Artificial Neural Network Models for Alternative Investments
Texte intégral
Figure
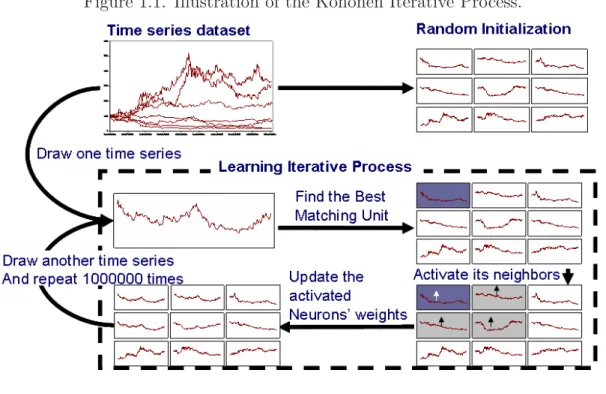

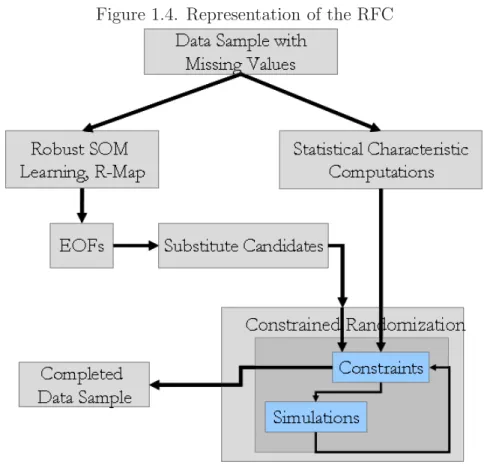




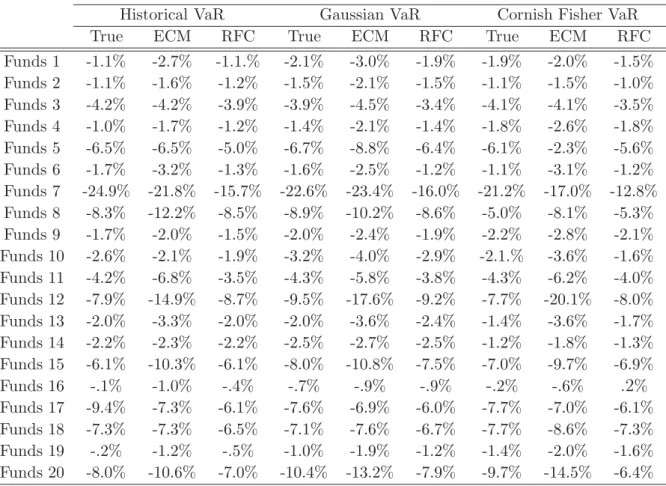


Documents relatifs
Based upon the recent literature on the aggregation theory, we have provided a model of realized log-volatility that aims at relating the behavior of the economic agents to the
In an empirical study conducted on a sample of 12 hedge funds, Lo (2002) noticed that the serial correlation in monthly hedge fund returns can overestimate the Sharpe ratio by up
More precisely, the long term dependence is examined in the …rst conditional moment of US stock returns through multivariate ARFIMA process and the time-varying feature of volatility
Artificial neural network can be used to study the effects of various parameters on different properties of anodes, and consequently, the impact on anode quality3. This technique
In each case one starts from very specific bounded square and dual square functions and concludes the boundedness of an H ∞ -calculus or even, in the case that the Banach space
Dans tous les cas, cependant, il s’avère que pour fabriquer cette entité didactique que constitue un « document authentique » sonore, on ne peut qu’occulter sa
We observed by immunoblot that the amount of P450 2C9 in HepG2 cells infected by Ad-2C9 was comparable to that measured in a pool of human liver microsomes (ratio P450 2C9
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
