Universite de Sherbrooke ^ ^^ ^-:;> ._> i 0
31156008104419
:33-Tn
c" » ^GENERATION DE PLANS REACTIFS BASEE SUR
L'ABSTRACTION
JL^-^
par
Ghassan Fadlallah
memoire presente au Departement de mathematiques et d informatique
en vue de Pobtention du grade de maitre es sciences (M.Sc.)
FACULTE DES SCIENCES
UNIVERSITE DE SHERBROOKE
Sherbrooke, Quebec, Canada, decembre 1997
1*1
National Library of Canada Acquisitions and Bibliographic Services 395 Wellington Street Ottawa ON K1AON4 Canada Bibliotheque nationale du Canada Acquisitions et services bibliographiques 395, rue Wellington Ottawa ON K1AON4 CanadaYour We Votre reference
Our file Notre reference
The author has granted a
non-exclusive licence allowing the
National Library of Canada to
reproduce, loan, distribute or sell
copies of this thesis in microform,
paper or electronic formats.
The author retains ownership of the
copyright m this thesis. Neither the
thesis nor substantial extracts from it
may be printed or otherwise
reproduced without the author's
permission.
L'auteur a accorde une Ucence non
exclusive permettant a la
Bibliofheque nationale du Canada de
reproduire, prefer, distnbuer ou
vendre des copies de cette these sous
la forme de microfiche/film, de
reproduction sur papier ou sur format
electronique.
L'auteur conserve la propriete du
droit d'auteur qui protege cette these.
Ni la these ni des extraits substantiels
de celle-ci ne doivent eti-e imprimes
ou autrement reproduits sans son
autonsation.
0-612-35673-6
Le 5 janvier 1998, Ie jury suivant a accepte ce memoire, dans sa version finale.
President-rapporteur: M. Froduald Kabanza
Membre:
Membre:
Departement de mathematiques et d'informatique
M. Abdelhamid Benchakroun
Departement de mathematiques et d'i^
M. Kacem Zeroual
Sommaire
La planification peut etre definie comme un processus permettant de poursuivre et d at-teindre des objectifs precis.
L'abstraction a longtemps ete per^ue par les chercheurs comme une maniere subtile
d analyser et de simplifier les systemes de grande taille.
Dans ce memoire, nous proposons une approche de planification qui, croyons-nous,
ac-croitra, Ie rendement dans les systemes de grande taille. Lorsque Ie probleme a etudier est modelise par un graphe, nous creons un autre graphe abstrait en groupant des parties du graphe initial. Dans chaque sous-graphe, nous appliquons V algorithme d'iteration de po-litique, ceci en vue de produire une politique partielle optimale. Les politiques assemblees a partir des sous-graphes forment une politique optimale du graphe initial.
Remerciements
M^erci aux Services des prets et bourses du gouvernement du Quebec pour 1 aide
finan-ciere accordee tout au long de mes etudes universitaires.
Merci a mon directeur de recherche, ]VL Kacem Zeroual, de sa gentillesse ainsi que de ses bons conseils fournis lors de la redaction de ce memoire.
Merci a M. Abdelhamid Benchakroun, professeur de recherche operationnelle au De-partement de mathematiques et d'informatique, pour ses suggestions qui m'ont ete tres utiles dans Ie cadre de cette recherche.
TABLE DES MATIERES
SOMMAIRE ii
REMERCIEMENTS iii
TABLE DES MATIERES vi
LISTE DES FIGURES viii
INTRODUCTION 1
CHAPITRE 1 — Travaux connexes 9
1.1 Abstraction a processus cognitifs de plusieurs niveaux ... 11
1.1.1 Planification basee sur la relaxation de predicats ... 11
1.1.2 Planification basee sur la "supervenience" ... 12
1.2 Abstraction a niveaux de details ... 14
1.2.1 Planification basee sur la technique de politique abstraite 15
1.2.2 Planification basee sur la technique d'enveloppe d'espace
cTetats ... 17
1.2.3 Planification basee sur la technique d'enveloppe abstraite 19 1.2.4 Modeles de deliberation ... 21
CHAPITRE 2 — Decomposition 25
2.1 Role de la decomposition ... 252.2 Notions de base de la decomposition ... 26
2.2.1 Algorithme de decomposition basee sur la topologie .... 27
2.3 Notions de base des processus stochastiques ... 32
2.3.1 Graphe ... 33
2.3.2 Theorie de la decision ... 34
2.3.3 Processus de decision markovien ... 35
2.3.4 Algorithme cPiteration de politique ... 37
CHAPITRE 3 — Une approche de planification basee sur 1'abstraction 39 3.1 Technique de la planification ... 39
3.2 L'approche ... 40
3.3 Representation d5un probleme de planification ... 42
3.3.1 Representation des actions en un seul etat ... 43
3.3.2 Representation d'une action en tous les etats ... 44
3.4.1 Politiques optimales dans les graphes partiels ... 46
3.4.2 Politique optimale dans Ie graphe initial ... 51
3.5 Exemple1 ... 53
3.5.1 Generation de politiques optimales dans les graphes partiels 59 3.5.2 Generation de la politique optimale dans Ie graphe initial 70 3.5.3 Plan resultant de la politique optimale dans Ie graphe initial 73
3.6 Exemple 2 ... 75
3.6.1 Generation des politiques optimales dans les graphes partiels 79 3.6.2 Generation de la politique optimale dans Ie graphe initial 81 3.6.3 Plan resultant de la politique optimale dans Ie graphe initial 83
CONCLUSION 85
BIBLIOGRAPHIE 87
LISTE DES FIGURES
2.1 Reseau de chambres ... 29
2.2 Graphe initial representant Ie reseau de chambres ... 30
2.3 Graphe abstrait ... 31
3.1 Actions possibles a 1'etat 1 ... 43
3.2 Graphe illustrant Faction 1 ... 45
3.3 Graphe partiel ajoute ... 48
3.4 Un etat fictif / dans Ie graphe ajoute precedemment ... 49
3.5 Graphe ajoute et augmente de la derniere feuille du graphe abstrait ... 50
3.6 Graphe et plan representant la politique generee par partition ... 52
3.7 Graphe et plan representant la politique optimale demandee ... 53
3.8 Graphe representant Faction 1 ... 54
3.9 Graphe representant Paction 2 ... 56
3.10 Graphe representant 1 action 3 ... 57
3.12 Sequence des graphes partiels dans Ie graphe abstrait ... 60
3.13 Graphe ajoute et augmente du graphe partiel 1 ... 61
3.14 Graphe ajoute et augmente du graphe partiel 2 ... 63
3.15 Graphe ajoute et augmente du graphe partiel 3 ... 64
3.16 Graphe ajoute et augmente du graphe partiel 4 ... 65
3.17 Graphe ajoute et augmente du graphe partiel 5 ... 67
3.18 Graphe ajoute et augmente du graphe partiel 6 ... 68
3.19 Graphe ajoute et augmente du graphe partiel 7 ... 69
3.20 Graphe et plan representant la politique generee par partition ... 71
3.21 Graphe et plan representant la politique optimale etablie ... 73
3.22 Plan resultant de la politique optimale ... 74
3.23 Graphe representant Pexemple 2 ... 75
3.24 Graphe representant Faction. 1 ... 76
3.25 Graphe representant I'action 2 ... 77
3.26 Graphe representant Faction 3 ... 78
3.27 Sequence des graphes partiels dans Ie graphe abstrait ... 79
3.28 Graphe et plan representant la politique globale generee par partition . . 81
3.29 Graphe et plan representant la politique optimale visee ... 82
3.30 Plan resultant de la politique optimale ... 84
Introduction
Les ordinateurs ont ete inventes 11 y a plus de cinquante ans et ils n'ont cesse depuis ce
temps d'etre perfectionnes. A 1'heure actuelle, nous retrouvons ces appareils
technolo-giques dans presque toutes les spheres de 1 activite humaine.
Dans les annees a venir, les ordinateurs seront encore capables d'un meilleur renderaent
dans les domaines de la planification, du raisonnement et de la generation de decisions. La planification est a la base des systemes de prise de decisions et les planificateurs reels sont des agents qui jouent un role fondamental dans la vie de tous les jours [16].
La planification, c'est tout simplement raisonner avant de passer a Paction [2]. La plani-fication ne permet pas de prevoir a long terme ni avec exactitude; elle ne peut non plus prevenir toutes les erreurs, bien qu elle puisse reduire Ie nombre de surprises. Elle peut
fournir des moyens d action quant aux evenements favorables et non favorables pouvant survenir en cours de route. Elle prevoit les choses a faire avant meme que nous ne les
fassions, ce qui nous evite d'entreprendre ces chases inutilement [21].
