Design and Implementation of a System for
MASSACHUSETTS INSTITUTE
Aggregate Internet Traffic Control
OF TECHNOLOGYby
OCT 0 3 2019
Francis
Cangialosi
LIBRARIES
ARCHIVES
Submitted to the Department of Electrical Engineering and Computer Science
in partial fulfillment of the requirements for the degree of
Master of Science in Computer Science and Engineering
at the
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
September 2019
@Massachusetts
Institute of Technology 2019. All rights reserved.
Author ...
Signatureredacted
Department of Electrical Engineering and Computer Science
August 30, 2019
Certified by ...
Signature redacted
Hari Balakrishnan
Fujitsu Chair Professor of Electrical Engineering and Computer Science
Thesis Supervisor
Accepted by
...
Signatureredacted
/ U/ U
Leslie A. Kolodziejski
Professor of Electrical Engineering and Computer Science
Chair, Department Committee on Graduate Students
Design and Implementation of a System for
Aggregate Internet Traffic Control
by
Francis Cangialosi
Submitted to the Department of Electrical Engineering and Computer Science on August 30, 2019, in partial fulfillment of the
requirements for the degree of
Master of Science in Computer Science and Engineering
Abstract
Internet content providers can benefit from applying different scheduling and queue management policies to their traffic. However, they currently lack control over the queues that build up at the bottleneck links in the network to effectively enforce desired policies. To address this issue, we propose a new kind of middlebox, called Bundler, which brings the queues in the network under the content provider's control. Bundler sits at the edge of a sender's domain, and bundles together groups of flows that share a common destination domain. It does rate control for each bundle, such that the queuing induced by its traffic is moved from the bottleneck (wherever it might be in the network) to Bundler itself. This allows the sender to unilaterally enforce its desired scheduling policy across the bundled traffic. Bundler has an immediately deployable, light-weight design, which we implement in only - 1500 lines of code. Our evaluation, on a variety of emulated
scenarios, shows that scheduling via Bundler can improve performance over status quo. Thesis Supervisor: Hari Balakrishnan
Contents
1 Introduction 2 Related Work
2.1 Aggregating congestion information . . . . 2.2 Packet scheduling . . . . 2.3 Split TCP Proxy . . . . 11 15 15 15 16
3 Bundler's Utility Regime 17
3.1 Amount of Aggregation . . . . 17
3.2 Congestion in the middle of the network . . . . 18
3.2.1 Self-inflicted congestion . . . . 18
3.2.2 Congestion due to bundled cross-traffic . . . . 18
3.2.3 Congestion due to un-bundled cross-traffic . . . . 19
3.3 Common bottleneck shared across flows in a bundle . . . . 19 4 Design Overview
4.1 Key Insight . . . . 4.2 Design Choices . . . . 4.2.1 Choice of congestion control algorithm . . . . 4.2.2 Two-sided measurement of congestion signals . . . .
5 Measuring Congestion
5.1 Determining Epoch Boundaries . . . .
5.2 Computing Measurements . . . . 21 21 22 22 23 25 25 26
5.3 ChoosingTheEpochSize. . . . . .. . . .. . . . . 5.4 Microbenchmarks. . . . . 6 Implementation 6.1 Responsibilities . . . . 6.1.1 Sendbox . .. . . .. . ... ... . . . .. 6.1.2 Receivebox . . . . 6.2 Prototype . . . . ... . . . . 6.2.1 Sendboxdataplane . . . . 6.2.2 Sendboxcontrolplane . . . .
6.2.3 Congestion control algorithms . . . . 6.2.4 Receivebox . . . .
6.3 BundlerEventLoop. . . . .
7 Evaluation
7.1 ExperimentalSetup . . . .
7.2 Understanding Performance Benefits . .
7.2.1 Using Bundler for fair queueing
7.2.2 FIFO is not enough . . . .
7.3 Applying Different Scheduling Policies . 7.4 Impact of Congestion Control . . . . 7.4.1 Sendbox congestion control . . 7.4.2 Endhost congestion control . . .
7.5 Impact of Cross Traffic . . . .
7.5.1 Short-lived flows . . . .
7.5.2 Buffer-filling flows . . . .
7.5.3 Competing Bundles . . . .
7.6 Varying Offered Load . . . .
7.7 Terminating TCP Connections... 8 Discussion 28 28 31 31 31 32 32 32 33 33 34 34 37 37 . . . . 38 38 39 40 42 42 42 43 43 44 45 45 . . . . 45 47
List of Figures
1-1 An example deployment scenario for Bundler. The sendbox sits at the sending domain's egress and receivebox sits at the receiving domain's ingress. All traffic between the two boxes is aggregated into a single bundle. The sendbox schedules the traffic within the bundle according to the policy the sending domain specifies
(§4). ... 12
4-1 This illustrative example with a single flow shows how Bundler can take control of queues in the network. The plots show the trend in measured queueing delays at the relevant queue over time. The queue where delays build up can best make scheduling decisions, since it has the most choice between packets to send. Therefore, the sendbox shifts the queues to itself to gain scheduling power. . . 22
5-1 Example of epoch-based measurement calculation. Time moves from top to bottom. The sendbox records the packets that are identified as epoch boundaries. The receivebox, up on identifying such packets, sends a feedback message back to the sendbox, which allows it to calculate the RTT and epochs. . . . . 27
5-2 Bundler's estimate of the delay . . . . 29
5-3 Bundler's estimate of the receive rate. . . . . 30
7-1 Bundler achieves 33% lower median slowdown. The three graphs show FCT distributions for the indicated request sizes: smaller than 10KB, between 10KB and 1MB, and greater than 1MB. Note the different y-axis scales for each group of request sizes. Whiskers show 1.25 x the inter-quartile range. For both Bundler and Optimal, performance benefits come from preventing short flows from queueing behind long ones. . . . . 39
7-2 With FIFO scheduling, the benefits of Bundler are lost: FCTs are 18% worse in the median. Note the different y-axis scales for each group of request sizes. 40
7-3 Bundler with SFQ achieves fair and stable rates. . . . . 41 7-4 Choosing a congestion control algorithm at Bundler remains important, just as
it is at the end-host. Note the different y-axis scales for each group of request sizes. 42
7-5 Bundler still provides benefits when the endhosts use different congestion control algorithm s. . . . . 43
7-6 Against cross traffic comprising of short lived flows. Bundler and the cross traf-fic combined offer 84Mbps of load to the bottleneck queue. The cross traftraf-fic's offered load increases along the x-axis. . . . . 44
7-7 Varying number of competing buffer-filling cross traffic flows. As before, Bundler's traffic offers 84Mbps of load, with one persistently backlogged
con-nection ... 44
7-8 Competing traffic bundles. In both cases, the aggregate offered load is 84Mbps, as in Figure 7-1. For "1:1", we evenly split the offered load between the two Bundles; for "2:1", one bundle has twice the offered load of the other. In both cases, each bundle observes improved median FCT compared to its performance in the baseline scenario. . . . . 45
7-9 Bundler offers diminishing returns with lower amounts of offered load. .... 46
7-10 A proxy-based implementation of Bundler could yield further benefits to the
Chapter 1
Introduction
The vast literature on scheduling and queue management policies [7,9,12,13,30,35,36,40,41, 43,45] has demonstrated their benefits. On many Internet paths, however, content providers and
end users have been unable to enjoy these benefits.
