HAL Id: hal-02104099
https://hal.archives-ouvertes.fr/hal-02104099
Submitted on 19 Apr 2019
HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
LES INDICATEURS D’ASYMÉTRIE SONT- ILS
PERTINENTS POUR ÉTUDIER LES SEUILS
COMPTABLES ?
Olivier Vidal
To cite this version:
Olivier Vidal. LES INDICATEURS D’ASYMÉTRIE SONT- ILS PERTINENTS POUR ÉTUDIER LES SEUILS COMPTABLES ?. Congrès de l’Association Francophone de Comptabilité, May 2009, Strasbourg, France. �hal-02104099�
LES INDICATEURS D’ASYMÉTRIE
SONT-ILS PERTINENTS POUR ÉTUDIER LES
SEUILS COMPTABLES ?
Olivier Vidal,
PRAG à l’ENS Cachan
Doctorant à HEC Paris, 1, av de la Libération, 78350 Jouy en Josas FRANCE @dresse : ovidal @ free.fr
Résumé de l’article :
S’attendant à ce que la distribution statistique des résultats non manipulés des entreprises présente une allure « lisse », les irrégularités de distribution des résultats publiés par les entreprises observées autour de certains seuils sont interprétées comme des manifestations de gestion du résultat. De nombreuses études ont tenté de mesurer ces irrégularités afin d’effectuer des comparaisons dans le temps, dans l’espace, ou entre les différents seuils. Ces études sont donc confrontées à un problème technique de mesure. Or la méthodologie de mesure des irrégularités n’est pas stabilisée. Parmi ces mesures, l’article s’intéresse plus spécifiquement aux indicateurs d’asymétrie. Il souligne leurs limites théoriques et teste leur validité à travers une application empirique. Les résultats tendent à montrer que de tels indicateurs sont myopes, et qu’ils peuvent conduire à des interprétations erronées des phénomènes qu’ils sont censés représenter.
Mots clefs :
Gestion du résultat, seuils comptables, indicateurs d’asymétrie, distribution des résultats
Abstract:
Are asymmetry measures relevant to analyze accounting thresholds?
Distributions of disclosed earnings are supposed to be smooth in the absence of earnings management. Irregularities have been observed around thresholds, suggesting earnings management. Recently, many studies have measured these irregularities in order to compare thresholds magnitude in space and over time. Most of these studies use asymmetry measures. The paper examines the theoretical limits of such indicators. The results of an empirical study tend to show that such indicators are myopic, and can drive to wrong interpretations.
Keywords:
INTRODUCTION
Dans la mesure où la comptabilité est un langage qui permet de traduire de manière synthétique la situation financière d’une entreprise, la recherche comptable s’est naturellement intéressée à la qualité des informations véhiculées par cet outil de communication. Il apparaît notamment que la comptabilité peut être manipulée par les entreprises pour publier des états financiers qui soient à leur avantage. La variable résultat étant le solde ultime de la construction comptable, un important courant de recherche s’est développé afin d’estimer l’ampleur, les causes, et les conséquences des manipulations susceptibles d’altérer son sens.
Dans ce cadre, s’attendant à ce que la distribution statistique des résultats non manipulés des entreprises présente une allure « lisse », les premiers articles (Hayn, 1995 ; Degeorge, Patel et Zeckhauser, 1999 ; Burgstahler et Dichev, 1997) qui ont mis en évidence l’existence de discontinuités autour de certains seuils, dans les distributions de résultats publiés, les ont interprétées comme des manifestations de manipulations. L’étude des irrégularités de distribution est dès lors apparue, au début des années 2000, comme une alternative à la mesure des accruals. Cette alternative est d’autant plus attractive qu’elle semble techniquement plus facile à mettre en œuvre comparée aux modèles complexes de mesure des accruals anormaux. De nombreuses études ont donc tenté de mesurer les irrégularités afin d’effectuer des comparaisons dans le temps −évolution− (Brown, 2001 ; Dechow, Richardson et Tuna, 2003), dans l’espace −comparaisons internationales− (Leuz, Nanda et Wysocki, 2003 ; Glaum, Lichtblau et Lindemann, 2004 ; Daske, Gebhardt et McLeay, 2006), ou entre les différents seuils −hiérarchisation− (Degeorge, Patel et Zeckhauser, 1999 ; Kasznik, 1999 ; Brown et Caylor, 2005).
Pour comparer des irrégularités, il faut être capable de les mesurer de manière fiable (Mard, 2004 ; Vidal, 2008). Il ne suffit pas de répondre à une question binaire du type : « l’irrégularité est-elle significative, oui ou non » ? Les études qui font des comparaisons sont donc confrontées à un problème technique de mesure. Or la revue de littérature développée dans la partie 1 de l’article montre que la méthodologie de mesure des irrégularités n’est pas stabilisée. Parmi ces mesures, la partie 2 s’intéresse plus spécifiquement aux indicateurs d’asymétrie, soulignant notamment leurs limites théoriques. Ces limites sont ensuite testées à travers une application empirique (parties 3 et 4). Les résultats tendent à montrer que de tels indicateurs sont myopes, et qu’ils peuvent conduire à des interprétations erronées des phénomènes qu’ils sont censés représenter.
1. REVUE DE LITTÉRATURE
L’étude des seuils comptables est à l’origine d’un nombre important et croissant de publications ces dernières années dans les revues internationales. Elle est apparue en effet comme une alternative aux mesures d’accruals pour étudier la gestion du résultat. La revue de littérature présente tout d’abord les travaux ayant mis en évidence l’existence de ces seuils. Puis elle présente les travaux ayant tenté de les expliquer, et enfin, les travaux ayant effectué
des comparaisons. C’est parmi ces travaux comparatifs que l’on trouve l’utilisation d’indicateurs d’asymétrie.
1.1. Les travaux observant les seuils
L’approche par les seuils est une démarche empirique qui se fonde sur les caractéristiques de la loi de distribution de l’ensemble des résultats. Cette démarche est tout d’abord décrite, avant de présenter les trois principaux seuils identifiés dans la littérature.
1.1.1 - Une démarche empirique
L’approche par les seuils pose un problème conceptuel : elle se fonde sur une qualité, non pas du résultat individuel d’une entreprise, mais de l’ensemble des résultats d’une population. C’est une approche empirique globale. Le référentiel n’est pas un référentiel du résultat, mais de la distribution d’un grand nombre de résultats.
Le problème, c’est que les règles comptables permettant de définir un résultat sont appliquées de manière individuelle, pour coller à la réalité de chaque entreprise. Elles ne tiennent pas compte des résultats des autres entreprises. Elles ne visent pas à obtenir une loi de distribution homogène quelconque. Il existe des indices de performance construits en relation avec les performances de l’ensemble d’une population. Ce sont des indices de performance relative. C’est le cas du classement Elo aux échecs ou du test du quotient intellectuel (QI). Ces indices visent à mesurer la performance d’un individu par rapport à la performance de ses « concurrents ». Ce n’est pas du tout la logique du résultat comptable.
Conceptuellement, le postulat qui pose comme référentiel de la qualité du résultat le comportement de l’ensemble d’une population suppose que la performance des entreprises obéit à des lois statistiques, loi des grands nombres. La force de l’approche par les seuils, c’est sa puissance empirique. On constate un phénomène qui est difficilement justifiable théoriquement, mais qui intuitivement, ne semble pas étonnant.
1.1.2 - Les différents seuils constatés
Burgstahler et Dichev (1997) sont les premiers à étudier les irrégularités de distribution des résultats comptables. Ils mettent en évidence deux discontinuités sur un échantillon de plus de 4 000 entreprises américaines :
(1) Seuil du résultat nul.
(2) Seuil des variations de résultat nulles.
Dans ces deux situations, les auteurs constatent une sous-représentation du nombre d’entreprises publiant des résultats légèrement en dessous du seuil, et une sur-représentation du nombre d’entreprises publiant des résultats légèrement au dessus du seuil.
