Accuracy Study and Improvement of Network Simulation in the SimGrid Framework
Texte intégral
Figure


Documents relatifs
Theorem 1 allows the robust stability of the global remote system to be guaranteed with respect to the packet dropout and for observer and controller gains given in Seuret et al..
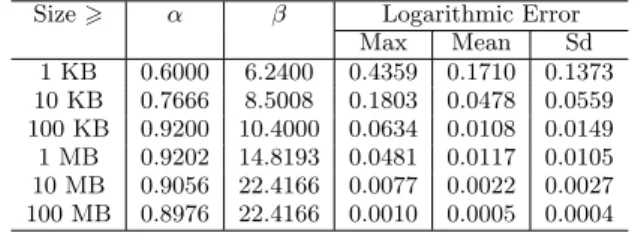
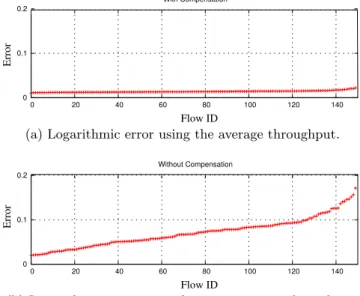
For a specified sample size K, the estimation of the flow network reliability parameter by the standard estimator is the frequency of operating capacity vectors in the set of
the magnetic anisotropy problem which has received considerable attention both theoretically [8] and experimentally [9] : let us consider a 3D Ising magnet with an
In this paper, we analyzed the overheads of lay- ered network protocol in a ULOS and proposed five optimization techniques: user-level signal masking, aggregated system calls,
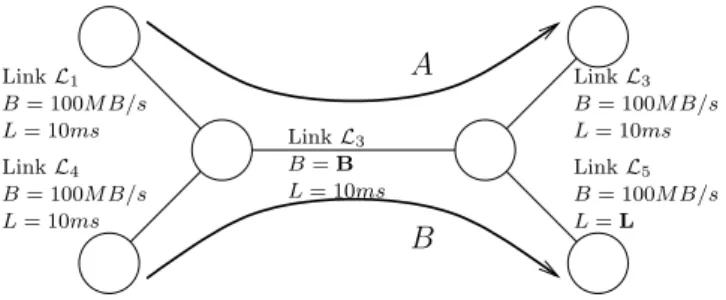
We will conduct a series of experiments with specified parameters and varying the redundancy ratio: L = 10 Mbit/s - bandwidth of the communication channels connecting clients and
Unit´e de recherche INRIA Rennes, Irisa, Campus universitaire de Beaulieu, 35042 RENNES Cedex Unit´e de recherche INRIA Rhˆone-Alpes, 655, avenue de l’Europe, 38330 MONTBONNOT ST
Key-words: distributed systems, performance evaluation, download time, response service time, data distribution, simulation model, max-min fairness.. ∗ INRIA, 2004 Route des
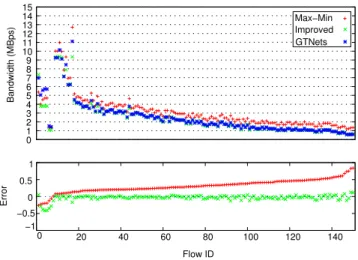
• There are still several cases where a flow with a very small trans- mission time has the same transmission time in both cases (DropTail and FavourTail): (1) it might have only