Internet content providers may desire such policies for their traffic. For example, a video streaming company might benefit from weighted fair queueing across its video traffic to its many different users sharing a bottleneck, and web sites might want to prioritize interactive web traffic
(e.g., e-commerce) over the bulk file transfers. However, such policies are effective only when
enforced on bottleneck links that experience a queue build-up, and such links are often outside the control of individual content providers [8,10,29,38]. Content providers are therefore unable
to apply desired policies to their traffic in such settings.
ISPs, on the other hand, do control the bottleneck links in their carrier networks to enforce
different scheduling and queue management policies. However, they neither have enough visibility into their customers' traffic to choose desired policies, nor enough incentives to enforce them.'
Large customers might be able to negotiate deals with certain carriers to enforce specific
poli-cies [3]. However, it might not be possible to negotiate such deals with all carriers in the traffic's path, and content providers may wish to keep their policies confidential from downstream ISPs.
To reduce a content provider's dependence on the ISPs with respect to how its traffic is managed, we attempt to bring the provider's traffic under its own control by moving the queues
'The case for private WANs is different, since they are owned by a single entity, and have, thus, been successful in exploiting the benefits of scheduling [20,21,24]. Our focus is public networks.
b Bunde r's Bunder's
sed Carrier A Carrier B - ''*
Sending Domain Receiving Domain
(say, a large content provider) Public Network (say, an enterprise network)
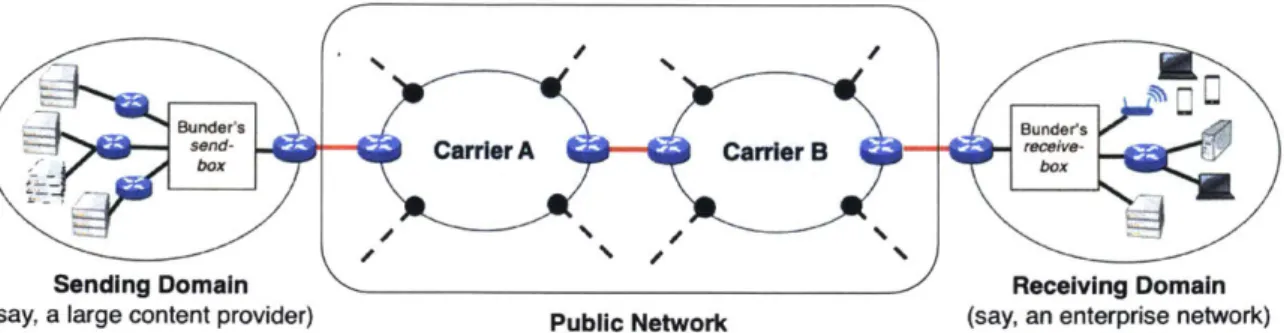
Figure 1-1: An example deployment scenario for Bundler. The sendbox sits at the sending domain's egress and receivebox sits at the receiving domain's ingress. All traffic between the two boxes is aggregated into a single bundle. The sendbox schedules the traffic within the bundle according to the policy the sending domain specifies (§4).
that its traffic would build at a downstream bottleneck to the provider's edge. Our approach allows the content provider to enforce its desired traffic management policies across traffic that share common sender and receiver domains. The natural question that arises is, how can the queues
be "moved"? This is the primary focus of our work.
We observe that the componentflows in traffic from a given sender's domain, destined for
the same downstream domain, are likely to share common bottlenecks within the network, as in Figure 1-1. Examples include large amounts of traffic between a content provider (e.g., Ama-zon, Google, etc.) and a network with many clients (e.g. an enterprise), between two different campuses of an organization, between collaborating institutes, and so on. By (i) aggregating such component flows into a single bundle at the sender's egress, and (ii) controlling the outgoing rate
of this bundle to match its bottleneck rate in the network, we can effectively move the queues
built by the traffic in the bundle, from within the network, to the sender's egress itself.
We propose a new type of middlebox, called Bundler, that (1) aggregates the traffic at the
content provider's egress into appropriate bundles, (2) does rate control for each bundle to move
the corresponding queues from within the network to itself, and (3) applies scheduling and AQM policies within each bundle.
Bundler is made up of a pair of middleboxes: a sendbox that sits at the sender's egress and a receivebox that sits at the receiver's ingress. A bundle is a group of flows traversing the
same sendbox-receivebox pair. The bulk of Bundler's functionality resides at the sendbox, which
coordinates with the receivebox to measure congestion signals, such as the round-trip time, and the rate at which packets are received. These signals are used by a congestion control algorithm
12
(requiring certain properties described in §4) that runs at the sendbox and computes appropriate sending rates for each bundle. The sending rates are computed such that the queuing induced
by the bundled traffic within the network is low and is incurred at the sendbox instead, while
ensuring that the bottleneck link on the path remains fully utilized.
We introduce a lightweight method for the coordination between the sendbox and the receive-box, which does not require any per-flow state, nor any modifications to the packets traversing the Bundler boxes. Our approach only requires introducing the Bundler boxes at the content provider's edge, and requires no changes to the end hosts or to the routers in the network.
Note that our goal is to perform scheduling and queue management only on the traffic within the same bundle. We do not attempt to control traffic across different bundles. Furthermore, as we will discuss in §3, there may be instances where Bundler does not improve performance for the bundled traffic, and falls back to the status quo performance. Despite these limitations, we believe that our work, provides a deployable solution for enabling some of the benefits of scheduling and queue management in the Internet from the edge of the content provider's network.
This thesis makes the following contributions:
1. A light-weight, scalable and deployable design of Bundler that does congestion control
on aggregated traffic to move queues to the content provider's edge (§4).
2. A novel low-overhead protocol-agnostic technique for measuring signals for congestion control between the sendbox-receivebox pair, that does not make any changes to the packet headers (§5). We evaluate our measurement strategy across a variety of RITs and link bandwidths in §5.4.
3. A prototype implementation of Bundler (§6).
4. Evaluation of our prototype implementation on a wide variety of emulated scenarios with a demonstration of performance benefits achieved from scheduling traffic via Bundler (§7). In a scenario with self-inflicted scheduling overhead, Bundler achieves 33% lower median slowdown.
Chapter 2
Related Work
This thesis lies at the intersection of the topics of congestion control, packet scheduling, and
middleboxes, each of which have a large body of prior work. We identify the most relevant pieces of prior work in each of these areas below.
2.1
Aggregating congestion information
A recent proposal [39] observes that the majority of today's traffic is owned by a few entities. This
observation implies that we can expect to have a small number of bundles across the Internet, each with large amounts of traffic, resulting in greater scheduling opportunities within a bundle. Note
that the proposal uses its observation to highlight the benefits of sharing information across a given
customer's traffic when configuring congestion control algorithms at the endhosts. This is orthogo-nal to our goal of scheduling such traffic by introducing a middlebox without modifying end hosts.
2.2 Packet scheduling
There have been some recent efforts towards enabling the benefits of packet scheduling. PIFO [42]
is a programmable priority queue that can be configured to express different scheduling policies at routers. However, not only does it require changing the in-network routers, but it also suffers from the issue of an ISP's limited visibility into the traffic to choose desired policies (and limited
the edge via header initialization, but also requires a change to the routers. Bundler provides a solution that does not require any cooperation from downstream networks in other organizations. In that spirit, Bundler is closer to OverQoS [44]. Proposed more than a decade ago, OverQoS aimed to provide QoS benefits in the Internet by aggregating and managing traffic at the nodes of an overlay network [I]. Given the aggregation opportunities today, where a few content providers generate a majority of the Internet traffic [39], we observe that the time for reaping benefits from such designs may have arrived. Recent trends enable a simpler and more deployable approach; instead of deploying an overlay network, Bundler proposes deploying a middlebox at the sending and the receiving domains to aggregate sufficient traffic. In addition, Bundler provides a novel mechanism to move the in-network queues, and gain the power to schedule the bundled traffic.