Degeorge, Patel et Zeckhauser (1999) ont étudié les irrégularités de distribution de la variable bénéfice par action aux États-Unis. Ils confirment les résultats de Burgstahler et Dichev (1997) et identifient un troisième seuil :
Les auteurs constatent que le nombre d’entreprises publiant un résultat légèrement inférieur aux prévisions est anormalement faible alors que le nombre d’entreprises publiant un résultat juste égal, ou légèrement supérieur aux prévisions est anormalement élevé.
L’existence de ces trois irrégularités a été largement observée depuis les articles précurseurs, et ce, dans des contextes variés. Si la plupart des études concernent les entreprises américaines, les seuils ont été observés également auprès d’entreprises françaises cotées entre 1990 et 1998 (Mard, 2004), auprès d’entreprises chinoises (Yu, Du et Sun, 2006), allemandes (Glaum, Lichtblau et Lindemann, 2004), russes (Goncharov et Zimmermann, 2006), australiennes (Holland et Ramsey, 2003 ; Davidson, Goodwin-Stewart et Kent, 2005), et japonaises (Shuto, 2008).
La plupart des études s’intéressent aux entreprises cotées, mais les seuils ont également été étudiés auprès d’entreprises non cotées françaises (Bisson, Dumontier et Janin, 2004), et européennes (Coppens et Peek, 2005 ; Burgstahler, Hail et Leuz, 2006). Par ailleurs, les irrégularités sont apparentes dans tous les secteurs d’activité. Leur existence a notamment été observée auprès d’échantillons composés exclusivement de banques, secteur généralement exclu des études empiriques sur bases de données (Schrand et Wong, 2003 ; Shen et Chih, 2005).
1.2. Les travaux sur les causes des seuils
Les irrégularités de distribution de résultat sont interprétées comme étant la manifestation de manipulations comptables. Les articles précurseurs ont proposé des explications qui sont, depuis, reprises telles quelles par l’ensemble des chercheurs. La première sous-partie présente le postulat de manipulation et la seconde présente les causes évoquées pour expliquer ces manipulations.
1.2.1 - L’irrégularité est la manifestation d’une manipulation
Hayn (1995) est le premier auteur à identifier comme suspect le nombre insuffisant d’entreprises faiblement déficitaires. À la différence de Burgstahler et Dichev (1997), l’auteur n’étudie pas la distribution dans son ensemble, et n’observe pas le surnombre à droite du seuil. Elle en déduit cependant que si le nombre d’entreprises faiblement déficitaire est anormalement faible, c’est que les entreprises évitent de publier un résultat négatif. Dépasser le seuil du résultat nul correspond à l’envoi d’un signal positif vers le marché, et rater le seuil correspond à l’envoi d’un signal négatif. Cette présomption de manipulation est d’autant plus généralement admise qu’elle est reconnue par les dirigeants eux-mêmes (Graham, Harvey et Rajgopal, 2005).
Burgstahler et Dichev (1997) observent que, parallèlement à l’absence d’entreprises faiblement déficitaires, le nombre d’entreprises faiblement bénéficiaires est, lui, étonnamment élevé.
Figure 1 : La double discontinuité
Les auteurs proposent alors l’interprétation suivante : puisqu’il y a une sous-représentation des effectifs juste en dessous du seuil, et une sur-représentation des effectifs juste au dessus, c’est qu’il y a un transfert d’effectifs d’un intervalle sur un autre. Les entreprises calculant un résultat (non manipulé) juste inférieur au seuil sont très motivées pour manipuler leur résultat afin de publier un résultat légèrement supérieur au seuil. Autrement dit, les irrégularités signalent des petites gestions de résultat à la hausse.
Figure 2 : Interprétation de la double discontinuité
Un exemple tiré de la presse économique illustre cette interprétation. Dans le Wall Street Journal, McGough (2000) cite le cas de la société Black Box1 qui publie en 2000 un résultat par action de 72 cents, exactement en accord avec les prévisions des analystes. En réalité, le résultat précis est de 71,505 cents par action, et c’est grâce à un arrondi que le chiffre publié correspond aux prévisions. Au global, à 750,62 $ près, le seuil de prévision des analystes n’aurait pas été atteint. Cet exemple est cité par Das et Zhang (2003) pour démontrer que le montant de la manipulation pour éviter un seuil peut être très faible.
Cependant, si cet exemple illustre concrètement le fait que le montant à manipuler n’est pas nécessairement élevé, il ne permet pas de démontrer pour autant, ni qu’il y a eu manipulation, ni que, si manipulation il y a eu, le montant manipulé ait été exactement de 750,62 $. Il est tout à fait possible que le résultat avant manipulation ait été très inférieur à 71 cents par action. Il est donc important de souligner que l’interprétation de Burgstahler et Dichev (1997) n’est pas démontrée. C’est un postulat (Vidal 2008).
1 Le nom de la société était-il prédestiné ?
Niveau lissé seuil Sous-représentation en dessous du seuil Sur-représentation au dessus du seuil seuil Sous-représentation en dessous du seuil Sur-représentation au dessus du seuil
1.2.2. Le postulat est étendu aux autres seuils (prévisions et variations)
De même que l’irrégularité autour du résultat nul est interprétée comme la manifestation d’une gestion du résultat, l’irrégularité autour des deux autres seuils (évitement d’une petite baisse de résultat et évitement d’une petite erreur de prévision) est interprétée de la même manière. Les entreprises manipulent leurs comptes (de manière marginale) afin d’atteindre et dépasser ces seuils.
Cependant, si les deux premiers seuils font référence à un niveau objectif de résultat (résultat = zéro et résultat = résultat de l’année précédente), le seuil des prévisions fait, quant à lui, référence à un niveau subjectif. Les prévisions sont des opinions formulées par des analystes (ou les dirigeants eux-mêmes). Ces prévisions peuvent être divergentes, et sont susceptibles d’évoluer. Dans l’équation « erreurs de prévisions = résultats prévus – résultats publiés », si les erreurs nulles sont anormalement nombreuses, c’est que (1) soit les résultats publiés sont manipulés, (2) soit les résultats prévus sont orientés. Autrement dit, les dirigeants peuvent aiguiller les analystes vers des objectifs de résultat que la société est en mesure d’atteindre ou de dépasser.
Un certain nombre d’études a ainsi cherché à déterminer dans quelle mesure l’irrégularité devait être attribuée à une gestion du résultat, ou à une gestion des prévisions2. Les auteurs montrent empiriquement que les analystes sont manipulés/influencés/guidés par les dirigeants (Bartov, Givoly et Hayn, 2002 ; Matsumoto, 2002 ; Burgstahler et Eames, 20063 ; Cotter, Tuna et Wysocki, 2006). Sur ce sujet, il est judicieux de remarquer que, si les dirigeants peuvent être motivés à éviter de publier des résultats supérieurs ou égaux aux prévisions, les analystes ne sont pas moins motivés à éviter de faire des erreurs. Une prévision juste est considérée comme une prévision de qualité et la réputation des analystes est d’autant plus forte que leurs prévisions sont vérifiées (Chambost, 2007).
1.3. Les travaux mesurant et comparant les seuils
Afin de mieux comprendre les causes des seuils, des études ont cherché à mesurer les facteurs qui influencent leur amplitude. Pour ce faire, elles ont effectué des comparaisons. Ces travaux sont présentés ci-dessous. Il en ressort qu’ils utilisent généralement des indicateurs d’asymétrie.
1.3.1. Les études longitudinales
Plusieurs études se sont intéressées à l’évolution dans le temps des irrégularités. La principale est celle de Brown et Caylor (2005) qui montre que la hiérarchie des seuils identifiée par Degeorge, Patel et Zeckhauser (1999) est vérifiée sur la période 1985 à 1994, mais s’inverse sur la période plus récente de 1994 à 2001. Les auteurs en déduisent que les dirigeants, influencés par l’évolution des attentes du marché des capitaux, ont réorienté leurs priorités en
2
Dans la littérature anglophone, on trouve les expressions « forecast management », « forecast guidance », ou encore « expectations management ».
