Royaume du Maroc
Ministère de l’Education Nationale, de la Formation Professionnelle, de
l’Enseignement Supérieur et de la Recherche
UNIVERSITE MOHAMMED V de RABAT
FACULTE DE MEDECINE ET DE PHARMACIE DE RABATMEMOIRE DE MASTER
MASTER DE BIOTECHNOLOGIE MEDICALE
OPTION : Biomédicale
Thème
Système d’aide à la décision pour classification des leucémies
aiguës lymphoblastiques par réseaux de neurones à convolution
(Deep Learning)
Présenté par : Encadré par :
SAID JADIDI Dr. MOUNEEM ESSABBAR
Promotion : Décembre & 2020
Jury de soutenance :
Président : Azedine IBRAHIMI, Professeur,
Faculté de Médecine et Pharmacie RabatEncadreur : Mouneem ESSABBAR, Doctorant,
Faculté de Médecine et Pharmacie RabatSAID JADIDI Dédicaces
A mes chers parents
Pour tous leurs sacrifices, leur amour, leur tendresse, leur soutien et leurs prières
tout au long de mes études,
A mes chères sœurs
Pour leurs encouragements permanents, et leur soutien moral,
A mes chers frères
Pour leur appui et leur encouragement,
A toute ma famille
Pour leur soutien tout au long de mon parcours universitaire,
A mon cher et dynamique Docteur encadrent Mr. Mouneem Essebbar
Vous avez toujours été présent, un remerciement particulier et sincère pour tous
vos efforts fournis tout le long de ce projet, Pour vos renseignements, votre
patiente, le temps passé en commun.
A notre cher amoureux Professeur Mr. Aezddine Ibrahimi
Pour vos efforts fournis pour nous offrir un enseignement de qualité, et
promouvoir notre master et notre faculté en général. Que ce travail soit un
témoignage de ma gratitude et mon profond. Espèrent que ce travail sera
satisfaisant
A toute personne
Qu’a contribué à la réussite de ce travail
Que ce travail soit l’accomplissement de vos vœux tant allégués, et le fruit de
votre soutien infaillible,
SAID JADIDI Remerciement
En préambule à rapport de projet de fins d’études nous remerciant ALLAH qui
m’a aidé, et m’a donné de la patience, et le courage durant ces langues années
d’étude.
Je souhaite adresser mes remerciements les plus sincères aux personnes qu’ont
m’apporté leur aide et qui ont contribué à l’élaboration de ce projet ainsi qu’à la
réussite de cette année universitaire.
Ces remerciements vont tout d’abord au corps professoral et administratif de la
faculté de Médecine et Pharmacie Rabat, et en particulier le laboratoire de
biotechnologie pour la richesse et la qualité de leur enseignement, et qui déploient
de grands efforts pour nous assurer une formation de haut niveau.
je tiens à remercier sincèrement et très chaleureusement Dr. Mouneem Essebbar
qui m’a permis de bénéficier de son encadrement, les conseils qu’il nous a fourni,
la patience, la confiance qu’il nous a témoigné ont été déterminants dans la
réalisation de mon projet.
Mes remerciements sont adressés également au Pr. Azeddine Ibrahimi pour son
accueil, et son coopération lors des recherches des sujets. Nous sommes
reconnaissants pour le temps qu’il nous a consacré et son aide tout au long de
cette expérience enrichissante.
Enfin, j’adresse mes plus sincères remerciements au doyen et toutes les équipes
pédagogiques et techniques de notre faculté pour leurs efforts fournies lors de
cette période critique pour nous offrir un environnent de travail à distance.
Les leucémies sont des cancers de sang, ils se caractérisent par une affection de cellules blanches de sang, dans tous les types des leucémies il faut réagir plus rapidement possible, la première étape à procéder est le diagnostic, ce dernier doit être rapide fiable et assure. Le développement d’un outil qui aide à accomplir cette mission est devenue indispensable.
Objectif :
L’objectif principal de notre travail est de développer un outil rapide et efficace basé sur l’intelligence artificielle (IA) qui aide au diagnostic des leucémies aigues lymphoïdes (LAL). L’autre objectif est comparer l’algorithme développé avec l’état d’art de la littérature et les outils existants.
Méthodes :
Notre projet a été divisé en deux parties : une première qui est une bibliographie sur les leucémies en détaille les causes, les symptômes pathologiques, techniques de diagnostic, et le traitement. Une deuxième partie consacrée au développement de modèle et l’application web. Le modèle est basé sur l’algorithme des réseaux des neurones de convolution (RNC), et sur l’architecture AlexNet.
Matériels :
Pour réaliser notre projet nous avons appui sur un jeu de données récupérées auprès de Pr. Fabio Scotti de l’université de Milan, Italie. L’Environnement de développement ANACONDA était utilisé. Le Python 3.7 est le langage de programmation utilisé, pour l’éditeur de texte on a choisi de travailler avec Spyder, et comme Web Micro frameWork nous avons utilisé FLASK.
Résultats :
Le résultat de travail est une application accessible depuis n’importe quel appareil mobile/desktop qui permet classifier. Il est issu également cette étude que la précision notre modèle a atteint le seuil maximal pour tous la détection des leucémies aigues lymphoïdes 95%, pour la classification on a abouti à une précision 70%.
SAID JADIDI Résumé
The main aim of our work is to develop a fast and effective tool based on artificial intelligence which helps in the diagnosis of acute lymphoid leukemias. The other objective is to propose a new algorithm and compare it with the algorithms already proposed in previous works.
Methods:
Our project was divided into two parts: a first which is a bibliography on leukemias in detail the causes, pathological symptoms, diagnostic techniques, and treatment. A second part devoted to model development and the web application.
The model is based on the algorithm of convolutional neural networks, and on the AlexNet architecture.
Materials:
To carry out our project we have a support on a data set recovered from Pr. Fabio Scotti of the University of Milan, Italy. The ANACONDA Development Environment was used. Python 3.7 is the programming language used, for the text editor on chose to work with Spyder, and as Web Micro-frameWork we used FLASK.
Results:
It emerges from this study that the accuracy of our model has reached the maximum threshold for all detection of acute lymphoid leukemia 95%, for the classification we have achieved an accuracy of 70%.
