable Dense . . . 125
6.1 Fenˆetre de gestion des multi-ensembles . . . 133
6.2 Fenˆetre de gestion des variables linguistiques . . . 134
6.3 Fenˆetre de gestion des pr´edicats . . . 134
6.4 Fenˆetre de gestion des faits . . . 135
6.5 Fenˆetre de gestion des r`egles . . . 135
6.6 Questionnaire de diagnostic . . . 139
6.7 Diagnostic d’un patient . . . 140
6.8 Les symptˆomes d’un patient . . . 141
6.9 R`egles de diagnostic d’autisme . . . 141
6.10 Protocole de test . . . 142
6.11 Multi-ensemble uniforme L7 . . . 143
6.12 Repr´esentation du multi-ensemble L′7 pour le deuxi`eme test . 144 6.13 Repr´esentation du multi-ensemble L′′7 pour le troisi`eme test . 146 6.14 Repr´esentation du multi-ensemble L′′′7 pour le quatri`eme test 147 A.1 Fonction d’appartenance d’un sous-ensemble floue . . . 160
A.2 Les modificateurs Tr`es et plus ou moins (Zadeh, 1979) . . . 160
A.3 Modificateurs de la classe λ-pr´ecis´ement (Despr`es, 1988) . . . 162
A.4 Modificateurs de la classe µ -tr`es (Despr`es, 1988) . . . 162
A.5 Modificateurs de la classe ν-tr`es exactement (Despr`es, 1988) . 163 A.6 Modificateurs de la classe π-plutˆot (Despr`es, 1988) . . . 164
A.7 Modificateurs de la classe ρ-approximativement (Despr`es, 1988)164 A.8 Modificateurs de la classe σ-environ (Despr`es, 1988) . . . 165 A.9 Modificateurs de la classe contrastante (Despr`es, 1988) . . . . 165 A.10 Modificateurs de la classe concentrante (Despr`es, 1988) . . . . 166 A.11 Exemples de α − coupe (Truck et al., 2001) . . . 166 A.12 Op´eration de dilatation par le modificateur EZ(F ) (Bosc
et al., 2007) . . . 168 A.13 Op´eration d’´erosion par le modificateur EZ(F ) (Bosc et al.,
2007) . . . 169 A.14 Effet des modificateurs adaptatifs sur la fonction
2.1 Exemples de T-normes et T-conormes . . . 17 2.2 Table de multiplication symbolique (El-Sayed, 2001) . . . 19 2.3 Table de division symbolique (El-Sayed, 2001) . . . 20 2.4 Hi´erarchie linguistique . . . 23 2.5 R´esultat de l’approche de Abchir et Truck sur les taux
d’al-cool´emie (Abchir et Truck, 2013) . . . 35 3.1 Modificateurs symboliques (Akdag et al., 2001) . . . 49 3.2 Les Modificateurs Symboliques G´en´eralis´es (Truck, 2002) . . . 51 3.3 R´esultats de l’agr´egation avec AT (Kacem et al., 2015) . . . . 65 3.4 R´esultats de l’agr´egation avec AS (Kacem et al., 2015) . . . . 65 5.1 R´esultats du premier test . . . 124 5.2 R´esultats du deuxi`eme test . . . 126 5.3 R´esultats du troisi`eme test . . . 127 5.4 R´esultats de la classification en logique multivalente . . . 127 6.1 R´esultats du premier test . . . 144 6.2 R´esultats selon diff´erentes m´etriques pour le premier test avec
l’agr´egateur Max . . . 144 6.3 R´esultats du deuxi`eme test . . . 145 6.4 R´esultats selon diff´erentes m´etriques pour le deuxi`eme test
avec l’agr´egateur Max . . . 145 6.5 R´esultats du troisi`eme test . . . 146 6.6 R´esultats selon diff´erentes m´etriques pour le troisi`eme test
avec l’agr´egateur Max . . . 147 6.7 R´esultats du quatri`eme test . . . 147
6.8 R´esultats selon diff´erentes m´etriques pour le quatri`eme test avec l’agr´egateur Max . . . 148 6.9 R´esultats selon diff´erentes m´etriques - Cas Max . . . 149 6.10 R´esultats selon diff´erentes m´etriques - Cas Moyenne . . . 150
Introduction g´
en´
erale
Dans la plupart des activit´es quotidiennes, l’Homme a tendance `a manipu-ler des connaissances imparfaites. L’imperfection se rapporte `a trois volets : l’impr´ecision, l’incertitude et l’incompl´etude. Le premier existe quand il n’est pas possible d’´evaluer une donn´ee de fa¸con pr´ecise avec des mesures exactes ceci peut alors ˆetre fait par des approximations en utilisant des descrip-tions qualitatives. Par exemple dire que le seisme est de forte magnitude est moins pr´ecis que dire qu’il est d’une magnitude de 6. Le second se rapporte au doute sur la validit´e d’une connaissance en raison du manque de fiabilit´e de la source ou d’erreurs de mesures. Dans ce cas, on ne sait pas si l’infor-mation est vraie ou fausse. Elle d´epend de la connaissance de la personne. Quant au troisi`eme, il concerne l’absence d’informations ou une information partielle. Ceci survient quand des valeurs manquent `a la description de cer-taines connaissances. Si une personne annonce qu’il y a eu un seisme, cette information est pr´ecise et certaine mais incompl`ete au sens o`u on ne connais pas sa magnitude, son emplacement et ses d´egats.
Diverses approches ont ´et´e propos´ees pour traiter les connaissances impr´ecises. Nous allons nous int´eresser en particulier `a la logique floue et la logique multivalente. Les th´eories des ensembles flous et des multi-ensembles sont un moyen tr`es appropri´e pour la repr´esentation et la mod´elisation de l’impr´ecision.
Dans la litt´erature, le traitement de l’information impr´ecise repose sur une hypoth`ese implicite de la r´epartition uniforme des degr´es de v´erit´e sur une
´echelle de 0 `a 1. N´eanmoins, dans certains cas, un sous-domaine de cette ´echelle peut ˆetre plus informatif et peut inclure plus de termes. Dans ce cas, l’information est d´efinie par des termes d´es´equilibr´es, c’est-`a-dire qui ne sont pas uniform´ement r´epartis et/ou sym´etriques par rapport `a un terme milieu. Par exemple, pour l’´evaluation des apprenants, il est possible de consid´erer un seul terme n´egatif F correspondant `a l’´echec. Quant `a la r´eussite, elle est d´ecrite par plusieurs valeurs de mention, i.e. D, C, B et A. Ainsi, si le terme Dest le seuil de la r´eussite, il est consid´er´e comme le terme milieu avec un seul terme `a sa gauche et trois `a sa droite. Il s’agit alors d’un ensemble non uniforme.
Nous avons remarqu´e, dans la litt´erature, que de nombreux chercheurs ont trait´e ces ensembles de termes dans le contexte de la logique floue. Toutefois, ce n’est pas le cas pour la logique multivalente.
Cette th`ese traite la repr´esentation et le traitement des connaissances impr´ecises non uniformes dans le cadre de la logique multivalente. Dans ce travail, nous nous int´eressons au traitement qualitatif de l’information impr´ecise dans les syst`emes `a base de connaissances.
