UNIVERSITÉ MOHAMMED V – AGDAL
FACULTÉ DES SCIENCES
Rabat
Faculté des Sciences, 4 Avenue Ibn Battouta B.P. 1014 RP, Rabat – Maroc
N° d’ordre: 2493
THÈSE DE DOCTORAT
Présentée par :
Lamia Benameur
Discipline : Sciences de l’Ingénieur
Spécialité : Informatique et Télécommunications
Titre :
Contribution à l’optimisation complexe par des techniques
de swarm intelligence
Soutenue le : 13 Mai 2010
Devant le jury
Président :
D. Aboutajdine,
Professeur, Faculté des Sciences de Rabat.Examinateurs :
A.A. El Imrani,
Professeur, Faculté des Sciences de RabatB.
El Ouahidi,
Professeur, Faculté des Sciences de RabatA. Sekkaki,
Professeur, Faculté des Sciences Ain Chock de CasablancaJ. Benabdelouahab,
Professeur, Faculté des Sciences de TangerAvant-Propos
Les travaux présentés dans ce mémoire ont été effectués au Laboratoire Conception et Systèmes (LCS) de la Faculté des Sciences de Rabat (Equipe de Soft Computing et aide à la décision) sous la direction du Professeur A. A. El Imrani.
J’exprime, tout d’abord, ma vive reconnaissance à Monsieur A. Ettouhami, Di-recteur du LCS, pour la confiance qu’il m’a accordée en m’autorisant à mener mes travaux de recherche dans ce laboratoire.
Je ne saurai témoigner toute ma gratitude à Monsieur A. A. El Imrani, Professeur à la Faculté des Sciences de Rabat, pour ses qualités humaines et scientifiques. Je suis heureuse de lui adresser mes vifs remerciements pour l’intérêt qu’il a manifesté à ce travail en acceptant la charge de suivre de près ces travaux. Je voudrais lui exprimer ma profonde reconnaissance pour l’aide qu’il m’a constamment octroyée tout au long de ce travail, qu’il trouve, en ce mémoire, le témoignage de mes sincères remerciements.
Je présente à Monsieur D. Aboutajdine, Professeur à la Faculté des sciences de Rabat, l’expression de ma profonde reconnaissance, pour l’honneur qu’il me fait en acceptant de présider ce jury de thèse.
Je tiens à remercier Monsieur B. El Ouahidi, Professeur à la Faculté des Sciences de Rabat, de l’intérêt qu’il a porté à ce travail en acceptant d’en être rapporteur et de sa participation au jury de cette thèse.
Je suis particulièrement reconnaissante à Monsieur J. Benabdelouahab, Professeur à la Faculté des Sciences et Techniques de Tanger, qui a bien voulu consacrer une part de son temps pour s’intéresser à ce travail, d’en être le rapporteur et qui me fait l’honneur de siéger dans le jury de cette thèse.
Que Monsieur A. Sekkaki, Professeur à la Faculté des Sciences Ain Chock de Casablanca, accepte mes vifs remerciements pour avoir bien voulu juger ce travail et pour sa participation au jury de cette thèse.
Mes remerciements et ma haute considération vont également à Monsieur Y. El Amrani, Professeur assistant à la Faculté des Sciences de Rabat, pour ses remarques, ses nombreux conseils et pour l’intérêt qu’il a porté à ce travail.
Je n’oublierai pas d’exprimer mon amitié et ma reconnaissance à Mademoiselle J. Alami Chentoufi, docteur chercheur et membre de l’équipe Soft computing et aide à la décision du laboratoire LCS, qui m’a initié au sujet de thèse. Elle m’a fait bénéficier de ses encouragements, de son soutien amical et moral et de son aide scientifique de tous les instants qu’elle n’a cessés de me témoigner.
Je tiens à remercier tous les membres du Laboratoire Conception et Systèmes, Professeurs et Doctorants, pour leur esprit de groupe. Qu’ils trouvent ici le témoi-gnage de toute mon estime et ma sincère sympathie.
Je tiens finalement à souligner que la partie de ce travail, portant sur le problème d’affectation de fréquences mobiles, entre dans le cadre du projet "Résolution du problème d’affectation de fréquences par des méthodes de Soft Computing" soutenu par la Direction de la technologie du Ministère de l’Enseignement Supérieur.
"Durant les trois dernières années de mes études doctorales, j’ai bénéficié d’une bourse d’excellence octroyée par le Centre National de Recherche Scientifique et Technique (CNRST) et ce dans le cadre du programme des bourses de recherche initié par le ministère de l’Education Nationale de l’Enseignement Supérieur, de la Formation des Cadres et de la Recherche Scientifique".
Table des matières
Introduction générale 1
I
Application de l’algorithme d’optimisation par essaims
particulaires à des problèmes réels
5
1 Techniques de calcul "intelligent" 7
1.1 Introduction . . . 8
1.2 Techniques de Calcul "Intelligent" . . . 10
1.2.1 Les réseaux de neurones (Neural Networks) . . . 10
1.2.2 La logique floue (Fuzzy Logic) . . . 12
1.2.3 Les techniques de calcul évolutif (Evolutionary Computation) 13 1.3 Conclusion . . . 24
2 Application de l’algorithme d’optimisation par essaims particu-laires aux problèmes MSAP et PAF 25 2.1 Introduction . . . 26
2.2 Commande en vitesse des machines synchrones à aimant permanent (MSAP) . . . 27
2.2.1 Modélisation d’une machine synchrone à aimant permanent . 27 2.2.2 Conception d’un contrôleur PI basé sur les essaims particulaires 29 2.2.3 Résultats de simulation . . . 31
2.3 Problème d’affectation de fréquences (PAF) . . . 38
2.3.1 Problématique . . . 38
2.3.2 Formulation du FS-FAP . . . 39
2.3.3 Implémentation de l’algorithme d’optimisation par essaims particulaires à la résolution de FS-FAP . . . 40
2.3.4 Etude expérimentale . . . 42
2.3.5 Comparaison avec d’autres techniques . . . 47
2.4 Conclusion . . . 49
II
Conception de nouveaux modèles pour l’optimisation
multimodale et l’optimisation multiobjectif
50
3 Conception d’un nouveau modèle d’optimisation multimodale (Mul-tipopulation Particle Swarms Optimization MPSO) 52
3.1 Introduction . . . 53
3.2 Problématique de l’optimisation multimodale . . . 54
3.3 Techniques de l’optimisation multimodale . . . 55
3.3.1 Les méthodes de niche . . . 55
3.3.2 Les systèmes basés sur l’intelligence des essaims particulaires (PSO) . . . 61
3.3.3 Les systèmes immunitaires artificiels . . . 62
3.4 Synthèse . . . 63
3.5 Conception d’un nouveau modèle d’optimisation multimodale (MPSO) 64 3.5.1 Le principe du modèle . . . 64
3.5.2 La couche de classification automatique floue . . . 64
3.5.3 La couche de séparation spatiale . . . 67
3.5.4 Le concept de migration . . . 68
3.5.5 Fonctionnement du modèle . . . 68
3.5.6 Complexité temporelle de l’algorithme . . . 69
3.6 Etude expérimentale . . . 69
3.6.1 Fonctions tests . . . 70
3.6.2 Résultats numériques . . . 71
3.6.3 Comparaisons avec d’autres techniques . . . 79
3.7 Conclusion . . . 82
4 Conception d’un nouveau modèle pour l’optimisation multiobjectif 83 4.1 Introduction . . . 84
4.2 Principe de l’optimisation multiobjectif . . . 85
4.2.1 Formulation d’un problème multiobjectif . . . 85
4.2.2 Exemple de problème multiobjectif . . . 86
4.3 L’optimisation multiobjectif . . . 86
4.3.1 Choix utilisateur . . . 87
4.3.2 Choix concepteur . . . 87
4.3.3 Les méthodes agrégées . . . 88
4.3.4 Les méthodes non agrégées, non Pareto . . . 90
4.3.5 Les méthodes Pareto . . . 92
4.3.6 Les techniques non élitistes . . . 94
4.3.7 Les techniques élitistes . . . 96
4.3.8 Difficultés des méthodes d’optimisation multiobjectif . . . 99
4.4 Optimisation multiobjectif par essaims particulaires . . . 100
4.4.1 Leaders dans l’optimisation multiobjectif . . . 102
4.4.2 Conservation et propagation des solutions non-dominées . . . 104
4.4.3 Maintien de la diversité par création de nouvelles solutions . . 105
4.4.4 Classification des différentes approches . . . 107
4.5 Synthèse . . . 109
4.6 Optimisation multiobjectif par essaims particulaires basée sur la Clas-sification Floue . . . 110
4.6.1 Implémentation de la couche PSOMO . . . 110
4.6.2 Fonctionnement du modèle . . . 111
4.7.1 Problèmes tests . . . 113
4.7.2 Résultats numériques . . . 115
4.7.3 Comparaisons avec d’autres techniques . . . 115
4.8 Conclusion . . . 118
Conclusion générale 119
Introduction générale
Les ingénieurs et les décideurs sont confrontés quotidiennement à des problèmes de complexité grandissante, relatifs à des secteurs techniques très divers, comme dans la conception de systèmes mécaniques, le traitement des images, l’électronique, les télécommunications, les transports urbains, etc. Généralement, les problèmes à résoudre peuvent souvent s’exprimer sous forme de problèmes d’optimisation. Ces problèmes sont le plus souvent caractérisés en plus de leur complexité, d’exigences qui doivent tenir compte de plusieurs contraintes spécifiques au problème à traiter. L’optimisation est actuellement un des sujets les plus en vue en " soft computing ". En effet, un grand nombre de problèmes d’aide à la décision peuvent être décrits sous forme de problèmes d’optimisation. Les problèmes d’identification, d’apprentissage supervisé de réseaux de neurones ou encore la recherche du plus court chemin sont, par exemple, des problèmes d’optimisation.
