Problème du démarrage à froid pour les systèmes de recommandation dans les entrepôts de données
Texte intégral
Figure
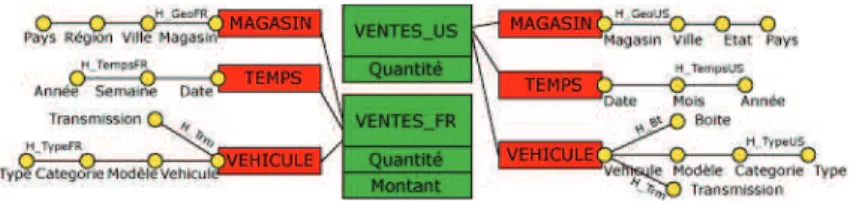

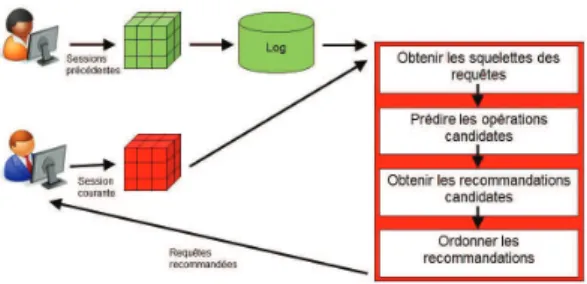
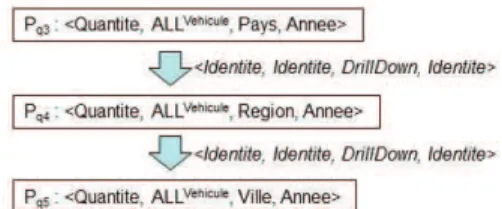
Documents relatifs
Apports d’une méthode de fouille de données pour la détection des cas incidents de cancer du sein dans les données du Programme de Médicalisation des Systèmes d’Information :
Résumé : Les producteurs de lait de l’ouest du Burkina Faso font évoluer leur système de production pour répondre à l’augmentation de la demande en lait. La
d’assemblages des PIV dans des ensembles muraux pour tirer parti de leur haut rendement thermique, tout en minimisant les risques de perforation de la membrane des panneaux sous
Résumé : Les producteurs de lait de l’ouest du Burkina Faso font évoluer leur système de production pour répondre à l’augmentation de la demande en lait. La
Le système de chiffrement homomorphique permet de traiter, au sein du Cloud, des requêtes sur les données chiffrées, sans devoir les téléchargées, les décryptées
Nous pouvons dire que les finalités de l’enseignement- apprentissage de l’oral par le biais des TICE nous permettent d’établir d’autres moyens de passerelles tels que les liens
Pour une prise en compte de la dimension cognitive du décideur dans les Systèmes d’Aide à la Décision: réflexion sur les apports d’un modèle hiérarchique de décisions