SAID JADIDI Tables des matières
Liste des figures ... 14
Liste des tableaux ... 16
Liste des abréviations ... 18
Introduction Générale ... 20
Introduction ... Erreur ! Signet non défini. 1. Contexte ... 21
2. Enone de problème ... 21
3. Les Objectifs ... 22
CHAPITRE I : Synthèse Bibliographique ... 24
I. Leucémie aigüe lymphoïde ... 25
1. Définition ... 25 2. Historique ... 25 II. Physiopathologie ... 28 1. Les symptomes ... 28 III. Etiopathologie ... 28 1. Facteurs exogènes ... 28 1.1 Facteurs physiques ... 28 1.2 Facteurs chimiques ... 28 1.3 Agents infectieux ... 29 2. Facteurs endogènes ... 29
2.1. Facteurs génétiques constitutionnels : ... 29
V. CLASSIFICATION ... 29 3.1. Classification cyto-morphologique ... 29 3.2. La cytochimie ... 32 3.3. Cytogénétique ... 32 IV. Diagnostic : ... 33 1. Hémogramme ... 33
2. Examen du frottis sanguin : ... 34
3. Frottis médulaire ... 34
V. Traitement et pronostic : ... 35
1. Bases du traitement des LAL : ... 35
2. La surveillance du traitement comprend : ... 35
VII. L’apprentissage approfondi et traitement d’image médicale : ... Erreur ! Signet non défini. CHAPITRE II : Matériels et méthodes ... 37
I. MATERIEL : ... 38
1. Collecte des données : ... 38
1.1. Prélèvement de sang et réalisation de frottis sanguin : ... 39
1.2. La coloration MGG : ... 39
2. Récupération des images microscopiques : ... 40
SAID JADIDI Tables des matières
1. Les réseaux des neurones de convolution CNN : ... 44
1.1. c’est quoi une image ? :... 44
1.2. Types d’images : ... 44
2. La Convolution : ... 45
3. Quelle est la valeur ajoutée des CNN ? ... 47
3.2. Dans notre projet (implémentation): ... 48
4. EXPREMENTATION : ... 51
CHAPITRE III : Résultats & Discussion ... 53
I. Etablissement de modèle : ... 54 1. Le premier modèle : ... 54 1.1. La précision : ... 54 1.2. La perte : ... 55 2. Le deuxième modèle : ... 55 2.1. La précision : ... 56 2.2. La perte :... 56 3. Le Troisième modèle : ... 57 3.1. La précision : ... 57 3.2. La perte :... 58 3.3. La matrice de confusion : ... 59
II. Construction de l’application Web : ... 64
CHAPITRE IV : Discussion Générale ... 60
Conclusion ... 63
Références Bibliographiques ... 65
Figure 1: Répartition des patients en fonction du sexe ... 27
Figure 2 : Aspect des blastes type L1 ... 31
Figure 3 : Aspect des blastes type L2 ... 31
Figure 4 : Aspect des blastes type L3 ... 32
Figure 5 : exemples d'images de base des données (IDB) 2. (A) une cellule de leucémie, (B) une cellule de leucémie, (C) une cellule normale, (D) cellule normale. ... 38
Figure 6 : Sous-types selon la classification FAB. (A) type L1, (B) type L2, (C) type L3, (D) Une cellule non cancéreuse L3 Type ALL. ... 39
Figure 7 : images microscopiques après rotation ... 41
Figure 8 : images microscopiques après application de l'effet miroir ... 41
Figure 9 : Le modèle HSV (A) une cellule de leucémie, (B) une cellule de leucémie, (C) une cellule normale, (D) cellule normale. ... 43
Figure 10 : schéma globale de l'étape de prétraitement ... 43
Figure 11 : Schéma de l’opération de la convolution, en particulier le balayage de la matrice ... 46
Figure 12 : Exemple de l’opération effectuée, dans ce cas on a utilisé le Max ... 46
Figure 13 : l’architecture générale des CNN ... 47
Figure 14 : La réduction des dimensions de la carte caractéristique... 48
Figure 15 : l’architecture proposée de notre réseau ... 50
Figure 16 : Schéma global de prétraitement des images ... 52
Figure 17 : courbe de la précision pour le train et la validation ... 54
Figure 18 : la courbe de la perte sur le set de train et le set de validation ... 55
Figure 19 : courbe de la précision pour le train et la validation ... 56
Figure 20 : la courbe de la perte sur le set de train et le set de validation ... 57
Figure 21 : Fig. courbe de la précision pour le train et la validation ... 58
SAID JADIDI Liste des tableaux
Tableau 1 : Répartition des cas en fonction de l'âge ... 27
Tableau 2 : Répartition selon la tranche d’âge chez les enfants ... 27
Tableau 3 : Classification FAB des LAL... 30
Tableau 4 : Aspect morphologique des lymphoblastes ... 34
Tableau 5 : le rapport de classification ... 59
ADN: acide désoxynucleique ARN: acide ribonulcéique CM : cyto-morphologique
CNN : Les réseaux des neurones de convolution Couleur HSV : teinte saturation valeur
Couleur RGB: Red, Green, Blue CPU: Central Processing Unit DH: Digital Health
Frottis sanguin: FS FS: frottis sanguins GB : Globules blanches
GPU: Graphic Processing Unit GR : Globules rouges
Hb : hemoglobine
IA : l’intelligence artificielle IP : L’immunophénotypage Jeu de donnée : JD
LAL : Lucémie aigue lymphoide LAM : Lucémie aigue meyloide LCR : liquide céphalorachidien LMC : Lucémie meyloide chronoque MGG: May-Grünwald Giemsa MO : la moelle osseuse
PLQ: plaquettes Px: pixels
ReLU: fonction redresseure RI : les rayonnements ionisants RNC : neurones de convolution
Réseaux de neurones artificiels : RNA SC : signes cliniques
SIM : Syndrome d’insuffisance médullaire SVM : Support vector machine
SAID JADIDI Introduction
Les leucémies font partie des hémopathies malignes de populations sanguines caractérisées par une prolifération maligne anormale d’un type bien précisé, sans régulation le physiopathologique se manifeste par des troubles fonctionnelles de cellules sanguines qui ne devient incapables d’accomplir leur mission [1].
Les leucémies sont de deux types : myéloïde qui touche les cellules de la lignée myéloïde et les leucémies lymphoïdes qui touchent la lignée lymphoïde : lymphoblastes, on se base aussi sur un deuxième critère qui est la chronicité et en effet on peut avoir dans les deux précédentes catégories une deuxième classification, et comme bilan on aura 4 types : [1]
Leucémie myéloïde chronique Leucémie myéloïde aigue Leucémie lymphoïde chronique Leucémie myéloïde aigue
1. Contexte :
Ce travail est le fruit d’une initiative de laboratoire de biotechnologie médicale de la faculté de médicine et de pharmacie, après l’organisation de la 7éme session de la journée internationale de la biotechnologie médicale, le thème de cette année était le Digital Health (DH), elle a reconnu l’organisation des conférences, des formations, et des tables ronds qui ont mis la lumière sur cette collaboration entre le digital et tout ce qui technique et la santé. Le développement de l’informatique et l’apparition des nouveaux domaines promissent ont facilité la monté de l’intelligence artificielle. Cette dernière à ouvrir tout un vaste champ pour l’innovation et la recherche dans le sens de l’amélioration les méthodes de diagnostic et le pronostic de maladies et aussi raccourci le processus consultation et la communication médecin-patient d’une façon générale. Notre laboratoire a fait un appel aux candidatures pour les titulaires des sujets de recherche qui s’inscrivent dans le DH.
2. ENONCE DE PROBLEME :
La LAL prend naissance dans les cellules souches lymphoïdes anormales et évolue rapidement [1], le diagnostic de la LAL ne se termine après la confirmation de la présence de l’anomalie mais il est très important de déterminer le type également La
SAID JADIDI Introduction
classification morphologique FAB reconnaissait trois groupes : L1, L2 et L3 [2]. La classification repose sur l’expérimentation de l’hématologue, et n’a pas été encore standardisé. La rapidité et la précision sont deux critères clés dans le diagnostic et le traitement des LAL.
La LAL est généralement diagnostiquée en effectuant un test sanguin complet. [3] Dans ce tes le médecin vérifié si le nombre de globules blancs augmente et avoir des signes cellules leucémiques. Mais parfois, ces symptômes ne sont pas assez pour que le médecin confirme que le patient a une leucémie.
Par conséquent, une autre méthode appelée aspiration de moelle osseuse [4] suivie d'un examen microscopique des frottis sanguins [5] (FS) est effectuée pour confirmer que le patient est diagnostiqué avec une leucémie. Tous ceux-ci différentes méthodes de diagnostic de la leucémie sont manuelles qui dépendent entièrement des médecins spécialistes formés professionnellement et de leur expérience. De plus, ces méthodes manuelles peuvent être longues et coûteux.
L’IA présente un bon alternatif de la décision humain, une solution raisonnable et efficace qui répond à la question en quelques secondes. Le développement d’un outil informatique aide à la prise de la décision dans ce cas est devenu un besoin intense, dès l’arrivé de patient et la susception d’une LAL le temps s’écoule très vite, et l’efficacité de diagnostic devient une obligation envers le patient. Notre travail s’inscrire dans cette vision de la digitalisation des processus de diagnostic des anomalies.