2.3 Split TCP Proxy
This middlebox splits the TCP connections traversing it, such that the senders observe a smaller round-trip time and can increase their sending rate faster. Since it terminates and re-establishes TCP connections, it requires implementing a full TCP stack, managing per-connection state and intrusively changing the packet headers. Again, Bundler has orthogonal goals, which allow for a lightweight design without requiring any per-connection state (unless needed for a specific
scheduling algorithm) or any modifications to the packets traversing it. We show how combining Bundler's features with a TCP Proxy could lead to further improvements in performance in §7.7.
Chapter 3
Bundler's Utility Regime
Figure 1-1 provides an example scenario for deploying Bundler. The sending domain (depicted as a large content provider) deploys Bundler's sendbox at its egress to the public network, while
the receiving domain (depicted as an enterprise network) deploys the receivebox at its ingress.'
All traffic between the sendbox-receivebox pair is aggregated into the same bundle. 2 The sendbox
moves the in-network queues built by the bundled traffic to itself (as described later in §4). It can thus enforce desired scheduling policies across the traffic in the bundle. The performance benefits
that this provides are dictated by the following.
3.1 Amount of Aggregation
The amount of aggregated traffic in a bundle correlates with the scheduling opportunities within it, thus influencing the performance benefits that Bundler provides. So a natural question is, would
a given bundle have sufficient traffic in practice to make a Bundler deployment beneficial? Past observations indicate a positive response to this question, since a majority of Internet traffic today
is owned by a few large content providers who host a wide array of services [27,39]. In our example scenario, a bundle might be comprised of large amounts of traffic generated by various
services (such as email, messaging, video conferencing, video streaming, cloud storage etc.) hosted by the content provider and used by different clients within the enterprise.
'We use these specific examples of sending and receiving domains for simplicity of discussion. Similar arguments would also hold for other deployment scenarios (such as those exemplified in §1).
2
3.2 Congestion in the middle of the network
Customers already have control over queues that are built within their own domains [20,21,24]. Bundler, therefore, provides benefits when congestion occurs, and queues build up, in the middle of the network (i.e. between a sendbox-receivebox pair). So the next question that arises is, does such in-network congestion occur in practice? A recent measurement study [10] indicates that inter-domain links in the network (depicted in red in Figure 1-1) can indeed experience significant congestion. We briefly discuss how the source of this congestion influences Bundler's benefits (and provide detailed results in §7).
3.2.1
Self-inflicted congestion
This occurs when traffic from a single bundle causes a queue to build up at the bottleneck links in the network, even without any other cross-traffic. It can happen when a small carrier network does not have enough capacity to sustain the large volume of traffic sent by a content provider to a receiving domain, or due to explicit rate limiting commonly done by ISPs [8,29,38]. In such cases, Bundler can result in significant improvements in performance, as it would then have control over the entire queue.
3.2.2
Congestion due to bundled cross-traffic
In-network congestion can further increase in the presence of other cross-traffic (e.g., when the peering link between Carrier B and the enterprise in Figure 1-1 is shared by traffic from multiple sending domains). Bundler continues to provide benefits when such competing flows also belong to bundles created by the sendboxes deployed in other domains; the rate control algorithm at each of these sendboxes would ensure that the in-network queues remain small, and appropriate scheduling policy would be applied to the per-bundle queues built at the sendboxes. We expect this to become common, as Bundler's popularity increases.
3.2.3
Congestion due to un-bundled cross-traffic
We now consider the scenario where the cross-traffic includes flows from domains that have not yet deployed a Bundler. If all such un-bundled competing flows are short-lived (up to a few MBs), the bundled traffic still sees significant performance benefits. However, if the cross traffic includes a persistent backlogged flow that aggressively fills up any available buffer space at the bottleneck link, then, in order to compete fairly, Bundler would push more packets into the network (as described in §6.2), thus relinquishing its control over the bundled traffic and falling back to the status quo performance. Such flows are unlikely to arrive very frequently [5].
3.3
Common bottleneck shared across flows in a bundle
Bundler's design for moving queues is most effective when the component flows within a bundle share in-network bottlenecks. We expect this to hold true in most deployment scenarios. As discussed above, in-network congestion primarily occurs at inter-domain links. Therefore, even if an ISP does load balancing for its core, the inter-domain links are still likely to be shared by the flows having common sending and receiving domains.Hence, while there can be certain situations where Bundler fails to provide any benefits, there are also many scenarios where it can significantly improve performance. This, combined with its deployment ease, makes a strong case for deploying Bundler.
Chapter 4
Design Overview
Recall that in order to do scheduling, we need to move the queues from the network to the Bundler. In this chapter, we first describe our key insight for moving the in-network queues, and
then explain our specific design choices.
4.1
Key Insight
A trivial strategy for inducing queuing at the Bundler is to throttle its outgoing rate. However,
if this rate is made smaller than the bundle's share of bandwidth at the bottleneck link in the
network, it can decrease throughput. Instead, the rate needs to be set such that the bottleneck link sees a small queue while remaining fully utilized (and the bundled traffic competes fairly in
the presence of cross traffic). We make a simple, but powerful, observation: existing congestion control algorithms [2,16] perform exactly this calculation. Therefore, running such an algorithm
at the sendbox to set a bundle's rate would reduce its self-inflicted queue at the bottleneck, shifting it to the sendbox instead, without impacting aggregate throughput. Note that each end host would
continue running its default congestion control algorithm [6,17], as before, which would now react to the queue build up and packet drops incurred at the sendbox.
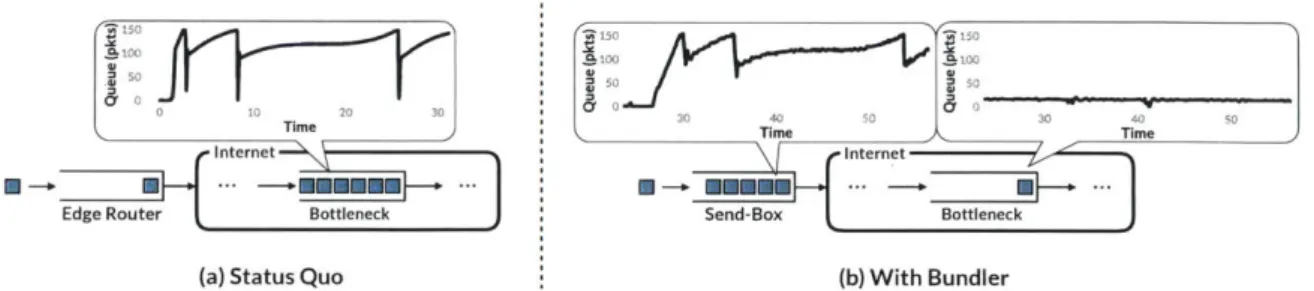
Figure 4-1 illustrates this method for a single flow traversing a bottleneck link in the network. Without Bundler, packets from the end hosts are queued in the network, while the queue at the edge is unoccupied. In contrast, a Bundler deployed at the edge is able to shift the queue to its sendbox.