Pour modéliser un problème, on définit une fonction objectif, ou fonction de coût (voire plusieurs), que l’on cherche à minimiser ou à maximiser par rapport à tous les paramètres concernés. La définition d’un problème d’optimisation est souvent complétée par la donnée de contraintes : tous les paramètres des solutions retenues doivent respecter ces contraintes, faute de quoi ces solutions ne sont pas réalisables. On distingue en réalité deux types de problèmes d’optimisation : les problèmes "discrets" et les problèmes à variables continues. Parmi les problèmes discrets, on trouve le problème d’affectation de fréquences à spectre fixe : il s’agit de trouver des solutions acceptables en minimisant le niveau global d’interférence de fréquences affectées. Un exemple classique de problème continu est celui de la recherche des valeurs à affecter aux paramètres d’un modèle numérique de processus, pour que ce modèle reproduise au mieux le comportement réel observé. En pratique, on rencontre aussi des "problèmes mixtes", qui comportent à la fois des variables discrètes et des variables continues.
Cette différenciation est nécessaire pour cerner le domaine de l’optimisation diffi-cile. En effet, deux sortes de problèmes reçoivent, dans la littérature, cette appella-tion :
– Certains problèmes d’optimisation discrète, pour lesquels on ne connaît pas d’algorithme exact polynomial. C’est le cas, en particulier, des problèmes dits "NP-difficiles".
– Certains problèmes d’optimisation à variables continues, pour lesquels on ne connaît pas d’algorithme permettant de repérer un optimum global (c’est-à-dire la meilleure solution possible) à coup sûr et en un nombre fini de calculs. Des efforts ont longtemps été menés pour résoudre ces deux types de problèmes, dans le domaine de l’optimisation continue, il existe ainsi un arsenal important de méthodes classiques dites d’optimisation globales, mais ces techniques sont souvent inefficaces si la fonction objectif ne possède pas une propriété structurelle particu-lière, telle que la convexité. Dans le domaine de l’optimisation discrète, un grand nombre d’heuristiques, qui produisent des solutions proches de l’optimum, ont été développées ; mais la plupart d’entre elles ont été conçues spécifiquement pour un problème donné.
Face à cette difficulté, il en a résulté un besoin d’outils informatiques nouveaux, dont la conception ne pouvait manquer de tirer parti de l’essor des technologies de l’information et du développement des mathématiques de la cognition.
Dans ce contexte, un nouveau thème de recherche dans le domaine des sciences de l’information a été récemment suggéré. Cette voie regroupe des approches possédant des caractéristiques ou des comportements "intelligents". Bien que ces techniques aient été développées indépendamment, elles sont regroupées sous un nouveau thème de recherche baptisé "Techniques de calcul intelligent" (Computational Intelligence). Ce thème, introduit par Bezdek (1994), inclut la logique floue, les réseaux de neu-rones artificiels et les méthodes de calcul évolutif. Ces différents champs ont prouvé, durant ces dernières années, leur performance en résistant à l’imperfection et à l’im-précision, en offrant une grande rapidité de traitement et en donnant des solutions satisfaisantes, non nécessairement optimales, pour de nombreux processus industriels complexes.
Par ailleurs, les techniques de calcul "intelligent" peuvent être vues comme un ensemble de concepts, de paradigmes et d’algorithmes, permettant d’avoir des ac-tions appropriées (comportements "intelligents") pour des environnements variables et complexes.
Selon Fogel, ces nouvelles techniques représentent, de façon générale, des mé-thodes, de calculs "intelligents", qui peuvent être utilisées pour adapter les solutions aux nouveaux problèmes et qui ne requièrent pas d’informations explicites. Par la suite, Zadeh a introduit le terme Soft Computing qui désigne également les mêmes techniques [Zadeh, 1994].
Les méthodes de calcul évolutif "Evolutionary Computation" constituent l’un des thèmes majeurs des techniques de calcul "intelligent". Ces méthodes qui s’inspirent de métaphores biologiques (programmation évolutive, stratégie évolutive, program-mation génétique, algorithmes génétiques), d’évolution culturelle des populations
(algorithmes culturels), ou du comportement collectif des insectes (colonies de four-mis, oiseaux migrateurs), etc., sont très utilisées dans le domaine de l’optimisation difficile.
A la différence des méthodes traditionnelles (Hard Computing), qui cherchent des solutions exactes au détriment du temps de calcul nécessaire et qui nécessitent une formulation analytique de la fonction à optimiser, les méthodes de calcul évo-lutif permettent l’étude, la modélisation et l’analyse des phénomènes plus ou moins complexes pour lesquels les méthodes classiques ne fournissent pas de bonnes per-formances, en termes de coût de calcul et de leur aptitude à fournir des solutions au problème étudié.
Une autre richesse de ces métaheuristiques est qu’elles se prêtent à toutes sortes d’extensions. Citons, en particulier :
– L’optimisation multiobjectif [Collette et Siarry, 2002], où il s’agit d’optimiser simultanément plusieurs objectifs contradictoires ;
– L’optimisation multimodale, où l’on s’efforce de repérer tout un jeu d’optima globaux ou locaux ;
– L’optimisation dynamique, qui fait face à des variations temporelles de la fonction objectif.
Dans ce contexte, les travaux présentés dans ce mémoire présentent dans un pre-mier temps l’adaptation de l’une des techniques de calcul évolutif, qui s’inspire du comportement collectif des insectes : l’optimisation par essaims particulaires (Par-ticle Swarm Optimization PSO), à l’optimisation de problèmes réels tels que machine synchrone à aimant permanent et le problème d’affectation de fréquences à spectre fixe.
La seconde partie de ce travail sera consacrée à une investigation de l’optimisation multimodale et l’optimisation multiobjectif par essaims particulaires.
Dans cet ordre d’idée, le présent travail propose une nouvelle méthode d’opti-misation multimodale par essaims particulaires, le modèle MPSO (Multipopulation Particle Swarms Optimization).
Dans le cadre de l’optimisation multiobjectif, une nouvelle approche, basée sur PSO, la dominance de Pareto et la classification floue, est proposée. Le but principal de cette approche est de surmonter la limitation associée à l’optimisation multiob-jectif par essaims particulaires standard. Cette limitation est liée à l’utilisation des archives qui fournit des complexités temporelles et spatiales additionnelles.
Les travaux présentés dans ce mémoire sont structurés selon quatre chapitres : Nous évoquerons dans le premier chapitre un concis rappel sur les différentes tech-niques de calcul "intelligent". Un intérêt tout particulier est destiné aux techtech-niques de calcul évolutif qui s’inscrivent dans le cadre de l’optimisation globale.
Le deuxième chapitre illustre la performance de l’algorithme d’optimisation par essaims particulaires dans l’optimisation globale de problèmes réels. Les différentes implémentations effectuées nécessitent une phase d’adaptation de la méthode adop-tée ainsi qu’un bon réglage des paramètres. Les problèmes traités dans ce chapitre sont de nature combinatoire, e.g., le problème d’affectation de fréquences dans les réseaux cellulaires, ou des problèmes de prise de décision, e.g., la commande en vitesse des machines synchrones à aimant permanent.
Le troisième chapitre présente, dans un premier temps, l’état de l’art dans le do-maine d’optimisation multimodale, et s’intéresse particulièrement aux techniques de niche, basées sur les algorithmes génétiques, les algorithmes culturels et sur les essaims particulaires. Les différentes couches du modèle présenté (MPSO) seront en-suite décrites plus en détail. Enfin, les performances du modèle MPSO sont validées sur plusieurs fonctions tests et comparées à d’autres modèles.
Dans le quatrième chapitre nous commencerons par présenter les différentes tech-niques d’optimisation multiobjectif proposées dans la littérature. Le modèle proposé FC-MOPSO (Fuzzy Clustering Multi-objective Particle Swarm Optimizer) est en-suite présenté et décrit en détail. Les performances du modèle seront enfin évaluées sur plusieurs fonctions tests et comparées à d’autres modèles.
Première partie
Application de l’algorithme
d’optimisation par essaims
Résumé
Cette partie introduit les différentes techniques de calcul "Intelligent". Les tech-niques de calcul évolutif tels que les systèmes immunitaires artificiels, les algorithmes évolutifs et les systèmes basés sur l’intelligence collective sont décrites. Dans un deuxième temps, nous présentons l’application de l’algorithme d’optimisation par essaims particulaires sur deux problèmes réels, un problème continu : la commande d’une machine synchrone à aimant permanent (MSAP), et un autre discrèt : le problème d’affectation de fréquences dans les réseaux cellulaires (PAF).
