Generative models : a critical review
Texte intégral
Figure
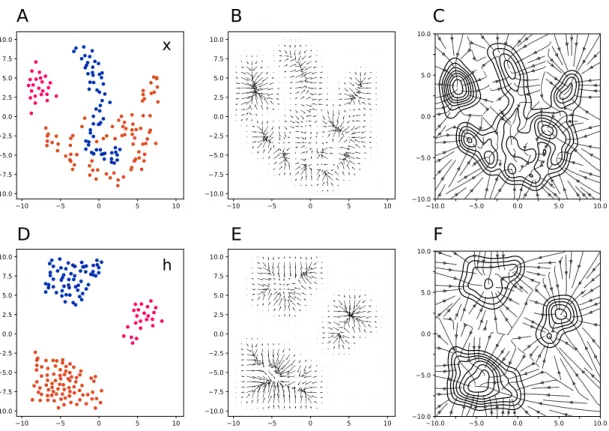
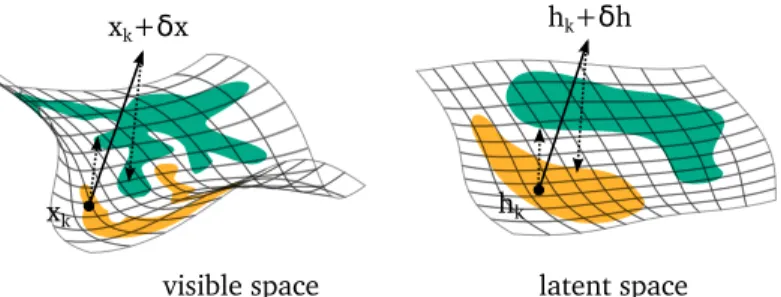
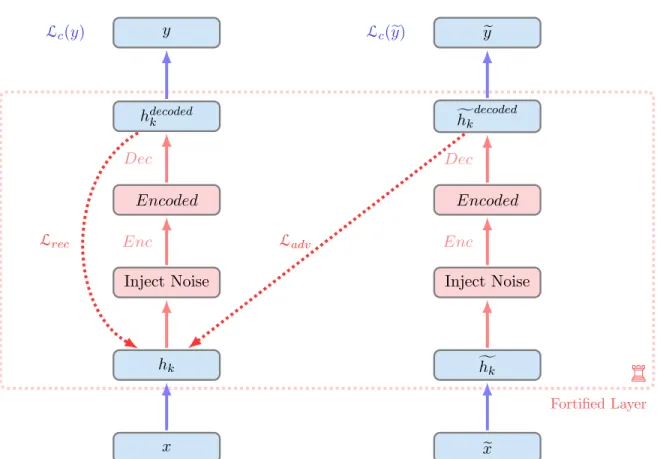
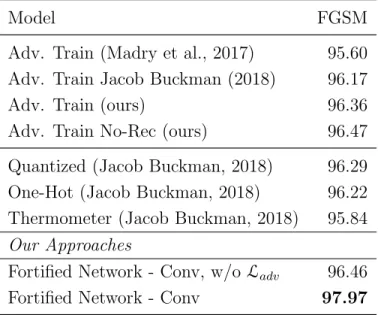

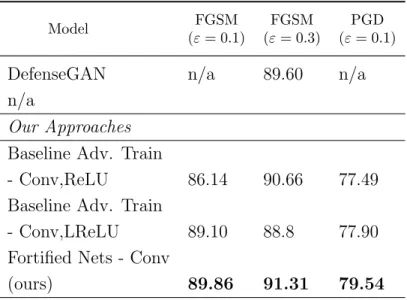
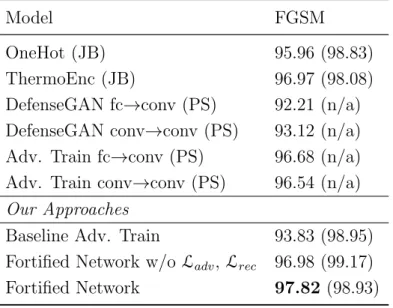
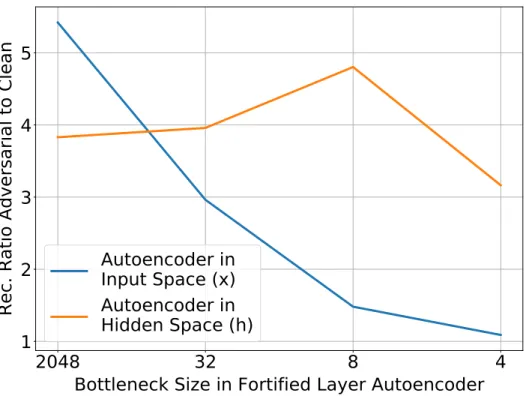


Documents relatifs
In Section III, we propose a penalized least-squares reconstruction method, called reconstruction with motion compensation and vessel prior (RMCVP), which uses the set of
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
Field experiments designed to examine the influence of prey density, nutrient availability and light intensity on mixotrophic nanoplankton abundances and their phagotrophic
This correlation matrix reflects species co-occurrence patterns not explained by the environmental predictors and may arise from model mis-specifications, miss- ing covariates
In this chapter, we first outline some of the most important and widely used latent linear models in a unified frame- work with an emphasis on their identifiability
We report results using two training sets, namely the MNIST training set and the QMNIST recon- structions of the MNIST training digits, and three testing sets, namely the official
The proof of the sufficient part of Theorem 3 makes use of the following general convergence theorem proved in [4, Th. Let us prove the reverse inclusion.. Q It is of interest to
Dans ce contexte, il n'est pas étonnant que le projet de Mario Botta pour la Banque de l'Etat de Fribourg ne suscite pas unique¬.. ment des