11 5 IS r --- -+-E M -- --- -o n
---~50~u u 50 50
0 0 Time 20 30 40 0 0 30 50
Time Time
InternetInternet
Edge Router Bottleneck Send-Box Bottleneck
(a) Status Quo (b) With Bundler
Figure 4-1: This illustrative example with a single flow shows how Bundler can take control of queues in the network. The plots show the trend in measured queueing delays at the relevant queue over time. The queue where delays build up can best make scheduling decisions, since it has the most choice between packets to send. Therefore, the sendbox shifts the queues to itself to gain scheduling power.
4.2 Design Choices
Our design choices were guided by our key requirement of deployment and management ease.
They provide the following properties:
1. Bundler requires no changes to the endhosts or to the routers in the network, making it
independently deployable.
2. Bundler maintains only per-bundle state, and no per-connection state (unless needed by
a specific scheduling algorithm), allowing it to scale trivially with the number of in-bundle connections.
3. The only persistent state maintained in the Bundler is the network condition (in the form of congestion signals) which can be naturally re-aquired, thus making it crash-resistant.
4. Bundler makes no changes to the headers of the packets traversing it, ensuring no
inter-ference with other networking components in a packet's path [14, 19,28].
We discuss specific design choices in more details below.
4.2.1
Choice of congestion control algorithm
The congestion control algorithm that Bundler runs at the sendbox must satisfy the following constraints:
1. Ability to limit network queueing. A loss-based congestion control algorithm is not a good
choice for Bundler, since it would build up a queue at the bottleneck until a packet drop
occurs, thus defeating our primary purpose. An ECN-based algorithm is also not an option with unmodified network routers. This makes delay-based algorithms (i.e., those that focus
on changes in the round-trip time (RTT)) the ideal choice.
2. Detection of buffer-filling cross-traffic It is well-known that RTT-based schemes compete poorly with buffer-filling loss-based schemes [2,16,32]. Therefore, Bundler's congestion control must have a mechanism to detect the presence of a competing buffer-filling flow,
and fall back to status quo performance.
Among the existing congestion control algorithms, Copa [2] and Nimbus [16] best satisfy the above requirements.
4.2.2
Two-sided measurement of congestion signals
Congestion control algorithms require network feedback from the receivers to measure congestion and adjust the sending rates accordingly. Conventional endhost-based implementations have used TCP acknowledgements for this. However, this is not a good option for Bundler because: (i) it is incompatible with UDP, which is commonly used by video streaming applications, and (ii) it requires the reverse traffic to also pass through Bundler's sendbox, which may not always be the case. Instead, Bundler's two-sided design allows measurement of congestion signals to be conducted solely between a sendbox-receivebox pair. We highlight the key features of our two-sided measurement technique below, and describe it in more detail in §5.
1. Out-of-bandfeedback. The receivebox sends explicit out-of-bandfeedback messages to
the sendbox, which are used for measuring congestion signals. This out-of-band feedback mechanism is not only agnostic to the underlying protocol (be it TCP or UDP), but also side-steps the issue of enforcing that TCP acknowledgements pass through the same sendbox.
2. Infrequent measurements. Sending an out-of-band feedback message for every packet
arriving at the receivebox would result in high communication overhead. Furthermore, conducting measurements on every outgoing packet at the sendbox would require main-taining state for each of them, which can be expensive, especially at high bandwidth-delay products. We, therefore, conduct measurements on a few sampled packets, at least once per RTT, which is sufficient for most congestion control algorithms [33].
3. Independent sampling. The sendbox and receivebox need to agree upon the set of sampled
pack-ets for which the receivebox generates feedback and the packpack-ets for which the sendbox maintains state). It is tempting to simply mark such packets at the sendbox. However, past studies [14,19,28] have shown how such strategies may fail in practice, as many deployed middleboxes have a tendency to drop or re-write packets with unfamiliar header fields. In the following section, we describe our technique to sample packets solely based on the hash computed over certain fields in the packet header, which allows the sendbox and the receivebox to independently sample the same set of packets.
Chapter 5
Measuring Congestion
Bundler measures network congestion signals (RTT and packet arrival rates) over the duration
(or epochs) between infrequently sampled packets (that we call epoch boundary packets). In this section, we describe our strategy for independently sampling the same set of epoch boundary
packets at the paired Bundler boxes, and for measuring congestion signals using them. We end with an evaluation showing the accuracy of our approach.
5.1
Determining Epoch Boundaries
Suppose the desired epoch size, i.e. the number of packets between two epoch boundary packets, is N. A naive strategy for determining common epoch boundaries at the sendbox and the
receive-box, without making any changes to the packet headers, would be to simply sample a packet after every N packets. However, any packet loss in the network would then desynchronize the
sampling at the two boxes. Another alternative is for the sendbox to explicitly send out-of-band messages to the receivebox indicating which packets are to be sampled. However, there is no
guarantee that these messages would arrive at and be processed by the receivebox before the indicated packets arrive themselves.
Our technique side-steps these issues by using the contents of a packet to sample epoch boundaries. More specifically, a packet is sampled as a boundary for an epoch of size N, if the hash over a subset of its fields is a multiple of N. Therefore, given sufficient entropy in the hashed
The combination of selected packet fields over which the hash is computed can vary across different deployments, but it must satisfy the following requirements:
1. It must be the same at both the sendbox and the receivebox. More specifically, its
val-ues must remain unchanged as a packet traverses the network from the sendbox to the receivebox (so, for example, the TTL field must be excluded).1
2. It differentiates individual packets (and not just flows), to allow sufficient entropy in the computed hash values.
3. It also differentiates a retransmitted packet from the original one, to prevent spurious
samples from disrupting the measurements (this precludes, for example, the use of TCP sequence number).
One possible combination of fields that satisfy all of the above requirements (and that we use in our prototype implementation described in §6) is: source IP, source port, and IP ID. The main scenario in which the IP or port of packets may be changed along the path is network address trans-lation. However, this is typically performed within the network, meaning it is under the control of the same network operator who is deploying Bundler. This situation can be avoided by delpoying Bundler closer to the edge of the network than any middleboxes that may modify packets.
5.2
Computing Measurements
Given our technique to identify epoch boundaries, it is straight-forward to measure congestion signals, as illustrated in Figure 5-1. For each bundle, the sendbox tracks the total number of bytes sent within this bundle, and, upon identifying an epoch boundary packet, pi, it records: (i) its hash, h(pi), (ii) the time when it is sent out, tsent(pi), and (iii) the total number of bytes sent thus
far including this packet, bsent(pi).
The receivebox similarly tracks the total number of bytes received for each bundle. Upon the arrival and identification of the epoch boundary packet pi, it immediately sends a feedback message to the sendbox containing: (i) its hash, h(pi), (ii) the time when it was received, trec, (pi),
and (iii) the total number of bytes received thus far including this packet, brec (pi).
'Certain fields, that are otherwise unchanged within the network, can be changed by NATs deployed in a customer's domain. Ensuring that the Bundler boxes sit outside the NAT would allow them to make use of those fields.
sendbox
receivebox
Send
P; Epoch
RTT
nowIraffic
-p
Feedback
••••* I~Figure 5-1: Example of epoch-based measurement calculation. Time moves from top to bottom. The sendbox records the packets that are identified as epoch boundaries. The receivebox, up on identifying such packets, sends a feedback message back to the sendbox, which allows it to calculate the RTT and epochs.