Chapitre 1
1.1
Introduction
La recherche de la solution optimale d’un problème est une préoccupation im-portante dans le monde actuel, qu’il s’agisse d’optimiser le temps, le confort, la sécurité, les coûts ou les gains. Beaucoup de problèmes d’optimisation sont difficiles à résoudre, la difficulté ne vient pas seulement de la complexité du problème mais également de la taille excessive de l’espace des solutions. Par exemple, le problème du voyageur de commerce a une taille de l’espace de solutions qui varie en factorielle (n-1) où n est le nombre de villes où il faut passer ; On s’aperçoit qu’à seulement 100 villes, il y a ∼ 9 · 10153 solutions possibles. Il est alors impensable de pouvoir les tester toutes pour trouver la meilleure [Amat et Yahyaoui, 1996].
En général, un problème d’optimisation revient à trouver un vecteur −→v ∈ M, tel
qu’un certain critère de qualité, appelé fonction objectif, f : M → R, soit maximisé (ou minimisé). La solution du problème d’optimisation globale nécessite donc de trouver un vecteur −→v ∗ tel que
∀−→v ∈ M : f (−→v ) ≤ f (−→v ∗)(resp. ≥)
Nous assistons ces dernières années à l’émergence de nouvelles techniques d’op-timisation. Le principe de ces techniques repose sur la recherche de solutions en tenant compte de l’incertitude, de l’imprécision de l’information réelle et utilisant l’apprentissage. Le but n’est plus de trouver des solutions exactes, mais des solutions satisfaisantes à coût convenable.
Sur la base de ces nouvelles techniques, le concept de "Computational Intelligence" (calcul "Intelligent") a été introduit par Bezdek [Bezdek, 1994] pour définir une nouvelle orientation de l’informatique. Ce nouveau thème de recherche considère les programmes comme des entités (ou agents) capables de gérer des incertitudes, avec une aptitude à apprendre et à évoluer.
Le terme "Soft Computing", a été également proposé par Zadeh [Zadeh, 1994] qui se réfère à un ensemble de techniques de calcul (Computational techniques) utilisées dans plusieurs domaines, notamment l’informatique, l’intelligence artificielle et dans certaines disciplines des sciences de l’ingénieur.
Les techniques de soft computing regroupent diverses méthodes de différentes ins-pirations, notamment la logique floue, les réseaux de neurones et les techniques de calcul évolutif. En général, ces méthodes reposent particulièrement sur les processus biologiques et sociologiques et considèrent les être vivants comme modèles d’inspira-tion. À la différence des méthodes traditionnelles (Hard Computing), qui cherchent des solutions exactes au détriment du temps de calcul nécessaire et qui nécessitent une formulation analytique de la fonction à optimiser, les méthodes de calcul "in-telligent" permettent l’étude, la modélisation et l’analyse des phénomènes plus ou moins complexes pour lesquels les méthodes classiques ne fournissent pas de bonnes performances, en termes du coût de calcul et de leur aptitude à fournir une solution au problème étudié.
L’objectif visé dans ce chapitre est de présenter les différentes techniques de cal-cul "intelligent". Un intérêt tout partical-culier est adressé aux techniques évolutives utilisées dans le cadre de l’optimisation.
1.2
Techniques de Calcul "Intelligent"
Le principe de base des méthodes de Calcul "Intelligent" consiste à considérer les êtres vivants comme modèles d’inspiration, le but étant de simuler à l’aide des machines leur comportement.
En général, ces techniques peuvent être regroupées en trois grandes classes : les réseaux de neurones artificiels qui utilisent l’apprentissage pour résoudre des pro-blèmes complexes tels que la reconnaissance des formes ou le traitement du langage naturel, la logique floue utilisée dans des applications d’intelligence artificielle, dans lesquelles les variables ont des degrés de vérité représentés par une gamme de valeurs situées entre 1 (vrai) et 0 (faux), et les méthodes de calcul évolutif pour la recherche et l’optimisation (figure 1.1). Ces différentes classes seront présentées dans les sec-tions suivantes.
Fig. 1.1 – Techniques de calcul "Intelligent"
1.2.1
Les réseaux de neurones (Neural Networks)
Un réseau de neurones (Artificial Neural Network) est un modèle de calcul dont la conception est schématiquement inspirée du fonctionnement de vrais neurones. Les réseaux de neurones sont généralement optimisés par des méthodes d’apprentissage de type statistique, si bien qu’ils sont placés d’une part dans la famille des applica-tions statistiques, qu’ils enrichissent avec un ensemble de paradigmes permettant de générer de vastes espaces fonctionnels, souples et partiellement structurés, et d’autre part dans la famille des méthodes de l’intelligence artificielle qu’ils enrichissent en permettant de prendre des décisions s’appuyant d’avantage sur la perception que sur le raisonnement logique formel.
Ce sont les deux neurologues Warren McCulloch et Walter Pitts [McCulloch et Pitts, 1943] qui ont mené les premiers travaux sur les réseaux de neurones. Ils consti-tuèrent un modèle simplifié de neurone biologique communément appelé neurone
formel. Ils montrèrent également théoriquement que des réseaux de neurones for-mels simples peuvent réaliser des fonctions logiques, arithmétiques et symboliques complexes.
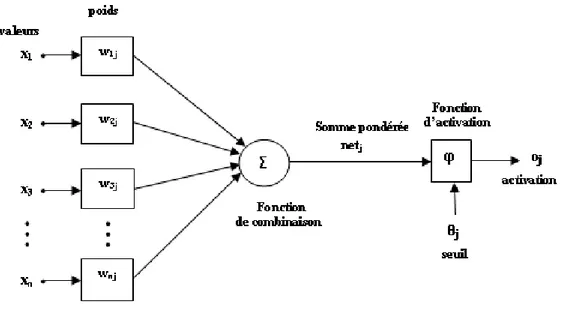
La fonction des réseaux de neurones formels à l’instar du modèle vrai est de résoudre divers problèmes. À la différence des méthodes traditionnelles de résolution informatique, on ne doit pas construire un programme pas à pas en fonction de la compréhension de celui-ci. Les paramètres les plus importants de ce modèle sont les coefficients synaptiques. Ce sont eux qui construisent le modèle de résolution en fonction des informations données au réseau. Il faut donc trouver un mécanisme, qui permet de les calculer à partir des grandeurs acquises du problème, c’est le principe fondamental de l’apprentissage. Dans un modèle de réseau de neurones formels, apprendre, c’est d’abord calculer les valeurs des coefficients synaptiques en fonction des exemples disponibles. La structure d’un réseau de neurones artificiel est donnée par la figure (1.2).
Le neurone calcule la somme de ses entrées puis cette valeur passe à travers la fonction d’activation pour produire sa sortie. La fonction d’activation (ou fonction de seuillage) sert à introduire une non linéarité dans le fonctionnement du neurone.
Fig. 1.2 – Structure d’un neurone artificiel
Les fonctions de seuillage présentent généralement trois intervalles :
1. en dessous du seuil, le neurone est non-actif (souvent dans ce cas, sa sortie vaut 0 ou 1),
2. au voisinage du seuil, une phase de transition,
En général, un réseau de neurone est composé d’une succession de couches dont chacune prend ses entrées à partir des sorties de la couche précédente. Chaque couche i est composée de Ni neurones, prenant leurs entrées sur les Ni−1 neurones
de la couche précédente. À chaque synapse est associé un poids synaptique, de sorte que les Ni−1sont multipliés par ce poids, puis additionnés par les neurones de
niveau i, ce qui est équivalent à multiplier le vecteur d’entrée par une matrice de transformation. Mettre l’une derrière l’autre, les différentes couches d’un réseau de neurones, reviendrait à mettre en cascade plusieurs matrices de transformation et pourrait se ramener à une seule matrice, produit des autres, s’il n’y avait à chaque couche, la fonction de sortie qui introduit une non linéarité à chaque étape. Ceci montre l’importance du choix judicieux d’une bonne fonction de sortie : un réseau de neurones dont les sorties seraient linéaires n’aurait aucun intérêt.
Plusieurs types de réseaux de neurones ont été reportés dans la littérature, no-tamment le perceptron proposé par Rosenblatt [Rosenblatt, 1958], les cartes auto-organisatrices de Kohonen [Kohonen, 1989], le modèle neural-gas [Martinez et Schul-ten, 1991] et les réseaux basés sur le modèle de Hopfield [Hopfield, 1982], etc, [Jedra, 1999].
Grâce à leur capacité de classification et de généralisation, les réseaux de neurones sont généralement utilisés dans des problèmes de nature statistique, tels que la classification automatique, reconnaissance de motif, approximation d’une fonction inconnue, etc.
1.2.2
La logique floue (Fuzzy Logic)
La théorie des sous ensembles flous a été introduite par Lotfi Zadeh en 1965 [Zadeh, 1965] et utilisée dans des domaines aussi variés que l’automatisme, la ro-botique (reconnaissance de formes), la gestion de la circulation routière, le contrôle aérien, l’environnement (météorologie, climatologie, sismologie), la médecine (aide au diagnostic), l’assurance (sélection et prévention des risques) et bien d’autres. Elle constitue une généralisation de la théorie des ensembles classiques, l’une des struc-tures de base sous-jacente à de nombreux modèles mathématiques et informatiques [Bezdek, 1992].
La logique floue s’appuie sur la théorie mathématique des sous ensembles flous. Cette théorie, introduite par Zadeh, est une extension de la théorie des ensembles classiques pour la prise en compte des sous ensembles définis de façon imprécise. C’est une théorie formelle et mathématique dans le sens où Zadeh, en partant du concept de fonction d’appartenance pour modéliser la définition d’un sous-ensemble d’un univers donné, a élaboré un modèle complet de propriétés et de définitions formelles. Il a aussi montré que la théorie des sous-ensembles flous se réduit ef-fectivement à la théorie des sous-ensembles classiques dans le cas où les fonctions d’appartenance considérées prennent des valeurs binaires (0, 1).
