Test de systèmes temps réel à l’aide du forçage en ligne
Texte intégral
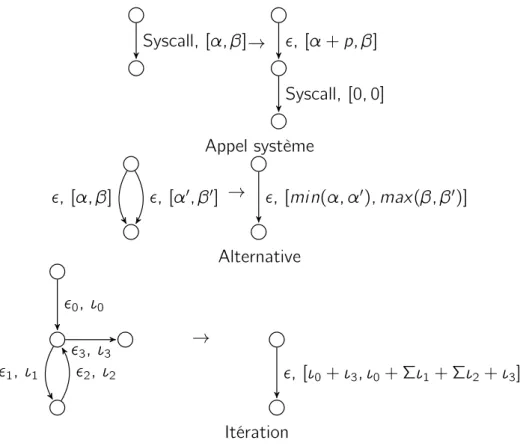
Figure
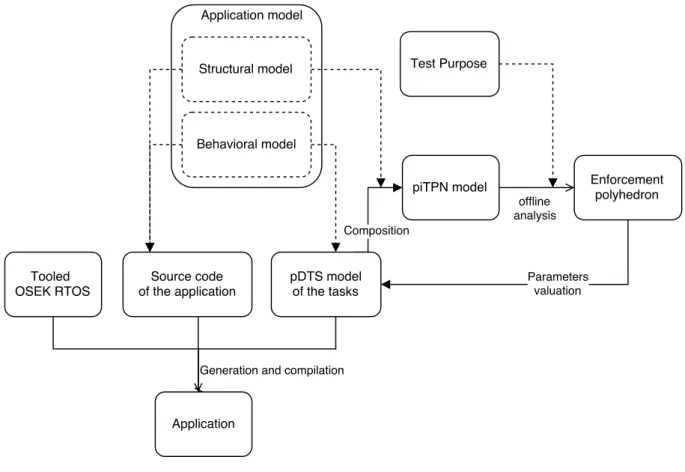
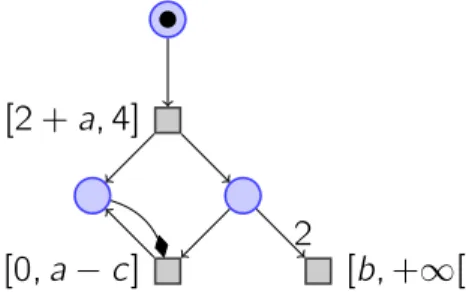
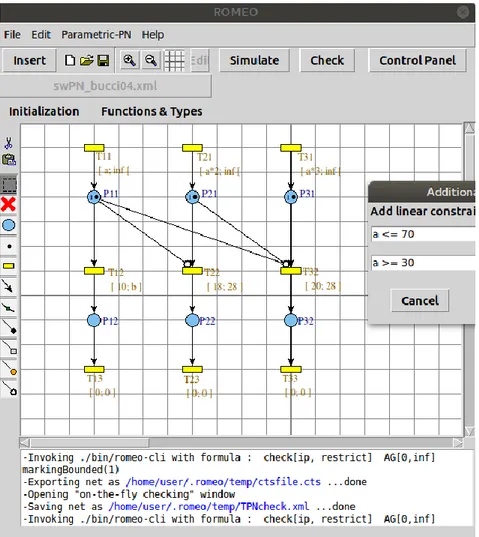
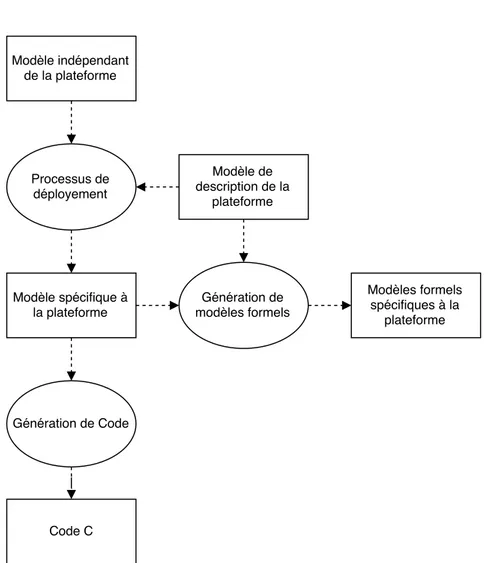

Documents relatifs
Elles sont toutes les deux sous contrat avec StadiumCompany pour leurs bureaux et services au sein du stade... Cinq de ces bureaux
Figure 5.35: Diagramme de classes de conception du cas d’utilisation «établir un contrat de location» «Entité» Locataire id_L :Integer Nom :String Prenom :String DateN :Date
Endlich in die Nähe des Rheins gelangt (der Bahnhof liegt etwa eine halbe Stunde vom Rhein entfernt), suchten wir ein Hotel auf, das uns von nutzen bürgerlich und
Afin.de consolider les acquis de ses apprenants, un professeur de SpCT · les soumet à une évaluation qui consiste ~ déterminer le pH d'un mélange de soluti~net à identifier
L’institution devrait, d’une part, informer les étudiants via des règlements sur les sanctions encourues en cas de découverte de plagiat dans certains documents
Dans notre exp´ erience, une flamme de pr´ em´ elange se propage dans une chambre confin´ ee entre deux vitres espac´ ees de 5mm [2]1. En for¸ cant un mode propre de l’une des
Le seul test d'arrêt satisfaisant est le test d'arrêt optimal qui consiste ici à interrompre le processus itératif sur la valeur X s pour laquelle les nombres de chiffres
L'implémentation du test d'arrêt optimal dans tout code d'optimisation non contrainte est très aisée. En effet, elle consiste à remplacer le test d'arrêt classique par le calcul,