Pour fournir son expertise, l’expert humain utilise g´en´eralement des termes ou des expressions qualitatifs du langage comme “la temp´erature est ´el´ev´ee” ou “l’odeur est d´esagr´eable”. Il s’agit de donn´ees impr´ecises dont la gestion se d´eroule en deux ´etapes. La premi`ere concerne leur repr´esentation. La seconde se rapporte au raisonnement sur celles-ci. Ces deux aspects sont ´etudi´es dans ce travail.
Notre travail s’inscrit dans le contexte de la logique multivalente. Celle-ci permet de repr´esenter symboliquement des connaissances impr´eCelle-cises en utilisant des expressions adverbiales ordonn´ees du langage naturel (De Glas, 1989). L’utilisation de ces degr´es symboliques est plus compr´ehensible par les experts que des valeurs num´eriques. Ce type de repr´esentation de donn´ees est ind´ependant du type de leurs domaines de discours. Ainsi, la manipulation des connaissances abstraites ou faisant r´ef´erence `a des ´echelles num´eriques se fait de la mˆeme mani`ere.
La contribution de la th`ese concerne la prise en compte du cas particulier o`u les degr`es de v´erit´e ne sont pas uniformes.
Ce chapitre est structur´e comme suit. Dans la premi`ere section, nous com-men¸cons par une introduction du contexte g´en´eral de la th`ese. Dans la se-conde, nous pr´esentons l’utilit´e des ensembles non uniformes. Par la suite, dans la section 3, nous introduisons les probl`ematiques de la th`ese ainsi que
nos contributions. La section 4 conclut ce chapitre en pr´esentant la structure de la th`ese.
1.1
Repr´
esentation des connaissances et
raisonne-ment
La repr´esentation des connaissances et le raisonnement comptent parmi les principaux sujets trait´es en intelligence artificielle. Ils concernent la repr´esentation des connaissances humaines dans l’objectif de proc´eder `a un raisonnement permettant ainsi de d´eduire de nouvelles connaissances. Le plus grand dilemme est alors de trouver la meilleure repr´esentation des donn´ees permettant d’obtenir des r´esultats qui s’approchent le plus de ceux du raisonnement humain. En effet, le succ`es d’une approche de raisonnement d´epend ´etroitement de la logique utilis´ee pour la repr´esentation.
La prise en compte des connaissances impr´ecises par des syst`emes infor-matiques s’appuie sur une repr´esentation des donn´ees par des variables lin-guistiques. Leurs valeurs sont group´ees sous forme d’un ensemble de mots exprimant les diff´erentes nuances de l’information trait´ee. Par exemple, la difficult´e d’une activit´e peut ˆetre d´ecrite en utilisant l’ensemble des termes : “pas du tout”, “peu”, “moyennement” et “tr`es”. Ainsi, dire que l’escalade est moyennement difficile indique que l’escalade appartient `a l’ensemble ac-tivit´e difficile avec le degr´e moyennement.
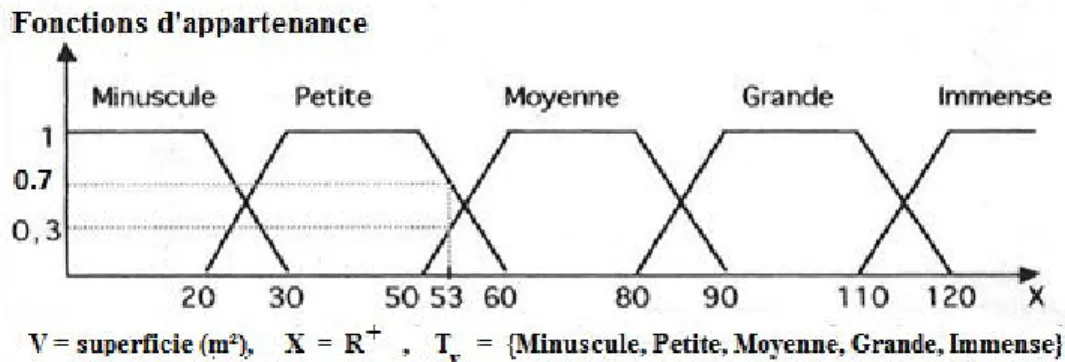
Pour d´ecrire la superficie d’un appartement, il est possible d’utiliser les termes : “minuscule”, “petit”, “moyen” et “grand”. En logique classique, un appartement de 20 m2 peut ˆetre consid´er´e comme petit ou non. Ainsi, l’appartenance de la superficie de l’appartement `a la cat´egorie petit ne peut ˆetre que vraie (valeur 1) ou fausse (valeur 0). Par contre, en logique multi-valu´ee, qui fait partie des logiques non classiques, cet appartement peut ˆetre consid´er´e comme petit `a 60% et moyen `a 40%. Ceci correspond `a une diff´erence entre le jugement des personnes questionn´ees sur la superficie de l’appartement. Il s’agit alors d’une appartenance partielle entre 0 et 1. Diff´erentes logiques multi-valu´ees existent dans la litterature. Les deux prin-cipales sont la logique floue et la logique multivalente. La premi`ere se base sur la th´eorie des sous-ensembles flous de Zadeh (1965) permettant de repr´esenter les propri´et´es impr´ecises comme “large”, “adulte” ou “grande”. Les fonctions d’appartenance y sont d´efinies sur une ´echelle num´erique de 0
`
a 1. La logique floue permet de repr´esenter des donn´ees impr´ecises principa-lement num´eriques. Ceci implique de simuler, arbitrairement, des domaines num´eriques pour d´efinir les termes abstraits (El-Sayed, 2001). La fonction d’appartenance floue est toujours num´erique et appartient `a l’intervalle [0,1], or dans de nombreux cas il est difficile d’estimer une appartenance par un degr´e num´erique. La d´etermination de la fonction d’appartenance floue n’est pas toujours triviale comme l’indique Medasani et al. (1998).
Quant `a la logique multivalente, elle se base sur la th´eorie des multi-ensembles de De Glas (1989). Elle permet de repr´esenter de fa¸con symbolique les connaissances impr´ecises ind´ependamment du type de leurs domaines de d´efinition. Ainsi, toutes les donn´ees, qu’elles soient abstraites ou faisant r´ef´erence `a une ´echelle num´erique, sont manipul´ees de la mˆeme mani`ere. Un multi-ensemble est repr´esent´e sous forme d’une ´echelle ordonn´ee et finie de M symboles (Akdag et Pacholczyk, 1989) : LM = {τ0, τ1, ..., τ(M −1)}; M ≥ 2. τi est appel´e degr´e d’appartenance au multi-ensemble. Il correspond `a un terme du langage naturel.
1.2
Ensembles non uniformes
En logique multivalente, les nombreux travaux existant dans la litt´erature traitant de la repr´esentation des donn´ees impr´ecises se basent sur une hy-poth`ese implicite de la r´epartition uniforme des degr´es de v´erit´e sur une ´echelle de 0 `a 1. Dans ce cas, la distance entre deux termes successifs est la mˆeme sur toute l’´echelle. Une deuxi`eme hypoth`ese existe dans certains travaux, `a savoir que le nombre de termes de l’ensemble ne d´epasse pas 7 et est toujours impair pour garantir l’existence d’un terme mileu.