3. Les Objectifs :
L’objectif principal est de débarrasser des limitations mentionnées précédemment, et développer un outil rapide et efficace qui aide au diagnostic, l’outil doit être gratuit et accessible au personnel de santé. L’autre objectif est de proposer un nouvel algorithme et le comparer avec les algorithmes déjà proposées dans des travaux précédents. Et comme le bon diagnostic constitue à peu près la moitié de traitement, la finalité de notre travail est l’amélioration des conditions de diagnostic et réduire le temps et augmenter l’efficacité et la précision, ce qui privilège la bonne prise en charge et le traitement des patients.
SAID JADIDI Introduction
peut aussi servi dans le pronostic de cette maladie, ce qui aide à bien contrôler l’évolution de maladie et l’amélioration des symptômes et la réponse aux traitements.
SAID JADIDI Introduction
CHAPITRE I :
SAID JADIDI Synthèse bibliographique
Les leucémies aiguës (LA) constituent un groupe hétérogène d'hémopathies malignes caractérisées par la prolifération clonale et incontrôlée de précurseurs hématopoïétiques bloqués dans leur différenciation. Ils représentent entre 10 et 15% des hémopathies malignes avec un taux d'incidence standardisé à la population mondiale inférieur à 6/100 000 habitants/an et un âge de survenue qui varie selon le type de leucémie [6]
I. Leucémie aigüe lymphoïde :
1. Définition :
La leucémie aiguë lymphoblastique (LAL) est une affection de la moelle osseuse(MO) caractérisée par une prolifération clonale de cellules précurseurs de lymphocytes appelées lymphoblastes malins.
2. Historique :
Vers 1850 : Les premières pas dans la description de la ‘’Leucémie’’ se produisirent
en plusieurs régions, en France, en Allemagne et en Grande Bretagne par David Craigie et Alfred Donné. [7]
En 1850 : Ernst Neumann Christian a découvert la moelle osseuse du patient
décédé atteint de leucémie était anormale [8].
En 1947 : Le pathologiste Sydney Farber a démontré que l’aminoptérine peut
améliorer les symptômes chez les enfants [8].
En 1960 : deux chercheurs américains de l’université de Philadelphie, Peter Nowell et David Hungerford ont découvert le caryotype des patients atteints de LMC la
présence d’un petit chromosome anormal qu’ils vont nommer « chromosome de Philadelphie »
En 1962 : deux chercheurs Freireich Emil et Frei Emil ont arrivé à traité les patients
pour la première fois avec une combinaison de chimiothérapie [8].
En 1963 : Georges Mathé, il a été le premier à subir une greffe de moelle osseuse allogénique au monde chez un étudiant en médecine de 19 ans, en rechute d’une LAL, qui a reçu une irradiation totale du corps puis de la moelle qui est compatible d’un de ses frères [8].
SAID JADIDI Synthèse bibliographique
En 1970 : les chercheurs dirigée par l’immunologiste Leonard Herzenberg ont
développé la cryométrie en flux permettant l’analyse et le tri unicellulaire.
En 1973 : le Docteur Janet D. Rowley réussit à montrer que cette anomalie résulte
d’une « translocation », c’est-à-dire d’un échange de fragments génétiques entre un chromosome 9 et un chromosome 22, lors de la division cellulaire.[ste
En 1980 : Découverte des gènes de fusion BCR ABL [9].
En 1990 : L'oncologue Brian Druker est le premier qui a découvert comment le gène
BCR ABL déclenche la divisions des globules blancs [9].
3. EPEDEMIOLOGIE :
Selon une étude rétrospective descriptive [10] et analytique de 60 cas de patients chez lesquels une leucémie aiguë a été diagnostiquée a été effectuée entre Juin 2010 et Juin 2016 par une équipe de recherche de la faculté de médecine et pharmacie de Marrakech les circonstances de découverte peuvent être résumés en :
La LAL a une incidence de 1,5 nouveau cas pour 100 000 habitants / an, soit environ 1000 nouveaux cas de LAL par an en France. Elle représente 80% des leucémies aigues de l’enfant et 20% chez l’adulte, avec 2 pics de fréquence : chez l'enfant de 2 à 10 ans (75% des cas sont diagnostiqués avant 6 ans) et chez l’adulte à partir de 50 ans. Elle est légèrement plus fréquente chez les garçons que chez les filles (1,3/1). La LAL est plus fréquente chez les Caucasiens, et plus rare dans la race noire. Elle très rare chez les Européens adultes, environ 10000 cas diagnostiqués et confirmés chaque année.
Justification de choix de l’étude :
Dans notre projet on traite un problème de classification des leucémies aigues lymphoïdes (LAL), dont les données sont des images collectés à partit des patients, une étude préalable de LAL permettra de bien comprendre de la problématique et l’utilité de notre travail. Cette étude satisfait notre besoin elle présente des données très intéressants pour l’assimilation de la pathologie étudiée.
SAID JADIDI Synthèse bibliographique
Tableau 1 : Répartition des cas en fonction de l'âge
Age Adultes Enfants
Pourcentage 70% 30%
Tableau 2 : Répartition selon la tranche d’âge chez les enfants
Tranche d’âge < 1 an 1-5 ans 6-10 ans > 10ans pourcentage 11% 50% 22% 17%
Figure 1: Répartition des patients en fonction du sexe
Une prédominance masculine a été montrée.
La sexe-ratio des cas de LAM confondus était de 1,6 contre 1,3 pour les LAL
Une dominance au niveau de la population européenne et rareté chez la population africaine. Avec une incidence de 1,7 pour 100.000 chez les blancs des Etats Unis par rapport à 0,9 pour 100.000 chez les Noirs [11]
SAID JADIDI Synthèse bibliographique
II.
PHYSIOPATHOLOGIE :
L’évolution maligne des cellules implique une différenciation dans l’acquisition des propriétés de différenciation qui peut être bloquée dans un stade primaire ou la cellule ne peut pas être considérée ni T ou B, on parle de leucémie nulle, ou dans un stade plus avancé ou les cellules acquissent quelques propriétés différenciations B ou T [12].
1. LES SYMPTOMES :
Voici les premiers symptômes révélateurs :
Les leucémies sont révélées par plusieurs symptômes dont on compte la fatigue associée à l’anémie et la fièvre, en plus d’une douleur osseuse, il arrive parfois que le patient souffre des infections fréquentes et une perte d’appétit et de poids.[13]
III.
ETIOPATHOGENIE :
Les causes de la LAL sont peu connues, une caractérisation des facteurs étiologiques repose sur la distinction entre les facteurs génétiques endogènes et les facteurs socioéconomiques et enviromentaux, le rôle de certains agents pathogènes comme le virus d’Epstein-Barr et le virus VIH ont été confirmés [14].
1. Facteurs exogènes :
1.1 Facteurs physiques :
Depuis les années 1900, un ensemble des agents étiologiques y compris les rayonnements ionisants (RI) en particulier chez les personnes qui ont vécu l’attaque nucléaire sur Hiroshima et Nakasagi ont été confirmés comme des facteurs causent de la leucémie et d’autres cancers lympho-hématopiétiques [16]. Elle peut être associée également à l'exposition professionnelle auxRI chez les personnes impliquées dans l'industrie nucléaire [17].
1.2 Facteurs chimiques :
Plusieurs agents chimiques tel que : le benzène, les solvants organiques comme le trichloréthylène ont été largement étudié et des corrélations preuvés. [18].
Cependant, des études ont montré un lien entre l'exposition de la mère durant la grossesse aux pesticides et la leucémiechez le fœtus [19].
SAID JADIDI Synthèse bibliographique
1.3 Agents infectieux :
Le rôle des agents infectieux a très souvent été étudié et confirmé, des études ont regroupé les mécanismes d’action des agents en deux catégories selon leur mode d’action, ceux qui sont responsables d’une activation de la division lymphocitaire par le biais du récepteur à l’antigène cas de : bactéries comme Helicobacter pylori et virus de l’hépatite, et ceux qui s’intègrent dans la cellule etse répliquent avec elle comme le HTLV-1 et l’EBV [20].
