Table des matières
Introduction générale
5
1 Les standard Vidéo
7
1.1 Compression du signal vidéo
81.2 Principe de la compression spatiale
91.3 Principe de la compression temporelle
91.3.1 Compression temporelle unidirectionnelle 9
1.3.2 Compression temporelle bidirectionnelle 11
1.4 Normes de compression vidéo
121.4.1 Normes H.26x 13
1.4.2 Normes MPEG 15
1.4.2.1 MPEG-1 16
1.4.2.2 MPEG-2 18
1.4.2.2.1 Notion de scalabilité 18
1.4.2.2.2 Les profils de MPEG-2 20 1.4.2.3 MPEG-4 21
1.4.3 H.264-AVC et SVC 23
1.5 Vers un codage vidéo basé ondelette
262 Eléments de communication numérique
28
2.1
Introduction
292.2 Les modulations numériques
302.2.1 Définitions et appellations 31
2.2.2 Modulations par déplacement de phase (MDP) 34
2.2.3 Modulation d’Amplitude en Quadrature (MAQ) 35
2.3 Le canal de transmission
36 2.3.1 Le canal gaussien 372.3.2 Le canal de Rayleigh 38
2.3.3 Performances des modulations numériques 38
2.4 Vers une utilisation des codes correcteurs
413 WTSOM Vidéo : Principe de ce codeur source 42
3.1 Introduction
443.2 Rappel sur le WTSOM
443.2.1 La transformée en ondelettes 44
3.2.2 Les cartes de Kohonen 47
3.2.3 L’algorithme WTSOM 50
3.2.3.2 Construction des dictionnaires 52
3.2.3.3 Application de l'algorithme WTSOM 53
3.2.3.4 Décodage 54 3.2.4 Choix du nombre de sous-bandes 54
3.2.5 Vers une stratégie de codage conjoint d'images fixes 55
3.3 WTSOM Vidéo
57 3.3.1 Le principe 57 3.3.2 WTSOM et GOP 58 3.3.2.1 Introduction 58 3.3.2.2 Stratégie adoptée 593.3.2.3 Retour sur la stratégie WTSOM/GOP 60
3.3.2.4 Problème des changements de plan 61
3.3.3 Vecteurs Mouvement 62
3.3.3.1 Introduction 62
3.3.3.2 Méthodes existantes 62
3.3.3.3 WTSOM Vidéo avec Vecteurs Mouvement 63
3.3.3.4 Construction des dictionnaires VM 65
3.4
Premiers
résultats
67
3.4.1 Taille des dictionnaires et évaluation du taux de compression 67
3.4.2. Comparaison avec ou sans VM 68
4 Transmission de séquences vidéo codées par WTSOM
Vidéo
70
4.1 Introduction
4.2 Choix de la base d'apprentissage
72 4.2.1 GOP avec 3 images ou GOP3 724.2.1.1 Premiers tests : utilisation d’une seule vidéo 73 4.2.1.2 Second tests : utilisation de trois vidéo différentes 74 4.2.1.3 Troisièmes tests : utilisation de six vidéo différentes 76 4.2.2 GOP avec 12 images ou GOP12 77
4.3 Stratégie de codage conjoint
784.3.1 Organisation du flux de données en sortie du codeur 79 4.3.2 Transmission via un canal bruité avec codage WTSOM Vidéo-GOP
79 4.3.3 Les résultats avec MPEG4 dans les mêmes contextes 82
4.3.4 Comparaisons de WTSOM Vidéo-GOP12 + VM et MPEG4/H264 dans les mêmes contextes . 84
4.4 Quelques aspects de la flexibilité de la méthode suivant la
qualité du canal ou la qualité visuelle attendue à la réception
87 4.4.1 Choix du nombre de sous bandes 87 4.4.2 Changement de taille des dictionnaires 874.4.2.1 Construction de dictionnaires de taille inférieure 87 4.4.2.2 Les résultats avec et sans erreurs 89
Conclusion générale et perspectives
91
Annexes
Annexe
1
94
Annexe
2
96
Bibliographie
Introduction générale
Les travaux de cette thèse s'inscrivent à la fois dans le contexte de la compression d'images et dans celui des communications numériques. On sait que le traitement d'images couvre un grand nombre d'applications liées aux communications, telles que l'imagerie médicale et la télémédecine, la vidéoconférence, le cinéma, la télévision. Le système de transmission numérique permet, quant à lui, de véhiculer l'information entre une source et un destinataire. Le support physique utilisé pour cette opération de transport n'étant pas toujours parfait, il est courant que, lors d'une transmission, l'information soit soumise à des perturbations, et qu'elle présente des erreurs en réception. En outre, d'autres erreurs peuvent être provoquées par le système de communication lui-même. C'est le cas en particulier des liaisons sans fil.
Dans un souci de performance, beaucoup de systèmes de codage d'images exploitent les défauts de la perception visuelle humaine, ce qui a pour conséquence de relativiser certains défauts à la réception (codage avec perte, notamment). Nous considérons dans ce travail cet aspect, en y intégrant, en partie, la notion de modulation et de modèle du canal lui-même, afin de proposer une stratégie de codage conjoint source-canal robuste aux erreurs de transmission. Par contre, nous n'évoquerons pas dans ce travail l'aspect codage canal, qui a pour but de fiabiliser la transmission à l'aide de codes correcteurs d'erreurs. Ces codes peuvent s'insérer dans la chaîne de transmission, quelque soit le standard utilisé, mais leur efficacité dépend de l'organisation des données binaires à la sortie du codeur source, ce qui sera une préoccupation essentielle tout au long de ce travail de thèse.
C'est pourquoi nous proposons d'utiliser la décomposition en ondelettes (DWT) dans le cadre de transmission sans fil de vidéos, ce qui diffère des standards actuels comme MPEG-4, H264, AVC, …. qui utilisent prioritairement les DCT. Cela permet plus de souplesse dans la hiérarchisation possible de l'information à coder et donc dans la protection de celle-ci. De plus, la qualité de service attendue à la réception d'un système de communication peut-être très variable suivant l'application et le type de réseaux. Pour donner plus de robustesse à notre système de codage source, nous considérons des quantifications vectorielles (QV) à partir de dictionnaires construits à l'aide de cartes auto-organisatrice (algorithme SOM), dictionnaires qui pourront se superposer aux constellations de modulations d'amplitude en quadrature (MAQ). Le codage à longueur fixe qui en découle pénalise le taux de compression, mais préserve mieux les données en cas d'erreurs sur le canal.
Le premier chapitre fait le point sur les différents codeurs vidéo existants et les transformées utilisées: DCT ou DWT, plus rarement. Nous proposons ainsi un overview des normes MPEG et H26x, en insistant sur les fonctionnalités les plus récents concernant la scalabilité du codeur (hiérarchisation de l'information) et le souci d'optimiser le codage par la compensation de mouvement.
Le second chapitre donne quelques notions de communications numériques qui seront nécessaires pour la suite de la thèse: modulations, modèles usuellement adoptés de canaux sans fil et mesures de qualité du canal de transmission.
Le troisième chapitre expose le principe du codeur que nous avons développé et intitulé WTSOM Vidéo. On commence par rappeler ce qui a servi d'origine à cette thèse, à savoir le principe de WTSOM, codeur d'images fixes basé sur une quantification vectorielle sur les sous-bandes d'ondelettes: travaux de thèse menés au laboratoire XLIM-SIC depuis 2002. Nous étendons ce travail au cas de vidéos, ce qui introduit des difficultés supplémentaires sur l'obtention et le choix des dictionnaires. Nous proposons diverses tailles de séquences (GOP) sur lesquelles nous codons les différences entre trames, et introduisons des Vecteurs Mouvement (VM), pour améliorer le taux de compression. Nous suivons en cela les normes MPEG-4/H264-AVC, mais ici sur des décompositions en ondelettes et en utilisant toujours des quantifications vectorielles. Nous concluons par quelques premiers résultats validant nos méthodes.
Le dernier chapitre montre les résultats en situation de transmission fortement bruitée (TEB > 10-3) de visioconférences, sur canaux Gaussien et de Rayleigh, avec ou sans VM. Nous
comparons les performances de WTSOM Vidéo face aux standards MPEG-4 et H264-AVC, dans un environnement de transmission comparable. Nous terminons ce chapitre par quelques réflexions concernant la flexibilité de notre codeur suivant la qualité de service attendue.
