HAL Id: hal-02478104
https://hal.archives-ouvertes.fr/hal-02478104
Submitted on 13 Feb 2020
HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
typologie de trajectoires individuelles
Olivier Barbary, Luz Mary Pinzon Sarmiento
To cite this version:
Olivier Barbary, Luz Mary Pinzon Sarmiento. L’analyse harmonique qualitative et son application à la typologie de trajectoires individuelles. Mathématiques et Sciences Humaines, Centre de Mathématique Sociale et de statistique, EPHE, 1998. �hal-02478104�
O
LIVIER
B
ARBARY
L
UZ
M
ARY
P
INZON
S
ARMIENTO
L’analyse harmonique qualitative et son application à la
typologie des trajectoires individuelles
Mathématiques et sciences humaines, tome 144 (1998), p. 29-54. <http://www.numdam.org/item?id=MSH_1998__144__29_0>
© Centre d’analyse et de mathématiques sociales de l’EHESS, 1998, tous droits réservés. L’accès aux archives de la revue « Mathématiques et sciences humaines » (http://msh.revues. org/) implique l’accord avec les conditions générales d’utilisation (http://www.numdam.org/legal. php). Toute utilisation commerciale ou impression systématique est constitutive d’une infraction pénale. Toute copie ou impression de ce fichier doit contenir la présente mention de copyright.
Article numérisé dans le cadre du programme Numérisation de documents anciens mathématiques
L’ANALYSE
HARMONIQUE
QUALITATIVE
ET SON APPLICATIONÀ
LA TYPOLOGIE DES TRAJECTOIRESINDIVIDUELLES
Olivier
BARBARY1,
LuzMary
PINZONSARMIENTO2
RÉSUMÉ 2014 Cet article présente une synthèse théorique et pratique de
«l’analyse
harmonique qualitative» en tant qu’outil de statistique descriptive de processus aléatoires, et son application à l’étude de la mobilité humaine. Dans la première partie, on s’intéresse, d’un point de vue mathématique, à l’analyse harmonique d’un processus qualitatif et à son approximation par l’analyse decorrespondance
du tableau des durées de séjour des individus dans les étatspossibles
duprocessus3.
La deuxième et la troisième partie sontconsacrées à une application aux données d’une enquête sur la mobilité résidentielle et professionnelle, et les événements familiaux que connaissent les résidents de l’aire métropolitaine de Bogota. On y montre comment
la méthode fournit une typologie des trajectoires intra-urbaines et permet de la mettre en relation avec d’autres éléments de la
biographie
des individus.SUMMARY 2014 Nominal harmonic analysis applied to individual trajectories typology
The article aims at a theoretical and practical presentation «nonominal harmonic analysis» as a tool for descriptive statistic of categorical stochastic processes and its
application
to humanmobility
studies. The first part is a mathematical overview of the extension of scalar spectral analysis to a categorical process and how itcan be approximate by a
particular
kind of correspondences analysis based on times that individuals accumulate in the process states. The second and third parts deal withapplication
to a data set taken from asurvey on residential mobility in Bogota metropolitan area.
We found
the method able to provide an interesting typology of urban residential trajectories and to show some relationships between residentialmobility
and otherbiographical
variables like family events and professional changes.INTRODUCTION
La collecte de données
biographiques
est deplus
enplus fréquente
en sciences sociales. Dans l’étude des formes de la mobilitéhumaine,
elle tente derépondre
à desquestionnements
nouveaux, dans des contextes
thématiques, disciplinaires
etméthodologiques
variés.Qu’il
s’agisse
en effet de la mobilitéspatiale,
sociale ouéconomique,
de celle des individus ou desgroupes
sociaux,
d’approches démographiques, géographiques,
économiques
ousocio-anthropologiques, l’objet
de la recherche est àchaque
fois unphénomène
continu(les
vies1
Institut de Recherche pour le Développement (IRD, ex Orstom), Centro de investigaciôn y Documentaciôn
Socio Econômica (CIDSE) - Universidad del Valle, e-mail : olibarba@mafalda.univalle.edu.co. 2
Universidad Nacional de Colombia, e-mail : lpinzon @ ciencias.ciencias.unal.edu.co. 3
Un programme SAS développé par 0. Barbary, mettant en oeuvre l’ensemble de la méthode, est disponible sur demande à l’auteur.
humaines sont
composées
d’une infinitéd’instants,
delieux,
d’événements...).
Dèslors,
mêmesi aucun
système
d’observation nepeut
prétendre
rendrecompte
de cette continuité"théorique",
l’appareil
desconcepts
et des méthodes de collecte doit viser l’observation laplus
exhaustivepossible
dutemps
et des espaces danslesquels
se déroule la mobilité des hommes.Récemment,
ce domaine a connu de
grands progrès,
depuis
la définition de nouveauxconcepts
d’observationjusqu’à
la réalisationd’enquêtes
sur des échantillonsreprésentatifs.
Mais si l’on sait de mieux en mieux collecter les donnéesbiographiques,
de nombreuses difficultés subsistentquant
à leuranalyse,
particulièrement
dans lechamp
de lastatistique descriptive
où font encore défaut des méthodesrespectant
la richesse et la «continuité» des corpus. Alors que lapriorité
estgénéralement
d’obtenir unetypologie
destrajectoires
individuelles,
on s’en tient souvent à desanalyses
transversales ou à l’examen d’indicateurslongitudinaux
monovariés,
nécessairement réducteurs de l’informationoriginale.
Cependant,
lesacquis méthodologiques
sur lastatistique descriptive
multivariée des processus se sont diversifiés et deviennentprometteurs
(Van
DerHeijden
[ 1987]
est à notreconnaissance la
synthèse
laplus complète
à cejour).