À l’inverse de la logique booléenne, la logique floue permet à une condition d’être en un autre état que vrai ou faux. Il y a des degrés dans la vérification d’une condi-tion. La logique floue tient compte de l’imprécision de la forme des connaissances et propose un formalisme rigoureux afin d’inférer de nouvelles connaissances.
Ainsi, la notion d’un sous ensemble flou permet de considérer des classes d’objets, dont les frontières ne sont pas clairement définies, par l’introduction d’une fonction caractéristique (fonction d’appartenance des objets à la classe) prenant des valeurs entre 0 et 1, contrairement aux ensemble "booléens" dont la fonction caractéristique ne prend que deux valeurs possibles 0 et 1.
La capacité des sous ensembles flous à modéliser des propriétés graduelles, des contraintes souples, des informations incomplètes, vagues, linguistiques, les rend aptes à faciliter la résolution d’un grand nombre de problèmes tels que : la commande floue, les systèmes à base de connaissances, le regroupement et la classification floue, etc.
Mathématiquement, un sous ensemble floue F sera défini sur un référentiel H par une fonction d’appartenance, notée µ, qui, appliquée à un élément µ ∈ H, retourne un degré d’appartenance µF(u) de u à F, µF(u) = 0 et µF(u) = 1 correspondent respectivement à l’appartenance et à la non appartenance.
1.2.3
Les techniques de calcul évolutif (Evolutionary
Com-putation)
Les techniques de calcul évolutif (EC) représentent un ensemble de techniques. Ces techniques sont regroupées en quatre grandes classes : les systèmes immuni-taires artificiels, l’intelligence collective, les algorithmes évolutifs et les algorithmes culturels (figure 1.1).
1.2.3.1. Les systèmes immunitaires artificiels
Les algorithmes basés sur les systèmes immunitaires artificiels (AIS Artificial Immune Systems) ont été conçus pour résoudre des problèmes aussi variés que la robotique, la détection d’anomalies ou l’optimisation [De Castro et Von Zuben, 1999], [De Castro et Von Zuben, 2000].
Le système immunitaire est responsable de la protection de l’organisme contre les agressions d’organismes extérieurs. La métaphore dont sont issus les algorithmes AIS mettent l’accent sur les aspects d’apprentissage et de mémoire du système im-munitaire dit adaptatif. En effet, les cellules vivantes disposent sur leurs membranes de molécules spécifiques dites antigènes. Chaque organisme dispose ainsi d’une iden-tité unique, déterminée par l’ensemble des antigènes présents sur ses cellules. Les lymphocytes (un type de globule blanc) sont des cellules du système immunitaire qui possèdent des récepteurs capables de se lier spécifiquement à un antigène unique, permettant ainsi de reconnaître une cellule étrangère à l’organisme. Un lymphocyte
ayant ainsi reconnu une cellule "étrangère" va être stimulé à proliférer (en produi-sant des clones de lui-même) et à se différencier en cellule permettant de garder en mémoire l’antigène, ou de combattre les agressions. Dans le premier cas, il sera ca-pable de réagir plus rapidement à une nouvelle attaque à l’antigène. Dans le second cas, le combat contre les agressions est possible grâce à la production d’anticorps. Il faut également noter que la diversité des récepteurs dans l’ensemble de la population des lymphocytes est quant à elle produite par un mécanisme d’hyper-mutation des cellules clonées [Forrest et al., 1993], [Hofmeyr et Forrest, 1999].
L’approche utilisée dans les algorithmes AIS est voisine de celle des algorithmes évolutionnaires, mais a également été comparée à celle des réseaux de neurones. On peut, dans le cadre de l’optimisation difficile, considérer les AIS comme une forme d’algorithme évolutionnaire présentant des opérateurs particuliers. Pour opérer la sélection, on se fonde par exemple sur une mesure d’affinité entre le récepteur d’un lymphocyte et un antigène ; la mutation s’opère quant à elle via un opérateur d’hy-permutation directement issu de la métaphore.
1.2.3.2. Les algorithmes évolutifs (AE)
Les algorithmes évolutifs (Evolutionary Algorithms) sont des techniques de re-cherche inspirées de l’évolution biologique des espèces, apparues à la fin des années 1950. Parmi plusieurs approches [Holland, 1962], [Fogel et al, 1966], [Rechenberg, 1965], les algorithmes génétiques (AG) constituent certainement les algorithmes les plus connus [Goldberg, 1989a].
Le principe d’un algorithme évolutionnaire est très simple. Un ensemble de N points dans un espace de recherche, choisi a priori au hasard, constituent la popula-tion initiale ; chaque individu x de la populapopula-tion possède une certaine performance, qui mesure son degré d’adaptation à l’objectif visé : dans le cas de la minimisation d’une fonction objectif f, x est d’autant plus performant que f(x) est plus petit. Un AE consiste à faire évoluer progressivement, par générations successives, la compo-sition de la population, en maintenant sa taille constante. Au cours des générations, l’objectif est d’améliorer globalement la performance des individus ; le but étant d’obtenir un tel résultat en imitant les deux principaux mécanismes qui régissent l’évolution des êtres vivants, selon la théorie de Darwin :
– la sélection, qui favorise la reproduction et la survie des individus les plus performants,
– la reproduction, qui permet le brassage, la recombinaison et les variations des caractères héréditaires des parents, pour former des descendants aux potentia-lités nouvelles.
En fonction des types d’opérateurs, i.e., sélection et reproduction génétique, em-ployés dans un algorithme évolutif, quatre approches différentes ont été proposées [Bäck et al, 1997] : les algorithmes génétiques (AG), la programmation génétique (PG), les stratégies d’évolution (SE) et la programmation évolutive (PE) que nous
allons décrire par la suite. La structure générale d’un AE est donnée par le pseudo code (7).
algorithme 1 Structure de base d’un algorithme évolutif Algorithme évolutif t ← 0 Initialiser la population P (t) Evaluer P(t) Répéter t ← t + 1
Sélectionner les parents
Appliquer les opérateurs génétiques Evaluer la population des enfants crées
Créer par une stratégie de sélection la nouvelle population P(t) Tant que (condition d’arrêt n’est pas satisfaite)
a. Les algorithmes génétiques (Genetic Algorithms)
Les algorithmes génétiques sont des techniques de recherche stochastiques dont les fondements théoriques ont été établis par Holland [Holland, 1975]. Ils sont ins-pirés de la théorie Darwinienne : l’évolution naturelle des espèces vivantes. Celles-ci évoluent grâce à deux mécanismes : la sélection naturelle et la reproduction. La sélection naturelle, l’élément propulseur de l’évolution, favorise les individus, d’une population, les plus adaptés à leur environnement. La sélection est suivie de la re-production, réalisée à l’aide de croisements et de mutations au niveau du patrimoine génétique des individus. Ainsi, deux individus parents, qui se croisent, transmettent une partie de leur patrimoine génétique à leurs progénitures. En plus, quelques gènes des individus, peuvent être mutés pendant la phase de reproduction. La combinai-son de ces deux mécanismes, conduit, génération après génération, à des populations d’individus de plus en plus adaptés à leur environnement. Le principe des AG est décrit par le pseudo code (8).
algorithme 2 Structure de base d’un algorithme génétique Algorithme Génétique t ← 0 Initialiser la population P (t) Evaluer P(t) Répéter t ← t + 1 P (t) = Sélectionner (P (t − 1)) Croiser (P (t)) Muter (P (t)) Evaluer P (t)
Dans leur version canonique, les AG présentent des limites qui conduisent le plus souvent à des problèmes de convergences lente ou prématurée. Pour pallier à ces inconvénients, des améliorations ont été apportées : e.g, codage, opérateurs bio-logiques, stratégie élitiste, etc. les détails de fonctionnement de ces algorithmes peuvent être trouvés dans plusieurs références principalement : [El Imrani, 2000], [Michalewicz, 1996].
b. Programmation génétique (Genetic Programming)
La programmation génétique est une variante, des algorithmes génétiques, des-tinée à manipuler des programmes [Koza, 1992] pour implémenter un modèle d’ap-prentissage automatique. Les programmes sont généralement codés par des arbres qui peuvent être vus comme des chaînes de bits de longueur variable. Une grande partie des techniques et des résultats concernant les algorithmes génétiques peuvent donc également s’appliquer à la programmation génétique.
c. Stratégies d’évolution (Evolutionary Strategy)
Les stratégies d’évolution forment une famille de métaheuristiques d’optimisa-tion. Elles sont inspirées de la théorie de l’évolud’optimisa-tion. Ce modèle fut initialement proposé par Rencherberg [Rechenberg, 1965]. il constitue, à ce titre, la première véritable métaheuristique et le premier algorithme évolutif.
Dans sa version de base, l’algorithme manipule itérativement un ensemble de vecteurs de variables réelles, à l’aide d’opérateurs de mutation et de sélection. L’étape de mutation est classiquement effectuée par l’ajout d’une valeur aléatoire, tirée au sein d’une distribution normale. La sélection s’effectue par un choix déterministe des meilleurs individus, selon la valeur de la fonction d’adaptation.