Nous terminons ce mémoire par une conclusion et des perspectives pouvant faire suite à ce travail de thèse.
Chapitre 1
Les standards vidéo
Sommaire
1.1 Compression du signal vidéo
1.2 Principe de la compression spatiale
1.3 Principe de la compression temporelle
1.3.1 Compression temporelle unidirectionnelle 1.3.2 Compression temporelle bidirectionnelle
1.4 Normes de compression vidéo
1.4.1 Normes H.26x 1.4.2 Normes MPEG 1.4.2.1 MPEG-1 1.4.2.2 MPEG-2
1.4.2.2.1 Notion de scalabilité 1.4.2.2.2 Les profils de MPEG-2 1.4.2.3 MPEG-4
1.4.3 H.264-AVC et SVC
Ce premier chapitre a pour but de présenter les grands principes de la compression vidéo et de donner une description simplifiée des principales caractéristiques des normes en vigueur, adoptées en vidéo, que sont les standards H.26x et MPEG. Une attention particulière sera apportée à l'existant en terme de scalabilité, de façon à démontrer l'intérêt d'introduire la transformée en ondelette dans une stratégie de codage de vidéo.
1.1
Compression du signal vidéo
La qualité et la quantité d’information à transmettre dans le domaine du multimédia n’ont cessé d’augmenter ces dernières années avec le développement des communications modernes. La phase de compression joue un rôle essentiel, en particulier pour la vidéo, et fait l’objet de nombreux sujets de recherche. L’approche est différente selon que l’on stocke où que l’on transmet un support vidéo.
Pour la transmission, deux contraintes essentielles sont à prendre en compte. La première est liée aux erreurs de transmission susceptibles d’endommager le média transmis et la seconde concerne l’aspect temps réel qui impose, pour une réalisation matérielle, une limitation au niveau de la complexité de la méthode utilisée.
Pour le stockage, où le risque d’erreur est infime, les contraintes sont limitées dans la mesure où les traitements associés peuvent s’effectuer en temps différé, ce qui offre la possibilité d’utiliser des techniques de compression plus complexes et plus performantes.
Dans cette thèse, nous nous intéresserons uniquement à la compression dans une optique de transmission. Les domaines d’application concernés par le codage d’image et de vidéo sont vastes. On peut citer, par exemple, la diffusion de la télévision numérique (TNT), la visioconférence ou visiophonie, la transmission d’images satellites ou encore la télémédecine. Il en résulte une très grande variété d’images et les contraintes associées sont directement liées à l’application. On ne peut donc dissocier la compression d’image ou de vidéo de l’application visée. La contrainte finale est souvent la qualité subjective de l’image reconstruite après codage et décodage. Dans le domaine de la télévision professionnelle, par exemple, on cherche à obtenir des images de qualité artistique alors que pour des applications militaires, c’est la qualité d’interprétation qui sera déterminante. Il semble donc assez difficile de classer de façon générale les performances des méthodes de compression de débit.
La compression d’un flux vidéo repose essentiellement sur l’exploitation de la redondance intra et inter images, c’est-à-dire de « l’excès » d’information de type spatial, temporel,
psychosensoriel et statistique [NIC02, ZAH04].
1.2 Principe de la compression spatiale
La compression spatiale exploite la similarité des pixels à l’intérieur d’une même image, d’où l’appellation d’intra pour désigner les images obtenues après ce type de compression. C’est le principe utilisé par la norme JPEG (Joint Photographic Experts Group) sur des images fixes. La première image d’une séquence vidéo est codée intra étant donné qu’aucune référence d’image n’est accessible auparavant. On peut même imaginer des séquences vidéo constituées exclusivement d’images intra. C’est ce que réalise l’algorithme de compression Motion JPEG (MJPEG) où chaque image est traitée indépendamment des images voisines. Les avantages de cette méthode sont le montage à l’image près et les travaux de postproduction. En revanche, comme les redondances temporelles ne sont pas traitées, le taux de compression autorisé pour une très bonne qualité d’image est faible. Ce type de compression a été adopté par les nouveaux formats DV (Digital Video) utilisés pour certains caméscopes. MJPEG utilise, comme JPEG, la transformation DCT qui s’applique non pas sur des blocs de taille 8x8 mais sur des blocs de taille 4x8 qui permet d’améliorer le taux de compression [KAM04]. Pour obtenir un taux de compression optimal, il est nécessaire d’exploiter la redondance temporelle. Ce principe fait l’objet du paragraphe suivant.
1.3 Principe de la compression temporelle
L’exploitation des similarités existantes entre des images successives a pour but de mettre à profit les redondances temporelles du signal vidéo pour le compresser. Il s’agit d’identifier les informations redondantes dans le temps, même si leur position dans le temps a changé. Ces similarités peuvent être constatées entre l’image courante et l’image précédente ou encore entre l’image courante et les deux images qui l’encadrent (précédente et suivante). Dans le premier cas on parlera d’analyse unidirectionnelle et dans le second cas d’analyse bidirectionnelle.
1.3.1 Compression temporelle unidirectionnelle
A partir de la première image intra d’une séquence vidéo donnée, on ne peut coder pour l’image suivante que les différences qui la distinguent de celle-ci. On obtient alors une image dite delta.
Pour respecter le principe de la compression temporelle, on ne transmet pour une image n que ce qui la différentie de l’image n-1. Autrement dit, on ne transmet jamais un élément d’image déjà transmis antérieurement. Les images delta ainsi obtenues subissent également
une compression spatiale au même titre que les images intra.
Pour la phase de décompression de la séquence vidéo, le décodeur va d’abord procéder à la décompression spatiale avant de compléter avec les différences de l’image précédente pour restituer l’image courante.
Pour les longues séquences vidéo on ne peut envisager d’avoir une seule image intra suivie exclusivement d’images delta. En effet, pour afficher une image quelconque on serait obliger de calculer toutes les images précédentes à partir de l’image intra jusqu’à celle qui nous intéresse. De plus, dans ces conditions, il serait impossible de commencer la lecture d’une vidéo en plein milieu d’une séquence, chose que l’on fait souvent en changeant de chaine de télévision. D’autre part, la moindre erreur intervenant durant la transmission ou le décodage d’une image se répercuterait sur l’ensemble des images suivantes, ce qui est totalement incompatible pour des applications de transmission sur canaux radio mobiles. Par ailleurs, lors d’un changement de plan, la différence entre deux images successives peut être tellement importante qu’il est préférable d’enregistrer l’image courante en intra (compression spatiale uniquement).
La solution consiste à insérer fréquemment des images de type intra (voir figure 1.1). La fréquence d’introduction de ces dernières dépendra du « dynamisme » de la séquence. Ainsi, une séquence animée devra contenir un nombre important d’images intra alors que pour une application de visioconférence c’est l’inverse puisque qu’il s’agit de personnages relativement statiques sur fond fixe… Cette technique est utilisée par les algorithmes de compression de type Cinepak ou Inde (Intel Video), première famille de codecs utilisant à la fois le traitement des redondances spatiales et celui des redondances temporelles : une image de référence intra est suivie de 4 à 12 images delta.
1.3.2 Compression temporelle bidirectionnelle
Supposons qu'un mouvement latéral de caméra fasse apparaitre sur l’image des éléments nouveaux sur lesquels les images précédentes ne nous apportent aucune information. Si l’on procède à un calcul différentiel à partir de la seule image n-1, la taille de l’image delta correspondant à l’image n risque d’être très grande car seuls quelques éléments sont communs aux 2 images. Mais si l’on compare l’image n non seulement à n mais également à n+1, il est possible d’appliquer un codage différentiel efficace à l’image n, dont une partie des éléments est commune à n-1 et l’autre à n+1 (figure 1.2).
n
n-1 n+1
Figure 1.2 Codage bidirectionnel
L’opération de codage des différences est peu efficace si le contenu de l’image est en mouvement. Les normes MPEG, décrites plus loin, mettent en œuvre des techniques de compensation du mouvement dans l’image pour optimiser la réduction des redondances temporelles. C'est notamment la notion de vecteur mouvement (figure 1.3).
Vecteur mouvement
n n+1
Figure 1.3 Vecteur mouvement entre deux images
La compression bidirectionnelle et la compensation de mouvement seront largement exploitées par l’algorithme de compression vidéo MPEG qui va être décrit dans les prochains
paragraphes.
