Beyond normality: Learning sparse probabilistic graphical models in the non-Gaussian setting
Texte intégral
Figure
Documents relatifs
Figure 20: Cholangiographie rétrograde endoscopique montrant la présence du matériel hydatique dans la voie biliaire principale ;. Figure 21 : Cholangiographie rétrograde
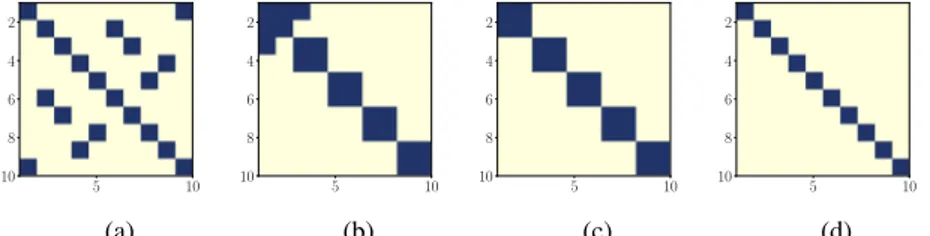
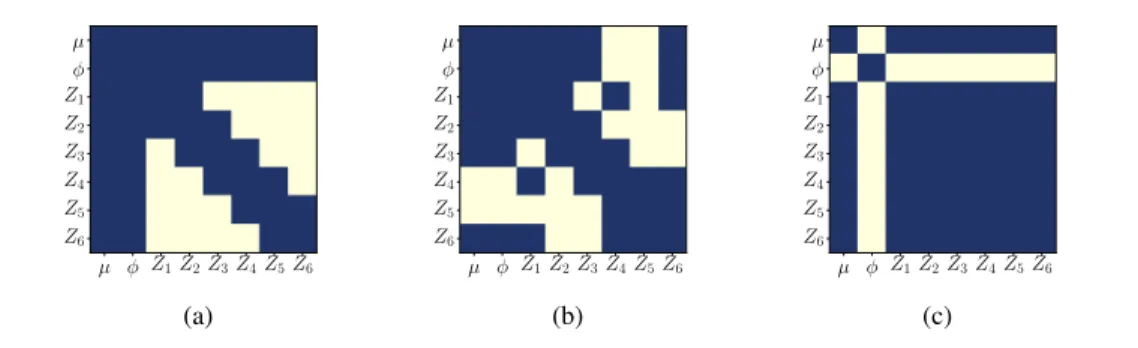
Si les graphes des modèles graphiques non orientés sont caractérisés par les zéros de la matrice de précision, les propositions qui suivent lient le graphe d’un modèle
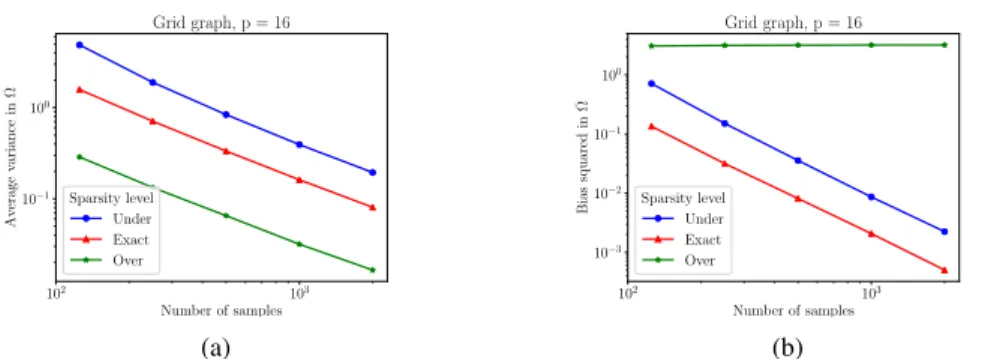
It is an important step for statistical physics since the authors are able to show by explicit calculations that, in two examples of random variables, previously put forward
tau xi precuneus hippocampus entorhinal cortex fusiform gyrus midtemporal lobe amygdala temporal pole insula parahippocampus cortex ventricles ADAS-Cog (multi-domain) RAVLT
Dis autrement, cette deuxième étape consiste donc en une analyse en profondeur de la relation de causalité entre (a) le changement de régime institutionnel
Keywords: Estimator selection, Model selection, Variable selection, Linear estimator, Kernel estimator, Ridge regression, Lasso, Elastic net, Random Forest, PLS1
We first investigate the order of magnitude of the worst-case risk of three types of estimators of a linear functional: the greedy subset selection (GSS), the group (hard and
Recalling that most linear sparse representation algorithms can be straight- forwardly extended to non-linear models, we emphasize that their performance highly relies on an