N´eanmoins, dans certains cas, un sous-domaine de l’ensemble peut ˆetre plus informatif. Ceci implique plus de termes dans ce sous-domaine en particulier par rapport au reste de l’ensemble. Dans ce cas, l’information est d´efinie par des termes d´es´equilibr´es, c’est-`a-dire qui ne sont pas uniform´ement r´epartis et/ou sym´etriques par rapport `a un terme milieu. Il s’agit des ensembles non uniformes.
Un premier exemple concret d’utilisation de ces ensembles est l’´evaluation des apprenants. En effet, l’intervalle de notes de 0 `a 9,99 est assimil´e `a un ´echec. Tandis que si la note est sup´erieure `a 10, une mention est g´en´eralement associ´ee `a la note. De ce fait, des intervalles plus fins sont mis en place. Ainsi,
le degr´e de finesse de l’information n’est pas le mˆeme `a droite et `a gauche de 10.
Xia et Xu (2015) ont propos´e d’utiliser ces ensembles dans un contexte ´economique. Ils indiquent que l’investissement d’un mˆeme montant est diff´erent si l’entreprise est performante ou pas. Dans ce cas, nous avons besoin d’une information plus pr´ecise pour une entreprise non performante. De mˆeme, l’´ecart entre les termes n’expriment pas la mˆeme information dans les deux cas. Par exemple, la diff´erence entre “petit investissement” et “moyen investissement” dans le cas d’une entreprise performante n’est pas identique `a celle entre ces deux types d’investissement pour une entreprise non performante.
Consid´erons un autre exemple dans le contexte de la psychiatrie, plus pr´ecis´ement au niveau de l’´echelle d’´evaluation de l’autisme infantile in-troduit par Schopler et al. (1980), le degr´e de s´ev´erit´e de l’autisme d´epend du score obtenu `a un questionnaire :
— Un score inf´erieur `a 30 ne permet pas de diagnostiquer l’autisme ; — Un score entre 30 et 37 repr´esente un diagnostic d’autisme de l´eger `a
moyen ;
— Un score sup´erieur `a 37 correspond `a un diagnostic d’autisme s´ev`ere. Nous remarquons que la r´epartition n’est pas uniforme : la diff´erence entre un enfant non autiste et un autre l´eg`erement autiste n’est pas la mˆeme que celle entre un enfant moyennement autiste et un autre qui l’est s´ev`erement. Dans un ensemble non uniforme, chaque terme du langage naturel est associ´e `
a un degr´e τi. Il repr´esente une valeur possible d’une variable linguistique. Les termes du multi-ensemble ne sont pas ´equidistants les uns des autres. Les distances s´eparant les couples de termes successifs ne sont alors pas ´egales. Cette in´egalit´e indique que la diff´erence entre la signification de deux termes successifs n’est pas conserv´ee tout au long de l’´echelle.
1.3
Probl´
ematiques et contributions
Dans ce travail, nous nous int´eressons `a la logique multivalente. Les nom-breux travaux men´es dans le cadre de cette logique se basent sur une hy-poth`ese implicite de r´epartition uniforme des degr´es de v´erit´e (Akdag et al.,
1992; Akdag et Mokhtari, 1996; El-Sayed et Pacholczyk, 2003; Khoukhi, 1996; Pacholczyk, 1992). De nombreux probl`emes sont concern´es par une r´epartition non uniforme des degr´es. Dans ces cas, la granularit´e de l’´echelle des degr´es n’est pas la mˆeme sur toute l’´echelle et la pr´ecision peut ˆetre plus ou moins fine. Dans le cadre de la logique multivalente, peu de travaux ont port´e sur la r´epartition non uniform´ement distribu´ee des degr´es de v´erit´e (Abchir, 2013; Kacem et al., 2013). Les principaux travaux traitant de cet aspect l’ont ´et´e dans un cadre flou. Ils ont ´et´e initi´es par Herrera et Mart´ınez (2001) et Herrera et al. (2008). Le traitement d’un tel ensemble de degr´es “non ´equilibr´es” dans le contexte de la logique multivalente est un axe de recherche peu explor´e.
L’objectif de cette th`ese est d’´etudier l’extension de la logique multiva-lente au cas de degr´es non uniform´ement r´epartis. Cette extension concerne diff´erents points trait´es dans la litt´erature multivalente comme les modifi-cateurs linguistiques ou le raisonnement approximatif.
Durant la th`ese, nous avons commenc´e par une ´etude bibliographique sur les logiques floue et multivalente, et plus pr´ecis´ement sur la repr´esentation et le traitement des donn´ees non uniform´ement r´eparties.
Cette ´etude a permis de proposer une extension de la logique multivalente au cas des multi-ensembles non uniformes. Trois algorithmes ont ´et´e propos´es (Chaoued et al., 2015b). Les deux premiers visent `a repr´esenter de tels degr´es dans un contexte uniforme. Quant au troisi`eme, il permet la repr´esentation inverse, c’est-`a-dire celle de degr´es uniformes dans une ´echelle de degr´es non uniformes.
En nous basant sur ces algorithmes, nous avons propos´e une d´emarche pour l’utilisation des modificateurs linguistiques avec des degr´es non uniformes (Chaoued et al., 2015b,a). De mˆeme, un mod`ele de raisonnement approxi-matif avec de telles donn´ees a ´et´e introduit.
Afin d’appliquer les diff´erentes propositions th´eoriques, nous avons mis en place deux applications concr`etes. La premi`ere concerne la perception de l’odeur camphr´ee pour des mol´ecules d’alcool aliphatique. Quant `a la se-conde, elle se rapporte au diagnostic de l’autisme infantile.
1.4
Organisation de la th`
ese
Cette th`ese est constitu´ee d’un chapitre introductif ainsi que de trois prin-cipales parties. La premi`ere pr´esente la synth`ese des travaux de l’´etat de l’art, la seconde d´etaille les principales contributions et la derni`ere conclut le manuscrit et discute des perspectives de recherche. Nous pr´esentons leurs contenus ci-apr`es.
Le chapitre 1 introduit la th`ese en pr´esentant le contexte, les probl´ematiques de recherche abord´ees et les contributions issues de nos tra-vaux.
La premi`ere partie de cette th`ese, intitul´ee Synth`ese des travaux de l’´etat de l’art pr´esente le contexte de nos travaux. Compte tenu du cadre de notre th`ese, nous avons ax´e l’´etat de l’art sur les logiques multi-valu´ees floue et multivalente, ainsi que les travaux de repr´esentation et de traitement des connaissances impr´ecises. Cette partie englobe deux chapitres :
— Le deuxi`eme chapitre intitul´e “Repr´esentation des connaissances impr´ecises” introduit les principaux concepts de base des logiques floue et multivalente. Il pr´esente aussi les principaux travaux traitant la repr´esentation des ensembles de degr`es non uniforme dans le contexte des logiques pr´ecit´ees. Ce chapitre met en ´evidence le fait que tr`es peu de travaux consid`erent ce type de connaissances en logique multiva-lente.
— Le troisi`eme chapitre intitul´e “Traitement des connaissances impr´ecises” aborde les diff´erents travaux de traitement des connais-sances dans le contexte de la logique multivalente. Deux aspects sont trait´es dans ce chapitre. Le premier concerne les modificateurs sym-boliques propos´e initialement par Akdag et al. (2001). Le deuxi`eme explique les principes de base du raisonement approximatif intro-duit en logique floue par Zadeh (1975a,b,c). Les mod`eles propos´es en litt´erature pour la mise en place d’un raisonnement approximatif en lo-gique multivalente sont aussi expos´es. Les diff´erents travaux pr´esent´es sont d´efinis pour les ensembles de degr´es uniformes.