1.4 Normes de compression vidéo
Ce paragraphe a pour but de présenter les différentes normes en termes de compression vidéo. La normalisation joue un rôle essentiel dans le succès des technologies numériques. En effet, le choix de ces technologies, en termes d’efficacité, d’interopérabilité et de pérennité, permet d’assurer un large déploiement des services et produits associés à un cout optimal pour les constructeurs et les utilisateurs.
Au niveau international, les deux organismes les plus actifs pour la normalisation des systèmes de compression vidéo sont l’UIT-T et l’ISO/IEC. Les travaux techniques de l’ISO/IEC sont menés au sein du groupe MPEG (Motion Picture Experts Group) qui a défini les standards MPEG-1, MPEG-2, MPEG-4, etc.… pour des applications aussi variées que la télévision ou le multimédia. En parallèle des activités de MPEG, un groupe vidéo de l’UIT-T s’intéresse principalement à la définition de recommandations techniques destinées aux applications de visiophonie et de visioconférence (normes H.261 et H.263).
Les deux organismes UIT-T et l'ISO ont créé le Joint Video Team (JVT) pour développer la norme H.264, ou MPEG-4 AVC (ITU-T Rec. H.264 | ISO/IEC 14496-10 AVC). Ce standard est issu précisément de l’étude commune des groupes ITU-T VCEG (Video Coding
Experts Group) et ISO MPEG. Les performances de H.264/MPEG-4 AVC permettent de
réduire de moitié le débit de transmission ou de stockage pour une qualité visuelle équivalente comparativement aux normes précédentes.
De même, Scalable Video Coding (SVC) est le nom donné à une nouvelle norme de compression vidéo développée encore conjointement par UIT-T et l'ISO. L'objectif de SVC est d'offrir un contenu échelonnable ou hiérarchique ou scalable, c'est-à-dire que le contenu peut être encodé une fois, et offrir ensuite différents débits avec différentes qualités de service (QoS). Nous retiendrons dans la suite l'expression "scalable " ou la "scalabilité".
Les schémas de compression vidéo utilisent toujours plus ou moins la même architecture générale, à savoir une première étape de décorrélation suivie d’opérations de quantification et de codage. Prédire le signal et coder l’erreur de prédiction sera indépendant du signal et donc sans coût [BAS 07]. Une méthode qui se révèle particulièrement efficace et qui a été évoqué dans le paragraphe 1.3 est la prédiction temporelle par estimation et compensation de mouvement. Tous les standards de compression vidéo reposent sur ces principes fondamentaux et sont illustrés sur la figure 1.4 et mettent en œuvre des algorithmes hybrides à prédiction-transformation [LYN 85]. Ces algorithmes associent une estimation de mouvement, un codage par transformation, une quantification et un codage entropique [BAS07]. On reviendra sur ces notions au fil du document.
Vecteurs mouvement DCT Quantification Codage entropique (CLV) Quantification inverse DCT inverse Compensation de mouvement Estimation de mouvement Image de référence + + + - Macrobloc Inter Intra Intra/ Inter Train binaire
Figure 1.4 Schéma de principe des algorithmes de compression H.26x et MPEG–X (d'après [NIC02])
1.4.1 Normes H.26x
Parmi les normes développées par l’ITU, on retrouve H.261, H.263 et H.263+ (la version 2 de H.263). Les normes H.26x utilisent les trois modes de codages suivants illustrés par la figure 1.5, l'ensemble des images (12 à 15 en général entre deux images I) constituant un GOP (Group Of Pictures).
- le mode intra (mode I) pour lequel la méthode de codage consiste essentiellement en une transformation DCT sur chaque bloc de luminance et de chrominance originales, suivi d’une phase de quantification des coefficients DCT et d’un codage entropique ; - le mode Prédictif (mode P) dans lequel les images sont prédites à partir d’une image
de référence. La prédiction se fait par compensation de mouvement entre l’image originale à coder et l’image décodée (P) ou (I) précédente. Une transformation DCT est ensuite appliquée sur chaque bloc de luminance et de chrominance de l’image d’erreur obtenue. Les coefficients obtenus sont alors quantifiés puis codés avec un codeur entropique. ;
- le mode Bidirectionnel (mode B, uniquement dans H.263 et H.263 +). Les images sont prédites alternativement en mode prédictif tel que décrit ci-dessus (image P) et en mode bidirectionnel (mode B). Une image de type (B) est prédite par compensation à partir du vecteur de mouvement calculé entre les images (P) ou (I) suivantes et précédentes. Prédiction Prédiction I B B P B B P Interpolation (prédiction bidirectionnelle) Interpolation (prédiction bidirectionnelle)
Figure 1.5 Principe des GOP
La norme H.261 vise plutôt des applications de visiophonie pour le réseau RNIS à des débits multiples de 64 kbits/s. Les formats d’images traités sont le QCIF (144x176 pixels) et
le CIF (288x352 pixels). La fréquence image de base est 29,97 Hz mais peut-être réduite (sous-multiple). Le schéma de codage est constitué de plusieurs blocs :
- l’estimation et la compensation de mouvement - le calcul des résidus
- la transformée DCT - la quantification - le codage entropique
On retrouve également un décodeur qui effectue les opérations inverses.
La norme H.263 est une norme de codage vidéo destinée aux communications vidéo à très bas débit dont la première version fut adoptée en 1995. Elle vise les applications de visiophonie et visioconférence sur RTC (Réseau Téléphonique Commuté) et RNIS (Réseau Numérique à Intégration de Services). Cette norme repose sur les principes mis en place par la recommandation H.261. Les formats d’images sont des multiples et sous-multiples du format CIF (352x288 pixels). Le codeur H.263 a la possibilité d’effectuer des compensations de mouvement avec une précision au demi-pixel, ce qui améliore grandement la qualité de la vidéo en réduisant fortement les effets dits « moustiques ». L’utilisation d’images de type bidirectionnelle est désormais possible.
En 1998 fut développée la norme H.263+ (H.263 version 2) qui met en œuvre douze options supplémentaires et permet de définir des formats et fréquences d’image personnalisés. Les caractéristiques de vidéo (taille, fréquence) sont transmises dans le flux vidéo. Les options ajoutées améliorent fortement la qualité et la robustesse aux erreurs.
Enfin en 2000, la dernière version de H.263, appelée H.263 ++, ajoute trois options et une spécification à la version antérieure. Outre l’amélioration en termes de qualité et taux de compression, elle prend mieux en compte la transmission vidéo temps réel sur des réseaux à qualité de service non garantie (IP et mobiles).
1.4.2 Normes MPEG
Parmi les normes développées par l’ISO/IEC, on retrouve MPEG-1, MPEG-2 et MPEG-4. MPEG appartient à la classe générale des algorithmes de compression hybrides de type prédiction-transformation. Le terme « hybride » signifie que plusieurs techniques sont employées conjointement pour augmenter la performance globale du système : une boucle de prédiction est appliquée pour la compression temporelle ; une transformation DCT suivie d’une quantification des coefficients transformés assurent la compression spatiale ; un codage entropique, enfin, optimise le code finale. La compression MPEG est de type asymétrique : le codage s’avère beaucoup plus complexe (quatre fois plus long) que le décodage.
MPEG-1 vise une qualité équivalente au VHS (format SIF ou CIF) à un débit de 1,5 Mbps. Cette norme a été construite sur la base de H.261. Elle n’est plus guère utilisée aujourd’hui si ce n’est en compression du son avec le format MP3 pour le stockage de la musique.
MPEG-2 a été définie pour les applications liées à la télévision numérique, à la fois au niveau professionnel (production audiovisuelle, etc.) et au niveau du grand public (diffusion vers les postes TV). Ce standard a également été adopté par le consortium DVB (Digital Video Broadcasting) pour les services de TV numérique par voie hertzienne terrestre (DVB-T) et satellite (DVB-S). Il est également utilisé comme format de codage du DVD (Digital Video Disc).
MPEG-4 est une norme générique de compression destinée à la manipulation d’objets multimédia. Cette norme adresse une large gamme d’applications audiovisuelles en passant par le streaming sur internet ou encore la réalité virtuelle distribuée. Concernant le codage de la vidéo traditionnelle, MPEG-4 combine les outils de MPEG-2 et H.263 ainsi que de nouveaux outils lui conférant une plus grande efficacité en compression tels que des modes de scalabilité plus adaptés à une transmission sur réseaux à débit fluctuant ainsi qu’une plus grande robustesse aux erreurs de transmission.