2. Facteurs endogènes :
2.1. Facteurs génétiques constitutionnels :
Différentes observations suggèrent l’intervention de facteurs génétiques, les sujets qui sont atteints de trisomie 21 ont un risque 20 fois plus élevé d’avoir une LAL par rapport à les personnes saines [21]. Les maladies héréditaires avec fragilité chromosomique comme l'anémie de Fanconi ont également été associés à la présence de LAL [22].
IV.
CLASSIFICATION :
La LAL peut être catégorisée en se basant sur plusieurs caractéristiques des cellules lymphoblastiques comme la morphologie des cellules, des anomalies au niveau des chromosomes. Des techniques complémentaires sont utilisées pour la classification des LAL comme [38]:
− La morphologie : l’aspect des cellules au microscope.
− La cytochimie : la coloration des cellules à la présence des colorants spécifiques
− L’immuno-phénotypage : utilisation des anticorps pour détecter des protéines à la surface ou à l’intérieur de la cellule.
− La cytogénétique et l’hybridation in situ : la détection des anomalies des chromosomes des lymphoblastes.
_ La biologie moléculaire : la reconnaissance d’anomalies des gènes dans les cellules leucémiques [9]
SAID JADIDI Synthèse bibliographique
La classification FAB est basée sur les caractéristiques cyto-morphologiques des cellules leucémiques, elle décrit 3 groupes selon leur taille, l’aspect du noyau et du cytoplasme [14]:
Tableau 3 : Classification FAB des LAL
Subtypes Blastes Morphologie pourcentage(%)
L1 Petites rondes blastes, cytoplasme peu abondant, noyau rond, chromatine homogène et nucléole
indistinct
75%
L2 Blastes pléomorphes plus gros, quantité modérée de cytoplasme,
noyaux irréguliers, chromatine fine, un ou plusieurs grands
distincts.
20%
L3 De grandes blastes, une quantité modérée de cytoplasme basophile
vacuolé rond à noyau ovale avec chromatine pointillée et un ou
plusieurs noyaux distincts.
5%
On distingue les types : L1, L2 et L3 :
L1 : rare chez l’adulte mais fréquente chez l’enfant; les cellules sont petites, monomorphes, le rapport N/C est haut, la basophilie est variable de faible à modérée.
SAID JADIDI Synthèse bibliographique
Figure 2 : Aspect des blastes type L1
− L2, caractérisée par l’hétérogénéité des blastes, dans leur taille comme dans leur aspect, bas rapport NC et basophilie variable du cytoplasme qui est intense (Figure 4)
Figure 3 : Aspect des blastes type L2
-L3 : Grandes et homogènes cellules le rapport N/C est bas, cytoplasme intensément basophile contenant des vacuoles. (Figure 5) (14).
SAID JADIDI Synthèse bibliographique
Figure 4 : Aspect des blastes type L3
3.2. La cytochimie :
a. la myélopéroxydase :
On trouve la myélopéroxydase négative (contrairement à la LAM).[14] b. Classification immuno-phénotypique :
On distingue deux grands types IP :
- les LAL T: CD2 (+), CD7 (+), CD3 intra cytoplasmique, autres marqueurs T.
- les LAL B classiques : CD19, DR (+), CD10 (+ -), CD 20 (+-) NB : une forme particulière : les B matures (LA de type Burkitt avec translocation (8;14)). (1,22)
3.3. Cytogénétique :
Fréquents chez 60%-70% des adultes atteints il s’agit des anomalies cytogénétiques ou moléculaires récurrentes [29,30]. Cette classification repose sur l’aspect d’IP des blastes : soit phénotype B ou T. il s’agit dans la plupart des cas des translocations.
a- Anomalies de structure dans les LAL de phénotype B Translocation (9;22) (q34;q11) ou chromosome Philadelphie
La LAL à chromosome Philadelphie (Ph+) est l’anomalie chromosomique la plus fréquente chez l’adulte (20-30%) [23]. L'incidence augmente avec l'âge à plus de 50% chez
SAID JADIDI Synthèse bibliographique
les patients âgés de plus de 55 ans. En outre, t (9,22) est presque exclusivement dans les LAL de phénotype B (LAL communes et pré-B) [24].
Translocation (4;11) (q21;q23)
La translocation (4;11) représente environ 3 à 8% des LAL de l’adulte [29]
Translocation (1;19) (q23;p13) :
La translocation (1;19) (q23;p13) est retrouvée avec une fréquence quasi-identique (5%) dans les LAL de l’adulte et de l’enfant [34].
b- Anomalies de structure dans les LAL de phénotype T
La majorité des anomalies chromosomiques décrites dans les LAL-T impliquent les gènes du récepteur T (TCR). Ces translocations sont retrouvées dans 30% des cas de LAL-T [25].
Classification selon type de l’anomalie :
a -
Autres anomalies de structureDans la plupart des temps on trouve des anomalies secondaires à type délétions partielles 6q, 9p, 12p ou plus rarement des isochromosomes (iso9q, iso17q, iso21q) ce qui entraine des pertes de matériel génétique [25]. Ces anomalies de structure ne sont pas spécifiques à un type de phénotype T ou B.
b -
Anomalies de nombre et ploïdieUne association entre des hyperdipoidies et augmentation de la chance pour l’évolution de la maladie a été montrée. [26]
V. Diagnostic :
1. Hémogramme :
- Anémie, Hémoglobine parfois < 7 g/dL :
SAID JADIDI Synthèse bibliographique
NB : une macrocytose en présence de LAL cause une carence des vitamines due au
consommation excessive de folates par les cellules tumorales. [3]
- Nombre de leucocytes :
Tout peut être observé de la cytopénie sanguine à la leucocytose majeure composée principalement de cellules blastes. [3]
La neutropénie est fréquente, parfois sévère (<0,5 G / L).
- Dans la plupart des cas, la thrombopénie peut être sévère (<10 G / L) [3]
2 Examen du frottis sanguin :
Différenciation au niveau de de la morphologie entre les lymphocytes normales et les blastes.
3. FROTTIS MÉDULLAIRE :
Habituellement richement cellulaire. Dans 10 % des cas, la moelle est hypocellulaire (liée à une discrète myélofibrose). [3]
Mégacaryocytes : en général absents ou très rares (en rapport avec la thrombopénie)
Blastose médullaire habituellement > 90%
Tableau 4 : Aspect morphologique des lymphoblastes
Petits lymphoblastes (plus fréquents chez
l’enfant)
Grands lymphoblastes
Taille des blastes < 2 diamètres
lymphocytaires > 2 diamètres lympho. (hétérogène)
Chromatine =/- Fine Fine
Nucléole non visible 1 ou plus (>25% Bl)
Rapport N/C >0.9 0.7-0.9 (hétérogène)
Contour noyau Irrégulier 0.7-0.9 (hétérogène)
Basophilie cytopl. modérée variable
SAID JADIDI Synthèse bibliographique
VI. Traitement et pronostic :
Les anomalies cytogénétiques, le profil IP, l’hyperleucocytose, l’Hb, sont des facteurs pronostiques importants. [2]
1. Bases du traitement des LAL :
On utilise d’abord un traitement d’induction combiné des : corticoïdes, vincristine, asparaginase, et parfois anthracyclines, avec une prophylaxie de la méningite cérébrale puis un traitement intensif (mêmes médicaments que précédemment), et finalement un traitement d’entretien qui sure 24 mois. [2]
2. La surveillance du traitement comprend :
Au diagnostic :
Comptage des blastes sanguins à J8 d’un traitement avec corticoïdes (évaluer le nombre de cellules sanguines; le nombre de J8 doit être inférieur à 1 G / L) ; étude de liquide céphalo-rachidien ; la réalisation des myélogrammes après la cure d’induction, et en fonction des schémas protocolaires (parfois cela peut expliquer la durée excessivement longue de la cytopénie) ; on peut effectuer un myélogramme à l’arrêt du traitement. [3]
VII. L’apprentissage approfondi et traitement
d’image médicale :
L’intelligence artificielle a explosé le domaine de l’imagerie médicale et des tonnes des travaux de recherche ont été effectués et d’autres sont lancés. Auparavant des méthodes classiques ont été explorés par exemple le Support vector Machine (SVM) et les K proches Voisins qui sont des méthodes statistiques qui sont développées par Chatap,N. and Shibu,S[38] Ils ont discuté du concept du concept SVM et Nearest Neighbor. Il a expliqué à propos de l'identification et du comptage des cellules sanguines dans le frottis sanguin en utilisant des techniques de classification des images et à inclure dans un logiciel de traitement d'images, qui permet à l'hématologue de diagnostiquer plus efficacement la LMA et Il a été mentionné que les hématologues rencontrent souvent des difficultés identifier les sous-types de LAM, en raison des similitudes de leur caractéristiques morphologiques. Après détection
SAID JADIDI Synthèse bibliographique
de la LMA, les cellules blastiques doivent être classées en myéloïde aigu sous-type 3 (M3) ou un des autres sous-types.