La deuxi`eme partie de cette th`ese, intitul´ee Extension de la logique multiva-lente aux ensembles non uniformes, pr´esente nos contributions relatives `a la prise en compte des ensembles non uniformes en logique multivalente. Elle englobe trois chapitres comme suit :
— Le quatri`eme chapitre intitul´e “Contributions th´eoriques pour la repr´esentation et le traitement des multi-ensembles non unifomes” pr´esente nos contributions th´eoriques, relatives `a la repr´esentation et au traitement des ensembles de degr´es non uniformes. Nous com-men¸cons par introduire les algorithmes pour la repr´esentation des degr´es non uniformes par des degr`es uniformes et inversement. Par la suite, nous pr´esentons une approche pour l’utilisation des modifica-teurs symboliques pr´esent´es dans le chapitre 3. Nous proposons aussi un mod`ele pour le raisonnement approximatif en pr´esence de donn´ees impr´ecises non uniformes.
— Le cinqui`eme chapitre intitul´e “Perception de l’odeur de camphre” est d´edi´e `a la mise en place d’un syst`eme `a base de connaissances pour la reconnaissance de l’odeur de camphre. Le syst`eme propos´e est un moteur d’inf´erence dans le contexte de la logique multivalente non uniforme qui d´etecte l’odeur de camphre produite par 99 alcools aliphatiques avec une ou deux mol´ecules de carbone. Le r´esultat obtenu est sous forme d’un terme linguistique qualifiant l’intensit´e de l’odeur. — Le sixi`eme chapitre intitul´e “Diagnostic de l’autisme infantile” illustre la mise en place d’un outil pour le diagnostic de l’autisme chez les enfants. Nous proposons un syst`eme bas´e sur la logique mul-tivalente non uniforme permettant le d´epistage pr´ecoce de l’autisme chez les enfants de moins de trois ans. Notre outil sera utile pour les p´ediatres ou les ´educateurs qui sont en contact avec les enfants. La troisi`eme partie, intitul´ee Conclusion g´en´erale discute l’apport de nos contributions. Cette partie conclut cette th`ese et pr´esente nos perspectives de recherche.
Etat de l’art sur la
repr´
esentation et le
traitement des connaissances
Repr´
esentation des
connais-sances impr´
ecises
2.1
Introduction
La mod´elisation de la connaissance humaine dans les syst`emes `a base de connaissances doit tenir compte des impr´ecisions et des incertitudes qui l’entachent. En effet, dans certains domaines, il n’est pas possible, vu les conditions d’observation, de fournir une valeur exacte de ladite variable. Cela peut ˆetre dˆu par exemple `a l’impr´ecision de l’outil de mesure. Il est alors n´ecessaire de faire une approximation de sa valeur. Ceci peut se faire en utilisant une description qualitative par des termes du langage naturelle comme grande, acre ou ti`ede. Dans ce cadre, Bouchon-Meunier (1995) in-dique qu’une variable linguistique, notion introduite auparavant par Zadeh (1975a), “sert `a mod´eliser les connaissances impr´ecises ou vagues sur une variable dont la valeur pr´ecise peut ˆetre inconnue”.
Diff´erentes approches ont ´et´e propos´ees dans la litt´erature pour la repr´esentation et le traitement des connaissances impr´ecises. Les deux ap-proches les plus utilis´ees sont la logique floue bas´ee sur la th´eorie des sous-ensembles flous de Zadeh (1965), et la logique multivalente fond´ee sur la th´eorie des multi-ensembles de De Glas (1989). Il s’agit d’une g´en´eralisation des ensembles classiques. Dans la logique classique, l’appartenance d’un ´el´ement x `a un sous-ensemble A ne peut ˆetre que vraie (valeur 1) ou fausse
(valeur 0). Cependant, celle d’un ´el´ement x `a un sous-ensemble flou ou `a un multi-ensemble A est partielle. Dans le cas flou, le degr´e d’appartenance de x `a A est compris entre 0 et 1.
L’approche floue comme l’approche multivalente proposent une mod´elisation symbolique des degr´es d’appartenance. Celle-ci permet une caract´erisation moins sp´ecifique que celle num´erique, et n´ecessite ainsi moins d’informations manipul´ees dans le cadre d’un syst`eme de raisonnement.
Les travaux men´es dans le cadre de la repr´esentation et du traitement des connaissances impr´ecises se basent sur une hypoth`ese implicite de la r´epartition uniforme des degr´es. De ce fait, la distance entre les termes deux `
a deux successifs est la mˆeme. Cependant, dans certains cas un sous-domaine de l’ensemble peut ˆetre plus informatif. Ceci implique plus de termes dans ce sous-domaine en particulier en comparaison avec le reste de l’ensemble. Dans ces cas, la r´epartition des degr´es n’est pas la mˆeme sur toute l’´echelle et la pr´ecision peut ˆetre plus ou moins fine.
Par exemple, pour la perception des odeurs, l’expert consid`ere un seul terme n´egatif, i.e. Pas du tout, qui correspond `a aucune odeur per¸cue. Alors qu’il est n´ecessaire d’avoir une information plus pr´ecise quand il y a une odeur per¸cue. Ainsi, l’odeur peut ˆetre d´ecrite avec des termes tels que Faible, L´eg`ere ou Forte (Figure 2.1). Il est important de pr´eciser que dans ce cas, les termes ne sont pas ´equidistants c’est-`a-dire que la distance entre les termes successifs deux `a deux n’est pas identique. Cette distance traduit un ´ecart en terme de sens qu’on leur attache.
Pas du tout Faible L`eg`ere Forte
Figure 2.1 – Ensemble non uniforme de 4 termes linguistiques
Dans d’autres cas, plusieurs experts sont sollicit´es pour la prise de d´ecision afin d’obtenir la d´ecision la plus fiable possible. Les experts peuvent ´evaluer leurs connaissances avec des ´echelles uniformes de tailles et distributions diff´erentes (Figure 2.2). Ainsi, l’ensemble utilis´e par le syst`eme inclut des termes provenant de ces diff´erentes ´echelles. Ceci implique la non uniformit´e de l’´echelle, comme l’illustrent les degr´es A, B, C, D et F sur la figure 2.2. La fonction d’appartenance correspondant `a ces termes est la combinaison des parties marqu´ees en gras dans les fonctions d’appartenance uniformes. Dans le cadre de la logique floue, diff´erents travaux ont utilis´e les
sous-Figure 2.2 – ´Echelles multi-granulaires floues (Herrera et al., 2008)
ensembles non uniformes (Wang et Hao, 2006; Herrera-Viedma et L´opez-Herrera, 2007; Herrera et al., 2008; Dong et al., 2009, 2013; Dong et Herrera-Viedma, 2015). Cependant dans le contexte de la logique multivalente peu de travaux ont ´et´e faites pour la prise en compte de ce type de donn´ees (Abchir, 2013).
Il est alors indispensable de consid`erer de tels ensembles de degr´es “non ´equilibr´es” dans le contexte de la logique multivalente. L’objectif de notre travail est alors d’´etendre cette logique pour la prise en compte des connais-sances impr´ecises non uniform´ement distribu´ees.