1.4.2.1 MPEG-1
L’application visée par la norme MPEG-1 est l’enregistrement. Il s’agit de permettre la restitution, à partir d’un CD, de 72 minutes de vidéo numérique plein écran (image et son) au rythme de 25 ou 30 images par seconde. Les premiers systèmes de télévision numérique aux Etats-Unis ont même fait appel à cette norme dans l’attente de la norme MPEG-2. La qualité proposée par MPEG-1 n’est pas comparable à celle de la diffusion broadcast mais reste subjectivement comparable à la qualité obtenue à partir d’un magnétoscope VHS. Pour parvenir à un tel résultat un certain nombre de méthodes de compression ont été mis en œuvre.
Tout d’abord, la réduction du format de la vidéo : format SIF (Source Input Format) 352x288 pixels en luminance et 176x144 en chrominance au lieu de 720x576 pixels en luminance et 360x576 en chrominance. En plus de compresser les redondances spatiales, comme dans MJPEG, MPEG permet de compresser les redondances temporelles. On retrouve, comme pour H.261, trois types d’images qui forment le GOP:
- les images intra I ; - les images prédites P ;
- les images bidirectionnelles B ;
I sont compressées selon l’algorithme JPEG qui ne prend évidemment en compte que les redondances spatiales. Ces images I serviront de référence pour le calcul des images P et B ainsi que pour le décodage. Les images prédites P sont construites à partir de l’image I ou P précédente à l’aide de vecteurs de mouvement et calcul des différences. Pour minimiser le flux de données nécessaires à la transmission des vecteurs de mouvement, ceux-ci sont calculés sur des blocs de pixels. Une image se compose de blocs, macroblocs et lignes de blocs. Une ligne de blocs est constituée de 16 lignes de 352 points pour la luminance et de 8 lignes de 176 points pour chaque chrominance.
Le codage se déroule alors de la façon suivante :
- une compensation de mouvement est appliquée aux macroblocs : les vecteurs de mouvement sont calculés selon le déplacement de chaque bloc de pixels d’une image à l’autre puis codés ;
- chaque bloc qui diffère de la prédiction est ensuite transformé par calcul des différences puis quantifié
- enfin, un codage entropique est appliqué aux valeurs obtenues après quantification La norme MPEG ne spécifie pas comment faire la recherche, ni jusqu’où la faire, ni même le seuil de ressemblance à atteindre, ces paramètres devant être fixés lors de chaque implémentation de l’algorithme. La complexité de l’algorithme MPEG est largement compensée par les résultats obtenus. A titre d’exemple, le tableau 1.1 donne le taux de compression obtenu pour chaque type d’image.
On rappelle que la compression MPEG est un codec asymétrique, donc que le temps de compression est plus long que celui de décompression.
Type d’images Taille (en Ko) Compression
Intra (I) 18 7 :1
Prédites (P) 6 20 :1
Bidirectionnelle (B) 2,5 50 :1
Moyenne 4,8 27 :1
Tableau 1.1 Taux de compression sur les différentes images du GOP
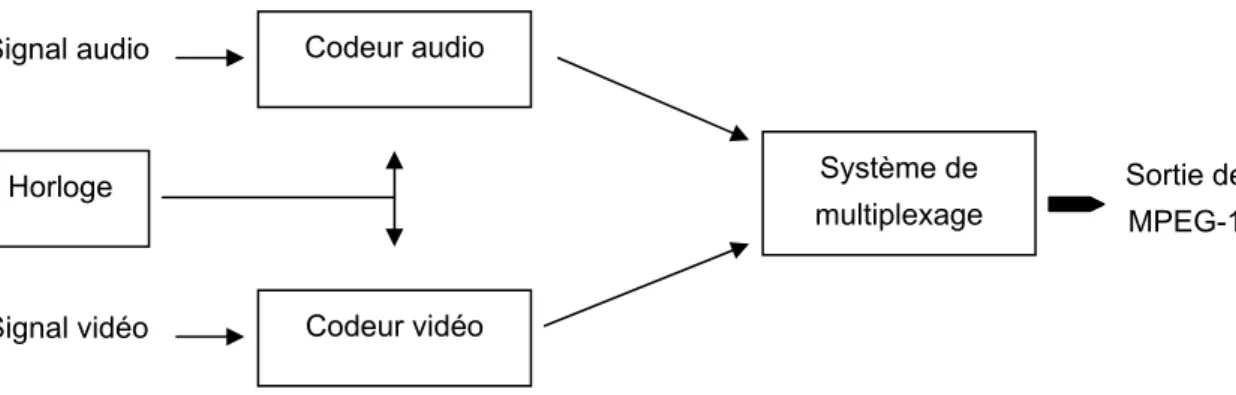
Quant à la compression du son dans MPEG-1, l’algorithme est fondé sur le standard MUSICAM (Masking-pattern Universal Sub-band Integrated Coding And Multiplexing). Le lecteur désireux d’approfondir ce sujet pourra consulter les références [DET90] [TUD95]. La compression du son et de l’image se faisant de manière totalement indépendante, il important de synchroniser ces deux flux. Pour ce faire, MPEG-1 est constitué de trois parties : vidéo, audio et système, cette dernière partie assurant l’intégration des deux premières. Cette synchronisation est schématisée sur la figure 1.6.
Codeur vidéo Codeur audio Horloge Signal audio Signal vidéo Système de multiplexage Sortie de MPEG-1
Figure 1.6 Multiplexage audio-vidéo de MPEG-1
1.4.2.2 MPEG-2
La norme MPEG-2 est définie pour des applications de stockage et de transmission vidéo. Cette norme est une extension de MPEG-1 et permet d’obtenir une qualité supérieure d’image et de son. L’application phare qui a guidé la norme est la télévision numérique (transmission satellite, câble, terrestre, studio…) et les nouvelles fonctionnalités nécessaires à l’élaboration de cette norme y ont été incorporées. Les procédures de compression spatiales et temporelles mises en œuvre par MPEG-2 sont directement reprises de MPEG-1. L’essentiel des ajouts réside dans la prise en compte du caractère entrelacé des signaux d’entrée, la définition propre à MPEG-2 de plusieurs niveaux de qualité et de profils de codage spécifiques.
De plus, pour autoriser un mode de codage compatible entre différents niveaux de qualité MPEG-2 propose des outils spécifiques. On parlera de scalabilité dans la suite de ce document.
Les débits utilisés dépendent directement de l’application visée, du format d’entrée ou encore de la qualité de service requise. A titre d’exemple, un format de télévision standard en mode broadcast demande un débit de 2 Mbits/s pour avoir une qualité comparable au VHS, de 4 à 5 Mbits/s pour une qualité PAL/SECAM et de 8 à 10 Mbits/s pour une excellente qualité.
1.4.2.2.1 Notion de scalabilité
Pour répondre à des besoins spécifiques des systèmes de transmission vidéo, la norme MPEG-2 définit des outils permettant un codage avec différents niveaux de résolution ou de qualité.
- Scalabilité SNR (Signal to Noise Ratio)
véhiculés par la couche de base. La couche de base contient les coefficients de basse fréquence et les couches d’amélioration contiennent les coefficients haute-fréquence. Ces différentes informations sont portées par plusieurs flux en parallèle.
- Scalabilité spatiale
La scalabilité spatiale offre la possibilité à un même flux vidéo d’être compatible à un format TV mais aussi à un format HDTV. Ceci permet une migration progressive du parc de récepteurs. Plutôt que de coder séparément 2 sources (une pour la TV et une autre pour la HDTV) où une redondance évidente entre les deux signaux existe, un mode de codage spécifique permettra de coder les deux signaux avec des résolutions différentes et donc d’exploiter ces redondances. A titre d’exemple, le flux de base contiendrait une version réduite de l’image (176x144) et les flux d’amélioration contiendraient les données supplémentaires pour décoder l’image avec une résolution plus grande (352x288).
Le signal de basse résolution est d’abord codé de façon standard. Le signal correspondant décodé est ensuite sur-échantillonné au format de haute définition. La source de haute définition est codée de façon pratiquement standard, la seule différence résidant dans une modification du processus de compensation de mouvement. Le signal basse définition ré-éhantillonné, peut, en effet, être utilisé comme prédiction du macrobloc courant, le choix entre ces deux modes se faisant de la même façon qu’entre les différents modes de compensations classiques. Le décodeur de haute résolution effectue donc aussi le décodage du signal basse définition pour le décodage de haute définition.