Ces dernières années les recherches sur la classification des leucémies sont principalement basées sur des techniques de vision par ordinateur [41], [42]. L’algorithme le plus courant dans cette approche consiste en plusieurs étapes rigides: prétraitement d'image, clustering, morphologique
Filtrage, segmentation, sélection ou extraction de caractéristiques, classification et évaluation [43]. La plupart des auteurs du la littérature a adopté des techniques d'apprentissage automatique telles que K-proches voisin afin de détecter et de classer les cellules sanguines dans les images... Au lieu de cela, l'apprentissage en profondeur peut apprendre et extraire automatiquement les fonctionnalités de haut niveau et effectuer classification dans le même temps. Par conséquent, nous proposons de travailler avec l’architecture des réseaux neuronales convolutifs pour distinguer les images de cellules sanguines normales et anormales. Cette technique qui été utilisée par Sarmad Shafique et all [39] qui ont exploité l’architecture CNN et ils ont atteinte des bonnes résultats. Amjad Rehman et All [40] ont utilisé la même technique mais avec une segmentation robuste et des techniques d'apprentissage approfondi avec le réseau neuronal convolutif qui sont utilisées pour entraîner le modèle sur les images afin d'obtenir des résultats de classification précis.
SAID JADIDI Synthèse bibliographique
CHAPITRE II :
SAID JADIDI Matériels et Méthodes
38
I. MATERIEL :
1. Collecte des données :
Les images utilisées dans ce projet ont été obtenues à partir de ALL-Image Ensemble de données DataBase (IDB)[27], qui est un jeu de données public disponible en ligne (open source). La récupération des données après le remplissage d’un formulaire de demande et l’envoyer au Pr Fabio Scotti, le professeur d’informatique à l’université de Milan, Italie. Ce JD a été divisé en 2 groupes.
Le premier groupe nommé IDB 1 se compose de 108 images : 59 les images provenaient de patients en bonne santé et 49 images provenaient de patients atteints de leucémie.
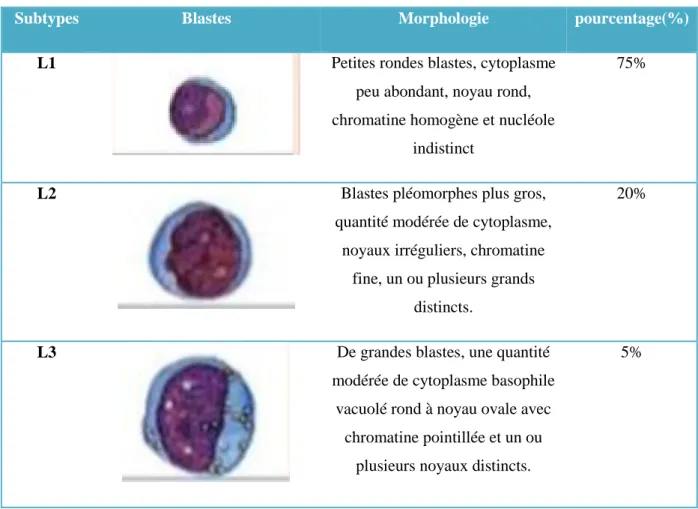
Le deuxième groupe IDB 2 se compose de 260 images cellule : 130 images provenaient de patients atteints de leucémie divisé en 3 groupes chaque groupe correspandant à un type de leuciémie : L1, L2 L2 , et 130 étaient des images normales. Ces images avaient une résolution de 257x257 avec une profondeur de couleur de 24 bits. Dans la figure 7, nous pouvons voir des échantillons d'images cancéreuses et saines de la base de données ALL-IDB2.
Figure 5 : exemples d'images de base des données (IDB) 2. (A) une cellule de leucémie, (B) une cellule de leucémie, (C) une cellule normale, (D) cellule normale.
SAID JADIDI Matériels et Méthodes
39
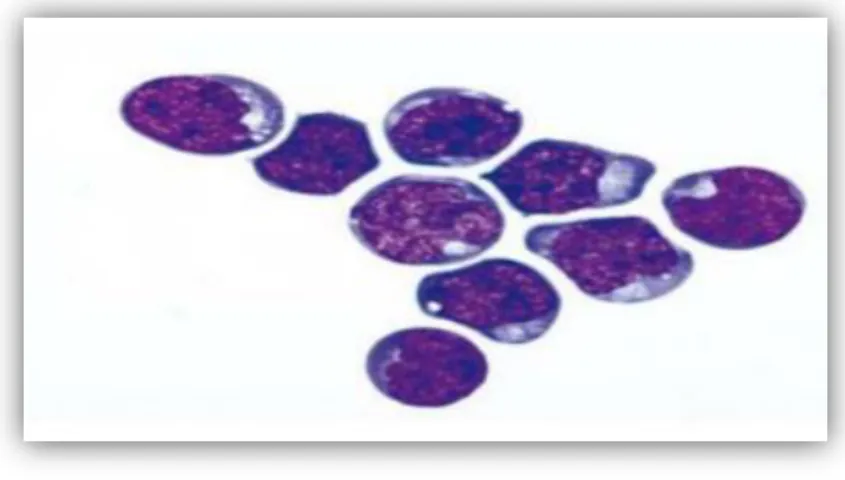
Selon la classification FAB, 18 LAL ont été classés en 3 sous-types, qui étaient L1, L2 et L3. Différents sous-types de TOUS sont illustrés à la figure 8 :
Figure 6 : Sous-types selon la classification FAB. (A) type L1, (B) type L2, (C) type L3, (D) Une cellule non cancéreuse L3 Type ALL.
Dans un premier temps, ces images de patients affectées par la leucémie ont été classées en trois catégories L1, L2, et L3 par un oncologue expert qui a étiqueté chaque image dans le sous-type correspondant.
2. Préparation des images :
2.1. Prélèvement de sang et réalisation de frottis sanguin (FS) :
La réalisation d’un FS nécessite un prélèvement de sang périphérique des patients à partir de coude de main, une conservation de sang dans un tube violet avec anticoagulant EDTA pour une utilisation ultérieure. Par la suite un on étale une goutte de sang sur une lame avec une degré d’inclinaison de 30 et le lisse sécher avant la coloration. (voir annexe I)
2.2. La coloration MGG :
La coloration MGG est une coloration utilisée en hématologie pour différencier entre les cellules sanguines lors de la préparation cytologique.
SAID JADIDI Matériels et Méthodes
40
Il contient deux colorants :
May-Grünwald: est un colorant acide contenant un colorant acide, l'éosine, et un colorant
basique, le bleu de méthylène.
Le Giemsa : contenant aussi de l'éosine, et un colorant basique, l'azur de méthylène.
Les composants cellulaires acides lieront sélectivement les colorants basiques. Ces éléments sont considérés basophiles (ADN, le cytoplasme des lymphocytes riches en ARN).
Les composants cellulaires basiques lieront sélectivement les colorants acides. Ces éléments sont appelés éosinophiles (dans le cas de l'hémoglobine, qui est une protéine basique contenue dans les globules rouges et les granules d'éosinophiles).