La planification est un probleme de longue date pour Pintelligence artificielle. Pour trai-ter un probleme relatif a la planification, 11 faut decrire un etat initial, un etat but et un ensemble de schemas generiques d'operateurs qui indiquent les actions sous-jacentes au
raisonnement entrepris pour faire un plan.
Un plan peut etre destine aussi bien a un robot d'assemblage qu a un vehicule auto-nome, un atelier de production ou tout systeme capable de fournir Ie resultat attendu en suivant ce plan [32].
Un plan est n'importe quel processus pouvant maintemr 1'ordre dans lequel une sequence
d'operations doit etre efFectuee [46]. Un plan est ainsi constitue d'une specification d'ope-rateurs qui, appliques success! vement a partir de 1'etat initial, perraettent d'atteindre Pobjectif. Un plan apporte ainsi une solution au probleme pose [31].
Un plan peut servir a superviser Ie progres pendant la resolution d un probleme ou 11
peut deceler et intercepter ou corriger les erreurs avant qu'elles causent des problemes
majeurs et compliques [15].
En ce qui a trait aux conditions de travail, soit la gestion du temps et des ressources
materielles et humaines, nous avons constate que plusieurs etudes ont examine ces
as-pects que 1 on cherche a ameliorer par les techniques de planification.
La planification en intelligence artificielle se caracterise par deux paradigmes. Le pre-mier paradigme concerne la planification classique [28, 27, 56, 24] qui suppose que 1'en-vironnement est statique [61]. Le second paradigrae concerne la planification dynamique [39, 6, 43, 29] qui met Pemphase sur la planification des systeraes reactifs dont Penviron-nement est imprevisible.
Peu importe Ie paradigme a considerer, toutes les methodes de planification font face au probleme central de la conception d'une strategic pour construire des plans optimaux
qui conduisent aux resultats escomptes.
Les concepteurs des systernes de planification classique out dans Ie passe erais differentes hypotheses qui se resument ainsi [61]:
1. Seul Pagent est actif dans Penvironnement considere; 11 n'y a pas de forces naturelles qui interferent avec 1'espace d'etats pendant Ie processus de planification ou pendant
1 execution.
2. Pour chaque application, les actions primitives de 1'agent modifieront avec succes
1 espace d etats, et cela, conformement a leurs specifications.
3. L agent est capable d'efFectuer une seule action a la fois.
4. L'agent connait tous les facteurs au debut du processus de la planification.
Sous ces hypotheses, Ie probleme de la planification revient a donner un etat initial et un ensemble de buts, puis a estimer un plan optimal et global qui, apres avoir ete execute, menera a la realisation des buts [61].
La plupart des systemes de planiflcation classique supposent une connaissance complete
de 1 univers d'ou ils fondent leurs raisonnements. De nombreux resultats issus de
re-cherches recentes [61] sur la planification suggerent que Ie paradigme de planification
classique, lequel est base sur Ie modele plan-execution d'actions ainsi que sur les supposi-tions d'un monde statique et sur un raisonnement omniscient (savoir tout sur
1'environne-ment), est inadequat pour des agents intelligents appeles a agir dans des environnements
complexes et dynamiques.
appele Ie paradigme de planification dynaraique ou reactive. La planification dynaraique touche les problemes ne pouvant etre resolus par les systemes de planification classique en raison de 1 incertitude dans Pespace, de la possibilite d echec, de la presence d autres agents ou de forces naturelles imprevisibles.
La tendance actuelle dans Ie domaine de la planification dynamique et Ie controle robo-tique est celle du developpement des systeraes reactifs. Ces systemes doi vent etre reactifs
face a leur environnement. Us re^oivent en entree un flux de donnees qu'ils infereront en
un flux correspondant de sorties de nature variee (conseils, alarmes, affichages, actions
a un precede, etc.). Ces systemes tiennent compte des evenements qui interviennent de fa^on asynchrone, notamment par Ie biais d une interruption. Ges systemes doivent aussi
hierarchiser ces interruptions en fonction de leur urgence [32]. Le but du systeme reactif est d'echapper a la planification totale (choisir toutes les actions en un seul coup) et de
choisir les actions une a la fois. Un systeme reactif doit avoir acces a la base de
don-nees qui decrit les actions devant etre prises de meme que les cir Constances entourant
ces memes actions. Les systemes reactifs previennent Pexplosion combinatoire pouvant
survenir dans la planification de deliberation, ce qui les rend interessants dans 1'accom-plissement des taches en temps reel comme la navigation d'un robot [53].
La planification reactive occupe jusqu'a maintenant une grande place au sein de
1'en-vironnement non deterministe ou des informations necessaires peuvent ne pas etre
com-pletes ou precises. La planification reactive se sert de plans predetermines pour realiser les sous-buts les plus immediats [53].
Plusieurs planificateurs out ete crees par rapport a I5 abstraction vue telle un moyen
sur pour reduire la taille et attenuer Ie caractere complexe des grands environnernents.
d'abstraction d operateurs, dans laquelle les operateurs plus abstraits sont alors definis suivant d'autres moins abstraits [58]. Dans ce modele de planificateur, chaque niveau d'abstraction se compose d'un ensemble d'operateurs (possiblement decomposables) et
de sous-buts restants. Ces niveaux sont arranges de fa^on explicite dans un reseau qui comporte une serie de procedures precises a respecter. Un niveau qui contient uniquement
des operateurs priraitifs avec des sous-buts particuliers est un plan dit executable [14].
II y a un autre type de technique d abstraction. II s agit de Pabstraction de Pespace d'etats qui est utilisee dans ABSTRIPS [56]. Ce planificateur presente une hierarchie d'espaces abstraits definie a partir du traitement des buts qui sont plus importants que les autres [15]. ABSTRIPS precede a une planification dans cette hierarchie d'espaces abstraits dont Ie plus haut niveau contient un plan ou n'apparaissent pas de details super-flus et dont Ie plus bas niveau comporte une sequence complete et detaillee d'operateurs
destines a resoudre les problemes.
GPS est un autre planificateur qui est compose d'une hierarchie d'espaces abstraits. Dans GPS un seul espace abstrait est construit lors de la resolution du probleme Ie plus general, soit celui qui se rapporte au plus haut niveau [15].
La "relaxation des predicats" est une nouvelle technique mise de Pavant pour effectuer les etats d abstraction. Le predicat est ici vrai non seulement dans les etats ou 11 est
defini, mais egalement dans tous les autres etats ou 11 peut s'averer juste au moyen d'une
ou plusieurs applications d'operateurs [14]. La "relaxation des predicats" a ete implantee dans PABLO. Ce planificateur considere d'une raaniere successive les predicats generaux, puis les autres predicats.
nous attardons ici a la technique de planification basee sur la theorie de decision et sur 1 abstraction, commela technique de planification approximative ou de strategic abstraite (strategic dans un espace d'etats abstrait du systeme) [48], la technique d'enveloppe [19] et la technique d'enveloppe abstraite [20]. Une enveloppe est un automate stochastique
restreint. Elle est un sous-ensemble d'etats de Pautomate du systeme. Elle est augrnentee
par un etat special appele OUT. Get etat represente n'importe quel etat a 1'exterieur
de Penveloppe. De meme, une enveloppe abstraite est un sous-ensemble raais de 1 espace
d etats abstrait du systeme.
Peu importe Ie paradigme de planification a choisir, la diminution de la taille de 1'es-pace de recherche demeure toujours une tache delicate lors des activites de planification, parce que ces activites impliquent une multitude d'operations complexes.
Les dernieres recherches efFectuees dans Ie paradigme de la planification reactive visent a eviter les difB.cultes liees a la planification faite dans les environneraents inaccessibles et dynamiques. Les chercheurs se sont penches sur Pidee des politiques optiraales dans Ie processus markovien [55, 59]. La methode de planification reactive dans ce paradigrae propose d'utiliser Valgorithme d iteration de politique du processus de decision markovien. Malgre son ef&cacite, cet algorithme n'est pas pratique dans les espaces de grande taille [19]. Pour cette raison, la planiflcation reactive sera inefficace et ne pourra etre traitee.
Pour trailer ce probleme, nous suggerons d'adopter une approche basee sur 1'abstraction.
II s'agit d'utiliser la decoraposition corarae un outil qui va diminuer la taille de Pespace d etats. La decomposition consiste a trouver une technique adequate ou un probleme P se divise en composantes P,, lesquelles satisferont a certames conditions.
Dans les planificateurs traditionnels, un probleme complexe est decompose selon une hierarchie de problemes simples. Lorsqu'une solution a ete trouvee pour aborder Ie ou
les problemes mineurs, il importe de se servir de cette meme solution pour regler les problemes encore plus ardus, tout ceci, jusqu'a ce que Ie probleme initial ait ete resolu. Meme si les solutions apportees a ces problemes simples ne sont generalement pas des plans executables, elles permettent tout de meme de vaincre les difficultes qu'engendrent
certains problemes, ceci par Ie seul fait d''orienter la recherche vers une resolution des
problemes moins abstraits [20].