Tout d’abord, il est int´eressant d’expliquer les principes de base des deux logiques cit´ees pr´ec´edemment. Dans ce chapitre, nous pr´esentons les travaux effectu´es aussi bien dans le cadre de la logique floue que multivalente.
2.2
Des logiques non classiques
Les informations manipul´ees par les humains sont le plus souvent impar-faites. Ces imperfections se manifestent sous de multiples formes : ambigu¨ıt´e,
incompl´etude, impr´ecision, incertitude ou incoh´erence. Sans oublier le ca-ract`ere variable et ´evolutif des informations relatives au monde dynamique. Ainsi il est particuli`erement important pour les experts d’inclure ces imper-fections dans la repr´esentation de leurs connaissances et dans les mod`eles de raisonnement. Plusieurs approches ont ´et´e propos´ees dans la litt´erature pour la prise en compte de ces connaissances, les plus connues sont la logique floue (Zadeh, 1965) et la logique multivalente (De Glas, 1989).
Dans ce qui suit nous allons pr´esenter les notions de base des logiques floue et multivalente avant de passer dans la section suivante aux approches exis-tantes de repr´esentation des ensembles non uniformes.
2.2.1 La logique Floue
La logique floue (Zadeh, 1965) ´etend la logique classique en introduisant un aspect graduel dans le but de formaliser et de traiter des concepts vagues, impr´ecis ou de nature incertaine. Selon cette logique, chaque terme est repr´esent´e par un sous-ensemble flou.
La particularit´e des sous-ensembles flous est d’une part l’appartenance par-tielle d’un ´el´ement `a un sous-ensemble, et d’autre part l’appartenance `a plusieurs sous-ensembles avec des degr´es diff´erents. Dans certains cas un chevauchement entre les sous-ensembles existe et il est dˆu `a l’aspect graduel d’appartenance des ´el´ements aux sous-ensembles flous (Figure 2.3).
Figure 2.3 – Variable linguistique d´ecrivant la superficie d’un logement (Bouchon-Meunier, 1995)
Les donn´ees sont repr´esent´ees par des variables linguistiques. Celles-ci ont ´et´e introduites par Zadeh (1975a). Leurs valeurs ne sont pas num´eriques
mais symboliques utilisant des mots du langage naturel. Ainsi, une variable linguistique (Figure 2.3) est une variable prenant ses valeurs dans un en-semble de termes linguistiques (Zadeh, 1975a). Ces derniers expriment les diff´erentes nuances, symbolis´ees par des mots, de l’information trait´ee. Un terme linguistique peut ˆetre interpr´et´e comme une ´etiquette d’un sous-ensemble flou sur les valeurs de la variable num´erique de base (Zadeh, 1975a). En d´ecrivant par exemple la superficie d’un logement, dire qu’elle est mi-nuscule est moins sp´ecifique que dire qu’elle fait 9m2. Ainsi minuscule est un terme linguistique de la variable surface ce qui est ´equivalent `a la valeur num´erique 9m2 mais dans un contexte moins informatif et moins pr´ecis. En effet, le mˆeme terme inclut un ensemble de valeurs num´eriques. Ainsi, chaque terme linguistique est associ´e `a un sous-ensemble flou. La s´emantique de ces termes est donn´ee par la fonction d’appartenance (Bouchon-Meunier, 1995). D´efinition 1 Un sous-ensemble flou A de l’ensemble de r´ef´erence X est d´efini par une fonction d’appartenance qui associe `a chaque ´el´ement x de X le degr´e fA(x), compris entre 0 et 1, avec lequel x appartient `a A :
fA : X → [0, 1]
Un sous-ensemble flou est d´efini par sa fonction d’appartenance. Il est alors important de connaˆıtre la meilleure fa¸con de la d´eterminer que ce soit de fa¸con manuelle ou automatique. Medasani et al. (1998) soulignent l’impor-tance de l’extraction de la fonction d’appartenance `a partir de donn´ees associ´ees `a l’application de la logique floue. Cependant il n’existe pas de r`egle `a suivre pour g´en´erer la fonction d’appartenance appropri´ee. Un autre probl`eme est mis en avant, `a savoir le manque de consensus par rapport `a la d´efinition et l’interpr´etation des fonctions d’appartenance ce qui rend leur g´en´eration une tˆache d´elicate et non triviale. Par exemple dire que le degr´e d’appartenance d’un logement A au sous-ensemble flou petite est de 0.7 peut ˆetre compris de diverses fa¸cons tels que 70% de la population d´eclare que A est petite ou que A est distant de 0.3 de la valeur id´eale pour qu’un A puisse ˆetre consid´er´e comme petite. Ceci implique l’existence d’une multitude de m´ethodes pour la g´en´eration des fonctions d’appartenance qui d´epend de l’interpr´etation de celles-ci. Les auteurs notent aussi l’absence de moyens pour mesurer la qualit´e et l’exactitude de la fonction g´en´er´ee surtout quand il s’agit de concepts abstraits qualitatifs. Ainsi, la g´en´eration des fonctions d’appartenance n’est pas toujours triviale. Le succ`es de l’utilisation de la logique floue d´epend de la fonction d’appartenance utilis´ee (Medasani et al., 1998).
2.2.2 La logique Multivalente
De Glas (1989) souligne que la logique floue interpr`ete mal les termes du point de vue s´emantique. L’univers du discours peut ˆetre discret, qualitatif ou num´erique. La logique floue permet de repr´esenter des donn´ees impr´ecises principalement num´eriques. Ceci implique de simuler, arbitrairement, des domaines num´eriques pour d´efinir les termes abstraits. La fonction d’ap-partenance floue est toujours num´erique et appartient `a l’intervalle [0,1], or dans de nombreux cas il est difficile d’estimer une appartenance par un degr´e num´erique. Par exemple pour la perception des odeurs, il est difficile de l’exprimer avec un nombre.
2.2.2.1 Notion de multi-ensemble
De Glas (1989) a propos´e la logique multivalente pour traiter les connais-sances imprecises. Chaque terme linguistique est repr´esent´e par un multi-ensemble. Dans celui-ci, les informations sont exprim´ees sous forme d’une ´echelle LM ordonn´ee et finie de symboles (Akdag et Pacholczyk, 1989).
LM ={τ0, τ1, ..., τ(M −1)}; M ≥ 2 (2.1) avec τi les degr´es d’appartenance aux multi-ensembles(i ∈ [0, M − 1]). Il est `a noter que ces degr´es sont reli´es uniquement par une relation d’ordre total ≤, d´efinie par Akdag et al. (1992) :
τα≤ τβ ⇐⇒ α ≤ β; ∀α et β ∈ [0, M − 1] (2.2) Dans la majorit´e des travaux existants relatifs `a cette logique, ces degr´es sont suppos´es ˆetre uniform´ement r´epartis sur l’´echelle repr´esentant LM. La relation d’appartenance en logique multivalente est partielle :
x∈αA⇐⇒ x appartient `a A `a un degr´e α (2.3) Pour exprimer l’impr´ecision d’un pr´edicat, un qualificateur linguistique ϑα est associ´e `a chaque degr´e :
x est ϑα A ⇐⇒ (x est ϑα A) est vrai
Par exemple, dire que l’odeur est peu acre signifie que l’odeur (x ) satisfait le pr´edicat acre (A) avec le degr´e τ2 repr´esent´e par l’adverbe peu comme le montre la figure 2.4.
