Dimensionnement de Burst-Buffers pour réduire la contention Entrées-Sorties
Texte intégral
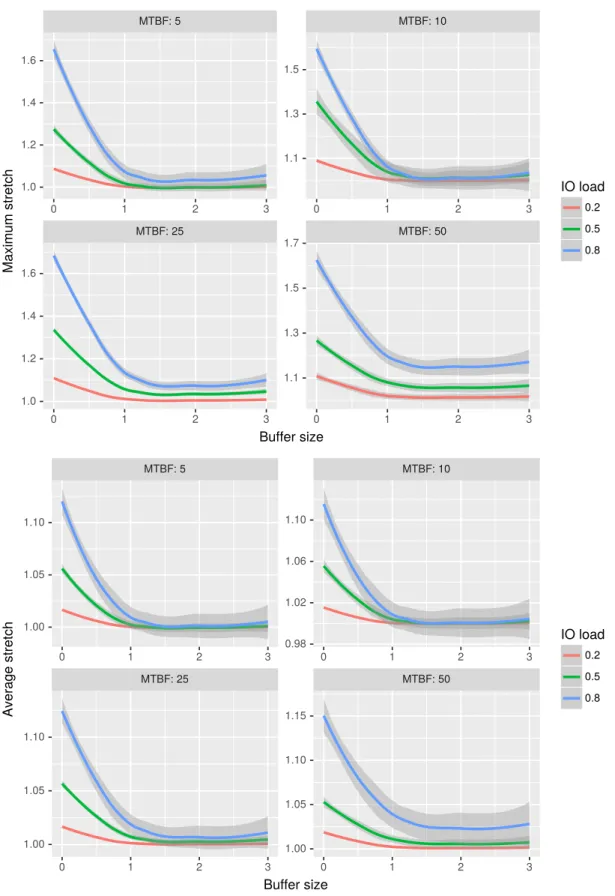
Figure
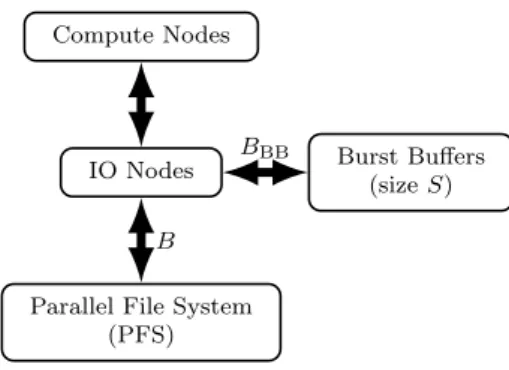
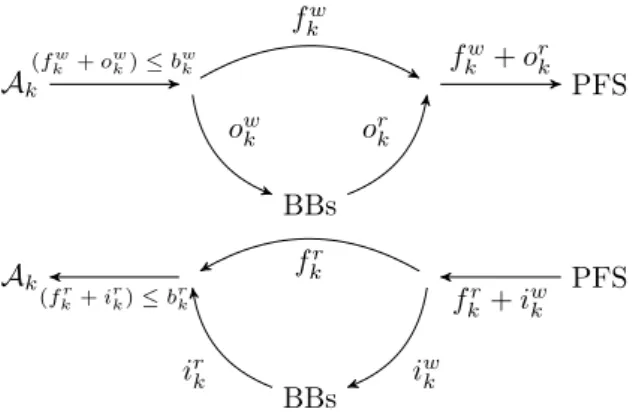
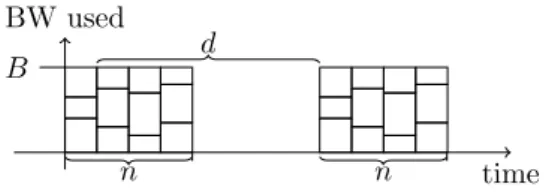
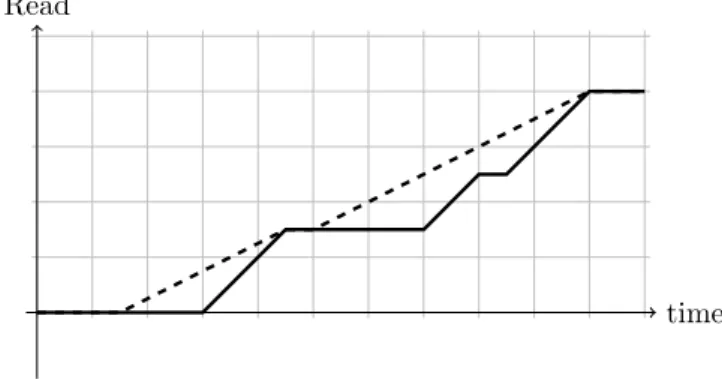
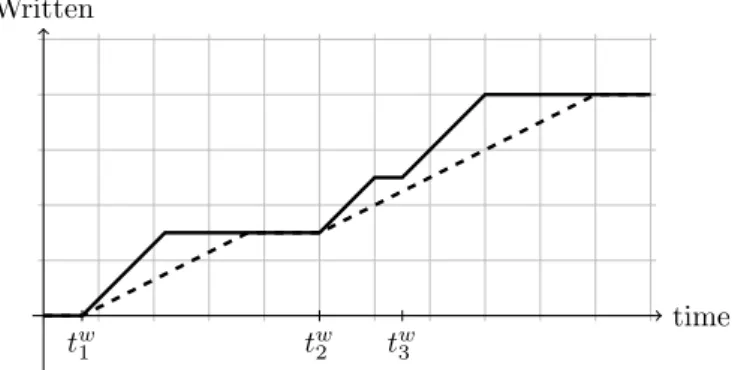
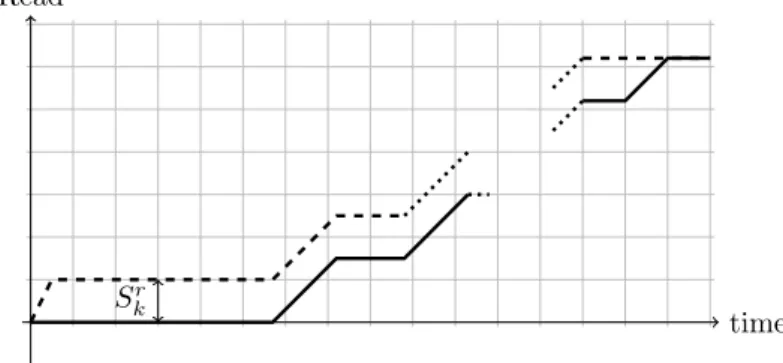
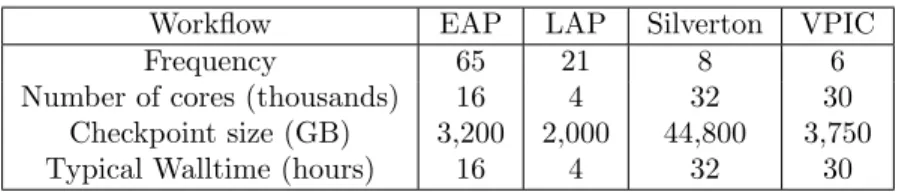
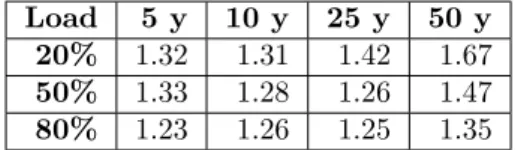
Documents relatifs
In a more specific mean- ing a Boolean category should provide the abstract algebraic structure underlying the proofs in Boolean Logic, in the same sense as a Carte- sian
The case research shows that the use of the category management (i.e. to categorize items in purchasing categories, set purchasing strategic objectives, prioritize the pur-
The data distribution feature is not available for the tree data structure needed in our SPH code and we provide it in the FleCSPH implementation.. The next step will be to
3 The Maastricht Treaty gives the ECB the task of conducting "a single monetary policy and exchange rate policy the primary objective of both of which shall be to maintain
24 International frameworks such as both FAO and its Global Plan of Action (GPA) for the Conservation and Sustainable Use of Plant Genetic Resources for Food and Agriculture
Fruit flies are major constraints for all fruit value chains (including wild species) : mango, citrus, guava, cashew, sour sop, tropical plum, sheanut, African wild
Gemäss Duden wird Barrierefreiheit wie folgt definiert: «Eine Internetseite muss so gestaltet sein, dass sie auch von Menschen mit Behinderung ohne Erschwernis oder fremde
En 2015, 43 % des nouveaux contrats d’apprentis- sage du secteur privé préparent à un diplôme ou un titre dans les spécialités des services (tableau 3).. Le niveau de formation y
