Distribution d'objets avec les techniques de développement orientées aspects
Texte intégral
Figure
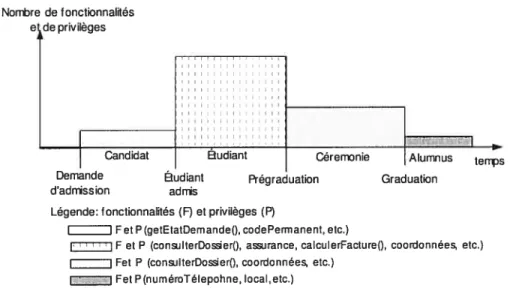
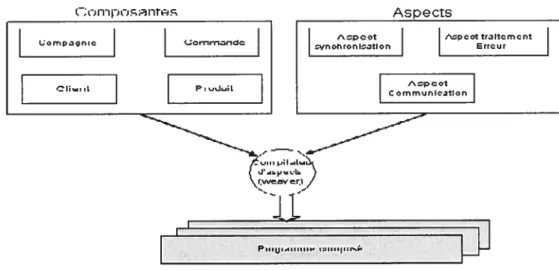
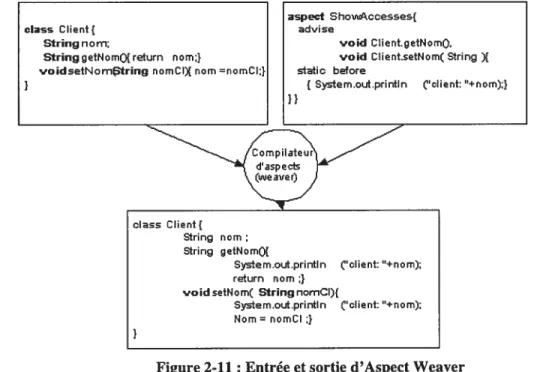
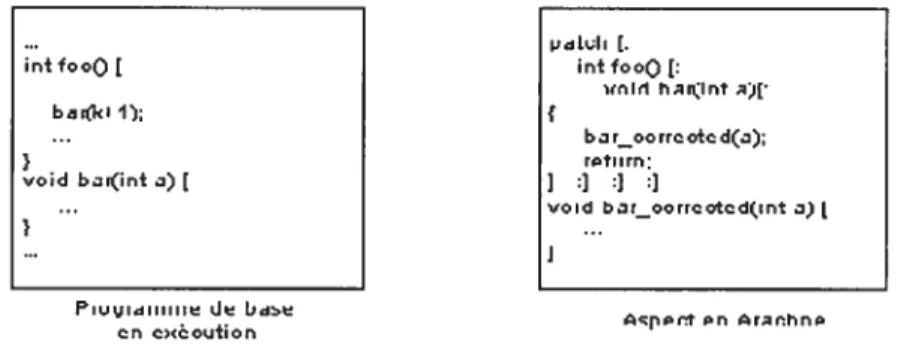
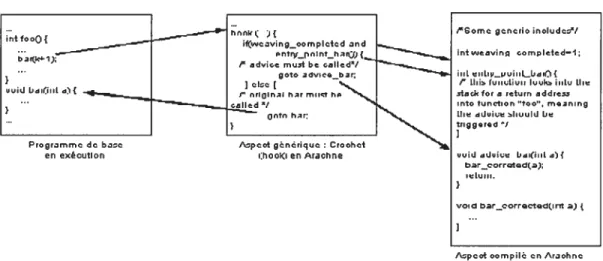
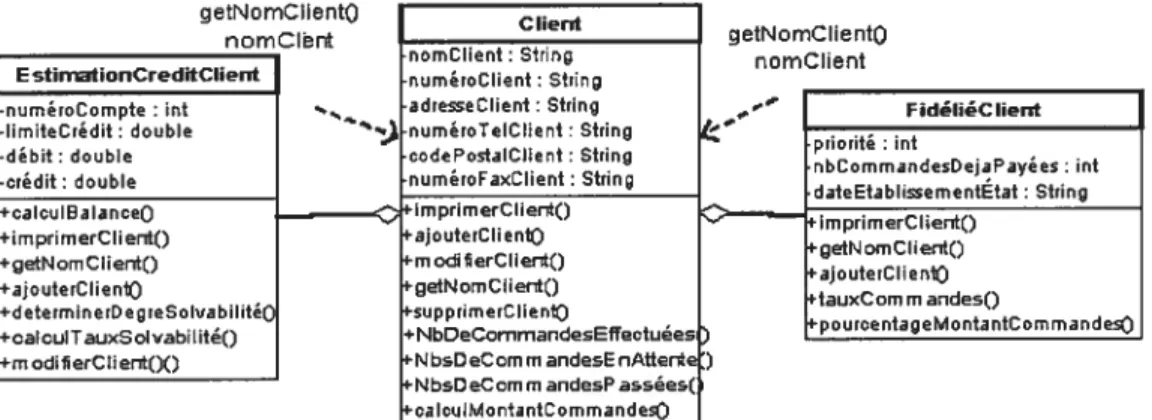
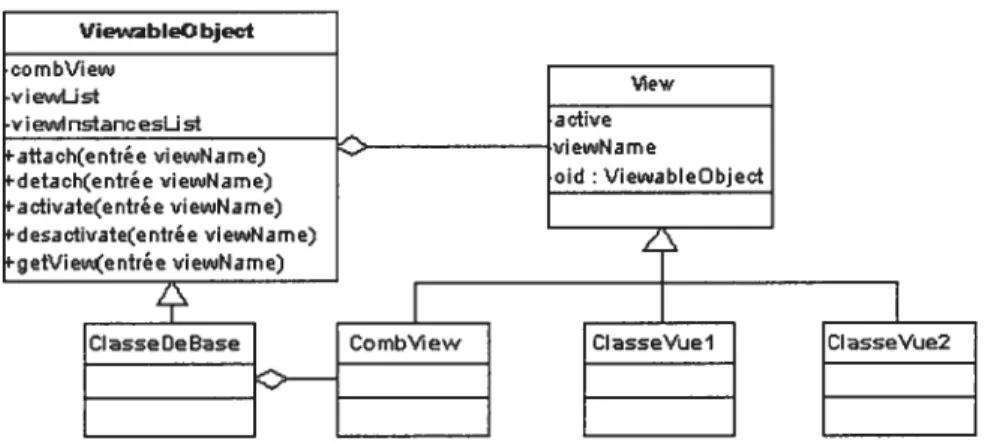
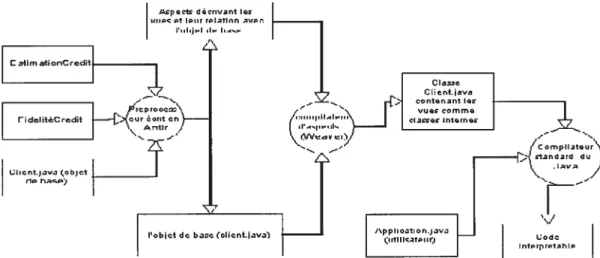
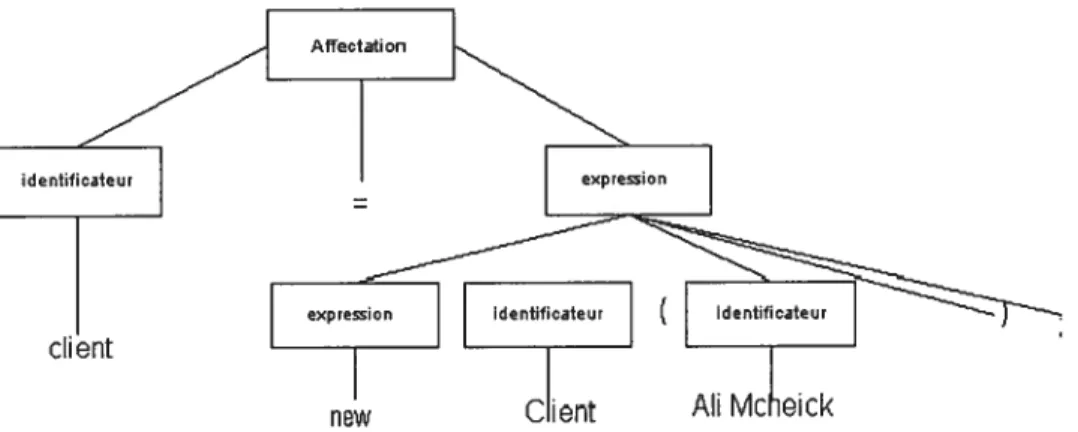
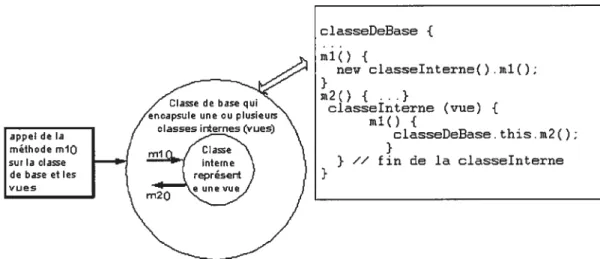
Documents relatifs
CYCLE DE VIE DES OBJETS GABAGE COLLECTOR.. Vincent Guigue &
Avec cinq graduations intermédiaires au minimum, celui-ci donne 40 configurations possibles qui incluent les deux qui viennent d’être mentionnées.. Pour L variant de 24
La révolution numérique : alors que tous les appareils à support physique photosensible (dit argentique) nécessitent de développer les photos sur papier, les photos
4°) absence de contrepartie au moins équivalente attendue du tiers après la clôture de l’exercice N ? Oui, la sortie de ressources probable est
27» L'exploitation du potentiel des ^changes intra-africains sera fonction notam-- ment de la mesure dans lac.uelle les gouvernenients, les producteurs et toutes les
Processus logiciel : Un processus logiciel est un ensemble d’activités et de résultats connexes. Lorsque ces activités sont effectuées dans un ordre spécifique,
Généralement, ce fichier est le fichier suivant : /etc/proftpd.conf Comme celui d'Apache, le fichier de configuration contient des directives globales (hors de tout
• Un objet quelconque soumis à deux forces est donc en équilibre si les forces ont la même direction et la même intensité mais sont de sens contraires.. Si l’une de