Figure2.4 – Echelle de 7 degr´es de v´erit´e symboliques
L’ensemble des degr´es de v´erit´e des multi-ensembles forme un treillis de Morgan {LM,⋁, ⋀, ¬, ≤} (Akdag et Pacholczyk, 1989) avec :
— LM ={τ0, τ1, ..., τ(M −1)} l’ensemble fini des M degr´es de v´erit´es, muni de la relation d’ordre total ≤ d´efinie par l’´equation 2.2 ;
— ⋁ un op´erateur de disjonction tel que τα∨ τβ = τmax(α,β) — ⋀ un op´erateur de conjonction tel que τα∧ τβ = τmin(α,β)
— ¬ un op´erateur de n´egation tel que ¬τα= τn(α) avec n(α) = M − α − 1
2.2.2.2 Les modificateurs
La modification de donn´ees en logique multivalente se fait par une transfor-mation du degr´e ou/et de l’´echelle du multi-ensemble. Cela aboutit `a une dilatation ou une ´erosion de l’´echelle.
Les travaux de Zadeh (1972) et plus r´ecemment ceux de Akdag et al. (2000, 2001) et Truck (2002) ont port´e sur le fait que tout sous-ensemble flou ou multi-ensemble peut ˆetre consid´er´e comme ´etant le modificateur d’un autre sous-ensemble flou ou multi-ensemble respectivement. Des modificateurs lin-guistiques symboliques ont ´et´e propos´es par Akdag et al. (2000, 2001) dans le contexte de la logique multivalente. Ils ont ´et´e g´en´eralis´es et formalis´es par Truck (2002), et nomm´es Modificateurs Symboliques G´en´eralis´es (MSG). Ces modificateurs seront plus d´etaill´es dans le chapitre suivant.
Il est `a noter qu’`a chaque degr´e linguistique de l’ensemble consid´er´e, Ak-dag et al. (2000, 2001) associent un taux ou degr´e d’intensit´e. En effet, un ´el´ement de l’ensemble peut ˆetre assimil´e `a un degr´e de pr´ecision d’une proposition et interpr´et´e comme une proportion associ´ee `a chaque τi. La proportion prop(τi) peut ˆetre vue comme le poids du degr´e τi par rapport `a
l’ensemble linguistique LM, c’est-`a-dire sa proportion par rapport au totale-ment vrai (τM−1). Elle correspond donc au quotient du degr´e consid´er´e par rapport au degr´e maximal : prop(τi) = p(τM−1i) = Mi−1; avec p(τi) la position dans l’´echelle du degr´e τi.
2.2.2.3 Agr´egation des degr´es de v´erit´e
Il est souvent n´ecessaire d’agr´eger plusieurs degr´es de v´erit´e dans une conjonction ou une disjonction de propositions dans le cadre d’un raison-nement par exemple. Il s’agit de combiner plusieurs valeurs, i.e. degr´es sym-boliques appartenant `a LM, en une seule.
Dans la litt´erature, il existe plusieurs agr´egateurs. Les principales sont les T-normes, T-conormes et les implications. Dans le contexte de la logique multivalente ce sont des applications de : LM × LM → LM
D´efinition 2 (El-Sayed, 2001) En logique multivalente, une T-norme T est une application de LM× LM dans LM satisfaisant les relations suivantes :
T1 - T(τ0, τα) = τ0
T2 - T(τβ, τM−1) = τβ
T3 - T(τα, τβ) = T(τβ, τα)
T4 - { τβ1 ≤ τβ2 et τα1 ≤ τα2 } ⇒ {T(τβ1, τα1) ≤ T(τβ2, τα2)}
T5 - T(τα, T(τβ, τγ)) = T(T(τα, τβ), τγ)
D´efinition 3 (El-Sayed, 2001) En logique multivalente, une T-conorme S est une application de LM×LM dans LM satisfaisant les relations suivantes : S1 - S(τα, τ0) = τα
S2 - S(τα, τβ) = S(τβ, τα)
S3 - S(τα, S(τβ, τγ)) = S (S(τα, τβ), τγ)
S4 - { τβ1 ≤ τβ2 et τα1 ≤ τα2 } ⇒ { S(τα1, τβ1) ≤ S(τα2, τβ2)}
D´efinition 4 (El-Sayed, 2001) Si T est une T-norme, toute application S telle que :
S(τα, τβ) =∼ T(∼ τα,∼ τβ) est une T-conorme.
Comme exemple de T-normes et T-conormes, nous pouvons citer ceux de Zadeh (1965) et de Lukasiewicz (Table 2.1).
Table 2.1 – Exemples de T-normes et T-conormes
Auteur T(τα, τβ) S(τα, τβ)
Zadeh min(τα, τβ) max(τα, τβ)
Lukasiewicz { τ0 si α+ β ≤ M − 1
τα+β−M −1 sinon {
τM−1 si α+ β ≥ M − 1 τα+β sinon
D´efinition 5 (El-Sayed, 2001) L’implication→ est une application de LM× LM dans LM qui satisfait les propri´et´es suivantes : ∀(τα, τβ, τγ) ∈ L3M
1. τM−1→ τβ = τβ
2. τα→ τβ = τβ= τM−1⇔ τα≤ τβ 3. τα→ (τβ → τα) = τM−1
4. (τα→ (τβ → τγ)) → (τβ→ (τα→ τγ)) = τM−1 5. (τα→ τβ) → ((τβ→ τγ) → (τα→ τγ)) = τM−1
L’implication de Lukasiewicz est d´efinie par : τα→Lτβ={
τM−1 si τα≤ τβ
τM−1−α+β sinon
2.2.2.4 Similarit´e multi-ensembliste
Une relation de similarit´e entre les multi-ensembles a ´et´e d´efinie par Akdag et al. (1992). Il s’agit d’une relation de similarit´e entre les degr´es de v´erit´e du multi-ensemble.
D´efinition 6 On dira que τα est τγ-voisin de τβ, not´ee ταϑγτβ, si et seule-ment si :
ταϑγτβ ⇔ τγ = Sim(τα, τβ) = Min {τα→ τβ, τβ→ τα }
2.2.2.5 Rapports de cardinalit´e d’El Sayed
El-Sayed (2001) a introduit la notion de cardinalit´e relative d’un terme A. En effet, celle-ci permet de connaitre la proportion des ´el´ements d’un ensemble qui satisfont A parmi ceux du domaine de discours Ω. Ainsi `a chaque degr´e τi, l’auteur lui associe une cardinalit´e Qα, celle-ci est alors not´ee A◂αΩ. Dans ce cas, Qα individus de Ω sont dans A :
A◂αΩ⇔ Qα= ∣A∣∣Ω∣, avec ∣.∣ la cardinalit´e de l’ensemble.
El-Sayed (2001) a propos´e un ensemble de degr´es symboliques de car-dinalit´e relative LQ9 : {rien-du-tout, moins-d’un-quart, environ-le-quart,
environ-le-tiers, environ-la-moiti´e, environ-les-deux-tiers, environ-les-trois-quarts, `a-peu-pr`es-´egale, ´egale}, sachant que “rien-du-tout” est not´e par Q1 et “´egale” par Q9. L9 est bas´e sur l’ensemble linguistique L9 : {pas-du-tout, peu, relativement-peu, plutˆot-peu, moyennement-peu, plutˆot, relativement, presque, tout-`a-fait}. Ainsi, l’indice α est le num´ero d’ordre du degr´e sym-bolique dans LQ9 correspondant au quotient. Nous rappelons que les indices
des degr´es symboliques de cardinalit´e relative appartenant `a l’ensemble QM comme d´efinis El-Sayed (2001) sont de 1 `a M et non de 0 `a (M-1) comme dans la d´efinition de De Glas (1989).