3
Dans un article précédent, Burgstahler et Eames (2003) estimaient que les analystes anticipaient la gestion du résultat destinée à éviter les faibles pertes et les faibles variations négatives. Cette « anticipation » s’est transformée en présomption de « guidance » avec le temps.
termes de gestion du résultat pour éviter les seuils. Dans la période charnière (1993 à 1996), l’attention des médias s’est davantage portée sur la propension des entreprises à atteindre leurs résultats que celle d’éviter les baisses de résultat.
Dechow, Richardson et Tuna (2003) observent également l’évolution dans le temps des discontinuités. Ils constatent un déclin dans le temps de l’évitement du résultat négatif et de la faible diminution de résultat, alors que l’évitement de l’erreur de prévision des analystes augmente. Les auteurs expliquent ce phénomène par des incitations liées aux réglementations des marchés financiers. Avant 1995, pour être inscrit à la bourse de New-York, il était important de présenter des comptes bénéficiaires. Après 1995, cette contrainte diminue si l’entreprise présente des chiffres d’affaires, capitalisation et flux de trésorerie opérationnels dépassant certains seuils.
Dans les deux cas, les auteurs utilisent une mesure des irrégularités par asymétrie.
1.3.2. Les études internationales
La comparaison entre les informations comptables publiées selon des normes différentes renvoie à la littérature volumineuse sur la comptabilité comparée. Cette littérature cherche à identifier l’influence de l’environnement culturel, juridique et politique sur les systèmes comptables. Plusieurs études internationales ont été réalisées sur les seuils.
Leuz, Nanda et Wysocki (2003) étudient la gestion des résultats dans 31 pays (entre 1990 et 2000), et la mettent en relation avec l’environnement économique et légal des pays. Les auteurs établissent un indicateur de gestion du résultat composite tenant compte de trois indicateurs de mesure des accruals et d’un indicateur d’évitement des faibles pertes. Ce dernier indicateur mesure l’irrégularité par asymétrie.
Glaum, Lichtblau et Lindemann (2004) comparent les seuils comptables entre entreprises américaines et allemandes. Leurs résultats ne montrent pas de différence significative entre les entreprises américaines et allemandes en ce qui concerne les seuils « résultat nul » et « variations de résultat nulles ». En revanche, les entreprises allemandes semblent moins éviter le seuil « prévisions des analystes » que les sociétés américaines. Burgstahler, Hail et Leuz (2006) comparent les pratiques comptables dans les pays européens. Ils montrent que les irrégularités de distribution sont plus prononcées lorsque la protection des investisseurs est faible, et que les seuils sont moins visibles dans les pays dont les systèmes légaux sont forts. Ces articles utilisent des indicateurs d’asymétrie pour mesurer les irrégularités. McNichols (2003) souligne la fragilité de ces indicateurs, faciles à calculer, mais difficiles à interpréter. Leurs limites sont développées dans la partie 2.
2. LES INDICATEURS D’ASYMÉTRIE POUR ÉTUDIER LES SEUILS
L’observation des irrégularités est assez simple à réaliser. En revanche, comparer des irrégularités est chose moins aisée. En effet, il est différent de répondre aux deux questions suivantes : (1) « y a-t-il irrégularité ? » et (2) « une irrégularité observée est elle plus ou moins importante qu’une autre ? ». Dans le second cas, il ne suffit plus de répondre de manière binaire ; la comparaison nécessite un instrument de mesure de l’irrégularité qui soit
suffisamment fiable pour être comparable. Deux grandes familles de mesures sont utilisées dans la littérature sur le sujet : (1) les mesures d’irrégularités à proprement parler, et (2) les mesures d’asymétrie.
(1) L’irrégularité est l’écart entre l’effectif observé et un effectif de référence (ou effectif attendu). C’est la « sous » ou « sur » représentation. Ces mesures nécessitent de connaître un effectif attendu (théorique), pour estimer l’irrégularité par différence avec l’effectif observé. Ces mesures ne sont pas l’objet du présent article.
(2) L’asymétrie est la comparaison des effectifs de deux intervalles successifs, dont l’un au moins est présumé être irrégulier. L’ampleur de la manipulation comptable est calculée en faisant un rapport entre l’effectif immédiatement à droite du seuil sur l’effectif immédiatement à gauche du seuil. Les études internationales ou longitudinales qui se fondent sur une mesure d’asymétrie évitent ainsi le problème de la mesure des irrégularités. Elles s’affranchissent de toute estimation théorique et se contentent de comparer les effectifs observés entre eux.
Mais, même si elles ne font pas explicitement référence au montant manipulé, ces études postulent implicitement que la manipulation pour atteindre le résultat positif est de faible ampleur. En effet, elles assimilent la sous-représentation à gauche et la sur-représentation à droite à l’expression du même phénomène. Cette hypothèse rejoint le postulat de manipulation marginale présenté dans la partie 1. Y a-t-il une corrélation entre l’effectif à droite du seuil et celui à gauche ? Cette hypothèse n’a jamais été testée.
Conceptuellement, le terme même d’« asymétrie » laisse supposer que la valeur de référence est la « symétrie ». Autrement dit, la neutralité supposerait l’égalité des effectifs sur les deux intervalles consécutifs. Glaum, Lichtblau et Lindemann (2004) disent ainsi que leur indicateur est centré sur zéro. En réalité, la distribution suivant une forme (plus ou moins) de cloche, il n’y a jamais deux intervalles consécutifs égaux (sauf éventuellement au sommet). Constater une asymétrie n’est donc pas nécessairement synonyme d’irrégularité. Il apparaît dès à présent que les indicateurs d’asymétrie posent des problèmes d’interprétation.
Deux indicateurs d’asymétrie sont recensés dans la littérature. Ils sont présentés successivement.
2.1. L’indicateur d’asymétrie « d/g » (ou « r/l »)
Le premier indicateur d’asymétrie utilisé dans la littérature est le ratio « effectif faibles gains » divisé par « effectif faibles pertes » (Leuz, Nanda et Wysocki, 2003 ; Burgstahler, Hail et Leuz, 2006).
n r = effectif de l’intervalle de droite (r = right)
n l = effectif de l’intervalle de gauche (l = left)
L’indicateur d’asymétrie est mesuré par le ratio = n r / n l
Ce ratio est souvent appelé par simplification « r/l » ou, en français, « d/g ». C’est un calcul extrêmement simple, repris par Dechow, Richardson et Tuna (2003) pour étudier l’évolution dans le temps (de 1989 à 2001) des « pics ». Les auteurs calculent ce ratio en réunissant deux
intervalles4. Si la mesure d’asymétrie d/g est simple à calculer, elle soulève plusieurs limites mathématiques :
(1) Pour des petits nombres (population réduite, ou largeur des intervalles faible), l’effectif à gauche de l’irrégularité peut être égal à zéro. Le dénominateur est alors nul et l’indicateur devient inopérant.
(2) L’indicateur est compris entre 0 et l’infini. Si les deux effectifs sont égaux, il est égal à un. La distribution de l’indicateur est donc asymétrique et non linéaire, rendant difficile les comparaisons et les interprétations. Par exemple, la différence entre une asymétrie de 1,5 et 2 est nettement plus importante qu’une différence entre une asymétrie de 10 et 10,5. Il est par ailleurs impossible de comparer une irrégularité située sur la partie droite de la courbe à une irrégularité située sur la partie gauche (par exemple une irrégularité de valeur 2/1 est identique à une irrégularité de valeur ½).