Les strategies d’évolution utilisent un ensemble de µ "parents" pour produire λ "enfants". Pour produire chaque enfant, ρ parents se "recombinent". Une fois pro-duits, les enfants sont mutés. L’étape de sélection peut s’appliquer, soit uniquement aux enfants, soit à l’ensemble (enfants + parents). Dans le premier cas, l’algorithme est noté (µ, λ)−ES, dans le second (µ + λ)−ES [Schoenauer et Michalewicz, 1997].
À l’origine, l’étape de recombinaison était inexistante, les algorithmes étant alors notés ((µ, λ)−ES ou (µ + λ)−ES. Les méthodes actuelles utilisent l’opérateur de recombinaison, comme les autres algorithmes évolutifs, afin d’éviter d’être piégées dans des optima locaux.
Une itération de l’algorithme général procède comme suit : 1. À partir d’un ensemble de µ parents,
2. produire une population de λ enfants : a. choisir ρ parents,
b. recombiner les parents pour former un unique individu, c. muter l’individu ainsi crée,
3. sélectionner les µ meilleurs individus.
d. Programmation évolutive (Evolutionary Programming)
La programmation évolutive a été introduite par Laurence Fogel en 1966 [Fo-gel et al, 1966] dans la perspective de créer des machines à état fini (Finite State Machine) dans le but de prédire des événements futurs sur la base d’observations antérieures.
La programmation évolutive suit le schéma classique des algorithmes évolutifs de la façon suivante :
1. on génère aléatoirement une population de n individus qui sont ensuite évalués ; 2. chaque individu produit un fils par l’application d’un opérateur de mutation
suivant une distribution normale ;
3. les nouveaux individus sont évalués et on sélectionne de manière stochastique une nouvelle population de taille n (les mieux adaptés) parmi les 2n individus de la population courante (parents + enfants) ;
4. on réitère, à partir de la deuxième étape, jusqu’à ce que le critère d’arrêt choisi soit valide.
La programmation évolutive partage de nombreuses similitudes avec les stratégies d’évolution : les individus sont, a priori, des variables multidimensionnelles réelles et il n’y a pas d’opérateur de recombinaison. La sélection suit une stratégie de type (µ + λ).
1.2.3.3. Les systèmes de classifieurs (Learning Classifier Systems)
Les classifieurs sont des machines, d’apprentissage automatique, basées sur la gé-nétique et l’apprentissage renforcé, mais sont d’une complexité et d’une richesse bien plus grande. Ils sont capables de s’adapter par apprentissage à un environnement dans lequel ils évoluent. Ils reçoivent des entrées de leur environnement et réagissent en fournissant des sorties. Ces sorties sont les conséquences de règles déclenchées directement ou indirectement par les entrées. Un système classifieur est constitué de trois composantes principales :
1. Un système de règles et de messages, 2. Un système de répartition de crédits, 3. Un algorithme évolutif.
Le système de règles et de messages est un type particulier de système de produc-tion (SP). Un SP est un procédé qui utilise des règles comme unique outil algorith-mique. Une règle stipule que quand une condition est satisfaite une action peut être réalisée (règle déclenchée) [Goldberg, 1989a].
Notons que l’environnement dans lequel évolue le système de classifieurs peut changer au cours de l’évolution. Le système s’adapte alors remettant éventuellement en cause des règles. D’une manière générale, les systèmes classifieurs sont capables d’induire de nouvelles règles par généralisation à partir d’exemples [Holland et al, 1986]. Les systèmes de classifieurs sont utilisés pour résoudre des problèmes réels en biologie, en médecine, en sciences de l’ingénieur, etc.
1.2.3.4. Les systèmes basés sur l’intelligence collective (Swarm Intelli-gence)
L’intelligence collective désigne les capacités cognitives d’une communauté ré-sultant des interactions multiples entre les membres (ou agents) de la communauté. Des agents, au comportement très simple, peuvent ainsi accomplir des tâches com-plexes grâce à un mécanisme fondamental appelé synergie. Sous certaines conditions particulières, la synergie créée, par la collaboration entre individus, fait émerger des possibilités de représentation, de création et d’apprentissage supérieures à celles des individus isolés.
Les formes d’intelligence collective sont très diverses selon les types de commu-nauté et les membres qu’elles réunissent. Les systèmes collectifs sont en effet plus ou moins sophistiqués. Les sociétés humaines en particulier n’obéissent pas à des règles aussi mécaniques que d’autres systèmes naturels, par exemple du monde animal. Pour des systèmes simples les principales caractéristiques sont :
1. L’information locale : Chaque individu ne possède qu’une connaissance par-tielle de l’environnement et n’a pas conscience de la totalité des éléments qui influencent le groupe,
2. L’ensemble de règles : Chaque individu obéit à un ensemble restreint de règles simples par rapport au comportement du système global,
3. Les interactions multiples : Chaque individu est en relation avec un ou plusieurs autres individus du groupe,
4. La collectivité : les individus trouvent un bénéfice à collaborer (parfois instinc-tivement) et leur performance est meilleure que s’ils avaient été seuls.
L’intelligence collective est observée notamment chez les insectes sociaux (fourmis, termites et abeilles) et les animaux en mouvement (oiseaux migrateurs, bancs de poissons). En conséquence, plusieurs algorithmes basés sur le principe d’intelligence collective ont été introduits : on peut citer les colonies de fourmis et les essaims particulaires [Hoffmeyer, 1994], [Ramos et al., 2005].
a. Les colonies de fourmis (Ants Colony)
Une colonie de fourmis, dans son ensemble, est un système complexe stable et autorégulé capable de s’adapter très facilement aux variations environnementales les plus imprévisibles, mais aussi de résoudre des problèmes, sans contrôle externe ou mécanisme de coordination central, de manière totalement distribuée.
L’optimisation par colonies de fourmis (ACO "Ants Colony Optimisation") s’ins-pire du comportement des fourmis lorsque celles-ci sont à la recherche de nourriture [Deneubourg et al, 1983], [Deneubourg et Goss, 1989], [Goss et al, 1990]. Il a ainsi été démontré qu’en plaçant une source de nourriture reliée au nid par une passerelle, formée d’une branche courte et d’une branche longue, les fourmis choisissaient toutes le chemin le plus court après un certain laps de temps [Beckers et al, 1992]. En effet, chaque fourmi se dirige en tenant compte des traces de phéromone déposées par les autres membres de la colonie qui la précèdent.
Comme cette phéromone s’évapore, ce choix probabiliste évolue continuellement. Ce comportement collectif, basé sur une sorte de mémoire partagée entre tous les individus de la colonie, peut être adapté et utilisé pour la résolution de problèmes d’optimisation combinatoire surtout les problèmes du parcours des graphes.
D’une façon générale, les algorithmes de colonies de fourmis sont considérés comme des métaheuristiques à population, où chaque solution est représentée par une fourmi se déplaçant dans l’espace de recherche. Les fourmis marquent les meilleures solu-tions, et tiennent compte des marquages précédents pour optimiser leur recherche.
Ces algorithmes utilisent une distribution de probabilité implicite pour effectuer la transition entre chaque itération. Dans leurs versions adaptées à des problèmes combinatoires, ils utilisent une construction itérative des solutions.
La différence qui existe entre les algorithmes de colonies de fourmis et les autres métaheuristiques proches (telles que les essaims particulaires) réside dans leur aspect constructif. En effet, dans le cas des problèmes combinatoires, il est possible que la meilleure solution soit trouvée, alors même qu’aucune fourmi ne l’aura découverte effectivement. Ainsi, dans l’exemple du problème du voyageur de commerce, il n’est pas nécessaire qu’une fourmi parcoure effectivement le chemin le plus court, i.e., celui-ci peut être construit à partir des segments les plus renforcés des meilleures solutions. Cependant, cette définition peut poser problème dans le cas des problèmes à variables réelles, où aucune structure de voisinage n’existe.
b. Les essaims particulaires (Particle Swarm Optimization PSO)
L’optimisation par essaims particulaires est une métaheuristique d’optimisation, proposée par Russel Ebenhart et James Kennedy en 1995 [Eberhart et Kennedy, 1995], [Kennedy et Eberhart, 1995]. Cette métaheuristique s’appuie notamment sur un modèle développé par le biologiste Craig Reynolds à la fin des années 1980, permettant de simuler le déplacement d’un groupe d’oiseaux.
Cette méthode d’optimisation se base sur la collaboration des particules entre elles. Elle a d’ailleurs des similarités avec les algorithmes de colonies de fourmis, qui s’appuient eux aussi sur le concept d’auto-organisation.
Ainsi, grâce à des règles de déplacement très simples (dans l’espace de solutions), les particules peuvent converger progressivement vers un optimum. Cette métaheu-ristique semble cependant mieux fonctionner pour des espaces en variables continues. Au départ de l’algorithme, un essaim est réparti au hasard dans l’espace de re-cherche de dimension D, chaque particule p est aléatoirement placée dans la position
xpde l’espace de recherche, chaque particule possède également une vitesse aléatoire.