Par exemple, dire qu’environ-le-quart des ´el`eves d’une classe sont des filles se traduit par F Q3 Ω avec :
— Ω le domaine de discours `a savoir tous les ´el`eves de la classe ; — F est l’ensemble des filles de la classe ;
— Q3 est le rapport de cardinalit´e vu que 3 est le num´ero d’odre de environ-le-quart dans LQ9.
L’auteur part aussi du principe que connaissant la cardinalit´e relative de deux ensembles A (∣A∣∣Ω∣) et B (∣B∣∣Ω∣) dans Ω tels que ∣A∣∣Ω∣ ≥ ∣B∣∣Ω∣, il est possible de d´eterminer leur rapport de cardinalit´e : ∣B∣∣A∣ =
∣B∣ ∣Ω∣ ∣A∣ ∣Ω∣
.
D´efinition 7 (El-Sayed, 2001) La multiplication symbolique I (Table 2.2) est une application d´efinie de Q2
M dans QM satisfaisant les propri´et´es sui-vantes : — ∀(Qα, Qβ) ∈ Q2M, I(Qα, Qβ) = I(Qβ, Qα) — ∀Qβ ∈ QM, I(Q1, Qβ) = Q1 — ∀Qα∈ QM, I(Qα, QM) = Qα — Si Qβ1 ≤ Qβ2 alors I(Qα, Qβ1) ≤ I(Qα, Qβ2) — ∀(Qα, Qβ, Qλ) ∈ Q3M, I(I(Qα, Qβ), Qλ) = I(Qα, I(Qβ, Qλ))
D´efinition 8 (El-Sayed, 2001) La division symbolique C (Table 2.3) est une application de Q2
M dans P(QM) d´efinie `a partir de I de la mani`ere suivante : Qµ∈ C(Qα, Qλ) ⇔ Qλ= I(Qα, Qµ)
La table 2.3 est construite `a partir de celle de la multiplication symbolique (Table 2.2) en utilisant l’´equivalence entre les deux rapports. Ce choix est
Table 2.2 – Table de multiplication symbolique (El-Sayed, 2001) I Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8 Q9 Q1 Q1 Q1 Q1 Q1 Q1 Q1 Q1 Q1 Q1 Q2 Q1 Q2 Q2 Q2 Q2 Q2 Q2 Q2 Q2 Q3 Q1 Q2 Q2 Q2 Q2 Q2 Q2 Q3 Q3 Q4 Q1 Q2 Q2 Q2 Q2 Q2 Q3 Q4 Q4 Q5 Q1 Q2 Q2 Q2 Q2 Q3 Q4 Q5 Q5 Q6 Q1 Q2 Q2 Q2 Q3 Q4 Q5 Q6 Q6 Q7 Q1 Q2 Q2 Q3 Q4 Q5 Q6 Q7 Q7 Q8 Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8 Q8 Q9 Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8 Q9
fait par El Sayed afin que “les degr´es Qα soient s´emantiquement proches de leurs homologues num´eriques” (El-Sayed, 2001).
D´efinition 9 (El-Sayed, 2001) Soient A et B deux sous ensembles de Ω. Le rapport symbolique de la cardinalit´e de A par celle de B, not´e A⊴µ B, est d´efini comme suit :
— ∀α, ∀λ ∣ α ≤ λ, {A ◂αΩ, B◂λΩ⇒ A ⊴µB avec Qµ∈ C(Qλ, Qα) — ∀µ, A ⊴µB ⇒ {∃α, ∃λ ∣ Qα≤ Qλ, A◂αΩ, B◂λΩ telle que
Qµ∈ C(Qλ, Qα)}
Avec C l’op´erateur de division symbolique (D´efinition 8)
Pour l’exemple d´ej`a cit´e, nous pouvons exprimer la proportion des filles par rapport `a celle des gar¸cons au lieu de le faire par rapport `a l’ensemble de la classe. Rappelons que l’ensemble des filles est environ-le-quart (Q3) de la classe. Dans ce cas, l’ensemble des gar¸cons est environ-les-trois-quarts (Q7) de la classe. En appliquant la d´efinition 8, le rapport de cardinalit´e de l’ensemble des filles par celui de l’ensemble des gar¸cons est :
Qµ∈ C(Q7, Q3) = Q4
Nous pouvons alors dire que l’ensemble des filles est environ-le-tiers de celui des gar¸cons.
Au regard de la d´efinition 9, une condition est impos´ee pour l’utilisation de ce rapport, `a savoir que la cardinalit´e de A est inf´erieur `a celle de B. Parfois, l’expert exprime ses connaissances telles que la cadinalit´e de A est sup´erieur `
a B. Dans ce cas, il faut d´eduire une expression ´equivalente en exprimant B en fonction de A. Par exemple, dire que la cardinalit´e de A est environ 4 fois
T a bl e 2. 3 – T ab le d e d iv is ion sy m b ol iq u e (E l-S ay ed , 2001) C Q 1 Q 2 Q 3 Q 4 Q 5 Q 6 Q 7 Q 8 Q 9 Q 1 [Q 1 ,Q 9] ∅ ∅ ∅ ∅ ∅ ∅ ∅ ∅ Q 2 { Q 1} [Q 2 ,Q 9] ∅ ∅ ∅ ∅ ∅ ∅ ∅ Q 3 { Q 1} [Q 2 ,Q 7] [Q 8 ,Q 9] ∅ ∅ ∅ ∅ ∅ ∅ Q 4 { Q 1} [Q 2 ,Q 6] { Q 7} [Q 8 ,Q 9] ∅ ∅ ∅ ∅ ∅ Q 5 { Q 1} [Q 2 ,Q 5] { Q 6} { Q 7} [Q 8 ,Q 9] ∅ ∅ ∅ ∅ Q 6 { Q 1} [Q 2 ,Q 4] { Q 5} { Q 6} { Q 7} [Q 8 ,Q 9] ∅ ∅ ∅ Q 7 { Q 1} [Q 2 ,Q 3] { Q 4} { Q 5} { Q 6} { Q 7} [Q 8 ,Q 9] ∅ ∅ Q 8 { Q 1} { Q 2} { Q 3} { Q 4} { Q 5} { Q 6} { Q 7} [Q 8 ,Q 9] ∅ Q 9 { Q 1} { Q 2} { Q 3} { Q 4} { Q 5} { Q 6} { Q 7} { Q 8} { Q 9}
celle de B est ´equivalent `a dire que la cardinalit´e de B est environ-un-quart de celle de A.
Un autre op´erateur a ´et´e d´efini par El-Sayed (2001) `a savoir la somme symbo-lique permettant de calculer l’union de deux sous-ensembles disjoints. Celle-ci correspond `a la somme des degr´es Qα et Qβ repr´esentant les cardinalit´es relatives des deux sous-ensembles.