(3) Par ailleurs, on ne peut pas considérer que l’indicateur soit centré sur 1 puisque cette situation n’est valable que si la courbe est plate (donc au sommet). L’indicateur ne tient donc absolument pas compte de l’endroit où l’on se situe dans la courbe (supposée en cloche). Un ratio de 2 peut être tout à fait normal lorsque l’on se trouve dans la partie croissante de la courbe, alors que c’est une irrégularité importante lorsque l’on est dans la partie haute, ou basse de la courbe.
Figure 3 : Indicateur d’asymétrie d/g et non linéarité de la distribution
(4) L’indicateur est par ailleurs très sensible à la taille de l’échantillon, en exagérant les valeurs extrêmes.
4 Les auteurs utilisent une largeur d’intervalle de 0,01, donc le ratio est mesuré sur une largeur de 0,02.
40
20 10
Indicateur = 2/1 alors qu’il
n’y a pas irrégularité
Indicateur = 2/1 alors
Figure 4 : Indicateur d’asymétrie et taille de l’échantillon
En conclusion, comme le soulignent Glaum, Lichtblau et Lindemann (2004), l’indicateur d/g est assez rudimentaire et est mal approprié pour effectuer des comparaisons d’irrégularités.
2.2. L’indicateur « (r-l)/(r+l) »
Glaum, Lichtblau et Lindemann (2004) ont créé un indicateur de mesure de l’asymétrie qui évite un certain nombre des « propriétés numériques indésirables5 » de l’indicateur de Leuz, Nanda et Wysocki (2003). Les auteurs s’inspirent d’un indicateur largement utilisé dans les sciences de la nature (Halzen et Martin, 1984), et appellent leur indicateur « A » comme « Asymétrie ».
A = (n r - n l ) / n rl
Avec :
n r = effectif de l’intervalle de droite (r = right)
n l = effectif de l’intervalle de gauche (l = left)
n rl = somme des effectifs des deux intervalles
En simplifiant l’expression, A = (r-l)/(r+l) et en la francisant, on obtient A = (d-g)/(d+g). Contrairement à l’indicateur de Leuz, Nanda et Wysocki (2003), A est centré sur 0, et compris entre -1 et 1. La distribution de l’indicateur est donc (en apparence) symétrique rendant a priori plus facile les comparaisons. Pour des petits nombres, un effectif à gauche du seuil égal à zéro (donc un dénominateur nul) ne rend pas l’indicateur inopérant. Il est par ailleurs moins sensible à la taille de l’échantillon puisque le dénominateur est moins « volatile ».
5 Selon l’expression des auteurs.
Rapport de 200/ 10 = 20 Rapport de 20 / 2 = 10
Cette asymétrie est jugée égale à la situation précédente, alors que le
faible nombre au dénominateur laisse planer
un doute sur la précision de la mesure Rapport de
100/10 = 10
Rapport de 10 / 0 = infini Lorsque le dénominateur est nul, l’indicateur ne peut
plus être interprété
20 0 10 10 100 2 10 200 1 20 Rapport de 20/ 1 = 20 Cette asymétrie est jugée égale à
la situation précédente, et deux fois supérieure à la situation encore précédente, alors que le
faible nombre au dénominateur laisser planer un doute sur la
Figure 5 : Comparaison des deux indicateurs d’asymétrie
Comme le montre la Figure 5 ci-dessus, les deux indicateurs fournissent la même hiérarchie des asymétries, mais les valeurs extrêmes sont lissées avec le second indicateur.
Cet indicateur présente cependant des limites. Tout d’abord, il n’est toujours pas « linéaire ». L’écart entre une asymétrie de 0,1 et 0,2 n’est pas comparable à l’écart entre une asymétrie de 0,8 et 0,9. Mais le plus préoccupant, c’est que l’indicateur ne prend toujours pas en considération la non linéarité de la courbe. En réalité, la distribution de l’indicateur ne doit pas être considérée comme réellement symétrique et centrée sur 0 puisque cette situation n’est valable que si la courbe est plate (donc au sommet).
Figure 6 : Indicateur d’asymétrie (r-l)/(r+l) et non linéarité de la distribution
La Figure 6 illustre par exemple le fait qu’un score de 0,33 peut être tout à fait normal lorsque l’on se trouve dans la partie croissante de la courbe, alors que c’est une irrégularité importante lorsque l’on est dans la partie haute, ou basse de la courbe.
2.3. Synthèse sur les indicateurs d’asymétrie
Le principal problème posé par l’utilisation d’indicateurs d’asymétrie est un problème conceptuel. Ces indicateurs considèrent en effet que l’effet de seuil se définit par la somme
Rapport de 19/ 21 = 0,90 au lieu de 20 Rapport de 90/110 = 0,82 au lieu de 10 Rapport de 18 / 22 = 0,82 au lieu de 10 Rapport de 190/ 210 = 0,90 au lieu de 20 Rapport de 10 / 10 = 1 au lieu de infini 20 0 10 10 100 2 10 200 1 20 40 20 10 Indicateur = (20-10)/30 = 1/3 alors qu’il y a irrégularité Indicateur = (40-20)/60 = 1/3 alors qu’il n’y a pas irrégularité
des deux effets : sur-représentation à droite, et sous-représentation à gauche. Or aucune étude n’a jamais vérifié la dépendance de ces deux effets. Cette hypothèse mérite d’être testée à partir d’une mesure d’irrégularité séparant les deux effets.
Par ailleurs, l’indicateur d’asymétrie est sensible à la largeur de l’intervalle d’étude fixé. Ce problème est d’autant plus important que l’indicateur est utilisé pour comparer des populations de tailles différentes, et pour lesquelles les largeurs d’intervalles retenues peuvent être différentes.
Figure 7 : Les indicateurs d’asymétrie se fondent sur des effectifs totaux, et pas sur les irrégularités
Enfin, les mesures sont faites sur la totalité des effectifs d’un intervalle, et non pas sur les effectifs irréguliers (voir Figure 7). De plus, la mesure de l’asymétrie ne tient pas compte de l’endroit où l’on se trouve sur la courbe (voir Figure 3 et Figure 6) ; il ne répond pas au problème de non linéarité de la pente de la courbe de distribution, rendant toute interprétation de l’indicateur délicate.
Tableau 1 : Synthèse des limites et avantages des indicateurs d’asymétrie Postulat
implicite sur la distribution
Méthode Avantages Limites Auteurs
d/g Simplicité des calculs
Ne tient pas compte de la non linéarité de la pente ;
Sensible à la largeur des intervalles ; Se fonde sur un intervalle irrégulier pour
estimer un intervalle théorique
Dechow, Richardson et Tuna, 2003 ; Leuz, Nanda et Wysocki, 2003 ; Burgstahler, Hail et Leuz, 2006 Les indicateurs d’asymétrie n’estiment pas un effectif théorique. Aucun postulat n’est fait implicitement sur
la distribution. (d-g)/(d+g) Simplicité des calculs
Ne tient pas compte de la non linéarité de la pente (et accentue ses conséquences) ;
Glaum, Lichtblau et Lindemann,
2004 L’étude empirique présentée par la suite cherche à évaluer l’impact de ces limites dans le cadre d’une étude longitudinale. L’objet de l’étude est de déterminer si les limites identifiées sont suffisantes pour remettre en cause la validité des résultats d’une étude sur les seuils.
3. ÉTUDE EMPIRIQUE DES INDICATEURS D’ASYMÉTRIE
Après avoir présenté la base utilisée, l’étude empirique cherche à estimer la pertinence des indicateurs d’asymétrie en mesurant séparément les irrégularités à droite et à gauche du seuil du résultat nul dans l’échantillon. Si ces deux mesures sont fortement corrélées, alors il est
40
20 10
L’indicateur = 40/20 = 2 est calculé sur l’effectif total. S’il était
calculé sur les seules irrégularités, il serait = 25/10 = 2,5 Irrégularité =
(20-10) = 10
Irrégularité = (40-15) = 25
possible d’en conclure que les indicateurs d’asymétrie sont pertinents pour traduire le phénomène étudié. Dans le cas contraire, les indicateurs d’asymétrie doivent être relativisés car ils assimilent deux phénomènes distincts (irrégularité à droite et irrégularité à gauche) dans un même et unique indicateur.