Upon receiving the feedback pi, the sendbox records the received information, and using its previously recorded state, it can compute the RTT and the rates at which packets are sent and received, as below:
RTT=
sendrate=
recvrate=
now -tsent (Pi)
bsent(pi) - bsent(Pi-1)
tsent(Pi) -tsent (pi_1) brecv (pi) -brecv(Pi-1)
trecv(Pi) - trecv(Pi_-1 )
Finally, the sendbox clears the recorded state of all epoch boundaries preceding pi.
Note that our measurement technique is robust to a boundary packet being lost between the sendbox and the receivebox. In this case, the sendbox would not get a feedback for the lost bound-ary packet, and it would simply compute rates for the next boundbound-ary packet over a longer epoch.
27 treev(Pi-1) • recv(Pi) (5.1a) (5.1b) (5.1c) tIsent(Pi-1) Asent i .,. ....••••
Recv
...---
Epoch
...-- 01a5.3
Choosing The Epoch Size
In §5.1, we assumed a fixed epoch size of N packets. However, in practice, epochs must be such that measurements are collected at least once per RTT [33]. Therefore, for each bun-dle, we track that minimum observed RTT (rinRTT) at the sendbox and set the epoch size
N =(0.25 x minRTT x send-rate), where the sendrate is compute as described above. The
final rates passed to the congestion control algorithms at the sendbox are then computed over a sliding window of epochs that corresponds to one RTT. Averaging over a window of multiple epochs also increases resilience to possible re-ordering of packets between the sendbox and the receivebox, which can result in them seeing different number of packets between two epochs.
When the sendbox updates the epoch size N for a bundle, it needs to send an out-of-band message to the receivebox communicating the new value. To keep our measurement technique resilient to potential delay and loss of this message, the epoch size N is always rounded down to the nearest power of two. Doing this ensures that the epoch boundary packets sampled by the receivebox are either a strict superset or a strict subset of those sampled by the sendbox. The sendbox simply ignores the additional feedback messages in former case, and the recorded epoch boundaries for which no feedback has arrived in the latter.
5.4
Microbenchmarks
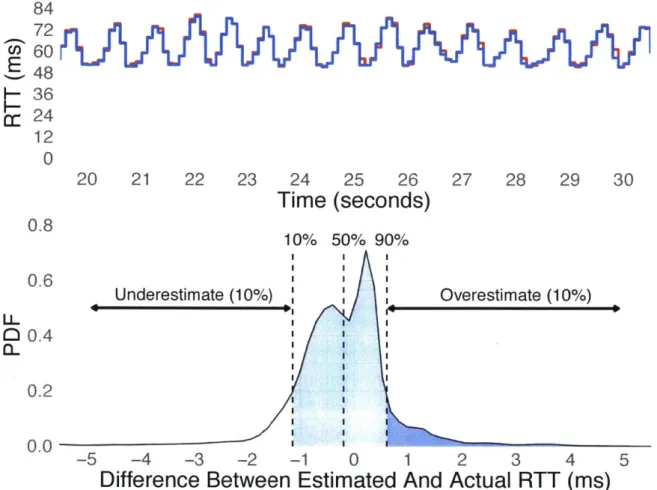
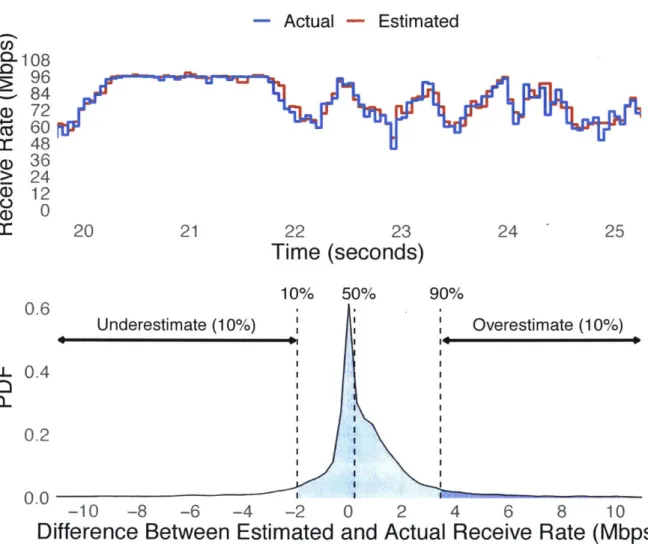
We now evaluate the accuracy of our technique and its robustness to various network conditions. We pick 90 traces of Bundler's measurements from experiments in our evaluation across a range of RTTs (20ms, 50ms, 100ms) and bottleneck rates (24Mbps, 48Mbps, 96Mbps) and compute the difference between our measured value of the RTT and receive rate at each time step compared to the values at the bottleneck router. We plot the distribution of these differences for all of the traces in Figure 5-2. 80% of our RTT estimates are within 1.2ms of the actual value and 80% of our receive rate estimates are within 4Mbps of the actual value.
To visualize how these measurements impact the behavior of the signals over time we pick an experiment for which the median difference matches that of the entire distribution and plot afive second segment of our estimates compared to the actual values in Figure 5-3.
- Estimated - Actual 84 72 C2) 60 E48 1-36 24 12 0 20 21 22 23 24 25 26 27 28 29 30
Time (seconds)
0.8 10% 50% 90% 0.6 Underestimate (10%) Overestimate (10%) LL 00.4 0.2 0.0 -5 -4 -3 -2 -1 0 1 2 3 4 5Difference Between Estimated And Actual RTT
(ms)
Figure 5-2: Bundler's estimate of the delay
- Actual - Estimated 22 23
Time (seconds)
10% 50% Underestimate (10%) I I I I I I I 4-I I I I I I I I I I I I I I I I I I I I I I I I I I I I t Overestimate (10%) -10 -8 -6 -4 -2 0 2 4 6 8 10Difference Between Estimated and Actual Receive Rate (Mbps
Figure 5-3: Bundler's estimate of the receive rate.
108 96 84 ) 72
1C
60 0[ 48 a 3 6 > 24 W 12 o 0 20 21 0.6 24 25 90% LL 0. 4 0 CL 0.2 00 WiChapter 6
Implementation
6.1
Responsibilities
Our design of Bundler leverages two middleboxes, an sendbox that sits at the edge of the sender's domain and an receivebox at the sits at the edge of the receiver's domain. We first describe the responsibilities of each box and the space of choices for implementation. Then we describe the specific choices we made for our prototype implementation evaluated in the following sections, however we note that different deployment scenarios may require slightly different choices.
6.1.1
Sendbox
The sendbox is further comprised of two components: a data plane and a control plane. The data plane is responsible for:
1. packet forwarding
2. tracking the number of sent bytes
3. identifying and reporting the epoch boundary packets to the control plane
4. enforcing a sending rate (computed by the control plane) on a bundle
5. enforcing the desired scheduling policies for a bundle.
It can implemented in software [18,22,23,26,37], or in programmable hardware [4]. The control plane is responsible for:
the feedback from the receivebox
2. computing and communicating epoch sizes
3. running the congestion control algorithm for each bundle to compute appropriate sending
rates based on the measured congestion signals.