Il fautrevenir,
pour situer lepoint
dedépart
de cesrecherches,
au travailpionnier
de Deville etSaporta (Analyse
harmonique
qualitative, [1980])
et à la thèse deSaporta
(Université
ParisVI,
[1981]) ;
c’est là sans aucundoute que se fondent au
plan théorique
les méthodesexploratoires,
etplus précisément
typologiques, d’analyse
des donnéesbiographiques.
Comme le ditSaporta
( [ 1981 ],
p. 10)
dansune introduction
clairvoyante
à uneépoque
où n’existent que très peu de données individuelleslongitudinales
sur des échantillonsimportants :
«leproblème ne
sera pas tant de découvrirdes
périodicités
comme lefait l’analyse spectrale,
que de trouver les traits dominants dedifférenciation
des évolutions des individus».Nous
partons
dans ce travail d’unetechnique déjà éprouvée, l’analyse harmonique
qualitative
(AHQ),
pour lacompléter
etl’appliquer
à l’étude de la mobilitéspatiale.
Lajustification
théorique
del’AHQ
estl’objet
de lapremière
partie :
avec cetteméthode,
l’analyse
factorielle des
correspondances
(Benzecri [1973])
trouve une nouvelleapplication
à latypologie
des données
longitudinales.
La secondepartie présente
rapidement l’enquête
sur la mobilité despopulations
de l’airemétropolitaine
deBogota
et décrit lesétapes
et lesproblèmes
de la mise enoeuvre de la méthode sur ces données
biographiques.
Dans la troisièmepartie,
àpartir
del’exemple
de certainsrésultats,
nous montrons que cetteapproche
est maintenantcomplètement
opérationnelle,
et tentons d’illustrer sesavantages,
ses limites et sesperspectives.
1.
BRÈVE
THÉORIE
DE L’ANALYSEHARMONIQUE QUALITATIVE
Nous allons décrire maintenant de manière
synthétique
les fondementsthéoriques
del’AHQ
jusqu’à
unepropriété
fondamentale dans lapratique : l’équivalence
avec uneanalyse
decorrespondance
particulière.
Nous passerons ensuite en revue lestechniques d’approximation
numérique
utilisées pour l’exécution del’AHQ.
Notreprésentation
s’en tiendra àl’énoncé,
sansdémonstration,
desprincipales étapes
de lajustification
de la méthode. Le lecteur intéressé parune
présentation
mathématique complète
doit s’en remettre aux travauxSaporta
[ 1981 ]
et Deville[1982] ;
on trouve dansSaporta
[1996]
une autreprésentation
synthétique
de la méthodeorientée vers
l’analyse
des donnéesbiographiques.
l.1.
Notations,
définitions etprincipe
L’analyse
harmonique
d’un processusqualitatif
part
de la donnée des éléments suivants :. un intervalle de
temps
T =[0, T J
munit de la mesure deLebesgue
et/3,
l’ensemble des· l’ensemble
fini Z
des modalités ou états du processus, de cardinalm, X
=~..., ~}
· un ensemble d’unités
statistiques
£2(ensemble
fini ou nond’individus),
munit d’uneprobabilité
P· un
processus X sur Ç2xT à valeur dans x :
1~
étant la variable indicatrice de l’événementXt
= x, nous noterons :, la
probabilité
et, la
probabilité
Un
codage
scalaire(ou
réel)
du processusX
est unefonction fde ZxT dans
i :
Bien
sûr,
dans l’ensemble de tous lescodages
scalaires deX,
certains sontplus
naturels etpratiques
que d’autres. Nous considérerons ici lescodages
de carréintégrable,
c’est-à-dire ceuxqui
vérifient :Un tel formalisme
«probabiliste»
peut
surprendre s’agissant
d’analyse
de données où ceque l’on observe en fin de
compte
ne sont que desfréquences. Saporta
([ 1981 ], pp.10-11 )
s’enexplique :
«si nous avons choisi deparler
de’processus’
et de’probabilité’
là où certainsne
pourraient
voir que ’courbes’ etf réquences’,
c’est que celangage
nous a semblé leplus
simple
à utiliser et le mieuxadapté
au cas d’uneinfinité
non dénombrable de variables. Ilreste
cependant
que nous avonstoujours
eu àl’esprit
lefait
que S~représente
unepopulation
d’individus et un processus un ensemble detrajectoires
individuelles».L’idée directrice du travail de Deville et
Saporta
est de faire lasynthèse
de deuxdémarches. La
première
consiste à se donner uncodage numérique
du processusqualitatif
et àen faire
l’analyse
harmonique
(d’où l’appellation
donnée à laméthode).
La seconde est dechoisir dans T une suite finie
d’instants,
OStl t2... t~
T,
pour effectuerl’analyse canonique
des variables
qualitatives Xtl,
En fait l’unité des deuxapproches apparaît
si l’on traite leproblème
comme celui de ladécomposition spectrale
d’unopérateur
caractérisant l’évolutiontemporelle
du processus(opérateur
analogue
à celui de la covariance d’un processusscalaire).
1.2.
L’analyse
spectrale
d’un processusqualitatif
Soit H
l’espace
de Hilbert des processus aléatoires réels sur £2XT de carréintégrable,
c’est-à-dire Soit le sous-espace
des processus constants dans le
temps
etL 2(X)
le sous-espaceengendré
par lescodages
tribu
engendrée
parXt.
se compose de variablesréelles, dépendantes
dutemps,
de laforme :
L’opérateur
d’espérance
conditionnelle àP1,
Et (~) =
E (§ / Xt ) ,
est donc laprojection
orthogonale
de surL2(Xt).
Lespropriétés
deE t
(E t
esthermitien,
idempotent
et derang au
plus égal
a m, le nombred’états)
et le fait que,inversement,
toutopérateur
ayant
cespropriétés
est uneespérance
conditionnelle relative à une variablequalitative
ayant
auplus m
modalités, permettent
de considérer commeéquivalents
l’opérateur
Et
et la variableXt.