Ensuite, à chaque pas de temps :
– chaque particule est capable d’évaluer la qualité de sa position et de garder en mémoire sa meilleure performance Pi : la meilleure position qu’elle a
at-teinte jusqu’ici (qui peut en fait être parfois la position courante) et sa qua-lité (la valeur en cette position de la fonction à optimiser),
– chaque particule est capable d’interroger un certain nombre de ses congénères (ses informatrices, dont elle-même) et d’obtenir de chacune d’entre elles sa propre meilleure performance Pg (et la qualité afférente),
– à chaque pas de temps, chaque particule choisit la meilleure des meilleures performances dont elle a connaissance, modifie sa vitesse V en fonction de cette information et de ses propres données et se déplace en conséquence. La modification de la vitesse est une simple combinaison linéaire de trois ten-dances, à l’aide de coéfficients de confiance :
– la tendance « aventureuse », consistant à continuer selon la vitesse actuelle, – la tendance « conservatrice », ramenant plus ou moins vers la meilleure
posi-tion déjà trouvée,
– la tendance « panurgienne », orientant approximativement vers la meilleure informatrice.
La mise à jour des deux vecteurs vitesse et position, de chaque particule p dans l’essaim, est donnée par les équations (1.1) et (1.2) :
vpj(t + 1) = τ (t)vjp(t) + µω1j(t)(Pji(t) − xpj(t)) + νω2j(t)(Pjg(t) − x p
j(t)) (1.1)
xpj(t + 1) = xpj(t) + vpj(t + 1) (1.2) Où j = 1 . . . , D, τ (t) est le facteur d’inertie, µ représente le paramètre cognitif et ν le paramètre social. ω1j(t) et ω2j(t) sont des nombres aléatoires compris entre 0 et 1.
Lors de l’évolution de l’essaim, il peut arriver qu’une particule sorte de l’es-pace de recherche initialement défini. Pour rester dans un esl’es-pace de recherche fini donné, on ajoute un mécanisme pour éviter qu’une particule ne sorte de cet espace.
le plus fréquent est le confinement d’intervalle. Supposons, par simplicité, que l’es-pace de recherche soit [xmin, xmax]D. Alors ce mécanisme stipule que si une
coordon-née xj, calculée selon les équations de mouvement, sort de l’intervalle [xmin, xmax],on
lui attribue en fait la valeur du point frontière le plus proche. En pratique, celà re-vient donc à remplacer la deuxième équation de mouvement (équation 1.2) par :
xj(t + 1) = min(max(xj(t) + vj(t + 1), xmin), xmax) (1.3)
De plus, on complète souvent le mécanisme de confinement par une modifica-tion de la vitesse, soit en remplaçant la composante qui pose problème par son oppo-sée, souvent pondérée par un coefficient inférieur à 1, soit, tout simplement, en l’an-nulant. Donc le principe du confinement consiste à ramener la particule qui sort de l’es-pace de recherche au point le plus proche qui soit dans cet esl’es-pace et modifier sa vitesse en conséquence. Le pseudo code de l’algorithme PSO de base est donné par l’algorithme (3), [De Falco et al, 2007].
Principales caractéristiques
Ce modèle présente quelques propriétés intéressantes, qui en font un bon outil pour de nombreux problèmes d’optimisation, particulièrement les problèmes forte-ment non linéaires, continus ou mixtes (certaines variables étant réelles et d’autres entières) :
– il est facle à programmer, quelques lignes de code suffisent dans n’importe quel langage évolué,
– il est robuste (de mauvais choix de paramètres dégradent les performances, mais n’empêchent pas d’obtenir une solution).
algorithme 3 Pseudo code de l’algorithme PSO
t ← 0
Pour chaque particule
Initialiser sa position et sa vitesse. Initialiser Pi(t)
Fin pour Répéter
Choisir la particule Pg(t) ayant la meilleure fitness dans l’itération courante
Pour chaque particule p
Calculer la vitesse vp(t + 1) utilisant l’équation (1.1).
Mettre à jour le vecteur position xp(t + 1) selon l’équation (1.2).
Calculer la valeur de la fitness f (xp(t))
Si f (xp(t)) > f (Pi(t))
Pi(t + 1) ← xp(t)
Fin si Fin pour
t ← t + 1
1.2.3.5. Les algorithmes culturels (Cultural Algorithms CA) a. Principes de base
Les algorithmes culturels sont des techniques évolutives modélisant l’évolution culturelle des populations [Reynolds, 1994]. Ces algorithmes supportent les méca-nismes de base de changement culturel [Durham, 1994]. Certains sociologues ont proposé des modèles où les cultures peuvent être codées et transmises à l’intérieur et entre les populations [Durham, 1994], [Renfrew, 1994]. En se basant sur cette idée, Reynolds a développé un modèle évolutif dans lequel l’évolution culturelle est consi-dérée comme un processus d’héritage qui agit sur deux niveaux évolutifs différents : le niveau microévolutif (espace population) et le niveau macro-évolutif (espace de connaissance) [Reynolds, 1994].
Fig. 1.3 – Les composants principaux d’un algorithme culturel
Ces algorithmes agissent donc sur deux espaces : l’espace de population qui contient un ensemble d’individus qui évoluent grâce à un modèle évolutif, et l’espace de connaissances qui contient les informations et les connaissances, spécifiques au problème à résoudre, utilisées pour guider et influencer l’évolution des individus des populations au cours des générations. De ce fait, un protocole de communication est indispensable pour établir une interaction entre ces deux espaces (figure 1.3).
Ce protocole a, en fait, une double mission, il détermine d’une part quels indi-vidus de la population peuvent influencer l’espace de connaissances (fonction d’ac-ceptance), et d’autre part quelles connaissances peuvent influencer l’évolution des populations (fonction d’influence). Le pseudo code (4) représente la structure de base d’un AC [Zhu et Reynolds, 1998].
Plusieurs versions d’algorithmes culturels ont été développées avec différentes im-plémentations des deux espaces évolutifs. VGA (Version space guided Genetic Algo-rithm) se sert d’un algorithme génétique comme modèle micro-évolutif et de "Version
algorithme 4 Structure de base d’un Algorithme Culturel
t ← 0
Initialiser la population P (t) ;
Initialiser l’espace de connaissances B(t) ; Répéter
Evaluer P(t) ;
Ajuster (B(t), acceptance P(t)) ; Evaluer (P(t), influence B(t)) ;
t ← t + 1 ;
Jusqu’à (condition d’arrêt valide) ;
Spaces" pour le niveau macro-évolutif [Reynolds et Zannoni, 1994], d’autres implé-mentations utilisent la programmation génétique pour le niveau micro évolutif et "Program segments" pour le niveau macro-évolutif [Zannoni et Reynolds, 1997].
1.3
Conclusion
Dans ce chapitre, nous avons présenté les différentes techniques de calcul "intel-ligent". Ces méthodes s’avèrent utiles dans divers domaines de recherche : l’appren-tissage, la classification, l’optimisation, etc. Un intérêt tout particulier est adressé aux problèmes d’optimisation, qui constitue l’un des principaux objectifs de cette étude.
Dans ce contexte, nous avons choisi de nous intéresser aux techniques de calcul évolutif (Evolutionary Computation EC) en raison de leur efficacité dans le cadre de l’optimisation globale. Ces techniques qui s’inspirent des métaphores biologiques (Programmation Evolutive, Stratégie d’Evolution, Programmation Génétique, Algo-rithmes Génétiques), de l’évolution culturelle des populations (AlgoAlgo-rithmes Cultu-rels), ou du comportement collectif (Colonies de Fourmis et Essaims particulaires), etc., offrent la possibilité de trouver des solutions optimales en un temps de calcul raisonnable.
En général, les techniques EC ont été conçues initialement, dans leur version de base, pour traiter un certain type de problèmes. Par exemple, les AG canoniques ont été proposés pour l’optimisation de fonctions, les algorithmes d’optimisation par colonies de fourmis pour les problèmes de parcours de graphe, etc. En général, ces méthodes ont prouvé leur efficacité à résoudre des problèmes analogues à ceux pour lesquelles elles ont été conçues à l’origine.
En conclusion, bien qu’on dispose d’une panoplie de méthodes utiles à l’optimisa-tion globale, leur applical’optimisa-tion directe à un problème donné est quasiment impossible. En effet, une phase d’adaptation de ces techniques au problème à résoudre reste une démarche indispensable pour obtenir de meilleures performances.
Chapitre 2
Application de l’algorithme
d’optimisation par essaims
particulaires aux problèmes MSAP
et PAF
2.1
Introduction
La résolution d’un problème d’optimisation consiste à explorer un espace de recherche afin de maximiser (ou minimiser) une fonction objectif. En effet, dans la vie courante nous sommes fréquemment confrontés à des problèmes réels d’optimisation plus ou moins complexes.
En général, deux sortes de problèmes reçoivent, dans la littérature, cette appella-tion :
– Certains problèmes d’optimisation discrets, pour lesquels on ne connait pas d’algorithme exact polynomial (NP-difficiles),
– Certains problèmes d’optimisation à variables continues, pour lesquels on ne connait pas d’algorithme permettant de repérer un optimum global à coup sûr et en un nombre fini de calculs.
Des efforts ont été longtemps menés, séparément, pour résoudre ces deux types de problèmes. Dans le domaine de l’optimisation continue, il existe un arsenal de mé-thodes classiques, mais ces techniques se trouvent souvent limitées. Cette limitation est due soit à l’absence de modèles analytiques, soit à l’inadéquation des techniques de résolution. Dans le domaine de l’optimisation discrète, un grand nombre d’heuris-tiques, qui produisent des solutions proches de l’optimum, ont été développées, mais la plupart d’entre elles ont été conçues spécifiquement pour un problème donné.