• Le composant qui fixe deux types de colorants est appelé neutrophiles.
3. Récupération des images microscopiques :
Après avoir effectué la coloration MGG, la lame est observée sous microscope optique équipé avec une caméra numérique pour prendre des images pour chaque frottis. Les images obtenues ont une résolution de 257x257 px.
3.1. Le prétraitement des images :
À la raison de manque des images notre modèle risque de ne pas avoir des données suffisantes pour donner des bonnes prédictions, pour cela on a fait une augmentation des données par deux méthodes :
3.2. La rotation :
L’avantage d'utilisation des rotations : c’est que on obtient des images strictement réelles et différentes chacune par rapport à l’autre.
Chaque image de jeu de donnée a été rotacée avec plusieurs angles plusieurs angles allant de 0 jusqu’au 360 degrés avec un pas de 10 degrés.
SAID JADIDI Matériels et Méthodes
41
Les images sont ensuite recadrées, avec lequel les paries vides sont éliminées, pour rotations différentes de, 90, 180, 270, 360
Figure 7 : images microscopiques après rotation
3.3. Le Flipping d’image :
Cet effet a pour objectif de créer plus d’images avec angle de vue différente, comme illustre dans la figure suivante :
SAID JADIDI Matériels et Méthodes
42
Bénéfice :
Le nombre des images a été augmenté de 130 aux 2600 images avec les proportions suivantes : - Pour le type L1 : le nombre a été augmenté de 40 aux 960 images (36%)
- Pour le type L2 : le nombre a été augmenté de 50 aux 980 images (37%) - Pour le type L3 : le nombre a été augmenté de 40 aux 660 images (25%)
Après l’augmentation des images le nombre dans chaque catégorie ne sont pas équilibré, donc on a précédé à une égalisation de nombre des images à un nombre de la catégorie faible des images. Maintenant chaque catégorie dans notre training set a le même nombre des images dans chaque catégorie.
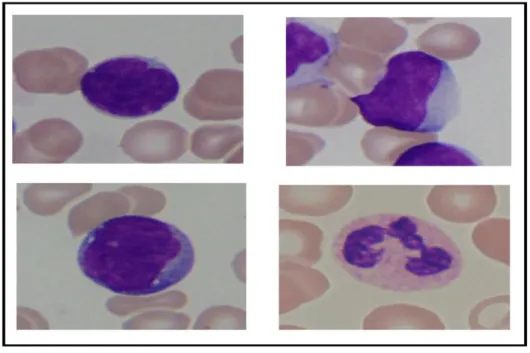
Coloration HSV :
Afin de trouver le modèle le plus performant il faut tester d’autre modalités de couleur, pour cela nous avons créé un deuxième jeu de donnée des images avec la couleur HSV, cela rendre notre application plus forte car il va s’habituer à travailler avec des images de différents modalités de couleur, et va nous aider à trouver le JD qui rendre la précision la plus performante.
SAID JADIDI Matériels et Méthodes
43
Figure 9 : Le modèle HSV (A) une cellule de leucémie, (B) une cellule de leucémie, (C) une cellule normale, (D) cellule normale.
SAID JADIDI Matériels et Méthodes
44
II. METOHDES :
1. Justification de choix de modèle :
Dans les années précédents, plusieurs modèles sont utilisées pour analyser et segmenter les images, tels que : le support vector machine, K-means clustering algorithm, les k plus proches voisins…etc., mais ces méthodes demandent plus de temps et d’expérience de la part de manipulateur, mais le plus important et que ils donnent une précision no satisfaisante. Les réseaux des neurones de convolution est une méthode révolutionnaire, elle est inspirée de la machinerie humain, et elle se caractérise par sa simplicité et rapidité et une haute précision, c’est pour cela on choisir de travailler avec elle, une autre raison c’est que elle n’est pas encore bien explorée par les scientifiques..
2. Les réseaux des neurones de convolution CNN : 2.1. C’est quoi une image ? :
Une image numérique est constituée d'un ensemble de pixels (pixels) juxtaposés en lignes et en colonnes. Un pixel (correspondant à un point ou un petit carré) est le plus petit élément que l'on puisse trouver sur une image. Chaque pixel a ses propres caractéristiques, luminosité, couleur, et luminosité, afin de pouvoir les distinguer et composer les images. [28]
2.2. Types d’images:
a. Image matricielle :
Elle est composée d'une matrice (tableau) de points à plusieurs dimensions, chacun représentant une dimension spatiale (largeur, profondeur, hauteur), le temps (durée) ou d'autres dimensions (par exemple, le niveau de résolution). [29]
b. Image 2D :
Dans le cas d'une image bidimensionnelle (la plus courante), ces points sont appelés pixels. Dans une image numérique, cela équivaut au nombre de pixels qui composent l'image en hauteur (axe vertical) et en largeur (axe horizontal): par exemple, 200 pixels sur 450 pixels.
SAID JADIDI Matériels et Méthodes
45
On considère l'image comme une fonction de ℝxℝ dans ℝ:
f(x, y) = p
Dans ce cas où la paire d'entrée est considérée comme un emplacement spatial, le singleton de sortie est le code de l'image. Le code peut être de couleur. Les codes de couleur les plus couramment utilisés sont RVB: rouge, vert et bleu.. la valeur maximale correspond au blanc, la valeur 0 correspond au noir, et d'autres combinaisons donnent d'autres couleurs.[44]
Le codage couleur est effectué sur trois octets, chaque octet représente une valeur comprise entre 0 et 250, donc le nombre de couleurs possibles est: 250 X 250 X 250 = 16,7 millions de couleurs. (Voir Annexe II)
Lorsque l'image a une composante temporelle, nous l'appelons animation..[45] Pour les images 3D, ces points sont appelés "voxels". Ils représentent un
volume.[46]
3. La Convolution :
a. C’est quoi la convolution ? :
Dans l'apprentissage automatique, les réseaux de neurones convolutifs ou réseaux de neurones convolutifs (CNN ou ConvNet pour les réseaux de neurones convolutifs) sont un réseau de neurones artificiels qui est acyclique, dans lequel la connexion entre les neurones est inspirée par la cortex animale de la vision [31]. Les neurones de cette région du cerveau sont arrangés de sorte qu'ils correspondent à des régions qui se chevauchent lors du pavage du champ visuel, Leurs fonctionnement s'inspire des processus biologiques [32], Ils sont composés de perceptrons multicouches dont le but est de prétraiter une petite quantité d'informations [33] . Les réseaux de neurones convolutifs sont largement utilisés dans les systèmes de reconnaissance et le traitement des d'images et de vidéos [34].
SAID JADIDI Matériels et Méthodes
46
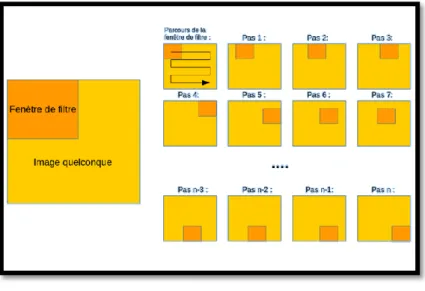
Figure 11 : Schéma de l’opération de la convolution, en particulier le balayage de la matrice
Dans chaque position on effectue une opération mathématique pour construire une image de la fenêtre, il peut s’agit d’une comparaison entre les pixels et on prend le max ou min. l’image précédente est transformée dans une nouvelle matrice de dimension inférieure à celle de la matrice mère.
Figure 12 : Exemple de l’opération effectuée, dans ce cas on a utilisé le Max
Dans cet exemple l’opérateur va extraire le plus grand pixel c.-à-d. 255 dans le premier et la deuxième fenêtre, 159 dans le troisième et 184 dans le 4éme et le 5éme fenêtre. Après chaque opération on fait glisser la fenêtre avec un pas de 1 pixel horizontal et vertical.