L'espace de recherche est, dans notre perspective de travail, illustre par un graphe a 1 interieur duquel chaque nceud repond a une situation probable et chaque arc a un ope-rateur applicable. Lorsque Pespace a etudier est reproduit par un graphe initial, un graphe abstrait doit etre construit en fonction des parties constituantes du graphe initial. Ainsi, chaque partie produite est un graphe partiel et elle represente un etat dans Ie nouveau graphe. Dans chacun de ces graphes partiels qui sont des espaces de petite taille, nous emploierons 1 algorithme d iteration de politique a grande efficacite puis construirons une politique globale du graphe initial par synthese des politiques partielles. Cette politique globale est analogue a la politique optimale ou au plan a faire. Cette politique est ega-lement choisie comme politique de fond de I5 algorithme d)iteration de politique dans Ie graphe initial. Get algorithme va fournir avec rapidite Ie plan deraande.
Dans notre travail, nous visons a resoudre Ie probleme de la generation de plans re-actifs dans les systemes de grande taille. Pour cerner cette question, nous avons divise notre travail en trois chapitres. Dans Ie premier chapitre, nous presentons quelques
tra-vaux connexes qui portent sur 1 abstraction puis sur la theorie de la decision, comme Papproche de la planification approximative, 1'approche de 1'enveloppe et 1'approche de la politique abstraite. Dans Ie deuxieme chapitre, nous abordons les notions de base de la decomposition, de la theorie des graphes et des chaines de M^arkov, et un algorithme de decomposition base sur la topologie. Dans Ie troisieme chapitre, nous introduisons
une nouvelle approche de planification qui se fonde sur 1 abstraction et nous donnons deux exemples qui illustrent certains aspects de notre methode. La conclusion effectue un retour sur les trois grands points examines dans notre travail et souligne les aspects
favorables de notre approche. La conclusion apporte aussi d'autres elements de recherche
CHAPITRE 1
Travaux connexes
Nous abordons Ie probleme de la planification dans les domaines non deterministes en
tenant compte des situations et des connaissances de nature ambigue. Plusieurs theories
et algorithmes ont ete developpes pour trouver les politiques optimales ou les plans dans
ces domaines.
Les algorithmes de la programmation dynamique dont nous nous servons pour creer la politique optimale sont utiles dans les espaces d'etats de petite et de moyenne taille, mais ils demeurent difficiles a trailer dans les tres larges espaces. Plusieurs suppositions
informelles [19], notamment celles rattachees aux environnements de travail, sont enon-cees pour contrer les difficultes et Ie mauvais rendement dans ce genre d'espace d'etats.
Ce fait permet de generer efficacement des solutions approximatives. L'environnement devrait avoir les proprietes suivantes :
- Une grande densite de solution: 11 est assez facile d'obtenir des solutions adequates. - Un petit taux de dispersion: a partir de n'importe quel etat, il existe un nombre
Continuite: 11 est raisonnable d'estimer les valeurs des etats en considerant les
valeurs des etats proches.
L abstraction nous dit d'ignorer les details et de nous concentrer sur les aspects majeurs du probleme [14]. Elle perraet aussi de rendre la recherche moins exhaustive [40]. Deux types d'abstraction out joue un role important dans les recherches en intelligence arti-ficielle. Le premier type d'abstraction est pris dans la theorie du controle robotique et dans la recherche sur les modeles cognitifs a large echelle. Dans ce type d abstraction, les processus cognitifs sont divises en plusieurs niveaux, leur donnant ainsi une certaine "souplesse" dans leur comportement pendant 1'utilisation de la modularite et du paralle-lisme. Ce genre d abstraction est illustre par Ie travail sur les architectures "blackboard" comme IIEARSAY-II [25] et dans lesquelles des structures de controle peuvent etre em-ployees pour rendre plus simple la resolution du probleme [61].
Le deuxieme type d'abstraction divise les systemes en des niveaux de detail (ABSTRIPS) [56]. Nous avons accorde recemment beaucoup d'importance a ce type d'abstraction qui est maintenant bien compris : les procedures rigoureuses qui y ont ete appliquees viennent demontrer 1 utilite de ce type d'abstraction dans la reduction de la taille de certains es-paces de recherche [38].
1.1 Abstraction a processus cognitifs de plusieurs
ni-veaux
1.1.1 Planification basee sur la relaxation de predicats
PABLO (Predicate ABstraction LOgic) [14] est un planificateur non lineaire qui raisonne hierarchiquement en generant des predicats abstraits. II agit dans une hierarchie d espaces abstraits. Dans PABLO les espaces abstraits de recherche sont produits de maniere au-tomatique grace a une technique de relaxation de predicats. Cette technique a comme objet de definir les hierarchies des predicats abstraits. Durant la planification, PABLO considere d'abord les predicats les plus generaux, puis ensuite les raoins generaux et il associe a chaque niveau de planification un niveau de relaxation, tout en faisant des
plans avec des predicats relaxes de ce niveau. Quand on elabore un plan dans un niveau
n, chaque predicat P dans les preconditions des operateurs et des buts est reraplace par Ie predicat Png; qui est defini comme suit:
?°. — ~rel =
%=^71vm^(Op.,^T1)
ou Reg(Opi^P) est la regression du predicat P a travers Poperateur Op^ et m est Ie
nombre d operateurs consideres dans Ie domaine.
Quand on descend les niveaux d'abstraction, par exemple, si des nouveaux sous-buts
independamment. En efFet, ces predicats etant consideres comme des "details" aux hauts
niveaux, ils n out pas de consequences globales.
La trace de la "relaxation" d'un predicat est en fait un plan reactif pour accomplir ce predicat en tant que tel. Ceci est une technique tres proraetteuse. Chaque plan indi-viduel est restreint en grandeur et peut etre pris par Ie planificateur dans les differentes instances du meme predicat. Contrairement aux autres techniques de la planification
re-active, lesquelles doivent construire un nouveau plan reactif pour chaque corabinaison de
buts a atteindre, PABLO peut reutiliser les definitions des plans reactifs de n'iraporte quel but specifie dans Ie doraaine. Avec PABLO 11 est possible d'etendre la methode de planification a des plans reactifs restreints, c est-a-dire d'autoriser seulement les
condi-tions communes que nous avons rencontrees dans les definicondi-tions relaxees. Ceci reduit Ie nombre d'espaces abstraits identifies aux hauts niveaux, donnant 1'occasion a chaque
predicat d'etre plus aisement identifie pour tenir de maniere abstraite.
1.1.2 Planiflcation basee sur la "supervenience"
La supervenient planning est une expression qui sous-entend une forme de planification abstraite. La "supervenience" [61] est une architecture qui capte les notions d5 abstraction
importantes pour les systemes devant integrer un raisonnement de haut niveau avec des actions en temps reel.
La consideration generale de la "supervenience" tient cependant compte de 1'utilisation d'une abstraction semblable a celle vacante dans les architectures "blackboard" (1'uti-lisation d une abstraction qui n'est pas possible dans n'importe quel systerae de style ABSTRIPS). Par exemple, un systeme de la "supervenient planning" peut prendre les difFerents systemes de representation des connaissances et les differents mecanismes du
raisonnement dans chaque niveau de la hierarchie d'abstraction. La "supervenience" est
une architecture a plusieurs niveaux de donnees/traiteraent pour integrer la planifica-tion et pour reagir dans les environnements dynamiques et complexes. Li dee centrale
de la supervenience" est que les representations de bas niveaux d abstraction sont
epis-temologiquement plus proches de la realite que celles de hauts niveaux. De plus, les
representations de hauts niveaux dependent de celles de plus bas niveaux. Les niveaux eleves peuvent contenir des representations qui sont des etats simplifies des niveaux m.oins eleves, mais ils peuvent aussi contenir des representations complexes, des ensembles bien structures qui n'ont pas de representations unifiees de bas niveaux.
La relation de supervenience" peut etre formalisee en utilisant Ie concept de "non
fai-sabilite" atm d'expliquer ce qu'on entend par "en savoir plus". La "supervenience" est
definie comme un cas selon lequel les bas niveaux peuvent detruire les faits des hauts
niveaux. Cette action ne peut etre appliquee inversement. La connaissance de bas
ni-veaux se traduit dans les hauts nini-veaux par des faits reels, tandis que la connaissance de
hauts niveaux apparait dans les bas niveaux comme des faits incertains. Cette raaniere d identifier les niveaux pourrait etre comparee a un mouvement ascendant, soit d'un etat
d affirmation et descendant, soit d'un etat de supposition.