Our decision to split the functionality into these two components builds on prior work on the design of a congestion control plane [33], which shows that it is possible to move the core logic of congestion control to a separate component off of the data path (e.g., the Linux kernel) and maintain good performance without requiring frequent communication. As a result, regardless of where the data plane is implemented, it makes the most sense to keep the implementation of the control plane in software, since moving it to hardware will not help performance and would only limit programmability.
6.1.2
Receivebox
The receivebox is responsible for:
1. tracking the number of received bytes
2. receiving and updating epoch size values
3. identifying epoch boundary packets and sending corresponding feedback messages to the
sendbox
Similar to the sendbox's data plane, it could also be implemented in either software or hardware. In both cases, the only part of the design that may not be fixed is the choice of header fields used to sample packets and compute measurements.
6.2 Prototype
We now describe our prototype implementation choices for each box.
6.2.1
Sendbox data plane
We implement it using Linux t c [26]. We patch the TBF queueing discipline (qdisc) [25] in the
con-trol plane using a netlink socket. We use the FNV hash function [15], a non-cryptographic fast hash function with a low collision rate, to compute the packet content hash for identifying epoch bound-aries. We also patch TBF's "inner-qdisc" to internally use any of the other queueing disciplines implemented in the Linux kernel for scheduling, including SFQ [30], FQ-CoDel [11] and strict pri-oritization, in addition to the default FIFO. By default, the Linux implementation of TBF instanta-neously re-fills the token bucket when the rate is updated; we disable this feature to avoid rate fluc-tuations caused by our frequent rate updates. Our patches to the TBF qdisc comprise 112 lines of C.
6.2.2
Sendbox control plane
We implement the control plane of the sendbox as a user-space application in 1167 lines of Rust. We use CCP [33] to run different congestion control algorithms (described next). CCP is a platform for expressing congestion control algorithms in an asynchronous format, which makes it a natural choice for our epoch-based measurement architecture. The control plane uses libccp [33] to interface with the congestion control algorithm, and libnl to communicate with the qdisc.
6.2.3
Congestion control algorithms
We use existing implementations of congestion control algorithms (namely, Nimbus [16], Copa [2] and BBR [6]) on CCP to compute sending rates at the sendbox. If the algorithm uses a congestion window, the sendbox computes an effective rate of cwNDand set it at the qdisc. We validated that our implementation of these congestion control schemes at the sendbox closely follows their implementation at an endhost.
The sendbox also leverages a recently proposed technique [16] to detect persistent buffer-filling flows. Its basic idea is to use short-timescale pulses to create traffic fluctuations at the bottleneck link, and measure if the cross traffic changes its rate in response to these fluctuations; if it does, it indicates the presence of long-running TCP flows that react to bandwidth variations. When such flows are detected, the sendbox starts pushing traffic at an increased rate, set to the
observed received rate plus a probe factor. Sending faster than the receive rate ensures that the rate of the sendbox eventually exceeds the offered load, thus draining any queue at the sendbox. This, in turn, allows the congestion control algorithms at the unmodified endhosts to compete
with the buffer-filling flow, as they would without a Bundler. The additive probe factor is set in our implementation to one-sixteenth of the maximum receive rate seen so far.
6.2.4
Receivebox
We implement the receivebox as auser-space application in 188 lines of Rust. It uses libpcap to monitor the headers of all packets on the incoming interface and maintains counters of the number of bytes that have passed through the bundle thus far. When it finds a packet header whose hash meets the epoch boundary condition, it sends a feedback message to the sendbox including these current counter values.
We use libpcap for simplicity of both implementation and deployment. In all of our experiments up to 1Gbps it is able to maintain line rate and does not affect performance in any way. However, at higher rates, this implementation may not be sufficient and it may be necessary to instead use a split implementation similar to the sendbox, where the packets are examined within the kernel and only sent to user-space if they meet the epoch boundary condition.
6.3 Bundler Event Loop
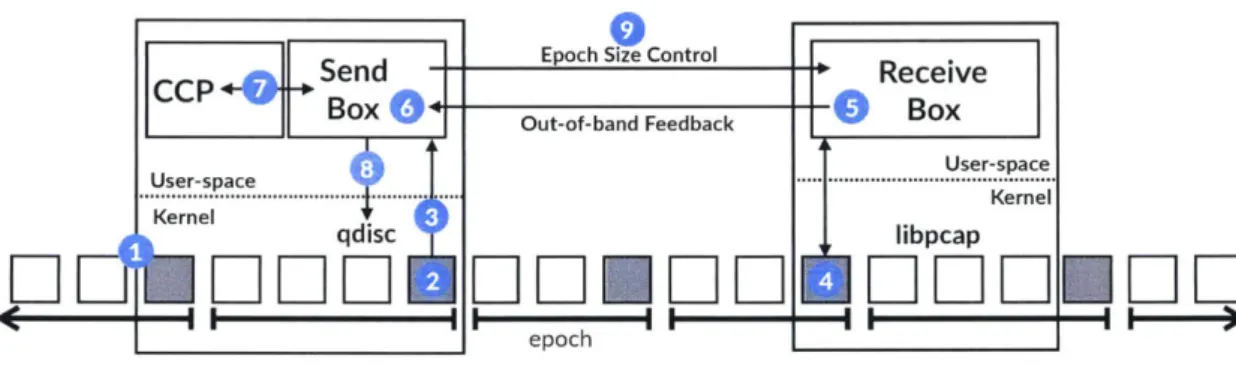
Figure 6-1 provides an overview of how our Bundler implementation operates.
1. Packets arriving at the sendbox are sent to the qdisc. Those that match a bundle are put
into the proper queue, otherwise they are forwarded immediately.
2. The qdisc determines whether a packet matches the epoch boundary condition (§5.1).
3. If so, it sends a netlink message to the control plane process running in user-space, and
then forwards the packet along. The control plane process records the epoch boundary packet (§5.2).
4. The receivebox observes the same epoch boundary packet.
5. It sends an out-of-band UDP message to the sendbox that contains the hash of the packet
and its current state.
6. The sendbox receives the UDP message, and uses it to calculate the epochs and
7. Asynchronously, the sendbox control plane invokes the congestion control algorithm every
lOms [33] via libccp,
8. The sendbox control plane communicates the rate, if updated, to the qdisc using 1ibn1. 9. Finally, if the sendbox changes the desired epoch length based on new measurements, it
Epoch Size Control Out-of-band Feedback
epoch
Figure 6-1: Bundler Implementation Overview.
36
I
Send CCP B+xO Box User-spacee... .. Kernel qdiSCEZn',
Receive Box User-space Kernel libpcapChapter 7
Evaluation
Given Bundler's ability to move the in-network queues to the sendbox (as shown earlier in Figure 4-1), we now explore:
1. Where do Bundler's performance benefits come from? We discuss this in the context of
improving the flow completion times of Bundler's component flows. (§7.2) 2. Can Bundler enforce different scheduling policies? (§7.3)
3. Do Bundler's performance benefits hold across different scenarios? (§7.5)
7.1
Experimental Setup
We evaluate our implementation of Bundler (discussed in §6) using network emulation via mahimahi [34]. Mahimahi creates a Linux network namespace and applies the configured
network condition (emulated delay or link bandwidth) to all packets that traverse it.