SAID JADIDI Matériels et Méthodes
47
b. Les réseaux des neurones de convolution : CNN
Les CNN sont des algorithmes de l’apprentissage approfondi utilisés dans plusieurs domaines, et pour différents objectifs tel que : La classification et la prédiction, les CNN sont représentés de la forme suivante :
Figure 13 : l’architecture générale des CNN
On distingue deux parties cette l’architecture, la première partie nommée la convolution, et la deuxième est la classification.
4. Quelle est la valeur ajoutée des CNN ?
3.1. Dans le traitement d’image classique MLP :
Prenons par exemple une image de 512 x 512 cad une image de 262.144 pixels, pour analyser cette image on va considérer un réseau des neurones avec une première couche cachée de 512 neurones cela a pour conséquence que la première couche cachée va nous demande 262.144 x 512 = 13 millions poids ce qui n’est pas pratique [35].
Dans les CNN :
Le CNN et en particulier sa partie convolutive permet de résoudre ce problème. Cela va grandement diminuer le nombre de poids à calculer dans le modèle. En effet, comme nous l’avons vu ci-dessus, la convolution va avoir pour effet de réduire la dimension de l’image sorite appelée «la carte de caractéristiques» que l’on obtient après convolution (en comparaison avec la taille de l’image en entrée). Si l’on répète ce processus plusieurs fois, en prenant comme nouvelle entrée (sur laquelle nous allons effectuer la convolution) la sortie de la convolution
SAID JADIDI Matériels et Méthodes
48
précédente, nous allons diminuer de plus en plus la taille de la carte de caractéristiques, et donc nous diminuons également le nombre de calculs. [35]
Figure 14 : La réduction des dimensions de la carte caractéristique
Il faut savoir également qu’une image est une forme 3D deux dimensions pour la largeur et la hauteur, et la troisième dimension pour la couleur. La couleur d’une image est une combinaison entre trois couleurs principaux : le rouge, le vert, et le bleu RGB.
Dans l’analyse précédente nous avons traité l’image avec deux dimensions, maintenant on va ajouter une autre dimension de couleur présentée par trois cartes caractéristiques, une pour chaque couleur.
Après chaque convolution on aura toujours une carte des caractéristiques, une pour chaque couleur, il faut savoir qu’on peut effectuer plusieurs convolutions sur une image ou une carte des caractéristiques selon le nombre des caractéristiques pertinentes qu’on souhaite manipuler sur l’image. Le nombre des opérations de convolutions corresponds au nombre des caractéristiques.
À la sortie de la partie convolution on a eu une long vecteur contient les caractéristiques les plus pertinentes, on connecte chaque valeur avec un neurone de réseau des neurones de la couche classification. Cette partie de classification se comporte comme un réseau des neurones classique.
SAID JADIDI Matériels et Méthodes
49
La partie de convolution comprend 2 parties :
A- Couche convolutionnelle : il était responsable de l'application de plusieurs détecteurs de caractéristiques pour explorer de nombreuses caractéristiques sur l'image d'entrée. Le CNN que nous avons utilisé avait 32 cartes des caractéristiques avec la taille de 3 × 3. Convolution des filtres ont été appliqués à l'image par glissement. Les valeurs des filtres ont été déterminées au hasard. Nous avons utilisé 2 couches de convolution pour éviter le sur-ajustement.
B- Couche Max-Pooling: cette couche était responsable de la diminution de la dimension de l'image filtrée ainsi, il s'est concentré sur la caractéristique / zone ou l'objet important dans
l'image. Dans notre réseau, nous avons utilisé une couche de mise en commun max avec la
taille de 2 × 2. Nous avons également doublé le nombre de cette couche. La partie Classification comprend 2 parties :
A- la couche Aplatir: le rôle de cette couche est de transformer une matrice regroupée Maxpooling de 2 dimensions en une dimension ainsi que chaque cellule de cette matrice pourrait être utilisée comme nœud d'entrée pour le réseau entièrement connecté.
B- Réseau entièrement connecté: cette partie était un réseau de neurones artificiels complets connectés naïf qui consistait en une couche d'entrée (la couche aplatie dans notre cas), une couche cachée et une couche de sortie. Dans notre modèle, la couche cachée se composait de 128 nœuds. Grâce à un calcul simple, la fonction d'activation ReLU avait été implémentée.
SAID JADIDI Matériels et Méthodes
50
Figure 15 : l’architecture proposée de notre réseau
Dans notre model nous étaient basés sur le concept de Transfer Learning pour le deep neural network, Transfer Learning est technique de machine Learning pour laquelle un model entrainé avec quelques tasks va être utilisé pour étudier d’autre tasks en se basant sur le principe de Transfer de connaissance.
Algorithme of AlexNet :
AlexNet est considéré comme l'un des articles les plus influents publiés en vision par ordinateur, ayant stimulé de nombreux autres articles publiés utilisant des CNN et des GPU pour accélérer l'apprentissage en profondeur. En 2019, le journal AlexNet a été cité plus de 47000 fois.
Notre model a été basé sur l’algorithme AlexNet qui est une implémentation rapide de GPU de CNN pour la recognition des images, elle contient 8 couches 5 parmi eux sont des convolutionnelles dont chaque layer est suivie d’une MaxPooling et les 3 dernières sont les constituants d’un réseau de connexion entière. La fonction d’activation utilisée est la fonction sigmoïde qui est de la forme (Krizhevsky, Alex, Sutskever and all):
SAID JADIDI Matériels et Méthodes 51 𝑓(𝑥) = 1 1 + 𝑒−𝑥 = 𝑒𝑥 1 + 𝑒𝑥
On a effectué quelques changements sur cette architecture, on a éliminé deux couches de convolution et on a gardé juste 2 couches la première pour la détection de la leucémie et la seconde pour la classification entre les 4 types : L1, L2, L3, NORMAL
5. EXPREMENTATION :
Toutes les opérations ont été effectuées avec un ordinateur processeur i5 et une mémoire RAM de 8 GB avec une carte graphique GPU de 4 GB, le système d’exploitation utilisé était le Windows 10, nous avons choisi de travailler avec ANACONDA, l’enivrement de développement dédié au Data Science et Machine Learning, l’éditeur de texte utilisé est le Jupyter NoteBook et le langage de programmation choisi était le Python 3.7. Nous avons créé un environnement virtuel dont on a installé les packages Keras, TensorFlow qui sont utilisés dans les projets de Deep Learning et le traitement d’image. Pour la préparation et l’augmentation des données nous étaient basés sur la bibliothèque OpenCV qu’est une bibliothèque graphique libre, spécialisée dans le traitement d'images.
Manipulation de données :
On éliminé le dataset ALL DD1 En raison de leur similitude interclasse, car pour chaque image présente dans toutes les classes on trouve la même forme et des constituants identiques (GB, GR, et PLQ) et de leur variabilité intraclasse car dans la même classe on trouve des images de résolution et coloration différente, ils étaient difficiles à classer. Par conséquent, nous avons utilisé dataset ALL-IDB 2 qui est un ensemble de zone d'intérêt croupées contient cellules normales et des blastes. Il contient 260 les images et 50% d'entre elles représentent des lymphoblastes. Il est désigné pour la classification.
L’étiquetage des images :
Le dataset augmenté a été divisé sur 4 classes : L1, L2, L3, Normal appelées labels et pour chaque classe on a constitué 3 dossier : Train, Test, Validation, l’ensemble des données précédentes a été manipulé d’une façon pour équaliseur le nombre des images dans chaque catégorie.
SAID JADIDI Matériels et Méthodes
52
.