Au vu de la complexité de mise en œuvre de cette technique, le gain en compression obtenu reste assez faible comparé à un système de transmission séparé des deux signaux. Ceci explique le peu d’intérêt rencontré par cet outil chez les utilisateurs.
- Scalabilité temporelle
De la même façon qu’en mode de scalabilité spatiale, la norme MPEG-2 a défini un mode de codage compatible entre deux signaux de même résolution spatiale, mais avec une résolution temporelle différente. Le signal à une fréquence d’image la plus basse est aussi utilisée, après décodage, dans la boucle de compensation du signal à la fréquence image la plus haute.
- Compression data partitionning
Ce mode de compression répond aux mêmes besoins que le mode de scalabilité SNR. Deux flux additionnels permettant de restituer l’image de qualité supérieure sont moins bien protégés dans la transmission. Dans le système de data partitionning, le codage reste identique au mode standard ; les données sont simplement séparées en deux niveaux à la sortie du VLC au niveau des blocs DCT. Les premiers mots VLC d’un bloc correspondant
aux coefficients DCT basses fréquences sont envoyés dans le canal haute protection, les mots restant étant transmis dans le canal additionnel. Ce mode de codage compatible est moins performant d’un point de vue de dégradation progressive du signal que le mode SNR. En effet, la suppression pure et simple de coefficients DCT entraine des défauts de codage plus visibles qu’une sur-quantification. En revanche, le data partitionning a le mérite d’être beaucoup plus simple à mettre en œuvre.
- Les niveaux de MPEG-2
Quatre niveaux définissent la résolution de l’image sous MPEG-2 selon le tableau 1.2 :
Niveaux de MPEG-2 Format de codage
Low level H 352 V 288 Main level H 720 V 576 High-1440 level H 1440 V 1152 High level H 1920 V 1152 H : Horizontal V : Vertical
Tableau 1.2 Les quatre résolutions disponibles dans MPEG-2
1.4.2.2.2 Les profils de MPEG-2
La norme MPEG-2, par l’étendue des applications visées en télévision, nécessite la mise en œuvre de nombreuses techniques de compression, en particulier pour les aspects de codage compatible. De façon à autoriser des implémentations de la norme spécifiques et donc une meilleure focalisation sur les applications visées, le comité MPEG a défini les profils de codage suivants donné en tableau 1.3.
Les combinaisons de profils et niveaux étant définis, l’utilisateur de la norme choisit de se conformer à un couple profil/niveau qui correspond aux besoins de son application. Cependant, pour certaines applications, ces combinaisons ne satisfont pas. Dans le domaine professionnel par exemple, de nombreuses applications nécessitent une compression de très bonne qualité mais ne peuvent se dispenser du système hiérarchique prévu par le High profile
en diffusion.
Un profil professionnel a été créé : MPEG-2 Profil Professionnel. Dans ces applications « professionnelles » les performances nécessaires sont [TUD95]:
- haute qualité d’image
- possibilité de compression et décompression successives avec préservation de la qualité après de multiples générations
- possibilité d’accès à chaque image individuelle
- conservation d’une bonne qualité même après des traitements ultérieurs comme les effets spéciaux, les incrustations (chroma keys), etc.
- intégration dans de nombreux équipements de codeurs et de décodeurs dont les dimensions et les couts doivent être faibles.
Mode de codage Descriptif
Simple profile Ce profil met en œuvre un minimum de modes de codage (images Intra et Prédites) de façon à autoriser des implantations bas cout de codeurs et décodeurs MPEG-2
Main profile Schéma de codage hérité de MPEG-1 avec images Intra, Prédites et Bidirectionnelles (I, P, B)
SNR scalable profile Il s’agit de permettre une réception sur deux niveaux grâce à l’organisation de deux trains distincts de données. C’est un profil équivalent au Main profile avec la fonctionnalité de scalabilité SNR
Spatially scalable profile Profil semblable au précédent mais disposant d’un train de données supplémentaires permettant d’obtenir une image de haute définition (scalabilité spatiale)
High profile Ce profil haut de gamme dispose de tous les outils des profils précédents
Tableau 1.3 Profils de codage MPEG-2 1.4.2.3 MPEG-4
La norme MPEG-4 se veut plus ambitieuse que les précédentes versions de MPEG. En effet, les objectifs visés vont au-delà d’une simple application de compression vidéo [KOE96] et englobent :
- la prise en compte d’une grande variété de sources audio et vidéo naturelles et synthétiques (modèle 3D synthétiques, séquences vidéo naturelles, parole synthétisée, morceau de musique compressé …) ;
- la prise en compte de la transmission des informations multimédias sur des supports de plus en plus hétérogènes de par la gamme de débit offerte. On peut citer par exemple les réseaux mobiles proposant quelques dizaines de kilobits par seconde en opposition aux réseaux câblés où l’on peut désormais atteindre plusieurs mégabits par seconde ; - l’interaction entre l’utilisateur et le contenu basé objet des images.
MPEG-4 est une approche nouvelle du codage et de la compression de l’image animée et du son, fondée sur une analyse du contenu en objets médias hiérarchiquement structurés et susceptibles de traitements spécifiques.
Cette approche orientée objet permet de décomposer une scène en différents objets. Ces derniers peuvent par exemple être une personne, un arbre ou encore une séquence musicale, un bruit, etc. On distingue les objets dits « naturels » des objets dits « synthétique ». A leur tour, ces objets peuvent être décomposés puis structurés et hiérarchisés dans une arborescence.
MPEG-1 et MPEG-2 visaient exclusivement une exploitation maximale des redondances spatiales (intra) et temporelles (inter) grâce à un découpage de l’image en blocs de pixels. MPEG-4 reprend l’ensemble des compétences de ses prédécesseurs, y compris le codage prédictif et la compensation de mouvement, mais en les appliquant aux objets préalablement identifiés et non plus à des blocs de pixels. Le gain de cette approche orientée objet est d’obtenir une grande efficacité de compression tout en préservant une bonne qualité visuelle finale.
MPEG-4 permet également d’optimiser la diffusion du flux de données en fonction des débits et/ou du système d’affichage dont dispose l’utilisateur final. On parle de scalabilité comme il en était question pour MPEG-2. On retrouve la scalabilité temporelle, spatiale ou encore "SNR" qui est celle relative au niveau de perte liée à la compression.
L’interactivité est une fonctionnalité essentielle à la diffusion et l’utilisation d’applications multimédias. Elle permet à l’auteur d’un document MPEG-4 d’envisager pour l’utilisateur final des possibilités d’interaction avec certains des objets qui composent une scène vidéo, comme par exemple changer la couleur d’un objet présenté sur un site de commerce électronique ou encore afficher un sous-titrage.
Tout comme pour MPEG-2, MPEG-4 a défini des profils dont le but est de réduire le flux des données transitant par les réseaux. Cela permet de cibler parfaitement tel ou tel type d’application. MPEG-4 propose cinq types de profils résumés dans le tableau 1.4.
La norme MPEG-4 est une véritable évolution dans la mesure où pour la première fois une solution technique prend en compte des sa conception l’intégration de l’ensemble des médias numériques et les interactions de l’utilisateur avec ces contenus. MPEG-4 est capable de proposer des solutions pour des applications aussi innovantes que la visioconférence, la production vidéo professionnelle ou encore le streaming sur l’Internet. La grande efficacité de ses outils de compression ainsi que sa robustesse à l’égard des erreurs de transmission lui assurent une excellente adaptation à la diffusion d’applications multimédias.
Mode de codage Descriptif
Profils visuels 5 niveaux d’exigence pour le codage des données naturelles et 4 pour le codage des données synthétiques ou mixtes
Profils audio 4 niveaux définis par le nombre d’outils intégrés et le débit requis
Profils graphiques 3 niveaux de traitement des éléments graphiques et textuels
Profils de description de scènes 4 niveaux déterminent les types d’information susceptibles d’être intégrés dans la description d’une scène
Profil de description d’objets Un seul niveau et proposant les outils suivants : descripteur d’objet, synchronisation, information sur les objets, propriété intellectuelle et protection
Tableau 1.4 Les différents profils de MPEG-4
1.4.3 H.264-AVC et SVC
On a déjà dit que les deux groupes MPEG de l’ISO et VCEG (Video Coding Experts Group) de l’UIT-T avait approuvé le rapprochement de leurs équipes vidéo pour la définition commune d’un nouveau standard de compression appelé H.264 Advanced Video Coding (AVC). Cette décision a conduit les groupes à fusionner sous le nom de JVT (Joint Video
Team) le 6 décembre 2001. Le but de cette nouvelle entité est de standardiser un codec vidéo
La norme H.264 n’apporte pas de rupture technologique par rapport aux normes de codage vidéo actuelles. Les différences se situent à plus petite échelle sur chaque partie du principe général de codage (prédiction, transformée, quantification, etc.).