L architecture de la "supervenience" se definit comrae quelques niveaux de donnees/traitement. Chaque niveau communique seulement avec les niveaux qui se trouvent dans 1'immediat
au-dessus et au-dessous d eux-memes dans la hierarchie. Les niveaux peuvent s'executer en parallele et communiquer de maniere asynchrone.
L5 architecture de "supervenience" a ete implantee dans Ie systeme "Abstraction Partitio-ned Evaluator" APE pour lequel un ensemble de cinq niveaux a ete choisi. Ces niveaux vont du plus bas au plus haut: perceptuel/manuel, spatial, temporel, causal et
conven-tionnel. APE raisonne a partir d'operateurs specifies sous forrne des reseaux de Petri et tient compte du parallelisme et des cornportements asynchrones. APE a ete applique dans un environnement de simulation appele domaine de "HomeBot"ou un robot domestique
est responsable d'une variete de taches. La performance du systerae "HoraeBot" n'est pas
suffisante jusqu'a present pour ce qui est de la reactivite a temps reel, mais elle peut etre amelioree par 1 optimisation et par la reimplantation dans un environnement parallele. L analyse de la performance du systeme actuel indique que deux extensions peuvent etre particulierement tres utiles. II s'agit des mecamsmes qui suppriment les operations non
appropriees et les mecanismes qui s'occupent des petits sous-ensembles relies au tableau local.
1.2 Abstraction a niveaux de details
Les recherches dans Ie domaine de la planification classique reposent sur des suppositions irrealistes qui adrnettent la connaissance complete de Penvironnement et des efFets des actions. Ces suppositions out ete verifiees dans Ie travail sur la planification dynamique [42]. La planification basee sur la theorie de la decision entrame Ie concept de plans ou politique. Une politique constitue 1 ensemble des decisions qui sont alors transposees cha-cune en un etat du graphe qui lui represente Ie problerae a etudier.
Plusieurs techniques out ete mises de 1'avant sur la politique optimale qui se repose sur Ie principe de maximiser Ie gain ou la moyenne des recompenses par transition. Un gain
est Ie revenu positif associe a une transition. Une recompense est une valeur attribuee
a un etat pour exprimer sa desirabilite. Ces techniques consistent en une restriction de recherche et une programmation dynamique pour des regions locales ou des enveloppes (sous-espaces de Pespace d'etats considere) [18, 64]. La programmation dynamique est
une technique d'optimisation permettant de resoudre les problems construits en modeles mathematiques . Elle permet d'optimiser une fonction separable de plusieurs variables liees par des contraintes (equations ou inequations) lineaires ou non lineaires [12].
1.2.1 Planification basee sur la technique de politique abstraite
Richard Dearden et Craig Boutilier [20] avancent une technique d'abstraction pour Ie processus de decision markovien PDM. Cette technique permet de calculer avec ap-proximation les solutions optimales du probleme. Ces chercheurs adoptent une methode d'abstraction dont certains details du probleme original (dans ce cas des atomes propo-sitionnels) sent ignores.
Pour accomplir 1'abstraction, ils construisent un PDM abstrait qui a moins d'etats, mais avec Ie meme ensemble d actions que Ie probleme initial. Pour reduire Ie nombre d etats, la description propositionnelle du probleme (c'est-a-dire actions et structure de recom-pense) est utilisee pour choisir quelques sous-enserables de variables qui sont considerees comme moins appropriees que Ie reste. Ges variables sont elirainees de la description du probleme. L idee de cette methode est de construire un probleme abstrait qui prend seulement les parties importantes du problerae original concret, de trouver une politique optimale pour ce probleme en prenant les algorithmes ordinaires et d'appliquer cette po-litique dans Ie probleme initial.
La construction de la politique optimale approximative utilisant 1'abstraction se fait
selon Palgorithme suivant [20]:
1. Utiliser la representation probabilitique de STRIPS, choisir les atomes importants pour construire une politique plausible (Ce qui defmit un espace d'etats abstrait
S).
2. Construire pour chaque action, une fonction abstraite de transition T par 1 elimi-nation de toute reference a des atomes non utiles dans la description d actions, et transformer la representation de STRIPS etendue de Paction en une fonction de transition de PDM. Noter qu'il n est pas necessaire de construire une raatrice de transition explicite pour chaque action comrae les regles etendues de STRIPS qul peuvent etre employees pour generer directement les equations lineaires requises pour Ie mecanisme d'iteration de politique.
3. Construire J?, la fonction de recompense pour Ie probleme abstrait.
4. Utiliser Yalgorithme d'iteration de politique pour trouver la politique optimale TT pour Ie PDM < S,A,T, R >.
5. Construire la politique TT telle que pour tout etat s G s € 5',7r(s) = ^(fi), ou 7r(5) est la politique associee a chaque element du groupe s. TT est une politique optimale approximative pour Ie PD]M original.
L'espace abstrait d'etats 6' est I'ensemble d'etats introduits par Ie langage obtenu en eliminant les atomes inappropries. Une vue alternative de Pespace d'etats abstrait est comme une agregation d'etats: chaque etat abstrait s C S est une collection d'etats concrets tel que chaque s G s est indifFerenciable dans Ie langage reduit. Alors, un
en-semble d'actions et une fonction de recompenses convenables au nouveau espace d'etats
S doivent etre batis. Une caracteristique fondamentale de ce modele est que 1'ensem.ble d actions abstrait est Ie meme que 1'enserable d'actions du probleme original.
Dans ce PDM abstrait, les methodes ordinaires, comme Valgorithme d'iteration de poli-tique^ peuvent etre prises pour produire une politique abstraite TT en associant une action a chaque etat abstrait s € S. Finalement, la politique abstraite determine une politique
concrete TT telle que 7r(s) = 7r(s) pour tout 5 C s : Faction associee a un groupe est appliquee a chaque etat constituant.
1.2.2 Planification basee sur la technique d?enveloppe cPespace
cPetats
Pour resoudre Ie probleme dans les espaces d'etats de grande taille, Dean T., et al. [19,18]
ont elabore une approche basee sur la theorie du processus de decision markovien en vue
de rendre la planification plus efficace en particulier dans les domaines non deterministes. Cette approche motivee par Ie travail de Drummond et Bresina [23] permet de traiter efficacement des espaces d'etats de grande taille. Elle utilise des informations concernant
ces espaces pour restreindre Pattention des planificateurs sur un ensemble d'etats
pro-babies qui peuvent etre rencontres pour atteindre Ie but. Dans cet ensemble restreint, Ie planificateur genere des plans plus ou moins cornplets dans un laps de temps deter-mine. Cette approche basee sur les techniques existantes de la production des politiques
considere que 1 environnement peut etre modele comme un automate stochastique: un
ensemble d'etats, un ensemble d'actions et des matrices de probabilites de transition.
Dans cette approche, la construction d'un plan repose sur une politique qui vise a donner
une grande performance. Cette derniere est basee sur les recompenses accumulees sur les
sequences de transitions d etats determinees par Fautomate stochastique sous-jacent. Les
recompenses sont determinees par une fonction de recompense specialement formalisee pour un but donne.
Comme la taille des espaces d'etats croit, alors Valgorithme d'iteration de politique de-vient trop inefficace. Au lieu de generer la politique optimale pour Ie systeme d'automate
tout entier, cette approche construit un automate stochastique restreint a partir duquel elle determine la politique optimale partielle.
Une politique partielle est une application d'un sous-ensemble Si de 1'espace d'etats S vers Pensemble des actions A; c'est I'ensemble des decisions choisies pour les etats de 5ri. Le domaine d'une politique partielle TT s'appelle enveloppe e^, et la frange d une politique partielle F^ est 1'ensemble des etats s qui n'appartiennent pas a 1 enveloppe e^ de cette politique, mais qui peuvent etre parvenus dans une seule etape d'execution de la poli-tique a partir de quelques etats 5 dans Penveloppe; c'est Pensemble des etats atteints par 1'execution des actions de la politique exprimees par: Pr(s/, 7r(5/), s) > 0, ou Pr(^i,a, ^2) designe la probabilite de passer de 1'etat si a 1'etat 52 en executant 1'action a. Alors,
F^{se(S- £,) | (3sf e ^ \ Pr(sf, 7T(sf),s) > 0)}.