There are three 8-core machines in our setup: one machine is a sender, another is configured
as a middlebox and runs a sendbox, and a third is the receiver. The receivebox runs on the same machine as the receiver, inside the same mahimahi network namespace as the receiving
application. Our prototype requires that the sending application and the sendbox run on different machines, to prevent TCP small queues (TSQ) from interfering with the queuing behaviour that one would expect in areal deployment. Since our receivebox implementation uses libpcap,
GRO would change the packets before they are delivered to the receivebox, which would cause inconsistent epoch boundary identification between the two boxes. We, therefore, disable TSO
and GRO. Throughout our experiments, CPU utilization on the machines remained below 10%. Unless otherwise specified, we emulate the following scenario. A many-threaded client generates requests from a request size CDF drawn from an Internet core router [5], and assigns them to one of 200 server processes on the traffic generator. The workload is heavy-tailed: 97.6% of requests are 10KB or shorter, and the largest 0.002% of requests are between 5MB and 100MB. Each server then sends the requested amount of data to the client and we measure the flow completion time of each such request. In addition, the server also generates a persistently backlogged connection to the client. The link bandwidth at the mahimahi link is set to 96Mbps, and the one-way delay is set to 25ms. The requests result in an offered load of 84Mbps.
The endhost runs Cubic [17] congestion controller, and the sendbox runs Copa [2] (we test other schemes in §7.4). The sendbox schedules traffic using stochastic fair queueing [30] in our experiments by default (we use other policies in §7.3). Each experiment is comprised of 100,000 requests sampled from this distribution, across 10 runs each with a different random seed.
7.2
Understanding Performance Benefits
We first present results for a simplified scenario without any cross-traffic, i.e. all traffic traversing through the network is generated by the same customer and is, therefore, part of the same bundle. This scenario highlights the benefits of using Bundler when the congestion on the bottleneck link in the network is self-inflicted. We explore the effects of congestion due to other cross-traffic in §7.5.
7.2.1
Using Bundler for fair queueing
In this section, we evaluate the benefits provided by doing fair queuing at the Bundler, and use median slowdown as our metric, where the "slowdown" of a request as its completion time divided by what its completion time would have been in an unloaded network. A slowdown of 1 is optimal, and lower numbers represent better performance.
We evaluate three configurations: (i) The "Status Quo" configuration represents the status quo: the sendbox simply forwards packets as it receives them, and the mahimahi bottleneck uses
FIFO scheduling. (ii) The "In-Network" configuration deploys fair queueingi at the mahimahi
Small
Medium
Large
<
10KB
10KB
- 1MB
> 1MB
4 5 4 12 0 3 8 22 4*
Status Quo*
Bundler*
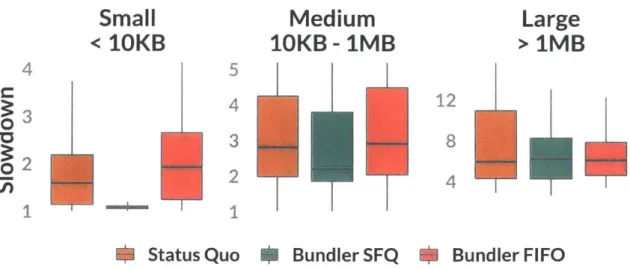
In-NetworkFigure 7-1: Bundler achieves 33% lower median slowdown. The three graphs show FCT distributions for the indicated request sizes: smaller than 10KB, between 10KB and 1MB, and greater than 1MB. Note the different y-axis scales for each group of request sizes. Whiskers show 1.25x the inter-quartile range. For both Bundler and Optimal, performance benefits come from preventing short flows from queueing behind long ones.
bottleneck. Recall from §I that this configuration is not enforced in practice. (iii) The default
Bundler configuration, that uses stochastic fair queueing [30] scheduling policy at the sendbox.
Figure 7-1 presents our results. As is expected from the use of fair queuing, Bundler is able
to achieve significant reductions in the slowdown for short flows, followed by some reduction for medium-sized flows, and similar performance for large flows. The median slowdown decreases
from 1.62 for Baseline to 1.08 with Bundler: 33% lower.
Furthermore, Bundler's performance is close to In-Network. Both Bundler and In-Network
achieve an identical median slowdown of 1.08. In-Network provides better performance in the
tail: the 99%ile slowdown is 4.46 for "In-Network" and 9.84 for Bundler. Meanwhile, the Status Quo achieves a 99%ile slowdown of 10.77.
7.2.2 FIFO is not enough
It is important to note that Bundler by itself (i.e. running FIFO scheduling) is not a means of
achieving improved performance. despite doing aggregated congestion control across all flows
in a bundle. To see why this is the case, recall that Bundler does not modify the endhosts: they
Medium
10KB - 1MB
Large
>
1MB
12Small
<
10KB
8 4*
StatusQuo
*
BundlerSFQ
1
BundlerFIFO
Figure 7-2: With FIFO scheduling, the benefits of Bundler are lost: FCTs are 18% worse in the median. Note the different y-axis scales for each group of request sizes.
continue to run the default Cubic congestion controller, which will probe for bandwidth until it
observes loss. Indeed, the packets endhost Cubic sends beyond those that the link can transmit must be queued somewhere in the network or get dropped. Without Bundler, they get queued up at the bottleneck link. With Bundler, they instead just get queued up at the sendbox. In addition, the congestion controller at sendbox also maintains a small standing queue at the bottleneck link
(which can be seen in Figure 4-1) to avoid under-utilization, which increases the end-to-end-delays slightly. Therefore, doing the FIFO scheduling at the Bundler, as is done by the Status Quo, results in slightly worse performance (shown in Figure 7-2).
7.3
Applying Different Scheduling Policies
We demonstrate that, in addition to improving flow completion times, our implementation of Bundler can achieve low packet delay, perform strict prioritization, and rate fairness.
Achieving Improved Flow Completion Times. §7.2 shows how enabling SFQ at the Bundler improves the median slowdown by 33%.
Achieving Low Packet Delays. We enable CoDel [11] at the sendbox, to lower the packet delays,
and test it for a single large backlogged flow, using the setup described in §7. We measure the
distribution of RTTs seen by the endhost connections with Bundler and Status Quo.
4
002
py
5 4 3 2 1100 75 50 25
fo~
0
o0:E100 $ 75 |- 50 25 0 Bundler Status Quo 0 20 40 60Time (s)
Figure 7-3: Bundler with SFQ achieves fair and stable rates.
Median RTT 4.25 122.2 99%ile RTT 15.32 151.53
As is expected from CoDel, Bundler in this experiment, achieves 97% lower median packet delay than Status Quo.
Strict Prioritization. We uniformly divide the web request distribution described in §7.1 into two classes, one of which is given a higher priority over the other. The results are presented below.
Scheme Bundler (Prio.) Bundler (SFQ) Status Quo
Median Slowdown Ij99%ile Slowdown
1.07 1.1 3.07 10.52 19.85 201.72
Using a priority scheduler at sendbox improves the flow completion times for the higher-priority class when compared to Status Quo. Furthermore, prioritization achieves 47% lower 99%ile FCT for the higher priority traffic class, when compared to using fair queueing instead.
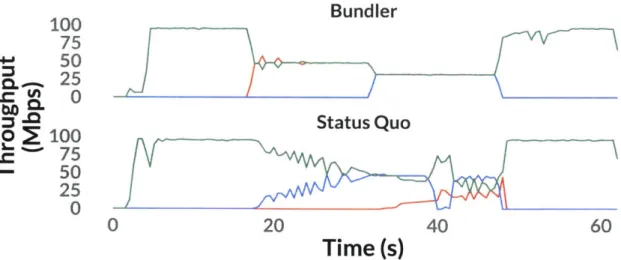
Rate Fairness and Stability. We next use our default SFQ scheduler to achieve fairness and rate
stability. We start three backlogged flows at different times (Os, 15s, and 30s). Figure 7-3 shows that Bundler converges to fair and stable rates faster than the Status Quo.