Selon le rapport des essais de vérification de H.264-AVC, l’efficacité du codage est nettement supérieure à celle de MPEG-2. Les principaux avantages sont les suivants :
- Les types d’images
On retrouve les mêmes types d’images (I, P ou B) que dans les normes précédentes. H.264 apporte un nouveau type d’image, les « SP frame », qui servent à coder la transition entre deux flux vidéo. Elles permettent, sans envoyer d’images intra couteuses en terme de débit, de passer d’une vidéo à une autre. Ces images peuvent être utilisées dans des contextes variés comme la transmission sur réseaux à QoS non garantie.
- Les macroblocs « intra »
Les coefficients des macroblocs intra sont prédits en privilégiant certaines directions spatiales. Huit directions de prédiction ainsi que deux méthodes de codage existent aujourd’hui. Ces améliorations permettent d’obtenir des taux de compression comparables à JPEG 2000 pour la compression d’images fixes.
- La compensation de mouvement
H.264 utilise des blocs de dimensions et de forme variables alors que MPEG-2 utilise des blocs fixes de taille 16x16. La précision peut atteindre le ¼ de pixel. Cette diversité dans le choix des types de blocs pour la compensation de mouvement permet de s’adapter plus finement au contenu spatial et en mouvement des images.
De plus, l’image à coder peut être prédite à partir de plusieurs images de référence. E principe est une mutualisation de MPEG-4 et de H.263+.
- La transformée fréquentielle
H.264 utilise une transformée entière qui a les mêmes propriétés que la DCT mais réduit l’impact des erreurs d’arrondi.
- La quantification
Les pas de quantification définis dans la norme s’incrémentent d’une valeur de 12.5% et leur dynamique est augmentée puisque les valeurs vont de 1 à 52. Dans les normes vidéo précédentes, le pas de quantification augmente par pas fixes, ce qui entraine des zones inaccessibles pour certains quantifieurs. De plus, afin d’obtenir de meilleurs résultats visuels, la quantification de la chrominance est plus fine que celle de la luminance.
H.264 utilise un filtre de boucle adaptatif qui permet d’améliorer l’efficacité en compression et la qualité visuelle des séquences vidéo en atténuant certains effets liés au codage tel que l’effet bloc.
- Le parcours des données
En plus du parcours des coefficients transformés (zigzag) pour concentrer l’information utilisée, H.264 offre la possibilité d’un parcours du macrobloc considéré en sens inverse pour fonctionner avec un codage entropique adaptatif.
- Le codage entropique
Le codage entropique peut être réalisé de trois manières différentes dans H.264. Une première méthode utilise une table universelle de mot de code (UVLC – Unified Variable
Lenght Coding). Cette table est utilisée pour coder la plupart des éléments de synchronisation
comme les en-têtes. Les deux autres méthodes sont utilisées pour coder presque tous les autres éléments syntaxiques (coefficients, vecteurs mouvements). Il s’agit d’une part d’un codage VLC adaptatif au contexte (CAVLC – Context Adaptative Variable Length Coding) et d’autre part d’un codage arithmétique adaptatif contextuel [RIS76] (CABAC – Context
Adaptative Binary Arithmetic Coding) basé sur le MDL (Minimum Description Length)
[RIS89].
- L’adaptation réseau
La couche d’abstraction réseau NAL (Network Abstraction Layer) est conçue pour faciliter l’adaptation des données de la couche de codage vidéo H.264 à une large variété de systèmes tels que :
- Les protocoles RTP/IP pour tout type de service temps réel Internet (communication et streaming) sur réseau filaire ou non.
- Les formats de fichiers pour le stockage et le service de messagerie multimédia (MMS) - H.32x pour les services de communication sur réseau filaire ou non
- Les trains de données MPEG-2 TS pour les services de diffusion en télévision
Les principaux éléments de la couche NAL sont les unités NAL (NAL units), le transport sous forme de paquets, l’ensemble des paramètres et les unités d’accès (Access Units).
L'extension SVC pour Scalable Video Coding est le nom donné à la nouvelle norme de compression vidéo développée encore conjointement par UIT-T et l'ISO. Elle offre pour fonctionnalités différents débits suivant la qualité visuelle souhaitée: c'est la scalabilité.
Les années récentes ont connu une croissance impressionnante, en terme d'efficacité, des algorithmes de codage vidéos. La norme MPEG-4, partie 10, ou le H.264, sont à ce jour, capables d'une économie de plus de 60% en débit binaire, par rapport à la norme MPEG-2, et pour la même qualité visuelle. Ceci pourrait mener à penser que la majeure partie du travail a été accomplie pour la compression du codage vidéo. Quelques problèmes, cependant, sont toujours loin d'être complètement résolus, et, parmi eux, le plus d'actualité est probablement la hiérarchisation ou scalabilité de l'information à la reconstruction. Comme nous l'avons vu, une représentation scalable doit permettre à l'utilisateur d'extraire instantanément d'une partie du full-rate, soit une version dégradée des données originales, c’est-à-dire avec une résolution réduite ou une déformation accrue, soit une version optimale visuellement de la source.
Avec une représentation scalable d'une vidéo, les différents utilisateurs peuvent recevoir différentes parties des données codées suivant la qualité souhaitée, et sans utiliser de "transcodage". On a vu que les normes récentes offrent un certain degré de graduabilité, mais qui n'est pas encore considéré comme complètement satisfaisant. En effet, la qualité visuelle obtenue à partir de flux binaires intrinsèquement scalables est habituellement moins satisfaisante que celle obtenue à partir de flux codés et disponibles séparément, sans scalabilité, et cela pour un même débit binaire.
La différence de la qualité entre les versions scalable et non-scalable des mêmes données reconstruites constitue un composant de ce que nous appelons le "coût de scalabilité". Un autre composant du coût de scalabilité est l'augmentation de la complexité de l'algorithme de codage scalable vis-à-vis de sa version non-scalable. Un codeur vidéo scalable pourrait profiter grandement d'un algorithme de codage de type JPEG2000, et donc basé sur les transformées en ondelettes. D'ailleurs, on sait que cette norme d'images fixes offre beaucoup de fonctionnalités network-oriented, qui coûteraient peu, en terme de complexité, à un codeur de vidéo compatible avec JPEG2000. La transformé en ondelette (WT), employée depuis plusieurs années dans le codage d'images fixes, a des qualités de scalabilité supérieures à la DCT qui sont dues à son approche multi-résolution.
Relativement à ce qui a été présenté précédemment, on voit bien qu'un des problèmes principaux, une fois les transformées en ondelettes choisies ainsi que le codage prédictif par GOP établi, est comment exécuter la compensation de mouvement dans le cadre des sous-bandes WT?
En fait, les codeurs vidéos basés ondelettes commencent à être proposés: la méthode MCWT (Motion-Compensated Wavelet Transform) [CAG04] permet, par exemple, de coder la vidéo à partir des transformées WT, et à avoir des performances proches des derniers codeurs vidéo de la génération basé DCT. Il existe aussi d’autres méthodes intégrant la compensation de mouvement et utilisant les ondelettes comme dans [SEC02].
Dans le chapitre 3, nous allons ainsi proposer une méthode intitulée "WTSOM vidéo" qui permet de coder la vidéo à partir des ondelettes, et nous montrerons, par son adéquation avec une modulation MAQ-256 ou MAQ-16, ses bonnes performances vis-à-vis d'erreurs de transmission trop nombreuses.
1.6 Conclusion
Nous avons dans ce chapitre décrit les principales fonctionnalités des normes H.26x et MPEG. Ces normes sont basées sur la transformée en DCT, ce qui limite les performances en terme de hiérarchisation de l'information (scalabilité) suivant la qualité de service, bien que les derniers développements de ces standards offrent des possibilités de résolution variables de plus en plus attrayantes et des gains indéniables en terme de débit-distorsion.
Cela nous a amené à finir ce chapitre sur l'idée de codeurs basés ondelette, dont le noyau même (la décomposition en sous-bandes d'ondelettes) s'adapte particulièrement bien à une protection et à une reconstruction variable de la source.