La construction d'un automate restreint se fait en prenant une enveloppe e, contenant
au debut les etats du plus court chemin de 1'etat de depart a 1'etat but, et puis par 1 ajout de 1 et at distingue OUT. L etat OUT represente n importe quel etat a 1'exterieur de Penveloppe. Pour n"'importe quel etat s et s' dans e et n'importe quelle action a dans A, la probabilite de transition reste la meme. En outre, V^ C 5'etaG A, nous definissons la probabilite de sortir de 1'enveloppe comnie:
Pr(s,a,OUT)=l- E Pr(s,a,sf).
s'Ge
Comme concession a la complexite dans la generation d'une politique, cette approche
considere seulement un sous-ensemble de I'espace d'etats du processus stochastique. Elle
commence part une politique initiale et une enveloppe e, puis elle etend cette enveloppe
Cette approche comporte deux etapes : la modification de Penveloppe e et la genera-tion de la politique. Ces deux etapes sont traitees separement quand nous debutons Ie processus global de la production de la politique en fonction de quelques parcours de modification de 1 enveloppe e suivie par la generation de la politique. A 1'etape de la mo-dification de Penveloppe, 1'approche prend une enveloppe et une politique comme entree
et genere une nouvelle enveloppe et une nouvelle politique comme sortie.
La generation de la politique est elle meme un algorithme iteratif qui ameliore la poli-tique initiale en estiraant les valeurs des polipoli-tiques par rapport au processus stochaspoli-tique d'espace restreint d'etats. La generation de la politique continue a iterer jusqu'a trouver une politique qui ne peut pas etre amelioree par rapport a sa valeur d'estimation; cette politique est garantie pour etre optimale a Regard du processus stochastique d'espace
restreint d'etats.
1.2.3 Planification basee sur la technique d'enveloppe abstraite
Nicholson A. et Kaelbling L. [48] etendent Ie travail precedent de Dean [19, 18] en intro-duisant une nouvelle technique pour construire des modeles d'espace d'etats abstraits. Ces modeles allouent une planification approximative efl&cace dans les domaines stochas-tiques tres larges. En effet, un espace abstrait d'etats de I'espace d'etats considere est construit en eliminant quelques dimensions de la description de 1'espace d'etats original,
de sorte que chaque etat dans 1'espace abstrait se presente coranie une classe
d'equiva-lence d etats de 1 esp ace initial. Etant donner un monde original < 5', A, T, R > ou les
elements de S ont la forme < a;i,..., Xm >, une abstraction peut etre specifiee en donnant
un ensemble d'indices i pour realiser 1'elimination des dimensions. Le monde abstrait est < 6',A,T,R >. L'etat 5"/ est construit en eliminant de chaque element les attributs
qui ont leurs indices dans i. Gette technique applique Palgorithme base sur la technique enveloppe utilisee dans Ie travail precedent, raais a condition d'extraire 1'enveloppe e de Pespace d'etats abstrait deja construit. Pour restreindre Pespace d'etats avant 1 applica-tion de Palgorithme a base de la technique enveloppe, on peut potentiellement reduire radicalement Ie nombre d'etats dans 1'enveloppe.
L'algorithme etendu de la planification est comme suit:
1. Generer une vue initiale du domaine < S , A, T', R' >.
2. Generer une enveloppe initiale e C S .
3. Tant que (e ^ Sf) et (non "deadline") faire
- Etendre 1 enveloppe e.
- Generer une politique optimale TT pour 1 automate restreint avec 1'ensemble
d'etats eU OUT.
- Si la vue courante du doraaine est insuffisante alors,
- Etendre la vue du domaine.
- Aller a 1'etape 2.
4. Retourner TT
Get algorithme, initialement, s execute en faisant une grande approximation du monde reel, dans laquelle 11 derive rapidement une politique partielle primaire. Alors que, Ie domaine approxime deja defini est toujours raffine et des nouvelles politiques sont y construites jusqu a arriver a la politique optimale.
1.2.4 Modeles de deliberation
Ce genre d'approches utilise les modeles de deliberation pour allouer des ressources a plusieurs routines iteratives et raffinees qui sont considerees pour resoudre les difFerents aspects du probleme de la determination des decisions. Deux modeles de deliberation sont presentes: Ie modele de deliberation precurseur et Ie modele de deliberation recurrente
[19].
Dans Ie modele de deliberation precurseur, toutes les decisions en formation sont
ac-complies anterieurement a Pexecution. Ce modele comporte deux phases separees
d'ope-rations: la planification et 1 execution. Le planificateur construit une politique qui est suivie par 1 agent jusqu a ce qu'un nouveau but soit poursuivi ou jusqu'a ce que 1'agent
tombe a, 1'exterieur de Penveloppe actuelle. Dans ce modele, un echeancier est specifie indiquant quand la planification s'arrete et 1'execution commence.
Pour une description donnee de 1'environnem.ent et un etat de depart SQ ou une
dis-tribution sur les etats de depart, Palgorithme de deliberation precurseur est cornrae suit:
1. Generer une enveloppe initiale e.
2. Tant que (e •=/=• S) et (non "deadline") faire (a) Etendre Penveloppe £.
(b) Generer une politique optimale TT pour Pautomate restreint avec 1'ensemble
d'etats £ U {OUT}.
3. Retourner TT.
Premierement, Palgorithme trouve un petit sous-ensemble de Pespace d'etats globale et calcule une politique optimale sur ses etats. Puis, il ajoute graduellement des nouveaux
etats dans Ie but de rendre la politique robuste par la diminution des chances que 1'agent tombe hors de Penveloppe. Apres que des etats sont ajoutes, la politique optimale sur cette nouvelle enveloppe est calculee. L'algorithme terraine quand un echeancier a ete atteint ou quand 1 enveloppe a ete developpee pour inclure 1 espace d etats tout entier.
Le modele de deliberation recurrente est un modele plus sophistique d'interaction entre la planification et 1 execution. Dans ce modele Ie planiflcateur s'execute simultanement
avec Pexecuteur en envoyant les nouvelles politiques a Pexecuteur a mesure qu'elles sont developpees, ou toutes les decisions en formation sont accomplies parallelement avec
1'exe-cution.
Deux modules separes sont con^us : un pour la planification et 1'autre pour 1'execution.
Dans ce modele, Ie planificateur et 1'executeur operent dans un cycle rigide avec une periode determinee par une longueur fixee de temps. Au debut de chaque cycle, Ie plani-ficateur fournit 1'etat courant pour Ie module cTexecution. II envoie la longueur fixee du temps en travaillant sur une nouvelle politique. A la fin du temps fixe, Ie planificateur donne la nouvelle politique au modele d'execution.
Dans les modeles recurrents, il est souvent necessaire d'enlever des etats de 1'enveloppe
afin de diminuer les couts afFerents aux calculs de generation de politiques de 1'automate
restreint.
L algorithme de la planification recurrente, qui donne une description de 1'environne-ment, la politique TTc qui est actuellement suivie par Pagent, et 1'etat Sc de 1'agent au debut de Pintervalle de planification, est cornme suit:
1. Tant que (non but) faire
2. Poser Sc pour etre Petat courant.
3. Tant que (n'est pas la fin de Pintervalle de la planification courante) faire (a) Etendre Penveloppe e.
(b) Elaguer Penveloppe e.
(c) Generer une politique optimale TT pour Pautomate restreint avec 1'ensemble
(Tetats £ U {OUT}.
4. Poser TTc pour etre la nouvelle politique TT .
L'algorithme de deliberation consiste en des composantes suivantes: 1. Generation de la politique :
Pour un automate restreint avec une enveloppe e, 1 algorithrae d iteration de la poli-tique est utilise pour generer une polipoli-tique optimale. L'utilisation de cet algorithme comme une procedure dans 1 algorithme de deliberation genere une politique plau-sible pour la premiere etape, et alors Pancienne politique est utilisee pour les etapes posterieures; elle est Ie point de depart de 1'algorithme d'iteration de la politique. La politique ne se change pas radicalement si 1 enveloppe est etendue.
Occasion-nellement, quand une consequence dure ou un nouveau chemin exceptionnel est
decouvert, la politique doit etre changee. 2. Planification de la trajectoire initiale:
Un chemin a partir de 1 et at de depart SQ au but est construit en effectuant une recherche en profondeur de 5o, et en considerant Ie plus probable aboutissernent pour chaque action par ordre decroissant de probabilite. Ce qui genere un ensemble d'etats qui peuvent etre traverses pour atteindre Ie but, en eliminant les etats intermediaires qui ne diminuent pas la probabilite d'atteindre Ie but dans Ie chemin
resultant.
Cette methode est utilisee pour generer un petit nombre de chemins de 1'etat de depart au but, puis Ie plus court chemin (il est souvent Ie chemin qui a la plus grande probabilite) est choisi, selon sa probabilite, pour former Penveloppe initial de la politique.
3. Modification de Penveloppe:
La modification de 1 enveloppe peut etre classifiee en fonction de trois operations sur 1'enveloppe: la planification de trajectoire, 1'extension de Fenveloppe et 1'elagage de 1 enveloppe.
(a,) Planification de la trajectoire : elle est efFectuee de la meme rnamere que la planification de la trajectoire initiale, a 1'exception que les notions de Petat initial et du but peu vent varier.