Par ailleurs, l’étude tente également de déterminer lequel des deux indicateurs présentés dans la partie 2 est le plus pertinent.
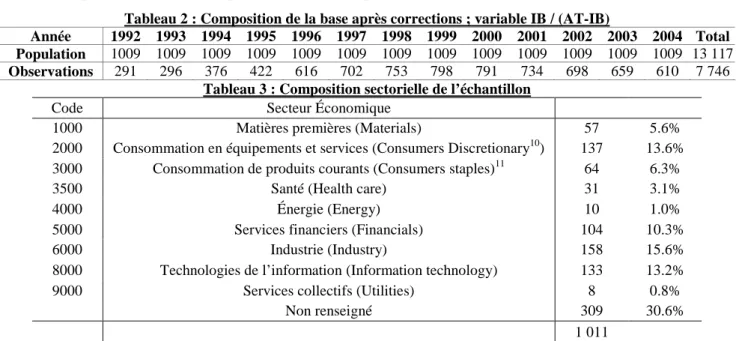
3.1. Description de la base utilisée
Pour effectuer les tests empiriques, la base de données utilisée est constituée des entreprises françaises cotées dont les données financières sont présentes sur la base Global Vantage (Compustat ; Standard & Poor’s).
Dans la section A, la base de données est décrite. Certaines corrections sont effectuées et sont décrites dans la section B. La section C décrit la base corrigée. Toutes les sociétés industrielles actives , sont retenues (code « $G » dans la base) et inactives (code « $D »), et toutes les sociétés financières actives (code « $F ») et inactives (code « $X ») françaises (code « Comp. Specifics country = FRA ») soit 1011 sociétés6. Les données accessibles de 1992 à 2004 couvrent près de 7746 observations.
Pour constituer la base, les entreprises actives et inactives de la base Global Vantage sont retenues afin d’éviter un biais de sélection en ne retenant que les entreprises survivantes. Le taux d’observation par an, qui ne dépasse jamais les 77 % de la base, est essentiellement dû aux variations de la constitution de la base (entrées et sorties de cote). Les véritables données manquantes sont relativement peu nombreuses chaque année.
Les études statistiques en comptabilité qui utilisent des bases de données ont pour habitude de supprimer les entreprises de banque et assurance. Cela se justifie du fait que les règles comptables qui leur sont appliquées sont différentes, et que l’interprétation et la comparaison des chiffres (aussi bien de structure du bilan que de performance) sont délicates. Dans le cas d’une étude sur les irrégularités de distribution, la pertinence de cet usage peut être questionnée. En effet, ce n’est ni la performance des entreprises, ni leur structure financière dans l’absolu qui est comparée, mais leur comportement (collectif) face à un seuil de résultat publié. Or ce comportement vis-à-vis du seuil peut se manifester aussi bien chez les entreprises industrielles que les entreprises financières, indépendamment des règles comptables qu’elles doivent appliquer. Il ne semble donc pas nécessaire de supprimer les entreprises financières de la base de données7.
La variable dont la distribution est retenue comme objet de l’étude est le résultat net, car c’est la variable de performance sur laquelle les entreprises communiquent le plus (Mard, 2004). Dans la base Global Vantage, le résultat net correspond à la variable « IB8 ». Cependant, dans un souci d’harmonisation internationale, ce résultat peut être diminué de certains résultats extraordinaires qui ne correspondent pas aux résultats exceptionnels en comptabilité française.
6 L’extraction des données a été faite en mars 2006.
7 104 entreprises de la base portent le code secteur financier (« sector code » 5000 dans la base), soit 10,27% de la population.
Ces résultats extraordinaires sont en général nuls. Lorsqu’ils apparaissent, ils sont négligeables. La variable IB est donc assimilable au résultat net habituellement publié par les entreprises françaises. Un retraitement systématique ne se justifie pas dans le cadre d’une étude qui ne s’intéresse essentiellement qu’aux très faibles bénéfices et aux très faibles pertes. Enfin, le résultat (en valeur) d’une entreprise n’a pas le même sens en fonction de la taille de l’entreprise (Burgstahler et Dichev, 1997 ; Degeorge, Patel et Zeckhauser, 1999), notamment lorsque l’on s’intéresse à la notion de « petite » perte ou de « petit » gain. La variable résultat net est donc mise à l’échelle (c'est-à-dire « divisée ») par la variable de taille AT9 (pour actif total) dans la base Global Vantage.
Dans la mesure où l’étude s’intéresse essentiellement à la distribution de la variable résultat divisée par une variable de taille, une attention particulière est portée à certaines valeurs très extrêmes. Par rapport au ratio IB/AT(n-1) généralement utilisé dans la littérature, il apparaît
que l’utilisation du ratio IB/(AT-IB) permet de limiter (ou de « tasser ») les valeurs extrêmes négatives, sans modifier de manière significative la partie centrale de la distribution, sur laquelle figure le seuil d’étude. Le seul cas de figure atypique est constitué par d’éventuelles valeurs extrêmes positives, mais elles sont rares, et jamais aussi extrêmes que les valeurs négatives.
La composition de la base après correction est présentée dans les Tableau 2 et Tableau 3.
Tableau 2 : Composition de la base après corrections ; variable IB / (AT-IB)
Année 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 Total Population 1009 1009 1009 1009 1009 1009 1009 1009 1009 1009 1009 1009 1009 13 117
Observations 291 296 376 422 616 702 753 798 791 734 698 659 610 7 746
Tableau 3 : Composition sectorielle de l’échantillon
Code Secteur Économique
1000 Matières premières (Materials) 57 5.6%
2000 Consommation en équipements et services (Consumers Discretionary10) 137 13.6% 3000 Consommation de produits courants (Consumers staples)11 64 6.3%
3500 Santé (Health care) 31 3.1%
4000 Énergie (Energy) 10 1.0%
5000 Services financiers (Financials) 104 10.3%
6000 Industrie (Industry) 158 15.6%
8000 Technologies de l’information (Information technology) 133 13.2%
9000 Services collectifs (Utilities) 8 0.8%
Non renseigné 309 30.6%
1 011
Tous les secteurs d’activité sont représentés dans la base d’entreprises françaises cotées étudiée.
9 En anglais : « Assets Total ».
10 Plus précisément, ce secteur inclut l’automobile, les biens durables d’équipement ménager, le textile, l’équipement de loisir, la restauration et l’hôtellerie, les médias, et les services.
11
Plus précisément, ce secteur inclut toutes les industries qui produisent ou vendent alimentation, médicaments, tabac, et produits ménagers.
3.2. Le lien entre irrégularité droite et irrégularité gauche
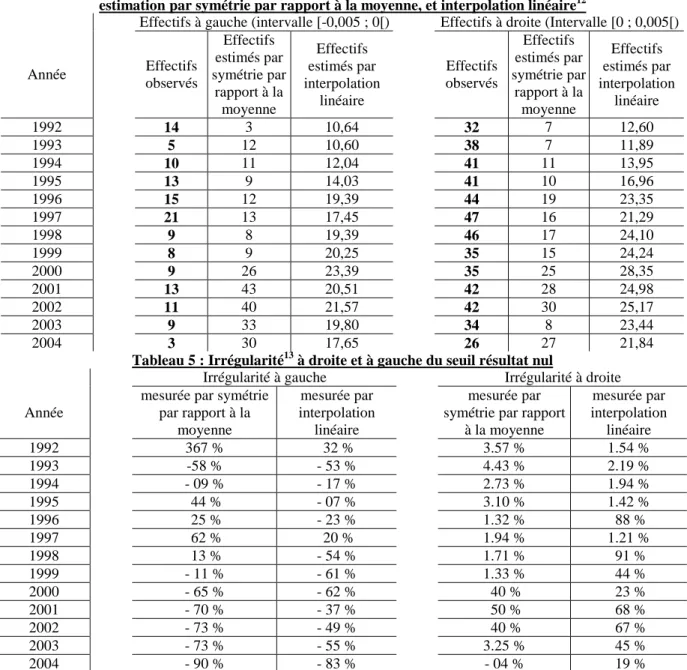
Les mesures des irrégularités à droite et à gauche du seuil sont effectuées successivement par symétrie (par rapport à la moyenne) et interpolation linéaire (qui est une extension de la moyenne arithmétique) car ces deux méthodes sont les plus souvent utilisées dans la littérature comptable (et notamment par Burgstahler et Dichev, 1997, dans leur article fondateur).
