Domain decomposition method for 2d and 3d transport calculations using hybrid mpi/openmp parallelism
Texte intégral
Figure
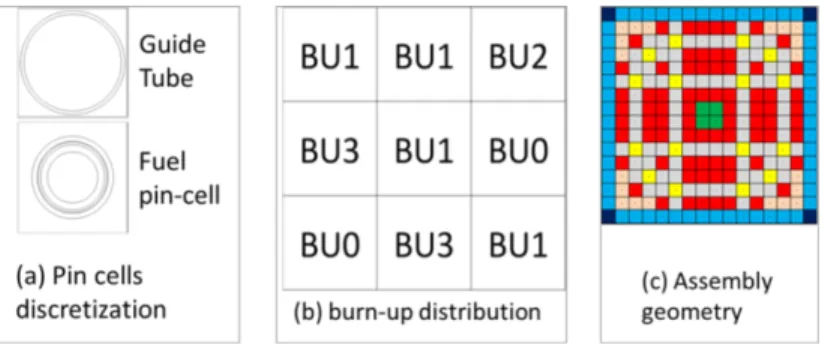
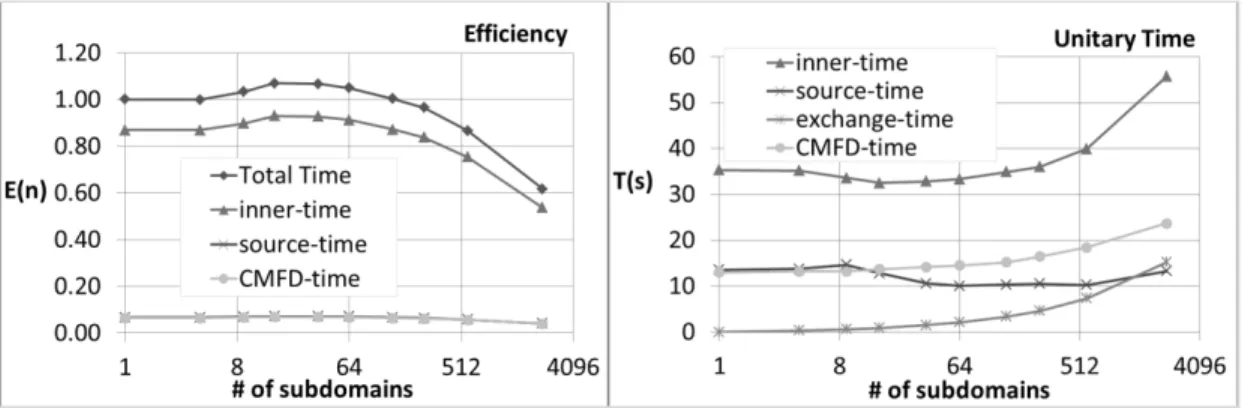
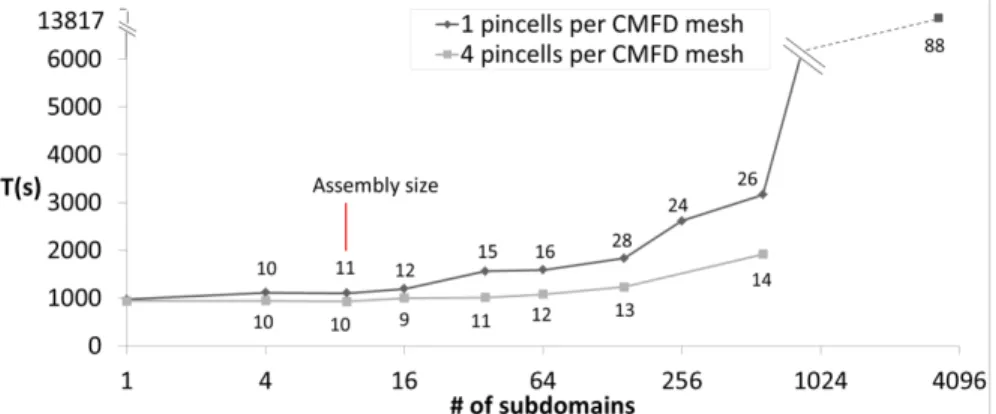
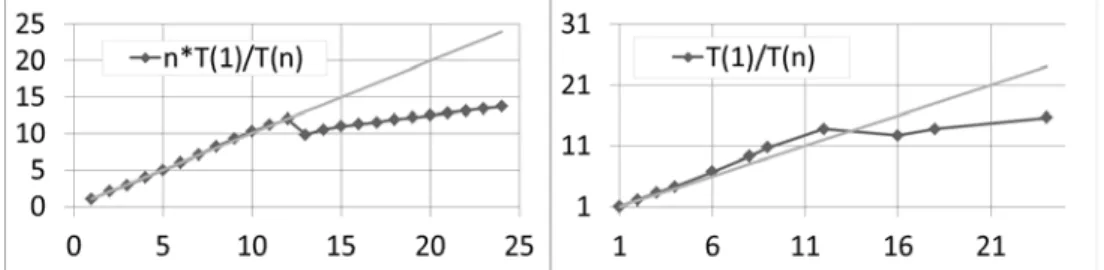
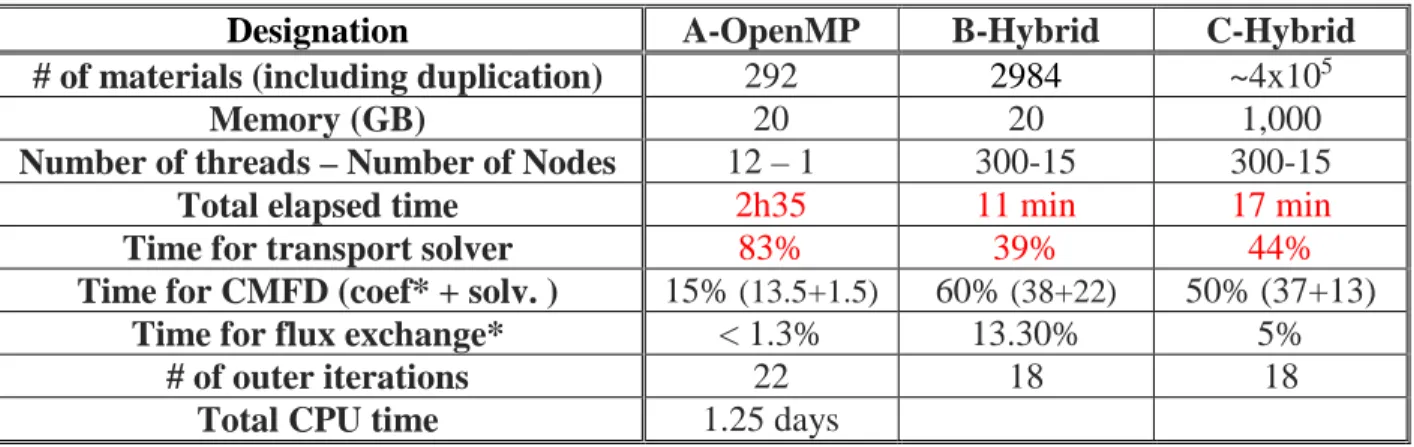

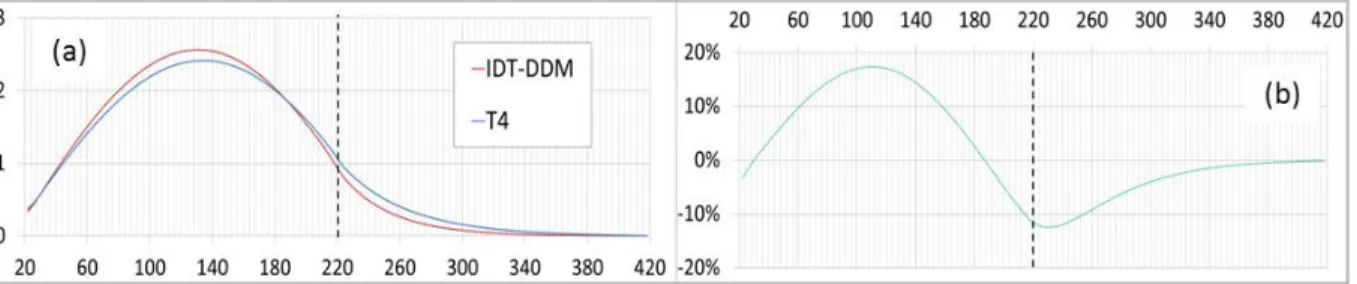
Documents relatifs
[ 35 ] Kinematic reconstructions [Dercourt et al., 1986; Le Pichon et al., 1988] suggest that at the end of Eocene times ( 35 Ma) the main plate boundary between Africa and Eurasia
8c the cholesteric liquid crystal must adapt its helical director modulation to fit the cylinder diameter d, in the sense that an integer number of full helix turns (pitches p) fit
3 Explicit/implicit and Crank-Nicolson domain decomposition meth- ods for parabolic partial differential equations 49 3.1 Model problem and DDM finite element
(6) As a conclusion, it can be observed that, for an angular speed with small variations, the Elapsed Time technique creates a low-pass filter with a sinc π shape based on ∆θ
Let the atoms be in a magnetic field of a few gauss, 10 G for example, sufficient to separate the Zeeman levels by more than their natural width (about I MHz) ; the fluorescent
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
[r]