Scheme Bundler Status Quo
Small
<10KB
a\, 0 0Medium
1OKB-1MB
__kA-Figure 7-4: Choosing a congestion control algorithm at Bundler remains important, just as it is at the end-host. Note the different y-axis scales for each group of request sizes.
7.4 Impact of Congestion Control
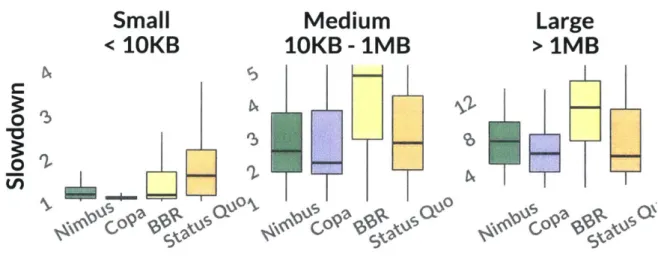
We now evaluate the impact of a different congestion control algorithm running at the sendbox
and at the endhosts.
7.4.1
Sendbox congestion control
So far we evaluate Bundler by running Copa [2] at the sendbox. Figure 7-4 shows Bundler's performance with other congestion control algorithms (namely, Nimbus [16] and BBR [6]), and using SFQ scheduling. We find that using Nimbus provides similar benefits over Status Quo as Copa. BBR, on the other hand, performs slightly worse than Status Quo. This is because it pushes packets into the network more aggressively than the other schemes, resulting in a bigger in-network queue. This, combined with the queue built at the Bundler, results in the endhosts experiencing higher queueing delays than Status Quo. This shows that the choice of congestion control algorithm, and its ability to maintain small queues in the network, plays an important role.
7.4.2
Endhost congestion control
We used Cubic congestion control at the endhosts for our experiments so far. When we configure endhosts to use BBR (as implemented in Linux 4.13), Bundler's benefits remain: in Figure 7-5,
Large
>1MB
I.'
3 ,,ovc)OL
Medium
1OKB -
IMB
BBR CubicLarge
>
1MB
12 8 4 BBR Cubic1 Bundler
*
Status QuoFigure 7-5: Bundler still provides benefits when the endhosts use different congestion control algorithms.
Bundler achieves 58% lower FCTs in the median compared to the updated Status Quo where
the endhosts use BBR. This is primarily because in the Status Quo using BBR causes endhosts to achieve 66% worse median slowdown (1.62 with Cubic to 2.68 with BBR); Bundler's slowdown
is only 5% worse when endhosts use BBR (1.08 with Cubic to 1.14 with BBR). This shows that
Bundler is compatible with multiple endhost congestion control algorithms.
7.5
Impact of Cross Traffic
In studying the impact of cross traffic, we present results with both Nimbus and Copa being used as the congestion control algorithm at the sendbox.
7.5.1
Short-lived flows
We first consider the case where the cross traffic comprises of short-lived flows up to a few MBs. We split the offered load (comprising of web requests described in §7.1) between the bundled
traffic and non-bundle cross traffic in the three ways, as shown in Figure 7-6. Bundler continues
to provide benefits for this case, since maintaining low in-network queues is still possible in the
presence of such flows.
Small
<
10KB
5 4 0 03 02 tn1 12 8 4 BBR CubicBundler
Bundler
$Status
Quo
Nimbus Copa 12Mbps Cross 72Mbps Bundle 24Mbps Cross 60Mbps Bundle 36Mbps Cross 48Mbps BundleFigure 7-6: Against cross traffic comprising of short lived flows. Bundler and the cross traffic combined offer 84Mbps of load to the bottleneck queue. The cross traffic's offered load increases along the x-axis.
Bundler
Bundler
0
Status Quo
Nimbus
Copa
inn ~7.5 0 ~5.0 0T1
2 3 4 5Figure 7-7: Varying number of competing buffer-filling cross traffic flows. As before, Bundler's traffic offers 84Mbps of load, with one persistently backlogged connection.
7.5.2
Buffer-filling flows
Competition from persistent backlogged flows that fill the bottleneck link's buffer, is the worst-case scenario for Bundler. As described in §6.2, Bundler's congestion controller must push packets into the bottleneck queue to compete fairly, and thus it cannot retain packets at the sendbox for scheduling. As a result, we expect performance to be no better than the baseline. We indeed see this in Figure 7-7, as we add different numbers of buffer-filling flows as cross-traffic.
5 g4 0 03 -02
1
sp Bundler Ei Status Quo
1:1 2:1
r 4
03 0
Bundle 1 Bundle 2 Bundle 1 Bundle 2
Figure 7-8: Competing traffic bundles. In both cases, the aggregate offered load is 84Mbps, as in Figure 7-1. For "1:1", we evenly split the offered load between the two Bundles; for "2:1", one bundle has twice the offered load of the other. In both cases, each bundle observes improved median FCT compared to its performance in the baseline scenario.
7.5.3 Competing Bundles
We finally evaluate the case where flows from multiple bundles compete with one another. In
Figure 7-8, we show the performance with two bundles of traffic competing with one another at the same bottleneck link. Both bundles comprise of web requests along with a backlogged flow. We find that Bundler continues to provide benefits for both bundles, even when the amount of
traffic in each bundle is different.
7.6 Varying Offered Load
We now use the web request distribution described in §7.1 to generate a load of 50% (48Mbps),
75% (72Mbps) and 87.5% (84Mbps) of the bottleneck link bandwidth. Our results in Figure 7-9
show that as the offered load is decreased, the benefits of Bundler reduce. This is because if a
link is less congested, scheduling the packets that traverse it will have less benefit.
7.7 Terminating TCP Connections
We now study the benefits of combining Bundler with a TCP proxy middlebox. A TCP-proxy
enables the the end-to-end congestion controller to observe a smaller RTT, by acknowledging
48Mbps 72Mbps
Status Quo Bundler Status Quo Bundler
Figure 7-9: Bundler offers diminishing returns with lower amounts of offered load.
Small
<
10KB
Medium
1OKB
-
1MB
5 4Large
>
1MB
Bundler Proxy 3 2 Bundler Proxy 12 8 4 Bundler ProxyFigure 7-10: A proxy-based implementation of Bundler could yield further benefits to the long flows. Note the different y-axis scales for each group of request sizes.
growth at the endhosts, causing packets to arrive at a faster rate at the middlebox. Combining
Bundler with such a proxy would result in even greater scheduling opportunities.
To evaluate this, we emulate a TCP proxy by modifying the endhosts to maintain a constant
congestion window of 450 packets-slightly larger than the bandwidth-delay product in our setup-and increase the buffering at the sendbox to hold these packets. The other aspects of Bundler remain unchanged, including its use of Copa to move the queues from the network, and its proper scheduling. The result is in Figure 7-10. As expected, combining Bundler with a TCP proxy produces even greater benefits, though primarily for large flows that benefit from the increased congestion window.
l1.5 31.4 0 1.3 ~1.2 0 1.1 "11.0 84Mbps
Status Quo Bundler
0 0 tn 1.25 1.20 1.15 1.10 1.05 1.00 I