L’arrivée des métaheuristiques marque une réconciliation des deux domaines : en effet, celles-ci s’appliquent à toutes sortes de problèmes discrèts et elles peuvent s’adapter aussi aux problèmes continus.
L’algorithme d’optimisation par essaims particulaires (PSO) fait partie de ces métaheuristiques. cet algorithme est basé sur la notion de coopération entre des agents (les particules qui peuvent être vues comme des « animaux » aux capacités assez limitées : peu de mémoire et de facultés de raisonnement). L’échange d’in-formation entre les agents fait que, globalement, ils arrivent néanmoins à résoudre des problèmes difficiles voire complexes.
Dans ce chapitre, l’algorithme d’optimisation par essaims particulaires est im-plémenté pour résoudre deux problèmes réels, un problème continu : la commande d’une machine synchrone à aimant permanent, et un autre discret : le problème d’affectation de fréquences dans les réseaux cellulaires.
2.2
Commande en vitesse des machines synchrones
à aimant permanent (MSAP)
Les machines synchrones à aimant permanent (MSAP) sont de grand intérêt, particulièrement dans les applications industrielles de faible et moyenne puissance, puisqu’elles possèdent de bonnes caractéristiques telles que la compacité de la di-mension, bons rapports couple/poids et couple/inertie et l’absence des pertes dans le rotor [Slemon, 1994]. Cependant, la performance de MSAP est très sensible aux variations de paramètres et aux perturbations externes de charge dans le système.
La conception du contrôleur conventionnel, i.e., Proportionnel-Intégrateur (PI), est basée sur un modèle mathématique du dispositif utilisé, qui peut souvent être inconnu, non-linéaire, complexe et multi-variable avec variation de paramètres. De ce fait, le contrôleur conventionnel PI ne présente pas, en général, une solution utile pour la commande du moteur MSAP. Pour surmonter ces problèmes, plusieurs stratégies de commande ont été proposées pour la commande en vitesse des MSAP, notamment par : la logique floue [Lee, 1990], [Akcayol et al, 2002], les réseaux de neurones artificiels [Lin et Lee, 1991] [Rahman et Hoque, 1998], les algorithmes génétiques [Loukdache et al, 2007], et par les essaims particulaires [Benameur et al, 2007].
Dans les sections suivantes nous décrivons la modélisation des MSAP, nous pré-sentons les résultats de simulation relatifs à l’utilisation d’un PI basé sur les essaims particulaires (PIPSO) [Benameur et al, 2007] et nous comparons enfin les résultats avec ceux obtenus par l’utilisation des algorithmes génétiques (PIGA) [Loukdache et al, 2007].
2.2.1
Modélisation d’une machine synchrone à aimant
per-manent
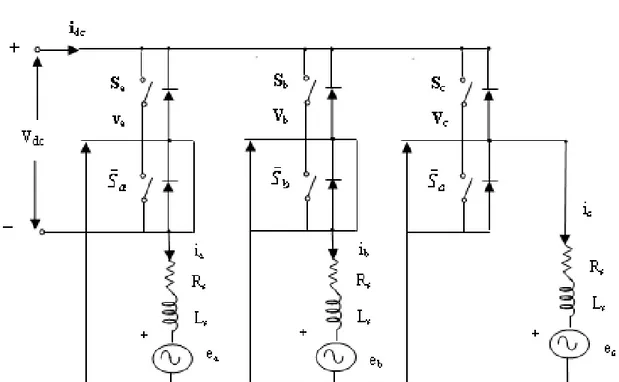
La configuration du système de commande des MSAP est donnée par la figure (2.1). Le système de commande se compose d’un contrôleur de vitesse, d’un régu-lateur de courant, d’un contrôleur de courant à bande d’hystérésis, d’un onduleur triphasé et d’un capteur de position.
θr représente la position du rotor, ωr est la vitesse actuelle, i∗a, i∗b, i∗c, sont les
courants de phase de référence et ew désigne l’erreur en vitesse. ew est la différence
entre la vitesse de référence ω∗
r et la vitesse actuelle ωr. Utilisant l’erreur en vitesse
ew, le contrôleur de vitesse génère un courant appelé courant de référence ou courant
de contrôle I∗.
Fig. 2.1 – Schéma de la commande en vitesse de MSAP
Les équations de tension au niveau du stator de la MSAP sous forme matricielle sont données par l’équation (2.1).
VVab Vc = R0s R0s 00 0 0 Rs iiab ic L0s L0s 00 0 0 Ls d dt iiab ic + eeab ec (2.1) Les équations d’état associées à l’équation (3.1) peuvent être écrites selon la formule (2.2) : d dt · ia ib ic ¸ = · Ls 0 0 0 Ls 0 0 0 Ls ¸−1½· −Rs 0 0 0 −Rs 0 0 0 −Rs ¸ · ia ib ic ¸ − · ea eb ec ¸ + · Va Vb Vc ¸¾ (2.2) La vitesse du rotor et le couple électrique Tepeuvent être formulés selon les équations
(2.3) et (2.4) : d dtωr = p 2 µ Te− TL− B µ 2 p ¶ ωr ¶ /J (2.3) Te = KI∗ (2.4)
Où K = −3p4 λf et λf est le flux dû à l’aimant permanent du rotor. L’équation du
contrôleur de courant de bande d’hystérésis est donnée par l’équation (2.5).
hx = ( 1 si i∗ x− ix ≤ 0.5hrb 0 si i∗ x− ix ≥ −0.5hrb (2.5) Où, x représente a, b, c respectivement. hx désigne la fonction du contrôleur de
courant à bande d’hystérésis ha, hb, hc. hrb est le rang du contrôleur de courant à
bande d’hystérésis. En utilisant la fonction hx, l’équation (2.2) peut être formulée
de la façon donnée en équation (2.6) :
d dt h i a ib ic i =h Ls 0 0 0 Ls 0 0 0 Ls i−1½h −R s 0 0 0 −Rs 0 0 0 −Rs i h i a ib ic i −h ea eb ec i + · (2ha−hb−hc) 3 (−ha+2hb−hc) 3 (−ha−hb+2hc) 3 ¸ [vdc] ¾ (2.6)
2.2.2
Conception d’un contrôleur PI basé sur les essaims
par-ticulaires
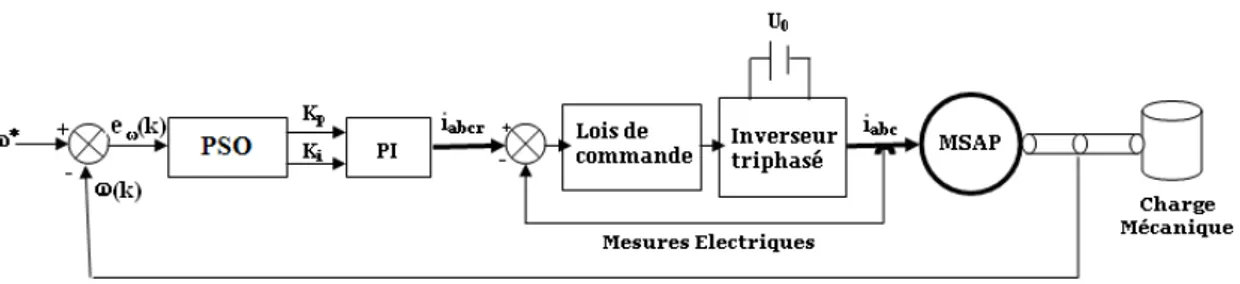
Le nouveau contrôleur proposé intègre le modèle PSO [Benameur et al, 2007] (figure 2.3). L’objectif principal est d’identifier les meilleurs paramètres du contrôleur conventionnel de vitesse PI (Kp et Ki), qui optimisent une fonction objectif et qui
dépend particulièrement de l’erreur en vitesse reçue.
ew représente l’erreur en vitesse et ω∗ est la vitesse de référence. La fonction
objective que nous souhaitons minimiser est donnée par l’équation (2.7) :
F (Kp, Ki) = α1· e2w(k) + α2· (Kp· ew(k) + Ki· ew(k) · T )2 (2.7)
Où α1 et α2 représentent le poids d’importance du premier et du second terme de l’équation (2.7) respectivement, T est le temps d’échantillonnage et Kp, Ki sont les
Fig. 2.3 – Contrôleur PI basé sur PSO pour la commande de MSAP
Dans cette application, les signaux de retour représentent respectivement la po-sition θ et les courants de phase. Le signal relatif à la popo-sition est θ utilisé pour calculer la vitesse.
La figure (2.3) montre que le bloc (PSO) reçoit l’erreur en vitesse eω et fournit les
paramètres optimaux (Kp, Ki) au bloc suivant PI. Ce bloc exploite ces paramètres
pour générer les courants de référence optimaux iabcr. Une boucle de courants,
com-posée d’un onduleur triphasé, produit ensuite les courants optimaux iabc qui vont
être injectés dans le bloc de la machine MSAP pour qu’elle puisse atteindre la vitesse
ω∗ requise.