Tableau 4 : Mesures des effectifs, observés et théoriques, à droite et à gauche du seuil résultat nul ; estimation par symétrie par rapport à la moyenne, et interpolation linéaire12
Effectifs à gauche (intervalle [-0,005 ; 0[) Effectifs à droite (Intervalle [0 ; 0,005[)
Année Effectifs observés Effectifs estimés par symétrie par rapport à la moyenne Effectifs estimés par interpolation linéaire Effectifs observés Effectifs estimés par symétrie par rapport à la moyenne Effectifs estimés par interpolation linéaire 1992 14 3 10,64 32 7 12,60 1993 5 12 10,60 38 7 11,89 1994 10 11 12,04 41 11 13,95 1995 13 9 14,03 41 10 16,96 1996 15 12 19,39 44 19 23,35 1997 21 13 17,45 47 16 21,29 1998 9 8 19,39 46 17 24,10 1999 8 9 20,25 35 15 24,24 2000 9 26 23,39 35 25 28,35 2001 13 43 20,51 42 28 24,98 2002 11 40 21,57 42 30 25,17 2003 9 33 19,80 34 8 23,44 2004 3 30 17,65 26 27 21,84
Tableau 5 : Irrégularité13 à droite et à gauche du seuil résultat nul
Irrégularité à gauche Irrégularité à droite Année
mesurée par symétrie par rapport à la moyenne mesurée par interpolation linéaire mesurée par symétrie par rapport
à la moyenne mesurée par interpolation linéaire 1992 367 % 32 % 3.57 % 1.54 % 1993 -58 % - 53 % 4.43 % 2.19 % 1994 - 09 % - 17 % 2.73 % 1.94 % 1995 44 % - 07 % 3.10 % 1.42 % 1996 25 % - 23 % 1.32 % 88 % 1997 62 % 20 % 1.94 % 1.21 % 1998 13 % - 54 % 1.71 % 91 % 1999 - 11 % - 61 % 1.33 % 44 % 2000 - 65 % - 62 % 40 % 23 % 2001 - 70 % - 37 % 50 % 68 % 2002 - 73 % - 49 % 40 % 67 % 2003 - 73 % - 55 % 3.25 % 45 % 2004 - 90 % - 83 % - 04 % 19 %
Pour représenter graphiquement les irrégularités, il est important de tenir compte du signe de l’irrégularité : en effet, l’irrégularité positive à droite signifie qu’il y a un sur-effectif, alors
12 L’interpolation est effectuée en utilisant les quatre intervalles à droite et les quatre intervalles à gauche des deux intervalles
présumés irréguliers encadrant immédiatement le seuil. La largeur des intervalles est de 0,005 (largeur généralement retenue dans la littérature, notamment par Burgstahler et Dichev, 1997 ; Burgstahler et Eames, 2003 ; Dechow, Richardson et Tuna, 2003 ; Mard, 2004 ; Brown et Caylor, 2005 ; Coppens et Peek, 2005 ; Durtschi et Easton, 2005 ; Beaver, McNichols et Nelson, 2007).
13
que l’irrégularité à gauche, généralement négative, s’interprète comme un sous-effectif. Autrement dit, une diminution de la valeur négative de l’irrégularité signifie qu’il y a accroissement de l’irrégularité en valeur absolue. Pour représenter les deux irrégularités sur le même graphe, l’irrégularité à gauche du seuil est représentée en inversant son signe.
Figure 8 : Comparaison graphique de l’évolution des irrégularités (tenant compte du signe de l’irrégularité) à droite et à gauche du seuil résultat nul ; mesures par symétrie
comparaison des irrég (mesure par sym.) - D inverse + G
-2.00 -1.00 0.00 1.00 2.00 3.00 4.00 5.00 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 e ff e c ti f ir ré g u li e
r irreg G par sym / moyenneIrreg D par sym/MOY
Polynomial (irreg G par sym / moyenne) Polynomial (Irreg D par sym/MOY)
Figure 9 : Comparaison graphique de l’évolution des irrégularités (tenant compte du signe de l’irrégularité) à droite et à gauche du seuil résultat nul ; mesures par interpolation linéaire
comparaison des irrég (mesure interpol.) - D inverse + G
-2.00 -1.00 0.00 1.00 2.00 3.00 4.00 5.00 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 e ff e c ti f ir ré g u li e
r Irreg G interpol lin
Irreg D interpol lin
Polynomial (Irreg D interpol lin) Polynomial (Irreg G interpol lin)
Cette représentation révèle de manière flagrante que l’évolution de l’irrégularité à gauche, dans l’échantillon d’entreprises françaises entre 1992 et 2004, évolue de manière strictement opposée à l’irrégularité à droite du seuil. Autrement dit, alors que l’irrégularité à droite diminue (le sur-effectif est plus important en début de période), l’irrégularité à gauche augmente (la sous-représentation des entreprises faiblement déficitaires, qui était pratiquement nulle en début de période, devient de plus en plus marquée durant la période d’étude).
En conclusion, l’étude montre que l’irrégularité à droite n’est pas corrélée positivement à l’irrégularité à gauche du seuil14. Cela signifie que l’étude de chacune de ces irrégularités mérite d’être menée indépendamment de l’autre. Ce résultat conduit à remettre en cause les fondements sur lesquels reposent les calculs d’asymétrie.
3.3. Comparaison des deux indicateurs d’asymétrie
Dans un premier temps, l’indicateur d’asymétrie d/g (Dechow, Richardson et Tuna, 2003 ; Leuz, Nanda et Wysocki, 2003 ; Burgstahler, Hail et Leuz, 2006) est mesuré. Dans le souci de contrôler les résultats, trois calculs sont effectués en faisant varier la largeur des intervalles.
Figure 10 : évolution de l’indicateur d’asymétrie d/g entre 1992 et 2004
Logiquement, il apparaît que plus la largeur est élevée, moins l’indicateur est volatile, ce qui est normal dans la mesure où plus les effectifs sont réduits, plus les variations d’effectifs ont un impact important. La tendance reste cependant la même.
Cet indicateur est ensuite comparé avec l’indicateur (d-g)/(d+g) (Glaum, Lichtblau et Lindemann, 2004). Comme l’indicateur d/g est compris entre 0 (si l’effectif de droite est nul) et + ∞, alors que l’indicateur (d-g)/(d+g) est compris entre -1 et 1, le second indicateur est multiplié par 10 pour permettre une comparaison graphique (voir Tableau 6).