Chapitre 2
Eléments de communication
numérique
Sommaire
2.1 Introduction
2. 2 Les modulations numériques
2.2.1 Définitions et appellations
2.2.2 Modulations par déplacement de phase (MDP)
2.2.3 Modulation d’Amplitude en Quadrature (MAQ)
2.3 Le canal de transmission
2.3.1 Le canal gaussien
2.3.2 Le canal de Rayleigh
2.3.3 Performances des modulations numériques
2.4 Vers l'utilisation des codes correcteurs
2.1 Introduction
Dans ce chapitre nous allons aborder l'aspect communication numérique. Les systèmes de transmission véhiculent de l'information entre une source et un destinataire en utilisant un support physique comme le câble, la fibre optique ou encore, la propagation sur canal radioélectrique. Dans le cas des transmissions numériques, les signaux transportés peuvent être soit directement d'origines numériques, comme dans les réseaux de données, soit d'origines analogiques (parole, image…) mais convertis en une forme numérique. La tache du système de transmission est d'acheminer l'information de la source vers le destinataire avec la plus grande fiabilité.
Le schéma synoptique des fonctions de base d'un système de transmission numérique est donné par la figure 2.1 :
Figure 2.1 Synoptique d'une chaîne de transmission numérique.
La source émet un signal numérique sous la forme d'une suite d'éléments binaires. Si l'intervalle de temps séparant l'émission de deux bits consécutifs est égal à Tb, alors la source se caractérise par son débit binaire Db:
1 bits/s
b
b T
D = (2.1)
- Le codeur peut éventuellement supprimer des éléments binaires non significatifs (compression de données ou codage de source), et/ou introduire de la redondance dans
l'information en vue de la protéger contre le bruit et les perturbations présentes sur le canal de transmission (codage de canal). Le codage de canal n'est possible que si le débit de source, après compression, est inférieur à la capacité du canal de transmission. Nous n'aborderons pas l'aspect codage canal dans cette thèse, en ce qui concerne spécifiquement les codes correcteurs.
- La modulation a pour rôle d'adapter le spectre du signal au canal (milieu physique) sur lequel il sera émis.
- Enfin, du coté récepteur, les fonctions de démodulation et de décodage sont les inverses respectifs des fonctions de modulation et de codage situées du coté émetteur.
Les deux paramètres principaux permettant de comparer entre elles les différentes techniques de transmission sont les suivantes :
- La probabilité d'erreur Peb par bit transmis, permet d'évaluer la qualité d'un système de transmission. Elle est fonction de la technique de transmission utilisée, mais aussi du canal sur lequel le signal est transmis.
- L'occupation spectrale du signal émis doit être connue pour utiliser efficacement la bande passante du canal de transmission. L'augmentation systématique des débits demandés contraint la plupart du temps les concepteurs à utiliser des modulations à haute efficacité spectrale.
2.2 Les modulations numériques
La modulation a pour objectif d'adapter le signal à émettre au canal de transmission. Cette opération consiste à modifier un ou plusieurs paramètres d'une onde porteuse centrée sur la bande de fréquence du canal : S(t)= Acos(ω0t+ϕ0)
Les paramètres modifiables sont : - L'amplitude : A
- La fréquence : f0 =ω0 /2π - La phase : ϕ0
Les types de modulations les plus fréquemment rencontrées sont les suivants :
- Modulation par Déplacement d'Amplitude : MDA ou ASK (Amplitude Shift Keying)
- Modulation par Déplacement de Phase : MDP ou PSK (Phase Shift Keying)
- Modulation d'Amplitude en Quadrature : MAQ ou QAM
- Modulation par Déplacement de Fréquence : MDF ou FSK (Frequency Shift Keying)
- Modulation multi-porteuses : OFDM (Orthogonal Frequency Division Multiplex)
2.2.1 Définitions et appellations
Dans les procédés de modulation binaire, l'information est transmise à l'aide d'un paramètre qui ne prend que deux valeurs possibles. En groupant sous forme d'un bloc, n éléments binaires, on obtient un alphabet de M = 2n symboles M-aires. En modulation M-aires, l'information est transmise à l'aide d'un paramètre qui prend M valeurs. Ceci permet d'associer à un état de modulation un mot de n éléments binaires.
La rapidité de modulation R s'exprime en bauds et se définit comme étant le nombre de symbole émis par seconde. En modulation binaire, la rapidité de modulation est égale au débit binaire : 1 bauds b T R= (2.2)
En modulation M-aires, la rapidité de modulation est plus petite que le débit binaire de la source. Si n est le nombre de bits constituant un symbole M-aires, alors :
bauds log 1 1 2 M D n D nT T R b b b = = = = . (2.3)
La qualité d'une liaison est liée au Taux d'Erreur Binaire (TEB) : transmis bits de nombre faux bits de nombre = TEB (2.4)
Le TEB est ainsi une approximation statistique de Peb, estimation au sens du maximum de vraisemblance, qui tend vers Peb si le nombre de bits transmis tend vers l'infini.
s'exprime en bit/seconde/hertz, où B est la largeur de la bande occupée par le signal modulé. Pour un signal utilisant des symboles M-aires, on aura :
1 bits / s / Hz B Tb = η . (2.5)
Le message à transmettre est issu d'une source binaire et le signal modulant, obtenu après codage, est un signal en bande de base, éventuellement complexe, qui s'écrit sous la forme :
(2.6) ) ( ) ( ) ( ) ( ) (t c g t kT c t a t jb t c k k k k c − = = + =
∑
La fonction g(t) est une forme d'onde qui est prise en considération dans l'intervalle [0; T[ et elle est modulée en amplitude par le symbole ck. En technologie analogique, g(t) peut être une fonction rectangle d'amplitude 1 et de durée T.
Dans les modulations MDA, MDP et MAQ, la modulation transforme ce signal c(t) en un signal modulé m(t) tel que :
(2.7)
⎥
⎦
⎤
⎢
⎣
⎡
=
∑
+ k o ot j kt
e
c
t
m
(
)
Re
(
)
(ω ϕ )La fréquence f0 et la phase ϕ0 caractérisent la porteuse utilisée pour la modulation.
Le signal modulé m(t) véhicule des informations distinctes à travers ak(t) et bk(t) qui sont deux signaux en bande de base appelés respectivement composante en phase (I) et composante en quadrature (Q).
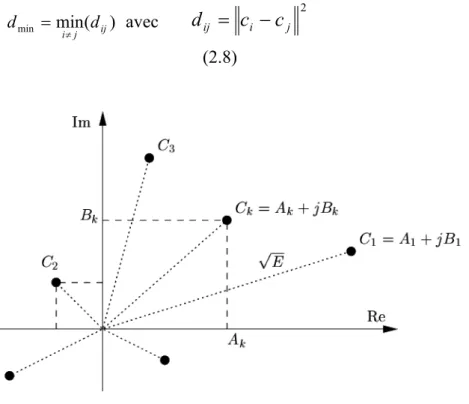
Une représentation dans le plan complexe qui fait correspondre à chaque signal élémentaire un point Ck = Ak + jBk permet de différencier chaque type de modulation.
L'ensemble de ces points associés aux symboles porte le nom de constellation (figure 2.2).
Le choix de la répartition des points dépend des critères suivants :
- Pour pouvoir distinguer deux symboles, il faut respecter une distance minimale dmin, entre les points représentatifs de ces symboles. Plus cette distance est grande et plus la
probabilité d'erreur sera faible. La distance minimale entre tous les symboles est : dmin =mini≠j (dij) avec
2 j i ij
c
c
d
=
−
(2.8)Figure 2.2 Définition d'une constellation numérique.
- A chaque symbole émis correspond un signal élémentaire mk(t) et donc une énergie nécessaire à la transmission de ce symbole. Dans la constellation, la distance entre un point et l'origine est proportionnelle à la racine carrée de l'énergie qu'il faut fournir pendant l'intervalle de temps [kT; (k + 1)T[.
Les deux critères évoqués ci-dessus sont contraires puisque l'on serait tenté d'une part d'éloigner les symboles au maximum pour diminuer la probabilité d'erreur et d'autre part, de les rapprocher de l'origine pour minimiser l'énergie nécessaire à la transmission.