(b) Extension de Penveloppe: elle vise a etendre Penveloppe choisie en y ajoutant des nouveaux etats de la politique courante. Une strategie simple est d'ajou-ter la frange de la politique courante toute entiere, ce qui resulte en 1'ajout
uniforme des etats autour de I'enveloppe courante.
(c) Elagage de Penveloppe: une methode est d'elaguer des etats de 1'enveloppe ac-tuelle de telle fa^on qu'il est improbable que 1'agent termine par ces etats, et par consequence ils ne sont pas consideres dans la formulation de la politique. Cependant, il est necessaire de faire attention a la methode suivie. II est pos-sible qu'un etat alt une basse recompense instantanee ou il est une telle sorte de puits; 11 est improbable de Patteindre et de Ie quitter par 1'agent. Dans ce cas, la politique courante va diriger 1'agent loin de cet etat, en aboutissant a une faible probabilite pour que cet etat soit parvenu. Souvent, il est necessaire de garder ce genre d'etats dans 1'enveloppe puisque sa presence dirige 1'agent loin d une zone qu'il veut eviter.
CHAPITRE 2
Decomposition
2.1 Role de la decomposition
La recherche de modeles de representation dans les domaines les plus divers conduit par souci de realisme a des systernes de grande taille, dont 1'analyse devient impossible, la simulation trop couteuse et la realisation d'une commande tres difficile. II est done in-dispensable d'etablir une theorie comme la decoraposition pour apprehender, de raamere systematique, ces systemes. La decomposition consiste a partitionner un systeme initial
en plusieurs sous systemes, a resoudre un certain nombre de problemes sur ces derniers
puis a coordonner 1 ensemble atm d atteindre ou d'approcher 1'objectif global [66]. Ce qui implique que Ie traitement des grands systemes est remplace par des traitements des petits sous systemes. De ce fait, Ie role de la decomposition est d'optimiser Ie travail a faire et de reduire les taches d'analyse, conception, controle, verification et maintenance.
2.2 Notions de base de la decomposition
Devant les multiples methodes de planification qui existent de nos jours, les chercheurs tentent, mais en vain, d'appliquer des techniques ad hoc qui conduisent tres souvent a des situations encore plus problematiques. Ces techniques s averent peu efficaces dans la pratique du fait qu elles comportent certains aspects qui empechent de realiser avec rapidite les plans recherches. Le planificateur a done besoin de meilleurs techniques s'il
veut en faire un instrument rent able .
Pour surmonter les difficultes entourant les problemes actuels, nous nous en reportons a
des approches usuelles de la planification. Celles-ci reposent sur Ie principe de reduire la taille du probleme a planifier en elirainant quelques parties, alors que la decomposition implique la diminution de la taille du probleme, sans toutefois en negliger aucune de ses
parties.
La decomposition se definit corame une operation par laquelle un probleme de grande taille est remplace par une suite de problemes de nature moindre. La decomposition per-met d'economiser des operateurs et des espaces memoires [57]. II faut diviser Ie probleme en de petits problemes, les resoudre separeraent et combiner les resultats obtenus [44].
La decomposition a ete longtemps con^ue coniine un ban outil pour analyser les systemes
de grande taille. Par exemple, elle a ete utilisee en analyse numerique ou la demarche fondamentale consiste a remplacer la resolution numerique d'un probleme complexe par la resolution numerique d'une suite de probleraes plus simple a resoudre [57].
La decomposition peut etre appliquee aux raodeles mathematiques qui representent des systemes a large echelle, ou elle fait a decomposer un probleme en un ensemble de sous
problemes de petite dimension dont leur reunion est equivalente au probleme original. Ces sous problemes doivent etre facile a resoudre et peuvent etre traites independamment [34].
La decomposition se traduit par 1'application d'une technique adequate selon laquelle un systeme S donne se divise en composantes ^, lesquelles repondent a certaines condi-tions qui preservent Ie probleme initial.
En matiere de decomposition des systemes, une approche formelle et systematique a ete developpee [5]. Cette approche se sert de notions de la topologie et des systemes a transition d etats pour deliver des composantes d'un systeme global. Son aspect original,
que nous ne retrouvons pas parmi d'autres techniques apparaissant dans la documenta-tion scientifique, consiste en ce que 1'etape de decomposidocumenta-tion est amorcee sans a priori quant au nombre de composantes inter venant dans Ie systeme a decomposer.
Au paragraphe suivant, nous presentons brievement 1'algorithm.e de decomposition que
nous allons utiliser dans ce travail.
2.2.1 Algorithme de decomposition basee sur la topologie
L'algorithme de decomposition basee sur la topologie [5] consiste tout d'abord a definir Ie
systeme S a decomposer, a determiner ses caracteristiques essentielles et les transferer en
des documents de specification complets et corrects, puis a modeliser ces specifications par un systeme de transition (ou machine d'etats finis) S = (Q^i^(10iQm)i ou Q designe 1 ensemble des etats du systeme, ^ Palphabet, S la fonction de transitions, qo 1 etat initial et Qm 1'ensemble des etats marques. L'etape suivante de cet algorithme se rapporte a definir Ie modele topologique du systeme en determinant un langage fini
Indus dans P^-langage 0 = Adh(L(S)) reconnu par 5', ou Adh(L(S)) est 1'adherence
du L(S). St la relation Oi U 0^ ^ Adh(0) U (9 n'est pas vraie, alors 11 doit la rendre vraie
par:
- definir une application de correspondance entre ouverts et predicats, soit
^ : Pco(E°°) —^POU P, = <S>(Oi) pour i = 1, 2,
ou P: ensemble des predicats, ^°°: ensemble des mots finis et infinis sur ^ et PcoQCO) = {X C E°° :X est compact };
determiner ^ (P^) ou la suite finie de predicats P^, P^,..., P; est telle que:
,piv-?2= y^',
i=l
puis, determiner les modules de connexion dans Ie systeme; les modules responsables de
Pexecution des taches communes aux sous-systeraes. Une fois les modules de connexions
sont etablis, cet algorithrae utilise les criteres de Miiller pour :
- convertir les ouverts 0, obtenus en termes de systemes a transitions d'etats,
denotes Si;
- produire les composantes du systerae dans Ie cas ou les Sk ainsi obtenus verifient les specifications du systeme deja defini. Dans Ie cas contraire, il doit redefinir ces specifications et recommencer 1 algorithme du debut.
Exemple de decomposition
1. Definir Ie systeme et determiner ses specifications
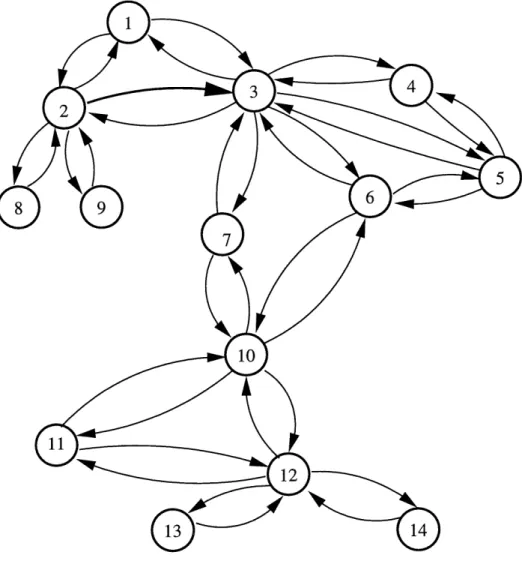
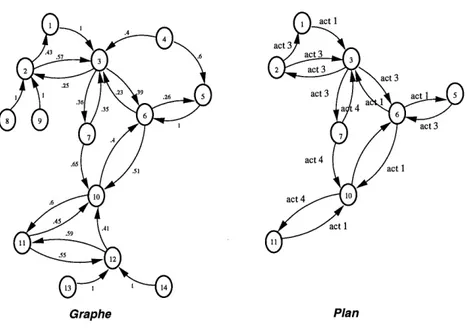
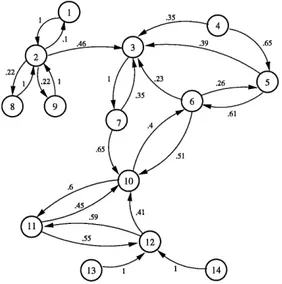
Nous presentons Ie probleme de construire un plan de navigation d'un robot dans un reseau de chambres (voir figure 2.1).
8
1
9
2
14
7
3
4
5
6
10
12
13
11
Figure 2.1 - Reseau de chambres
connexion directe des chambres et des couloirs par une corde ou bien par un arc
bidirectionnel (voir figure 2.2).