Lesdépendances statistiques
entre deux instants t et s du processus sont donc résumées par leproduit
K(t, s j
desopérateurs Et
etEs,
fonction de H dans lui-même définie de manièreanalogue
à la fonction de covariance :avec :
où :
Les processus propres et leurs
génératrices
Saporta
[1981,
pp. 101-103]
et Deville[1982],
pp.61-62])
démontrent alors que K estcompact
et de trace finie
égale
à mT. K admet donc unedécomposition spectrale
en vecteurs propresçi,
appelés
«processus propres» :Les ’
sont des processus de variance totaleunité,
orthogonaux
dansH,
associés aux00
valeurs propres
positives
Ai
(avec
1 Â,
i=mT ),
satisfaisantl’équation :
i=l
Le
produit
tensorielç 0 ~ ’
1est
l’opérateur
de rang 1 deHqui
transforme leprocessus 1I’t
en le processusT
Et
puisque :
on a :
On définit maintenant une variable aléatoire
z~ ,
appelée génératrice
du processus propreoù il est clair que
zi
nedépend
pas dutemps
et, parconséquent, appartient
au sous-espaceL2(S2)
de On a donc~,1~‘ r
=Et(zi),
c’est-à-dire quepour
chaque
t, le processuspropre çi
s’obtient parprojection orthogonale
de/ sur
L2(Xt),
d’où le nom degénératrice.
En utilisant la nouvelle variable et en
intégrant
l’équation précédente,
on obtient :Si nous
appelons Q l’opérateur
1l’équation
(3)
devient :L’analyse spectrale
de K(processus
propresçi)
dans se déduit donc del’analyse
plus
simple
deQ
(génératrices
z‘ )
dansL2(S~).
Les
codages
propresUne autre forme de
l’équation
aux valeurs propres s’obtient en revenant àl’expression
(1)
de~t.
En abandonnant l’indice i poursimplifier
l’écriture, (2)
se transforme en :Par
conséquent,
et, par
identification,
lesystème d’équations :
En
résumé,
leséquations
(4)
et(5)
montrent queles z’
et lesat
forment deuxdécompositions
spectrales
du processus. Dans lapremière,
la série des variables aléatoires(z~,
i=l, .... m7)
sontindépendantes
dutemps
et dans laseconde,
lescodages
réels non aléatoiresx=l,...,m)
dépendent
dutemps.
Commel’analyse
canonique
généralisée,
l’analyse
harmonique qualitative
est basée sur la recherche de deux vecteurs aléatoires decorrélation maximum. Il
s’agit
d’identifier l’élémentzi
deL2(Q)
et le processus scalaire(codage
de deL2(Xt)
qui
ont la corrélation maximum dansL2(QxT),
puis
d’itérer ce processus sous la conditiond’orthonormalité ;
c’est-à-dire de fairel’analyse
canonique
des sous-espacesL2(S~)
etL2(X)
dans1.3.
Équivalence
avecl’analyse
descorrespondances
etapproximation numérique
del’AHQ
Supposons
maintenantqu’il
existe p
+ 1 instants tels que le processussoit stable sur
chaque
intervallejtj_1 ,
c’est-à-direqu’aucun
individu nechange
d’étatdurant ce
temps.
Soit 4j
lecodage
propre surE j
l’espérance
conditionnelle à~j
etlj
la
longueur
del’ intervalle j
(l j = tj - tj_ 1 ) ;
l’équation
(2)
devient :et
puisque
Étant
donné que lescodages
propres associés auxvariables 4k
sont des fonctionsconstantes sur chacun des intervalles de la
partition
deT,
lesystème d’équations
(5)
s’écrit de la manière suivante :Cette nouvelle forme
(5’)
correspond
àl’équation
fondamentale del’analyse canonique
généralisée. Quand
f2 estfini,
composé
de nindividus,
on retrouve uneanalyse
decorrespondance
particulière
(voir
G.Saporta
[ 1981 ],
pp. 110-111 et J.C. Deville[1982],
pp.
68-74).
Dans ce cas eneffet,
leséquations
(2’)
et(5’)
sont leséquations
del’analyse
descorrespondances
de l’ensemble des indicatrices des modalités d’étatsmultipliées
par les mesures des intervallestif.
Lescodages
réelsak sont
donc lesvecteurs propres de
l’analyse
descorrespondances
du tableaudisjonctif
à nlignes
(nombre
d’individus)
et mp colonnes(produit
du nombre d’états par le nombre d’intervalles de stabilitédu
processus),
dont la case élémentaire vaut 1 si l’individu est dans cet état durant cet intervallede
temps
et 0 sinon. Mais un tel tableaupeut
rarement être soumis àl’analyse,
à cause de sa taille et de sa structure très «clairsemée» due au fait que leschangements
individuels d’état nesont pas, en
général,
synchronisés.
Parexemple,
l’observation sur 600 individus de 3changements
d’état en moyenne d’une variable à 5 modalitésengendre
un tableaudisjonctif
pondéré
de 600lignes
et 9000colonnes,
avec seulement uncinquième
des cases nonnulles ;
ilest clair que son
analyse
ne donnera pas de résultattypologique
intéressant,
chaque
individu formant à lui seul untype.
La solution
pratique
consiste à diviser l’intervalle d’observation du processus en unnombre raisonnable d’intervalles
(de
durées constantes ounon),
sans tenircompte
deschangements
individuels d’état. Le tableau defréquence
est ensuite construit en calculant laproportion
detemps
passé
par les individus dans chacun des étatspossibles
des variables au cours dechaque
intervalle derecodage
(voir
ci-dessous la définition de la densité individuelle deséjour
dans lesétats).