D´efinition 10 (El-Sayed, 2001) La somme symbolique est l’application SL d´efinie uniquement si α+ β ≤ M + 1 comme suit : SL(Qα, Qβ) = Qα+β+1. Elle satisfait les propri´et´es suivantes :
— Partiellement d´efinie ∀(Qα, Qβ), SL(Qα, Qβ) est d´efinie si Qβ≤∼ Qα — Compl´ementarit´e∀Qα, SL(Qα,∼ Qα) = QM
— Commutativit´e∀(Qα, Qβ), SL(Qα, Qβ) = SL(Qβ, Qα) — Associativit´e SL(SL(Qα, Qβ), Qγ) = SL(Qα, SL(Qβ), Qγ) — El´ement neutre ∀Qα, SL(Qα, Q1) = Qα
— Croissance Si Qβ1 ≤ Qβ2 alors SL(Qα, Qβ1) ≤ SL(Qα, Qβ2)
D´efinition 11 (El-Sayed, 2001) La soustraction symbolique DLest une ap-plication d´efinie uniquement si α ≥ β par : DL(Qα, Qβ) = Qα−β+1.
Au regard de la propri´et´e de compl´ementarit´e de la somme symbolique (D´efinition 10) et la d´efinition de la soustraction symbolique, il est possible de d´eduire la cardinalit´e compl´ementaire ∼ Qα `a partir de :
SL(Qα,∼ Qα) = QM ⇔ DL(QM, Qα) =∼ Qα
En appliquant la d´efinition de la soustraction, nous obtenons : ∼ Qα= QM−α+1
El-Sayed (2001) a aussi ´etudi´e la propagation des rapports symboliques de cardinalit´es pour deux relations ayant un argument en commun. Il a pro-pos´e, par la suite, une g´en´eralisation pour n relations. Dans ce qui suit nous pr´esentons les r`egles de propagation appliqu´ees dans le cas de plusieurs re-lations ⊴.
D´efinition 12 (El-Sayed, 2001) Transivit´e faible Soit (Qα, Qβ) ∈ Q2M.
Si { A ⊴βB et B ⊴αE } alors A ⊴γE avec Qγ= I(Qα, Qβ) Par exemple, si :
— La cardinalit´e de B est environ-la-moiti´e de celle de E
⇒ La cardinalit´e de A est environ-le-quart de celle de E : Q3= I(Q6, Q5) D´efinition 13 (El-Sayed, 2001) R´eduction `a droite
Soit(Qα, Qβ) ∈ Q2M. Si { A ⊴αE et B ⊴βE } alors : — B ⊴γA avec Qγ∈ C(Qα, Qβ) si Qα≥ Qβ — A ⊴γB avec Qγ∈ C(Qβ, Qα) si non Par exemple, si :
— La cardinalit´e de A est environ-les-deux-tiers de celle de E — La cardinalit´e de B est environ-la-moiti´e de celle de E ⇒ La cardinalit´e de B est environ-les-trois-quart de celle de A : C(Q6, Q5) = {Q7}
D´efinition 14 (El-Sayed, 2001) R´eduction `a gauche Soit(Qα, Qβ) ∈ Q2M. Si { A ⊴αE et A ⊴βB } alors :
— B ⊴γE avec Qγ∈ C(Qβ, Qα) si Qα≤ Qβ — E ⊴γB avec Qγ∈ C(Qα, Qβ) si non Par exemple, si :
— La cardinalit´e de A est environ-le-quart de celle de E — La cardinalit´e de A est environ-la-moiti´e de celle de B ⇒ La cardinalit´e de B est environ-les-deux-tiers de celle de E :
C(Q5, Q3) = {Q6}
2.3
La
repr´
esentation
des
connaissances
impr´
ecises non uniform´
ement distribu´
ees
Dans la section pr´ec´edente, nous avons pr´esent´e les deux principales lo-giques utilis´ees pour la mod´elisation des connaissances impr´ecises `a savoir la logique floue et la logique multivalente. Dans cette section, nous allons pr´esenter les travaux portant sur la mod´elisation des ensembles linguistiques non uniform´ement distribu´es dans le cadre des deux logiques pr´ecit´ees. Nous rappellons que la non uniformit´e peut ˆetre due `a la d´efinition mˆeme de la variable utilis´ee dans le sens o`u la pr´ecision n’est pas la mˆeme tout au long de l’´echelle. Elle peut exister aussi quand plusieurs experts interviennent
chacun avec sa propre ´echelle uniforme. L’ensemble des degr´es utilis´e in-clut alors des degr´es provenant d’ensembles de tailles et de distributions diff´erentes. Ceci correspond `a une ´echelle non uniforme.
2.3.1 En logique floue
Les principaux travaux traitant les connaissances non uniform´ement dis-tribu´ees dans le contexte de la logique floue ont ´et´e initi´es par Herrera et Mart´ınez (2001) et Herrera et al. (2008). Par la suite, Cabrerizo et al. (2009, 2010) ont propos´e une am´elioration de cette approche. Abchir et Truck (2012, 2013) ont critiqu´e l’approche de Herrera et Martinez et ont pr´esent´e une autre. Ces diff´erents travaux sont pr´esent´es dans ce qui suit.
2.3.1.1 Approche de Herrera et Martinez
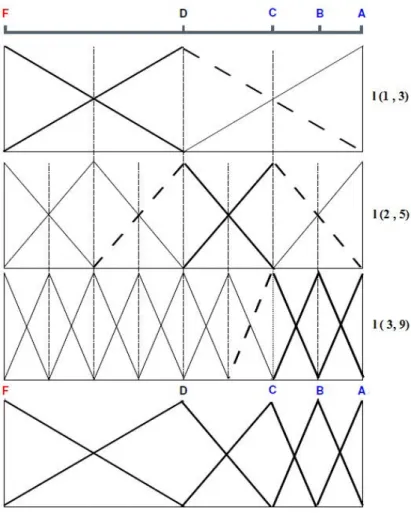
Pour travailler sur des ´echelles non uniform´ement distribu´ees, Herrera et Mart´ınez (2001) ont propos´e d’utiliser les hi´erarchies linguistiques floues. Une hi´erarchie linguistique (Herrera et Mart´ınez, 2001) est l’union de plu-sieurs ensembles de termes linguistiques appel´es niveaux de la hi´erarchie. Chaque niveau a un nombre de termes, nomm´e granularit´e, diff´erents des autres niveaux. Un niveau de la hi´erarchie est not´e l(t, n(t)) avec :
— t : un nombre indiquant le niveau de la hi´erarchie ;
— n(t) : la granularit´e du niveau t, c’est-`a-dire le nombre de termes lin-guistiques dans ce niveau. Chaque terme linguistique a une fonction d’appartenance de forme triangulaire. L’ensemble des fonctions est uni-form´ement et sym´etriquement distribu´e sur [0,1]. La granularit´e de chaque niveau est toujours impaire (Table 2.4).
Table 2.4 – Hi´erarchie linguistique
Niveau 1 Niveau 2 Niveau 3 Niveau 4
l(t, n(t)) l(1,3) l(2,5) l(3,9) l(4,17)
l(t, n(t)) l(1,7) l(2,13)
Il est `a noter que Herrera et Mart´ınez (2001) ont introduit deux hi´erarchies linguistiques. La premi`ere contenant quatre niveaux (premi`ere ligne de la table 2.4) et une seconde avec deux niveaux uniquement (deuxi`eme ligne