Figure 2.2 - Graphe initial representant Ie reseau de chambres
2. Decomposition du graphe
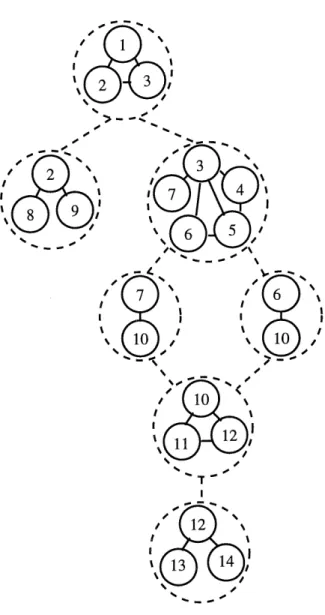
En appliquant 1 algorithme de decomposition basee sur la topologie [5], nous
nons Ie graphe abstrait suivant (voir figure 2.3) qui servira de base pour la deter-mination du plan. /• / / I
\(
\v s / I I;,(
\v
^ ^ ^^'ffiss
8)lL
'i ^1
2
s >-<^ \ I>;
^
/(
I\
s <»\
*^)''
"/ ^ — ^ ^ ^» ^ / li'( 7
I'\(
/^ ?>—_ -^.3
^
/ ^-^-.
^\
!
10),
'^' \ \<-/ /' / ,-s-V.
^J\
';
<5J/'
^\ -^ \.>
,/(
I\
s>
^ ^-=<'N^10
\
\ _-<6
10
"«« ^\1\
I I/
'^' •2.3 Notions de base des processus stochastiques
Les processus stochastiques et en particulier les chaines de Markov sont aujourd hui de
plus en plus employes comme modeles matheraatiques de systemes divers.
On appelle processus stochastique une famille de variables aleatoires
{xt.t^T}
ou t esi un parametre parcourant 1'enserable T qui est soit Pensemble SR des reels, soit Pensemble SR+ des reels positifs, soit 1'ensemble N des entiers naturels. Le plus souvent, i represente une date et T soit une suite discrete de dates, soit un intervalle de temps. Lorsque T est discret et denombrable, les xi forment une suite stochastique. Lorsque T
est un intervalle, fmi ou non, les Xf ferment un processus continu ( ou permanent).
On appelle espace des etats 1'enserable 5' ou les variables Xf prennent leurs valeurs. S
peut etre discret ou continu [13].
Les chaines de Markov a espace d'etats discret peuvent etre etudiees selon trois points de vue differ ents :
- Ie plus classique est Paspect probabiliste. II presente 1'avantage de bien se preter directement aux chaines de Markov a espace d'etats discret infini, ce qui n'est pas toujours Ie cas pour les deux suivants;
- Ie point de vue algebrique, qui fait appel a des connaissances preliminaires sur la theorie des valeurs propres et vecteurs propres;
Ie point de vue "theorie des graphes", qui donne une vision siinpliflee du processus et permet a lui seul (dans Ie cas d'un espace d'etats fini) de donner 1'essentiel des
resultats qualitatifs sur Ie com.portem.ent du processus.
2.3.1 Graphe
La representation d'un probleme occupe une grande importance a la phase de la plamfica-tion, ou son efficacite est directernent proportionnelle a la clarte de cette representation.
Un des meilleurs moyens de representation dans ce domaine est Ie graphe.
Un graphe est Ie couple forme par un ensemble 5' et une application multivoque T de S dans lui-meme. On note ce graphe G = (<S',F). L'application F fait correspondre a tout element s de •S' un ensemble F(s) d'elements de 5', qui peut eventuelleraent coraporter 5
lui-meme, ou se reduire a un seul element, ou encore etre vide. Les elements de r(.s), s'ils existent, s'appellent les suivants de s.
On appelle arc du graphe tout couple oriente (s, t) tel que t G T'(s) , c'est-a-dire que t
soit un successeur de s. On dit inversement que s est un predecesseur de t. s s'appelle
origine de Parc et t son extremite. L'application F apparait comme une partie du
pro-duit cartesien S x S. C est pourquoi on note souvent F 1'ensemble des arcs. Ainsi, pour
traduire que Ie graphe G = (*S',F) comporte 1'arc (s, t), on ecrit (s^t) G F.
Or, s'il est naturel de representer un ensemble par des points d'un plan, 11 Rest tout autant de representer les relations binaires orientees de cet ensemble par des fleches ou
des arcs entre ces points. Le graphe se trouve ainsi represente par un reseau dont les noeuds (ou les sornmets) representent les elements de S, dans Ie sens ou Ie reseau est
noeud correspond a une situation possible et chaque arc correspond a un operateur
ap-plicable [19].
2.3.2 Theorie de la decision
La representation d'un plan reflete la structure du processus qui realise ce plan. Un plan
est une specification des actions ou des operations prevues pour transforraer quelques
etats initiaux en quelques etats de but, ces operations permettent d'atteindre un objectif represente par un etat de but a partir d'un etat initial [1].
Plusieurs types de planification sont deja construits comme la planification condition-nelle, la replanification et la planification basee sur la theorie de la decision, etc ... La theorie de la decision a pour objectif: qu'un agent choisit 1'action de la plus grande uti-lite parmi les resultats de toutes les actions; Ie concept de Putiuti-lite depend du domaine d'application. Cette theorie peut se presenter par la formule suivante [55]:
Theorie de la decision = Theorie de probabilite + Theorie d'utilite
Dans Ie cas de la planification basee sur la theorie de la decision, une distribution de probabilite des difFerents etats du systeme est disposee, alors que les buts sont represen-tes par une fonction de recompense attribuee aux etats satisfaisant un but particulier. Cette methode de planification avec incertitude est basee sur la theorie de processus Markovien [37]. Elle est utilisee dans les domaines stochastiques pour accomplir un but. Les buts sont encodes cornme des fonctions de recompense, exprimant la desirabilite de chaque etat; Ie planificateur doit trouver une strategic qui maximise les recompenses au
futur [19].
2.3.3 Processus de decision markovien
Le processus de decision markovien ou Ie processus de Markov est une approche
mathe-matique permettant d'etudier certains systemes complexes. Ses principaux concepts sont ceux d'etat de transition et probabilites [35]. Les chaines de ]V[arkov etudient 1'evolution d un systeme complexe dans Ie domaine de Paleatoire. Elles semblent pouvoir donner entiere satisfaction dans la determination d'une strategic optimale [17].
La modelisation par graphe d etats, en particulier par des chaines de Markov, a connu un
essor considerable en raison de sa grande capacite de representation du comportement
de nombreux systemes materiels. Le modele markovien est un outil relativement simple pour lequel on dispose de nombreux resultats theoriques et logiciels. II peut egalement etre utilise pour realiser des analyses de cout [45].
La chaine de Markov est un systeme evolue entre n etats £',, Ie passage d'un etat E{ a un autre etat Ej ou transition, ne depend que de ces deux etats et s'effectue selon la probabilite conditionnelle:
prob{E,/Ei)=pij.
Une chaine de Markov est caracterisee par une matrice stochastique, dite raatrice de transition:
M = [pzj] ;z,j = 1 an
transi-tion d un etat Ei vers un etat Ej est attache un revenu nj. Ce revenu est positif pour un gain et negatif pour un cout. L ensemble des revenus d une chaine de Markov, de matrice de transition M, constitue la matrice de revenus:
w = [7\?] ;?,J = 1 an
Une chaine de JVIarkov multiple avec revenus est caracterisee par plusieurs matrices
sto-chastiques, Mi, M2, ..., M^, ou chaque etat dans ce cas a au maximum k options ou choix de transitions, et des matrices de revenus qui leur correspondent, Wi, ..., Wk [17].
On appelle decision en etat Ei, Faction choisie a cet etat et strategic ou politique Pen-semble des decisions pour tous les etats du graphe.
La selection d'une strategic determine Ie processus de Markov avec revenus [17] ou avec recompenses [35, 19]. II est possible de decrire une strategie par un vecteur de decisions
dont ses elements representent les actions choisies en chaque etat.
Une strategic optimale est definie coraine celle qui maximise Ie gain ou la moyenne de
recompense par transition. Le nombre N de strategic d'un systeme de n etats est donne
par la formule suivante [35] :
n
N =H_ ki; fci nornbre d'actions en i.
»=0
II est concevable de trouver Ie gain de chacune de ces strategies dans Ie but de trou-ver la strategic optimale.
Une strategic est optimale quand les vecteurs de decision sont tous egaux a un meme
vecteur qui represente la strategic.