CHAPITRE III :
Résultats
SAID JADIDI Résultats
54
I. Etablissement de modèle :
1. Le premier modèle :Dans ce modèle nous avons utilisé 2 couches de convolution avec un filtre de 32 px et une fenêtre de convolution de taille 3x3 la fonction d’activation est la fonction redresseur ‘Relu’, chacune de ces deux couches est suivie avec une couche de Pooling, avec une fenêtre de taille 2x2, pour la partie de classification est composée de d’une douche de Flatten et deux couches cachées, la première avec 128 neurones, et une fonction d’activation de type ’Relu’, la deuxième est une couche de sorite avec 4 neurones et une fonction d’activation de type ‘Sigmoïde’
1.1. La précision :
La précision représente la somme des prédictions justes divises sur la somme des observations totales, il est calculé pour l’ensemble de train et pour le set de validation :
SAID JADIDI Résultats
55
On remarque bien que la précision augment avec le nombre d’epochs, une epoch est une prédiction suivi par une rétro-propagation dans le réseau des neurones avec l’ajustement de poids des neurones. Pour le train la précision a atteint le seuil de 70% au bout des 10 epochs, or pour la validation on est déjà au dans 70 % après 4 epochs. On peut expliquer ca par le fait que le réseau de neurones s’entraine déjà sur le set de train avant d’entamer le set de validation
1.2. La perte :
La perte représente la somme des prédictions fausses divisé sur la somme des observations totales, il est calculé pour le set de train et pour le set de validation :
Figure 18 : la courbe de la perte sur le set de train et le set de validation
De même on remarque que la perte sur le set de train diminue au bout de 2 epochs, et que la perte sur le set de validation prend des valeurs faibles après la première epochs.
1. Le deuxième modèle :
Dans ce modèle nous avons ajouté une couche de convolution avec un filtre de 64 px et une fenêtre de convolution avec la taille de 3x3, pour la fonction d’activation pour gardent la
SAID JADIDI Résultats
56
fonction redresseur ‘Relu’, pour la couche de Pooling nous avons gardé la même couche que le précédent model.
Pour la partie de classification nous avons adopté la même configuration que le premier modèle.
1.1. La précision :
Figure 19 : courbe de la précision pour le train et la validation
On constate que la précision augmente avec les epochs. Il faut noter bien que la précision a augmenté vers 75%. Ce qui un taux satisfaisable généralement.
SAID JADIDI Résultats
57
Figure 20 : la courbe de la perte sur le set de train et le set de validation
Comme dans la précision on note une amélioration de la perte ce qui traduit par une diminution considérable qui arrive jusqu’au 0.6.
2. Le Troisième modèle :
Dans ce modèle nous avons gardé la même configuration que celle de modèle 2, mais nous avons augmenté steps_per_epoch pour le jeu de train qui est devenue 300 au lieu de 66 et pour le jeu de validation qui devenue 76, nous avons augmenté le nombre d’epoch également et on a choisi de travailler avec 30 epochs la fonction d’activation reste la même ‘Relu’, suivie par une couche de Pooling.
SAID JADIDI Résultats
58
Figure 21 : Fig. courbe de la précision pour le train et la validation
De nouveau notre modèle s’améliore, la précision a atteint le seuil de 95% pour le jeu
d’entrainement et 91% pour e jeu de validation. L’augmentation de nombre d’epochs a donné des bonnes résultats, ce qui apparaitre logique car le modèle a plusieurs chance pour faire plus de cycle et ajuster les poids et améliorer la précision
2.2. La perte :
SAID JADIDI Résultats
59
La perte a diminué considérablement surtout pour le jeu d’entrainement et que elle a atteint le seuil de 14%, pour le jeu de validation on remarque que la perte a baissé également mais n’a pas arrivé à la perte de jeu d’entrainement, ce qui peut être expliqué par le nombre des epochs qui inférieur à celle de heu d’entrainement et aussi le nombre des images.
2.3. La matrice de confusion :
Tableau 5 : le rapport de classification
Type Précision
L1 0.954
L2 0.9623
L3 0.959
NORMAL 0.99
On remarque que la précision de notre modèle sur le jeu de validation semble très acceptable, on note aussi que la détection de leucémie est nettement considérable.
CHAPITRE IV :
Par l’utilisation de l’apprentissage profond et en particulier les réseaux des neurones à convolution, nous avons bien amélioré la performance du processus de détection et classification des sous-types des leucémies lymphoïdes aigues en 4 classes. Notre méthode proposée a fonctionné efficacement et il est également meilleur que les précédentes méthodes standards car il n’a pas besoin de segmentation des images microscopiques requises par l'extraction de caractéristiques précédentes méthodes. Les couches de convolution et autres couches cachées dans DCNN sont suffisamment puissant pour détecter et classer automatiquement cellules de leucémie spécifiques à partir d'un grand ensemble de données d'images microscopiques.
Les réseaux de neurones profonds nécessitaient généralement une grande quantité de données pour s'entraîner. Mais dans cette étude, malgré que notre jeu de données est très limité, nous avons pu d’atteindre une précision plus élevée de 99,50% pour la détection de la leucémie et 95,06% pour la classification des sous-types de leucémie après l'augmentation des données.
Plusieurs études ont proposé différents techniques de détection de la leucémie, mais la plupart des études ont négligé la classification de ses sous-types en raison de leur grande similitude interclasse et de leur variabilité intraclasse. Bien que ces sous-types soient difficiles pour classer, ils jouent un rôle important dans le diagnostic détaillé des malades et est très crucial pour le traitement médical de la leucémie. Dans cette étude préliminaire, nous avons effectué la détection automatique et la classification de ses sous-types en 4 classes. Contrairement, Moradi Amin et All ont proposé une méthode de détection et de classification de la leucémie dans laquelle ils ont utilisé l'égalisation d'histogramme et contraste linéaire pour le prétraitement [36]. Pour la segmentation des images, le k-mean Clustering a été déployé et après l'extraction des différentes fonctionnalités, le classificateur SVM est utilisé pour la classification de tous les sous-types. Sur leur ensemble de données spécifique, ils sont capables d'atteindre une précision de 97% pour la détection de la leucémie et une précision de 95,6% pour la classification des sous-types. Même si les résultats ne peuvent pas être directement comparés avec leur ensemble de données, nous déduisons que de meilleurs résultats peuvent être obtenus en utilisant DCNN sans implication de segmentation d'image.
Putzu et All. a proposé une autre méthode de détection de la leucémie dans lesquels ils ont déployé l'algorithme zack pour la segmentation des leucocytes cet algorithme consiste à isoler les groupes des leucocytes, puis séparer le noyau et le cytoplasme et calculer le rapport noyau/cytoplasme[37]. Après cela, le classificateur SVM a été utilisé pour classer les cellules
normales et cancéreuses sur les caractéristiques données selon ce rapport à l’aide de la séparation des distributions par des droites. Ils sont capables d'atteindre une précision de 92%. Chatap et All, ont déployé le seuillage globale en utilisant la technique de seuil Otsu pour la segmentation de lymphocytes [38]. Après avoir extrait les fonctions basées sur la forme, une algorithme des k les plus proches voisins a été formé pour atteindre une précision de 93%. Notre modèle développé présente une précision supérieure à celles des travaux précédentes. Également nous avons utilisé un grand nombre des images après l’augmentation des données. Comparaison des performances des différentes méthodes fournies dans la littérature avec notre méthode proposée est présentée dans le tableau 6.
Tableau 6 : comparaison avec d’autres études
Nombre d’images Classifier Précision de la détection % Précision de la classification%
Putzu et al22 368 Support Vector
machine
92.00 Négligeable
Joshi et al5 108 K plus proches
voisins 93.00 Négligeable MoradiAmin et al8 312 Support Vector machine 97.00 95.60
Notre modèle 130 Réseaux neurones à
convolution
99,50 95,06
Cependant des limites sont présentes dans notre travail, l’absence de segmentation est désormais un facteur limite car il facilite le processus d’utilisation de l’outil par un utilisateur qui va manipuler une image quelconque non segmentée. Un autre contrainte le non traitement de bruit qui peut affecter les résultats dans quelques situations, mais heureusement nous avons basé sur le jeu de données 2 qui contient des images déjà segmentées et l’effet de bruit minimale.