Ce tableau est soumis àl’analyse
descorrespondances
et les résultatss’interprètent
avec lestechniques
habituelles. Il fautsouligner
que cetteanalyse,
si elle conserveintégralement
l’information sur les durées deprésence
des individus dans lesétats,
perd
enrevanche,
en cumulant lestemps
deséjour
au sein des intervalles derecodage,
l’ordre depassage dans les états et les retours éventuels
lorsque
ceschangements
interviennent dans unmême intervalle.
Il existe diverses
possibilités
pour ledécoupage
de lapériode
d’observation et le calcul desfréquences.
Lors de la division de l’intervalleen p intervalles
de
longueurs
égales
ou non(notons
2
cettepartition),
le choix destk
doits’appuyer
àla
fois,
comme nous le verrons par lasuite,
sur la connaissancepréalable
du processus(arguments
propres à ladiscipline qui
l’étudie),
et sur l’étude de la distribution deschangements
d’état des individus dans le
temps
(arguments
statistiques).
Une fois choisie lapartition
dutemps,
lecodage
scalaire du processus recherché(Y(i, j,k),
jex,
kE 1),
est une fonction àvaleur réelle définie sur le
produit
cartésien Notant letemps
deséjour
de l’individu i dansl’état j
au cours de l’intervalle Deville etSaporta [ 1980]
donnent àY(i, j, k)
la valeur c’est-à-dire laproportion
dutemps
total d’observation du processus(Tj
que l’individu i apassé
dansl’état j
durant l’intervalle detemps
que nousappellerons
aussi la densité deprésence
de l’individu dans l’état. Dans ce cas,quelle
que soit lapartition
de lamétrique
sur letemps
est uniforme et la somme dechaque
ligne
du tableauvaut 1
(100
% dutemps
d’observation del’individu).
L’interprétation
du tableau est alorsexactement celle d’une table de
contingence
qui
distribue la densité deprésence
des individus entre les états et les intervalles detemps.
Cependant,
dupoint
de vue du calculalgébrique
effectué lors del’analyse
factorielle,
rienn’oblige
à ce que les intervalles decodage
soient de même durée ou que lamétrique
sur letemps
soituniforme,
bien au contraire. D’unepart
plusieurs
arguments
statistiques
militent en faveurd’un
découpage plus
détaillé dans lespériodes
où leschangements
d’état sont nombreux etplus
relâché
lorsqu’ils
sont rares(voir
Deville[1982]
et Florette[1988]).
D’autrepart,
dupoint
devue de la
problématique qui
va nous occuper dans la suite(la
stratégie
résidentielle desindividus),
il est naturel de s’intéresserplus
spécialement
auxchangements
de résidencequi
surviennent àl’âge
adulte(plus particulièrement
lapériode
deplus
fortemobilité,
15-35 ans parexemple),
dont la décision revientgénéralement
àl’individu,
plutôt qu’aux
changements
de résidence durant l’enfance ou lavieillesse,
plus
souvent décidés par des tiers. Onpeut
alors avoir intérêt à faire varier lamétrique
dans différentssegments
de lapériode
d’observation.Ainsi,
onadopte
souvent la solutionqui
consiste à calculer la densité deprésence
desindividus dans les états par
rapport
à la durée dechaque
intervalle detemps :
proportion
de la durée de l’intervalle que l’individu i apassé
dansl’état j.
Dans ce cas la somme d’uneligne
du tableau vaut p, le nombre d’intervalles définis dans et si les intervalles sont delongueur
variable,
lamétrique
sur letemps
n’estplus
uniforme. C’est cette méthode que nous avonsappliquée
aux données del’enquête
deBogota.
Lesalgorithmes correspondant
à l’ensemble destechniques
présentées
dans cette section ont été
programmés
sous SAS.2.
L’ENQUÊTE
ET L’APPLICATION DEL’AHQ
2.1. La collecte des données
Contexte et
problématique
L’enquête
etl’analyse
statistique
présentées
ici s’inscrivent dans une rechercheentreprise depuis
août 1992 par une
équipe
de chercheurs du C.E.D.E.(Centro
de Estudios sobre el DesarolloEconômico,
de l’Université des Andes -Colombie)
et del’ I . R. D .4
sur la mobilité despopulations
deBogota
et sonimpact
sur ladynamique
de l’airemétropolitaine.
Parallèlement àce programme s’est
développé depuis
février 1994 un programme de recherche encoopération
entre l’I.R.D. et le
département
demathématiques
etstatistique
de l’Université Nationale deColombie sur les méthodes
d’analyse statistique
des donnéesbiographiques5.
Bogota
est lamétropole
latino-américainequi
a connu la croissancedémographique
laplus
rapide
durant les annéescinquante
et soixante(plus
de 6 % paran).
Entre 1951 et 1964 la ville adoublé sa
population
et en 1970 ellecomptait
2,5
millions d’habitants.Depuis
unevingtaine
d’années,
lerythme
de croissance de lacapitale
colombienne,
comme celui des autresmétropoles
dusous-continent,
s’est ralenti : il était d’environ2,5
% annuel lors du dernierrecensement en 1985. Au moment de
l’enquête
C.E.D.E./O.R.S.T.O.M.(octobre 1993),
Bogota
compte
près
de5,5
millions d’habitants et croîttoujours
à unrythme
légèrement
supérieur
à 2 % par an. Ce ralentissement de la croissances’explique
par les effetsconjugués
detrois
phénomènes :
la réduction durythme
d’accroissement naturel due à la baisserapide
de lafécondité,
une diminution des fluxmigratoires
à destination deBogota
proprement
dit et la transformation du schémagéographique
de la croissance auprofit
desmunicipalités
périphériques
de l’airemétropolitaine.
L’évolutiondémographique
récente de la villes’accompagne
de nouvellesstratégies
de localisation résidentielle des habitantsqui
produisent
deschangements rapides
etimportants
dans larépartition
de lapopulation
et les formes deségrégation
sociale au sein del’agglomération.