2.2.2.1. Implémentation de PSO pour la commande de MSAP La configuration des paramètres de l’algorithme PSO est donnée par :
– Taille de l’essaim : la première étape d’un algorithme PSO est de créer l’essaim de particules initial. La taille de l’essaim utilisée est de 50. La position et la vitesse de chaque particule sont représentées par des valeurs réelles ;
– Intervalle de variables : l’algorithme PSO est utilisé pour chercher les valeurs des gains du Kp et Ki contrôleur PI. Par conséquent, chaque particule aura
deux positions associées à ces deux gains. Chaque position doit appartenir à un intervalle de recherche spécifique. Pour cette application, le premier para-mètre (Kp) peut varier dans l’intervalle [50, 100], alors que les valeurs permises
de (Kp) appartiennent à l’intervalle [1, 10] ;
– Le facteur d’inertie τ (t) utilisé est donné par l’équation (2.8)
τ (t) = 0.9 − t ∗ (0.5/(t + 1)) (2.8)
– Les paramètres µ et ν, utilisés dans l’équation de la mise à jour du vecteur vitesse (équation (1.1)), sont initialisés à 2.
2.2.3
Résultats de simulation
Dans cette section, les résultats de simulation relatifs au contrôleur proposé PIPSO pour la commande en vitesse d’une machine synchrone à aimant perma-nent seront présentés et comparés avec ceux obtenus par l’utilisation du contrôleur conventionnel PI et des algorithmes génétiques (PIGA) [Loukdache et al, 2007].
Les paramètres, de la MSAP étudiée dans cette application, sont les suivants : – Résistance du stator : Rs = 2.875 Ω ;
– Inductance Ld= Lq = 8.5e−3H ;
– Inertie = 0.8e−3kg · m2;
– Nombre de paires de pôles = 4.
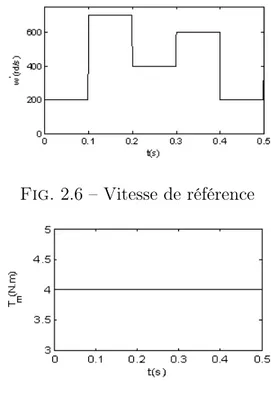
L’objectif principal de cette application étant de fournir comme entrée une vitesse de référence que la MSAP doit asservir. Pour cela, deux cas d’exemple sont étudiés. Dans le premier cas, la vitesse de référence est définie par un échelon qui varie entre 200 et 700 rd/s (figure 2.4), le couple de charge mécanique varie entre 0 et 6 N.m (figure 2.5). Pour le deuxième cas, la vitesse de référence est représentée par séquence répétitive de trapézoïdes (figure 2.6), le couple de charge mécanique étant maintenu constant durant le temps de simulation (Tm = 4 N.m) (figure 2.7).
Fig. 2.4 – Vitesse de référence
Fig. 2.6 – Vitesse de référence
Fig. 2.7 – Couple de charge mécanique 2.2.3.1. Premier cas : Commande par échelon
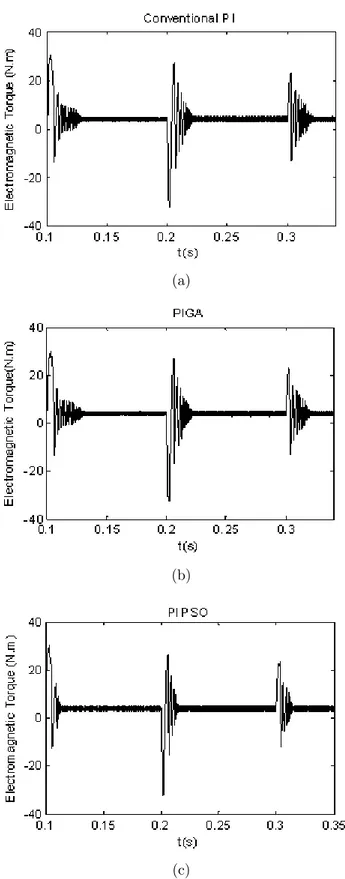
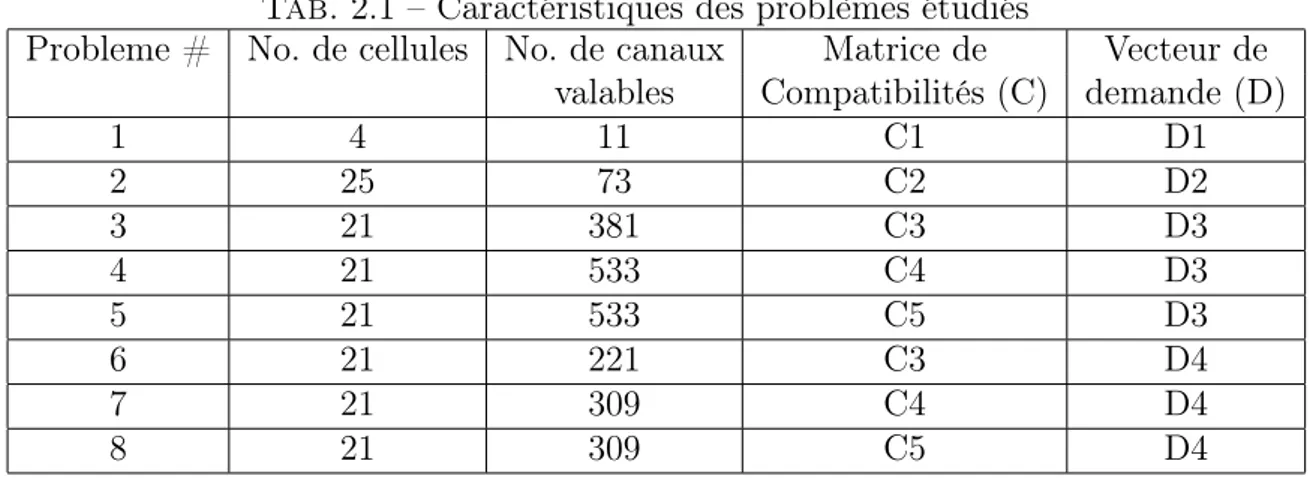
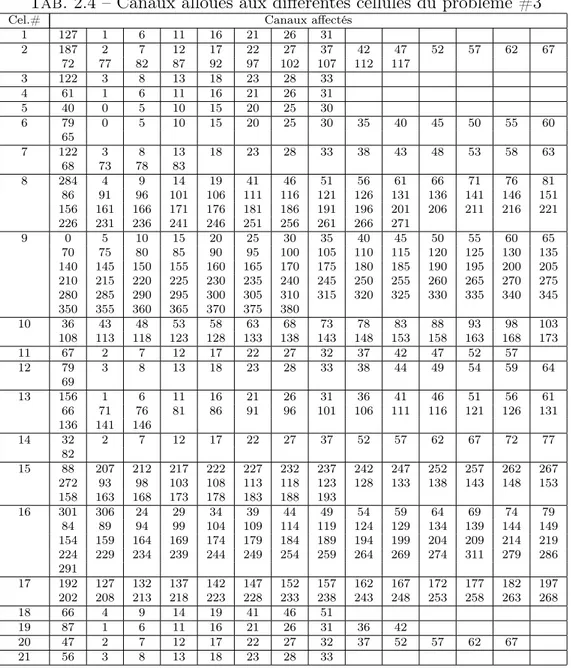
Dans ce cas, la vitesse de référence et le couple de charge mécanique sont définis par des échelons (figures 2.4 et 2.5). La figure (2.8) représente la réponse temporelle de la machine à la vitesse de référence utilisant les trois stratégies de commande (contrôleurs) : le PI conventionnel (figure 2.8(a)), PIGA (figure 2.8(b)) et PIPSO (figure 2.8(c)).
La figure (2.8(a)) montre que le temps de réponse, à la vitesse de référence utilisée, n’est pas atteint en utilisant le contrôleur conventionnel PI. Cependant, la réponse temporelle relative à PIGA est obtenue à l’instant t ≈ 0.222s (figure 2.8(b)) alors que à l’instant t ≈ 0.21s, la réponse en vitesse est atteinte utilisant PIPSO (figure 2.8(c)). Par conséquent, le contrôleur PIPSO est 94% plus rapide que la stratégie de commande PIGA.
Il est clair que la performance du contrôleur PIPSO relative à la réponse en vitesse est meilleure que celles des deux contrôleurs PIGA et du PI conventionnel.
De plus, pour illustrer la performance et l’efficacité du modèle proposé, la figure (2.9) présente la réponse en couples électromagnétiques fournie par ces trois contrô-leurs.
La réponse en couple électromagnétique présentée par la figure (2.9(a)), relative au contrôleur conventionnel PI, montre que les oscillations ne sont pas atténuées durant
(a)
(b)
(c)
(a)
(b)
(c)
![Tab. 2.7 – Comparaison des performances des différentes techniques pour les 8 problèmes Méthodes Problème # 1 2 3 4 5 6 7 8 DPSO # d’itérations 1 5 30 40 55 60 50 60 Taux de 100 100 100 100 100 100 100 100 Convergence% [Cheng et # d’itérations 1 5 3 1 5 8.6 4 5 al, 2005] Taux de 100 100 100 100 100 100 100 100 Convergence% [Alami et # d’itérations 1 2 2 2 2.25 2.75 3.52 4 El Imrani, Taux de 100 100 100 100 100 100 100 100 2008] Convergence% [Funabiki # d’itérations 212 294 147.8 117.5 100.3 234.8 85.6 305.6 et Takefuji, Taux de 100 9 93 100 100 79 100 24 1992] Convergence%](https://thumb-eu.123doks.com/thumbv2/123doknet/2186984.10990/54.892.165.719.311.544/comparaison-performances-convergence-convergence-iterations-convergence-iterations-convergence.webp)