Si M est une puissance de 2, on peut associer une suite de n = log2M à un symbole. Cette association se fait en général en suivant un code de Gray qui permet d'obtenir une distance minimale entre deux symboles voisins. Sur la constellation, on peut indiquer la correspondance entre les valeurs et leurs représentations binaires. La figure 2.3 illustre ce cas pour une constellation de modulation à M = 4 niveaux.
Figure 2.3 Constellation d'une modulation M-aire à 4 niveaux.
Les critères de choix d'une modulation sont :
- La constellation, qui suivant les applications, mettra en évidence une faible énergie nécessaire à la transmission des symboles ou une faible probabilité d'erreur.
- L'occupation spectrale du signal modulé.
- La simplicité de réalisation (avec éventuellement une symétrie entre les points de la constellation).
2.2.2 Modulations par déplacement de phase (MDP)
Reprenons l'expression générale d'une modulation numérique (équation 2.7). Dans le cas présent, les symboles ck sont répartis sur un cercle, et par conséquent :
Ck = ak(t)+ jbk(t) =ejϕk (2.9) ak(t)=cos(
ϕ
k)g(t −kT) (2.10) bk(t)=sin(ϕ
k)g(t −kT) (2.11) Cette dernière expression montre que la phase de la porteuse est modulée par l'argumentϕk de chaque symbole ce qui explique le nom donné à la MDP.
On pourrait imaginer plusieurs MDP-M pour la même valeur de M où les symboles seraient disposés de façon quelconque sur le cercle. Pour améliorer les performances par rapport au bruit, on impose aux symboles d'être repartis régulièrement sur le cercle, ainsi, l'ensemble des phases possibles se traduit par les expressions suivantes :
M k M k
π
π
ϕ
= + 2 lorsque M > 2 (2.12) et :ϕ
k =0 ouπ
lorsque M = 2 (2.13)m(t)=Acos(ω0t +ϕ0)cos(ϕk)−Asin(ω0t+ϕ0)sin(ϕk) (2.14)
On appelle MDP-M une modulation de phase correspondant à des symboles M-aires. La figure 2.4 montre différentes constellations de MDP pour M = 2 et 4 où l'amplitude A est égale à 1.
(a) Constellation d'une MDP-2 (BPSK) (b) Constellation d'une MDP-4 (QPSK)
Figure 2.4 Constellations de deux modulations MDP.
2.2.3 Modulation d’Amplitude en Quadrature (MAQ)
La MDP ne constitue pas une solution satisfaisante pour utiliser efficacement l'énergie émise lorsque le nombre de points M est grand. En effet, dans la MDP les points de la constellation sont sur un cercle. Or, la probabilité d'erreur est fonction de la distance minimale entre les points de la constellation, et la meilleure modulation est celle qui maximise cette distance pour une puissance moyenne donnée. Un choix plus rationnel consiste alors à repartir les points uniformément dans le plan en utilisant simultanément une modulation d'amplitude et de phase.
Les symboles ak et bk prennent respectivement leurs valeurs dans deux alphabets à M éléments (A1,A2,…AM) et (B1,B2,…BM) donnant ainsi naissance à une modulation possédant un nombre E = M2 états, chacun étant représenté par un couple (ak, bk).
Dans le cas particulier, mais très fréquent où M peut s'écrire M=2n, les ak et les bk
représentent deux mots de n bits et le symbole ck se représente alors par un mot de 2.n bits. Par exemple, la MAQ-16 est construite à partir de symboles ak et bk qui prennent leurs
valeurs dans l'alphabet A est une constante donnée. Une représentation de la constellation de cette modulation est donnée figure 2.5(a). La MAQ-16 a été souvent utilisée, notamment pour la transmission sur ligne téléphonique du RTC (à 9600 bits/s) et pour les faisceaux hertziens à grande capacité (140 Mbits/s) développés dans les années 1980.
{
±A 3,± A}
}
Plus généralement lorsque les symboles ak et bk prennent leurs valeurs dans l'alphabet avec M=2n, on obtient une modulation à 22n états et une constellation avec un contour carré. Deux de ces constellations à contour carré sont représentées sur la figure 2.5.
{
±A,±3,...,±(m−1)A
(a) Constellation d'une MAQ-16 (b) Constellation d'une MAQ-64
Figure 2.5 Constellations de deux modulations MAQ.
Un dernier paramètre reste à définir, c'est la distance quadratique entre des signaux réels, elle est définie par la moitié de la distance quadratique des signaux équivalents en bande de base. Que se soit pour la modulation MDP-2 ou les modulations MAQ, la distance minimale entre deux voisins est dmin = d = 2A, soit la distance euclidienne entre deux symboles voisins : (2.15) 2 2 4A d =
Ce paramètre interviendra dans le calcul de la probabilité d'erreur.
Le canal de transmission est un milieu physique qui sépare l'émetteur du récepteur. La connaissance de ses caractéristiques permet entre autre d'évaluer une qualité de service ou de définir une zone de couverture. Les canaux de transmission peuvent être classés en deux groupes :
- Les canaux stationnaires dont les paramètres sont fixes au cours du temps : fibres optiques, câbles métalliques, ...
- Les canaux non stationnaires dont les paramètres évoluent au cours du temps : canal radio-mobile, canal ionosphérique, ...
Les modèles statistiques de canaux les plus courants sont ceux de Gauss, de Rice et de Rayleigh. Ces modèles ont pour objectif de définir les variations de l’amplitude du signal reçu et parfois celles de la phase de ce signal.
2.3.1 Le canal Gaussien
Parmi les canaux stationnaires les plus utilisés, le canal BBAG pour Bruit Blanc Additif Gaussien ou AWGN est celui sur lequel l'évaluation des performances de systèmes de communications est la plus simple à déterminer. Les résultats obtenus avec ce canal servent de référence pour les autres systèmes. Il représente assez fidèlement un canal de transmission radio électrique, lorsque les antennes d'émission et de réception sont en vue directe (simple trajet), la diffusion de la télévision par satellite en est un exemple courant.
Mentionnons que l'adjectif « additif » dans BBAG signifie que l'impact du bruit sur le signal transmis peut être modélisé comme une variable aléatoire N qui s'additionne au signal modulé, cette variable est supposée gaussienne de moyenne nulle et de variance σ2 et donc de densité de probabilité : 2 2 2 2 1 ) ( σ π σ n e n p = − (2.16)
La densité spectrale de puissance bilatérale du bruit présent lors de la transmission sur fréquence porteuse est égale à N0/2. Si ck est la variable qui représente le signal modulé correspondant à un symbole à l'instant k, alors à la sortie du canal nous recueillons :
rk =ck +n (2.17)
AWGN (Additive White Gaussian Noise) est donnée sur la figure 2.6.
Figure 2.6 Modélisation du canal gaussien.
2.3.2 Les canaux de Rice et de Rayleigh
Nous reprenons dans ce qui suit [OLI07]. Le modèle de Rice est utilisé lorsque l'un des trajets reçus est prédominant ; cela est généralement le cas lorsque l’émetteur et le récepteur sont en visibilité directe. L’amplitude N = n du signal reçu suit alors la loi de probabilité suivante : ( ) ⎟⎞ ⎜ ⎛ = ⎟⎟⎠ ⎞ ⎜⎜ ⎝ ⎛− + 2 0 2 2 2 2 2 ) (n s e σ I An p A n ⎠ ⎝σ σ (2.18)
où - I0 est la fonction de Bessel de première espèce à l’ordre 0 - A est l’amplitude de l’onde prédominante
- σ2 est la puissance totale du signal.
Signalons que l’on peut considérer la phase comme constante ou variant selon une loi de probabilité uniforme.
Dans le cas où aucun trajet ne prédomine, le modèle de Rice se transforme en un modèle de Rayleigh défini par la loi de probabilité suivante :
2 2 2 ) ( σ σ n e n n p = − (2.19)
En outre, il faut aussi noter l’existence possible du phénomène Doppler existant lorsque l’émetteur et/ou le récepteur se déplacent. Ce phénomène induit un décalage en fréquence des signaux transmis directement lié à la vitesse de déplacement, à la fréquence porteuse et aux directions d’arrivée des ondes par rapport à la direction de déplacement.


![Figure 1.4 Schéma de principe des algorithmes de compression H.26x et MPEG–X (d'après [NIC02])](https://thumb-eu.123doks.com/thumbv2/123doknet/8066214.270445/15.892.134.794.150.789/figure-schéma-principe-algorithmes-compression-mpeg-après-nic.webp)