Tableau 6 : Calcul des indicateurs d’asymétrie d/g et (d-g)/(d+g)
effectifs d/g 10 x (d-g)/(d+g) [-0,015 ;-0,00[ [-0,01 ;-0,00[ [-0,005 ;0[ [0 ; 0,005[ [0 ; 0,01[ [0 ; 0,015[ largeur 0,005 largeur 0,01 largeur 0,015 largeur 0,005 largeur 0,01 largeur 0,015 1992 27 19 14 32 50 67 2.29 2.63 2.48 3.91 3.30 4.26 1993 18 10 5 38 56 69 7.60 5.60 3.83 7.67 5.29 5.86 1994 21 17 10 41 62 86 4.10 3.65 4.10 6.08 4.21 6.07 1995 25 18 13 41 65 90 3.15 3.61 3.60 5.19 4.09 5.65 1996 38 33 15 44 79 115 2.93 2.39 3.03 4.92 3.01 5.03 1997 41 34 21 47 83 109 2.24 2.44 2.66 3.82 3.27 4.53 1998 18 16 9 46 96 132 5.11 6.00 7.33 6.73 5.33 7.60 14 Si corrélation il y a, elle est négative.
indicateur d/g 0 1 2 3 4 5 6 7 8 9 10 1991 1993 1995 1997 1999 2001 2003 d/g largeur 0,005 d/g largeur 0,01 d/g largeur 0,015
1999 22 14 8 35 74 111 4.38 5.29 5.05 6.28 4.51 6.69 2000 24 15 9 35 94 131 3.89 6.27 5.46 5.91 5.10 6.90 2001 29 22 13 42 87 113 3.23 3.95 3.90 5.27 4.58 5.92 2002 36 24 11 42 96 126 3.82 4.00 3.50 5.85 4.44 5.56 2003 31 20 9 34 77 112 3.78 3.85 3.61 5.81 3.99 5.66 2004 19 12 3 26 55 90 8.67 4.58 4.74 7.93 3.94 6.51
Comme le montre la Figure 11 les deux indicateurs fournissent une information similaire. Les limites de l’indicateur d/g ne se font sentir que sur des valeurs extrêmes (effectif nul de l’effectif de gauche notamment) qui n’apparaissent pas dans le cadre de l’application. Par ailleurs, l’indicateur (d-g)/(d+g) n’étant jamais négatif, la représentation sur un même graphe des deux indicateurs est possible.
Figure 11 : Comparaison graphique des indicateurs d’asymétrie d/g et (d-g)/(d+g)
comparaison des indicateurs ; largeur 0,005
0 1 2 3 4 5 6 7 8 9 1991 1993 1995 1997 1999 2001 2003 2005 d/g largeur 0,005 (d-g)/(d+g) largeur 0,005
comparaison des indicateurs ; largeur 0,01
0 1 2 3 4 5 6 7 8 9 1991 1993 1995 1997 1999 2001 2003 2005 d/g largeur 0,01 (d-g)/(d+g) largeur 0,01
comparaison des indicateurs ; largeur 0,015 0 1 2 3 4 5 6 7 8 1991 1993 1995 1997 1999 2001 2003 2005 d/g largeur 0,015 (d-g)/(d+g) largeur 0,015
Enfin, comme l’ont fait Dechow, Richardson et Tuna (2003), l’évolution de l’irrégularité mesurée par asymétrie est observée. La Figure 12 fait apparaître la droite de régression permettant de visualiser la tendance de chaque série correspondant à chacun des indicateurs d’asymétrie.
Figure 12 : Comparaison graphique des indicateurs d’asymétrie d/g et (d-g)/(d+g) avec courbe de tendance
Il apparaît nettement que l’indicateur d’asymétrie, quelle que soit la méthode utilisée, augmente durant la période étudiée. Selon la littérature comptable, cela doit être interprété comme la manifestation d’une aggravation des pratiques de gestion du résultat pour éviter les seuils. Or ce résultat masque le double phénomène déjà mis en évidence : une diminution de l’irrégularité à droite et l’augmentation de l’irrégularité à gauche.
En conclusion, il apparaît que les indicateurs d’asymétrie sont myopes. La diminution de l’irrégularité à droite du seuil (qui se traduit par une diminution des effectifs) est masquée par l’augmentation de l’irrégularité à gauche (qui se traduit également par une diminution des effectifs). Ce biais méthodologique est d’autant plus fort que les effectifs à gauche étant en
Evolution des indicateurs d'asymétrie
0 1 2 3 4 5 6 7 8 1992 1995 1998 2001 2004 d/g largeur 0,005 (d-g)/(d+g) largeur 0,005 Linéaire ((d-g)/(d+g) largeur 0,005) Linéaire (d/g largeur 0,005)
général plus faibles, une diminution de même ampleur des effectifs à droite et à gauche induisent une augmentation non proportionnelle de l’asymétrie puisque le dénominateur est formé d’un chiffre plus faible. L’utilisation des indicateurs d’asymétrie ne semble donc pas satisfaisante dans l’étude des pratiques de gestion du résultat pour éviter les seuils.
Par ailleurs, la comparaison des mesures effectuées avec chacun des deux indicateurs ne permet pas de trancher en faveur de l’un ou l’autre. L’indicateur d/g a l’avantage d’être extrêmement simple à calculer. L’indicateur (d-g)/(d+g) possède quelques avantages théoriques (notamment dans quelques cas extrêmes d’effectif nul) qui ne sont cependant pas utiles dans le cadre de l’étude test. Les deux indicateurs sont, en définitive, tout aussi myope l’un que l’autre.
CONCLUSIONS ET APPORTS DE L’ÉTUDE
Une relecture des travaux antérieursDans leur étude sur l’évolution des seuils pour les entreprises cotées au NYSE de 1989 à 2001, Dechow, Richardson et Tuna (2003) observent que l’indicateur d’asymétrie au seuil résultat nul décline régulièrement de 2,09 à 1,31 lorsqu’en 1995 les conditions de cotation15 changent. Mais les auteurs ne fournissent pas de détail de l’impact sur les irrégularités respectivement à gauche et à droite du seuil. Par ailleurs, Leuz, Nanda et Wysocki (2003) comme Burgstahler, Hail et Leuz (2006) étudient la gestion du résultat dans 31 pays et les classent notamment grâce à un indicateur d’asymétrie. Tous ces résultats peuvent être revisités puisqu’ils se fondent sur un outil de mesure fortement limité.
Un exemple de cette limite est visible dans la représentation graphique (voir Figure 13) des résultats de Glaum, Lichtblau et Lindemann (2004). Les auteurs, qui utilisent un indicateur d’asymétrie, concluent à la non significativité des tests de comparaison des entreprises allemandes et américaines. Mais cette apparente similitude masque en réalité une double divergence. Les entreprises allemandes légèrement bénéficiaires sont sur-représentées, alors que les entreprises américaines légèrement déficitaires sont sous-représentées. L’indicateur composite annule, par compensation, les deux différences.
Figure 13 : Comparaison des distributions des entreprises cotées américaines et allemandes (Glaum, Lichtblau et Lindemann, 2004) : mise en évidence de deux irrégularités distinctes
Les limites à l’utilisation d’indicateurs d’asymétrie
Seule une forte corrélation entre les deux irrégularités à droite et à gauche du seuil permet de légitimer l’utilisation d’indicateurs d’asymétrie. Cette corrélation n’est pas vérifiée sur l’échantillon d’entreprises cotées françaises sur la période 1992 à 2004. Il semble donc que l’utilisation d’indicateurs d’asymétrie pour mesurer la gestion du résultat pour éviter les seuils doit être évitée. Ce résultat a un intérêt évident pour les chercheurs qui s’engagent dans des études comparatives, internationales ou longitudinales.
Les entreprises américaines légèrement déficitaires sont
sous-représentées
Les entreprises allemandes légèrement bénéficiaires sont
Plus fondamentalement, il semble que le principal problème posé par l’utilisation d’indicateurs d’asymétrie est un problème conceptuel. Cet indicateur considère en effet que l’effet de seuil se définit par la somme des deux effets : sur-représentation à droite, et sous-représentation à gauche. L’étude montre qu’il est utile de ne pas confondre ces deux phénomènes qui peuvent avoir des évolutions distinctes. Une porte est ouverte à de futures études sur ce sujet.