Ce sont cesrecompositions,
mal mesurées et peu étudiéesjusqu’à présent,
qui
sont au centre de lathématique
del’enquête.
4 Équipe
dirigée parFrançoise
Dureau (I.R.D.) et Carmen Elisa Florez (C.E.D.E.).Population
soumise àl’enquête
L’unité d’observation pour
l’enquête
est leménage,
défini comme le groupe de personnesqui
occupe tout oupartie
d’unlogement
etpartage
les repas. Lapopulation
desménages
inclut les résidents habituels(personnes
vivant lamajeure partie
dutemps
dans leménage
même si elles sesont absentées au moment de
l’enquête
pour unepériode
courte -depuis
moins de troismois)
etles résidents non habituels
(personnes
qui
vivent lamajorité
dutemps
hors duménage
mais ont habité au moins 30jours
- consécutifs ou non - dans leménage
enquêté
au cours de l’annéeécoulée,
que ces personnes soient ou nonprésentes
au moment du passage del’enquêteur).
Ainsi,
s’ils accumulent la durée deprésence
nécessaire,
les individus suivants seront considérés comme faisantpartie
duménage :
militaires ducontingent,
élèves internes ou travailleursexerçant
leur activité hors duménage
ou deBogota
qui
reviennentrégulièrement
oupériodiquement
dans leursfoyers,
personnesemprisonnées
ouhospitalisées
pour destemps
courts,employés-domestiques
ou autres salariéslorsqu’ils
dorment dans lelogement,
personnes de passage(invitées)
ou enpension.
Enrevanche,
les personnesqui
louent une ouplusieurs
pièces
dulogement
et cuisinentséparément
(«inquilinos»),
forment desménages
différents.
Échantillonnage
Pour des raisons de
coût,
leplan
desondage adopté
ne vise pas lareprésentativité
de l’ensemble de l’airemétropolitaine
deBogota
mais seulement l’observation fiable de 11 domaines d’études(4
communes ouparties
de communes de l’airemétropo-litaine et 7
quartiers
deBogota),
ces zones
ayant
été choisies apriori
commeayant
une valeurheuristique
pour laproblématique
du programme
(Figure
1).
Danschacun des 11 domaines
préala-blement
stratifiés,
leplan
d’échantillonnage
consiste en unsondage
aréolaire à troisdegrés
avec
probabilités
inégales
de sélection des unitésprimaires
(U.P.).
Aupremier degré
les aires sélectionnées danschaque
strate sont des «manzanas»
(pâtés
demaison),
unitésspatiales
que définissent le réseau de voirie etles limites naturelles ou autres :
rivières,
«quebradas»
(fossés),
clôtures etc. On assure une bonne
répartition
géographique
del’échantillon en sélectionnant les
U.P. au moyen d’une
grille
depoints
dont la taille de la mailleest fonction du taux de
sondage
dans la strate
(tirage spatial
matique) ;
laprobabilité
de sélection dechaque
U.P. est doncproportionnelle
à sasuperficie.
Ausecond
degré,
après
avoir établi la listecomplète
deslogements
dupâté
demaison,
on sélectionne danschaque
U.P.cinq
logements
(unités
secondaires)
partirage
systématique
équiprobable
dans la liste. Enfin au troisièmedegré,
les unités d’observation sont tous lesménages
deslogements
sélectionnés.Questionnaire
Le
questionnaire
del’enquête
comprend
un formulaire d’informationsocio-démographique
couvrant l’ensemble des individus des
ménages
sélectionnés(1031
ménages),
ainsiqu’une
sériede modules visant à
recueillir,
sous forme decalendriers,
des donnéesrétrospectives
sur labiographie
résidentielle,
professionnelle
et familiale d’un sous échantillon de lapopulation
desménages
appelé
"sous-échantillonbiographique".
L’échantillonauquel
est soumis lapartie
biographique
duquestionnaire
estcomposé
d’un individu deplus
de 18 ans parménage
enquêté
(1031 individus)
et, sa structure, contrôlée par desquotas
de sexe,d’âge,
de relation deparenté
avec le chef de
ménage
et de statutmigratoire.
Les conclusions del’analyse
n’ont donc deportée
qu’à
l’intérieur de cetunivers,
pour cettepopulation particulière,
et non pour l’ensemble de lapopulation
deBogota
et son airemétropolitaine6.
Variables soumises àl’analyse
Visant en
premier
lieu unetypologie
destrajectoires
résidentielles enville,
l’analyse
se base surla variable d’état construite à
partir
de l’observation des localisations dans l’airemétropolitaine
de l’ensemble des résidences de
plus
d’un an connues par les individus(variable
active)’.
Le niveaud’agrégation géographique
de la variable doit fournir laprécision
maximum dansl’analyse
de la mobilitéspatiale
intra-urbaine tout en conservant des effectifs suffisants danschaque
modalité. La nomenclaturegéographique
qui
convient le mieux à cetobjectif
est celle des "alcadias menores" deBogota :
19 unités que nousappellerons
désormais arrondissements.À
cesmodalités,
qui
décrivent les résidences à l’intérieur de laville,
s’ajoute
une modalité pour leslieux de
Bogota
nonspécifiés,
quatre
modalités pour lesquatre
zones d’étude de lapériphérie
del’aire
métropolitaine
(communes
deChia, Tabio,
Madrid etSoacha),
une modalité pour lesautres communes de l’aire
métropolitaine (autres
mun.a.m.)
et enfin une modalité pour les résidences situées hors de l’airemétropolitaine.
Autotal,
les individuspeuvent
donc se trouverdans 26 modalités d’état.