2.3.4 Algorithme d'iteration de politique
Une methode pour trouver la strategic optimale est la methode iterative sur des politiques
possibles decrite dans [19] :
1. Soit TT une politique quelconque sur S 2. Tant que TT 7^ TT faire
(a) 7T := 7T
(b) Pour tout s C S, calculer V^(s) en resolvant Ie systerae de | 5' equations lineaires a | S \ inconnues donne par Pequation (1)
(c) Pour tout s G 5', pour tout actions a G A tel que a ^ 7T(S)^ alors i. sum := [R(s) + -7 E Pr(.s,.s/,a)K(.s/)]
s'es
ii. Si sum > K(-s), alors A. 7T/(5) := a
B. V^(s) := sum iii. Sinon 7T'(s) := 7T(s)
3. Retourner TT
ou S est I5 ensemble des etats.
A est 1 ensemble des actions; chaque action peut etre prise en tous les etats.
Une fonction de recompense R(s) est une application de Svevs SR (ensemble des norabres
1. Cette methode converge en un temps polynomial en fonction du nombre d'etats dans Pautomate
reels), specifiant la recompense instantanee que 1'agent entraine pour etre dans un etat.
Alors, a chaque etat s la fonction de recompense R(s) associe une valeur constante de SR, cette valeur peut se calculer, pour chaque action en 5, en utilisant les matrices de probabilites et de revenus et en appliquant la formule suivante :
R(s) = ^ Pr(s,a,s')xr^.
s'ES,aeA
Mais comme ces valeurs sont des constantes de SR associees aux etats, alors il est possible et preferable de les associer directement aux etats.
Pr(5, a, 5/) est la probabilite de la transition de Petat s a 1'etat s' par Faction a.
rss' est Ie revenu de la transition de Petat s a 1'etat s .
Pour une strategic n et une fonction de recompense R donnees, la valeur V^(s) d'un etat
s € S est la somme des valeurs de recompense esperees pour etre re^u a chaque etape
dans Ie futur. V^(5) est donnee par la formule :
K(5) = ^) + 7 E Pr(5, 7T(5), 5/)KM (1)
s'es
7 est Ie facteur d'escompte qui controle Pmfluence des recompenses dans Ie futur lointain, 0<7< 1.
CHAPITRE 3
Une approche de planification basee
sur 1 abstraction
3.1 Technique de la planification
Un probleme de planification necessite de produire une sequence d'actions. Ces actions garantissent 1'atteinte d un but quand elles s'appliquent a un etat de depart specifie.
La planification basee sur la theorie de la decision implique la conception de plans ou de politiques dans des situations ou les conditions initiales et les efFets des actions sont comms avec incertitude. Dans pareilles situations, les objectifs multiples et contradic-toires doivent etre troques centre d'autres objectifs qui serviront a determiner Ie cours optimal d actions.
Le processus de decision markovien [52] vient d'etre propose comme un cadre statistique et semantique pour solutionner les problemes de la planification basee sur la theorie de
la decision [65, 4, 9, 11, 8]. Beaucoup de recherches concernant la planification basee sur la theorie de la decision mettent Pemphase sur I'amelioration des algorithmes au moyen d approximation. Une classe d'approches implique une recherche sur la restriction d'espace d'etats en des regions locales ou des enveloppes [19]. Ces approches reduisent Pespace d'etats a des regions locales accessibles et dans lesquelles elles permettent d'ap-pliquer les methodes de la recherche operationnelle, et cela, afin de generer un plan. Une de ces methodes qui se veut tres efficace est celle basee sur la theorie de processus de
decision markovien. Avec ces approches, la construction d'un plan pour realiser un but correspond a trouver la politique optimale qui maximise la performance esperee. La tech-nique de ces approches consiste a raodeler Penvironnement sous forme d un automate
stochastique initial, restreindre cet automate et a determiner la politique optimale pour Pautomate restreint en appliquant Valgorithme d'iteration de politique. Alors, cette poli-tique construite a partir de 1 automate restreint est complete et elle est consideree comme la politique optimale de Pautomate initial.
3.2 I/approche
Nous elaborons une approche basee sur 1'abstraction dans les domaines stochastiques.
Cette approche de planification vise a contribuer a la resolution du probleme de la pla-nification implique par la taille du domaine considere. Notre approche consiste a reduire la taille du domaine en Ie decomposant en de petits sous domaines.
Comme la generation d'un plan pour atteindre un but correspond a trouver la poli-tique optimale, alors plusieurs approches de la planification utilisent les algorithmes de la programmation dynamique, en particulier Valgorithme d iteration de politique^ afin de generer cette politique. Get algorithme a une grande habilite a generer Ie plan a travers
un nombre relativement petit d'iterations [7].
Notre approche est motivee par d'autres travaux deja realises: 1'approche d'enveloppe [19], 1'approche de politique abstraite [20] et Papproche de planification approximative [48]. Ces approches cherchent a appliquer 1' algorithme d'iteration de politique dans un
sous-espace reduit de Fespace d etats considere. La construction du sous-espace reduit se
realise selon quelques suppositions proposees. Ces suppositions permettent de choisir un
sous-ensemble d'etats et de rejeter les autres.
Dans Ie but de reduire la taille de Pespace en gardant tous ses etats, notre approche se sert de 1'approche de decomposition basee sur la topologie [5] dans cet espace. Gette approche transforme Ie graphe initial representant 1 espace d etats en un autre graphe
abs-trait, ou chaque partie construite est consideree comme un etat dans Ie nouveau graphe.
Ce graphe abstrait n est autre qu'une collection de graphes partiels issus du graphe initial. Ainsi, dans chaque etat du graphe abstrait, qui est en realite un graphe de petite taille, nous appliquons 1' algorithme d iteration de politique pour produire la politique optimale concernant ses etats. En fixant les actions choisies pour chaque etat dans les graphes partiels, nous arrivons a construire une politique globale pour tous les etats du graphe initial. En considerant cette politique (elaboree a partir des graphes partiels), cornm.e politique de depart, Valgorithme d'iteration de politique genere la politique optimale re-cherchee dans Ie graphe initial. Des testes empiriques suggerent que cette approche est generalement plus efficace que si on partait d'une politique quelconque.
3.3 Representation d9un probleme de planification
Par la suite, nous considerons Ie probleme de construire un plan de navigation d un robot dans Ie reseau de chambres traite dans Ie chapitre precedent (voir figure 2.1). Apres que ce reseau de chambres a ete illustre par un graphe (voir figure 2.2) et afin de generer
Ie plan recherche, nous etablissons une methode basee sur Ie processus de Markov dans
laquelle, les actions sont representees par des matrices carrees de probabilite d'ordre egale au nombre des etats du graphe deja construit. Ainsi que les buts sont codes comme des fonctions de recompense exprimant Putilite de chaque etat.
Une politique dans un graphe est un ensemble d'actions; chacune est prise en un etat.
Chaque action peut etre formee d une seule ou de plusieurs arcs ou chacun d eux amene
vers un etat du graphe. Generalement une politique choisie fixe une action en chaque etat. Done, Ie choix d une politique optiraale dans un graphe permet de fixer la meilleure action en chaque etat du graphe.
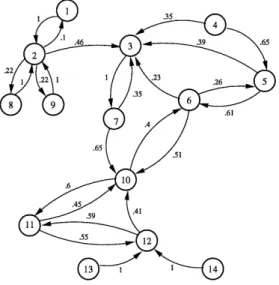
Les etats du graphe sont affectes de valeurs appelees recompenses, specifiant les re-compenses instantanees qui gui dent Pagent vers un etat. Ces sont des applications de Pensemble des etats dans I'ensemble des nombres reels (R(s) recompense de Petat s). Le choix de ces valeurs depend des etats de depart et d'arrivee de 1'agent, en estimant Ie
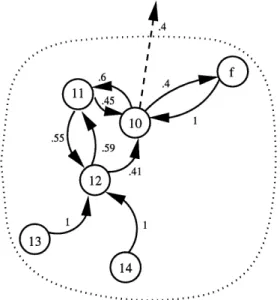
plus court chemin entre ces deux etats. Par exemple, pour se rendre de 1'etat 1 a Petat 11, ces valeurs peuvent etre choisies et representees par Ie vecteur suivant:
[2.2 453 56.58 1 29 10.1 643]
A chaque arc on associe un ensemble de valeurs de probabilites defmissant les actions.
D apres Ie procesus de Markov, la somme des probabilites associees a une action doit
etre egale a 1. Ce qui implique que la somme des probabilites attribuees aux arcs partant
d'un meme etat dans Ie graphe est egale a 1. Done, la sonime des valeurs dans chaque
ligne de la matrice de probabilites representant cette action doit etre egale a 1.
Afm de representer clairement les actions d'un processus de decision il est preferable de les montrer de deux fa9ons:
1. representation de toutes les actions considerees en un seul etat;
2. representation d'une action en tous les etats.
3.3.1 Representation des actions en un seul etat
L'etat 1 par exemple (voir figure 3.1) est connecte aux etats 2 et 3. Les arcs vers les etats
2 et 3 sent charges par quatre actions.