Enfin, d’autres limites doivent être soulignées. L’indicateur d’asymétrie ne s’affranchit pas des problèmes de largeur d’intervalle. Ce problème est d’autant plus important que l’indicateur a été utilisé notamment pour comparer des populations de taille différente, et pour lesquelles la largeur d’intervalle retenue peut être différente (Leuz, Nanda et Wysocki, 2003 ; Burgstahler, Hail et Leuz, 2006). Par ailleurs, les mesures sont faites sur la totalité des effectifs d’un intervalle, et non pas sur les effectifs irréguliers, ce qui peut diluer la mesure et provoquer des problèmes d’échelle. La mesure de l’asymétrie ne tient pas compte de l’endroit où l’on se trouve sur la courbe, et ne règle pas le problème de la pente non linéaire de la courbe de distribution, rendant toute interprétation délicate. Enfin, les indicateurs d’asymétrie peuvent être, par construction, totalement inopérants dans des cas extrêmes, notamment lorsque le dénominateur est nul. En révélant empiriquement ces limites, l’article plaide en faveur de l’abandon des indicateurs d’asymétrie, et de l’utilisation de mesures d’irrégularités fondées sur l’estimation des effectifs attendus.
Pour conclure, alors que la confiance dans les informations comptables est un élément crucial pour le bon fonctionnement d’une économie fondée sur le financement par les marchés, la recherche sur les manipulations comptable demeure plus que jamais un champ d’investigation primordial. Les manipulations pour atteindre un seuil, qui ont été identifiées à la toute fin du XXème siècle, constituent un terrain d’investigation novateur, et la méthodologie de recherche n’a pas encore fait l’objet d’un large consensus. Il semble donc important de consolider les fondements théoriques de ces travaux. En étudiant les limites des indicateurs d’asymétrie, l’article espère participer concrètement à la construction de ce courant de recherche prometteur.
BIBLIOGRAPHIE
Bartov E., Givoly D. et Hayn C. (2002), "The rewards to meeting or beating earnings expectations", Journal of Accounting & Economics 33 (2): 173-204.
Beaver W. H., McNichols M. F. et Nelson K. K. (2007), "An Alternative Interpretation of the Discontinuity in Earnings Distributions", Review of Accounting Studies 12 (4): 525-556.
Bisson B., Dumontier P. et Janin R. (2004), "Les entreprises non cotées manipulent-elles leurs résultats ?", 3ème colloque international : gouvernance et juricomptabilité, Montréal.
Brown L. D. (2001), "A Temporal Analysis of Earnings Surprises: Profit versus Losses", Journal of Accounting Research 39 (2): 221-241.
Brown L. D. et Caylor M. L. (2005), "A Temporal Analysis of Earnings Management Thresholds: Propensities and Valuation Consequences", Accounting Review 80 (2): 423-440.
Burgstahler D. et Dichev I. (1997), "Earnings management to avoid earnings decreases and losses", Journal of Accounting & Economics 24 (1): 99.
Burgstahler D. et Eames M. (2006), "Management of Earnings and Analysts' Forecasts to Achieve Zero and Small Positive Earnings Surprises", Journal of Business Finance and Accounting 33 (5): 633-652. Burgstahler D., Hail L. et Leuz C. (2006), "The Importance of Reporting Incentives: Earnings Management in
European Private and Public Firms", The Accounting Review 81 (5): 983-1016.
Burgstahler D. C. et Eames M. J. (2003), "Earnings Management to Avoid Losses and Earnings Decrease: Are Analysts Fooled?", Contemporary Accounting Research 20 (2): 253-294.
Chambost I. (2007), Contribution à l'analyse de la formation du jugement des analystes financiers sell-side, Doctorat en sciences de gestion, Paris: Conservatoire National des Arts et Métiers.
Coppens L. et Peek E. (2005), "An analysis of earnings management by European private firms", Journal of International Accounting, Auditing and Taxation 14 (1): 1-17.
Cotter J., Tuna I. et Wysocki P. D. (2006), "Expectations Management and Beatable Targets: How Do Analysts React to Explicit Earnings Guidance?", Contemporary Accounting Research 23 (3): 593-624.
Das S. et Zhang H. (2003), "Rounding-up in reported EPS, behavioral thresholds, and earnings management", Journal of Accounting and Economics 35 (1): 31-50.
Daske H., Gebhardt G. et McLeay S. (2006), "The distribution of earning relative to targets in the European Union", Accounting & Business Research 36 (3): 137-168.
Davidson R., Goodwin-Stewart J. et Kent P. (2005), "Internal governance structures and earnings management", Accounting & Finance 45 (2): 241-267.
Dechow P. M., Richardson S. A. et Tuna I. (2003), "Why Are Earnings Kinky? An Examination of the Earnings Management Explanation", Review of Accounting Studies 8 (2/3): 355-384.
Degeorge F., Patel J. et Zeckhauser R. (1999), "Earnings Management to Exceed Thresholds", The Journal of Business 72 (1): 1-33.
Durtschi C. et Easton P. (2005), "Earnings Management ? The shapes of the Frequency Distributions of Earnings Metrics Are Not Evidence Ipso Facto", Journal of Accounting Research 43 (4): 557-593.
Glaum M., Lichtblau K. et Lindemann J. (2004), "The Extent of Earnings Management in the US & Germany", Journal of International Accounting Research 3 (2): 45-77.
Goncharov I. et Zimmermann J. (2006), "Earnings Management when Incentives Compete: The Role of Tax Accounting in Russia", Journal of International Accounting Research 5 (1): 41-65.
Graham J. R., Harvey C. R. et Rajgopal S. (2005), "The economic implications of corporate financial reporting", Journal of Accounting & Economics 40 (1-3): 3-73.
Halzen F. et Martin A. D. (1984), Quarks and Leptons: An introductory course in modern particle physics, New York: NY: Wiley.
Hayn C. (1995), "The information content of losses", Journal of Accounting and Economics 20 (2): 125-153. Holland D. et Ramsey A. (2003), "Do Australian companies manage earnings to meet simple earnings
benchmarks?", Accounting and Finance 43: 41-62.
Kasznik R. (1999), "On the Association between Voluntary Disclosure and Earnings Management", Journal of Accounting Research 37 (1): 57-81.
Leuz C., Nanda D. et Wysocki P. D. (2003), "Earnings Management and Investor Protection: An International Comparison", Journal of Financial Economics 69 (3): 505-527.
Mard Y. (2004), "Les sociétés françaises cotées gèrent-elles leurs chiffres comptables afin d'éviter les pertes et les baisses de résultats ?", Comptabilité Contrôle Audit 10 (2): 73-98.
Matsumoto D. A. (2002), "Management's Incentives to Avoid Negative Earnings Surprises", Accounting Review 77 (3): 483-514.
McGough R. (2000), "How 'Round-Ups' Can Give Stocks a Hard Ride", Wall Street Journal - Eastern Edition 236 (14): C1.
McNichols M. F. (2003), "Discussion of "Why are Earnings Kinky? An Examination of the Earnings Management Explanation"", Review of Accounting Studies 8 (2-3): 385-391.
Schrand C. M. et Wong M. H. F. (2003), "Earnings Management Using the Valuation Allowance for Deferred Tax Assets under SFAS No 109", Contemporary Accounting Research 20 (3): 579-611.
Shen C.-H. et Chih H.-L. (2005), "Investor protection, prospect theory, and earnings management: An international comparison of the banking industry", Journal of Banking & Finance 29 (10): 2675-2697. Shuto A. (2008), "Earnings Management to Avoid Earnings Decreases: A Comparative Analysis of Consolidated
Earnings and Parent-Only Earnings", Working Paper. Kobe University.
Vidal O. (2008), Gestion du résultat et seuils comptables : Impact des choix méthodologiques et proposition d'un instrument de mesure des irrégularités, Doctorat en sciences de gestion, Paris: École des Hautes Etudes Commerciales de Paris.
Yu Q., Du B. et Sun Q. (2006), "Earnings Management at rights issues thresholds - Evidence from China", Journal of Banking & Finance 30 (12): 3453-3468.