Pour mettre à
jour
les relations existant entre lestypes
de mobilité résidentielle et les autrescomposantes
de labiographie,
nous introduisons 7 variableslongitudinales
illustrativesqui
résument des«chapitres»
de labiographie
que l’onpeut
supposer être déterminés et/oudéterminants par
rapport
à latrajectoire
spatiale :
relation deparenté
avec le chef deménage,
statut
matrimonial,
co-résidence avec lesenfants,
composition
duménage,
accès aulogement,
carrière d’éducation et mobilitéprofessionnelle. Chaque
variableayant
son calendrier propre, le nombred’étapes
vécues par les individus de l’échantillon est donc différent pour chacuned’elles,
etindépendant
du nombred’étapes
résidentielles.Enfin une caractérisation
socio-économique
des individuspratiquant chaque
type
de mobilité et desménages
auxquels
ilsappartiennent
sera obtenuegrâce
à un second ensemble devariables illustratives
transversales,
caractéristiques
individuelles et collectives à la date del’enquête.
Onreprend
dans ce bloc devariables,
lesdescripteurs
socio-démographiques
6 A propos du contrôle des quotas, voir aussi le
premier
paragraphe de la troisième partie ; le lecteur intéressé par des informations plus détaillées sur la méthodologie de l’enquête et lareprésentativité
des résultats peut consulterDureau, Florez,
Barbary,
Garcia, Hoyos [ 1994] et Dureau et Florez [ 1996].’
classiques
des individus -sexe,
âge,
statutmigratoire,
niveaud’instruction,
catégorie
socioprofessionnelle
etc., desménages
- taille duménage,
caractéristiques
dulogement
(taille,
statut
d’occupation,
indice depromiscuité)
et du chef deménage
-sexe,
âge,
statutmigratoire,
âge
moyen des enfants.2.2. Les
étapes
d’exécution del’AHQ jusqu’à
la classification destrajectoires
Le temps de
l’analyse :
période
d’analyse,
donnéescensurées,
discrétisationL’analyse
des donnéesprésentées
dans la sectionprécédente
va être menée selon cequ’on
peut
appeler
letemps
biographique
individuel,
c’est-à-dire en suivant les individusdepuis
leur naissancejusqu’à
l’âge
atteint à la date del’enquête.
D’autresoptions
sontpossibles,
onpourrait
parexemple
menerl’analyse
entemps
historique (en
suivant les individus entre deuxdates)
ou encore selon unehorloge
démarrant à un événement autre que lanaissance,
mais lechoix du
temps
biographique correspond
à une orientationproblématique
déterminée. Ilpermet
en effet de mettre en
relation,
au niveau individuel et au niveaustatistique
dans l’ensemble de l’échantillon ou dans chacune des classes de latypologie,
les différents itinérairesrésidentiels,
familiaux,
éducatifs ouprofessionnels,
pour ques’exprime
la cohérence desstratégies
individuelles et collectives.
L’option
dutemps
biographique
étantprise,
ilfaut,
pour coder lesdonnées,
choisir unepériode
detemps
commune à tous les individusquel
que soit leurâge
à ladate de
l’enquête.
Si l’on souhaite conserver la totalité desétapes
vécues,
c’estl’âge
atteint à ladate de
l’enquête
par l’individu leplus
vieux(92
ans dans notrecas)
qui
fixe l’étendue de lapériode.
Afin d’éviter que lapartie
finale du tableau soit presque totalement vide(«censure
àdroite»,
voirFigure 2),
onpréfère
arrêterl’analyse
à 65 ans pour la variable active et 70 anspour les variables
illustratives,
sauf la carrière éducativearrêtée, celle-ci,
dès 45 ans.Les individus
n’ayant
pas atteint cesâges
sortentd’observation,
donc des modalitésprévues
pour les variableslongitudinales,
àpartir
de leurâge
à la date del’enquête (phénomène
appelé
"censure à droite" dans lejargon
del’analyse
longitudinale).
On note au passage que letype
de censure que l’on doitprendre
encompte
dépend
dutype
detemps
choisi pourl’analyse :
avec untemps
historique
parexemple,
les données seraient censurées àgauche
pour lesindividus n’étant pas encore nés à une date donnée. La solution retenue pour cette
première
analyse
sur l’ensemble de l’échantillon estl’ajout
d’une modalitésupplémentaire
à chacune des variableslongitudinales
danslaquelle
l’individu entre dèsqu’il
est censuré. Ainsi l’ensemble desindividus de l’échantillon est
"présent"
dans une modalité d’état tout aulong
de lapériode
d’analyse (de
0 à 65ans).
Ce choixpeut
êtrecritiqué
puisque
la durée de"présence"
dans lamodalité de censure influence le résultat
typologique :
dans le cas dutemps
biographique
individuel et de la censure àdroite,
cet effet seramène,
comme on le verra, à un effetd’âge (la
structure par
âge
des classes étant nécessairementhomogène).
Onpeut
limiter cet effet en traitantles modalités de censure en
supplémentaire
dans l’AFC ou en réalisant desanalyses séparées
pour différentes cohortes d’individus. Nous n’avons retenu aucune de ces solutions car nous
cherchons une
typologie globale
de lamobilité,
pour l’ensemble de l’échantillon etprenant
encompte
l’ensemble de latrajectoire
résidentielle. Dans cetteperspective
l’effetd’âge
nousparaît
au contraire devoir être conservé : un individu de 20 ans nepeut
pasappartenir
à la même classequ’un
individu de 50 ans(c’est-à-dire
avoir la mêmetrajectoire
au mêmeâge
sur l’ensemble dela
période d’analyse).
Comme on l’a dit en
présentant
laméthode,
la mise en oeuvre del’AHQ
repose sur undécoupage
de lapériode d’analyse
en un nombre "raisonnable" d’intervalles derecodage.
Nous avons d’abord testé undécoupage
uniforme de lapériodes
0-65 ans ensegments
quinquennaux,
lesfréquences
étant calculées enproportion
du total de lapériode
analysée.
