Modélisation floue de type takagi-sugeno appliquée à un bioprocédé
72
0
0
Texte intégral
Figure




+7
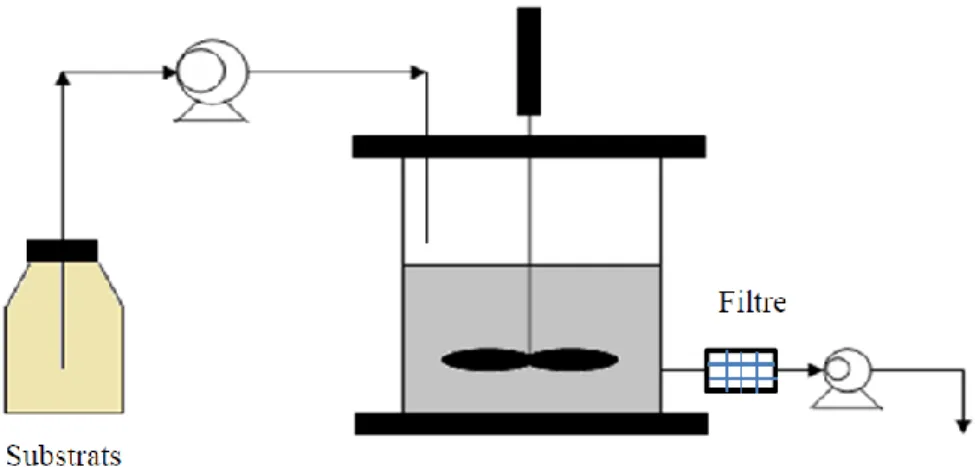
![Figure II-1 Architecture du multimodèle Takagi-Sugeno [Bez 13]](https://thumb-eu.123doks.com/thumbv2/123doknet/3446386.100656/35.893.107.840.370.728/figure-ii-architecture-du-multimodèle-takagi-sugeno-bez.webp)
![Figure II-2 Architecture du multimodèle découplé [Bez 13]](https://thumb-eu.123doks.com/thumbv2/123doknet/3446386.100656/38.893.106.832.323.742/figure-ii-architecture-du-multimodèle-découplé-bez.webp)


Documents relatifs