Cetteanalyse
fournit des grosses classes d’individusjeunes
dont lestrajectoires
sont peuhomogènes
et, àl’inverse,
des
changements
d’état selonl’âge
des individus(Figure
2)
permet
de définir undécoupage,
mieuxadapté
auxdonnées,
en 15périodes d’amplitude
variablecorrespondant
à peuprès
auxquantiles
de la distribution. Laprécision
est bonne entre 13 et 25 ans, elle diminue avant etaprès.
La même démarche a étéappliquée
aux variableslongitudinales
illustratives. Pour l’ensemble desvariables,
lesfréquences
sont calculées enproportion
de la durée dechaque
intervalle derecodage.
Le tableau soumis à l’AFCcomprend
1031lignes,
398 colonnes actives(15
x 27 moins 7 colonnesvides)
et 625 colonnes illustratives.Figure
2 : Distribution deschangements
de résidence(RESIALC)
selonl’âge
Pondération de l’échantillon
Compte
tenu du fait que leplan
desondage
n’est pasauto-pondér
et que le sous-échantillonbiographique
n’est pasprobabiliste
(méthode
desquotas),
leproblème
se pose de savoir sil’analyse
factorielle doit être faite sur les donnéespondérées
par les facteursd’extrapolation
(inverse
de laprobabilité
de sélection desménages).
Les deux AFC(pondérée
ounon)
donnentdes résultats tout à fait semblables en ce
qui
concernel’interprétation
des facteurs deplus
haut rang(dix
premiers
facteurséquivalents,
àquelques
inversionsprès).
Cependant
lors de la classification dansl’espace
despremiers
facteurs,
lapondération
a pour effet de rendre très "volatiles" les individusenquêtés
àChia,
Madrid et Tabio(trois
communes à faiblepopulation),
alors que l’inertie des individus des autres domaines
d’étude,
beaucoup
plus peuplés,
est au contraire très forte. Dans cetteétape
de mise àplat
des différentstypes
d’itinéraires,
nouspréférons
que tous les individus soient àégalité
(AFC
nonpondérée).
Enrevanche,
lors de laphase
dedescription
et caractérisation desclasses,
il nous a sembléimportant
de tenircompte
dupoids
démographique
(même
approximatif)
dechaque
type
demobilité ;
nous avons doncAnalyse
factorielle
L’analyse
descorrespondances
(CORRESP
de SAS ou CORBI deSPADN)
fournit unhistogramme
de valeurs propres trèsplat (Figure
3),
cequi
nesurprend
pas étant donné lastructure du tableau :
grand
nombre de colonnes auregard
du nombre delignes
et abondance de colonnes presque vides.Rappelons
ici que lerecodage adopté,
s’il conserve la totalité des durées deséjour
des individus dans lesétats,
perd
en revanche l’ordrechronologique
desétapes
puisque
toutepermutation
des colonnes est indifférente pour le résultat de l’AFC. D’autrepart
deux individus
ayant
des itinéraires strictement semblables maissimplement
décalés d’une oudeux
années,
sont trèséloignés
sur lesplans
factoriels. Le tableauanalysé
est donc très "bruité"par
rapport
à la structure deproximité
qui
nousintéresse,
"bruitage"
que l’on retrouve dansl’allure de
l’histogramme
des valeurs propres.Figure
3 :Histogramme
des dixpremières
valeurs propres de l’AFC(tableau
1031 x398)
Malgré
cela,
l’interprétation
despremiers
facteurs est aisée et même si lachronologie
estformellement
perdue
lors ducodage,
cette méta-information structure si fortement les donnéesqu’elle
ressort sur tous les axes factoriels utiles. Leplan
1 x 2(Figure 4)
montre letype
destructure mise en évidence par les
premiers
axes : lesséquences
de variables concernant unmême lieu de résidence sont
regroupées,
ordonnéeschronologiquement
lelong
des axes, ellescorrespondent
à des sous-ensembles d’individus minoritaires mais très stables dans ces lieux :dans le cas des deux
premiers
facteurs,
trois groupesayant
vécu toute leur vierespectivement
àTabio
(A22),
Chia(A21)
et Madrid(A23).
Pourcompléter
la démarcheclassique d’interprétation
del’AFC,
onpeut
projeter
sur lesplans
les variables illustrativeslongitudinales
et faireapparaître
lespoints représentant
les centres degravité
descaractéristiques
transversales. Apartir
despremiers
facteurs del’analyse,
onparvient
ainsi sans difficulté à identifier etcaractériser l’ensemble des groupes stables. Ces individus
représentent
à peuprès
22 % del’échantillon et environ 52 % de l’inertie
expliquée
par les 10premiers
facteurs ;
cesfacteurs,
dont
l’interprétation
estclaire,
totalisent 25 % de l’inertie totale du nuage. Les schémas demobilité
qui
caractérisent le reste des individus(78
% del’échantillon)
sont moins faciles àmettre en évidence à
partir
de la seuleinterprétation
des facteurs. Cequi
caractérise les axes, cesont des associations entre modalités
qui témoignent
de transitionsfréquentes,
à certainsâges,
entre les lieux
qu’elles
représentent.
Nous n’avonsplus,
comme pour les individusstables,
d’axes entièrement déterminés par un ou deux groupes aux
trajectoires
semblables,
maisseulement la mise en évidence de groupes
ayant
en commun une transition donnée à unâge
donné mais dont le reste de la
trajectoire
peut
différer. Cesrésultats,
typiques
del’application
del’analyse harmonique
qualitative
aux données de calendriers(voir
Deville[ 1982],
Béret[1988]
et
Degenne,
Lebeaux et Mounier[1995]),
restent insuffisants dupoint
de vue de notreobjectif
typologique.
Classification
du nuage des individusPour
parvenir
à unetypologie complète
destrajectoires,
nous avonsprocédé
à une classificationdes individus dans
l’espace
vectoriel despremiers
facteurs del’analyse
descorrespondances 8 .
Après plusieurs
essais,
en faisant varier le nombre de facteurs de 7 à 15 et enexplorant
lespartitions jusqu’à
30 classes etplus,
on constate quejusqu’à
10 facteurs latypologie
gagne enprécision.
Apartir
du onzièmefacteur,
la taille de la classe laplus importante
augmente,
mêmesi l’on considère des
partitions
comprenant
ungrand
nombre de classes dontbeaucoup
ont parconséquent
des effectifstrop
faibles. Sur cette baseempirique,
nous avons retenul’espace
vectoriel constitué par les dix
premiers
facteurs del’AFC,
que nous considérons comme le sous-espace conservant l’information utile(25
% de l’inertie totale dunuage).
La partconsidérable du "bruit" dans l’information
originale (75
%)
s’explique
par le fait que les 27 modalités d’état croisées avec les 15 intervalles detemps
produisent
un tableau très clairsemédont une
grande
part
de lavariabilité,
qui provient
despetits
décalages
temporels
entretrajectoires
équivalentes,
n’est pasinterprétable.
Le nuage des individus dans cet espace estensuite soumis à des
algorithmes
de classification ascendantehiérarchique
ousemi-hiérarchique
(CLUSTER -
critère de Ward sousSAS,
SEMIS deSPADN) ;
les deuxprocédures
donnentdes résultats très
proches
et nous avons conservés ceux de SPADNqui présentent l’avantage
d’optimiser
lapartition
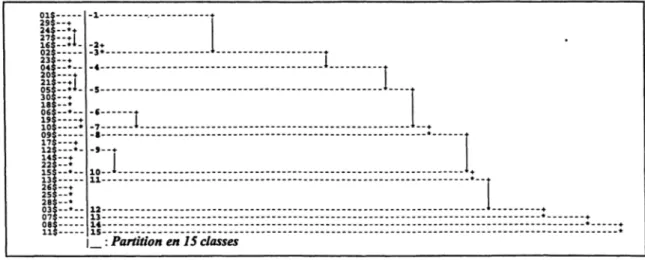
une fois choisi le nombre de classes(Figure
5)9.
La
partition
en 15 classes constitue latypologie
que nous allons décrire. Elle est obtenueaprès
coupure de l’arbre de classification etoptimisation
par affectation des individus à la classedont le centre de
gravité
est leplus proche
(PARTI
deSPADN).
Après
cette maximisation de8
La même démarche est appliquée par Degenne, Lebeaux et Mounier [1995] aux données sur l’insertion professionnelle des jeunes en France.
9
Rappelons qu’une partition en un nombre donné de classes, issue d’un arbre de classification ascendante hiérarchique, n’est pas optimale au sens du critère de la maximisation de l’inertie inter-classe.
l’inertie
inter-classe,
lapartition
explique
82 % de l’inertie totale du nuage dansl’espace
des dixpremiers
facteurs,
cequi
montre que la démarcheprend
correctement encompte,
hors le"bruit",
l’informationsignificative
fournie parl’enquête.
Figure
5 : Arbre de classification dansl’espace
des dixpremiers
facteurs de l’AFCCaractérisation et
interprétation
du résultattypologique
Le caractère
longitudinal
des donnéesimpose
l’emploi
detechniques
particulières
pour caractériser etinterpréter
latypologie. Classiquement
enanalyse
typologique,
les coordonnéesdes centres de classes sur les facteurs et les valeurs tests
associées,
ainsi que les individus lesplus
proches
du centre dechaque
classe,
fournissent la base d’uneinterprétation
"indirecte" desclasses à
partir
des facteurs. Pour décrire unetypologie
detrajectoire,
il est à la foisplus
direct,
plus
précis
etplus
riche de revenir à la donnéeoriginale
codée. En affectant sa classed’appartenance
àchaque
individu et en calculant lesfréquences
deséjour
moyennes des individus de la classe dans les modalités d’état au cours dechaque
intervalle decodage,
on obtient leprofil
de mobilité de la classe que l’onpeut
traduiregraphiquement
(Figures
9 à 23 enannexe).
La mêmetechnique
fournit lesprofils
des classescorrespondant
à chacune desvariables
longitudinales
illustratives(Figures
6 à8).
Tous cesprofils
peuvent
êtrecomparés
entre eux ainsi
qu’au
profil
d’ensemble del’échantillon’°.
Enfin,
onpeut
éditer la série de tableaux croisésqui
mettent en relation latypologie
avec chacune descaractéristiques
transversales des individus et desménages
retenues commeillustratives ;
lepouvoir
"explicatif’
de
chaque caractéristique
transversalepeut
être résumé par lastatistique
dux2
associée autableau et l’on
structure
le commentaire enrepérant
les cellules du tableauayant
les contributionsles
plus
fortes au Xglobal.
A
partir
de l’ensemble de cematériel,
onpeut donc,
pourchaque
classe,
décrire lecomportement
résidentiel desenquêtés
etdégager
leurtrajectoire spatiale spécifique.
Cettetrajectoire
est mise en relation avec la succession des événements ducycle
de vie quepermettent
d’appréhender
les variableslongitudinales
illustratives. Onsignale également
lescaractéristiques
démographiques
etsocio-économiques qui
complètent
la "carte d’identité" de la classe. Des’°
Pour permettre ces comparaisons, il faut éliminer l’effet des structures par âge, différentes dans chaque classe, effet directement lisible dans l’importance prise par la modalité de censure à droite au fur et à mesure que l’on progresse dans l’âge. Pour ce faire on calculera les fréquences par modalité d’état pour chaque âge sur l’ensemble
des individus de la classe ayant atteint cet âge (i.e. hors individus censurés) ; le total de